
검색엔진은 표시되지 않을 경우에만 검색결과에 해당 페이지를 표시할 수 있습니다. 검색엔진 크롤러에 의한 색인 생성을 명시적으로 차단합니다. 일부 HTTP 헤더 및 메타 태그는 페이지의 색인이 생성되어서는 안 된다는 것을 크롤러에 알립니다.
검색결과에 표시하고 싶지 않은 콘텐츠의 색인 생성만 차단하세요.
Lighthouse 색인 생성 감사가 실패하는 경우
Lighthouse 플래그 페이지 색인을 생성할 수 없는 항목:
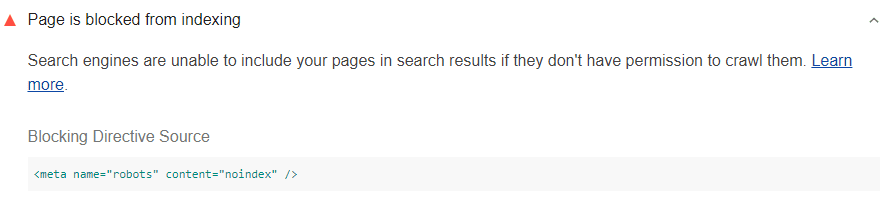
Lighthouse는 모든 검색엔진을 차단하는 헤더나 요소만 확인합니다.
있습니다. 예를 들어 아래의 <meta> 요소는 모든 검색엔진을 차단합니다.
크롤러 (로봇이라고도 함)가 페이지에 액세스하는 것을 차단할 수 있습니다.
<meta name="robots" content="noindex"/>
이 HTTP 응답 헤더는 모든 크롤러를 차단합니다.
X-Robots-Tag: noindex
다음과 같이 특정 크롤러를 차단하는 <meta> 요소가 있을 수도 있습니다.
<meta name="Googlebot" content="noindex"/>
Lighthouse는 이와 같은 크롤러 관련 지시어에 대한 감사를 통과하지 못하지는 않지만 이렇게 하면 페이지를 찾기가 더 어려워지므로 주의해서 사용하세요. Lighthouse는 크롤러 관련 지시어가 일반적인 색인 생성 봇을 차단하는 경우 경고가 표시됩니다.
검색엔진이 페이지를 크롤링할 수 있도록 하는 방법
먼저 검색엔진이 페이지의 색인을 생성하도록 할 것인지 확인합니다. 일부 페이지(예: 사이트맵 일반적으로 색인이 생성되지 않는 것이 일반적입니다. (차단이 색인 생성은 사용자가 URL을 알고 있어도 페이지에 액세스하는 것을 차단하지 않습니다.)
색인을 생성하려는 페이지의 경우 HTTP 헤더 또는 <meta> 요소를 삭제하세요.
포함되어 있습니다. 사이트를 설정하는 방법에 따라
아래 단계 중 일부 또는 전체를 수행해야 할 수 있습니다.
- HTTP를 설정하는 경우
X-Robots-TagHTTP 응답 헤더 삭제 응답 헤더:
X-Robots-Tag: noindex
- 페이지 헤드에 다음 메타 태그가 있으면 삭제하세요.
<meta name="robots" content="noindex">
- 이러한 태그가 페이지 헤드입니다. 예를 들면 다음과 같습니다.
<meta name="Googlebot" content="noindex">
추가 컨트롤 추가 (선택사항)
검색엔진에서 페이지의 색인을 생성하는 방식을 더 세밀하게 제어하기를 원할 수도 있습니다. 예를 들어 Google에서 이미지의 색인을 생성하는 것은 원하지 않지만 페이지의 나머지 부분은 색인이 생성됩니다.
<meta> 요소 및 HTTP 구성 방법에 대한 자세한 내용
다음 가이드를 참조하세요.
리소스
- 페이지의 색인 생성이 차단됨 감사의 소스 코드
- Google의 로봇 메타 태그 및 X-robots-Tag HTTP 헤더 사양
- Bing의 로봇 메타태그
- Yandex의 HTML 요소 사용