


使用 GPU 设置一致的测试环境可能比预期更困难。以下步骤可以在真实的浏览器环境中测试基于浏览器的客户端 AI 模型,同时还能实现可伸缩、可自动化且在已知的标准化硬件设置中。
在这种情况下,浏览器是真正的 Chrome 浏览器,支持硬件,而不是软件模拟。
无论您是 Web AI、Web 游戏还是图形开发者,还是对 Web AI 模型测试感兴趣,本指南都适合您。
第 1 步:创建新的 Google Colab 笔记本
1. 请前往 colab.new,创建新的 Colab 笔记本。它看起来应类似于图 1。 2. 按照提示登录您的 Google 帐号。
第 2 步:连接到支持 GPU 的 T4 服务器
- 点击笔记本右上角附近的连接 。
- 选择更改运行时类型:
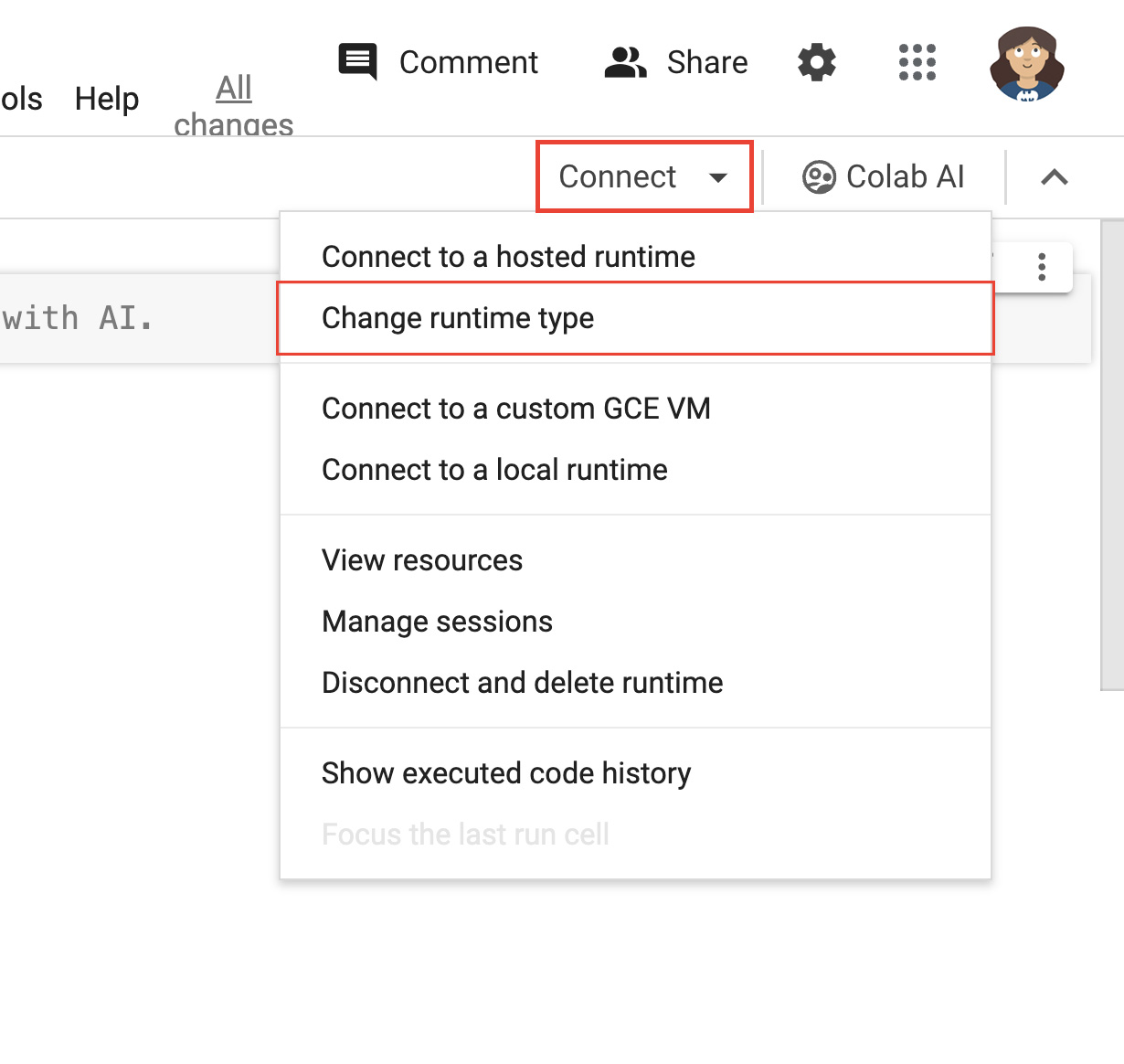
图 2. 在 Colab 界面中更改运行时。 - 在模态窗口中,选择 T4 GPU 作为硬件加速器。连接后,Colab 将使用挂接了 NVIDIA T4 GPU 的 Linux 实例。
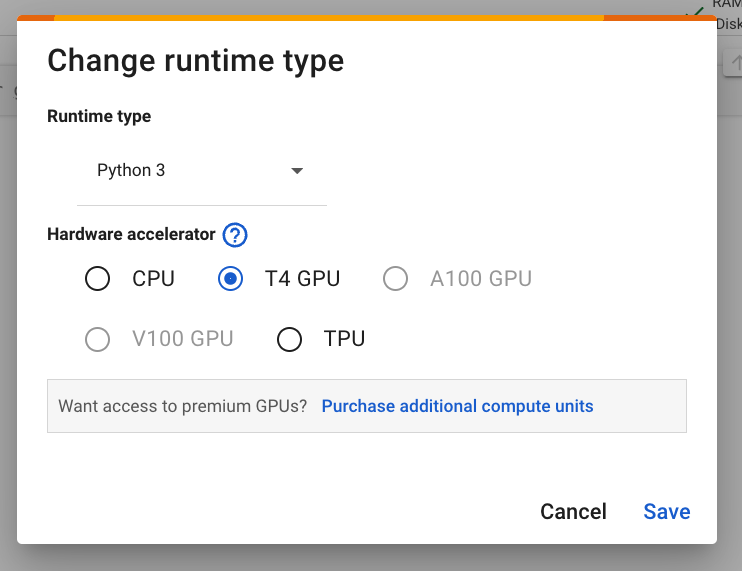
图 3:在“硬件加速器”下,选择 T4 GPU。 - 点击保存。
- 点击 Connect 按钮以连接到您的运行时。一段时间后,该按钮会显示绿色对勾标记,以及 RAM 和磁盘使用情况图表。这表示已使用所需硬件成功创建了服务器。
非常好!您刚刚创建了一个连接了 GPU 的服务器。
第 3 步:安装正确的驱动程序和依赖项
将以下两行代码复制并粘贴到笔记本的第一个代码单元中。在 Colab 环境中,命令行执行作业前带有一个感叹号。
!git clone https://github.com/jasonmayes/headless-chrome-nvidia-t4-gpu-support.git !cd headless-chrome-nvidia-t4-gpu-support && chmod +x scriptyMcScriptFace.sh && ./scriptyMcScriptFace.sh- 您可以检查 GitHub 上的脚本,查看此脚本执行的原始命令行代码。
# Update, install correct drivers, and remove the old ones. apt-get install -y vulkan-tools libnvidia-gl-525 # Verify NVIDIA drivers can see the T4 GPU and that vulkan is working correctly. nvidia-smi vulkaninfo --summary # Now install latest version of Node.js npm install -g n n lts node --version npm --version # Next install Chrome stable curl -fsSL https://dl.google.com/linux/linux_signing_key.pub | sudo gpg --dearmor -o /usr/share/keyrings/googlechrom-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrom-keyring.gpg] http://dl.google.com/linux/chrome/deb/ stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list sudo apt update sudo apt install -y google-chrome-stable # Start dbus to avoid warnings by Chrome later. export DBUS_SESSION_BUS_ADDRESS="unix:path=/var/run/dbus/system_bus_socket" /etc/init.d/dbus start点击单元旁边的 以执行代码。
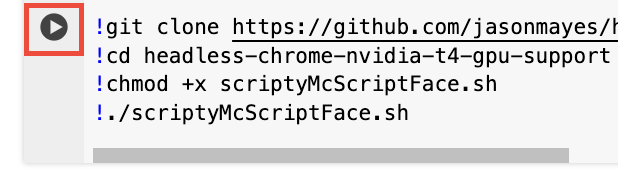
图 4. 代码执行完毕后,验证
nvidia-smi是否输出类似于以下屏幕截图的内容,以确认您确实连接了 GPU,并在服务器上识别出该 GPU。您可能需要滚动到日志的前面部分才能查看此输出。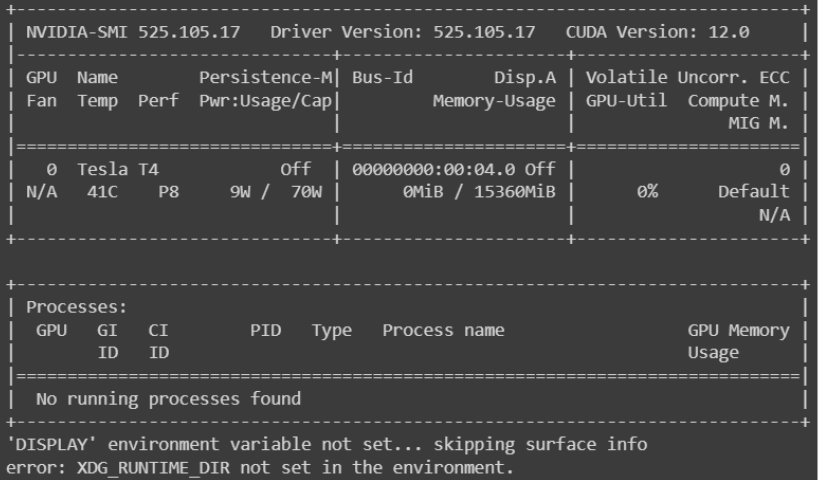
图 5:查找以“NVIDIA-SMI”开头的输出。
第 4 步:使用并自动执行无头 Chrome
- 点击 代码按钮以添加新的代码单元格。
- 然后,您可以编写自定义代码,以使用您偏好的参数调用 Node.js 项目(或者直接在命令行中调用
google-chrome-stable)。我们在下方提供了两个示例。
A 部分:直接在命令行中使用无头 Chrome
# Directly call Chrome to dump a PDF of WebGPU testing page
# and store it in /content/gpu.pdf
!google-chrome-stable \
--no-sandbox \
--headless=new \
--use-angle=vulkan \
--enable-features=Vulkan \
--disable-vulkan-surface \
--enable-unsafe-webgpu \
--print-to-pdf=/content/gpu.pdf https://webgpureport.org
在该示例中,我们将生成的 PDF 捕获存储在 /content/gpu.pdf 中。如需查看该文件,请展开内容 。然后点击 以将 PDF 文件下载到本地机器。
B 部分:使用 Puppeteer 命令 Chrome
我们提供了一个极简的示例使用 Puppeteer 控制 Headless Chrome,可以按如下方式运行:
# Call example node.js project to perform any task you want by passing
# a URL as a parameter
!node headless-chrome-nvidia-t4-gpu-support/examples/puppeteer/jPuppet.js chrome://gpu
在 jPuppet 示例中,我们可以调用 Node.js 脚本来创建屏幕截图。不过,工作原理是什么呢?查看 jPuppet.js 中的 Node.js 代码演示。
jPuppet.js 节点代码细分
首先,导入 Puppeteer。这样,您就可以使用 Node.js 远程控制 Chrome:
import puppeteer from 'puppeteer';
接下来,查看哪些命令行参数已传递给 Node 应用。确保已设置第三个参数,它表示要导航到的网址。您需要检查此处的第三个参数,因为前两个参数调用 Node 本身以及我们运行的脚本。第 3 个元素实际上包含传递给 Node 程序的第一个参数:
const url = process.argv[2];
if (!url) {
throw "Please provide a URL as the first argument";
}
现在,定义一个名为 runWebpage() 的异步函数。这会创建一个使用命令行参数配置的浏览器对象,以便按照使 WebGL 和 WebGPU 正常运行所需的方式(如启用 WebGPU 和 WebGL 支持中所述)运行 Chrome 二进制文件。
async function runWebpage() {
const browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--headless=new',
'--use-angle=vulkan',
'--enable-features=Vulkan',
'--disable-vulkan-surface',
'--enable-unsafe-webgpu'
]
});
创建一个新的浏览器页面对象,稍后您可以使用该对象访问任何网址:
const page = await browser.newPage();
然后,添加事件监听器,以便在网页执行 JavaScript 时监听 console.log 事件。这样,您就可以在 Node 命令行上记录消息,并检查控制台文本中是否存在会触发屏幕截图,然后结束 Node 中的浏览器进程的特殊短语(在本例中为 captureAndEnd)。这对于需要在截取屏幕截图之前执行一些工作并且执行时间不确定的网页非常有用。
page.on('console', async function(msg) {
console.log(msg.text());
if (msg.text() === 'captureAndEnd') {
await page.screenshot({ path: '/content/screenshotEnd.png' });
await browser.close();
}
});
最后,命令网页访问指定的网址,并在页面加载后获取初始屏幕截图。
如果您选择获取 chrome://gpu 的屏幕截图,则可以立即关闭浏览器会话,而无需等待任何控制台输出,因为此页面并非由您自己的代码控制。
await page.goto(url, { waitUntil: 'networkidle2' });
await page.screenshot({path: '/content/screenshot.png'});
if (url === 'chrome://gpu') {
await browser.close();
}
}
runWebpage();
修改 package.json
您可能已经注意到,我们在 jPuppet.js 文件的开头使用了 import 语句。您的 package.json 必须将类型值设置为 module,否则您将收到模块无效的错误。
{
"dependencies": {
"puppeteer": "*"
},
"name": "content",
"version": "1.0.0",
"main": "jPuppet.js",
"devDependencies": {},
"keywords": [],
"type": "module",
"description": "Node.js Puppeteer application to interface with headless Chrome with GPU support to capture screenshots and get console output from target webpage"
}
这就是全部内容!使用 Puppeteer 可以更轻松地以编程方式与 Chrome 进行交互。
成功
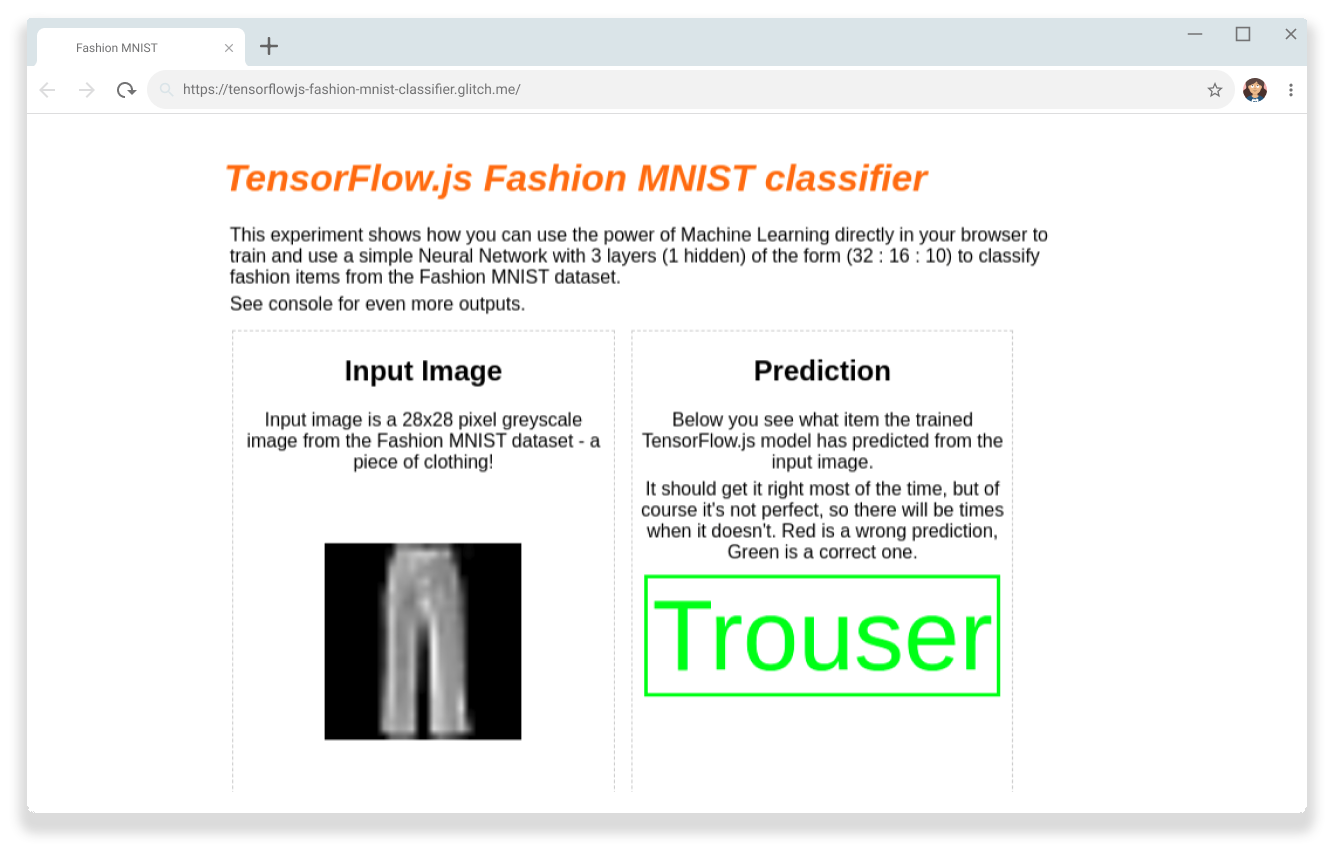
现在,我们可以在使用 GPU 在浏览器中进行客户端处理,验证 TensorFlow.js Fashion MNIST 分类器能否正确识别图片中的一双裤子。
您可以将此模型用于任何基于 GPU 的客户端工作负载,从机器学习模型到图形和游戏测试。
资源
在 GitHub 代码库中添加星标,以接收将来的更新。