
この投稿では、例を通して試験運用版の WebGPU API を説明し、GPU を使用したデータ並列計算の実行を開始するのに役立つ情報を提供します。

公開日: 2019 年 8 月 28 日、最終更新日: 2025 年 8 月 12 日
背景
ご存知のとおり、グラフィック プロセッシング ユニット(GPU)は、元々グラフィック処理に特化したコンピュータ内の電子サブシステムです。しかし、この 10 年間で、GPU の独自のアーキテクチャを活用しながら、3D グラフィックのレンダリングだけでなく、さまざまな種類のアルゴリズムをデベロッパーが実装できる、より柔軟なアーキテクチャへと進化しました。これらの機能は GPU コンピューティングと呼ばれ、汎用科学技術計算のコプロセッサとして GPU を使用することは、汎用 GPU(GPGPU)プログラミングと呼ばれます。
GPU コンピューティングは、最近の機械学習ブームに大きく貢献しています。これは、畳み込みニューラル ネットワークなどのモデルがこのアーキテクチャを利用して GPU でより効率的に実行できるためです。現在のウェブ プラットフォームには GPU コンピューティング機能が不足しているため、W3C の「GPU for the Web」コミュニティ グループは、現在のほとんどのデバイスで利用可能な最新の GPU API を公開する API を設計しています。この API は WebGPU と呼ばれます。
WebGPU は WebGL のような低レベルの API です。ご覧のとおり、非常に強力で冗長です。ただし、問題はありません。パフォーマンスを重視しています。
この記事では、WebGPU の GPU コンピューティング部分に焦点を当てます。正直なところ、表面をなぞる程度ですが、ご自身で試してみるには十分でしょう。今後の記事では、WebGPU レンダリング(キャンバス、テクスチャなど)について詳しく説明します。
GPU にアクセスする
WebGPU では GPU に簡単にアクセスできます。navigator.gpu.requestAdapter() を呼び出すと、GPU アダプタで非同期的に解決される JavaScript Promise が返されます。このアダプターはグラフィック カードのようなものです。統合型(CPU と同じチップ上)またはディスクリート型(通常は PCIe カードで、パフォーマンスは高いが消費電力が多い)のいずれかになります。
GPU アダプターを取得したら、adapter.requestDevice() を呼び出して、GPU 計算に使用する GPU デバイスで解決される Promise を取得します。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
どちらの関数も、必要なアダプター(電力設定)とデバイス(拡張機能、制限)の種類を指定できるオプションを受け取ります。わかりやすくするために、この記事ではデフォルトのオプションを使用します。
書き込みバッファメモリ
JavaScript を使用して GPU のメモリにデータを書き込む方法を見てみましょう。最新のウェブブラウザで使用されているサンドボックス モデルのため、このプロセスは簡単ではありません。
次の例は、GPU からアクセス可能なバッファメモリに 4 バイトを書き込む方法を示しています。バッファのサイズとその使用状況を取得する device.createBuffer() を呼び出します。この特定の呼び出しでは使用フラグ GPUBufferUsage.MAP_WRITE は必須ではありませんが、このバッファに書き込みたいことを明示的に示しましょう。mappedAtCreation が true に設定されているため、作成時にマッピングされた GPU バッファ オブジェクトが生成されます。関連付けられた未加工のバイナリ データバッファは、GPU バッファ メソッド getMappedRange() を呼び出すことで取得できます。
ArrayBuffer を使用したことがある場合は、バイトの書き込みに慣れているでしょう。TypedArray を使用して、値をコピーします。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
この時点で、GPU バッファはマッピングされています。つまり、CPU が所有しており、JavaScript から読み取り/書き込みアクセスできます。GPU がアクセスできるように、マッピングを解除する必要があります。これは gpuBuffer.unmap() を呼び出すだけで簡単に行えます。
マッピング/マッピング解除の概念は、GPU と CPU が同時にメモリにアクセスする競合状態を防ぐために必要です。
バッファメモリの読み取り
次に、GPU バッファを別の GPU バッファにコピーして読み取る方法を見てみましょう。
最初の GPU バッファに書き込み、それを 2 番目の GPU バッファにコピーするため、新しい使用フラグ GPUBufferUsage.COPY_SRC が必要です。2 つ目の GPU バッファは、今回は device.createBuffer() でマッピングされていない状態で作成されます。使用フラグは GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ です。これは、最初の GPU バッファの宛先として使用され、GPU コピー コマンドが実行されると JavaScript で読み取られるためです。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
GPU は独立したコプロセッサであるため、すべての GPU コマンドは非同期で実行されます。そのため、GPU コマンドのリストが作成され、必要に応じてバッチで送信されます。WebGPU では、device.createCommandEncoder() によって返される GPU コマンド エンコーダは、ある時点で GPU に送信される「バッファリングされた」コマンドのバッチを構築する JavaScript オブジェクトです。一方、GPUBuffer のメソッドは「バッファリングされない」ため、呼び出されたときにアトミックに実行されます。
GPU コマンド エンコーダを取得したら、次に示すように copyEncoder.copyBufferToBuffer() を呼び出して、このコマンドを後で実行するためのコマンドキューに追加します。最後に、copyEncoder.finish() を呼び出してエンコード コマンドを終了し、GPU デバイス コマンドキューに送信します。キューは、device.queue.submit() を介して行われた送信を GPU コマンドを引数として処理します。これにより、配列に格納されているすべてのコマンドが順番にアトミックに実行されます。
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
この時点で、GPU キューコマンドは送信されていますが、必ずしも実行されているとは限りません。2 番目の GPU バッファを読み取るには、GPUMapMode.READ を指定して gpuReadBuffer.mapAsync() を呼び出します。これは、GPU バッファがマッピングされると解決される Promise を返します。次に、キューに登録されたすべての GPU コマンドが実行されたら、最初の GPU バッファと同じ値を含む gpuReadBuffer.getMappedRange() でマッピングされた範囲を取得します。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
バッファメモリ オペレーションに関して覚えておくべきことは次のとおりです。
- GPU バッファは、デバイスキューの送信で使用するためにマッピング解除する必要があります。
- マッピングされた GPU バッファは JavaScript で読み書きできます。
mappedAtCreationが true に設定されたmapAsync()とcreateBuffer()が呼び出されると、GPU バッファがマッピングされます。
シェーダー プログラミング
GPU で実行され、計算のみを行う(三角形を描画しない)プログラムは、コンピューティング シェーダーと呼ばれます。これらのタスクは、データを処理するために連携して動作する数百個の GPU コア(CPU コアよりも小さい)によって並列で実行されます。入力と出力は WebGPU のバッファです。
WebGPU でのコンピューティング シェーダーの使用例として、以下に示す機械学習でよく使用されるアルゴリズムである行列乗算を扱います。
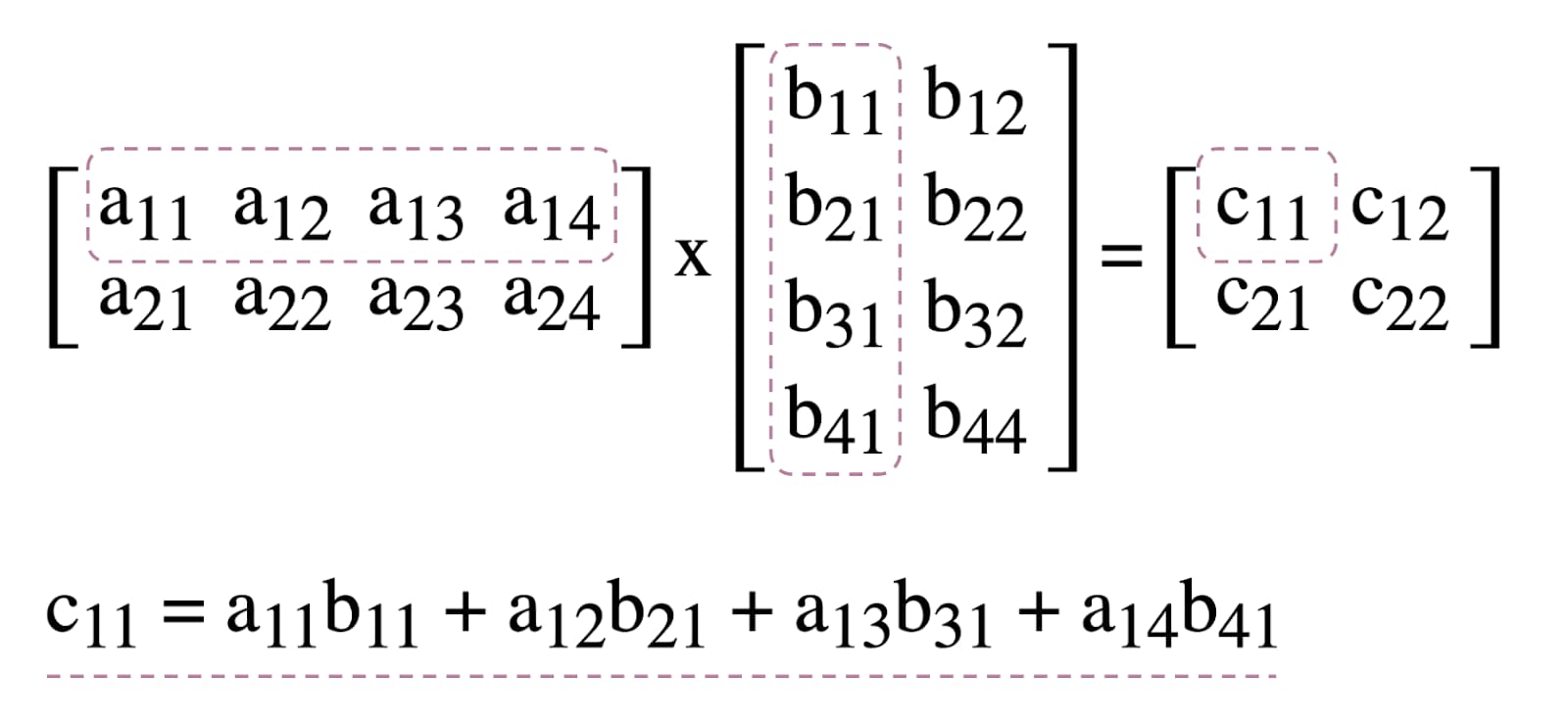
要約すると、次のことを行います。
- 3 つの GPU バッファを作成します(乗算する行列用に 2 つ、結果行列用に 1 つ)。
- コンピュート シェーダーの入力と出力について説明する
- コンピューティング シェーダー コードをコンパイルする
- コンピューティング パイプラインを設定する
- エンコードされたコマンドを GPU にバッチで送信する
- 結果マトリックスの GPU バッファを読み取る
GPU バッファの作成
簡単にするため、行列は浮動小数点数のリストとして表します。最初の要素は行数、2 番目の要素は列数、残りは行列の実際の数値です。

3 つの GPU バッファは、コンピューティング シェーダーでデータを保存して取得する必要があるため、ストレージ バッファです。このため、GPU バッファ使用フラグにはすべて GPUBufferUsage.STORAGE が含まれています。結果行列の使用フラグにも GPUBufferUsage.COPY_SRC があります。これは、すべての GPU キューコマンドが実行された後、読み取りのために別のバッファにコピーされるためです。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
バインド グループ レイアウトとバインド グループ
バインド グループ レイアウトとバインド グループのコンセプトは WebGPU に固有のものです。バインド グループ レイアウトは、シェーダーが想定する入出力インターフェースを定義します。一方、バインド グループは、シェーダーの実際の入出力データを表します。
次の例では、バインド グループ レイアウトは、番号付きエントリ バインディング 0、1 に 2 つの読み取り専用ストレージ バッファを、コンピューティング シェーダー用に 2 に 1 つのストレージ バッファを想定しています。一方、このバインド グループ レイアウト用に定義されたバインド グループは、GPU バッファをエントリに関連付けます。gpuBufferFirstMatrix をバインディング 0 に、gpuBufferSecondMatrix をバインディング 1 に、resultMatrixBuffer をバインディング 2 に関連付けます。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
コンピューティング シェーダー コード
行列を乗算するコンピューティング シェーダー コードは、WebGPU シェーダー言語である WGSL で記述されており、SPIR-V に簡単に変換できます。詳細には触れませんが、var<storage> で識別される 3 つのストレージ バッファを以下に示します。プログラムは、入力として firstMatrix と secondMatrix を使用し、出力として resultMatrix を使用します。
各ストレージ バッファには、上記のバインド グループ レイアウトとバインド グループで定義された同じインデックスに対応する binding デコレーションが使用されています。
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
パイプラインの設定
コンピューティング パイプラインは、実行するコンピューティング オペレーションを実際に記述するオブジェクトです。device.createComputePipeline() を呼び出して作成します。この関数は、前に作成したバインド グループ レイアウトと、コンピューティング シェーダーのエントリ ポイント(main WGSL 関数)と device.createShaderModule() で作成された実際のコンピューティング シェーダー モジュールを定義するコンピューティング ステージの 2 つの引数を取ります。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
コマンドの送信
3 つの GPU バッファとバインド グループ レイアウトを含むコンピューティング パイプラインでバインド グループをインスタンス化したら、それらを使用します。
commandEncoder.beginComputePass() を使用して、プログラマブル コンピューティング パス エンコーダを開始しましょう。これを使用して、行列乗算を実行する GPU コマンドをエンコードします。passEncoder.setPipeline(computePipeline) でパイプラインを設定し、passEncoder.setBindGroup(0, bindGroup) でインデックス 0 のバインド グループを設定します。インデックス 0 は、WGSL コードの group(0) デコレーションに対応します。
次に、このコンピューティング シェーダーが GPU でどのように実行されるかについて説明します。このプログラムを結果行列の各セルに対して並列でステップごとに実行することが目標です。たとえば、16×32 の結果行列の場合、実行コマンドをエンコードするには、@workgroup_size(8, 8) で passEncoder.dispatchWorkgroups(2, 4) または passEncoder.dispatchWorkgroups(16 / 8, 32 / 8) を呼び出します。最初の引数「x」は最初のディメンション、2 番目の引数「y」は 2 番目のディメンション、最後の引数「z」は 3 番目のディメンションです。ここでは必要ないため、デフォルトの 1 に設定されています。GPU コンピューティングの世界では、一連のデータに対してカーネル関数を実行するコマンドをエンコードすることをディスパッチと呼びます。
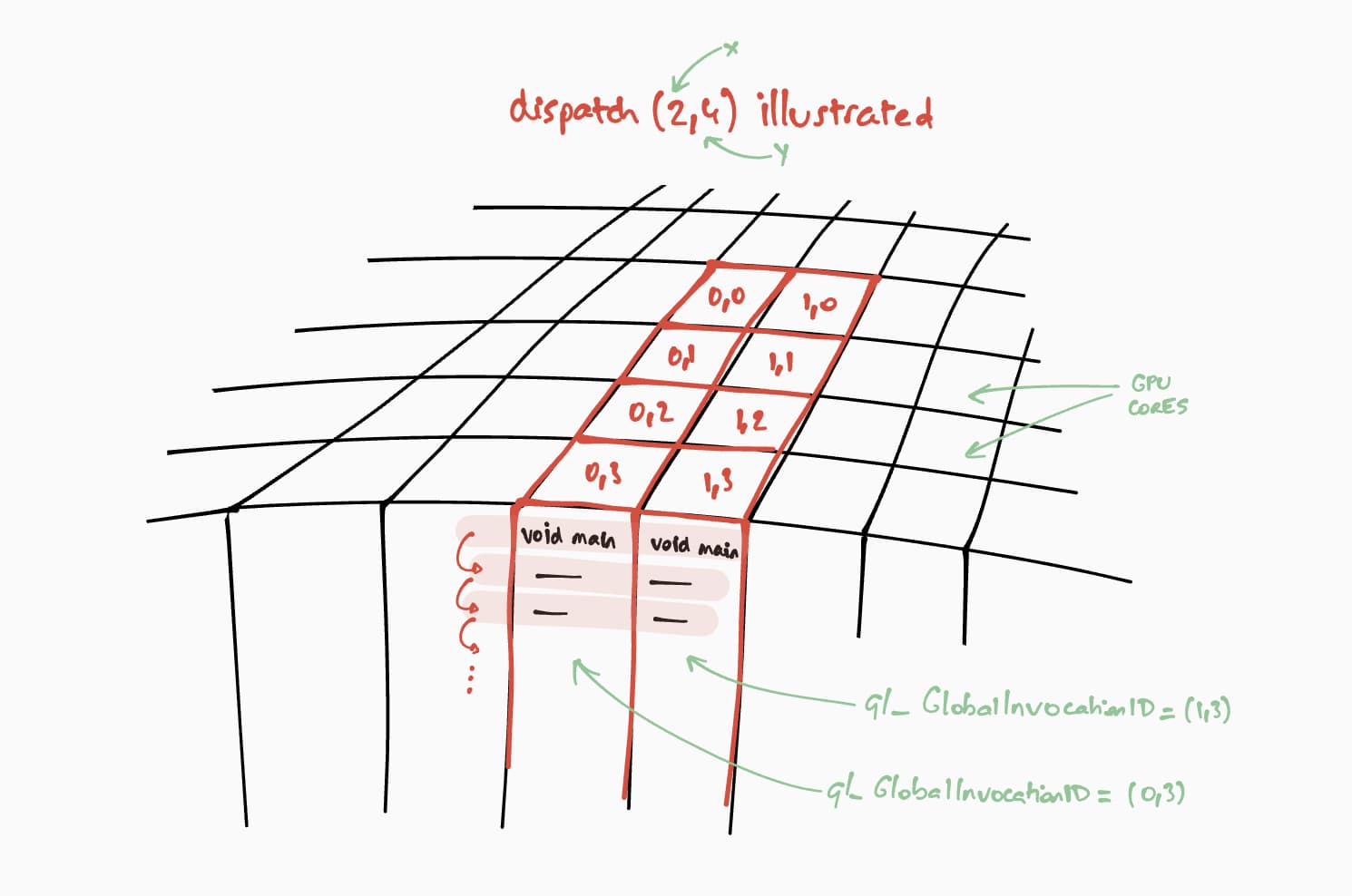
コンピューティング シェーダーのワークグループ グリッドのサイズは、WGSL コードでは (8, 8) です。そのため、それぞれ最初の行列の行数と 2 番目の行列の列数である「x」と「y」は 8 で除算されます。これで、passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) を使用してコンピューティング呼び出しをディスパッチできるようになりました。実行するワークグループ グリッドの数は dispatchWorkgroups() 引数です。
上の図のように、各シェーダーは、計算する結果マトリックスのセルを特定するために使用される一意の builtin(global_invocation_id) オブジェクトにアクセスします。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
コンピュート パス エンコーダを終了するには、passEncoder.end() を呼び出します。次に、copyBufferToBuffer で結果行列バッファをコピーする宛先として使用する GPU バッファを作成します。最後に、copyEncoder.finish() でエンコード コマンドを終了し、GPU コマンドで device.queue.submit() を呼び出して、それらを GPU デバイスキューに送信します。
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
結果マトリックスを読み取る
結果行列の読み取りは、GPUMapMode.READ で gpuReadBuffer.mapAsync() を呼び出し、返された Promise が解決されるのを待つだけで簡単です。これは、GPU バッファがマッピングされたことを示します。この時点で、gpuReadBuffer.getMappedRange() を使用してマッピングされた範囲を取得できます。
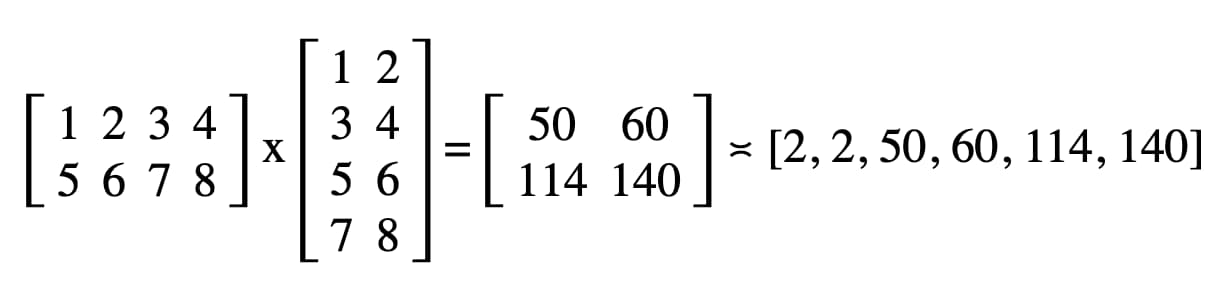
このコードでは、DevTools の JavaScript コンソールに「2, 2, 50, 60, 114, 140」という結果が記録されます。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
おめでとうございます!お疲れさまでした。サンプルを試すことができます。
最後のトリック
コードを読みやすくする方法の 1 つは、コンピューティング パイプラインの便利な getBindGroupLayout メソッドを使用して、シェーダー モジュールからバインド グループ レイアウトを推測することです。この方法では、カスタム バインド グループ レイアウトを作成して、コンピューティング パイプラインでパイプライン レイアウトを指定する必要がなくなります。
前のサンプルの getBindGroupLayout の図はこちらでご覧いただけます。
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
パフォーマンスの検出結果
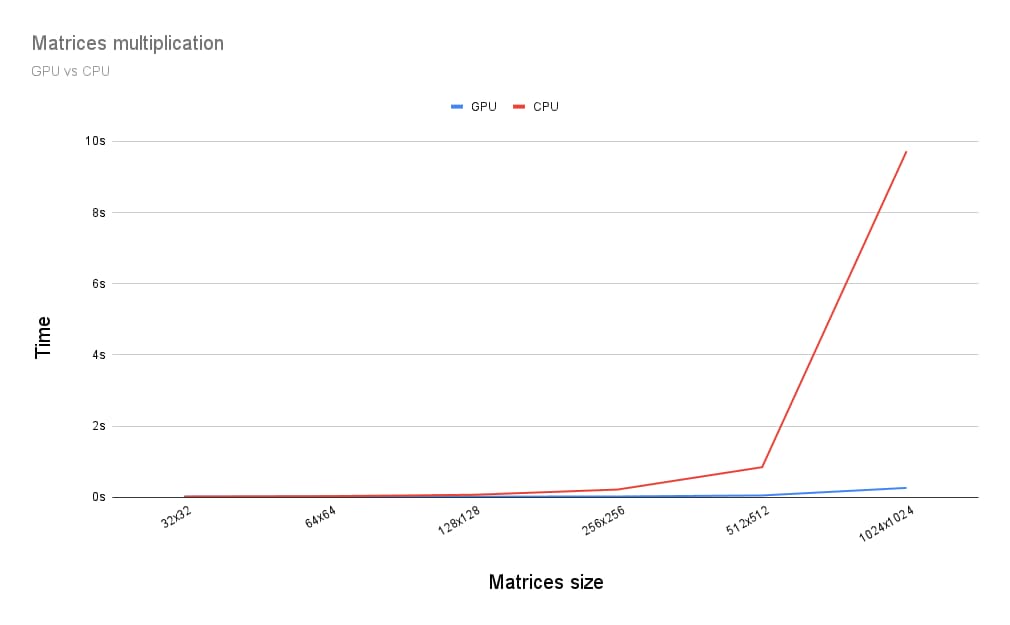
GPU で行列乗算を実行する場合と CPU で実行する場合を比較してみましょう。そこで、CPU 向けに前述のプログラムを作成しました。下のグラフに示すように、行列のサイズが 256×256 を超える場合は、GPU のフルパワーを使用するのが明らかに有利です。
この記事は、WebGPU の探索の旅の始まりにすぎません。GPU コンピューティングの詳細や、WebGPU でのレンダリング(キャンバス、テクスチャ、サンプラー)の仕組みについて、近日中にさらに詳しい記事を公開する予定です。