


GPU を使用して一貫したテスト環境を設定することは、予想よりも難しい場合があります。以下では、スケーラブルで自動化可能であり、既知の標準化されたハードウェア設定内で、クライアントサイドのブラウザベースの AI モデルを実際のブラウザ環境でテストする手順について説明します。
この場合、ブラウザはソフトウェア エミュレーションではなく、ハードウェア サポートを備えた実際の Chrome ブラウザです。
ウェブ AI、ウェブ ゲーム、グラフィック デベロッパーの方、またはウェブ AI モデルのテストに関心をお持ちの方は、このガイドをご利用ください。
ステップ 1: 新しい Google Colab ノートブックを作成する
1. colab.new に移動して、新しい Colab ノートブックを作成します。図 1 のようになります。2. 画面の指示に沿って Google アカウントにログインします。
ステップ 2: T4 GPU 対応サーバーに接続する
- ノートブックの右上にある [接続] をクリックします。
- [ランタイム タイプを変更] を選択します。
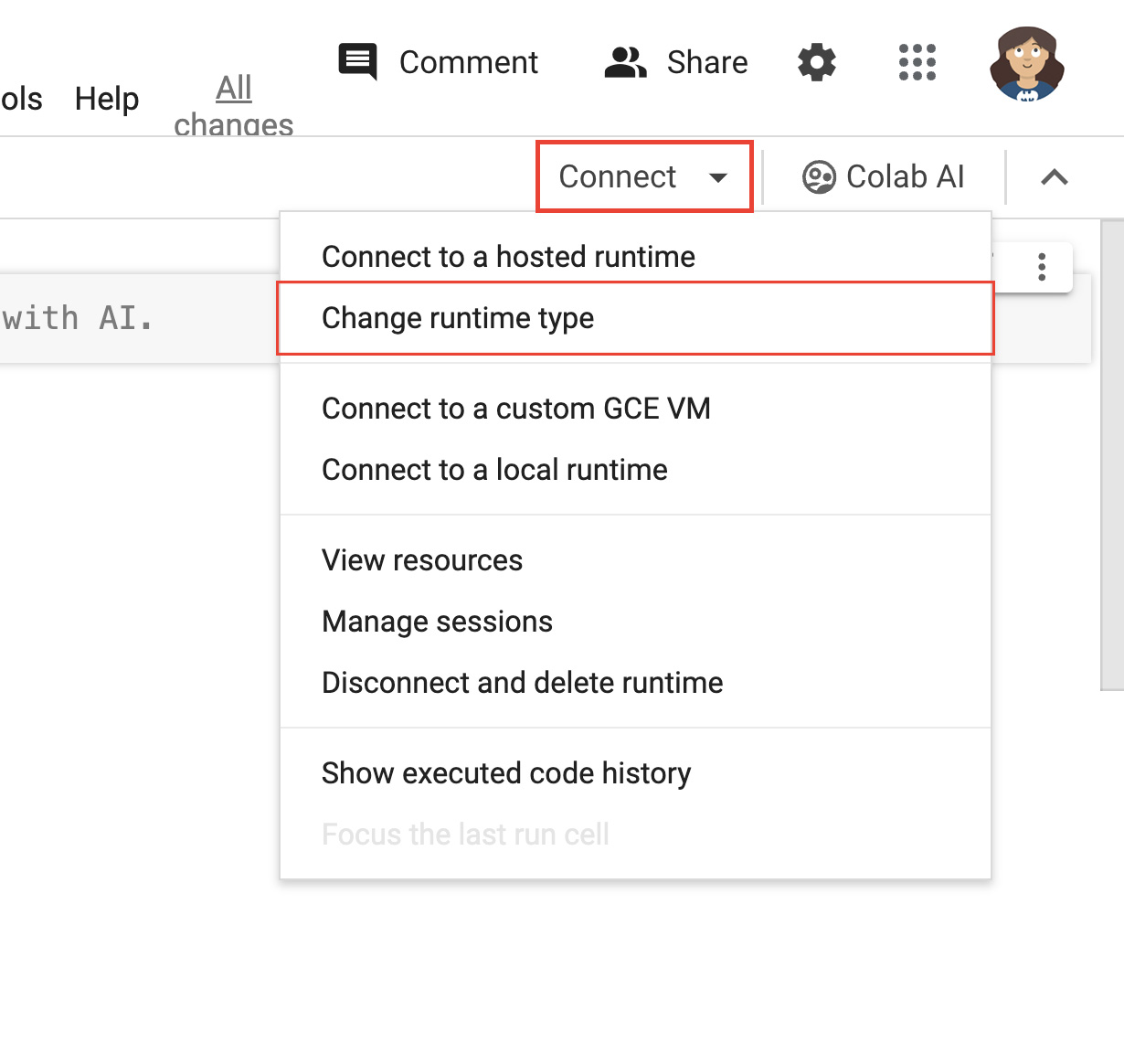
図 2Colab インターフェースでランタイムを変更します。 - モーダル ウィンドウで、ハードウェア アクセラレータとして [T4 GPU] を選択します。接続すると、Colab は NVIDIA T4 GPU が接続された Linux インスタンスを使用します。
![[ランタイムのタイプを変更] モジュールのスクリーンショット。](https://developer.chrome.google.cn/static/docs/web-platform/webgpu/colab-headless/image/select-t4.png?authuser=00&hl=ja)
図 3: [ハードウェア アクセラレータ] で [T4 GPU] を選択します。 - [保存] をクリックします。
- [接続] ボタンをクリックしてランタイムに接続します。しばらくすると、ボタンに緑色のチェックマークと、RAM とディスクの使用状況のグラフが表示されます。これは、必要なハードウェアを使用してサーバーが正常に作成されたことを示します。
これで、GPU が接続されたサーバーが作成されました。
ステップ 3: 適切なドライバと依存関係をインストールする
次の 2 行のコードをコピーして、ノートブックの最初のコードセルに貼り付けます。Colab 環境では、コマンドライン実行の前に感嘆符が付加されます。
!git clone https://github.com/jasonmayes/headless-chrome-nvidia-t4-gpu-support.git !cd headless-chrome-nvidia-t4-gpu-support && chmod +x scriptyMcScriptFace.sh && ./scriptyMcScriptFace.sh- GitHub でスクリプトを検査して、このスクリプトが実行する未加工のコマンドライン コードを確認できます。
# Update, install correct drivers, and remove the old ones. apt-get install -y vulkan-tools libnvidia-gl-525 # Verify NVIDIA drivers can see the T4 GPU and that vulkan is working correctly. nvidia-smi vulkaninfo --summary # Now install latest version of Node.js npm install -g n n lts node --version npm --version # Next install Chrome stable curl -fsSL https://dl.google.com/linux/linux_signing_key.pub | sudo gpg --dearmor -o /usr/share/keyrings/googlechrom-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrom-keyring.gpg] http://dl.google.com/linux/chrome/deb/ stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list sudo apt update sudo apt install -y google-chrome-stable # Start dbus to avoid warnings by Chrome later. export DBUS_SESSION_BUS_ADDRESS="unix:path=/var/run/dbus/system_bus_socket" /etc/init.d/dbus startセルの横にある をクリックしてコードを実行します。
図 4. コードの実行が完了したら、
nvidia-smiが次のスクリーンショットに類似した内容を出力していることを確認して、GPU が実際に接続され、サーバーで認識されていることを確認します。この出力を表示するには、ログの前の部分までスクロールする必要がある場合があります。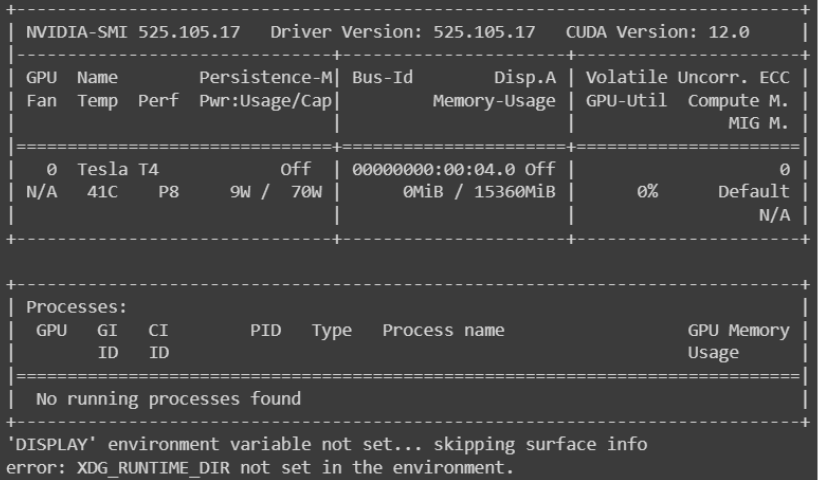
図 5: 「NVIDIA-SMI」で始まる出力を確認します。
ステップ 4: ヘッドレス Chrome を使用して自動化する
- [コード] ボタンをクリックして、新しいコードセルを追加します。
- 次に、カスタムコードを記述して、目的のパラメータを使用して Node.js プロジェクトを呼び出します(または、コマンドラインから
google-chrome-stableを直接呼び出します)。以下に、両方の例を示します。
パート A: コマンドラインでヘッドレス Chrome を直接使用する
# Directly call Chrome to dump a PDF of WebGPU testing page
# and store it in /content/gpu.pdf
!google-chrome-stable \
--no-sandbox \
--headless=new \
--use-angle=vulkan \
--enable-features=Vulkan \
--disable-vulkan-surface \
--enable-unsafe-webgpu \
--print-to-pdf=/content/gpu.pdf https://webgpureport.org
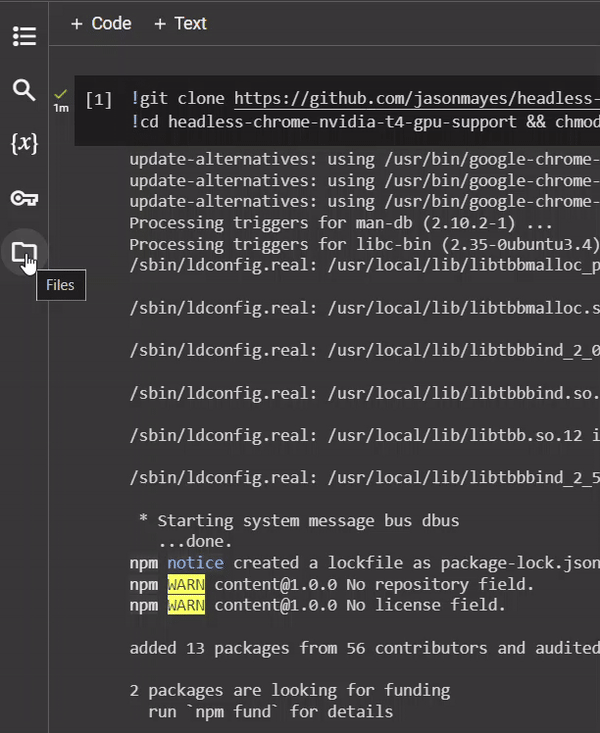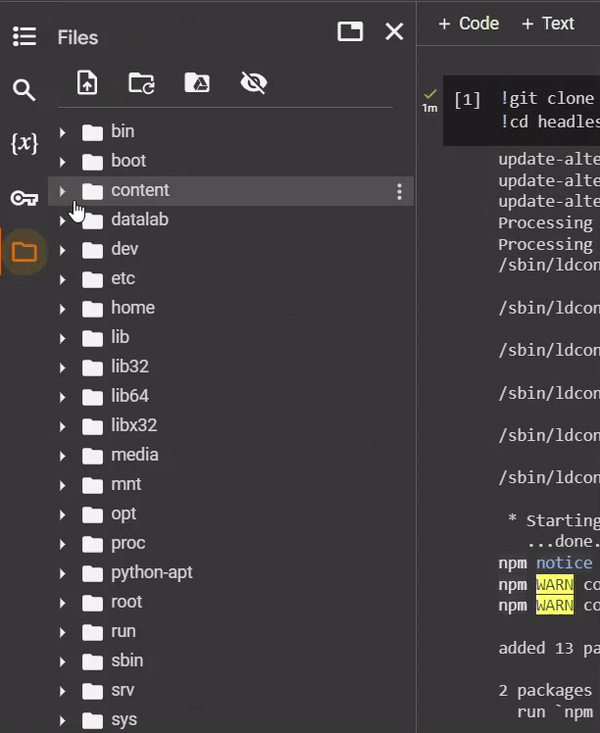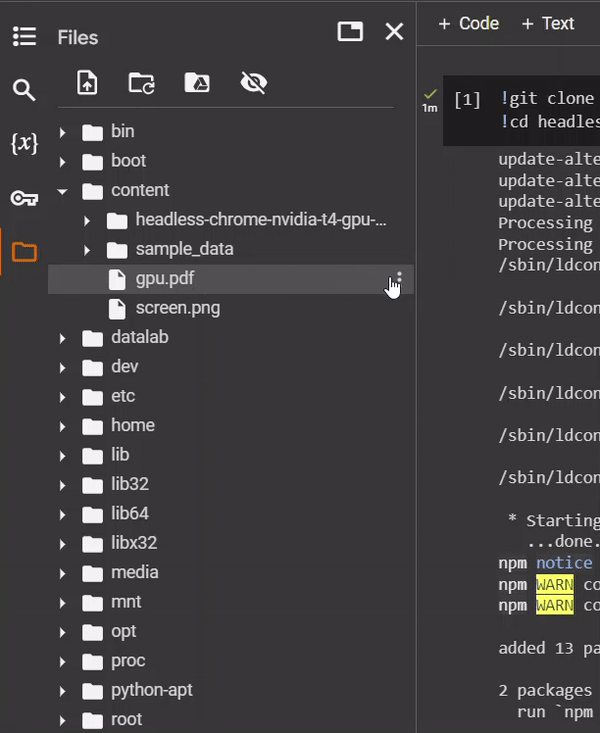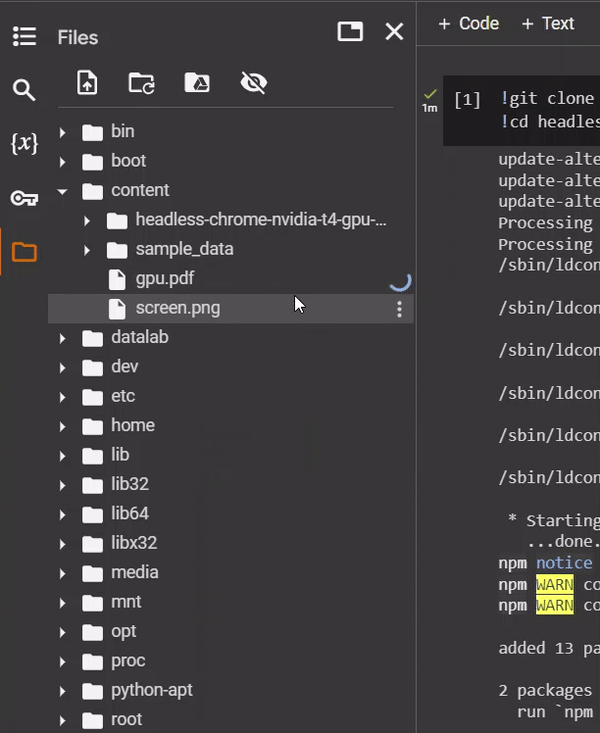
この例では、生成された PDF キャプチャを /content/gpu.pdf に保存しました。このファイルを表示するには、コンテンツ を開きます。次に、 をクリックして PDF ファイルをローカルマシンにダウンロードします。
パート B: Puppeteer で Chrome を操作する
Puppeteer を使用してヘッドレス Chrome を制御する最小限の例を用意しました。次のように実行できます。
# Call example node.js project to perform any task you want by passing
# a URL as a parameter
!node headless-chrome-nvidia-t4-gpu-support/examples/puppeteer/jPuppet.js chrome://gpu
jPuppet の例では、Node.js スクリプトを呼び出してスクリーンショットを作成できます。では、これはどんな仕組みですか?jPuppet.js の Node.js コードのチュートリアルをご覧ください。
jPuppet.js ノードのコードの内訳
まず、Puppeteer をインポートします。これにより、Node.js を使用して Chrome をリモートで制御できます。
import puppeteer from 'puppeteer';
次に、Node アプリケーションに渡されたコマンドライン引数を確認します。3 つ目の引数(移動先の URL を表す)が設定されていることを確認します。最初の 2 つの引数は Node 自体と実行中のスクリプトを呼び出すため、ここでは 3 番目の引数を調べる必要があります。3 番目の要素には、Node プログラムに渡された最初のパラメータが実際に含まれています。
const url = process.argv[2];
if (!url) {
throw "Please provide a URL as the first argument";
}
次に、runWebpage() という名前の非同期関数を定義します。これにより、WebGPU と WebGL のサポートを有効にするで説明されているように、WebGL と WebGPU を機能させるために必要な方法で Chrome バイナリを実行するコマンドライン引数で構成されたブラウザ オブジェクトが作成されます。
async function runWebpage() {
const browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--headless=new',
'--use-angle=vulkan',
'--enable-features=Vulkan',
'--disable-vulkan-surface',
'--enable-unsafe-webgpu'
]
});
後で任意の URL にアクセスするために使用できる、新しいブラウザ ページ オブジェクトを作成します。
const page = await browser.newPage();
次に、ウェブページが JavaScript を実行するときに console.log イベントをリッスンするイベント リスナーを追加します。これにより、Node コマンドライン上でメッセージをログに記録し、スクリーンショットをトリガーして Node でブラウザ プロセスを終了する特別なフレーズ(この場合は captureAndEnd)をコンソール テキストで検査できます。これは、スクリーンショットを撮影する前に一定の作業を行う必要があり、実行時間が不確定なウェブページに役立ちます。
page.on('console', async function(msg) {
console.log(msg.text());
if (msg.text() === 'captureAndEnd') {
await page.screenshot({ path: '/content/screenshotEnd.png' });
await browser.close();
}
});
最後に、指定した URL にアクセスするようページに指示し、ページが読み込まれたら最初のスクリーンショットを取得します。
chrome://gpu のスクリーンショットを取得する場合は、このページは独自のコードによって制御されていないため、コンソール出力を待たずにブラウザ セッションをすぐに閉じることができます。
await page.goto(url, { waitUntil: 'networkidle2' });
await page.screenshot({path: '/content/screenshot.png'});
if (url === 'chrome://gpu') {
await browser.close();
}
}
runWebpage();
package.json を変更する
jPuppet.js ファイルの先頭で import ステートメントを使用していることに気づいたかもしれません。package.json で型値を module に設定する必要があります。設定しないと、モジュールが無効であるというエラーが発生します。
{
"dependencies": {
"puppeteer": "*"
},
"name": "content",
"version": "1.0.0",
"main": "jPuppet.js",
"devDependencies": {},
"keywords": [],
"type": "module",
"description": "Node.js Puppeteer application to interface with headless Chrome with GPU support to capture screenshots and get console output from target webpage"
}
これで設定は終了です。Puppeteer を使用すると、プログラムで Chrome とインターフェースを簡単に設定できます。
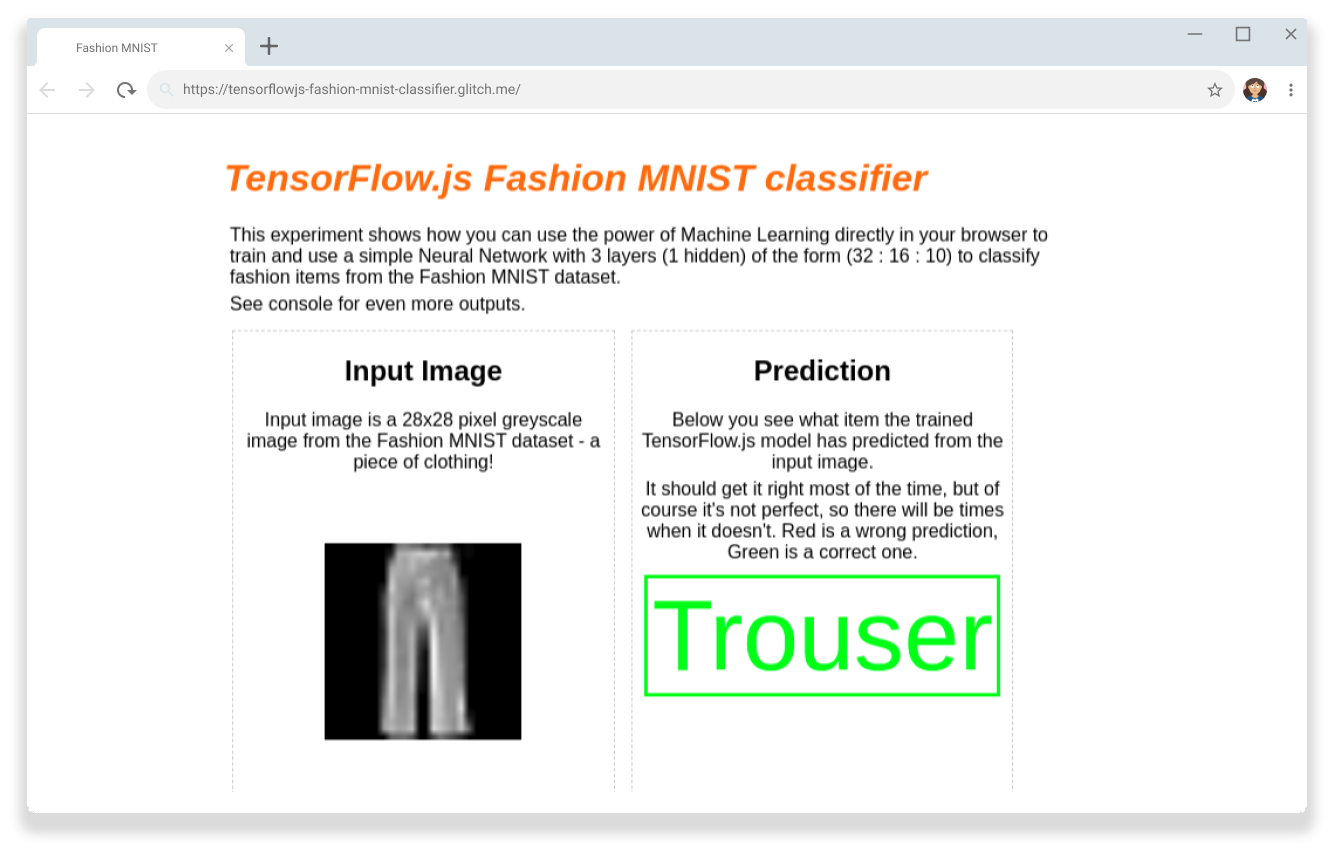
成功
これで、TensorFlow.js Fashion MNIST 分類器が、GPU を使用してブラウザでクライアントサイド処理を行い、画像内のズボンを正しく認識できることを確認できます。
これは、機械学習モデルからグラフィックやゲームのテストまで、クライアントサイドの GPU ベースのワークロードに使用できます。
リソース
GitHub リポジトリにスターを付けると、今後の最新情報を受け取ることができます。