


Nazywam się Ian Kilpatrick i razem z Koji Ishii kieruję zespołem inżynierów odpowiedzialnym za układy w Blink. Zanim dołączyłam do zespołu Blink, byłam inżynierem front-endu (przed pojawieniem się w Google stanowiska „inżynier front-endu”) i tworzyłam funkcje w Dokumentach Google, Dysku i Gmailu. Po około 5 latach pracy w tym dziale zdecydowałem się na ryzykowny krok i dołączyłem do zespołu Blink. W ramach tej pracy nauczyłem się C++, a także zacząłem się przyzwyczajać do bardzo złożonej bazy kodu Blink. Nawet dzisiaj rozumiem tylko niewielką część. Dziękuję za poświęcony czas. Pocieszył mnie fakt, że wielu „byłych front-endowych inżynierów” przedo mnie przeszło na stanowisko „inżynierów zajmujących się przeglądarkami”.
Moje wcześniejsze doświadczenia w zespole Blink pomogły mi osobiście. Jako inżynier front-endowy często natrafiałem na niespójności w przeglądarce, problemy z wydajnością, błędy renderowania i brakujące funkcje. Dzięki LayoutNG udało mi się systematycznie rozwiązywać te problemy w systemie układu Blink. Jest to suma wysiłków wielu inżynierów na przestrzeni lat.
W tym poście wyjaśnię, jak duża zmiana architektury może ograniczać występowanie różnych typów błędów i problemów z wydajnością.
Architektura silnika układu na 9000 stóp
Wcześniej drzewo układu w Blink było tym, co nazywam „drzewem zmiennym”.
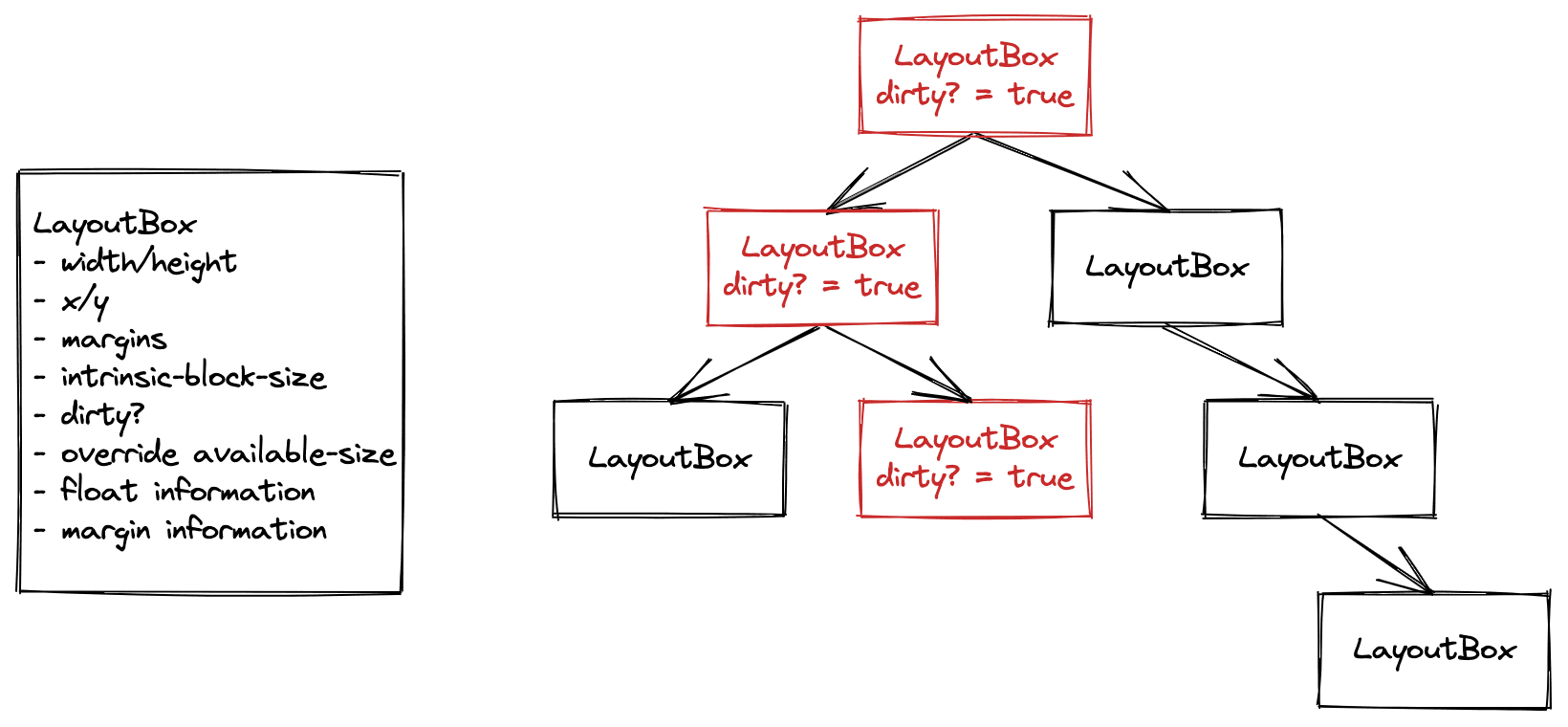
Każdy obiekt w drzewie układu zawierał informacje wejściowe, takie jak dostępny rozmiar narzucony przez element nadrzędny, położenie dowolnych elementów typu float oraz informacje wyjściowe, np. ostateczną szerokość i wysokość obiektu lub jego położenie w kierunku osi X i Y.
Te obiekty były przechowywane między renderowaniami. Gdy nastąpiła zmiana stylu, oznaczyliśmy ten obiekt jako zmieniony, a także wszystkie jego nadrzędne w drzewie. Gdy została uruchomiona faza układu w pipeline renderowania, oczyszczono drzewo, przejrzano wszystkie brudne obiekty, a następnie uruchomiono układ, aby je oczyścić.
Okazało się, że ta architektura spowodowała wiele klas problemów, które opisujemy poniżej. Najpierw jednak zastanów się, jakie są dane wejściowe i wyjściowe układu.
Uruchomienie układu na węźle w tym drzewie polega na koncepcyjnym pobraniu „stylu plus DOM” oraz wszelkich ograniczeń nadrzędnych z systemu układu nadrzędnego (siatka, blok lub flex), a następnie na uruchomieniu algorytmu ograniczenia układu i wygenerowaniu wyniku.
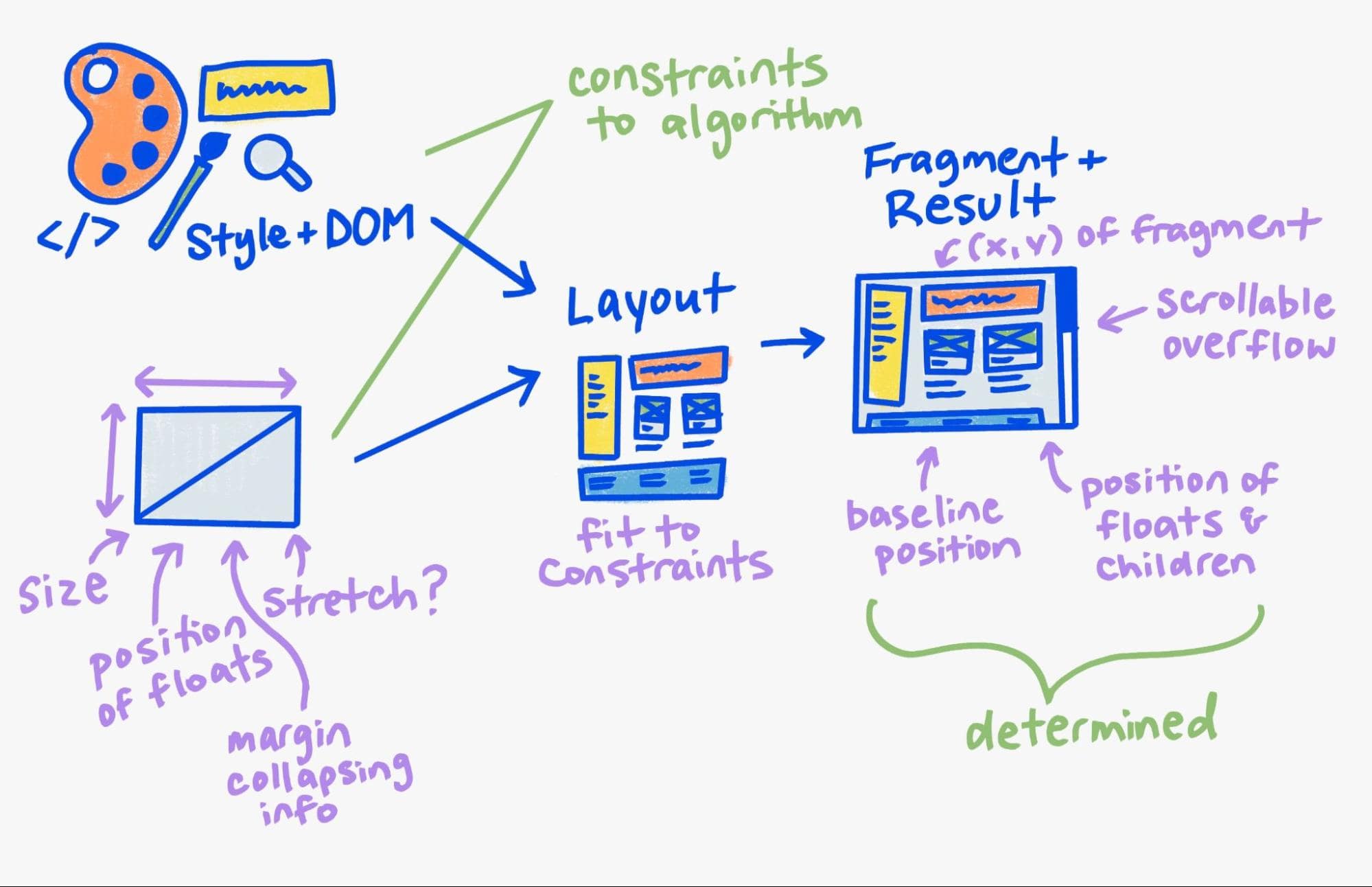
Nasza nowa architektura formalizuje ten model koncepcyjny. Nadal mamy drzewo układu, ale używamy go głównie do przechowywania danych wejściowych i wyjściowych układu. Na potrzeby danych wyjściowych generujemy zupełnie nowy, niezmienny obiekt o nazwie drzewo fragmentów.
W poprzednim artykule omawialiśmy niezmienną strukturę fragmentów i opisywaliśmy, jak została ona zaprojektowana, aby umożliwić ponowne wykorzystanie dużych fragmentów poprzedniej struktury w przypadku układów przyrostowych.
Dodatkowo przechowujemy nadrzędny obiekt ograniczeń, który wygenerował ten fragment. Używamy go jako klucza pamięci podręcznej, o którym opowiemy więcej poniżej.
Algorytm układu wstawionego tekstu został również przepisany, aby pasował do nowej niezmiennej architektury. Oprócz niezmiennej reprezentacji listy płaskiej do tworzenia układu wstawianego, zawiera też buforowanie na poziomie akapitu, aby przyspieszyć ponowne układanie, stosowanie kształtów na poziomie akapitu, aby stosować właściwości czcionek do elementów i słów, nowy algorytm dwukierunkowy Unicode z wykorzystaniem ICU, wiele poprawek związanych z poprawnością i inne.
Typy błędów układu
Błędy układu można ogólnie podzielić na 4 kategorie, z różnymi przyczynami.
Poprawność
Gdy mówimy o błędach w systemie renderowania, mamy na myśli poprawność. Przykładowo: „Przeglądarka A ma zachowanie X, a Przeglądarka B – zachowanie Y” lub „Przeglądarki A i B są uszkodzone”. Wcześniej poświęcaliśmy na to dużo czasu, ponieważ ciągle walczyliśmy z systemem. Typowym błędem było zastosowanie bardzo ukierunkowanej poprawki dotyczącej jednego błędu, ale po kilku tygodniach okazało się, że spowodowaliśmy regresję w innej (pozornie niezwiązanej) części systemu.
Jak pisaliśmy w poprzednich postach, jest to oznaka bardzo niestabilnego systemu. W przypadku układu nie mieliśmy czystego powiązania między klasami, przez co inżynierowie przeglądarek musieli polegać na stanie, na który nie powinni mieć wpływu, lub błędnie interpretować niektóre wartości z innej części systemu.
Na przykład w ciągu ponad roku mieliśmy łańcuch około 10 błędów związanych z flex layoutem. Każda poprawka powodowała problemy z poprawnością lub wydajnością w części systemu, co prowadziło do kolejnych błędów.
Teraz, gdy LayoutNG wyraźnie określa relacje między wszystkimi komponentami systemu układu, możemy wprowadzać zmiany z większym poczuciem pewności. Korzystamy też z wyników projektu Web Platform Tests (WPT), który umożliwia wielu stronom tworzenie wspólnego zestawu testów internetowych.
Obecnie stwierdziliśmy, że jeśli wprowadzimy prawdziwą regresję na stabilnym kanale, zwykle nie ma ona powiązanych testów w repozytorium WPT i nie jest wynikiem niezrozumienia umów dotyczących komponentów. Ponadto zgodnie z naszą polityką dotyczącą poprawek zawsze dodajemy nowy test WPT, aby żadna przeglądarka nie popełniła tego samego błędu.
Unieważnienie
Jeśli kiedykolwiek spotkałeś się z tajemniczym błędem, który znikał po zmianie rozmiaru okna przeglądarki lub przełączeniu właściwości CSS, prawdopodobnie był to problem z niepełnym unieważnianiem. Część drzewa z możliwością zmiany została uznana za czystą, ale z powodu pewnych zmian w ograniczeniach nadrzędnych nie stanowiła prawidłowego wyjścia.
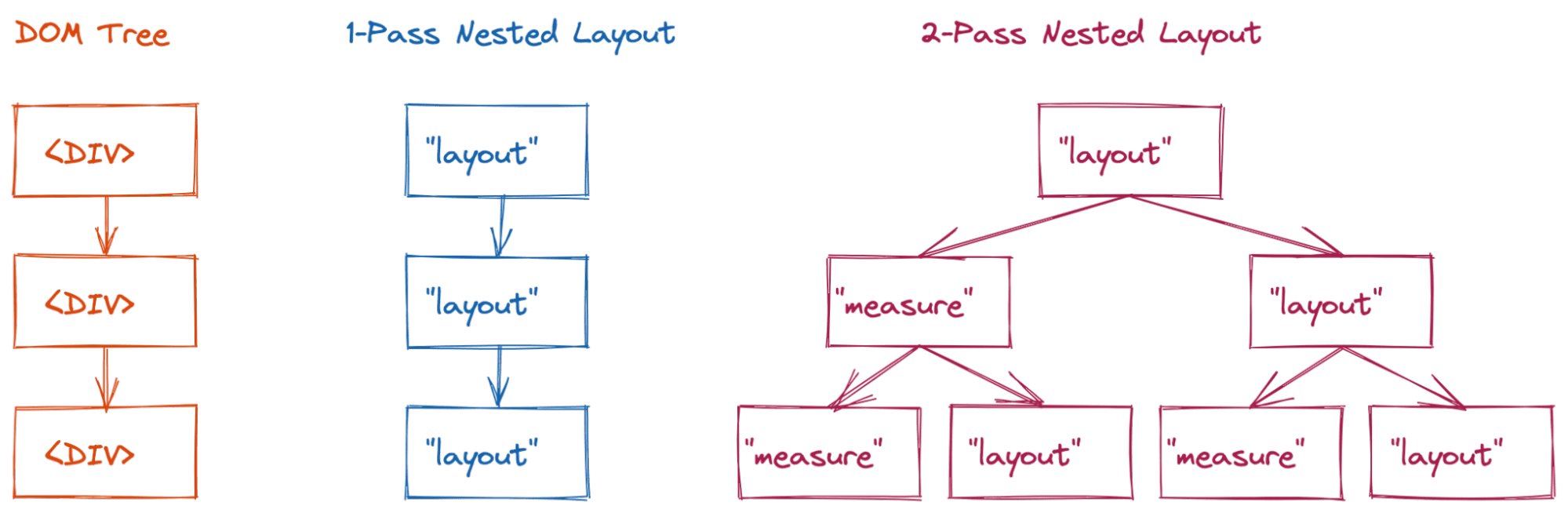
Jest to bardzo częste w przypadku trybów układu z 2 przechodami (przejście po drzewie układu 2 razy w celu określenia ostatecznego stanu układu), opisanych poniżej. Wcześniej nasz kod wyglądał tak:
if (/* some very complicated statement */) {
child->ForceLayout();
}
W przypadku tego typu błędów zwykle należy:
if (/* some very complicated statement */ ||
/* another very complicated statement */) {
child->ForceLayout();
}
Rozwiązanie tego typu problemów zwykle powoduje poważne pogorszenie wydajności (patrz poniżej sekcja „Zbyt duża ilość anulowań”) i było bardzo trudne do naprawienia.
Obecnie (jak opisano powyżej) mamy niezmienny obiekt ograniczeń rodzica, który opisuje wszystkie dane wejściowe od układu rodzica do podrzędnego. Przechowujemy go razem z wynikiem niezmiennego fragmentu. Dlatego mamy centralne miejsce, w którym porównujemy te 2 parametry, aby określić, czy dziecko musi przejść kolejną procedurę układu. Ta logika porównywania jest skomplikowana, ale dobrze zorganizowana. Debugowanie tej klasy problemów z niepełnym unieważnianiem zwykle wymaga ręcznego sprawdzenia obu danych wejściowych i ustalenia, co się w nich zmieniło, że wymagane jest ponowne wykonanie passu układu.
Poprawki w tym kodzie porównywania są zwykle proste i łatwe do testowania jednostkowego ze względu na prostotę tworzenia tych niezależnych obiektów.
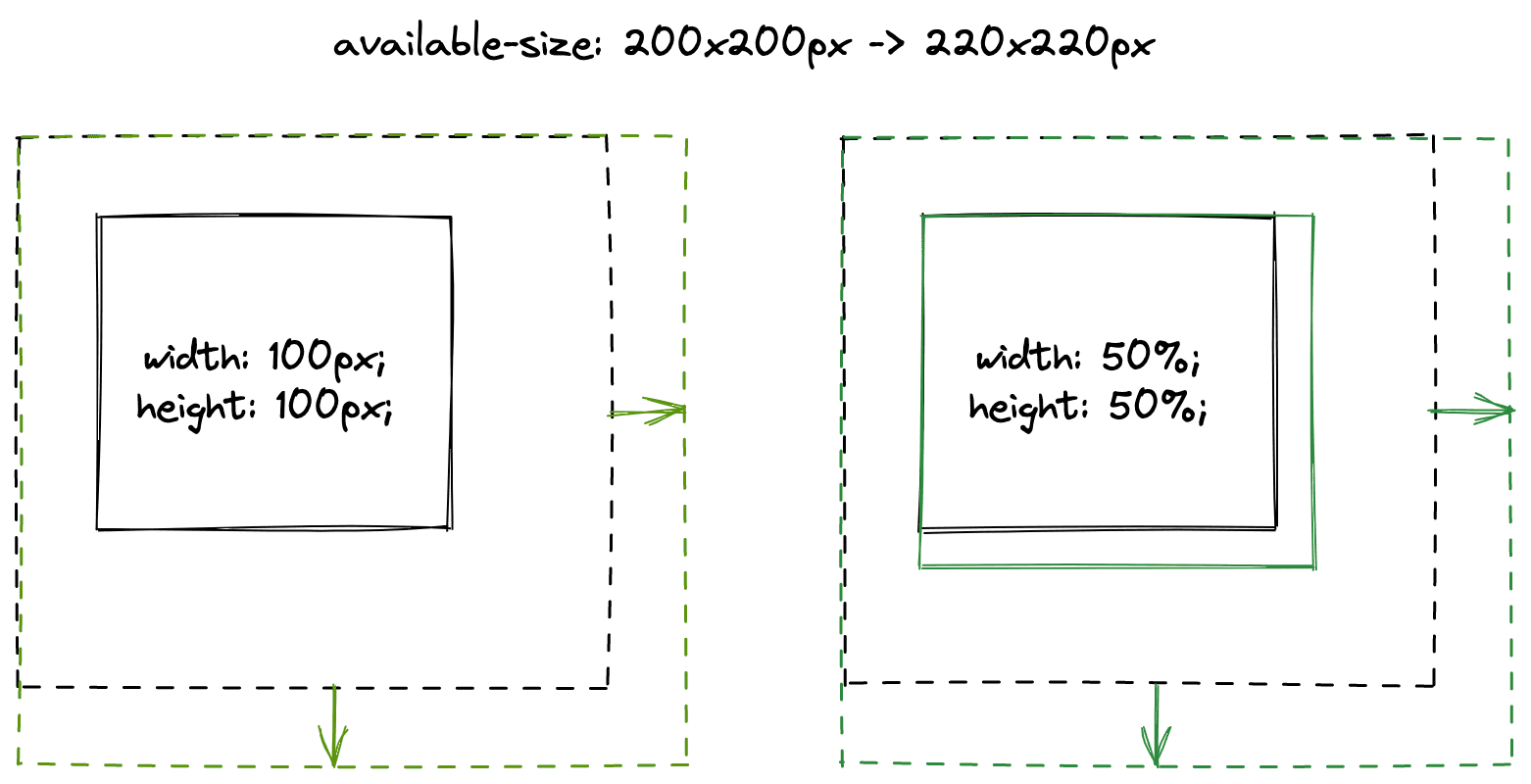
Kod porównywania w przykładzie powyżej:
if (width.IsPercent()) {
if (old_constraints.WidthPercentageSize()
!= new_constraints.WidthPercentageSize())
return kNeedsLayout;
}
if (height.IsPercent()) {
if (old_constraints.HeightPercentageSize()
!= new_constraints.HeightPercentageSize())
return kNeedsLayout;
}
Hysteresis
Ta klasa błędów jest podobna do niepełnego unieważnienia. W poprzednim systemie bardzo trudno było zapewnić idempotentność układu, czyli powtórne uruchomienie układu z tymi samymi danymi wejściowymi dawało ten sam wynik.
W przykładzie poniżej po prostu przełączamy właściwość CSS między 2 wartościami. Spowoduje to jednak „nieskończone” powiększanie prostokąta.
W poprzednim drzewie z możliwością zmiany bardzo łatwo było wprowadzać takie błędy. Jeśli kod popełnił błąd i odczytał rozmiar lub położenie obiektu w niewłaściwym momencie lub na nieodpowiednim etapie (ponieważ nie „wyczyściliśmy” poprzedniego rozmiaru lub położenia), natychmiast dodamy subtelny błąd histerezy. Te błędy zwykle nie pojawiają się podczas testowania, ponieważ większość testów koncentruje się na jednym układzie i renderowaniu. Co więcej, wiedzieliśmy, że pewna histereza jest potrzebna do prawidłowego działania niektórych trybów układu. Wystąpiły błędy, w których przypadku optymalizacja polegała na usunięciu przejścia układu, ale wprowadzała „błąd”, ponieważ tryb układu wymagał 2 przejść, aby uzyskać prawidłowe dane wyjściowe.
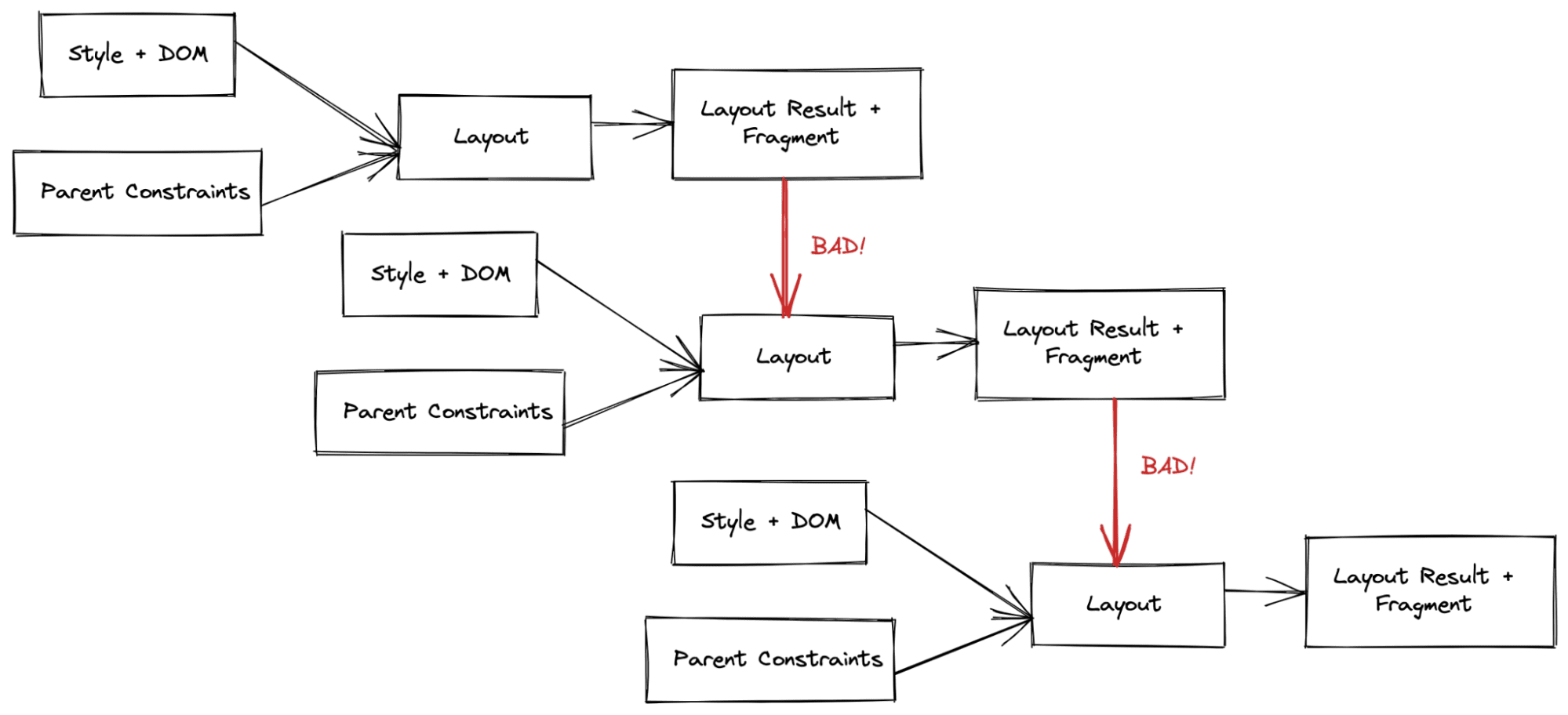
W LayoutNG mamy wyraźne struktury danych wejściowych i wyjściowych, a dostęp do poprzedniego stanu nie jest dozwolony, dzięki czemu udało nam się w dużej mierze wyeliminować z systemu układu tę klasę błędów.
Nadmierne unieważnianie i wydajność
Jest to przeciwieństwo klasy błędów związanych z niepełnym unieważnianiem. Często podczas naprawiania błędu związanego z niepełnym unieważnieniem powodowaliśmy spadek wydajności.
Często musieliśmy podejmować trudne decyzje, wybierając poprawność kosztem wydajności. W następnej sekcji omówimy szczegółowo, jak rozwiązaliśmy te problemy.
Układy z 2 przechodami i spadek skuteczności
Układy flex i siatka to zmiana w wyrazistości układów w internecie. Jednak te algorytmy różniły się zasadniczo od wcześniejszego algorytmu układu bloków.
Blok układu (w prawie wszystkich przypadkach) wymaga od silnika wykonania układu wszystkich jego elementów dokładnie raz. To świetne rozwiązanie pod względem wydajności, ale nie jest tak efektywne, jak chcieliby to programiści.
Często na przykład chcesz, aby rozmiar wszystkich elementów potomnych był taki sam jak rozmiar największego z nich. Aby to umożliwić, układ nadrzędny (flex lub siatka) wykona pomiar, aby określić rozmiar każdego elementu podrzędnego, a następnie wykona pomiar układu, aby rozciągnąć wszystkie elementy podrzędne do tego rozmiaru. To zachowanie jest domyślne zarówno w przypadku układu elastycznego, jak i siatki.

Te układy z 2 przelotami początkowo zapewniały akceptowalną wydajność, ponieważ użytkownicy zwykle nie umieszczali ich głęboko w hierarchii. Jednak wraz z pojawianiem się bardziej złożonych treści zaczęły się pojawiać poważne problemy z wydajnością. Jeśli nie zapiszesz w pamięci podręcznej wyniku fazy pomiaru, drzewo układu będzie się przełączać między stanem pomiaru a ostatecznym stanem układu.
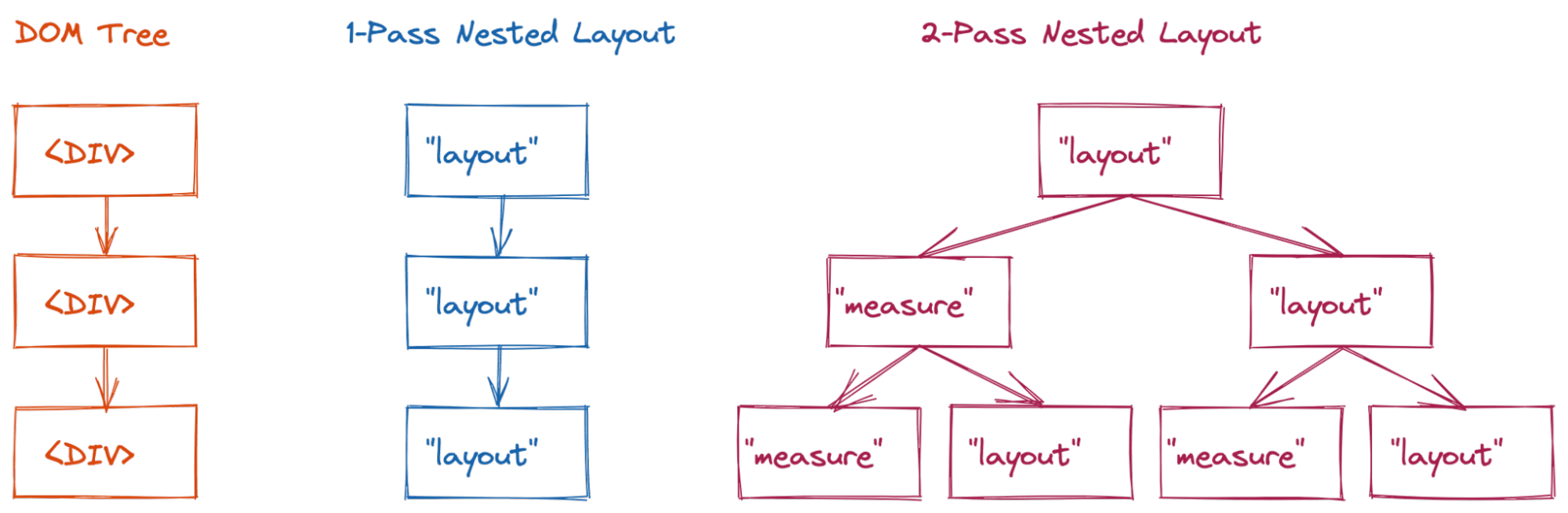
<div>.
Prosty układ z jednym przejściem (np. układ blokowy) odwiedzi 3 węzły układu (złożoność O(n)).
Jednak w przypadku układu z 2 przelotami (np. flex lub siatka) może to potencjalnie skutkować złożonością O(2n) wizyt w tym przykładzie.
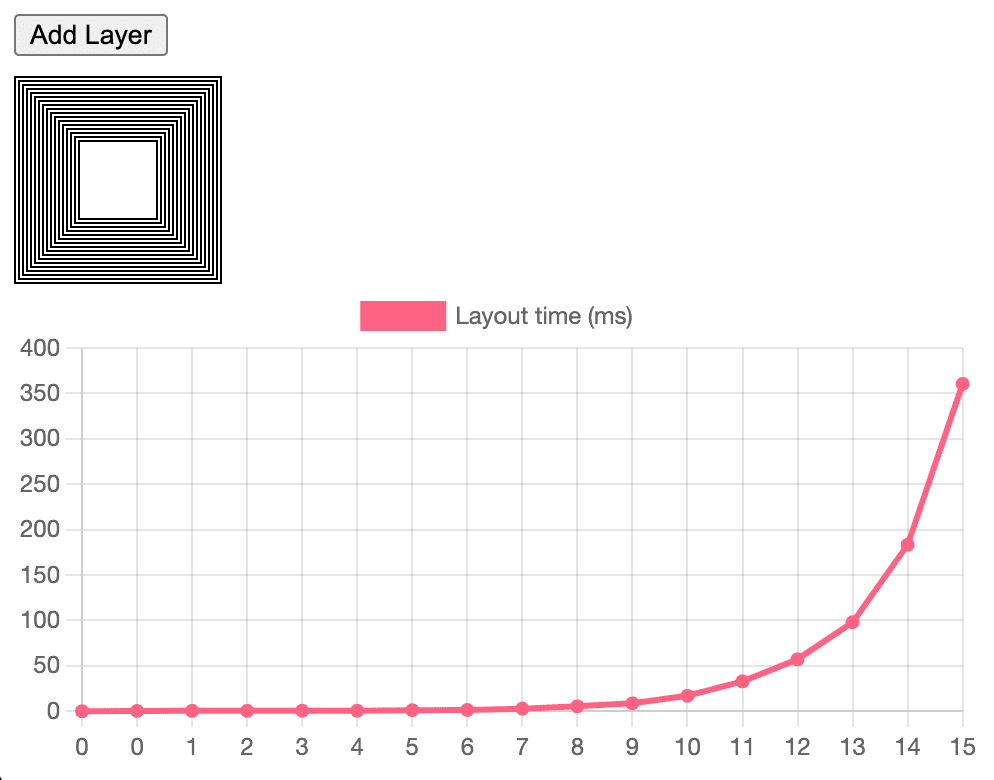
Wcześniej, aby rozwiązać ten problem, próbowaliśmy dodawać do układów elastycznych i siatek bardzo konkretne pamięci podręczne. To zadziałało (i doszliśmy bardzo daleko z Flex), ale ciągle walczyliśmy z błędami nieprawidłowej weryfikacji.
Dzięki LayoutNG możemy tworzyć jawne struktury danych zarówno dla danych wejściowych, jak i wyjściowych układu. Oprócz tego zbudowaliśmy pamięć podręczną pomiarów i przesłań układu. Dzięki temu złożoność wraca do O(n), co daje przewidywalnie liniową wydajność dla programistów stron internetowych. Jeśli układ będzie wymagał 3 przebiegów, po prostu zapiszemy ten przebieg w pamięci podręcznej. Może to w przyszłości umożliwić bezpieczne wprowadzenie bardziej zaawansowanych trybów układu. Jest to przykład tego, jak RenderingNG zasadniczo umożliwia rozszerzalność. W niektórych przypadkach układ siatki może wymagać użycia 3 przebiegów, ale obecnie jest to bardzo rzadkie.
Ustaliliśmy, że gdy deweloperzy napotykają problemy z wydajnością układu, jest to zwykle spowodowane błędem związanym z wykładniczym czasem układania, a nie surową przepustowością etapu układania w pipeline. Jeśli niewielka zmiana (jeden element zmieniający jedną właściwość CSS) powoduje opóźnienie układu o 50–100 ms, prawdopodobnie jest to błąd układu o charakterze wykładniczym.
W skrócie
Układ jest bardzo złożoną kwestią, a my nie omawiamy wszystkich interesujących szczegółów, takich jak optymalizacja układu wstawianego (czyli całego podsystemu tekstowego). Nawet omawiane tu zagadnienia są tylko wierzchołkiem góry lodowej, a wiele szczegółów zostało pominięte. Mamy jednak nadzieję, że udało nam się pokazać, jak systematyczne ulepszanie architektury systemu może prowadzić do niesamowitych długoterminowych zysków.
Wiemy jednak, że przed nami jeszcze dużo pracy. Zdajemy sobie sprawę z istnienia różnych klas problemów (zarówno związanych z wydajnością, jak i z poprawnością), nad których rozwiązaniem pracujemy. Cieszymy się też z nowych funkcji układu, które pojawią się w CSS. Uważamy, że architektura LayoutNG pozwala bezpiecznie i skutecznie rozwiązywać te problemy.
Jedno zdjęcie (wiesz, które!) autorstwa Una Kravets.