

我是 Chromium 媒体播放工程主管 Dale Curtis。我所在的团队负责视频播放的面向 Web 的 API(例如 MSE 和 WebCodecs),以及与解复 mux、解码和渲染音频和视频相关的平台专用内部机制。
在本文中,我将向您介绍 Chromium 的视频渲染架构。 虽然可扩展性的一些细节可能仅适用于 Chromium,但本文中讨论的大多数概念和设计都适用于其他渲染引擎,甚至适用于原生播放应用。
多年来,Chromium 的播放架构发生了显著变化。虽然我们一开始并未采用本系列第一篇文章中所述的成功金字塔理念,但最终还是遵循了类似的步骤:可靠性、性能,然后是可扩展性。
在开始时,视频渲染非常简单,只需一个 for 循环即可选择要将哪些软件解码的视频帧发送给合成器。多年来,这种方法一直非常可靠,但随着 Web 的复杂性增加,对更高性能和效率的需求促成了架构变革。许多改进都需要使用特定于操作系统的原语;因此,我们的架构也必须变得更加可扩展,才能覆盖 Chromium 的所有平台。

视频渲染可分为两个步骤:选择要传送的内容,以及高效传送这些信息。为方便阅读,我先介绍一下高效传送,然后再深入探讨 Chromium 如何选择要传送的内容。
一些术语和布局
由于本文重点介绍的是渲染,因此我将仅简要介绍该流水线的解复 mux 和解码方面。
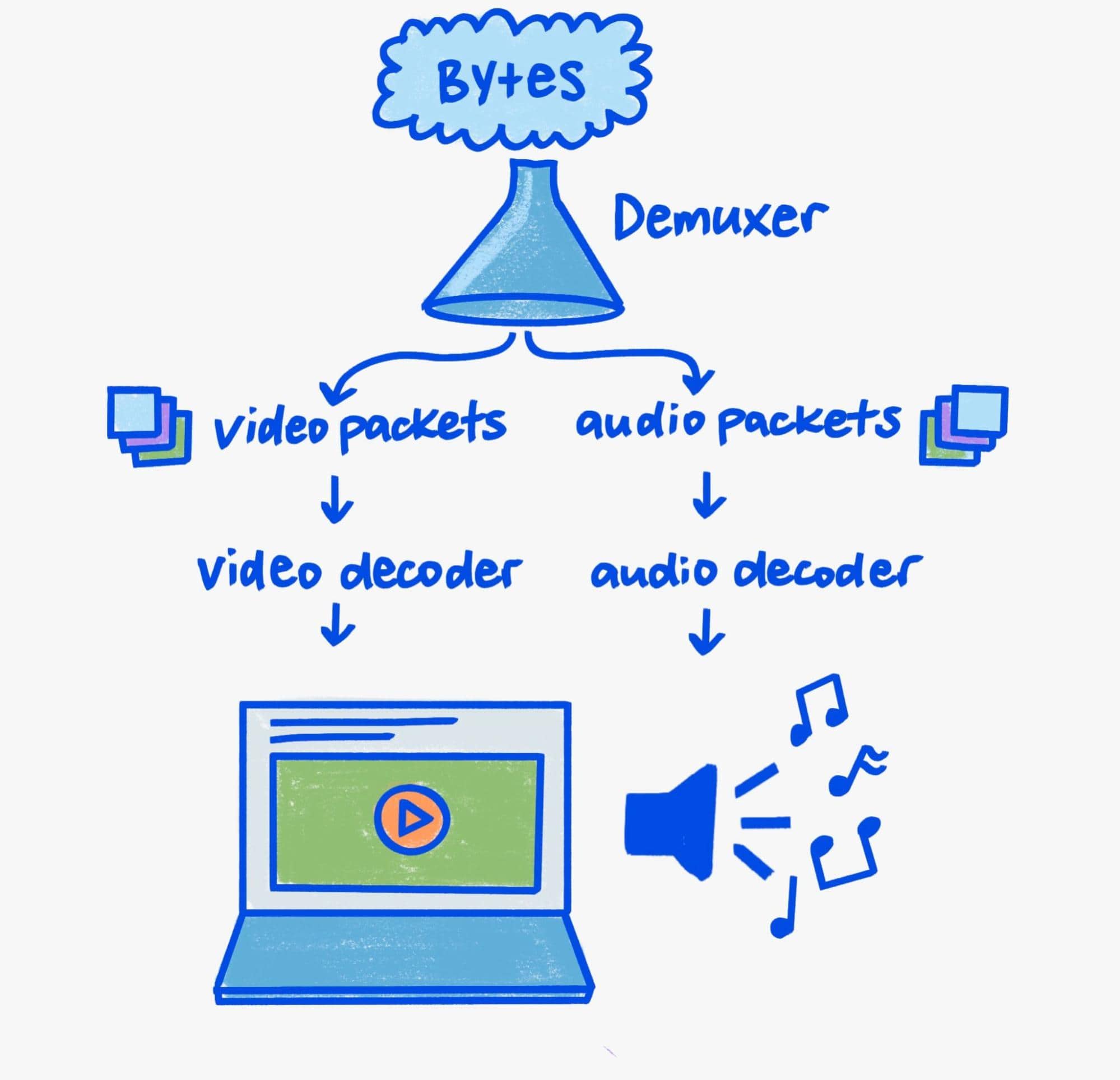
在注重安全的现代社会中,解码和解复用需要多加小心。 二进制解析器是丰富的目标环境,而媒体播放充满了二进制解析。因此,媒体解析器中的安全问题非常常见。
Chromium 采用纵深防御策略,以降低用户遭遇安全问题的风险。实际上,这意味着解复 mux 和软件解码始终在低特权进程中进行,而硬件解码则在仅具有与系统 GPU 通信所需特权的进程中进行。

Chromium 的跨进程通信机制称为 Mojo。虽然本文不会详细介绍 Mojo,但作为进程之间的抽象层,它是 Chromium 可扩展媒体流水线的基石。在我们介绍播放流水线时,请务必注意这一点,因为它有助于了解交互以接收、解复 mux、解码和最终显示媒体的跨进程组件的复杂编排。
这么多位
要了解当今的视频渲染流水线,需要了解视频为何与众不同:带宽。 以 60 帧/秒的帧速率播放 3840x2160 (4K) 分辨率视频需要 9-12 Gbps 的内存带宽。虽然现代系统的峰值带宽可能高达每秒数百千兆比特,但视频播放仍占据了相当大的一部分。如果不加以注意,总带宽可能会因 GPU 和 CPU 内存之间的复制或往返而轻松成倍增加。
任何注重效率的现代视频播放引擎的目标都是尽可能缩短解码器和最终渲染步骤之间的带宽。因此,视频渲染在很大程度上与 Chromium 的主要渲染流水线解耦。具体而言,从主要渲染流水线的角度来看,视频只是一个具有不透明度的固定大小的洞。Chromium 使用一个名为Surface的概念来实现这一点,其中每个视频都直接与 Viz 通信。
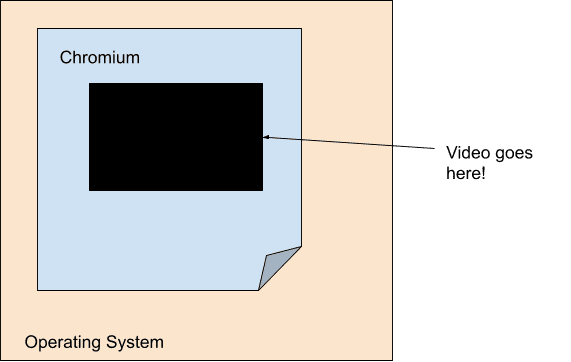
由于移动计算的普及,功率和效率已成为当前一代产品的重要关注点。因此,解码和渲染在硬件级别上的耦合度比以往更加紧密,导致视频看起来就像一个不透明的洞,即使对操作系统本身也是如此!平台级解码器通常只提供不透明缓冲区,Chromium 会以叠加层的形式将其传递给平台级合成系统。
每个平台都有自己的叠加层形式,其平台解码 API 会与之协同工作。Windows 具有直接合成和 Media Foundation 转换,macOS 具有 CoreAnimation 层和 VideoToolbox,Android 具有 SurfaceView 和 MediaCodec,Linux 具有 VASurfaces 和 VA-API。Chromium 对这些概念的抽象分别由 OverlayProcessor 和 mojo::VideoDecoder 接口处理。
在某些情况下,这些缓冲区可以映射到系统内存,因此它们甚至不需要不透明,并且在被访问之前不会占用任何带宽 - Chromium 将这些缓冲区称为 GpuMemoryBuffers。在 Windows 上,这些缓冲区由 DXGI 缓冲区提供支持;在 macOS 上,由 IOSurfaces 提供支持;在 Android 上,由 AHardwareBuffers 提供支持;在 Linux 上,由 DMA 缓冲区提供支持。虽然视频播放通常不需要此访问权限,但这些缓冲区对于视频捕获至关重要,可确保捕获设备与最终编码器之间的带宽最小。
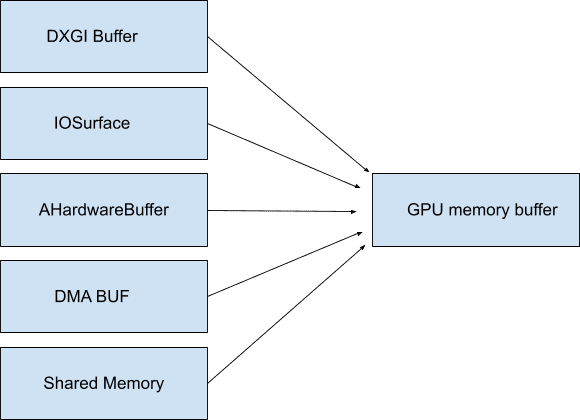
由于 GPU 通常负责解码和显示,因此使用这些(通常也是不透明的)缓冲区可确保高带宽视频数据从未真正离开 GPU。正如我们之前所讨论的,将数据保留在 GPU 上对于提高效率至关重要,尤其是在高分辨率和高帧速率下。
我们越能充分利用叠加层和 GPU 缓冲区等操作系统基元,就越少需要花费带宽来不必要地重新排列视频字节。将从解码到渲染的所有内容都放在一个位置,可以显著提高功耗效率。 例如,当 Chromium 在 macOS 上启用叠加层后,全屏视频播放期间的电源消耗量减半!在 Windows、Android 和 ChromeOS 等其他平台上,即使在非全屏模式下,我们也可以使用叠加层,几乎在所有情况下都能节省高达 50% 的资源。
渲染
现在,我们已经介绍了最佳传送机制,接下来可以讨论 Chromium 如何选择要传送的内容。Chromium 的播放堆栈使用基于“拉取”的架构,这意味着堆栈中的每个组件都会按层次顺序向其下方的组件请求输入。堆栈顶部是音频和视频帧的渲染,其次是解码,然后是解复 mux,最后是 I/O。每个渲染的音频帧都会推进时钟,该时钟与呈现间隔时间结合使用,用于选择要渲染的视频帧。
在每次呈现间隔(显示屏的每次刷新)时,系统都会通过附加到前面提到的 SurfaceLayer 的 CompositorFrameSink 请求视频渲染程序提供视频帧。对于帧速率低于显示速率的内容,这意味着重复显示同一帧;如果帧速率高于显示速率,则某些帧永远不会显示。
要想以令人愉悦的方式同步音频和视频,还有很多方面需要注意。 如需详细了解如何在 Chromium 中实现最佳视频流畅度,请参阅 Project Butter。该文档介绍了如何将视频渲染拆分为理想序列,以表示应显示每个帧的次数。例如:“每隔一个显示间隔显示 1 帧 ([1],60 Hz 时为 60 fps)”“每隔 2 个间隔显示 1 帧 ([2],60 Hz 时为 30 fps)”,或更复杂的模式,例如 [2:3:2:3:2](60 Hz 时为 25 fps),涵盖多个不同的帧和显示间隔。视频渲染程序越接近此理想模式,用户就越有可能认为播放流畅。
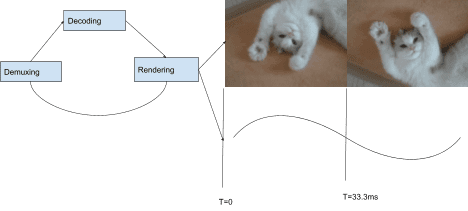
虽然大多数 Chromium 平台都是逐帧渲染,但并非全部如此。我们的可扩展架构还支持批量渲染。批量渲染是一种高效技术,它会提前告知操作系统级合成器多个帧,并处理在应用提供的时间表上发布这些帧。
未来已来?
我们专注于研究 Chromium 如何利用操作系统基元提供卓越的播放体验。但对于希望提供超出基本视频播放功能的网站,该怎么办? 我们能否为他们提供 Chromium 自身用于引入新一代 Web 内容的强大基元?
我们认为答案是肯定的! 可扩展性是我们目前在思考 Web 平台时所考虑的核心要素。我们一直在与其他浏览器和开发者合作,共同打造 WebGPU 和 WebCodecs 等新技术,以便 Web 开发者在与操作系统通信时使用与 Chromium 相同的原语。WebGPU 支持 GPU 缓冲区,WebCodecs 则提供了与上述叠加层和 GPU 缓冲区系统兼容的平台解码和编码基元。

数据流结束
感谢您的阅读!希望您能更好地了解现代播放系统,以及 Chromium 如何助力用户每天观看数亿小时的视频。 如果您想进一步了解编解码器和现代网络视频,建议您阅读 Sid Bala 撰写的 H.264 is magic、Erica Beaves 撰写的 How Modern Video Players Work 以及 Cyril Concolato 撰写的 Packaging award-winning shows with award-winning technology。
一张插图(漂亮的那张!)由 Una Kravets 创作。