
本文将通过示例探索实验性 WebGPU API,帮助您开始使用 GPU 执行数据并行计算。

发布日期:2019 年 8 月 28 日,上次更新日期:2025 年 8 月 12 日
背景
您可能已经知道,图形处理单元 (GPU) 是计算机中的一个电子子系统,最初专门用于处理图形。不过,在过去 10 年中,它已发展为更灵活的架构,让开发者能够实现多种类型的算法,而不仅仅是渲染 3D 图形,同时还能充分利用 GPU 的独特架构。这些功能称为 GPU 计算,而将 GPU 用作通用科学计算的协处理器称为通用 GPU (GPGPU) 编程。
GPU 计算对近期的机器学习热潮做出了巨大贡献,因为卷积神经网络和其他模型可以利用该架构在 GPU 上更高效地运行。由于当前的 Web 平台缺乏 GPU 计算功能,W3C 的“GPU for the Web”社区组正在设计一个 API,以公开大多数当前设备上可用的现代 GPU API。此 API 称为 WebGPU。
WebGPU 是一种低级 API,与 WebGL 类似。如您所见,它非常强大,但也很冗长。不过没关系。我们追求的是性能。
在本文中,我将重点介绍 WebGPU 的 GPU 计算部分,但说实话,我只是浅尝辄止,以便您自行开始探索。在后续文章中,我将深入探讨并介绍 WebGPU 渲染(画布、纹理等)。
访问 GPU
在 WebGPU 中,访问 GPU 非常简单。调用 navigator.gpu.requestAdapter() 会返回一个 JavaScript promise,该 promise 将异步解析为 GPU 适配器。您可以将此适配器视为显卡。它可以是集成式(与 CPU 在同一芯片上),也可以是独立式(通常是性能更高但耗电更多的 PCIe 卡)。
获得 GPU 适配器后,调用 adapter.requestDevice() 以获取一个 promise,该 promise 将解析为 GPU 设备,您将使用该设备执行一些 GPU 计算。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
这两个函数都接受选项,让您可以指定所需的适配器类型(电源偏好设置)和设备(扩展程序、限制)。为简单起见,本文将使用默认选项。
写入缓冲区内存
我们来看看如何使用 JavaScript 将数据写入 GPU 的内存。由于现代网络浏览器中使用的沙盒模型,此过程并不简单。
以下示例展示了如何将 4 个字节写入可从 GPU 访问的缓冲区内存。它会调用 device.createBuffer(),该函数会获取缓冲区的大小及其使用情况。即使此特定调用不需要使用情况标志 GPUBufferUsage.MAP_WRITE,我们也要明确表示要写入此缓冲区。由于 mappedAtCreation 设置为 true,因此在创建时会映射 GPU 缓冲区对象。然后,可以通过调用 GPU 缓冲区方法 getMappedRange() 来检索关联的原始二进制数据缓冲区。
如果您已经使用过 ArrayBuffer,那么写入字节应该很熟悉;使用 TypedArray 并将值复制到其中。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
此时,GPU 缓冲区已映射,这意味着它归 CPU 所有,并且可以通过 JavaScript 以读/写模式访问。为了让 GPU 可以访问它,必须取消映射它,这就像调用 gpuBuffer.unmap() 一样简单。
需要映射/取消映射的概念来防止 GPU 和 CPU 同时访问内存时出现竞态条件。
读取缓冲区内存
现在,我们来看看如何将一个 GPU 缓冲区复制到另一个 GPU 缓冲区并将其读回。
由于我们要写入第一个 GPU 缓冲区,并希望将其复制到第二个 GPU 缓冲区,因此需要新的使用标志 GPUBufferUsage.COPY_SRC。这次,第二个 GPU 缓冲区是在未映射状态下创建的,大小为 device.createBuffer()。其使用标志为 GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ,因为该缓冲区将用作第一个 GPU 缓冲区的目标,并且在执行 GPU 复制命令后在 JavaScript 中读取。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
由于 GPU 是一个独立的协处理器,因此所有 GPU 命令都是异步执行的。因此,系统会构建一个 GPU 命令列表,并在需要时分批发送。在 WebGPU 中,由 device.createCommandEncoder() 返回的 GPU 命令编码器是一个 JavaScript 对象,用于构建一批“缓冲”命令,这些命令将在某个时间点发送到 GPU。另一方面,GPUBuffer 上的方法是“无缓冲”的,这意味着它们在被调用时以原子方式执行。
获得 GPU 命令编码器后,请按如下所示调用 copyEncoder.copyBufferToBuffer(),将此命令添加到命令队列以供稍后执行。最后,通过调用 copyEncoder.finish() 完成编码命令,并将这些命令提交到 GPU 设备命令队列。该队列负责处理通过 device.queue.submit() 完成的提交,并将 GPU 命令作为实参。此方法会按顺序以原子方式执行数组中存储的所有命令。
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
此时,GPU 队列命令已发送,但不一定已执行。如需读取第二个 GPU 缓冲区,请使用 GPUMapMode.READ 调用 gpuReadBuffer.mapAsync()。它会返回一个在 GPU 缓冲区映射时解析的 promise。然后,在所有排队的 GPU 命令都已执行完毕后,获取包含与第一个 GPU 缓冲区相同值的映射范围 gpuReadBuffer.getMappedRange()。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
您可以试用此示例。
简而言之,以下是您需要记住的有关缓冲区内存操作的信息:
- GPU 缓冲区必须取消映射才能在设备队列提交中使用。
- 映射后,可以在 JavaScript 中读取和写入 GPU 缓冲区。
- 当调用
mapAsync()和createBuffer()且mappedAtCreation设置为 true 时,GPU 缓冲区会被映射。
着色器编程
在 GPU 上运行且仅执行计算(而不绘制三角形)的程序称为计算着色器。它们由数百个 GPU 核心(比 CPU 核心小)并行执行,这些核心协同工作来处理数据。它们的输入和输出是 WebGPU 中的缓冲区。
为了说明如何在 WebGPU 中使用计算着色器,我们将使用矩阵相乘(一种常见的机器学习算法,如下图所示)进行演示。
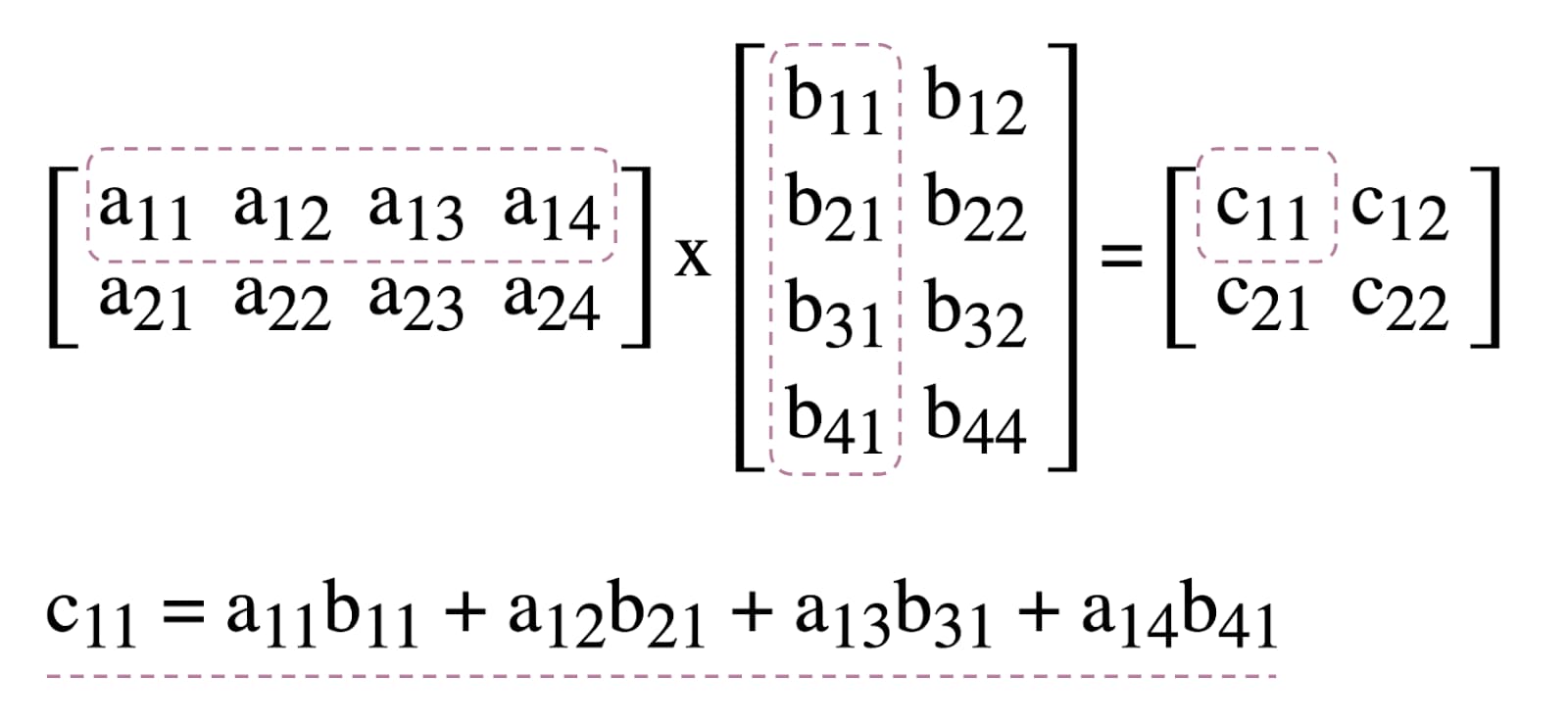
简而言之,我们将执行以下操作:
- 创建三个 GPU 缓冲区(两个用于要相乘的矩阵,一个用于结果矩阵)
- 描述计算着色器的输入和输出
- 编译计算着色器代码
- 设置计算流水线
- 以批处理方式向 GPU 提交编码后的命令
- 读取结果矩阵 GPU 缓冲区
GPU 缓冲区创建
为简单起见,矩阵将表示为浮点数列表。第一个元素是行数,第二个元素是列数,其余元素是矩阵的实际数字。

这三个 GPU 缓冲区都是存储缓冲区,因为我们需要在计算着色器中存储和检索数据。这说明了为什么所有 GPU 缓冲区的用法标志都包含 GPUBufferUsage.STORAGE。结果矩阵使用情况标志也具有 GPUBufferUsage.COPY_SRC,因为在所有 GPU 队列命令都已执行完毕后,它将被复制到另一个缓冲区以供读取。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
绑定组布局和绑定组
绑定组布局和绑定组的概念是 WebGPU 特有的。绑定组布局定义了着色器所需的输入/输出接口,而绑定组则表示着色器的实际输入/输出数据。
在下面的示例中,绑定组布局需要两个只读存储缓冲区(位于编号的条目绑定 0、1 处)和一个存储缓冲区(位于 2 处),以用于计算着色器。另一方面,为此绑定组布局定义的绑定组会将 GPU 缓冲区与条目相关联:gpuBufferFirstMatrix 与绑定 0 相关联,gpuBufferSecondMatrix 与绑定 1 相关联,resultMatrixBuffer 与绑定 2 相关联。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
计算着色器代码
用于矩阵相乘的计算着色器代码采用 WGSL(WebGPU 着色器语言)编写,可轻松转换为 SPIR-V。下面列出了三个用 var<storage> 标识的存储缓冲区,这里不再赘述。该程序将使用 firstMatrix 和 secondMatrix 作为输入,并使用 resultMatrix 作为输出。
请注意,每个存储缓冲区都具有一个 binding 装饰器,该装饰器与上述绑定组布局和声明的绑定组中定义的索引相同。
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
流水线设置
计算流水线是实际描述我们将要执行的计算操作的对象。通过调用 device.createComputePipeline() 创建该对象。
它接受两个实参:我们之前创建的绑定组布局,以及一个计算阶段,用于定义计算着色器的入口点(main WGSL 函数)和使用 device.createShaderModule() 创建的实际计算着色器模块。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
命令提交
使用三个 GPU 缓冲区和一个具有绑定组布局的计算流水线实例化绑定组后,就可以使用它们了。
我们先使用 commandEncoder.beginComputePass() 启动可编程计算通道编码器。我们将使用此功能对将执行矩阵乘法的 GPU 命令进行编码。使用 passEncoder.setPipeline(computePipeline) 设置其流水线,并使用 passEncoder.setBindGroup(0, bindGroup) 设置其索引 0 处的绑定组。索引 0 对应于 WGSL 代码中的 group(0) 装饰器。
现在,我们来谈谈此计算着色器将如何在 GPU 上运行。我们的目标是针对结果矩阵的每个单元格,逐步并行执行此程序。例如,对于大小为 16x32 的结果矩阵,为了在 @workgroup_size(8, 8) 上对执行命令进行编码,我们会调用 passEncoder.dispatchWorkgroups(2, 4) 或 passEncoder.dispatchWorkgroups(16 / 8, 32 / 8)。第一个实参“x”是第一个维度,第二个实参“y”是第二个维度,最后一个实参“z”是第三个维度,由于我们不需要它,因此默认值为 1。
在 GPU 计算领域,对命令进行编码以在一组数据上执行内核函数称为调度。
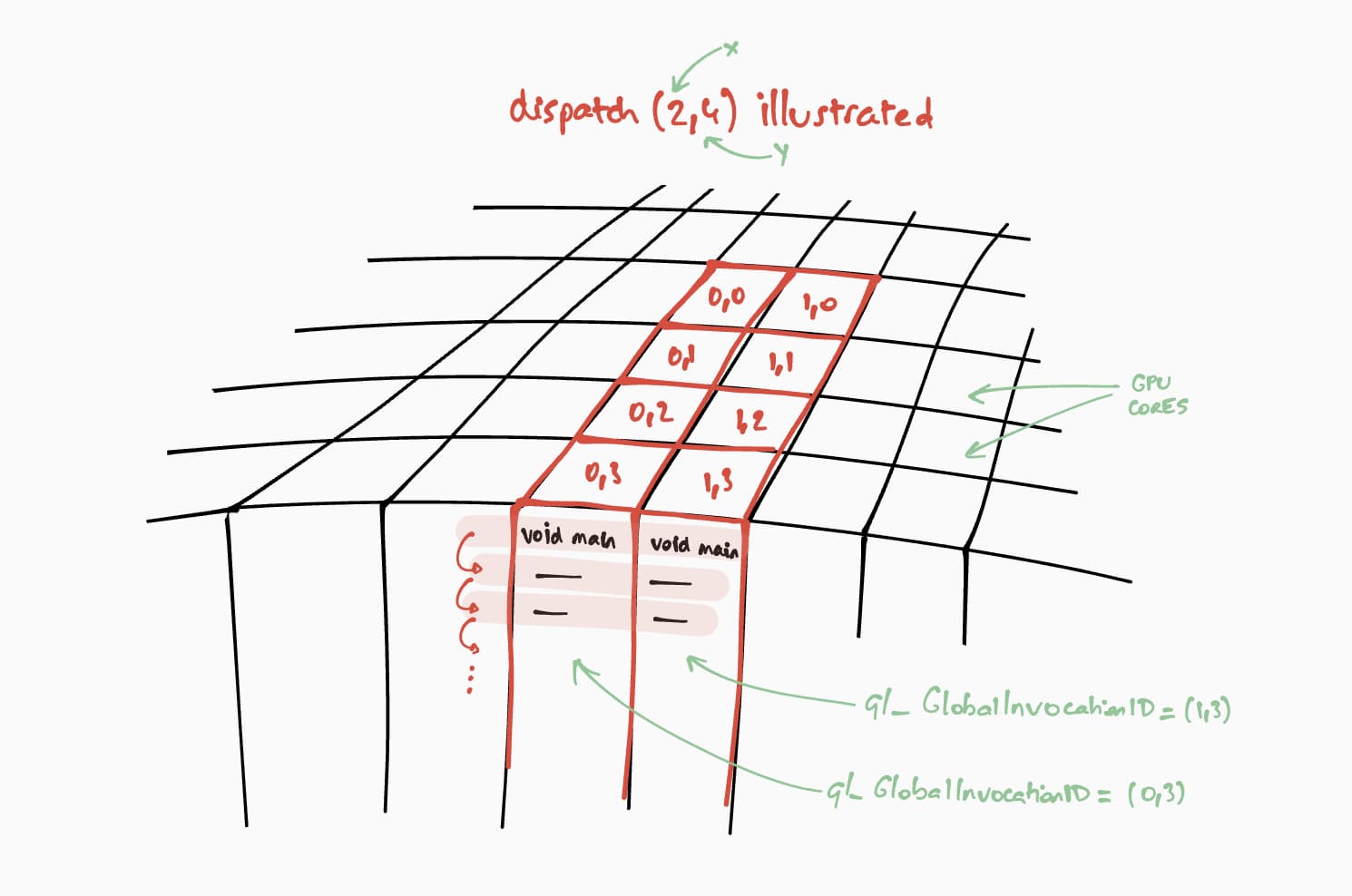
在我们的 WGSL 代码中,计算着色器的工作组网格大小为 (8, 8)。因此,第一个矩阵的行数“x”和第二个矩阵的列数“y”将除以 8。这样一来,我们现在就可以使用 passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) 调度计算调用了。要运行的工作组网格数量为 dispatchWorkgroups() 个实参。
如上图所示,每个着色器都将有权访问一个唯一的 builtin(global_invocation_id) 对象,该对象将用于确定要计算哪个结果矩阵单元格。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
如需结束计算传递编码器,请调用 passEncoder.end()。然后,创建一个 GPU 缓冲区,以用作使用 copyBufferToBuffer 复制结果矩阵缓冲区的目标。最后,使用 copyEncoder.finish() 完成编码命令,并通过调用 device.queue.submit() 并传入 GPU 命令,将这些命令提交到 GPU 设备队列。
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
读取结果矩阵
读取结果矩阵非常简单,只需使用 GPUMapMode.READ 调用 gpuReadBuffer.mapAsync(),然后等待返回的 promise 解析,这表示 GPU 缓冲区现在已映射。此时,可以使用 gpuReadBuffer.getMappedRange() 获取映射的范围。
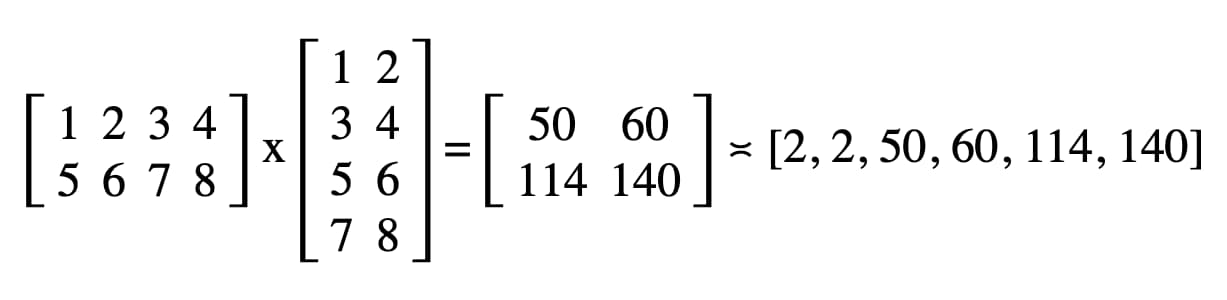
在我们的代码中,开发者工具 JavaScript 控制台中记录的结果为“2、2、50、60、114、140”。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
恭喜!您做到了。您可以试用该示例。
最后一个技巧
让代码更易于阅读的一种方法是使用计算流水线的便捷 getBindGroupLayout 方法从着色器模块推断绑定组布局。此技巧无需创建自定义绑定组布局并在计算流水线中指定流水线布局,如下所示。
如需查看上一个示例的 getBindGroupLayout 图示,请点击此处。
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
效果发现
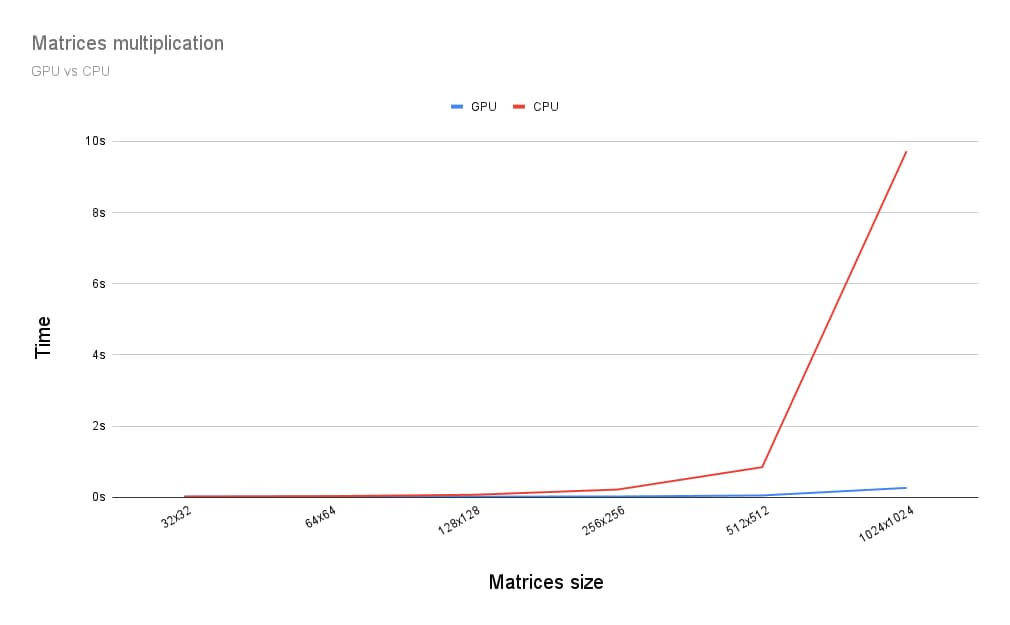
那么,在 GPU 上运行矩阵乘法与在 CPU 上运行矩阵乘法相比如何?为了找出答案,我编写了上述针对 CPU 的程序。从下图可以看出,当矩阵大小大于 256x256 时,充分利用 GPU 的强大功能似乎是显而易见的选择。
这篇文章只是我探索 WebGPU 的开始。敬请期待更多文章,深入了解 GPU 计算以及 WebGPU 中渲染(画布、纹理、采样器)的工作原理。