
Pelajari cara peningkatan WebAssembly dan WebGPU meningkatkan performa machine learning di web.



Inferensi AI di web
Kita semua telah mendengar ceritanya: AI mentransformasi dunia kita. Web juga demikian.
Tahun ini, Chrome menambahkan fitur AI generatif, termasuk pembuatan tema kustom dan atau membantu Anda menulis draf teks pertama. Namun, AI jauh lebih dari itu; AI dapat memperkaya aplikasi web itu sendiri.
Halaman web dapat menyematkan komponen cerdas untuk visi, seperti memilih wajah atau mengenali gestur, untuk klasifikasi audio, atau untuk deteksi bahasa. Dalam setahun terakhir, kami telah melihat AI generatif berkembang pesat, termasuk beberapa demo model bahasa besar yang sangat mengesankan di web. Pastikan untuk membaca AI praktis di perangkat untuk developer web.
Inferensi AI di web saat ini tersedia di sebagian besar perangkat, dan pemrosesan AI dapat terjadi di halaman web itu sendiri, dengan memanfaatkan hardware di perangkat pengguna.
Hal ini sangat bermanfaat karena beberapa alasan:
- Pengurangan biaya: Menjalankan inferensi di klien browser secara signifikan mengurangi biaya server, dan hal ini dapat sangat berguna untuk kueri GenAI, yang dapat jauh lebih mahal daripada kueri reguler.
- Latensi: Untuk aplikasi yang sangat sensitif terhadap latensi, seperti aplikasi audio atau video, jika semua pemrosesan Anda dilakukan di perangkat, latensi akan berkurang.
- Privasi: Berjalan di sisi klien, juga berpotensi membuka kelas aplikasi baru yang memerlukan peningkatan privasi, dengan data yang tidak dapat dikirim ke server.
Cara kerja workload AI di web saat ini
Saat ini, developer dan peneliti aplikasi membuat model menggunakan framework, model dijalankan di browser menggunakan runtime seperti Tensorflow.js atau ONNX Runtime Web, dan runtime menggunakan Web API untuk dijalankan.
Semua runtime tersebut pada akhirnya akan berjalan di CPU melalui JavaScript atau WebAssembly atau di GPU melalui WebGL atau WebGPU.
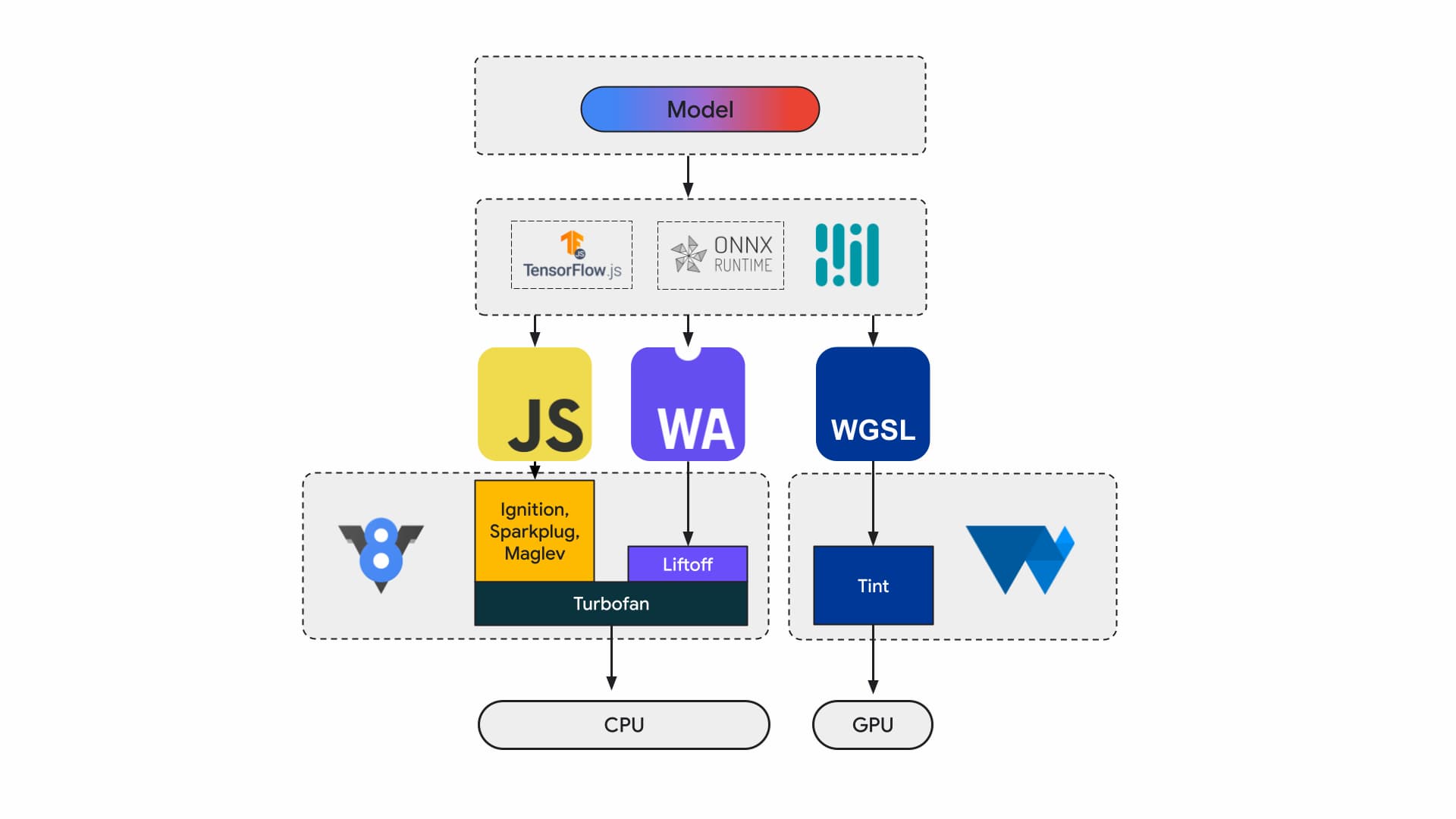
Workload machine learning
Beban kerja machine learning (ML) mendorong tensor melalui grafik node komputasi. Tensor adalah input dan output node ini yang melakukan komputasi dalam jumlah besar pada data.
Hal ini penting, karena:
- Tensor adalah struktur data yang sangat besar, yang melakukan komputasi pada model yang dapat memiliki miliaran bobot
- Penskalaan dan inferensi dapat menyebabkan paralelisme data. Artinya, operasi yang sama dilakukan di semua elemen dalam tensor.
- ML tidak memerlukan presisi. Anda mungkin memerlukan bilangan floating point 64-bit untuk mendarat di bulan, tetapi Anda mungkin hanya memerlukan banyak angka 8-bit atau kurang untuk pengenalan wajah.
Untungnya, desainer chip telah menambahkan fitur untuk membuat model berjalan lebih cepat, lebih dingin, dan bahkan memungkinkannya berjalan sama sekali.
Sementara itu, di tim WebAssembly dan WebGPU, kami sedang berupaya mengekspos kemampuan baru tersebut kepada developer web. Jika Anda adalah developer aplikasi web, Anda mungkin tidak akan sering menggunakan primitif tingkat rendah ini. Kami berharap toolchain atau framework yang Anda gunakan akan mendukung fitur dan ekstensi baru, sehingga Anda dapat memperoleh manfaat dengan perubahan minimal pada infrastruktur. Namun, jika Anda ingin menyesuaikan aplikasi secara manual untuk meningkatkan performa, fitur ini relevan dengan pekerjaan Anda.
WebAssembly
WebAssembly (Wasm) adalah format kode byte yang ringkas dan efisien yang dapat dipahami dan dieksekusi oleh runtime. WebAssembly dirancang untuk memanfaatkan kemampuan hardware yang mendasarinya, sehingga dapat dijalankan dengan kecepatan mendekati native. Kode divalidasi dan dijalankan di lingkungan sandbox yang aman untuk memori.
Informasi modul Wasm direpresentasikan dengan encoding biner yang padat. Dibandingkan dengan format berbasis teks, hal ini berarti decoding yang lebih cepat, pemuatan yang lebih cepat, dan pengurangan penggunaan memori. Compose bersifat portabel dalam arti tidak membuat asumsi tentang arsitektur yang mendasarinya yang belum umum untuk arsitektur modern.
Spesifikasi WebAssembly bersifat iteratif dan dikerjakan di grup komunitas W3C terbuka.
Format biner tidak membuat asumsi tentang lingkungan host, sehingga dirancang untuk berfungsi dengan baik dalam penyematan non-web juga.
Aplikasi Anda dapat dikompilasi satu kali, dan berjalan di mana saja: desktop, laptop, ponsel, atau perangkat lain dengan browser. Lihat Write once, run anywhere akhirnya terwujud dengan WebAssembly untuk mempelajari lebih lanjut.
Sebagian besar aplikasi produksi yang menjalankan inferensi AI di web menggunakan WebAssembly, baik untuk komputasi CPU maupun untuk berinteraksi dengan komputasi tujuan khusus. Pada aplikasi native, Anda dapat mengakses komputasi tujuan umum dan tujuan khusus, karena aplikasi dapat mengakses kemampuan perangkat.
Di web, untuk portabilitas dan keamanan, kami mengevaluasi dengan cermat kumpulan primitif yang diekspos. Hal ini menyeimbangkan aksesibilitas web dengan performa maksimal yang disediakan oleh hardware.
WebAssembly adalah abstraksi CPU portabel, sehingga semua inferensi Wasm dijalankan di CPU. Meskipun bukan pilihan yang berperforma terbaik, CPU tersedia secara luas dan berfungsi di sebagian besar beban kerja, di sebagian besar perangkat.
Untuk beban kerja yang lebih kecil, seperti beban kerja teks atau audio, GPU akan mahal. Ada sejumlah contoh terbaru yang menunjukkan bahwa Wasm adalah pilihan yang tepat:
- Adobe menggunakan Tensorflow.js untuk meningkatkan Photoshop untuk web.
- Google Meet menambahkan pemburaman latar belakang, salah satu efek video berbasis Wasm pertama di web.
- YouTube memiliki beberapa efek augmented reality.
- Google Foto memungkinkan pengeditan online.
Anda dapat menemukan lebih banyak lagi di demo open source, seperti: whisper-tiny, llama.cpp, dan Gemma2B yang berjalan di browser.
Mengambil pendekatan menyeluruh untuk aplikasi Anda
Anda harus memilih primitif berdasarkan model ML tertentu, infrastruktur aplikasi, dan pengalaman aplikasi yang diinginkan secara keseluruhan bagi pengguna
Misalnya, dalam deteksi penanda wajah MediaPipe, inferensi CPU dan inferensi GPU sebanding (berjalan di perangkat Apple M1), tetapi ada model yang variannya bisa jauh lebih tinggi.
Dalam hal beban kerja ML, kami mempertimbangkan tampilan aplikasi menyeluruh, sambil mendengarkan penulis framework dan partner aplikasi, untuk mengembangkan dan mengirimkan peningkatan yang paling banyak diminta. Secara umum, hal ini terbagi menjadi tiga kategori:
- Mengekspos ekstensi CPU yang penting untuk performa
- Mengaktifkan model yang lebih besar
- Mengaktifkan interop yang lancar dengan Web API lainnya
Komputasi yang lebih cepat
Saat ini, spesifikasi WebAssembly hanya menyertakan kumpulan petunjuk tertentu yang kami ekspos ke web. Namun, hardware terus menambahkan petunjuk yang lebih baru yang meningkatkan kesenjangan antara performa native dan WebAssembly.
Ingat, model ML tidak selalu memerlukan tingkat presisi yang tinggi. Relaxed SIMD adalah proposal yang mengurangi beberapa persyaratan non-determinisme yang ketat, sehingga menghasilkan codegen yang lebih cepat untuk beberapa operasi vektor yang merupakan hot spot untuk performa. Selain itu, Relaxed SIMD memperkenalkan perkalian titik dan petunjuk FMA baru yang mempercepat beban kerja yang ada dari 1,5 - 3 kali lipat. Fitur ini dikirimkan di Chrome 114.
Format floating point presisi setengah menggunakan 16-bit untuk IEEE FP16, bukan 32-bit yang digunakan untuk nilai presisi tunggal. Dibandingkan dengan nilai presisi tunggal, ada beberapa keuntungan dalam menggunakan nilai presisi setengah, mengurangi persyaratan memori, yang memungkinkan pelatihan dan deployment jaringan saraf yang lebih besar, mengurangi bandwidth memori. Mengurangi presisi akan mempercepat transfer data dan operasi matematika.
Model yang lebih besar
Pointer ke memori linear Wasm direpresentasikan sebagai bilangan bulat 32-bit. Hal ini memiliki dua konsekuensi: ukuran heap dibatasi hingga 4 GB (jika komputer memiliki RAM fisik yang jauh lebih besar dari itu), dan kode aplikasi yang menargetkan Wasm harus kompatibel dengan ukuran pointer 32-bit (yang).
Terutama dengan model besar seperti yang kita miliki saat ini, memuat model ini ke WebAssembly dapat menjadi terbatas. Proposal Memory64 menghapus batasan ini dengan memori linear yang lebih besar dari 4 GB dan cocok dengan ruang alamat platform native.
Kami memiliki penerapan yang berfungsi penuh di Chrome dan diperkirakan akan dirilis akhir tahun ini. Untuk saat ini, Anda dapat menjalankan eksperimen dengan flag chrome://flags/#enable-experimental-webassembly-features, dan mengirimkan masukan kepada kami.
Interop web yang lebih baik
WebAssembly dapat menjadi titik entri untuk komputasi tujuan khusus di web.
WebAssembly dapat digunakan untuk menghadirkan aplikasi GPU ke web. Artinya, aplikasi C++ yang sama yang dapat berjalan di perangkat juga dapat berjalan di web, dengan sedikit modifikasi.
Emscripten, toolchain compiler Wasm, sudah memiliki binding untuk WebGPU. Ini adalah titik entri untuk inferensi AI di web, sehingga Wasm harus dapat beroperasi secara lancar dengan platform web lainnya. Kami sedang mengerjakan beberapa proposal yang berbeda di ruang ini.
Integrasi promise JavaScript (JSPI)
Aplikasi C dan C++ standar (serta banyak bahasa lainnya) biasanya ditulis berdasarkan API sinkron. Artinya, aplikasi akan menghentikan eksekusi hingga operasi selesai. Aplikasi pemblokiran tersebut biasanya lebih intuitif untuk ditulis daripada aplikasi yang mendukung asinkron.
Jika operasi yang mahal memblokir thread utama, operasi tersebut dapat memblokir I/O dan jank akan terlihat oleh pengguna. Ada ketidakcocokan antara model pemrograman sinkron aplikasi native dan model asinkron web. Hal ini terutama bermasalah untuk aplikasi lama, yang akan mahal untuk di-port. Emscripten menyediakan cara untuk melakukannya dengan Asyncify, tetapi ini tidak selalu merupakan opsi terbaik - ukuran kode yang lebih besar dan tidak seefisien.
Contoh berikut menghitung fibonacci, menggunakan promise JavaScript untuk penambahan.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
Dalam contoh ini, perhatikan hal-hal berikut:
- Makro
EM_ASYNC_JSmenghasilkan semua kode glue yang diperlukan sehingga kita dapat menggunakan JSPI untuk mengakses hasil promise, seperti yang dilakukan untuk fungsi normal. - Opsi command line khusus,
-s ASYNCIFY=2. Tindakan ini akan memanggil opsi untuk membuat kode yang menggunakan JSPI untuk berinteraksi dengan impor JavaScript yang menampilkan promise.
Untuk mengetahui informasi selengkapnya tentang JSPI, cara menggunakannya, dan manfaatnya, baca Memperkenalkan WebAssembly JavaScript Promise Integration API di v8.dev. Pelajari uji coba origin saat ini.
Kontrol memori
Developer memiliki kontrol yang sangat sedikit atas memori Wasm; modul memiliki memorinya sendiri. Setiap API yang perlu mengakses memori ini harus menyalin masuk atau menyalin keluar, dan penggunaan ini dapat benar-benar bertambah. Misalnya, aplikasi grafis mungkin perlu menyalin masuk dan menyalin keluar untuk setiap frame.
Proposal Kontrol memori bertujuan untuk memberikan kontrol yang lebih terperinci atas memori linear Wasm dan mengurangi jumlah salinan di seluruh pipeline aplikasi. Proposal ini masih dalam Fase 1, kami sedang membuat prototipenya di V8, mesin JavaScript Chrome, untuk menginformasikan evolusi standar.
Menentukan backend yang tepat untuk Anda
Meskipun CPU ada di mana-mana, CPU tidak selalu merupakan opsi terbaik. Komputasi tujuan khusus di GPU atau akselerator dapat menawarkan performa yang jauh lebih tinggi, terutama untuk model yang lebih besar dan di perangkat kelas atas. Hal ini berlaku untuk aplikasi native dan aplikasi web.
Backend yang Anda pilih bergantung pada aplikasi, framework, atau toolchain, serta faktor lain yang memengaruhi performa. Meskipun demikian, kami terus berinvestasi dalam proposal yang memungkinkan Wasm inti berfungsi dengan baik dengan platform web lainnya, dan lebih khusus dengan WebGPU.