


Blink se refere à implementação do Chromium da plataforma da Web e abrange todas as fases de renderização anteriores à composição, culminando no commit do compositor. Leia mais sobre a arquitetura de renderização do Blink em um artigo anterior desta série.
O Blink começou como um fork do WebKit, que é um fork do KHTML, que data de 1998. Ele contém alguns dos códigos mais antigos (e mais importantes) do Chromium, e em 2014 já estava desatualizado. Naquele ano, iniciamos um conjunto de projetos ambiciosos sob o nome de BlinkNG, com o objetivo de resolver deficiências de longa data na organização e estrutura do código do Blink. Este artigo vai abordar o BlinkNG e os projetos que o compõem: por que os fizemos, o que eles alcançaram, os princípios que orientaram o design e as oportunidades de melhorias futuras.
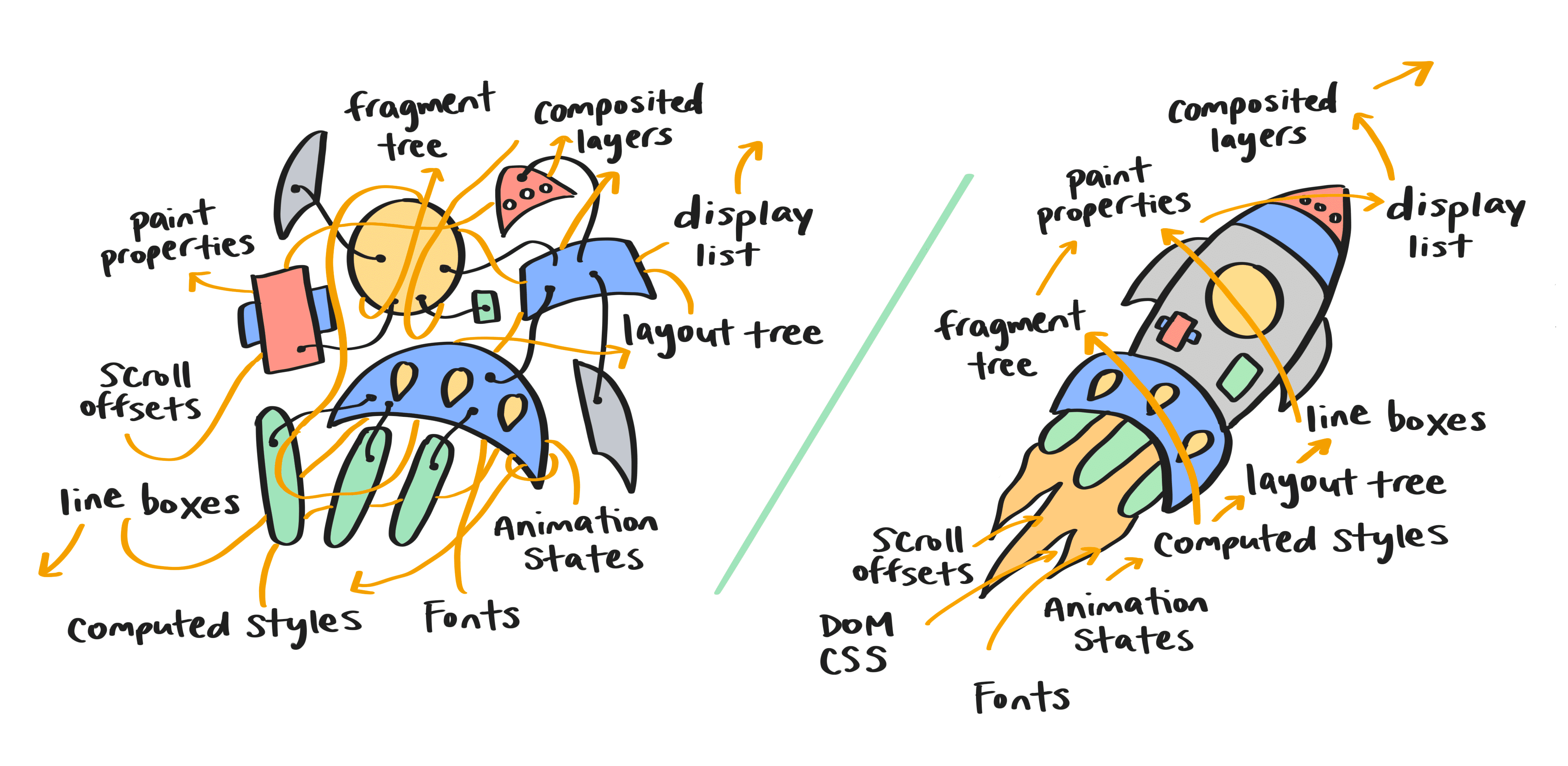
Renderização pré-NG
O pipeline de renderização no Blink sempre foi dividido conceitualmente em fases (estilo, layout, pintura e assim por diante), mas as barreiras de abstração eram permeáveis. De modo geral, os dados associados à renderização consistiam em objetos mutáveis de longa duração. Esses objetos podiam ser modificados a qualquer momento e eram reciclados e reutilizados com frequência por atualizações de renderização sucessivas. Era impossível responder a perguntas simples com confiabilidade, como:
- A saída de estilo, layout ou pintura precisa ser atualizada?
- Quando esses dados vão receber o valor "final"?
- Quando é permitido modificar esses dados?
- Quando esse objeto será excluído?
Há muitos exemplos disso, incluindo:
O estilo gera ComputedStyles com base em folhas de estilo, mas o ComputedStyle não é imutável. Em alguns casos, ele é modificado em estágios posteriores do pipeline.
O estilo gera uma árvore de LayoutObject, e o layout anota esses objetos com informações de tamanho e posicionamento. Em alguns casos, o layout até modifica a estrutura da árvore. Não havia uma separação clara entre as entradas e saídas do layout.
O estilo gera estruturas de dados acessórios que determinam o curso da composição, e essas estruturas de dados são modificadas no lugar em todas as fases após o estilo.
Em um nível mais baixo, os tipos de dados de renderização consistem principalmente em árvores especializadas (por exemplo, a árvore DOM, a árvore de estilo, a árvore de layout, a árvore de propriedades de pintura) e as fases de renderização são implementadas como percursos de árvores recursivas. O ideal é que uma caminhada pela árvore seja contida: ao processar um determinado nó da árvore, não devemos acessar nenhuma informação fora do subárvore com raiz nesse nó. Isso nunca foi verdade antes do RenderingNG. As árvores de navegação acessavam com frequência informações dos ancestrais do nó que estava sendo processado. Isso tornou o sistema muito frágil e propenso a erros. Também era impossível iniciar uma caminhada em qualquer lugar, exceto na raiz da árvore.
Por fim, havia muitos acessos ao pipeline de renderização espalhados por todo o código: layouts forçados acionados pelo JavaScript, atualizações parciais acionadas durante o carregamento do documento, atualizações forçadas para se preparar para a segmentação de eventos, atualizações programadas solicitadas pelo sistema de exibição e APIs especializadas expostas apenas para testar o código, para citar alguns. Havia até alguns caminhos recursivos e reentrantes no pipeline de renderização, ou seja, pular para o início de uma etapa no meio de outra. Cada uma dessas rampas de acesso tinha um comportamento idiossincrático, e, em alguns casos, a saída da renderização dependia da maneira como a atualização da renderização era acionada.
O que mudamos
O BlinkNG é composto por muitos subprojetos, grandes e pequenos, todos com o objetivo comum de eliminar os déficits arquitetônicos descritos anteriormente. Esses projetos compartilham alguns princípios de orientação projetados para tornar o pipeline de renderização mais parecido com um pipeline real:
- Ponto de entrada uniforme: sempre devemos entrar no pipeline no início.
- Fases funcionais: cada fase precisa ter entradas e saídas bem definidas, e o comportamento dela precisa ser funcional, ou seja, determinístico e repetível, e as saídas precisam depender apenas das entradas definidas.
- Entradas constantes: as entradas de qualquer etapa precisam ser constantes enquanto a etapa estiver em execução.
- Saídas imutáveis: quando uma etapa é concluída, as saídas dela precisam ser imutáveis para o restante da atualização de renderização.
- Consistência de checkpoint: no final de cada etapa, os dados de renderização produzidos até o momento precisam estar em um estado autoconsistente.
- Eliminação de duplicação de trabalho: calcule cada coisa apenas uma vez.
Uma lista completa de subprojetos do BlinkNG seria uma leitura cansativa, mas a seguir estão algumas consequências específicas.
Ciclo de vida do documento
A classe DocumentLifecycle monitora nosso progresso no pipeline de renderização. Isso nos permite fazer verificações básicas que impõem as invariantes listadas anteriormente, como:
- Se estivermos modificando uma propriedade ComputedStyle, o ciclo de vida do documento precisa ser
kInStyleRecalc. - Se o estado do DocumentLifecycle for
kStyleCleanou mais recente,NeedsStyleRecalc()precisará retornar falso para qualquer nó anexado. - Ao entrar na fase do ciclo de vida paint, o estado do ciclo de vida precisa ser
kPrePaintClean.
Durante a implementação do BlinkNG, eliminamos sistematicamente os caminhos de código que violavam essas invariantes e espalhamos muitas outras declarações em todo o código para garantir que não houvesse regressão.
Se você já se aventurou a olhar o código de renderização de baixo nível, pode se perguntar: "Como cheguei aqui?" Como mencionado anteriormente, há vários pontos de entrada no pipeline de renderização. Antes, isso incluía caminhos de chamada recursivos e reentrantes e lugares em que entrávamos no pipeline em uma fase intermediária, em vez de começar do início. No curso do BlinkNG, analisamos esses caminhos de chamada e determinamos que todos eles podem ser reduzidos a dois cenários básicos:
- Todos os dados de renderização precisam ser atualizados, por exemplo, ao gerar novos pixels para exibição ou fazer um teste de acerto para segmentação de eventos.
- Precisamos de um valor atualizado para uma consulta específica que possa ser respondida sem atualizar todos os dados de renderização. Isso inclui a maioria das consultas JavaScript, por exemplo,
node.offsetTop.
Agora há apenas dois pontos de entrada no pipeline de renderização, correspondentes a esses dois cenários. Os caminhos de código reentrante foram removidos ou refatorados, e não é mais possível entrar no pipeline a partir de uma fase intermediária. Isso eliminou muito do mistério sobre exatamente quando e como as atualizações de renderização acontecem, facilitando muito a compreensão do comportamento do sistema.
Estilo, layout e pré-pintura do pipeline
Coletivamente, as fases de renderização antes de paint são responsáveis por:
- Executar o algoritmo de cascata de estilo para calcular as propriedades de estilo finais dos nós do DOM.
- Geração da árvore de layout que representa a hierarquia de caixas do documento.
- Determinar informações de tamanho e posição para todas as caixas.
- Arredonda ou fixa a geometria de subpixel em limites de pixels inteiros para pintura.
- Determinar as propriedades de camadas compostas (transformação afim, filtros, opacidade ou qualquer outra coisa que possa ser acelerada pela GPU).
- Determinar qual conteúdo mudou desde a fase de pintura anterior e precisa ser pintado ou repintado (invalidação de pintura).
Essa lista não mudou, mas antes do BlinkNG, grande parte desse trabalho era feito de forma ad hoc, espalhado por várias fases de renderização, com muitas funcionalidades duplicadas e ineficiências integradas. Por exemplo, a fase de estilo sempre foi a principal responsável pelo cálculo das propriedades de estilo final dos nós, mas houve alguns casos especiais em que não determinamos os valores da propriedade de estilo final até que a fase de estilo fosse concluída. Não havia um ponto formal ou aplicável no processo de renderização em que pudéssemos dizer com certeza que as informações de estilo eram completas e imutáveis.
Outro bom exemplo de problema antes do BlinkNG é a invalidação de pintura. Antes, a invalidação de pintura era espalhada por todas as fases de renderização que levavam à pintura. Ao modificar o código de estilo ou layout, era difícil saber quais mudanças na lógica de invação de pintura eram necessárias, e era fácil cometer um erro que levava a bugs de invação insuficiente ou excessiva. Leia mais sobre as complexidades do antigo sistema de invalidação de pintura no artigo desta série dedicado ao LayoutNG.
Agrupar a geometria do layout de subpixels em limites de pixels inteiros para pintura é um exemplo de onde tivemos várias implementações da mesma funcionalidade e fizemos muito trabalho redundante. Havia um caminho de código de ajuste de pixel usado pelo sistema de pintura e um caminho de código totalmente separado usado sempre que precisávamos de um cálculo único e em tempo real de coordenadas ajustadas a pixels fora do código de pintura. Obviamente, cada implementação tinha seus próprios bugs, e os resultados nem sempre eram os mesmos. Como não havia armazenamento em cache dessas informações, o sistema às vezes executava a mesma operação várias vezes, o que também afetava a performance.
Confira alguns projetos importantes que eliminaram os déficits arquitetônicos das fases de renderização antes da pintura.
Project Squad: Pipelining the style phase
Esse projeto abordou dois principais problemas na fase de estilo que impediam que ele fosse executado corretamente:
Há duas saídas principais da fase de estilo: ComputedStyle, que contém o resultado da execução do algoritmo de cascata CSS na árvore DOM, e uma árvore de LayoutObjects, que estabelece a ordem das operações para a fase de layout. Conceitualmente, a execução do algoritmo em cascata precisa acontecer estritamente antes da geração da árvore de layout. No entanto, anteriormente, essas duas operações eram intercaladas. O Project Squad conseguiu dividir essas duas fases em fases distintas e sequenciais.
Anteriormente, o ComputedStyle nem sempre recebia o valor final durante a recalculação de estilo. Em algumas situações, o ComputedStyle era atualizado durante uma fase posterior do pipeline. O Project Squad refatorou esses caminhos de código para que ComputedStyle nunca seja modificado após a fase de estilo.
LayoutNG: como fazer o pipelining da fase de layout
Esse projeto monumental, uma das bases do RenderingNG, foi uma reescrita completa da fase de renderização do layout. Não vamos fazer justiça a todo o projeto aqui, mas há alguns aspectos importantes para o projeto geral do BlinkNG:
- Antes, a fase de layout recebia uma árvore de
LayoutObjectcriada pela fase de estilo e anotava a árvore com informações de tamanho e posição. Portanto, não havia uma separação clara entre entradas e saídas. O LayoutNG introduziu a árvore de fragmentos, que é a saída principal de leitura somente do layout e serve como a entrada principal para fases de renderização subsequentes. - O LayoutNG trouxe a propriedade de contenção para o layout: ao calcular o tamanho e a posição de um determinado
LayoutObject, não procuramos mais fora do subárvore enraizada nesse objeto. Todas as informações necessárias para atualizar o layout de um determinado objeto são calculadas com antecedência e fornecidas como uma entrada somente leitura para o algoritmo. - Antes, havia casos extremos em que o algoritmo de layout não era estritamente funcional: o resultado do algoritmo dependia da atualização de layout anterior mais recente. O LayoutNG eliminou esses casos.
Fase de pré-pintura
Antes, não havia uma fase formal de renderização pré-pintura, apenas um conjunto de operações pós-layout. A fase de pré-pintura surgiu do reconhecimento de que havia algumas funções relacionadas que poderiam ser melhor implementadas como uma travessia sistemática da árvore de layout após a conclusão do layout. Mais importante:
- Emitir invalidações de pintura: é muito difícil fazer a invalidação de pintura corretamente durante o layout quando temos informações incompletas. É muito mais fácil fazer isso corretamente e pode ser muito eficiente se for dividido em dois processos distintos: durante o estilo e o layout, o conteúdo pode ser marcado com uma flag booleana simples como "possivelmente precisa de invalidação de pintura". Durante a pré-pintura, verificamos essas sinalizações e emitimos invalidações conforme necessário.
- Como gerar árvores de propriedades de paint: um processo descrito em mais detalhes mais adiante.
- Cálculo e gravação de locais de pintura com ajuste de pixel: os resultados gravados podem ser usados pela fase de pintura e por qualquer código downstream que precise deles, sem cálculos redundantes.
Árvores de propriedades: geometria consistente
As árvores de propriedades foram introduzidas no início do RenderingNG para lidar com a complexidade da rolagem, que na Web tem uma estrutura diferente de todos os outros tipos de efeitos visuais. Antes das árvores de propriedades, o compositor do Chromium usava uma única hierarquia de "camadas" para representar a relação geométrica do conteúdo composto, mas isso rapidamente se desfez à medida que as complexidades completas de recursos como position:fixed se tornaram aparentes. A hierarquia de camadas cresceu com ponteiros não locais extras indicando o "pai de rolagem" ou o "pai de recorte" de uma camada, e logo foi muito difícil entender o código.
As árvores de propriedades corrigiram isso representando os aspectos de rolagem e clipe de overflow do conteúdo separadamente de todos os outros efeitos visuais. Isso possibilitou a criação de um modelo correto da estrutura visual e de rolagem dos sites. Depois, tudo o que precisamos fazer foi implementar algoritmos nas árvores de propriedades, como a transformação de espaço de tela de camadas compostas ou determinar quais camadas rolaram e quais não rolaram.
Na verdade, logo percebemos que havia muitos outros lugares no código em que perguntas geométricas semelhantes eram feitas. O post sobre estruturas de dados principais tem uma lista mais completa. Vários deles tinham implementações duplicadas da mesma coisa que o código do compositor estava fazendo. Todos tinham um subconjunto diferente de bugs e nenhum deles modelou corretamente a estrutura real do site. A solução ficou clara: centralize todos os algoritmos de geometria em um só lugar e refatore todo o código para usá-los.
Esses algoritmos dependem das árvores de propriedades, por isso elas são uma estrutura de dados chave (usada em todo o pipeline) do RenderingNG. Para alcançar esse objetivo de código de geometria centralizado, precisamos introduzir o conceito de árvores de propriedades muito antes no pipeline, na pré-pintura, e mudar todas as APIs que dependiam delas para exigir que a pré-pintura fosse executada antes da execução.
Essa história é outro aspecto do padrão de refatoração do BlinkNG: identificar as principais computações, refatorar para evitar a duplicação delas e criar estágios de pipeline bem definidos que criam as estruturas de dados que as alimentam. Computamos as árvores de propriedades exatamente no momento em que todas as informações necessárias estão disponíveis e garantimos que elas não podem mudar enquanto os estágios de renderização posteriores estão em execução.
Composição após a pintura: pipelining de pintura e composição
A geração de camadas é o processo de descobrir qual conteúdo do DOM vai para a própria camada composta (que, por sua vez, representa uma textura da GPU). Antes do RenderingNG, a estratificação era executada antes da pintura, não depois (consulte este link para conferir o pipeline atual e observar a mudança de ordem). Primeiro, decidimos quais partes do DOM iam para qual camada composta e, só depois, desenhamos listas de exibição para essas texturas. Naturalmente, as decisões dependiam de fatores como quais elementos DOM estavam animando ou rolando, ou tinham transformações 3D, e quais elementos eram pintados em cima de quais.
Isso causou problemas importantes, porque exigia mais ou menos que houvesse dependências circulares no código, o que é um grande problema para um pipeline de renderização. Vamos conferir o motivo com um exemplo. Suponha que seja necessário invalidar a pintura, ou seja, que seja necessário redesenhar a lista de exibição e rasterizar novamente. A necessidade de invalidação pode vir de uma mudança no DOM ou de um estilo ou layout alterado. Mas, é claro, queremos invalidar apenas as partes que realmente mudaram. Isso significava descobrir quais camadas compostas foram afetadas e, em seguida, invalidar parte ou todas as listas de exibição dessas camadas.
Isso significa que a invalidação dependia de decisões anteriores de DOM, estilo, layout e camadas (passado: significa o frame renderizado anterior). Mas a estratificação atual também depende de todas essas coisas. Como não tínhamos duas cópias de todos os dados de estratificação, era difícil identificar a diferença entre as decisões de estratificação passadas e futuras. Então, acabamos com muito código com raciocínio circular. Isso às vezes levava a um código ilógico ou incorreto, ou até mesmo a falhas ou problemas de segurança, se não fôssemos muito cuidadosos.
Para lidar com essa situação, apresentamos o conceito do objeto DisableCompositingQueryAsserts. Na maioria das vezes, se o código tentasse consultar decisões de estratificação anteriores, isso causaria uma falha de declaração e faria com que o navegador travasse se estivesse no modo de depuração. Isso nos ajudou a evitar novos bugs. E em cada caso em que o código precisava consultar decisões de camadas anteriores, colocamos um código para permitir isso alocando um objeto DisableCompositingQueryAsserts.
Nosso plano era, com o tempo, se livrar de todos os objetos DisableCompositingQueryAssert de sites de chamada e, em seguida, declarar o código como seguro e correto. Mas descobrimos que algumas chamadas eram basicamente impossíveis de remover, desde que a estratificação ocorresse antes da pintura. (Finalmente conseguimos remover há muito pouco tempo.) Essa foi a primeira razão descoberta para o projeto Composite After Paint. O que aprendemos foi que, mesmo que você tenha uma fase de pipeline bem definida para uma operação, se ela estiver no lugar errado no pipeline, você vai ficar preso.
O segundo motivo para o projeto "Composite After Paint" foi o bug de composição fundamental. Uma maneira de declarar esse bug é que os elementos DOM não são uma boa representação 1:1 de um esquema de estratificação eficiente ou completo para o conteúdo da página da Web. Como a composição era anterior à pintura, ela dependia mais ou menos de elementos DOM, não de listas de exibição ou árvores de propriedades. Isso é muito semelhante ao motivo pelo qual apresentamos as árvores de propriedades. Assim como nas árvores de propriedades, a solução é direta se você descobrir a fase certa do pipeline, executá-la no momento certo e fornecer as estruturas de dados principais corretas. Assim como nas árvores de propriedades, essa foi uma boa oportunidade para garantir que, após a conclusão da fase de pintura, a saída dela seja imutável para todas as fases subsequentes do pipeline.
Vantagens
Como você viu, um pipeline de renderização bem definido gera enormes benefícios a longo prazo. Há ainda mais do que você imagina:
- Melhoria significativa na confiabilidade: isso é bem simples. Códigos mais limpos com interfaces bem definidas e compreensíveis são mais fáceis de entender, escrever e testar. Isso aumenta a confiabilidade. Isso também torna o código mais seguro e estável, com menos falhas e bugs use-after-free.
- Cobertura de teste ampliada: no curso do BlinkNG, adicionamos muitos novos testes ao nosso pacote. Isso inclui testes de unidade que fornecem verificação focada de recursos internos, testes de regressão que evitam a reintrodução de bugs antigos que corrigimos (muitos!), e muitas adições ao conjunto de testes da plataforma da Web público e mantido coletivamente, que todos os navegadores usam para medir a conformidade com os padrões da Web.
- Fácil de estender: se um sistema é dividido em componentes claros, não é necessário entender outros componentes em qualquer nível de detalhes para progredir no atual. Isso facilita a adição de valor ao código de renderização sem precisar ser um especialista, além de facilitar a compreensão do comportamento de todo o sistema.
- Desempenho: otimizar algoritmos escritos em código spaghetti já é difícil, mas é quase impossível alcançar coisas ainda maiores, como rolagem e animações em linha de execução universal ou processos e linhas de execução para isolamento de sites sem esse pipeline. O paralelismo pode ajudar a melhorar muito a performance, mas também é extremamente complicado.
- Yielding e contenção: o BlinkNG oferece vários recursos novos que exercitam o pipeline de maneiras novas e inovadoras. Por exemplo, e se quiséssemos executar o pipeline de renderização apenas até que um orçamento expirasse? Ou pular a renderização de subárvores que não são relevantes para o usuário no momento? É isso que a propriedade CSS content-visibility permite. E se o estilo de um componente depender do layout dele? Isso é consultas em contêiner.
Estudo de caso: consultas em contêiner
As consultas de contêiner são um recurso da plataforma da Web muito aguardado (é o recurso mais solicitado pelos desenvolvedores de CSS há anos). Se é tão bom, por que ainda não existe? Isso acontece porque a implementação de consultas de contêiner exige um entendimento e controle muito cuidadosos da relação entre o estilo e o código de layout. Vamos analisar melhor.
Uma consulta de contêiner permite que os estilos aplicados a um elemento dependam do tamanho do layout de um ancestral. Como o tamanho do layout é calculado durante o layout, precisamos executar o recalc do estilo após o layout, mas o recalc do estilo é executado antes do layout. Esse paradoxo é o motivo pelo qual não conseguimos implementar consultas de contêineres antes do BlinkNG.
Como podemos resolver isso? Não é uma dependência de pipeline reversa, ou seja, o mesmo problema que projetos como o Composite After Paint resolveram? Pior ainda, e se os novos estilos mudarem o tamanho do ancestral? Isso não pode levar a um loop infinito?
Em princípio, a dependência circular pode ser resolvida usando a propriedade CSS contain, que permite que a renderização fora de um elemento não dependa da renderização dentro do subárvore desse elemento. Isso significa que os novos estilos aplicados por um contêiner não podem afetar o tamanho dele, porque as consultas de contêiner exigem contenção.
Mas isso não foi suficiente, e foi necessário introduzir um tipo de contenção mais fraco do que apenas a contenção de tamanho. Isso ocorre porque é comum que um contêiner de consulta de contêineres possa ser redimensionado em apenas uma direção (geralmente bloco) com base nas dimensões inline. Por isso, o conceito de contenção de tamanho inline foi adicionado. No entanto, como você pode ver na nota muito longa dessa seção, não ficou claro por muito tempo se a contenção de tamanho inline era possível.
Descrever o contenção em uma linguagem de especificação abstrata é uma coisa, mas implementá-lo corretamente é outra. Lembre-se de que um dos objetivos do BlinkNG era trazer o princípio de contenção para as caminhadas de árvore que constituem a lógica principal da renderização: ao percorrer um subárvore, nenhuma informação precisa ser exigida de fora dela. Como acontece (não foi exatamente um acidente), é muito mais fácil implementar a contenção de CSS se o código de renderização obedecer ao princípio de contenção.
Futuro: composição fora da linha de execução principal… e muito mais!
O pipeline de renderização mostrado aqui está um pouco à frente da implementação atual do RenderingNG. Ele mostra a estratificação como estando fora da linha de execução principal, enquanto atualmente ela ainda está na linha de execução principal. No entanto, isso será feito em breve, agora que o Composite After Paint foi enviado e a estratificação está após a pintura.
Para entender por que isso é importante e o que mais pode acontecer, precisamos considerar a arquitetura do mecanismo de renderização de um ponto de vista um pouco mais alto. Um dos obstáculos mais duradouros para melhorar o desempenho do Chromium é o simples fato de que a linha de execução principal do renderizador processa a lógica principal do aplicativo (ou seja, executa o script) e a maior parte da renderização. Como resultado, a linha de execução principal fica saturada com frequência e o congestionamento da linha de execução principal é frequentemente o gargalo em todo o navegador.
A boa notícia é que não precisa ser assim. Esse aspecto da arquitetura do Chromium remonta aos dias do KHTML, quando a execução de thread único era o modelo de programação dominante. Quando os processadores multicore se tornaram comuns em dispositivos de consumo, a suposição de único thread foi totalmente integrada ao Blink (anteriormente WebKit). Há muito tempo, queríamos introduzir mais linhas de execução no mecanismo de renderização, mas isso era simplesmente impossível no sistema antigo. Um dos principais objetivos da Renderização NG era sair dessa situação e permitir que o trabalho de renderização fosse transferido, parcial ou totalmente, para outra linha de execução.
Agora que o BlinkNG está chegando ao fim, já estamos começando a explorar essa área. O commit não bloqueante é uma primeira incursão na mudança do modelo de linha de execução do renderizador. O commit do compositor (ou apenas commit) é uma etapa de sincronização entre a linha de execução principal e a do compositor. Durante o commit, fazemos cópias dos dados de renderização produzidos na linha de execução principal para serem usados pelo código de composição downstream executado na linha de execução do compositor. Enquanto essa sincronização está acontecendo, a execução da linha de execução principal é interrompida enquanto o código de cópia é executado na linha de execução do compositor. Isso é feito para garantir que a linha de execução principal não modifique os dados de renderização enquanto a linha de execução do compositor está copiando.
A confirmação não bloqueante elimina a necessidade de a linha de execução principal parar e esperar o fim da etapa de confirmação. A linha de execução principal continua trabalhando enquanto a confirmação é executada simultaneamente na linha de execução do compositor. O efeito líquido da confirmação não bloqueante será uma redução no tempo dedicado à renderização do trabalho na linha de execução principal, o que diminuirá a congestionamento na linha de execução principal e melhorará o desempenho. No momento em que este artigo foi escrito (março de 2022), tínhamos um protótipo funcional de confirmação não bloqueante e estamos nos preparando para fazer uma análise detalhada do impacto dela na performance.
Aguardando a Composição fora da linha de execução principal, com o objetivo de fazer com que o mecanismo de renderização corresponda à ilustração movendo a camada da linha de execução principal para uma linha de execução de worker. Assim como a confirmação não bloqueante, isso vai reduzir a congestionamento na linha de execução principal, diminuindo a carga de trabalho de renderização. Um projeto como esse nunca seria possível sem as melhorias arquitetônicas do Composite After Paint.
E há mais projetos em andamento (intencionalmente). Finalmente temos uma base que permite experimentar a redistribuição do trabalho de renderização, e estamos muito animados para ver o que é possível fazer.