
Bu yayında, deneysel WebGPU API örneklerle açıklanmakta ve GPU kullanarak veri paralel hesaplamalar yapmaya başlamanıza yardımcı olunmaktadır.

Yayınlanma tarihi: 28 Ağustos 2019, Son güncelleme tarihi: 12 Ağustos 2025
Arka plan
Grafik İşleme Birimi'nin (GPU) başlangıçta grafik işleme konusunda uzmanlaşmış bir bilgisayar alt sistemi olduğunu biliyor olabilirsiniz. Ancak son 10 yılda, GPU'nun benzersiz mimarisinden yararlanırken geliştiricilerin yalnızca 3D grafik oluşturmakla kalmayıp birçok algoritma türünü uygulamasına olanak tanıyan daha esnek bir mimariye doğru evrildi. Bu özelliklere GPU İşlemi denir ve genel amaçlı bilimsel işlem için GPU'yu yardımcı işlemci olarak kullanmaya genel amaçlı GPU (GPGPU) programlama adı verilir.
Evrişimli sinir ağları ve diğer modeller, GPU'larda daha verimli çalışmak için mimariden yararlanabildiğinden GPU Compute, son dönemdeki makine öğrenimi patlamasına önemli ölçüde katkıda bulunmuştur. Mevcut Web Platformu'nda GPU bilgi işlem özellikleri eksik olduğundan W3C'nin "Web için GPU" topluluk grubu, güncel cihazların çoğunda bulunan modern GPU API'lerini kullanıma sunmak için bir API tasarlıyor. Bu API'nin adı WebGPU'dur.
WebGPU, WebGL gibi düşük seviyeli bir API'dir. Gördüğünüz gibi, bu model çok güçlü ve oldukça ayrıntılı. Ancak bu durum sorun teşkil etmez. Aradığımız şey performanstır.
Bu makalede, WebGPU'nun GPU Compute kısmına odaklanacağım ve dürüst olmak gerekirse, kendi başınıza oynamaya başlayabilmeniz için sadece yüzeyi çiziyorum. İlerleyen makalelerde WebGPU oluşturma (tuval, doku vb.) konusunu daha ayrıntılı bir şekilde ele alacağım.
GPU'ya erişme
WebGPU'da GPU'ya erişmek kolaydır. navigator.gpu.requestAdapter()
çağrısı, bir GPU bağdaştırıcısıyla eşzamansız olarak çözümlenecek bir JavaScript sözü döndürür. Bu adaptörü grafik kartı olarak düşünebilirsiniz. Entegre (CPU ile aynı çip üzerinde) veya ayrı (genellikle daha yüksek performanslı ancak daha fazla güç kullanan bir PCIe kartı) olabilir.
GPU bağdaştırıcınız olduğunda, bazı GPU hesaplamaları yapmak için kullanacağınız bir GPU cihazıyla çözülecek bir söz almak üzere adapter.requestDevice() işlevini çağırın.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Her iki işlev de istediğiniz adaptör (güç tercihi) ve cihaz (uzantılar, sınırlar) türü hakkında ayrıntılı bilgi vermenize olanak tanıyan seçenekler sunar. Basitlik adına bu makalede varsayılan seçenekleri kullanacağız.
Yazma arabellek belleği
GPU için belleğe veri yazmak üzere JavaScript'i nasıl kullanacağımızı görelim. Modern web tarayıcılarında kullanılan korumalı alan modeli nedeniyle bu işlem kolay değildir.
Aşağıdaki örnekte, GPU'dan erişilebilen arabellek belleğine dört baytın nasıl yazılacağı gösterilmektedir. Bu işlev, arabelleğin boyutunu ve kullanımını alan device.createBuffer() işlevini çağırır. Bu özel çağrı için kullanım işareti GPUBufferUsage.MAP_WRITE gerekli olmasa da bu arabelleğe yazmak istediğimizi açıkça belirtelim. Bu, oluşturma sırasında mappedAtCreation değeri doğru olarak ayarlandığı için eşlenen bir GPU arabellek nesnesiyle sonuçlanır. Ardından, ilişkili ham ikili veri arabelleği, GPU arabelleği yöntemi getMappedRange() çağrılarak alınabilir.
ArrayBuffer ile daha önce çalıştıysanız bayt yazma konusunda deneyimlisinizdir. TypedArray kullanın ve değerleri içine kopyalayın.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
Bu noktada, GPU arabelleği eşlenir. Yani, CPU'ya aittir ve JavaScript'ten okuma/yazma erişimi vardır. GPU'nun erişebilmesi için bu arabelleğin eşlemesinin kaldırılması gerekir. Bu işlem, gpuBuffer.unmap() işlevini çağırmak kadar basittir.
GPU ve CPU'nun aynı anda belleğe eriştiği yarış durumlarını önlemek için eşlenmiş/eşlenmemiş kavramı gereklidir.
Arabellek belleğini okuma
Şimdi de bir GPU arabelleğini başka bir GPU arabelleğine kopyalama ve geri okuma işlemlerinin nasıl yapılacağını inceleyelim.
İlk GPU arabelleğine yazdığımız ve bunu ikinci bir GPU arabelleğine kopyalamak istediğimiz için yeni bir kullanım işareti GPUBufferUsage.COPY_SRC gerekir. İkinci GPU arabelleği, bu kez device.createBuffer() ile eşlenmemiş durumda oluşturulur. İlk GPU arabelleğinin hedefi olarak kullanılacağından ve GPU kopyalama komutları yürütüldükten sonra JavaScript'te okunacağından kullanım işareti GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ'dır.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
GPU bağımsız bir yardımcı işlemci olduğundan tüm GPU komutları eşzamansız olarak yürütülür. Bu nedenle, gerektiğinde toplu olarak gönderilen bir GPU komutları listesi oluşturulur. WebGPU'da, device.createCommandEncoder() tarafından döndürülen GPU komut kodlayıcı, bir noktada GPU'ya gönderilecek "arabelleğe alınmış" komutlar grubu oluşturan JavaScript nesnesidir. Öte yandan, GPUBuffer üzerindeki yöntemler "arabelleğe alınmamış" yöntemlerdir. Yani, çağrıldıkları anda atomik olarak yürütülürler.
GPU komut kodlayıcıyı aldıktan sonra, bu komutu daha sonra yürütülmek üzere komut sırasına eklemek için aşağıda gösterildiği gibi copyEncoder.copyBufferToBuffer() çağrısı yapın.
Son olarak, copyEncoder.finish() çağırarak kodlama komutlarını tamamlayın ve bunları GPU cihazı komut sırasına gönderin. Kuyruk, device.queue.submit() aracılığıyla gönderilen ve GPU komutlarının bağımsız değişken olarak kullanıldığı gönderimleri işlemekten sorumludur.
Bu işlem, dizide depolanan tüm komutları sırayla atomik olarak yürütür.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
Bu noktada, GPU kuyruğu komutları gönderilmiştir ancak yürütülmemiş olabilir.
İkinci GPU arabelleğini okumak için gpuReadBuffer.mapAsync() işlevini GPUMapMode.READ ile çağırın. GPU arabelleği eşlendiğinde çözümlenecek bir söz döndürür. Ardından, sıraya alınmış tüm GPU komutları yürütüldükten sonra ilk GPU arabelleğiyle aynı değerleri içeren gpuReadBuffer.getMappedRange() ile eşlenmiş aralığı alın.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Özetle, arabellek belleği işlemleriyle ilgili hatırlamanız gerekenler şunlardır:
- GPU arabelleklerinin, cihaz kuyruğu gönderiminde kullanılabilmesi için eşlenmemiş olması gerekir.
- GPU arabellekleri eşlendiğinde JavaScript'te okunabilir ve yazılabilir.
mapAsync()vecreateBuffer()ilemappedAtCreationdoğru olarak ayarlandığında GPU arabellekleri eşlenir.
Gölgelendirici programlama
Yalnızca hesaplama yapan (ve üçgen çizmeyen) GPU'da çalışan programlara hesaplama gölgelendiricileri denir. Verileri işlemek için birlikte çalışan yüzlerce GPU çekirdeği (CPU çekirdeklerinden daha küçüktür) tarafından paralel olarak yürütülürler. Giriş ve çıkışları WebGPU'da arabelleklerdir.
WebGPU'da Compute Shader'ların kullanımını göstermek için, aşağıda gösterilen makine öğreniminde yaygın bir algoritma olan matris çarpımıyla oynayacağız.
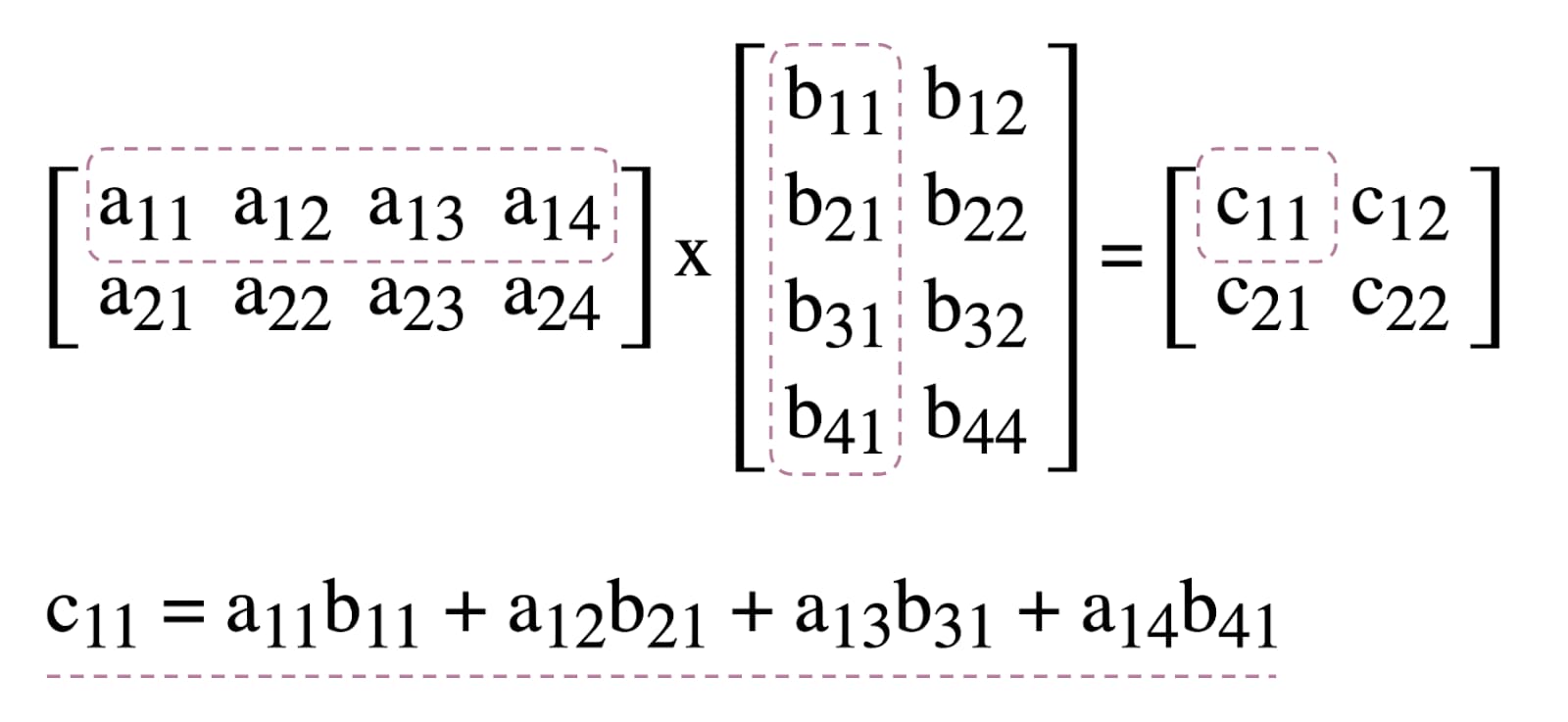
Özetle, yapacaklarımız:
- Üç GPU arabelleği oluşturun (ikisi çarpılacak matrisler, biri de sonuç matrisi için)
- Bilgi işlem gölgelendiricisi için giriş ve çıkışı açıklayın
- Compute shader kodunu derleyin.
- İşlem ardışık düzeni oluşturma
- Kodlanmış komutları GPU'ya toplu olarak gönderme
- Sonuç matrisi GPU arabelleğini okuma
GPU arabellekleri oluşturma
Basitlik adına matrisler, kayan noktalı sayıların listesi olarak gösterilir. İlk öğe satır sayısı, ikinci öğe sütun sayısı, geri kalanı ise matrisin gerçek sayılarından oluşur.

Üç GPU arabelleği, bilgi işlem gölgelendiricisinde verileri depolamamız ve almamız gerektiğinden depolama arabellekleridir. Bu nedenle, GPU arabellek kullanım işaretlerinin tümünde GPUBufferUsage.STORAGE bulunur. Sonuç matrisi kullanım işaretinde de GPUBufferUsage.COPY_SRC vardır. Bunun nedeni, tüm GPU kuyruğu komutları yürütüldükten sonra okunmak üzere başka bir arabelleğe kopyalanacak olmasıdır.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Bağlama grubu düzeni ve bağlama grubu
Bağlama grubu düzeni ve bağlama grubu kavramları WebGPU'ya özgüdür. Bir bağlama grubu düzeni, bir gölgelendiricinin beklediği giriş/çıkış arayüzünü tanımlarken bir bağlama grubu, bir gölgelendiricinin gerçek giriş/çıkış verilerini temsil eder.
Aşağıdaki örnekte, bağlama grubu düzeni, 0, 1 numaralı giriş bağlamalarında iki salt okunur depolama arabelleği ve bilgi işlem gölgelendiricisi için 2 konumunda bir depolama arabelleği bekliyor.
Diğer tarafta, bu bağlama grubu düzeni için tanımlanan bağlama grubu, GPU arabelleklerini girişlerle ilişkilendirir: gpuBufferFirstMatrix ile bağlama 0, gpuBufferSecondMatrix ile bağlama 1 ve resultMatrixBuffer ile bağlama 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
Compute shader kodu
Matrisleri çarpma için kullanılan Compute Shader kodu, WGSL (WebGPU Shader Language) ile yazılmıştır. Bu dil, SPIR-V'ye kolayca çevrilebilir. Ayrıntıya girmeden, var<storage> ile tanımlanan üç depolama arabelleğini aşağıda bulabilirsiniz. Program, giriş olarak firstMatrix ve secondMatrix'yi, çıkış olarak ise resultMatrix'yi kullanır.
Her depolama arabelleğinde, yukarıda belirtilen bağlama grubu düzenlerinde ve bağlama gruplarında tanımlanan aynı indekse karşılık gelen bir binding dekorasyonu kullanıldığını unutmayın.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Ardışık düzen kurulumu
İşlem hattı, gerçekleştireceğimiz işlem operasyonunu açıklayan nesnedir. device.createComputePipeline() numarasını arayarak oluşturun.
İki bağımsız değişken alır: daha önce oluşturduğumuz bağlama grubu düzeni ve bilgi işlem gölgelendiricimizin giriş noktasını (main WGSL işlevi) ve device.createShaderModule() ile oluşturulan gerçek bilgi işlem gölgelendirici modülünü tanımlayan bir bilgi işlem aşaması.
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
Komut gönderme
Üç GPU arabelleğimiz ve bir bağlama grubu düzenine sahip bir işlem hattı ile bir bağlama grubu oluşturduktan sonra bunları kullanabilirsiniz.
commandEncoder.beginComputePass() ile programlanabilir bir bilgi işlem geçişi kodlayıcısı başlatalım. Bu, matris çarpımını gerçekleştirecek GPU komutlarını kodlamak için kullanılır. passEncoder.setPipeline(computePipeline) ile işlem hattını ve passEncoder.setBindGroup(0, bindGroup) ile 0 dizinindeki bağlama grubunu ayarlayın. 0 dizini, WGSL kodundaki
group(0) süslemesine karşılık gelir.
Şimdi bu işlem gölgelendiricinin GPU'da nasıl çalışacağından bahsedelim. Amacımız, bu programı sonuç matrisinin her hücresi için adım adım paralel olarak yürütmektir. Örneğin, 16 x 32 boyutlu bir sonuç matrisi için yürütme komutunu @workgroup_size(8, 8) üzerinde kodlamak üzere passEncoder.dispatchWorkgroups(2, 4) veya passEncoder.dispatchWorkgroups(16 / 8, 32 / 8) çağrısını yaparız.
İlk bağımsız değişken "x" ilk boyutu, ikinci bağımsız değişken "y" ikinci boyutu ve son bağımsız değişken "z" üçüncü boyutu ifade eder. Burada ihtiyacımız olmadığı için varsayılan olarak 1'dir.
GPU hesaplama dünyasında, bir dizi veride çekirdek işlevini yürütmek için bir komutun kodlanmasına gönderme adı verilir.
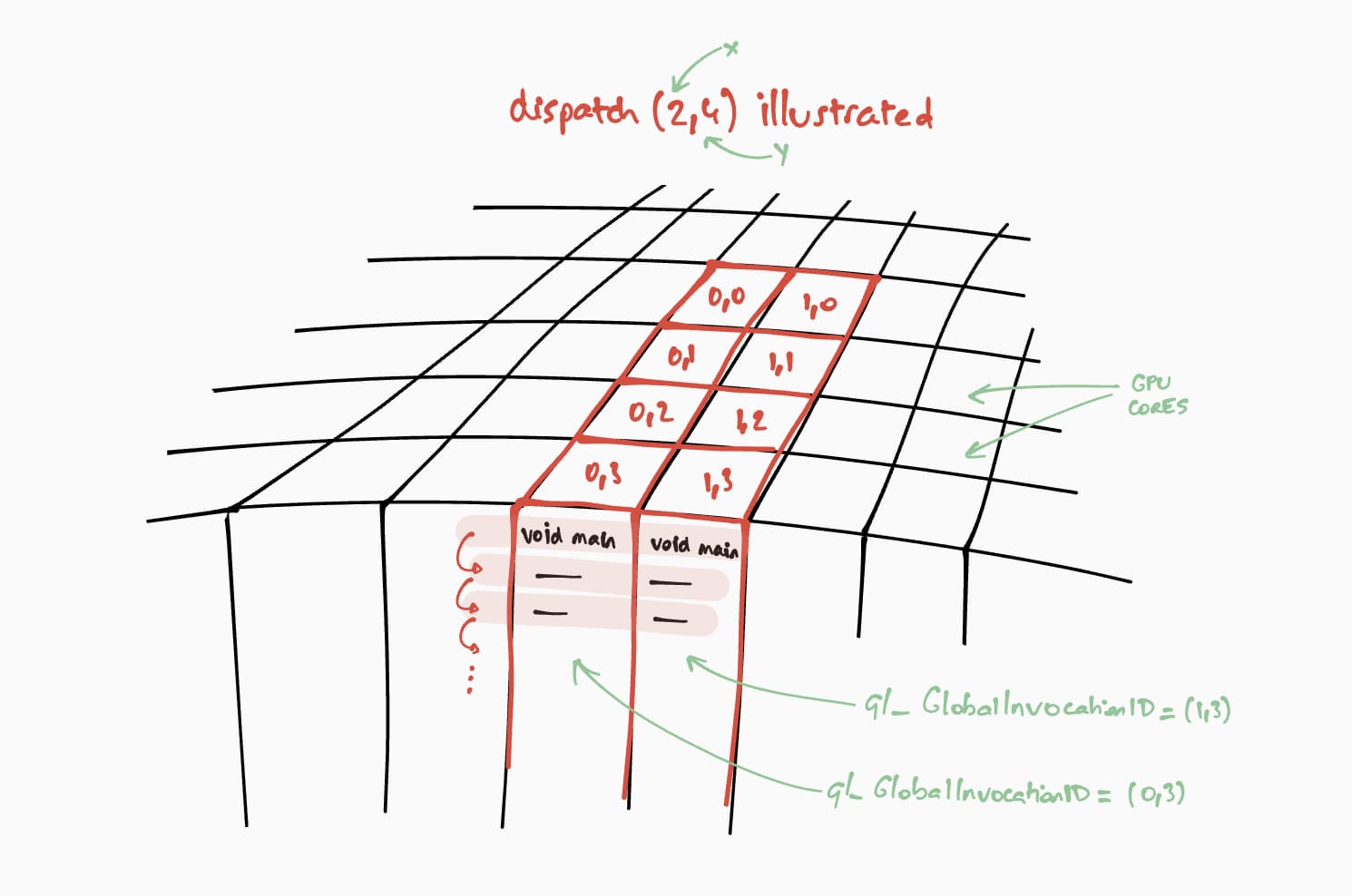
WGSL kodumuzda, hesaplama gölgelendiricimiz için iş grubu ızgarasının boyutu (8, 8)'dır. Bu nedenle, sırasıyla ilk matrisin satır sayısı ve ikinci matrisin sütun sayısı olan "x" ve "y" 8'e bölünür. Bununla birlikte, artık passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) ile bir hesaplama çağrısı gönderebiliriz. Çalıştırılacak çalışma grubu ızgaralarının sayısı dispatchWorkgroups() bağımsız değişkenleridir.
Yukarıdaki çizimde görüldüğü gibi, her gölgelendirici, hangi sonuç matrisi hücresinin hesaplanacağını bilmek için kullanılacak benzersiz bir builtin(global_invocation_id) nesnesine erişebilir.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
İşlem geçişi kodlayıcıyı sonlandırmak için passEncoder.end() işlevini çağırın. Ardından, sonuç matrisi arabelleğini copyBufferToBuffer ile kopyalamak için hedef olarak kullanılacak bir GPU arabelleği oluşturun. Son olarak, kodlama komutlarını copyEncoder.finish() ile tamamlayın ve GPU komutlarıyla device.queue.submit() çağrısı yaparak bunları GPU cihaz kuyruğuna gönderin.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Sonuç matrisini okuma
Sonuç matrisini okumak, gpuReadBuffer.mapAsync() işlevini GPUMapMode.READ ile çağırmak ve döndürülen sözün çözülmesini beklemek kadar kolaydır. Bu, GPU arabelleğinin artık eşlendiğini gösterir. Bu noktada, gpuReadBuffer.getMappedRange() ile eşlenmiş aralığı almak mümkündür.
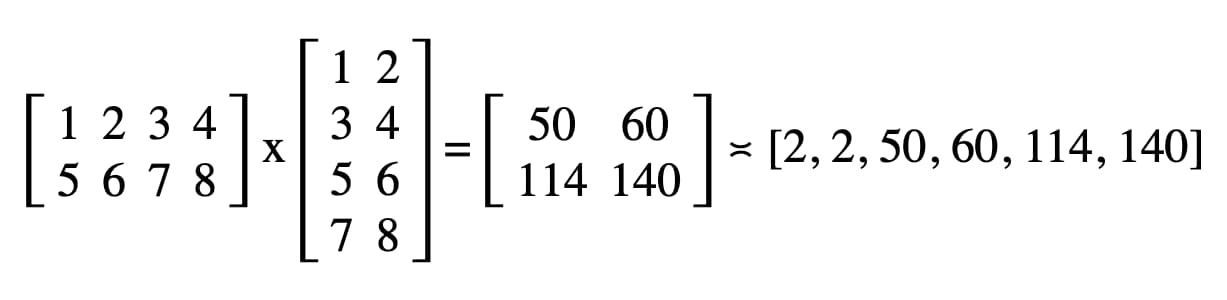
Kodumuzda, DevTools JavaScript konsoluna kaydedilen sonuç "2, 2, 50, 60, 114, 140" şeklindedir.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Tebrikler! Ba. Örnekle oynayabilirsiniz.
Son bir numara
Kodunuzun okunmasını kolaylaştırmanın bir yolu, bağlama grubu düzenini gölgelendirici modülünden çıkarmak için hesaplama işlem hattının kullanışlı getBindGroupLayout yöntemini kullanmaktır. Bu yöntem, aşağıda görebileceğiniz gibi, özel bir bağlama grubu düzeni oluşturma ve işlem hattı düzenini işlem hattınızda belirtme ihtiyacını ortadan kaldırır.
Önceki örnek için getBindGroupLayout görseli mevcuttur.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Performans bulguları
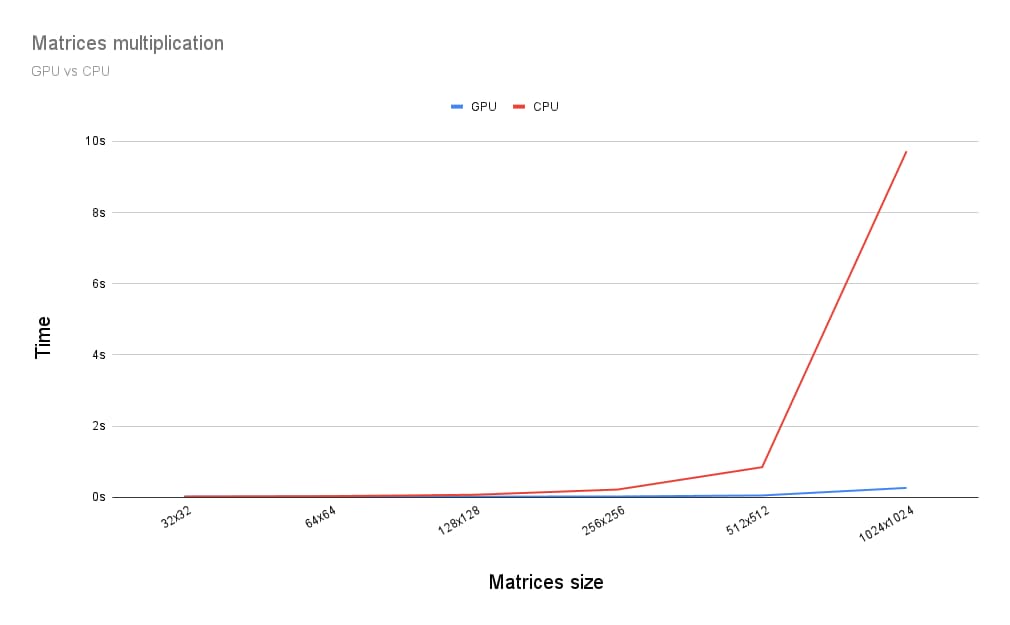
Peki, matris çarpımını GPU'da çalıştırmak ile CPU'da çalıştırmak arasında nasıl bir fark var? Bunu öğrenmek için, az önce açıklanan programı bir CPU için yazdım. Aşağıdaki grafikte de görebileceğiniz gibi, matrislerin boyutu 256 x 256'dan büyük olduğunda GPU'nun tüm gücünü kullanmak açık bir seçim gibi görünüyor.
Bu makale, WebGPU'yu keşfetme yolculuğumun sadece başlangıcıydı. Yakında GPU Compute ve WebGPU'da oluşturma (tuval, doku, örnekleyici) işleminin nasıl çalıştığına dair daha ayrıntılı bilgilerin yer aldığı makaleler yayınlayacağız.