
只有在這些網頁符合以下條件時,搜尋引擎才能在搜尋結果中顯示網頁 明確禁止搜尋引擎檢索器建立索引。部分 HTTP 標頭和中繼 標記會告訴檢索器不要為網頁建立索引。
建議您只針對不想顯示在搜尋結果中的內容封鎖索引作業。
Lighthouse 索引稽核失敗方式
Lighthouse 標記頁面 搜尋引擎無法建立索引的內容:
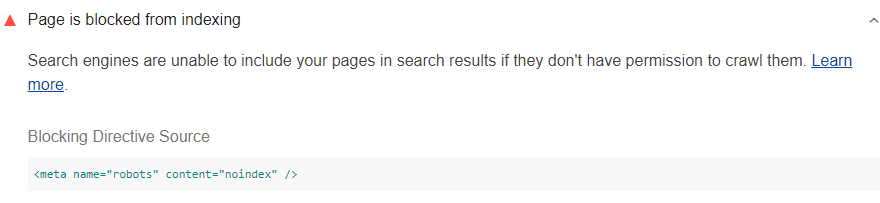
Lighthouse 只會檢查封鎖「所有」搜尋引擎的標題或元素
檢索器。舉例來說,下方的 <meta> 元素可禁止所有搜尋引擎
檢索器 (又稱為漫遊器) 無法存取您的網頁:
<meta name="robots" content="noindex"/>
這個 HTTP 回應標頭也會封鎖所有檢索器:
X-Robots-Tag: noindex
可能也有 <meta> 元素會封鎖特定檢索器,例如:
<meta name="Googlebot" content="noindex"/>
Lighthouse 雖未通過類似檢索器專屬指令的稽核,但可以 仍會使網頁更難搜尋,因此使用時請謹慎小心。Lighthouse 會發出 。
如何確保搜尋引擎能夠檢索您的網頁
首先,請確認你想讓搜尋引擎將網頁編入索引。部分網頁,例如 Sitemap 或合法內容,通常不應建立索引。(提醒您,封鎖 如果使用者知道網頁的網址,索引功能就不會禁止他們存取網頁)。
如果要為網頁建立索引,請移除所有 HTTP 標頭或 <meta> 元素
封鎖搜尋引擎檢索器。根據您網站的設定方式
您可能需要執行下列部分或所有步驟:
- 如果您設定了 HTTP,請移除
X-Robots-TagHTTP 回應標頭 回應標頭:
X-Robots-Tag: noindex
- 移除下列中繼標記 (如果在網頁標頭中):
<meta name="robots" content="noindex">
- 避免使用會封鎖特定檢索器的中繼標記,這些標記出現在 做為參考依據例如:
<meta name="Googlebot" content="noindex">
新增其他控制項 (選用)
您可能想要進一步控制搜尋引擎將網頁編入索引的方式,例如: 您可能不想讓 Google 為圖片建立索引,但又希望網頁的其他部分 已編入索引。
瞭解如何設定 <meta> 元素和 HTTP
瞭解特定搜尋引擎的標頭,請參閱下列指南:
資源
- 「網頁無法建立索引」原始碼
- Google 的漫遊器中繼標記和 X-Robots-Tag HTTP 標頭規範
- Bing 的漫遊器中繼標記
- Yandex 的使用 HTML 元素