

Building websites that respond quickly to user input has been one of the most challenging aspects of web performance—one that the Chrome Team has been working hard to help web developers meet. Just this year, it was announced that the Interaction to Next Paint (INP) metric would graduate from experimental to pending status. It is now poised to replace First Input Delay (FID) as a Core Web Vital in March of 2024.
In a continued effort to deliver new APIs that help web developers make their websites as snappy as they can be, the Chrome Team is currently running an origin trial for scheduler.yield starting in version 115 of Chrome. scheduler.yield is a proposed new addition to the scheduler API that allows for both an easier and better way to yield control back to the main thread than the methods that have been traditionally relied upon.
On yielding
JavaScript uses the run-to-completion model to deal with tasks. This means that, when a task runs on the main thread, that task runs as long as necessary in order to complete. Upon a task's completion, control is yielded back to the main thread, which allows the main thread to process the next task in the queue.
Aside from extreme cases when a task never finishes—such as an infinite loop, for example—yielding is an inevitable aspect of JavaScript's task scheduling logic. It will happen, it's just a matter of when, and sooner is better than later. When tasks take too long to run—greater than 50 milliseconds, to be exact—they are considered to be long tasks.
Long tasks are a source of poor page responsiveness, because they delay the browser's ability to respond to user input. The more often long tasks occur—and the longer they run—the more likely it is that users may get the impression that the page is sluggish, or even feel that it's altogether broken.
However, just because your code kicks off a task in the browser doesn't mean you have to wait until that task is finished before control is yielded back to the main thread. You can improve responsiveness to user input on a page by yielding explicitly in a task, which breaks the task up to be finished at the next available opportunity. This allows other tasks to get time on the main thread sooner than if they had to wait for long tasks to finish.
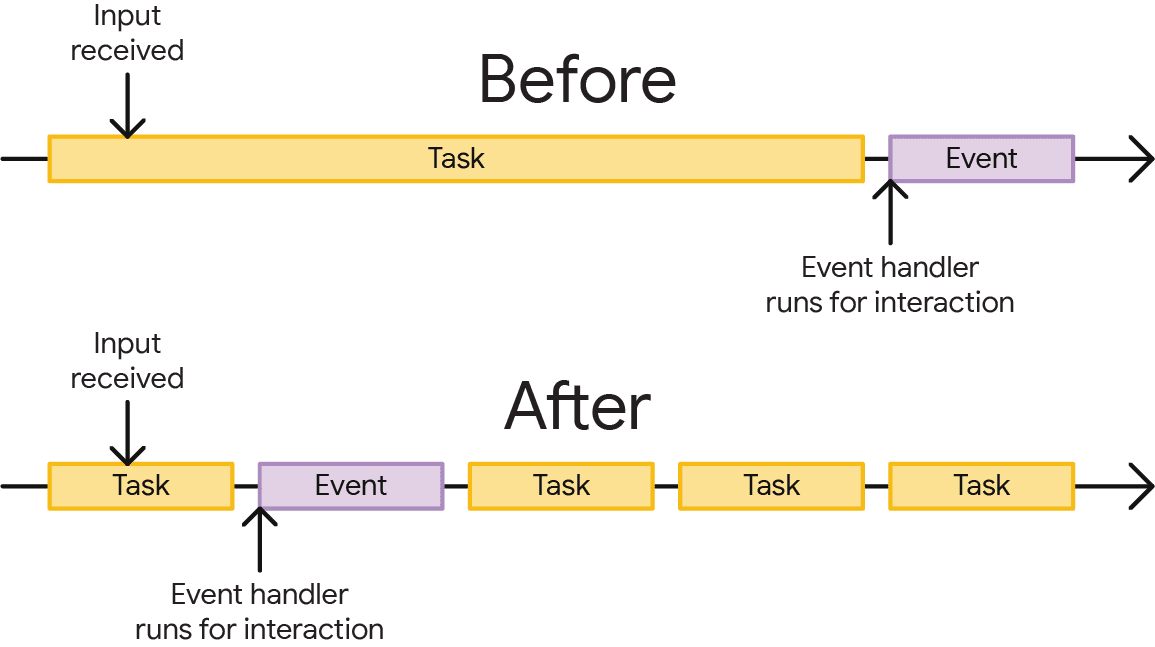
When you explicitly yield, you're telling the browser "hey, I understand that the work I'm about to do could take a while, and I don't want you to have to do all of that work before responding to user input or other tasks that might be important, too". It's a valuable tool in a developer's toolbox that can go a long way towards improving the user experience.
The problem with current yielding strategies
A common method of yielding uses setTimeout with a timeout value of 0. This works because the callback passed to setTimeout will move the remaining work to a separate task that will be queued for subsequent execution. Rather than waiting for the browser to yield on its own, you're saying "break this big chunk of work up into smaller bits".
However, yielding with setTimeout carries a potentially undesirable side effect: the work that comes after the yield point will go to the back of the task queue. Tasks scheduled by user interactions will still go to the front of the queue as they should—but the remaining work you wanted to do after explicitly yielding could end up being further delayed by other tasks from competing sources that were queued ahead of it.
To see this in action, try out this Codepen demo—or experiment with it in the following embedded version. The demo consists of a few buttons you can click, and a box beneath them that logs when tasks are run. When you land on the page, perform the following actions:
- Click the top button labeled Run tasks periodically, which will schedule blocking tasks to run every so often. When you click this button, the task log will populate with several messages that read Ran blocking task with
setInterval. - Next, click the button labeled Run loop, yielding with
setTimeouton each iteration.
You'll notice that the box at the bottom of the demo will read something like this:
Processing loop item 1
Processing loop item 2
Ran blocking task via setInterval
Processing loop item 3
Ran blocking task via setInterval
Processing loop item 4
Ran blocking task via setInterval
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
This output demonstrates the "end of task queue" behavior that occurs when yielding with setTimeout. The loop that runs processes five items, and yields with setTimeout after each one has been processed.
This illustrates a common problem on the web: it's not unusual for a script—particularly a third-party script—to register a timer function that runs work on some interval. The "end of task queue" behavior that comes with yielding with setTimeout means that work from other task sources may get queued ahead of the remaining work that the loop has to do after yielding.
Depending on your application, this may or may not be a desirable outcome—but in many cases, this behavior is why developers may feel reluctant to give up control of the main thread so readily. Yielding is good because user interactions have the opportunity to run sooner, but it also allows other non-user interaction work to get time on the main thread too. It's a real problem—but scheduler.yield can help solve it!
Enter scheduler.yield
scheduler.yield has been available behind a flag as an experimental web platform feature since version 115 of Chrome. One question you might have is "why do I need a special function to yield when setTimeout already does it?"
It's worth noting that yielding was not a design goal of setTimeout, but rather a nice side effect in scheduling a callback to run at a later point in the future—even with a timeout value of 0 specified. What's more important to remember, however, is that yielding with setTimeout sends remaining work to the back of the task queue. By default, scheduler.yield sends remaining work to the front of the queue. This means that work you wanted to resume immediately after yielding won't take a back seat to tasks from other sources (with the notable exception of user interactions).
scheduler.yield is a function that yields to the main thread and returns a Promise when called. This means you can await it in an async function:
async function yieldy () {
// Do some work...
// ...
// Yield!
await scheduler.yield();
// Do some more work...
// ...
}
To see scheduler.yield in action, do the following:
- Navigate to
chrome://flags. - Enable the Experimental Web Platform features experiment. You may have to restart Chrome after doing this.
- Navigate to the demo page or use the following embedded version of it after this list.
- Click the top button labeled Run tasks periodically.
- Finally, click the button labeled Run loop, yielding with
scheduler.yieldon each iteration.
The output in the box at the bottom of the page will look something like this:
Processing loop item 1
Processing loop item 2
Processing loop item 3
Processing loop item 4
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Unlike the demo that yields using setTimeout, you can see that the loop—even though it yields after every iteration—doesn't send the remaining work to the back of the queue, but rather to the front of it. This gives you the best of both worlds: you can yield to improve input responsiveness on your website, but also ensure that the work you wanted to finish after yielding doesn't get delayed.
Give it a try!
If scheduler.yield looks interesting to you and you want to try it out, you can do so in two ways starting in version 115 of Chrome:
- If you want to experiment with
scheduler.yieldlocally, type and enterchrome://flagsin Chrome's address bar and select Enable from the drop-down in the Experimental Web Platform Features section. This will makescheduler.yield(and any other experimental features) available in only your instance of Chrome. - If you want to enable
scheduler.yieldfor real Chromium users on a publicly accessible origin, you'll need to sign up for thescheduler.yieldorigin trial. This lets you safely experiment with proposed features for a given period of time, and gives the Chrome Team valuable insights into how those features are used in the field. For more information on how origin trials work, read this guide.
How you use scheduler.yield—while still supporting browsers that don't implement it—depends on what your goals are. You can use the official polyfill. The polyfill is useful if the following applies to your situation:
- You're already using
scheduler.postTaskin your application to schedule tasks. - You want to be able to set task and yielding priorities.
- You want to be able to cancel or reprioritize tasks using the
TaskControllerclass thescheduler.postTaskAPI offers.
If this doesn't describe your situation, then the polyfill might not be for you. In that case, you can roll your own fallback in a couple of ways. The first approach uses scheduler.yield if it's available, but falls back to setTimeout if it isn't:
// A function for shimming scheduler.yield and setTimeout:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to setTimeout:
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
This can work, but as you might guess, browsers that don't support scheduler.yield will yield without "front of queue" behavior. If that means you'd rather not yield at all, you can try another approach which uses scheduler.yield if it's available, but won't yield at all if it isn't:
// A function for shimming scheduler.yield with no fallback:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to nothing:
return;
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
scheduler.yield is an exciting addition to the scheduler API—one that will hopefully make it easier for developers to improve responsiveness than current yielding strategies. If scheduler.yield seems like a useful API to you, please participate in our research to help improve it, and provide feedback on how it could be further improved.
Hero image from Unsplash, by Jonathan Allison.