


Blink hace referencia a la implementación de la plataforma web de Chromium y abarca todas las fases de renderización anteriores a la composición, que culminan en la confirmación del compositor. Puedes obtener más información sobre la arquitectura de renderización de Blink en un artículo anterior de esta serie.
Blink comenzó como un derivado de WebKit, que a su vez es un derivado de KHTML, que data de 1998. Contiene algunos de los códigos más antiguos (y más críticos) de Chromium, y en 2014 ya se notaba su antigüedad. En ese año, comenzamos un conjunto de proyectos ambiciosos bajo el lema de lo que llamamos BlinkNG, con el objetivo de abordar deficiencias de larga data en la organización y la estructura del código de Blink. En este artículo, se explorará BlinkNG y sus proyectos constituyentes: por qué los hicimos, qué lograron, los principios rectores que dieron forma a su diseño y las oportunidades de mejoras futuras que ofrecen.
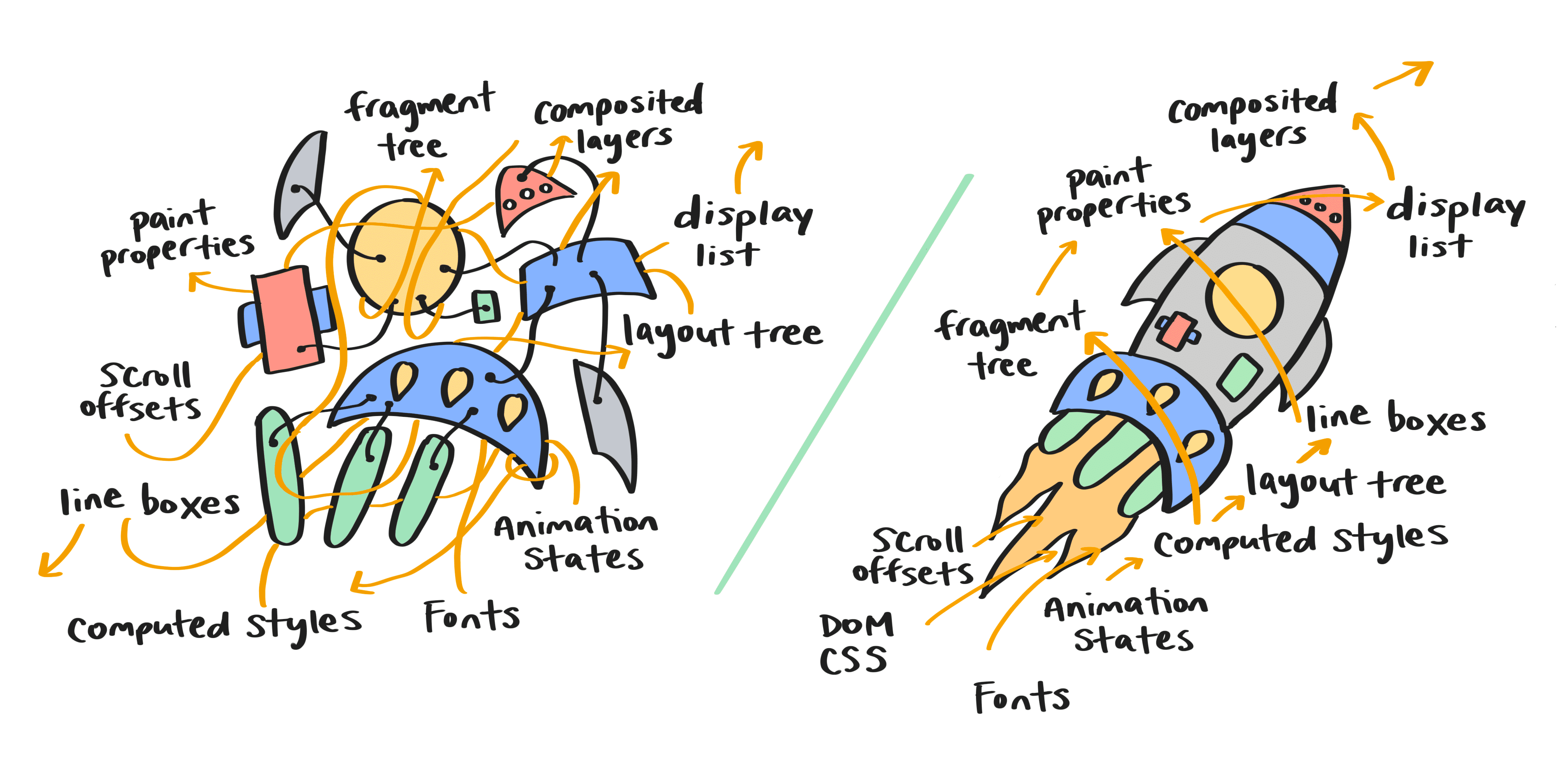
Renderización previa a la NG
La canalización de renderización dentro de Blink siempre se dividió conceptualmente en fases (estilo, diseño, pintura, etcétera), pero las barreras de abstracción tenían filtraciones. En términos generales, los datos asociados con la renderización consistían en objetos inmutables de larga duración. Estos objetos se podían modificar (y se modificaban) en cualquier momento, y se reciclaban y reutilizaban con frecuencia mediante actualizaciones de renderización sucesivas. Era imposible responder de forma confiable preguntas simples, como las siguientes:
- ¿Se debe actualizar el resultado del estilo, el diseño o la pintura?
- ¿Cuándo tendrán estos datos su valor "final"?
- ¿Cuándo es correcto modificar estos datos?
- ¿Cuándo se borrará este objeto?
Existen muchos ejemplos de esto, como los siguientes:
Style generaría ComputedStyle en función de los diseños de plantillas, pero ComputedStyle no era inmutable; en algunos casos, las etapas posteriores de la canalización lo modificarían.
Style generaría un árbol de LayoutObject y, luego, layout anotaría esos objetos con información de tamaño y posicionamiento. En algunos casos, el diseño incluso modificaría la estructura del árbol. No había una separación clara entre las entradas y salidas del diseño.
Style generaría estructuras de datos accesorias que determinarían el curso de la composición, y esas estructuras de datos se modificarían en su lugar en cada fase después de style.
En un nivel inferior, los tipos de datos de renderización consisten en gran medida en árboles especializados (por ejemplo, el árbol DOM, el árbol de diseño, el árbol de propiedades de pintura) y las fases de renderización se implementan como recorridos de árbol recursivos. Idealmente, un recorrido de árbol debe estar contenido: cuando se procesa un nodo de árbol determinado, no debemos acceder a ninguna información fuera del subárbol con raíz en ese nodo. Eso nunca fue cierto antes de RenderingNG; los recorridos de árbol a menudo accedían a información de los ancestros del nodo que se estaba procesando. Esto hizo que el sistema fuera muy frágil y propenso a errores. Tampoco era posible iniciar un recorrido por el árbol desde cualquier lugar que no fuera la raíz.
Por último, había muchas incorporaciones a la canalización de renderización repartidas por todo el código: diseños forzados activados por JavaScript, actualizaciones parciales activadas durante la carga del documento, actualizaciones forzadas para prepararse para la segmentación de eventos, actualizaciones programadas solicitadas por el sistema de visualización y APIs especializadas expuestas solo para probar el código, entre otras. Incluso había algunas rutas recursivas y reentrantes en la canalización de renderización (es decir, saltar al principio de una etapa desde el medio de otra). Cada una de estas incorporaciones tenía su propio comportamiento idiosincrásico y, en algunos casos, el resultado de la renderización dependía de la forma en que se activaba la actualización de renderización.
Qué cambiamos
BlinkNG se compone de muchos subproyectos, grandes y pequeños, todos con el objetivo compartido de eliminar los déficits arquitectónicos descritos anteriormente. Estos proyectos comparten algunos principios rectores diseñados para que la canalización de renderización sea más una canalización real:
- Punto de entrada uniforme: Siempre debemos ingresar a la canalización al principio.
- Etapas funcionales: Cada etapa debe tener entradas y salidas bien definidas, y su comportamiento debe ser funcional, es decir, determinista y repetible, y los resultados deben depender solo de las entradas definidas.
- Entradas constantes: Las entradas de cualquier etapa deben ser constantes mientras se ejecuta.
- Resultados inmutables: Una vez que finaliza una etapa, sus resultados deben ser inmutables durante el resto de la actualización de renderización.
- Coherencia de los puntos de control: Al final de cada etapa, los datos de renderización producidos hasta el momento deben estar en un estado coherente.
- Anulación de duplicación del trabajo: Solo calcula cada elemento una vez.
Una lista completa de los subproyectos de BlinkNG sería una lectura tediosa, pero a continuación, se incluyen algunos de particular importancia.
El ciclo de vida de los documentos
La clase DocumentLifecycle realiza un seguimiento de nuestro progreso a través de la canalización de renderización. Nos permite realizar verificaciones básicas que aplican las invarianzas mencionadas anteriormente, como las siguientes:
- Si modificamos una propiedad ComputedStyle, el ciclo de vida del documento debe ser
kInStyleRecalc. - Si el estado de DocumentLifecycle es
kStyleCleano una versión posterior,NeedsStyleRecalc()debe mostrar false para cualquier nodo adjunto. - Cuando se ingresa a la fase del ciclo de vida de pintura, el estado del ciclo de vida debe ser
kPrePaintClean.
Durante la implementación de BlinkNG, eliminamos de forma sistemática las instrucciones de código que infringían estas invarianzas y agregamos muchas más aserciones en todo el código para asegurarnos de no tener una regresión.
Si alguna vez te has sumergido en el código de renderización de bajo nivel, es posible que te preguntes: "¿Cómo llegué hasta aquí?". Como se mencionó anteriormente, hay una variedad de puntos de entrada a la canalización de renderización. Anteriormente, esto incluía las instrucciones de llamada recursivas y reentrantes, y los lugares en los que ingresábamos a la canalización en una fase intermedia, en lugar de comenzar desde el principio. En el transcurso de BlinkNG, analizamos estas instrucciones de llamada y determinamos que todas se podían reducir a dos situaciones básicas:
- Se deben actualizar todos los datos de renderización, por ejemplo, cuando se generan píxeles nuevos para la visualización o se realiza una prueba de hit para la segmentación de eventos.
- Necesitamos un valor actualizado para una consulta específica que se pueda responder sin actualizar todos los datos de renderización. Esto incluye la mayoría de las consultas de JavaScript, por ejemplo,
node.offsetTop.
Ahora, solo hay dos puntos de entrada a la canalización de renderización, que corresponden a estas dos situaciones. Se quitaron o refactorizaron las instrucciones de código reentrantes, y ya no es posible ingresar a la canalización a partir de una fase intermedia. Esto eliminó muchos misterios sobre cuándo y cómo ocurren exactamente las actualizaciones de renderización, lo que facilita mucho el razonamiento sobre el comportamiento del sistema.
Estilo, diseño y pintura previa de la canalización
En conjunto, las fases de renderización anteriores a paint son responsables de lo siguiente:
- Ejecutar el algoritmo de cascada de estilo para calcular las propiedades de estilo finales de los nodos DOM
- Genera el árbol de diseño que representa la jerarquía de cuadros del documento.
- Determina la información de tamaño y posición de todos los cuadros.
- Redondear o ajustar la geometría de subpíxeles a los límites de píxeles completos para pintar
- Determina las propiedades de las capas compuestas (transformación afín, filtros, opacidad o cualquier otro elemento que pueda acelerarse con la GPU).
- Determinar qué contenido cambió desde la fase de pintura anterior y que se debe pintar o volver a pintar (invalidación de pintura)
Esta lista no cambió, pero antes de BlinkNG, gran parte de este trabajo se realizaba de forma ad hoc, distribuida en varias fases de renderización, con muchas funciones duplicadas y ineficiencias integradas. Por ejemplo, la fase de estilo siempre fue la principal responsable de calcular las propiedades de estilo finales para los nodos, pero hubo algunos casos especiales en los que no determinamos los valores de las propiedades de estilo finales hasta después de que se completó la fase de estilo. No había un punto formal o ejecutable en el proceso de renderización en el que pudiéramos decir con certeza que la información de estilo era completa e inmutable.
Otro buen ejemplo de un problema anterior a BlinkNG es la invalidación de pintura. Anteriormente, la invalidación de pintura se extendía a todas las fases de renderización previas a la pintura. Cuando se modificaba el código de diseño o estilo, era difícil saber qué cambios se necesitaban en la lógica de invalidación de pintura, y era fácil cometer un error que generaba errores de invalidación insuficiente o excesiva. Puedes obtener más información sobre las complejidades del antiguo sistema de invalidación de pintura en el artículo de esta serie dedicado a LayoutNG.
La alineación de la geometría del diseño de subpíxeles con los límites de píxeles completos para la pintura es un ejemplo de un caso en el que tuvimos varias implementaciones de la misma funcionalidad y realizamos mucho trabajo redundante. El sistema de pintura usaba una ruta de código de ajuste de píxeles y una ruta de código completamente independiente que se usaba cada vez que necesitábamos un cálculo único sobre la marcha de coordenadas ajustadas a píxeles fuera del código de pintura. No hace falta decir que cada implementación tenía sus propios errores y que los resultados no siempre coincidían. Como no se almacenaba en caché esta información, el sistema a veces realizaba el mismo cálculo de forma repetida, lo que generaba otra carga en el rendimiento.
Estos son algunos proyectos importantes que eliminaron los déficits arquitectónicos de las fases de renderización antes de pintar.
Project Squad: Canalización de la fase de diseño
Este proyecto abordó dos déficits principales en la fase de diseño que impedían que se canalizara de forma clara:
Hay dos resultados principales de la fase de diseño: ComputedStyle, que contiene el resultado de ejecutar el algoritmo de cascada de CSS en el árbol DOM, y un árbol de LayoutObjects, que establece el orden de las operaciones para la fase de diseño. Conceptualmente, la ejecución del algoritmo en cascada debe ocurrir estrictamente antes de generar el árbol de diseño, pero antes, estas dos operaciones se intercalaban. Project Squad logró dividir estos dos en fases secuenciales y distintas.
Anteriormente, ComputedStyle no siempre obtenía su valor final durante el recálculo de estilo. Había algunas situaciones en las que ComputedStyle se actualizaba durante una fase posterior de la canalización. El equipo de Project Squad refactorizó correctamente estas instrucciones de código para que ComputedStyle nunca se modifique después de la fase de diseño.
LayoutNG: Creación de una canalización para la fase de diseño
Este proyecto monumental, uno de los pilares de RenderingNG, fue una reescritura completa de la fase de renderización del diseño. No haremos justicia a todo el proyecto aquí, pero hay algunos aspectos notables para el proyecto general de BlinkNG:
- Anteriormente, la fase de diseño recibía un árbol de
LayoutObjectcreado por la fase de diseño y lo anotaba con información de tamaño y posición. Por lo tanto, no había una separación clara de las entradas de las salidas. LayoutNG introdujo el árbol de fragmentos, que es el resultado principal de solo lectura del diseño y sirve como entrada principal para las fases de renderización posteriores. - LayoutNG incorporó la propiedad de contención al diseño: cuando se calcula el tamaño y la posición de un
LayoutObjectdeterminado, ya no se busca fuera del subárbol con raíz en ese objeto. Toda la información necesaria para actualizar el diseño de un objeto determinado se calcula de antemano y se proporciona como una entrada de solo lectura al algoritmo. - Anteriormente, había casos extremos en los que el algoritmo de diseño no era estrictamente funcional: el resultado del algoritmo dependía de la actualización de diseño anterior más reciente. LayoutNG eliminó esos casos.
La fase previa a la pintura
Anteriormente, no había una fase de renderización previa a la pintura formal, solo un conjunto de operaciones posteriores al diseño. La fase de prepintura surgió del reconocimiento de que había algunas funciones relacionadas que se podrían implementar mejor como un recorrido sistemático del árbol de diseño después de que se completaba el diseño. Lo más importante es lo siguiente:
- Emisión de invalidaciones de pintura: Es muy difícil realizar la invalidación de pintura correctamente durante el diseño, cuando tenemos información incompleta. Es mucho más fácil hacerlo bien y puede ser muy eficiente si se divide en dos procesos distintos: durante el diseño y el estilo, el contenido se puede marcar con una marca booleana simple como "posiblemente necesite invalidación de pintura". Durante el recorrido del árbol previo a la pintura, verificamos estas marcas y emitimos invalidaciones según sea necesario.
- Generación de árboles de propiedades de pintura: Es un proceso que se describe con más detalle más adelante.
- Cálculo y registro de ubicaciones de pintura ajustadas a píxeles: La fase de pintura puede usar los resultados registrados, así como cualquier código descendente que los necesite, sin ningún cálculo redundante.
Árboles de propiedades: Geometría coherente
Los árboles de propiedades se introdujeron al principio de RenderingNG para abordar la complejidad del desplazamiento, que en la Web tiene una estructura diferente a la de todos los demás tipos de efectos visuales. Antes de los árboles de propiedades, el compositor de Chromium usaba una sola jerarquía de "capa" para representar la relación geométrica del contenido compuesto, pero eso se deshizo rápidamente a medida que se hicieron evidentes las complejidades completas de funciones como position:fixed. La jerarquía de capas creció con punteros no locales adicionales que indicaban el "elemento superior de desplazamiento" o el "elemento superior de recorte" de una capa, y en poco tiempo fue muy difícil entender el código.
Los árboles de propiedades solucionaron este problema representando los aspectos de desplazamiento y recorte del contenido por separado de todos los demás efectos visuales. Esto permitió modelar correctamente la verdadera estructura visual y de desplazamiento de los sitios web. A continuación, "todo" lo que teníamos que hacer era implementar algoritmos en los árboles de propiedades, como la transformación del espacio en pantalla de las capas compuestas o determinar qué capas se desplazaban y cuáles no.
De hecho, pronto notamos que había muchos otros lugares en el código donde se planteaban preguntas geométricas similares. (La publicación de estructuras de datos clave tiene una lista más completa). Varios de ellos tenían implementaciones duplicadas de lo mismo que hacía el código del compositor, todos tenían un subconjunto diferente de errores y ninguno modelaba correctamente la estructura real del sitio web. La solución quedó clara: centralizar todos los algoritmos de geometría en un solo lugar y refactorizar todo el código para usarlo.
Estos algoritmos, a su vez, dependen de los árboles de propiedades, por lo que estos son una estructura de datos clave (es decir, una que se usa en toda la canalización) de RenderingNG. Por lo tanto, para lograr este objetivo de código de geometría centralizado, tuvimos que presentar el concepto de árboles de propiedades mucho antes en la canalización, en la pintura previa, y cambiar todas las APIs que ahora dependían de ellas para que se ejecutara la pintura previa antes de que pudieran ejecutarse.
Esta historia es otro aspecto del patrón de refactorización de BlinkNG: identificar cálculos clave, refactorizar para evitar duplicarlos y crear etapas de canalización bien definidas que creen las estructuras de datos que los alimentan. Calculamos los árboles de propiedades exactamente en el momento en que toda la información necesaria está disponible y nos aseguramos de que los árboles de propiedades no puedan cambiar mientras se ejecutan etapas de renderización posteriores.
Compuesto después de la pintura: Canalización de pintura y compositación
La agrupación en capas es el proceso de determinar qué contenido del DOM va a su propia capa compuesta (que, a su vez, representa una textura de la GPU). Antes de RenderingNG, la división en capas se ejecutaba antes de la pintura, no después (consulta aquí para ver la canalización actual; observa el cambio de orden). Primero, decidiríamos qué partes del DOM se colocaron en qué capa compuesta y, solo después, dibujaríamos listas de visualización para esas texturas. Por supuesto, las decisiones dependían de factores como qué elementos del DOM se animaban o se desplazaban, o tenían transformaciones 3D, y qué elementos se pintaban sobre qué.
Esto causó problemas importantes, ya que más o menos requería que hubiera dependencias circulares en el código, lo que es un gran problema para una canalización de renderización. Veamos por qué con un ejemplo. Supongamos que necesitamos invalidar la pintura (es decir, que debemos volver a dibujar la lista de visualización y, luego, volver a rasterizarla). La necesidad de invalidar puede provenir de un cambio en el DOM o de un cambio de estilo o diseño. Pero, por supuesto, nos gustaría invalidar solo las partes que realmente cambiaron. Esto significaba averiguar qué capas compuestas se vieron afectadas y, luego, invalidar parte o la totalidad de las listas de visualización de esas capas.
Esto significa que la invalidación dependía del DOM, el estilo, el diseño y las decisiones de la capa anterior (pasado: significa para el fotograma renderizado anterior). Pero la actual organización en capas también depende de todos esos elementos. Además, como no teníamos dos copias de todos los datos de la agregación en capas, era difícil distinguir entre las decisiones de agregación en capas anteriores y futuras. Así que terminamos con mucho código que tenía un razonamiento circular. Esto, a veces, generaba código ilógico o incorrecto, o incluso fallas o problemas de seguridad si no éramos muy cuidadosos.
Para abordar esta situación, presentamos el concepto del objeto DisableCompositingQueryAsserts al principio. La mayoría de las veces, si el código intentaba consultar decisiones de la estratificación anteriores, se produciría una falla de aserción y se bloquearía el navegador si estuviera en modo de depuración. Esto nos ayudó a evitar errores nuevos. Y, en cada caso en el que el código necesitaba consultar decisiones de agregación de capas anteriores, agregamos código para permitirlo asignando un objeto DisableCompositingQueryAsserts.
Nuestro plan era, con el tiempo, deshacernos de todos los objetos DisableCompositingQueryAssert de los sitios de llamada y, luego, declarar el código seguro y correcto. Sin embargo, descubrimos que algunas de las llamadas eran prácticamente imposibles de quitar, siempre y cuando la división en capas se produjera antes de la pintura. (Finalmente, pudimos quitarlo hace muy poco). Este fue el primer motivo descubierto para el proyecto Composite After Paint. Lo que aprendimos es que, incluso si tienes una fase de canalización bien definida para una operación, si está en el lugar equivocado de la canalización, con el tiempo te quedarás atascado.
El segundo motivo del proyecto Composite After Paint fue el error de composición fundamental. Una forma de indicar este error es que los elementos DOM no son una buena representación 1:1 de un esquema de estratificación eficiente o completo para el contenido de las páginas web. Y como la composición era anterior a la pintura, dependía más o menos de forma inherente de los elementos del DOM, no de las listas de visualización ni de los árboles de propiedades. Esto es muy similar al motivo por el que presentamos los árboles de propiedades y, al igual que con los árboles de propiedades, la solución se obtiene directamente si encuentras la fase correcta de la canalización, la ejecutas en el momento adecuado y le proporcionas las estructuras de datos clave correctas. Y, al igual que con los árboles de propiedades, esta fue una buena oportunidad para garantizar que, una vez completada la fase de pintura, su resultado sea inmutable para todas las fases posteriores de la canalización.
Beneficios
Como has visto, una canalización de renderización bien definida genera enormes beneficios a largo plazo. Hay incluso más de lo que crees:
- Confiabilidad muy mejorada: Esto es bastante sencillo. Un código más limpio con interfaces bien definidas y comprensibles es más fácil de entender, escribir y probar. Esto lo hace más confiable. También hace que el código sea más seguro y estable, con menos fallas y menos errores de uso después de la liberación.
- Cobertura de pruebas expandida: Durante BlinkNG, agregamos muchas pruebas nuevas a nuestro paquete. Esto incluye pruebas de unidades que proporcionan una verificación enfocada de los elementos internos, pruebas de regresión que nos impiden volver a introducir errores anteriores que corregimos (¡hay muchos!) y muchas incorporaciones al paquete de pruebas de la plataforma web público y mantenido de forma colectiva, que todos los navegadores usan para medir el cumplimiento de los estándares web.
- Más fácil de extender: Si un sistema se divide en componentes claros, no es necesario comprender otros componentes en ningún nivel de detalle para avanzar en el actual. Esto permite que todos agreguen valor al código de renderización sin tener que ser expertos, y también facilita el razonamiento sobre el comportamiento de todo el sistema.
- Rendimiento: Optimizar los algoritmos escritos en código de espagueti es bastante difícil, pero es casi imposible lograr tareas aún más grandes, como animaciones y desplazamiento con subprocesos universales o los procesos y subprocesos para el aislamiento de sitios sin una canalización de este tipo. El paralelismo puede ayudarnos a mejorar el rendimiento de manera significativa, pero también es muy complicado.
- Rendimiento y contención: BlinkNG ofrece varias funciones nuevas que ejercitan la canalización de nuevas maneras. Por ejemplo, ¿qué sucede si solo queremos ejecutar la canalización de renderización hasta que venza un presupuesto? ¿O bien omitir la renderización de subárboles que se sabe que no son relevantes para el usuario en este momento? Eso es lo que habilita la propiedad CSS content-visibility. ¿Qué tal si hacemos que el estilo de un componente dependa de su diseño? Eso son las consultas de contenedores.
Caso de éxito: Consultas de contenedores
Las consultas de contenedor son una función muy esperada de la próxima plataforma web (ha sido la función más solicitada por los desarrolladores de CSS durante años). Si es tan bueno, ¿por qué aún no existe? El motivo es que una implementación de consultas de contenedor requiere una comprensión y un control muy cuidadosos de la relación entre el estilo y el código de diseño. Veamos los detalles.
Una consulta de contenedor permite que los estilos que se aplican a un elemento dependan del tamaño del diseño de un elemento superior. Dado que el tamaño del diseño se calcula durante el diseño, eso significa que debemos ejecutar el recálculo de diseño después del diseño, pero el recálculo de diseño se ejecuta antes del diseño. Esta paradoja del huevo y la gallina es la razón por la que no pudimos implementar consultas de contenedores antes de BlinkNG.
¿Cómo podemos resolver esto? ¿No es una dependencia de canalización hacia atrás, es decir, el mismo problema que resolvieron proyectos como Composite After Paint? Peor aún, ¿qué sucede si los estilos nuevos cambian el tamaño del ancestro? ¿No se generará un bucle infinito?
En principio, la dependencia circular se puede resolver con el uso de la propiedad CSS contain, que permite que la renderización fuera de un elemento no dependa de la renderización dentro del subárbol de ese elemento. Eso significa que los estilos nuevos que aplica un contenedor no pueden afectar su tamaño, ya que las consultas de contenedores requieren contención.
Pero, en realidad, eso no fue suficiente, y fue necesario introducir un tipo de contención más débil que solo la contención de tamaño. Esto se debe a que es común querer que un contenedor de consultas de contenedor pueda cambiar de tamaño en una sola dirección (por lo general, un bloque) según sus dimensiones intercaladas. Por lo tanto, se agregó el concepto de contención de tamaño intercalado. Sin embargo, como puedes ver en la nota muy larga de esa sección, durante mucho tiempo no estuvo claro si era posible el control de tamaño intercalado.
Describir la contención en un lenguaje de especificación abstracto es una cosa, y otra muy distinta es implementarla correctamente. Recuerda que uno de los objetivos de BlinkNG era llevar el principio de contención a los recorridos de árbol que constituyen la lógica principal de la renderización: cuando se recorre un subárbol, no se debe requerir información de fuera de él. Como sucede (bueno, no fue exactamente un accidente), es mucho más limpio y fácil implementar el aislamiento de CSS si el código de renderización cumple con el principio de aislamiento.
Futuro: Compilación fuera del subproceso principal y mucho más
La canalización de renderización que se muestra aquí está un poco por delante de la implementación actual de RenderingNG. Muestra que la estratificación está fuera del subproceso principal, mientras que, en la actualidad, aún está en el subproceso principal. Sin embargo, es solo cuestión de tiempo que esto se haga, ahora que se envió el compuesto después de la pintura y la capa se encuentra después de la pintura.
Para comprender por qué esto es importante y a qué más puede llevar, debemos considerar la arquitectura del motor de renderización desde un punto de vista más elevado. Uno de los obstáculos más duraderos para mejorar el rendimiento de Chromium es el simple hecho de que el subproceso principal del renderizador controla tanto la lógica principal de la aplicación (es decir, la ejecución de la secuencia de comandos) como la mayor parte de la renderización. Como resultado, el subproceso principal suele estar saturado de trabajo, y la congestión del subproceso principal suele ser el cuello de botella de todo el navegador.
La buena noticia es que no tiene por qué ser así. Este aspecto de la arquitectura de Chromium se remonta a los días de KHTML, cuando la ejecución de subproceso único era el modelo de programación dominante. Cuando los procesadores multinúcleo se volvieron comunes en los dispositivos de consumo, la suposición de un solo subproceso estaba completamente integrada en Blink (anteriormente WebKit). Hace mucho tiempo que queríamos agregar más subprocesos al motor de renderización, pero era imposible en el sistema anterior. Uno de los objetivos principales de Rendering NG era salir de este problema y permitir que el trabajo de renderización se trasladara, de forma parcial o total, a otro subproceso (o subprocesos).
Ahora que BlinkNG está a punto de completarse, ya comenzamos a explorar esta área. La confirmación no bloqueante es una primera incursión en el cambio del modelo de subprocesos del renderizador. La confirmación del compositor (o solo confirmación) es un paso de sincronización entre el subproceso principal y el subproceso del compositor. Durante la confirmación, hacemos copias de los datos de renderización que se producen en el subproceso principal para que los use el código de composición descendente que se ejecuta en el subproceso del compositor. Mientras se produce esta sincronización, se detiene la ejecución del subproceso principal mientras el código de copia se ejecuta en el subproceso del compositor. Esto se hace para garantizar que el subproceso principal no modifique sus datos de renderización mientras el subproceso del compositor los copia.
La confirmación no bloqueante eliminará la necesidad de que el subproceso principal se detenga y espere a que finalice la etapa de confirmación. El subproceso principal seguirá trabajando mientras la confirmación se ejecuta de forma simultánea en el subproceso del compositor. El efecto neto de la confirmación no bloqueante será una reducción en el tiempo dedicado a renderizar el trabajo en el subproceso principal, lo que disminuirá la congestión en el subproceso principal y mejorará el rendimiento. En el momento de escribir este artículo (marzo de 2022), tenemos un prototipo en funcionamiento de la confirmación no bloqueante y nos estamos preparando para hacer un análisis detallado de su impacto en el rendimiento.
En el alero, se encuentra la composición fuera del subproceso principal, cuyo objetivo es hacer que el motor de renderización coincida con la ilustración moviendo la capa del subproceso principal a un subproceso de trabajador. Al igual que la confirmación no bloqueante, esto reducirá la congestión en el subproceso principal, ya que disminuirá su carga de trabajo de renderización. Un proyecto como este nunca hubiera sido posible sin las mejoras arquitectónicas de Composite After Paint.
Y hay más proyectos en camino (juego de palabras intencional). Por fin tenemos una base que permite experimentar con la redistribución del trabajo de renderización, y nos entusiasma ver lo que es posible hacer.