
Dokumen ini adalah kelanjutan dari Peningkatan WebAssembly dan WebGPU untuk AI Web yang lebih cepat, bagian 1. Sebaiknya baca postingan ini atau tonton diskusi di IO 24 sebelum melanjutkan.



WebGPU
WebGPU memberi aplikasi web akses ke hardware GPU klien untuk melakukan komputasi yang efisien dan sangat paralel. Sejak meluncurkan WebGPU di Chrome, kami telah melihat demo kecerdasan buatan (AI) dan machine learning (ML) yang luar biasa di web.
Misalnya, Stable Diffusion Web menunjukkan bahwa AI dapat digunakan untuk membuat gambar dari teks, langsung di browser. Awal tahun ini, tim Mediapipe Google sendiri memublikasikan dukungan eksperimental untuk inferensi model bahasa besar.
Animasi berikut menunjukkan Gemma, model bahasa besar (LLM) open source Google, yang berjalan sepenuhnya di perangkat di Chrome, secara real time.
Demo Hugging Face berikut dari Model Segmen Apa Pun Meta menghasilkan mask objek berkualitas tinggi sepenuhnya di klien.
Ini hanyalah beberapa project luar biasa yang menunjukkan kecanggihan WebGPU untuk AI dan ML. WebGPU memungkinkan model ini dan model lainnya berjalan jauh lebih cepat daripada di CPU.
Benchmark WebGPU untuk penyematan teks Hugging Face menunjukkan peningkatan kecepatan yang luar biasa dibandingkan dengan implementasi CPU dari model yang sama. Di laptop Apple M1 Max, WebGPU lebih cepat 30 kali lipat. Pengguna lain melaporkan bahwa WebGPU mempercepat benchmark lebih dari 120 kali.
Meningkatkan fitur WebGPU untuk AI dan ML
WebGPU sangat cocok untuk model AI dan ML, yang dapat memiliki miliaran parameter, berkat dukungan untuk compute shader. Compute shader berjalan di GPU dan membantu menjalankan operasi array paralel pada volume data yang besar.
Di antara banyak peningkatan pada WebGPU dalam setahun terakhir, kami terus menambahkan lebih banyak kemampuan untuk meningkatkan performa ML dan AI di web. Baru-baru ini, kami meluncurkan dua fitur baru: floating point 16-bit dan perkalian titik bilangan bulat yang dikemas.
Floating point 16-bit
Ingat, beban kerja ML tidak memerlukan presisi. shader-f16 adalah fitur yang memungkinkan penggunaan jenis f16 dalam bahasa shading WebGPU. Jenis floating point ini menggunakan 16 bit, bukan 32 bit seperti biasa. f16 memiliki rentang yang lebih kecil dan kurang presisi, tetapi untuk banyak model ML, hal ini sudah cukup.
Fitur ini meningkatkan efisiensi dengan beberapa cara:
Memori yang dikurangi: Tensor dengan elemen f16 hanya menggunakan setengah ruang, sehingga mengurangi penggunaan memori menjadi setengah. Komputasi GPU sering kali mengalami bottleneck pada bandwidth memori, sehingga setengah memori sering kali berarti shader berjalan dua kali lebih cepat. Secara teknis, Anda tidak memerlukan f16 untuk menghemat bandwidth memori. Anda dapat menyimpan data dalam format presisi rendah, lalu memperluasnya ke f32 penuh di shader untuk komputasi. Namun, GPU menghabiskan daya komputasi ekstra untuk memaketkan dan mengekstrak data.
Mengurangi konversi data: f16 menggunakan lebih sedikit komputasi dengan meminimalkan konversi data. Data presisi rendah dapat disimpan, lalu digunakan langsung tanpa konversi.
Peningkatan paralelisme: GPU modern dapat memuat lebih banyak nilai secara bersamaan di unit eksekusi GPU, sehingga dapat melakukan lebih banyak komputasi paralel. Misalnya, GPU yang mendukung hingga 5 triliun operasi floating point f32 per detik mungkin mendukung 10 triliun operasi floating point f16 per detik.
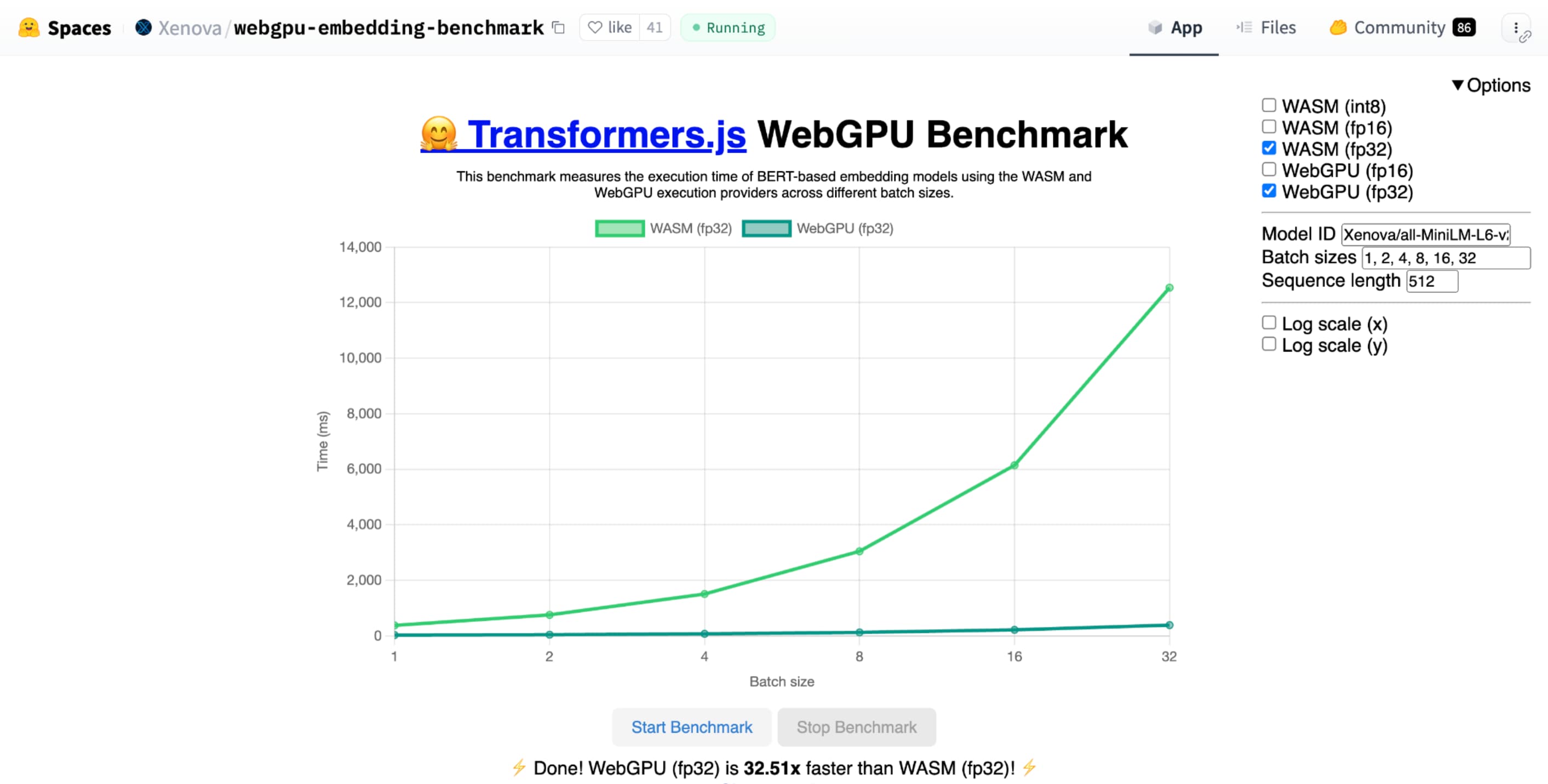
shader-f16, benchmark benchmark WebGPU untuk penyematan teks Hugging Face menjalankan benchmark 3 kali lebih cepat daripada f32 di laptop Apple M1 Max.
WebLLM adalah project yang dapat menjalankan beberapa model bahasa besar. Framework ini menggunakan Apache TVM, framework compiler machine learning open source.
Saya meminta WebLLM untuk merencanakan perjalanan ke Paris, menggunakan model parameter delapan miliar Llama 3. Hasilnya menunjukkan bahwa selama fase pra-pengisian model, f16 2,1 kali lebih cepat daripada f32. Selama fase dekode, kecepatannya lebih dari 1,3 kali lebih cepat.
Aplikasi harus mengonfirmasi terlebih dahulu bahwa adaptor GPU mendukung f16, dan jika tersedia, aktifkan secara eksplisit saat meminta perangkat GPU. Jika f16 tidak didukung, Anda tidak dapat memintanya dalam array requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Kemudian, di shader WebGPU, Anda harus mengaktifkan f16 secara eksplisit di bagian atas. Setelah itu, Anda bebas menggunakannya dalam shader seperti jenis data float lainnya.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Perkalian titik bilangan bulat yang dipaketkan
Banyak model masih berfungsi dengan baik hanya dengan presisi 8 bit (setengah dari f16). Hal ini populer di kalangan LLM dan model gambar untuk segmentasi dan pengenalan objek. Meskipun demikian, kualitas output untuk model akan menurun dengan presisi yang lebih rendah, sehingga kuantisasi 8-bit tidak cocok untuk setiap aplikasi.
Hanya sedikit GPU yang secara native mendukung nilai 8-bit. Di sinilah produk titik bilangan bulat yang dikemas digunakan. Kami mengirimkan DP4a di Chrome 123.
GPU modern memiliki petunjuk khusus untuk mengambil dua bilangan bulat 32-bit, menafsirkannya masing-masing sebagai 4 bilangan bulat 8-bit yang dikemas secara berurutan, dan menghitung hasil perkalian titik antara komponennya.
Hal ini sangat berguna untuk AI dan machine learning karena kernel perkalian matriks terdiri dari banyak sekali produk titik.
Misalnya, mari kita kalikan matriks 4x8 dengan vektor 8x1. Untuk menghitungnya, Anda harus mengambil 4 perkalian titik untuk menghitung setiap nilai dalam vektor output; A, B, C, dan D.
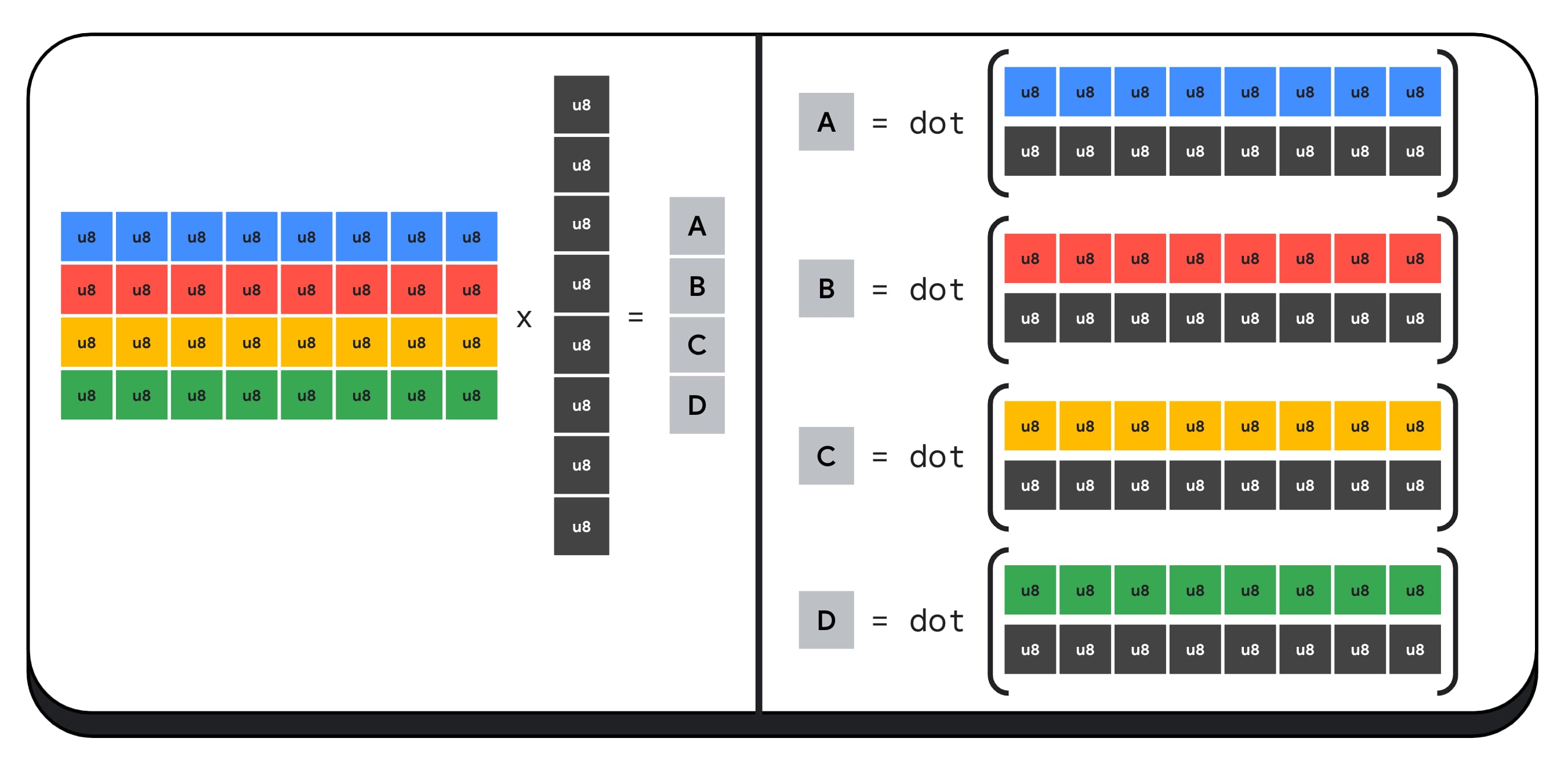
Proses untuk menghitung setiap output ini sama; kita akan melihat langkah-langkah yang terlibat dalam menghitung salah satunya. Sebelum komputasi apa pun, kita harus mengonversi data bilangan bulat 8-bit terlebih dahulu ke jenis yang dapat digunakan untuk melakukan aritmetika, seperti f16. Kemudian, kita menjalankan perkalian elemen dan terakhir, menjumlahkan semua produk. Secara total, untuk seluruh perkalian matriks-vektor, kami melakukan 40 konversi bilangan bulat ke float untuk mengekstrak data, 32 perkalian float, dan 28 penambahan float.
Untuk matriks yang lebih besar dengan lebih banyak operasi, produk titik bilangan bulat yang dikemas dapat membantu mengurangi jumlah pekerjaan.
Untuk setiap output dalam vektor hasil, kita melakukan dua operasi perkalian titik yang dikemas menggunakan dot4U8Packed bawaan WebGPU Shading Language, lalu menambahkan hasilnya. Secara total, untuk seluruh perkalian matriks-vektor, kita tidak melakukan konversi data apa pun. Kita mengeksekusi 8 produk titik yang dikemas dan 4 penambahan bilangan bulat.
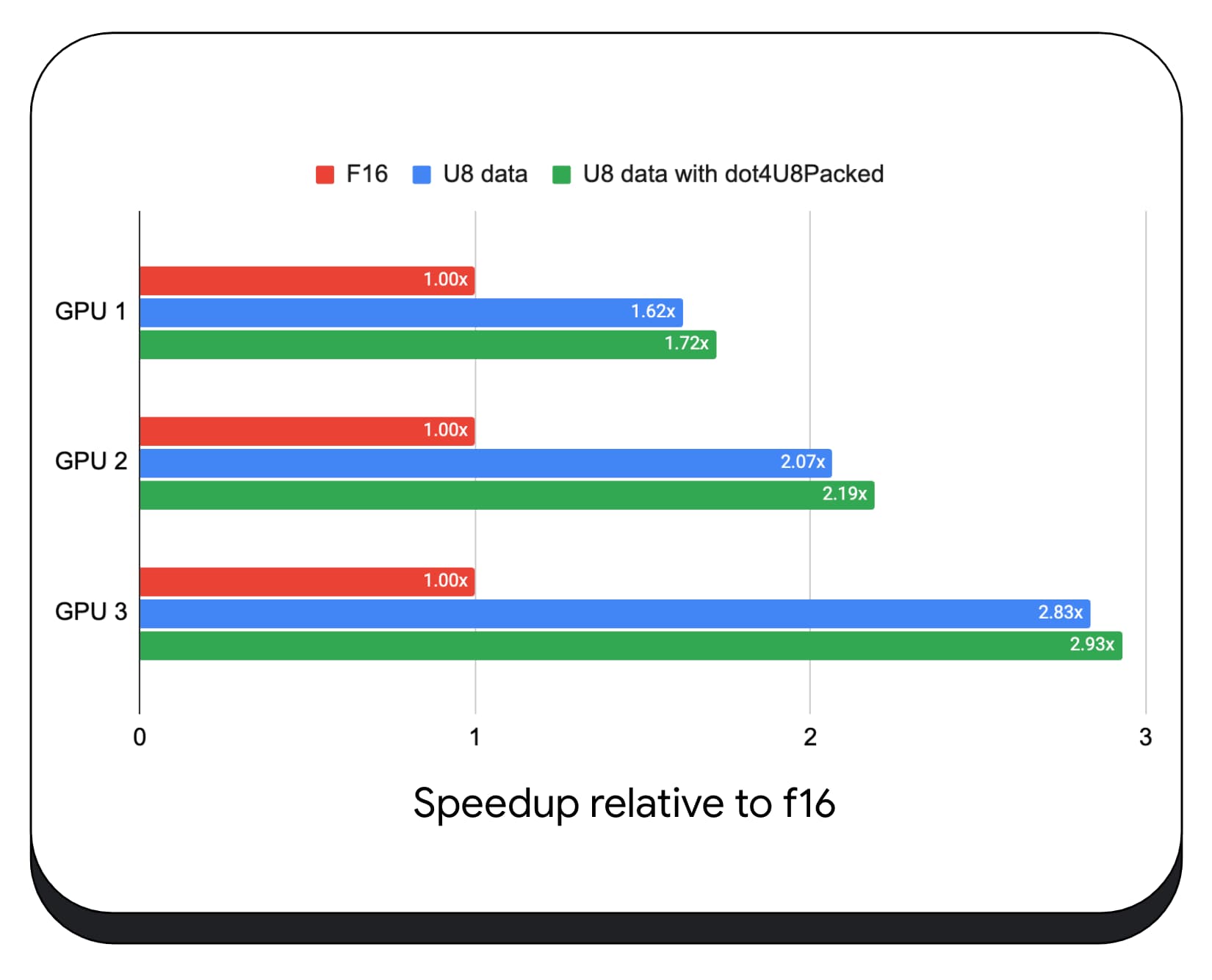
Kami menguji produk titik bilangan bulat yang dikemas dengan data 8-bit di berbagai GPU konsumen. Dibandingkan dengan floating point 16-bit, kita dapat melihat bahwa 8-bit 1,6 hingga 2,8 kali lebih cepat. Jika kita juga menggunakan produk titik bilangan bulat yang dikemas, performanya akan lebih baik. 1,7 hingga 2,9 kali lebih cepat.
Periksa dukungan browser dengan properti wgslLanguageFeatures. Jika GPU tidak mendukung produk titik yang dikemas secara native, browser akan melakukan polyfill pada implementasinya sendiri.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Perbedaan cuplikan kode berikut menyoroti perubahan yang diperlukan untuk menggunakan produk bilangan bulat yang dikemas dalam shader WebGPU.
Sebelum — Shader WebGPU yang mengakumulasi produk titik parsial ke dalam variabel `sum`. Di akhir loop, `sum` menyimpan produk titik penuh antara vektor dan satu baris matriks input.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
After — Shader WebGPU yang ditulis untuk menggunakan produk titik bilangan bulat yang dikemas. Perbedaan utamanya adalah shader ini memuat satu bilangan bulat 32-bit, bukan memuat 4 nilai float dari vektor dan matriks. Bilangan bulat 32-bit ini menyimpan data dari empat nilai bilangan bulat 8-bit. Kemudian, kita memanggil dot4U8Packed untuk menghitung hasil perkalian titik dari kedua nilai tersebut.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Floating point 16-bit dan produk titik bilangan bulat yang dikemas adalah fitur yang dikirimkan di Chrome yang mempercepat AI dan ML. Floating point 16-bit tersedia jika hardware mendukungnya, dan Chrome menerapkan produk titik bilangan bulat yang dikemas di semua perangkat.
Anda dapat menggunakan fitur ini di Chrome Stabil sekarang untuk mendapatkan performa yang lebih baik.
Fitur yang diusulkan
Ke depannya, kami akan menyelidiki dua fitur lainnya: subgrup dan perkalian matriks kooperatif.
Fitur subgrup memungkinkan paralelisme tingkat SIMD untuk berkomunikasi atau melakukan operasi matematika kolektif, seperti jumlah untuk lebih dari 16 angka. Hal ini memungkinkan pembagian data lintas thread yang efisien. Subgrup didukung di API GPU modern, dengan nama yang bervariasi dan dalam bentuk yang sedikit berbeda.
Kami telah menyaring kumpulan umum menjadi proposal yang telah kami bawa ke grup standardisasi WebGPU. Selain itu, kami telah membuat prototipe subgrup di Chrome dengan flag eksperimental, dan telah memasukkan hasil awal kami ke dalam diskusi. Masalah utamanya adalah cara memastikan perilaku portabel.
Perkalian matriks kooperatif adalah tambahan terbaru untuk GPU. Perkalian matriks besar dapat dibagi menjadi beberapa perkalian matriks yang lebih kecil. Perkalian matriks kooperatif melakukan perkalian pada blok berukuran tetap yang lebih kecil ini dalam satu langkah logis. Dalam langkah tersebut, sekelompok thread bekerja sama secara efisien untuk menghitung hasilnya.
Kami mensurvei dukungan di API GPU yang mendasarinya, dan berencana untuk mempresentasikan proposal kepada grup standarisasi WebGPU. Seperti halnya subgrup, kami memperkirakan bahwa sebagian besar diskusi akan berfokus pada portabilitas.
Untuk mengevaluasi performa operasi subgrup, dalam aplikasi yang sebenarnya, kami mengintegrasikan dukungan eksperimental untuk subgrup ke dalam MediaPipe dan mengujinya dengan prototipe Chrome untuk operasi subgrup.
Kami menggunakan subgrup dalam kernel GPU pada fase pra-pengisian model bahasa besar, jadi saya hanya melaporkan percepatan untuk fase pra-pengisian. Pada GPU Intel, kami melihat bahwa subgrup berperforma dua setengah kali lebih cepat daripada dasar pengukuran. Namun, peningkatan ini tidak konsisten di berbagai GPU.
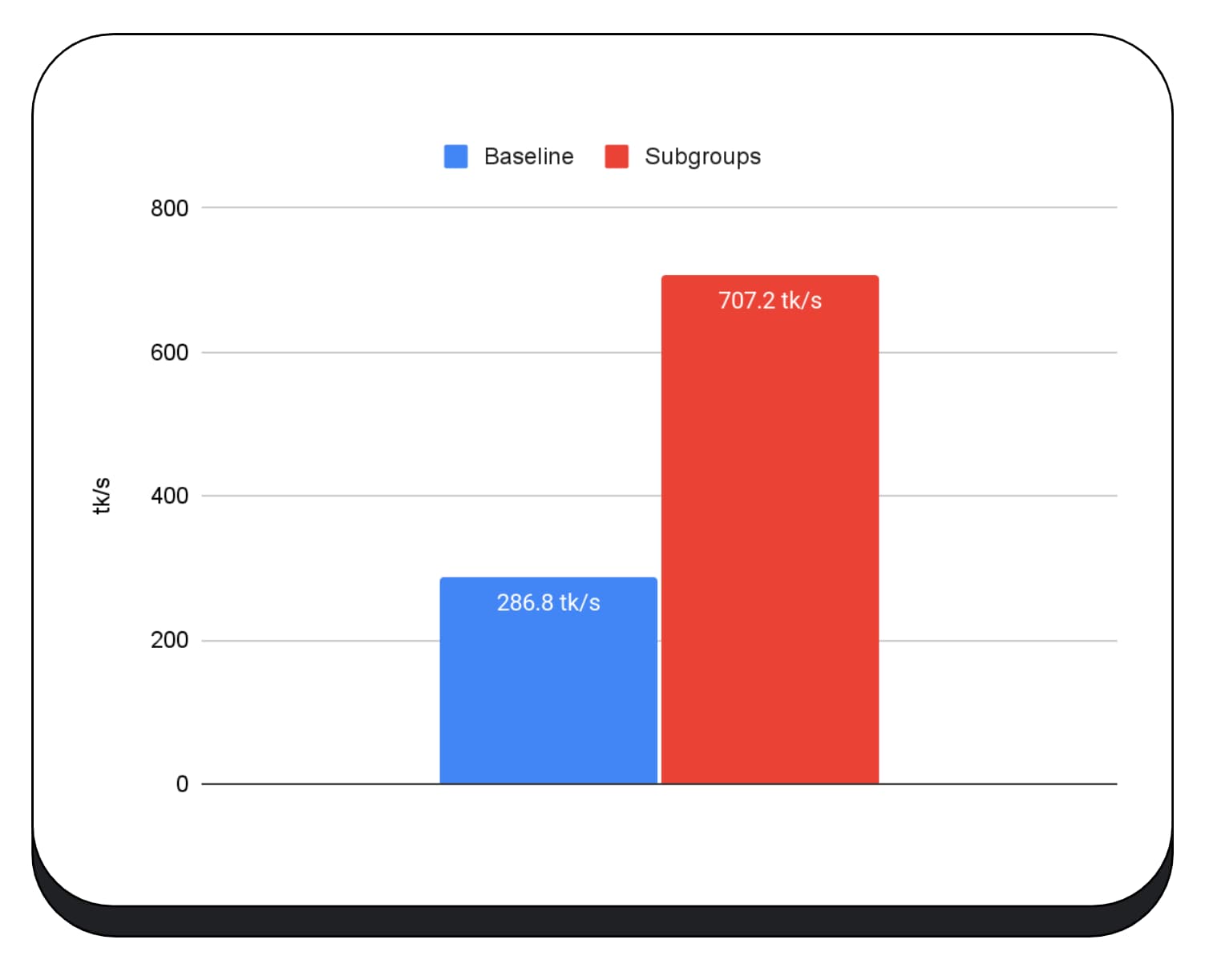
Diagram berikutnya menunjukkan hasil penerapan subgrup untuk mengoptimalkan microbenchmark perkalian matriks di beberapa GPU konsumen. Perkalian matriks adalah salah satu operasi yang lebih berat dalam model bahasa besar. Data menunjukkan bahwa pada banyak GPU, subgrup meningkatkan kecepatan dua, lima, dan bahkan tiga belas kali lipat dari dasar pengukuran. Namun, perhatikan bahwa pada GPU pertama, subgrup tidak jauh lebih baik.
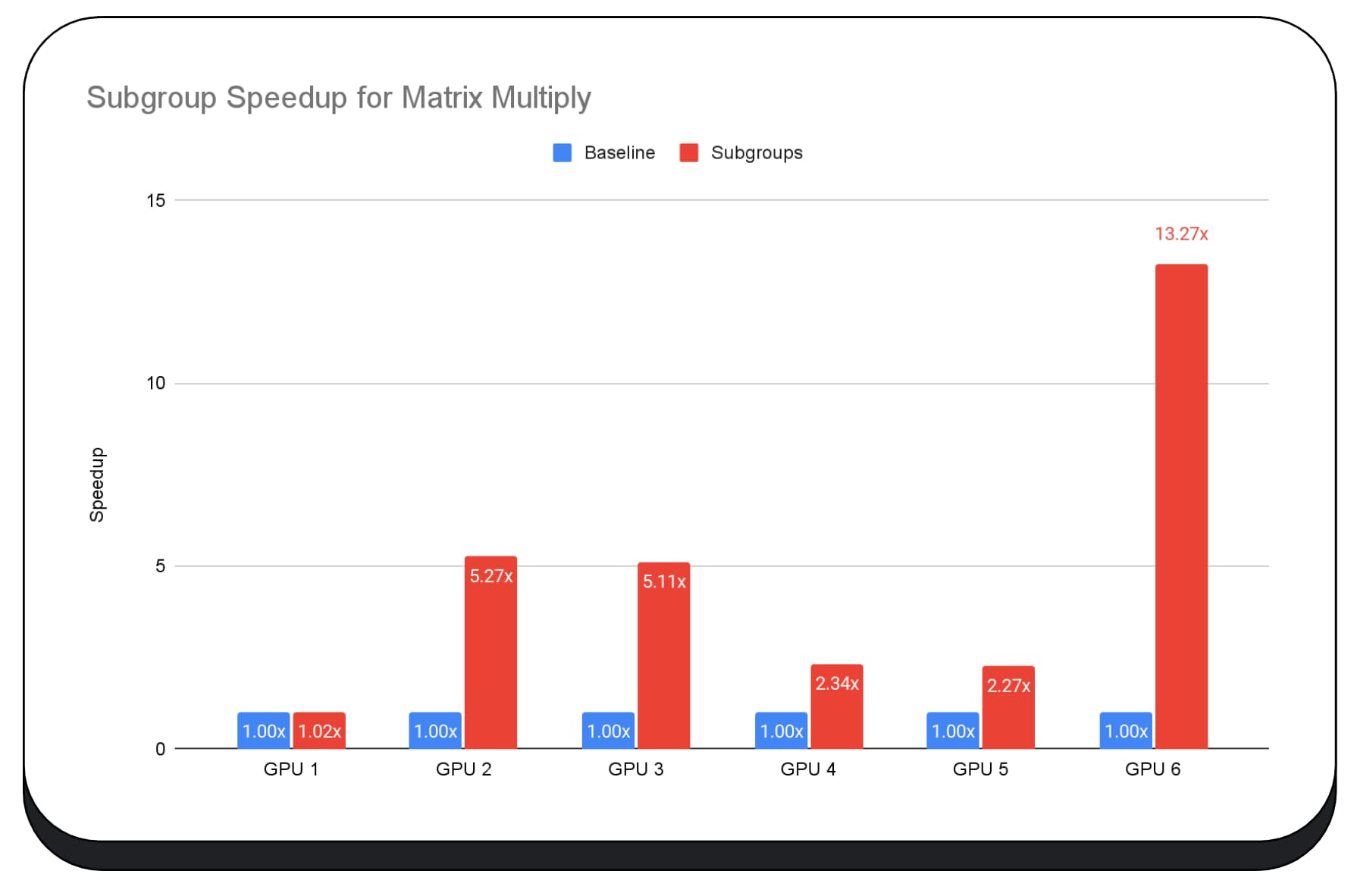
Pengoptimalan GPU sulit dilakukan
Pada akhirnya, cara terbaik untuk mengoptimalkan GPU Anda bergantung pada GPU yang ditawarkan klien. Menggunakan fitur GPU baru yang canggih tidak selalu memberikan hasil seperti yang Anda harapkan, karena mungkin ada banyak faktor kompleks yang terlibat. Strategi pengoptimalan terbaik di satu GPU mungkin bukan strategi terbaik di GPU lain.
Anda ingin meminimalkan bandwidth memori, sekaligus menggunakan thread komputasi GPU sepenuhnya.
Pola akses memori juga bisa sangat penting. GPU cenderung berperforma jauh lebih baik saat thread komputasi mengakses memori dalam pola yang optimal untuk hardware. Penting: Anda akan melihat karakteristik performa yang berbeda pada hardware GPU yang berbeda. Anda mungkin perlu menjalankan pengoptimalan yang berbeda bergantung pada GPU.
Dalam diagram berikut, kami telah menggunakan algoritma perkalian matriks yang sama, tetapi menambahkan dimensi lain untuk lebih menunjukkan dampak berbagai strategi pengoptimalan, serta kompleksitas dan varian di berbagai GPU. Kami telah memperkenalkan teknik baru di sini, yang akan kita sebut "Swizzle". Swizzle mengoptimalkan pola akses memori agar lebih optimal untuk hardware.
Anda dapat melihat bahwa swizzle memori memiliki dampak yang signifikan; terkadang bahkan lebih berdampak daripada subgrup. Pada GPU 6, swizzle memberikan peningkatan kecepatan 12x, sedangkan subgrup memberikan peningkatan kecepatan 13x. Jika digabungkan, keduanya memiliki peningkatan kecepatan 26x yang luar biasa. Untuk GPU lain, terkadang kombinasi swizzle dan subgrup berperforma lebih baik daripada salah satunya saja. Dan pada GPU lain, penggunaan swizzle secara eksklusif akan memberikan performa terbaik.
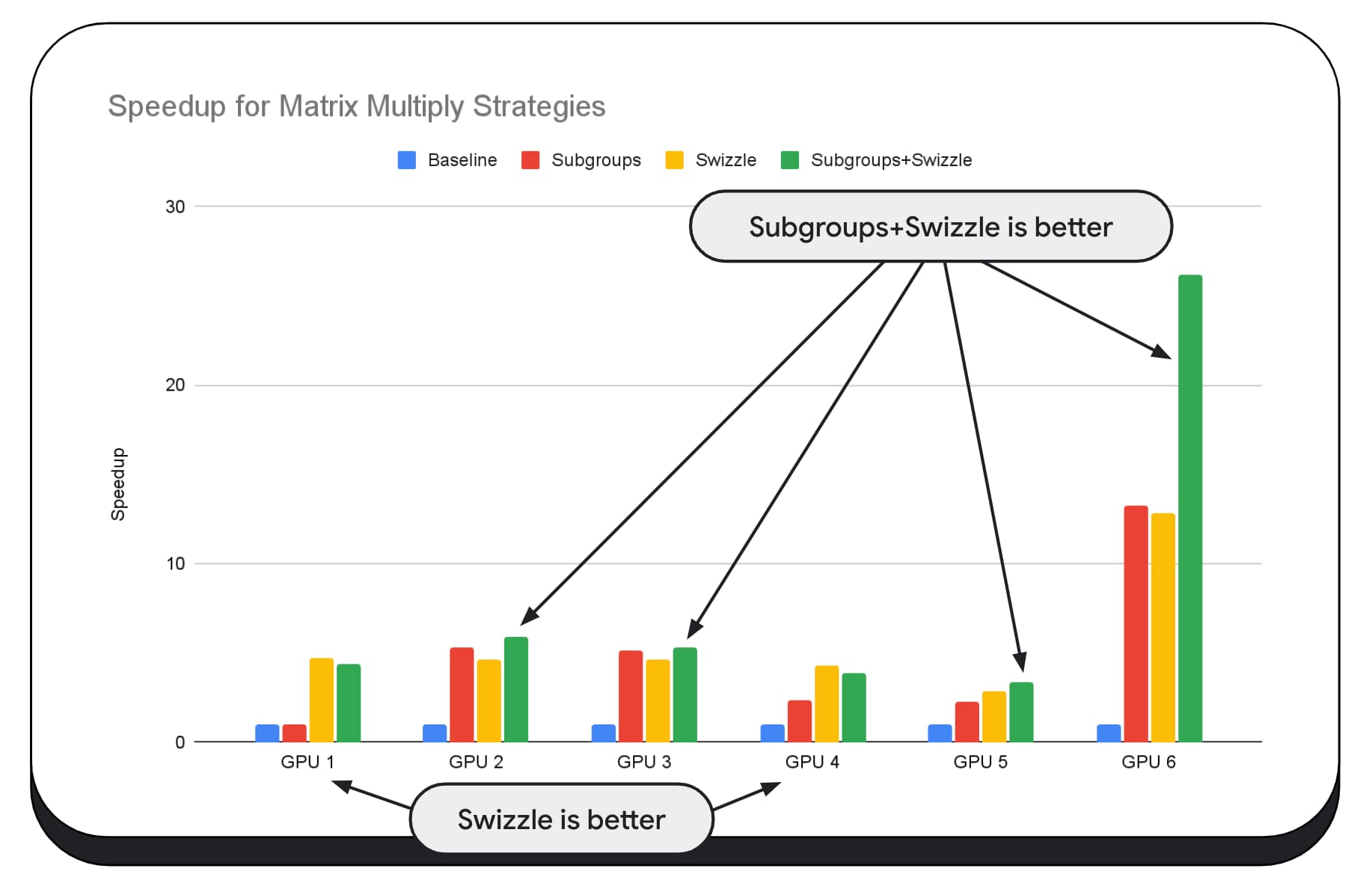
Menyesuaikan dan mengoptimalkan algoritma GPU agar berfungsi dengan baik di setiap hardware, dapat memerlukan banyak keahlian. Namun, untungnya ada banyak sekali karya berbakat yang masuk ke framework library tingkat tinggi, seperti Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web, dan lainnya.
Library dan framework berada dalam posisi yang baik untuk menangani kompleksitas pengelolaan berbagai arsitektur GPU, dan menghasilkan kode khusus platform yang akan berjalan dengan baik di klien.
Poin-poin penting
Tim Chrome terus membantu mengembangkan standar WebAssembly dan WebGPU untuk meningkatkan platform web bagi workload machine learning. Kami berinvestasi dalam primitif komputasi yang lebih cepat, interop yang lebih baik di seluruh standar web, dan memastikan bahwa model besar dan kecil dapat berjalan secara efisien di seluruh perangkat.
Sasaran kami adalah memaksimalkan kemampuan platform sekaligus mempertahankan hal terbaik dari web: jangkauan, kegunaan, dan portabilitasnya. Dan kami tidak melakukannya sendirian. Kami bekerja sama dengan vendor browser lain di W3C, dan banyak partner pengembangan.
Kami harap Anda mengingat hal berikut saat menggunakan WebAssembly dan WebGPU:
- Inferensi AI kini tersedia di web, di seluruh perangkat. Hal ini memberikan keuntungan untuk dijalankan di perangkat klien, seperti pengurangan biaya server, latensi rendah, dan peningkatan privasi.
- Meskipun banyak fitur yang dibahas terutama relevan bagi penulis framework, aplikasi Anda dapat memperoleh manfaat tanpa banyak overhead.
- Standar web bersifat dinamis dan terus berkembang, dan kami selalu mencari masukan. Bagikan masukan Anda untuk WebAssembly dan WebGPU.
Ucapan terima kasih
Kami ingin berterima kasih kepada tim grafis web Intel, yang berperan penting dalam mendorong fitur WebGPU f16 dan fitur perkalian titik bilangan bulat yang dikemas. Kami ingin berterima kasih kepada anggota lain dari grup kerja WebAssembly dan WebGPU di W3C, termasuk vendor browser lainnya.
Terima kasih kepada tim AI dan ML di Google dan di komunitas open source karena telah menjadi partner yang luar biasa. Dan tentu saja, semua rekan tim kami yang memungkinkan semua ini.