
Suchmaschinen können Seiten in ihren Suchergebnissen nur anzeigen, wenn diese Seiten die Indexierung durch Suchmaschinen-Crawler explizit blockieren. Einige HTTP-Header und Meta-Tags -Tags weisen Crawler darauf hin, dass eine Seite nicht indexiert werden sollte.
Blockieren Sie nur die Indexierung für Inhalte, die nicht in den Suchergebnissen angezeigt werden sollen.
So schlägt die Lighthouse-Indexierungsprüfung fehl
Lighthouse-Flags-Seiten die Suchmaschinen nicht indexieren können:
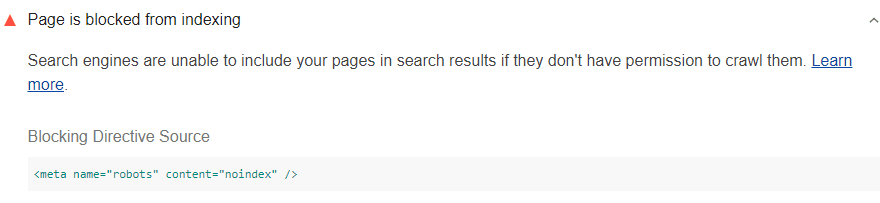
Lighthouse prüft nur auf Überschriften oder Elemente, die alle Suchmaschinen blockieren
Crawlern. Beispielsweise verhindert das unten stehende <meta>-Element, dass alle Suchmaschinen
Crawler (auch als Robots bezeichnet) daran gehindert, auf Ihre Seite zuzugreifen:
<meta name="robots" content=>"noindex"/
Dieser HTTP-Antwortheader blockiert außerdem alle Crawler:
X-Robots-Tag: noindex
Möglicherweise werden auch <meta>-Elemente verwendet, die bestimmte Crawler blockieren, z. B.:
<meta name="Googlebot" content=>"noindex"/
Lighthouse schlägt die Prüfung auf Crawler-spezifische Anweisungen wie diese zwar nicht, Ihre Seite ist trotzdem schwerer zu finden. Seien Sie daher vorsichtig, wenn Sie sie verwenden. Lighthouse gibt Warnung, wenn eine Crawler-spezifische Anweisung einen allgemeinen Indexierungsbot blockiert.
Sicherstellen, dass Suchmaschinen Ihre Seite crawlen können
Prüfen Sie zuerst, ob die Seite von Suchmaschinen indexiert werden soll. Einige Seiten, wie Sitemaps oder legale Inhalte, sollten im Allgemeinen nicht indexiert werden. (Denken Sie daran, dass das Blockieren die Indexierung hindert Nutzer nicht am Zugriff auf eine Seite, wenn sie deren URL kennen.)
Entfernen Sie bei Seiten, die indexiert werden sollen, alle HTTP-Header oder <meta>-Elemente
die Suchmaschinen-Crawler blockieren. Je nachdem, wie Sie Ihre Website eingerichtet haben,
müssen Sie möglicherweise einige oder alle der folgenden Schritte ausführen:
- Entfernen Sie den HTTP-Antwortheader
X-Robots-Tag, wenn Sie eine HTTP-Verbindung einrichten Antwortheader:
X-Robots-Tag: noindex
- Entfernen Sie das folgende Meta-Tag, wenn es im Header der Seite vorhanden ist:
<meta name="robots" content>="noindex"
- Vermeiden Sie Meta-Tags, die bestimmte Crawler blockieren, wenn diese Tags im Kopfzeile der Seite hinzu. Beispiel:
<meta name="Googlebot" content>="noindex"
Zusätzliche Einstellung hinzufügen (optional)
Möglicherweise möchten Sie mehr Kontrolle darüber haben, wie Suchmaschinen Ihre Seite indexieren. Beispiel: Vielleicht möchten Sie nicht, dass Google Bilder indexiert, der Rest der Seite indexiert.
Informationen zum Konfigurieren der <meta>-Elemente und von HTTP
Kopfzeilen für bestimmte Suchmaschinen finden Sie in diesen Leitfäden: