


Meu nome é Ian Kilpatrick, líder de engenharia da equipe de layout do Blink, junto com Koji Ishii. Antes de trabalhar na equipe do Blink, eu era engenheiro de front-end (antes que o Google tivesse a função de "engenheiro de front-end"), criando recursos nos Documentos Google, no Drive e no Gmail. Depois de cerca de cinco anos nessa função, fiz uma grande aposta ao mudar para a equipe do Blink, aprendendo C++ no trabalho e tentando acelerar a base de código extremamente complexa do Blink. Até hoje, só entendo uma parte relativamente pequena. Agradeço o tempo que você dedicou a mim durante esse período. Fiquei mais tranquilo ao saber que muitos "engenheiros de front-end em recuperação" fizeram a transição para se tornarem "engenheiros de navegador" antes de mim.
Minha experiência anterior me guiou pessoalmente enquanto estava na equipe do Blink. Como engenheiro de front-end, eu constantemente encontrava inconsistências no navegador, problemas de desempenho, bugs de renderização e recursos ausentes. O LayoutNG foi uma oportunidade para ajudar a corrigir sistematicamente esses problemas no sistema de layout do Blink e representa a soma dos esforços de muitos engenheiros ao longo dos anos.
Neste post, vou explicar como uma grande mudança de arquitetura como essa pode reduzir e mitigar vários tipos de bugs e problemas de desempenho.
Uma visão de 9.144 metros das arquiteturas de mecanismo de layout
Anteriormente, a árvore de layout do Blink era o que eu chamava de "árvore mutável".
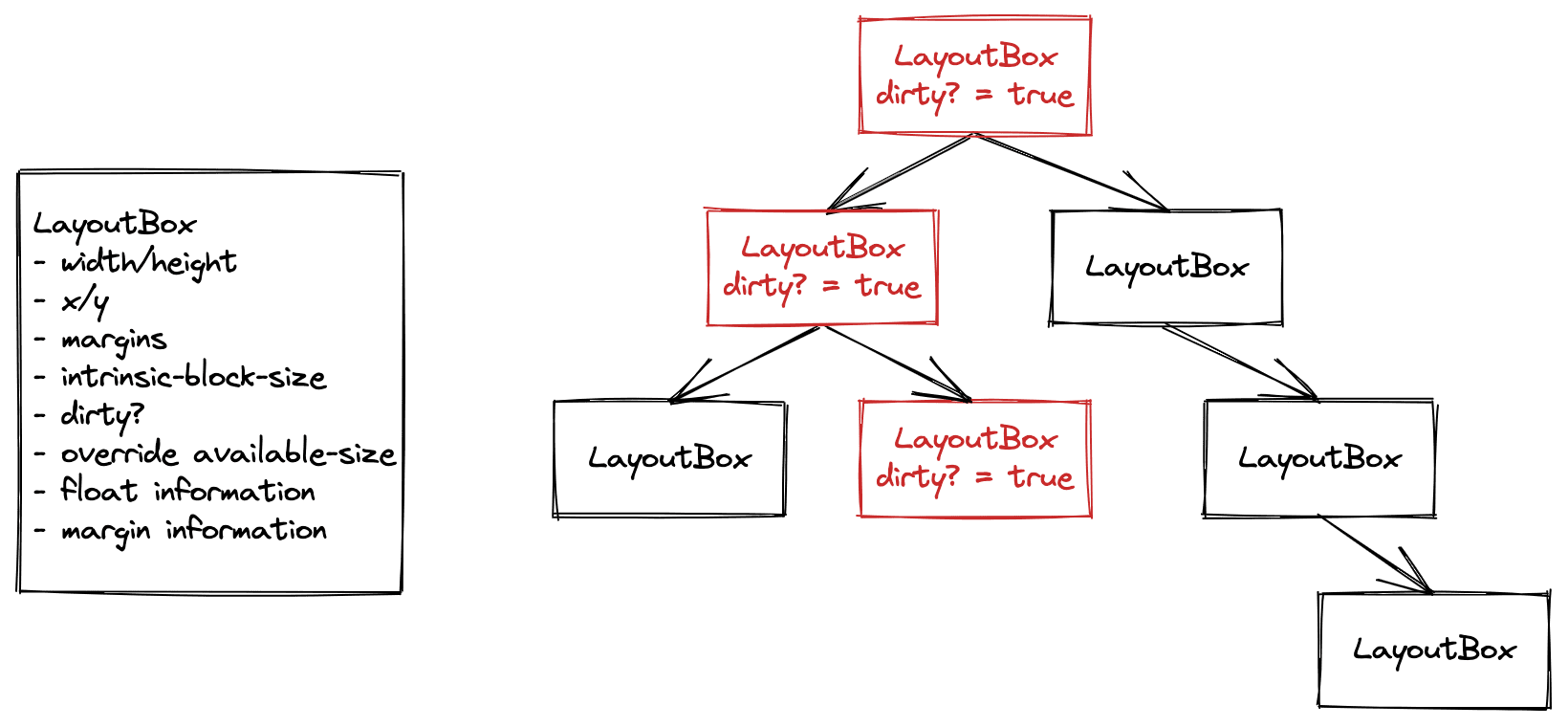
Cada objeto na árvore de layout continha informações de entrada, como o tamanho disponível imposto por um pai, a posição de qualquer flutuação e informações de saída, por exemplo, a largura e altura finais do objeto ou a posição x e y.
Esses objetos foram mantidos entre os renders. Quando uma mudança de estilo ocorreu, marcamos esse objeto como sujo e todos os pais dele na árvore. Quando a fase de layout do pipeline de renderização era executada, limpávamos a árvore, percorríamos todos os objetos sujos e executávamos o layout para que eles ficassem limpos.
Descobrimos que essa arquitetura resultou em muitas classes de problemas, que vamos descrever abaixo. Mas primeiro, vamos dar um passo atrás e considerar o que são as entradas e saídas do layout.
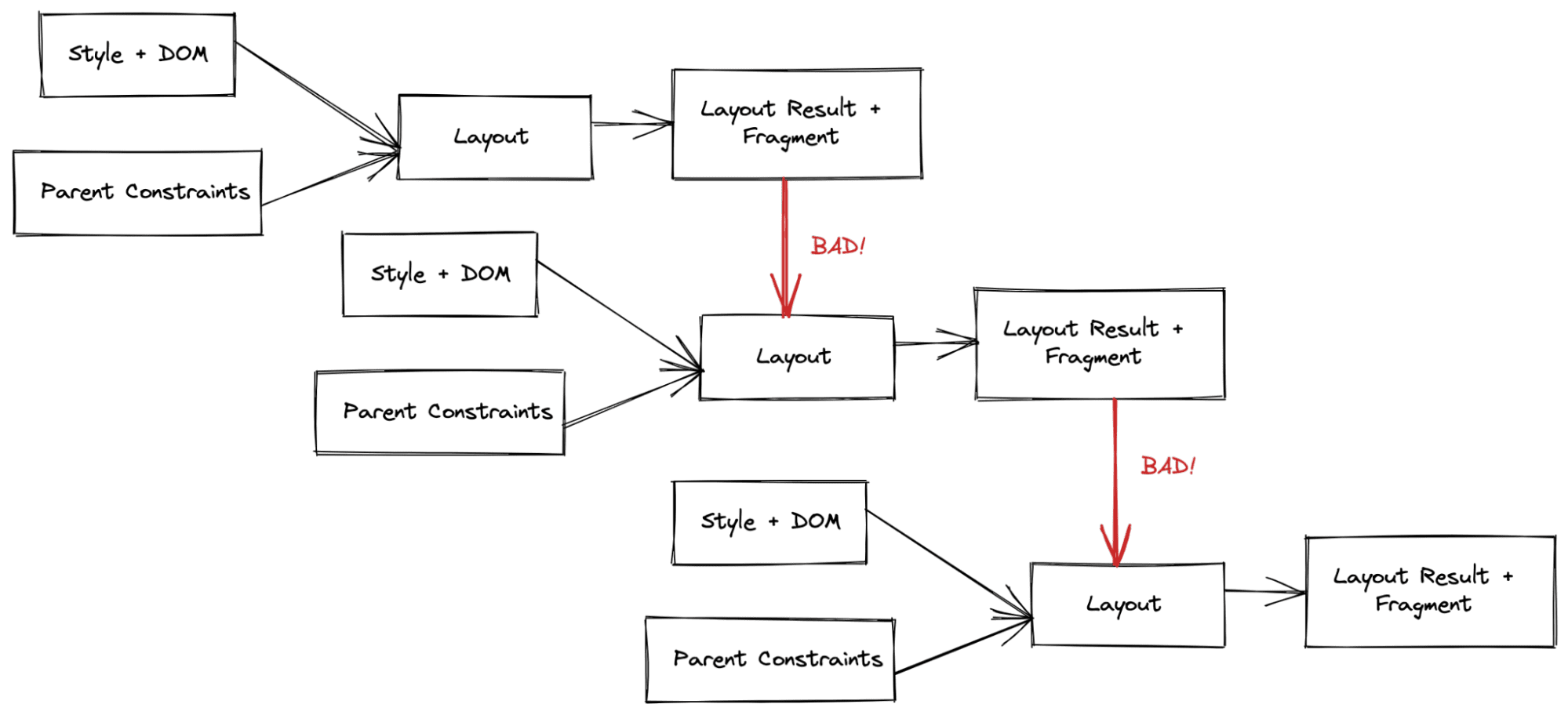
Executar o layout em um nó dessa árvore conceitualmente leva o "Style plus DOM", e todas as restrições mães do sistema de layout pai (grade, bloco ou flex), executa o algoritmo de restrição de layout e produz um resultado.
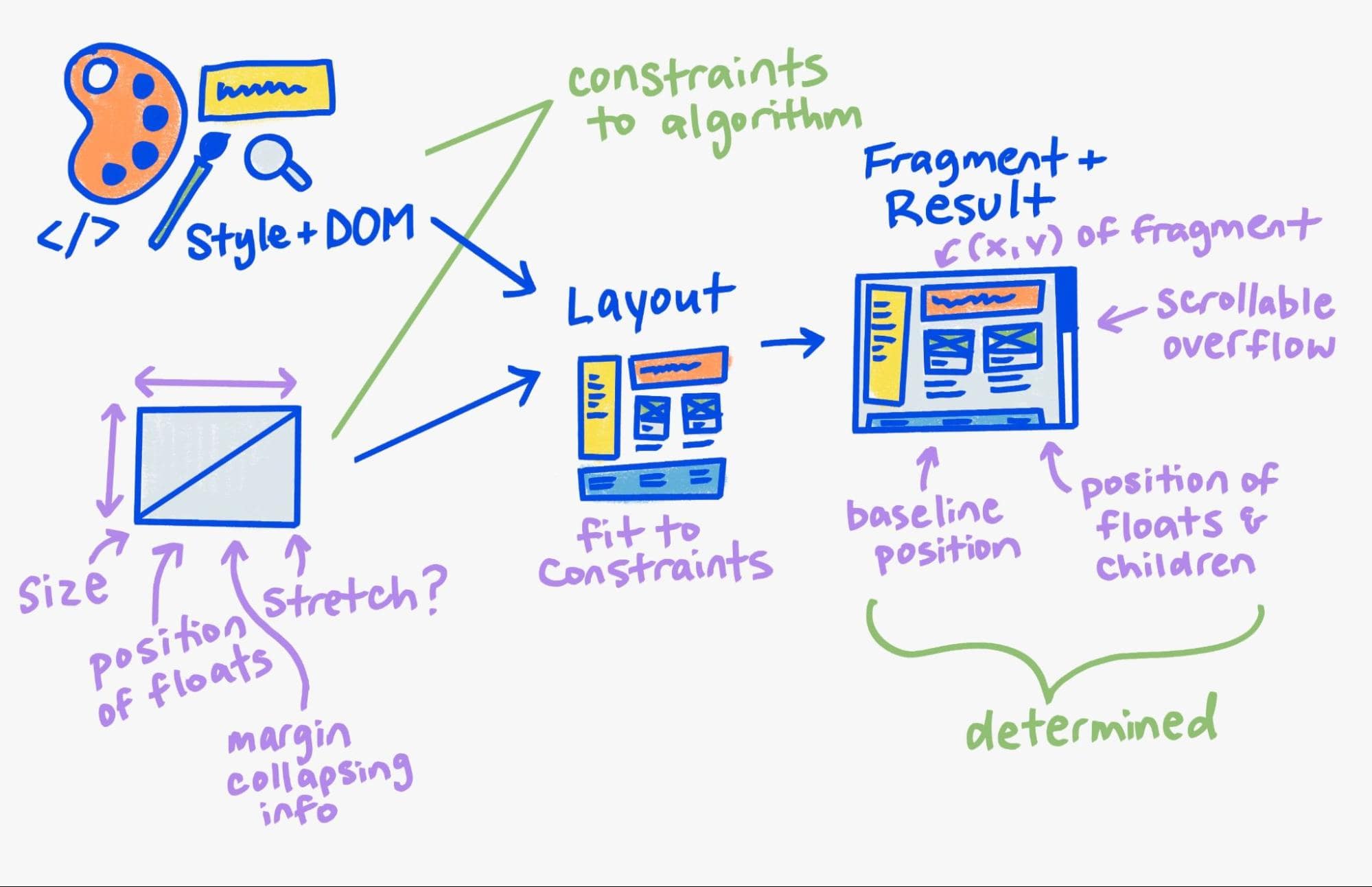
Nossa nova arquitetura formaliza esse modelo conceitual. Ainda temos a árvore de layout, mas a usamos principalmente para manter as entradas e saídas do layout. Para a saída, geramos um objeto imutável totalmente novo chamado árvore de fragmentos.
Eu abordei a árvore de fragmentos imutáveis anteriormente, descrevendo como ela foi projetada para reutilizar grandes partes da árvore anterior para layouts incrementais.
Além disso, armazenamos o objeto de restrições pai que gerou esse fragmento. Usamos isso como uma chave de cache, que será discutida abaixo.
O algoritmo de layout inline (texto) também foi reescrito para corresponder à nova arquitetura imutável. Ele não apenas produz a representação de lista plana imutável para layout inline, mas também apresenta armazenamento em cache no nível do parágrafo para relayout mais rápido, forma por parágrafo para aplicar recursos de fonte em elementos e palavras, um novo algoritmo bidirecional Unicode usando ICU, muitas correções de correção e muito mais.
Tipos de bugs de layout
Os bugs de layout se dividem em quatro categorias, cada uma com causas diferentes.
Correção
Quando pensamos em bugs no sistema de renderização, geralmente pensamos em correção. Por exemplo: "O navegador A tem comportamento X, enquanto o navegador B tem comportamento Y", ou "Os navegadores A e B estão quebrados". Antes, passávamos muito tempo nisso, e no processo, lutávamos constantemente com o sistema. Um modo de falha comum era aplicar uma correção muito específica para um bug, mas descobrir semanas depois que causamos uma regressão em outra parte (aparentemente não relacionada) do sistema.
Como descrito em postagens anteriores, esse é um sinal de um sistema muito frágil. Especificamente para o layout, não tínhamos um contrato limpo entre as classes, o que fazia com que os engenheiros do navegador dependessem de um estado que não deveriam ou interpretassem incorretamente algum valor de outra parte do sistema.
Por exemplo, em um momento, tivemos uma cadeia de aproximadamente 10 bugs ao longo de mais de um ano, relacionada ao layout flexível. Cada correção causou um problema de correção ou desempenho em parte do sistema, levando a outro bug.
Agora que o LayoutNG define claramente o contrato entre todos os componentes do sistema de layout, descobrimos que podemos aplicar mudanças com muito mais confiança. Também nos beneficiamos muito do excelente projeto Web Platform Tests (WPT, na sigla em inglês), que permite que várias partes contribuam para um conjunto de testes da Web comum.
Hoje, descobrimos que, se lançarmos uma regressão real no nosso canal estável, ela normalmente não tem testes associados no repositório do WPT e não resulta de um mal-entendido dos contratos de componentes. Além disso, como parte da nossa política de correção de bugs, sempre adicionamos um novo teste do WPT, para garantir que nenhum navegador cometa o mesmo erro novamente.
Invalidação parcial
Se você já teve um bug misterioso em que redimensionar a janela do navegador ou alternar uma propriedade CSS faz com que o bug desapareça, você encontrou um problema de inválido. Uma parte da árvore mutável foi considerada limpa, mas devido a uma mudança nas restrições principais, ela não representava a saída correta.
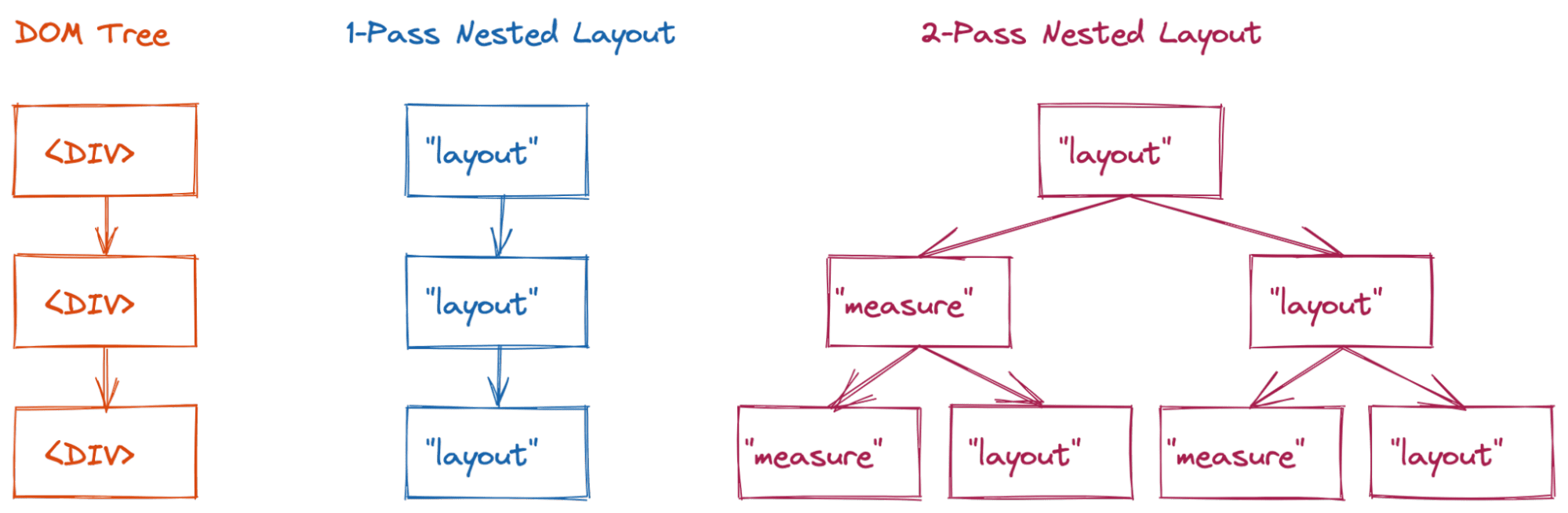
Isso é muito comum com os modos de layout de duas etapas (que percorrem a árvore de layout duas vezes para determinar o estado final do layout) descritos abaixo. Antes, nosso código era assim:
if (/* some very complicated statement */) {
child->ForceLayout();
}
Uma correção para esse tipo de bug geralmente seria:
if (/* some very complicated statement */ ||
/* another very complicated statement */) {
child->ForceLayout();
}
Uma correção para esse tipo de problema normalmente causaria uma regressão de desempenho severa (consulte a invalidação excessiva abaixo) e era muito difícil de corrigir.
Atualmente, como descrito acima, temos um objeto de restrições pai imutável que descreve todas as entradas do layout pai para o filho. Armazenamos isso com o fragmento imutável resultante. Por isso, temos um local centralizado em que comparamos essas duas entradas para determinar se o elemento filho precisa de outra passagem de layout. Essa lógica de comparação é complicada, mas bem contida. A depuração dessa classe de problemas de invalidação parcial geralmente resulta na inspeção manual das duas entradas e na decisão sobre o que mudou na entrada para que outra passagem de layout seja necessária.
As correções para esse código de comparação normalmente são simples e podem ser facilmente testadas em unidades devido à simplicidade da criação desses objetos independentes.
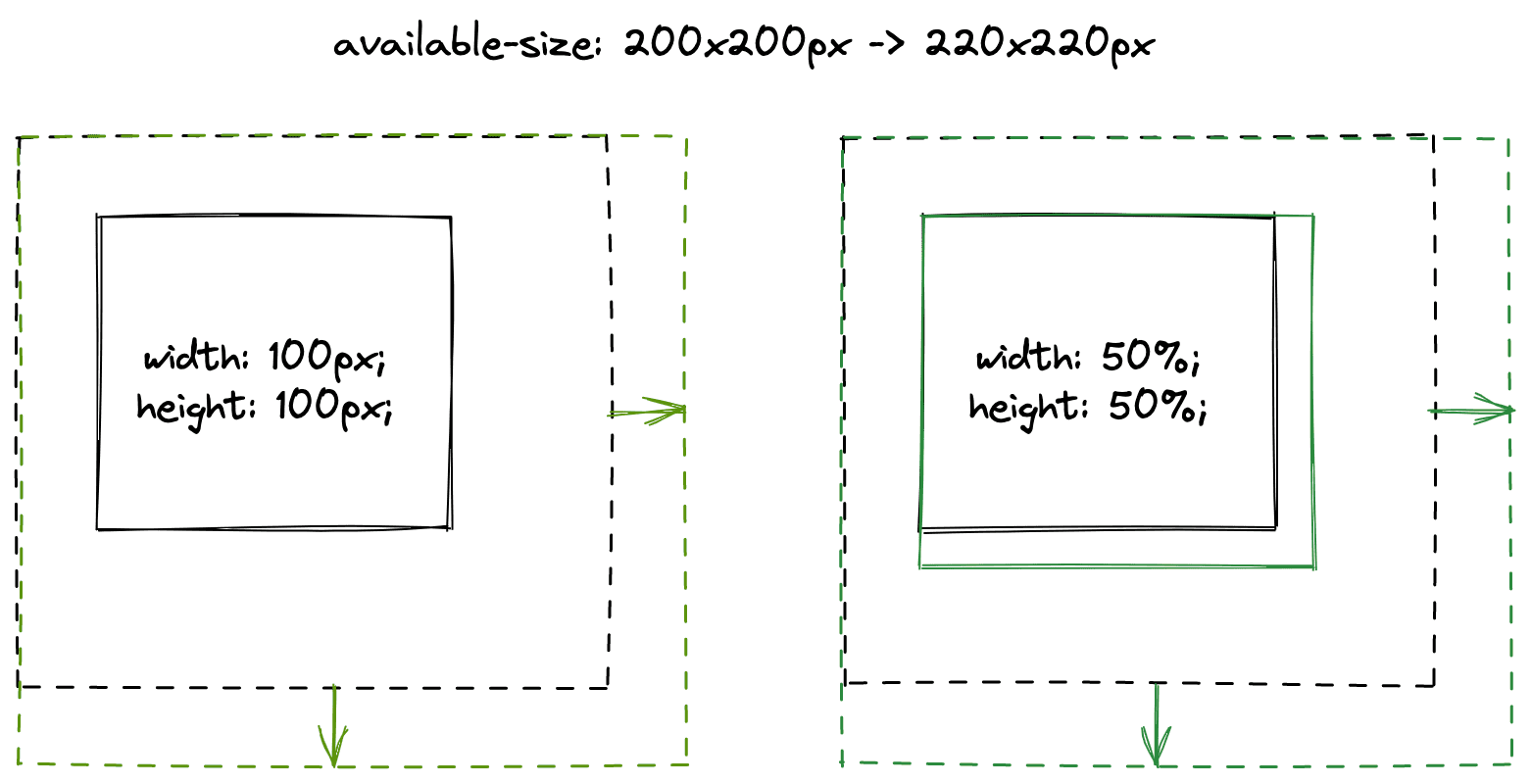
O código de comparação do exemplo acima é:
if (width.IsPercent()) {
if (old_constraints.WidthPercentageSize()
!= new_constraints.WidthPercentageSize())
return kNeedsLayout;
}
if (height.IsPercent()) {
if (old_constraints.HeightPercentageSize()
!= new_constraints.HeightPercentageSize())
return kNeedsLayout;
}
Histerese
Essa classe de bugs é semelhante à invalidação insuficiente. Basicamente, no sistema anterior, era muito difícil garantir que o layout fosse idempotente, ou seja, realizar o layout novamente com as mesmas entradas resultava na mesma saída.
No exemplo abaixo, estamos simplesmente alternando uma propriedade CSS entre dois valores. No entanto, isso resulta em um retângulo "em crescimento infinito".
Com nossa árvore mutável anterior, era muito fácil introduzir bugs como esse. Se o código cometesse o erro de ler o tamanho ou a posição de um objeto no momento ou estágio incorreto (porque não "limpamos" o tamanho ou a posição anterior, por exemplo), adicionaríamos imediatamente um bug de histerese sutil. Esses bugs geralmente não aparecem nos testes, já que a maioria deles se concentra em um único layout e renderização. Além disso, sabíamos que parte dessa histerese era necessária para que alguns modos de layout funcionassem corretamente. Tivemos bugs em que realizamos uma otimização para remover uma passagem de layout, mas introduzimos um "bug", já que o modo de layout exigia duas passagens para gerar a saída correta.
Com o LayoutNG, como temos estruturas de dados de entrada e saída explícitas e o acesso ao estado anterior não é permitido, mitigamos amplamente essa classe de bugs do sistema de layout.
Invalidação excessiva e desempenho
Isso é o oposto direto da classe de bugs de invalidação insuficiente. Muitas vezes, ao corrigir um bug de inválido, desencadeamos uma queda de desempenho.
Muitas vezes, tivemos que fazer escolhas difíceis, favorecendo a correção em vez da performance. Na próxima seção, vamos nos aprofundar em como mitigamos esses tipos de problemas de desempenho.
Aumento dos layouts de duas etapas e quedas de desempenho
O layout flexível e de grade representou uma mudança na expressividade dos layouts na Web. No entanto, esses algoritmos eram fundamentalmente diferentes do algoritmo de layout de bloco anterior.
O layout de bloco (em quase todos os casos) exige apenas que o mecanismo execute o layout em todas as crianças exatamente uma vez. Isso é ótimo para a performance, mas acaba não sendo tão expressivo quanto os desenvolvedores da Web gostariam.
Por exemplo, muitas vezes você quer que o tamanho de todos os filhos seja expandido para o tamanho do maior. Para oferecer suporte a isso, o layout pai (flexível ou de grade) vai realizar uma passagem de medição para determinar o tamanho de cada um dos filhos e, em seguida, uma passagem de layout para esticar todos os filhos para esse tamanho. Esse comportamento é o padrão para layout flexível e de grade.

Esses layouts de duas etapas eram aceitáveis em termos de desempenho, porque as pessoas geralmente não os aninhados profundamente. No entanto, começamos a notar problemas de desempenho significativos à medida que o conteúdo mais complexo foi sendo criado. Se você não armazenar em cache o resultado da fase de medição, a árvore de layout vai alternar entre o estado medição e o estado layout final.
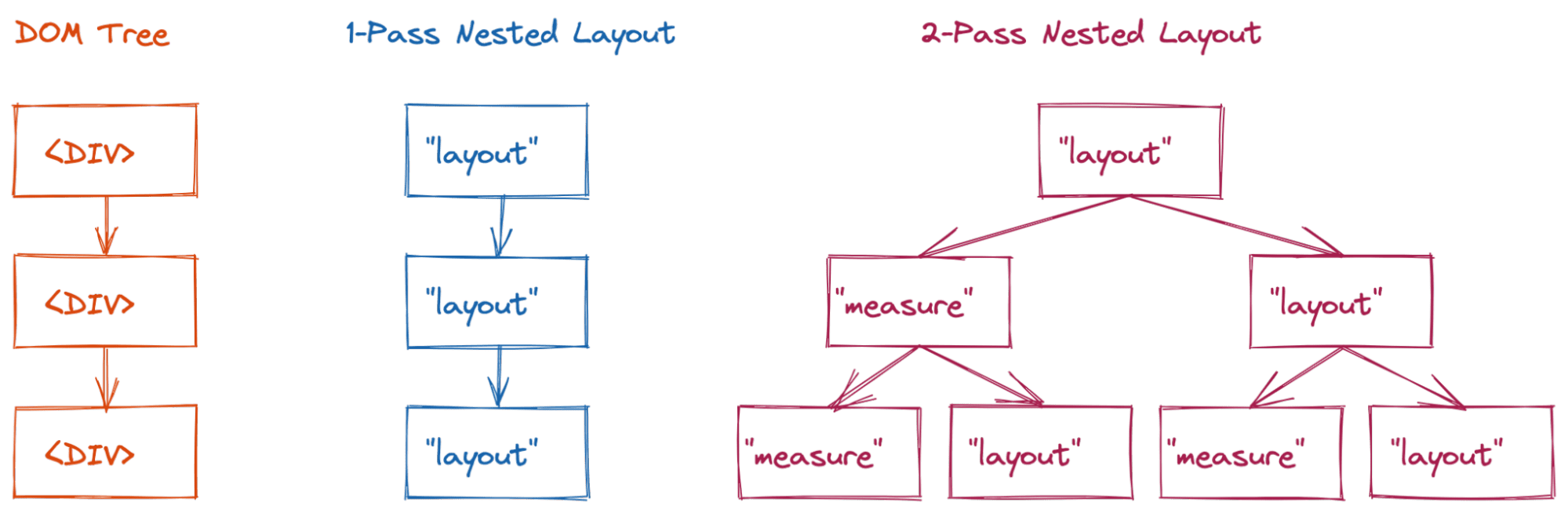
<div>.
Um layout simples de uma única passagem (como o layout de bloco) vai visitar três nós de layout (complexidade O(n)).
No entanto, para um layout de duas etapas (como flex ou grade),
isso pode resultar na complexidade de O(2n) visitas para este exemplo.
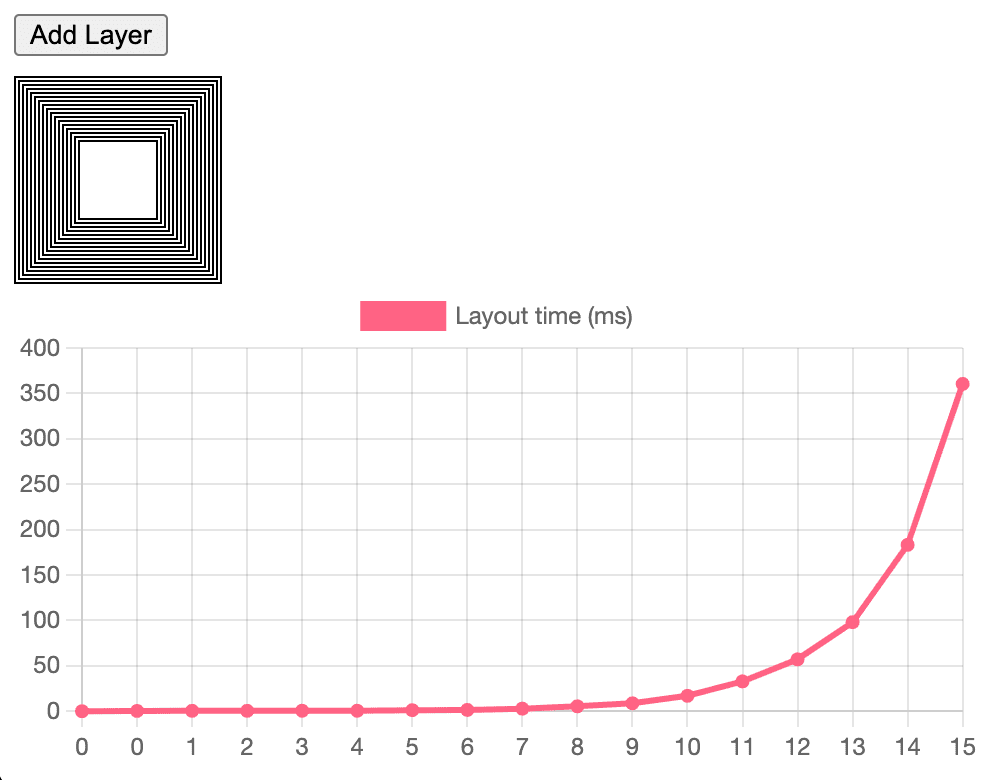
Antes, tentávamos adicionar caches muito específicos ao layout flexível e de grade para combater esse tipo de queda de desempenho. Isso funcionou (e avançamos muito com o Flex), mas estávamos constantemente lutando contra bugs de invalidação insuficiente e excessiva.
O LayoutNG permite criar estruturas de dados explícitas para a entrada e a saída do layout. Além disso, criamos caches das medições e transmissões de layout. Isso traz a complexidade de volta para O(n), resultando em um desempenho linear previsível para desenvolvedores da Web. Se um layout estiver fazendo um layout de três passagens, vamos armazenar em cache essa passagem também. Isso pode abrir oportunidades para introduzir com segurança modos de layout mais avançados no futuro, um exemplo de como o RenderingNG desbloqueia a extensibilidade em todo o sistema. Em alguns casos, o layout de grade pode exigir layouts de três passagens, mas isso é extremamente raro no momento.
Descobrimos que, quando os desenvolvedores encontram problemas de desempenho especificamente com o layout, geralmente é devido a um bug exponencial no tempo de layout, e não ao throughput bruto da etapa de layout do pipeline. Se uma pequena mudança incremental (um elemento mudando uma única propriedade CSS) resultar em um layout de 50 a 100 ms, provavelmente é um bug de layout exponencial.
Resumo
O layout é uma área extremamente complexa, e não abordamos todos os tipos de detalhes interessantes, como otimizações de layout inline (na verdade, como todo o subsistema inline e de texto funciona), e mesmo os conceitos mencionados aqui apenas arranharam a superfície e ignoraram muitos detalhes. No entanto, esperamos ter mostrado como melhorar sistematicamente a arquitetura de um sistema pode levar a ganhos excessivos a longo prazo.
Dito isso, sabemos que ainda temos muito trabalho pela frente. Estamos cientes de algumas classes de problemas (de desempenho e precisão) que estamos trabalhando para resolver e estamos animados com os novos recursos de layout que estão chegando ao CSS. Acreditamos que a arquitetura do LayoutNG torna a resolução desses problemas segura e tratável.
Uma imagem (você sabe qual!) de Una Kravets.