
Esta postagem explora a API WebGPU experimental com exemplos e ajuda você a começar a realizar cálculos paralelos de dados usando a GPU.

Publicação: 28 de agosto de 2019, Última atualização: 12 de agosto de 2025
Contexto
Como você já deve saber, a unidade de processamento gráfico (GPU) é um subsistema eletrônico em um computador que foi originalmente especializado no processamento de gráficos. No entanto, nos últimos 10 anos, ela evoluiu para uma arquitetura mais flexível, permitindo que os desenvolvedores implementem muitos tipos de algoritmos, não apenas renderizem gráficos 3D, aproveitando a arquitetura exclusiva da GPU. Esses recursos são chamados de computação de GPU, e o uso de uma GPU como um coprocessador para computação científica de uso geral é chamado de programação de GPU de uso geral (GPGPU).
A computação de GPU contribuiu significativamente para o recente boom do machine learning, já que as redes neurais convolucionais e outros modelos podem aproveitar a arquitetura para serem executados com mais eficiência nas GPUs. Como a plataforma da Web atual não tem recursos de computação de GPU, o grupo da comunidade "GPU para a Web" do W3C está projetando uma API para expor as APIs de GPU modernas disponíveis na maioria dos dispositivos atuais. Essa API é chamada de WebGPU.
A WebGPU é uma API de baixo nível, como a WebGL. Ele é muito poderoso e bastante detalhado, como você vai ver. Mas tudo bem. O que estamos procurando é desempenho.
Neste artigo, vou me concentrar na parte de computação de GPU do WebGPU e, para ser honesto, estou apenas começando, para que você possa começar a jogar por conta própria. Vou me aprofundar e abordar a renderização do WebGPU (canvas, textura etc.) em artigos futuros.
Acessar a GPU
Acessar a GPU é fácil na WebGPU. Chamar navigator.gpu.requestAdapter()
retorna uma promessa de JavaScript que será resolvida de forma assíncrona com um adaptador
de GPU. Pense nesse adaptador como a placa de vídeo. Ela pode ser integrada (no mesmo chip da CPU) ou discreta (geralmente um cartão PCIe mais eficiente, mas que usa mais energia).
Depois de ter o adaptador de GPU, chame adapter.requestDevice() para receber uma promessa
que será resolvida com um dispositivo de GPU que você usará para fazer alguns cálculos de GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Ambas as funções usam opções que permitem especificar o tipo de adaptador (preferência de energia) e dispositivo (extensões, limites) desejado. Para simplificar, vamos usar as opções padrão neste artigo.
Memória de buffer de gravação
Vamos ver como usar JavaScript para gravar dados na memória da GPU. Esse processo não é simples devido ao modelo de sandbox usado nos navegadores da Web modernos.
O exemplo abaixo mostra como gravar quatro bytes na memória do buffer acessível
pela GPU. Ele chama device.createBuffer(), que usa o tamanho do buffer e o uso dele. Embora a flag de uso GPUBufferUsage.MAP_WRITE não seja necessária para essa chamada específica, vamos deixar claro que queremos gravar nesse buffer. Isso resulta em um objeto de buffer de GPU mapeado na criação graças a
mappedAtCreation definido como "true". Em seguida, o buffer de dados binários brutos associado pode ser recuperado chamando o método de buffer da GPU getMappedRange().
Escrever bytes é familiar se você já trabalhou com ArrayBuffer. Use um
TypedArray e copie os valores para ele.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
Nesse ponto, o buffer da GPU é mapeado, ou seja, pertence à CPU e pode ser acessado para leitura/gravação em JavaScript. Para que a GPU possa acessar, ela
precisa ser desalocada, o que é tão simples quanto chamar gpuBuffer.unmap().
O conceito de mapeado/não mapeado é necessário para evitar condições de corrida em que a GPU e a CPU acessam a memória ao mesmo tempo.
Ler a memória do buffer
Agora vamos ver como copiar um buffer de GPU para outro e ler de volta.
Como estamos gravando no primeiro buffer de GPU e queremos copiá-lo para um segundo buffer de GPU, uma nova flag de uso GPUBufferUsage.COPY_SRC é necessária. O segundo buffer de GPU é criado em um estado não mapeado desta vez com device.createBuffer(). A flag de uso é GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ, já que será usada como destino do primeiro buffer de GPU e lida em JavaScript depois que os comandos de cópia da GPU forem executados.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Como a GPU é um coprocessador independente, todos os comandos são executados
de forma assíncrona. Por isso, há uma lista de comandos de GPU criada e enviada em lotes quando necessário. Na WebGPU, o codificador de comandos da GPU retornado por
device.createCommandEncoder()é o objeto JavaScript que cria um lote de
comandos "em buffer" que serão enviados à GPU em algum momento. Já os métodos em
GPUBuffer são "não armazenados em buffer", ou seja, são executados de maneira atômica
no momento em que são chamados.
Depois de ter o codificador de comandos da GPU, chame copyEncoder.copyBufferToBuffer()
conforme mostrado abaixo para adicionar esse comando à fila de comandos para execução posterior.
Por fim, termine de codificar os comandos chamando copyEncoder.finish() e envie
para a fila de comandos do dispositivo GPU. A fila é responsável por processar
envios feitos via device.queue.submit() com os comandos da GPU como argumentos.
Isso vai executar atomicamente todos os comandos armazenados na matriz em ordem.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
Neste ponto, os comandos da fila de GPU foram enviados, mas não necessariamente executados.
Para ler o segundo buffer de GPU, chame gpuReadBuffer.mapAsync() com
GPUMapMode.READ. Ela retorna uma promessa que será resolvida quando o buffer da GPU for mapeado. Em seguida, receba o intervalo mapeado com gpuReadBuffer.getMappedRange() que
contém os mesmos valores do primeiro buffer de GPU depois que todos os comandos de GPU enfileirados
forem executados.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Você pode testar este exemplo.
Em resumo, aqui está o que você precisa lembrar sobre operações de memória de buffer:
- Os buffers de GPU precisam ser desalocados para serem usados no envio de filas de dispositivos.
- Quando mapeados, os buffers da GPU podem ser lidos e gravados em JavaScript.
- Os buffers da GPU são mapeados quando
mapAsync()ecreateBuffer()commappedAtCreationdefinido como "true" são chamados.
Programação de sombreadores
Programas em execução na GPU que apenas realizam computações (e não desenham triângulos) são chamados de shaders de computação. Elas são executadas em paralelo por centenas de núcleos de GPU (que são menores que os núcleos de CPU) que operam juntos para processar dados. A entrada e a saída são buffers no WebGPU.
Para ilustrar o uso de sombreadores de computação em WebGPU, vamos trabalhar com a multiplicação de matrizes, um algoritmo comum em machine learning ilustrado abaixo.
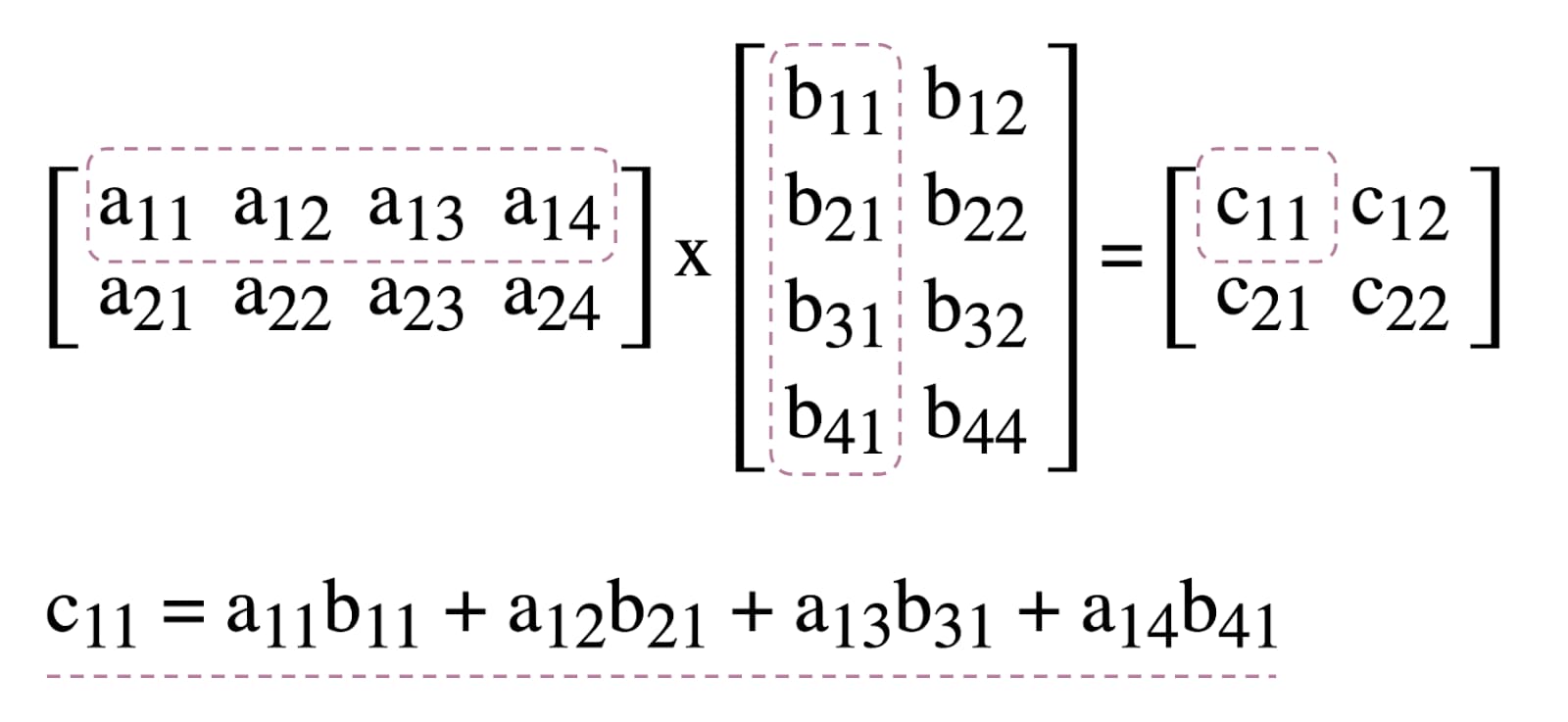
Resumindo, vamos fazer o seguinte:
- Crie três buffers de GPU (dois para as matrizes a serem multiplicadas e um para a matriz de resultado).
- Descrever a entrada e a saída do shader de computação
- Compilar o código do shader de computação
- Configurar um pipeline de computação
- Enviar em lote os comandos codificados para a GPU
- Ler o buffer da GPU da matriz de resultados
Criação de buffers de GPU
Para simplificar, as matrizes serão representadas como uma lista de números de ponto flutuante. O primeiro elemento é o número de linhas, o segundo é o número de colunas, e o restante são os números reais da matriz.

Os três buffers de GPU são buffers de armazenamento, já que precisamos armazenar e recuperar dados no shader de computação. Isso explica por que as flags de uso do buffer da GPU incluem
GPUBufferUsage.STORAGE para todas elas. A flag de uso da matriz de resultados também tem GPUBufferUsage.COPY_SRC porque será copiada para outro buffer para leitura depois que todos os comandos da fila da GPU forem executados.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Layout e grupo de vinculação
Os conceitos de layout e grupo de vinculação são específicos do WebGPU. Um layout de grupo de vinculação define a interface de entrada/saída esperada por um shader, enquanto um grupo de vinculação representa os dados de entrada/saída reais de um shader.
No exemplo abaixo, o layout do grupo de vinculação espera dois buffers de armazenamento somente leitura nas vinculações de entrada numeradas 0, 1 e um buffer de armazenamento em 2 para o shader de computação.
O grupo de vinculação, por outro lado, definido para esse layout, associa buffers de GPU às entradas: gpuBufferFirstMatrix à vinculação 0, gpuBufferSecondMatrix à vinculação 1 e resultMatrixBuffer à vinculação 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
Código do shader de computação
O código do sombreador de computação para multiplicar matrizes é escrito em WGSL, a
linguagem de sombreador WebGPU, que é facilmente traduzida para SPIR-V. Sem
entrar em detalhes, confira abaixo os três buffers de armazenamento identificados
com var<storage>. O programa vai usar firstMatrix e secondMatrix como entradas e resultMatrix como saída.
Cada buffer de armazenamento tem uma decoração binding usada que corresponde ao mesmo índice definido nos layouts e grupos de vinculação declarados acima.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Configuração do pipeline
O pipeline de computação é o objeto que descreve a operação de computação
que vamos realizar. Para criar, chame device.createComputePipeline().
Ele usa dois argumentos: o layout do grupo de vinculação que criamos antes e um estágio de computação que define o ponto de entrada do nosso shader de computação (a função main do WGSL) e o módulo de shader de computação real criado com device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
Envio de comandos
Depois de instanciar um grupo de vinculação com nossos três buffers de GPU e um pipeline de computação com um layout de grupo de vinculação, é hora de usá-los.
Vamos iniciar um codificador de transmissão de computação programável com
commandEncoder.beginComputePass(). Vamos usar isso para codificar comandos de GPU
que vão realizar a multiplicação de matrizes. Defina o pipeline com
passEncoder.setPipeline(computePipeline) e o grupo de vinculação no índice 0 com
passEncoder.setBindGroup(0, bindGroup). O índice 0 corresponde à
decoração group(0) no código WGSL.
Agora vamos falar sobre como esse shader de computação será executado na GPU. Nosso objetivo é executar esse programa em paralelo para cada célula da matriz de resultados, etapa por etapa. Por exemplo, para uma matriz de resultados de tamanho 16 por 32, para codificar
o comando de execução em um @workgroup_size(8, 8), chamaríamos
passEncoder.dispatchWorkgroups(2, 4) ou passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
O primeiro argumento "x" é a primeira dimensão, o segundo "y" é a segunda dimensão, e o último "z" é a terceira dimensão, que tem como padrão 1 porque não precisamos dela aqui.
No mundo da computação de GPU, codificar um comando para executar uma função de kernel em um conjunto de dados é chamado de envio.
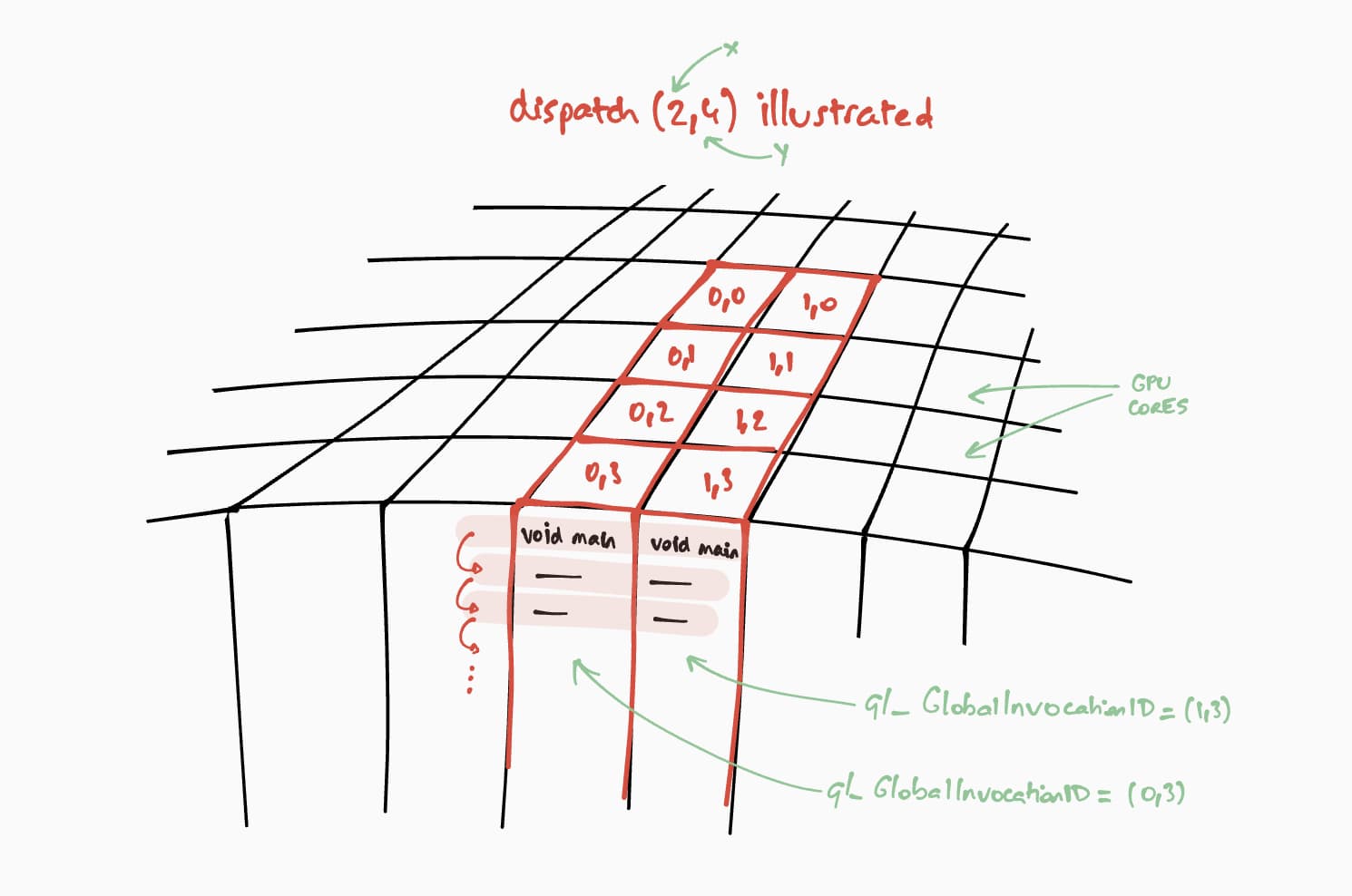
O tamanho da grade do grupo de trabalho para nosso shader de computação é (8, 8) no código
WGSL. Por isso, "x" e "y", que são respectivamente o número de linhas da primeira matriz e o número de colunas da segunda matriz, serão divididos por 8. Com isso, agora podemos enviar uma chamada de computação com
passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). O número de grades de grupo de trabalho a serem executadas são os argumentos dispatchWorkgroups().
Como mostrado no desenho acima, cada shader terá acesso a um objeto builtin(global_invocation_id) exclusivo que será usado para saber qual célula da matriz de resultados calcular.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Para encerrar o codificador de transmissão de computação, chame passEncoder.end(). Em seguida, crie um buffer de GPU para usar como destino e copie o buffer da matriz de resultados com copyBufferToBuffer. Por fim, termine de codificar os comandos com
copyEncoder.finish() e envie-os à fila de dispositivos da GPU chamando
device.queue.submit() com os comandos da GPU.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Ler matriz de resultados
Ler a matriz de resultados é tão fácil quanto chamar gpuReadBuffer.mapAsync() com GPUMapMode.READ e aguardar a resolução da promessa de retorno, o que indica que o buffer da GPU agora está mapeado. Nesse ponto, é possível receber o intervalo mapeado com gpuReadBuffer.getMappedRange().
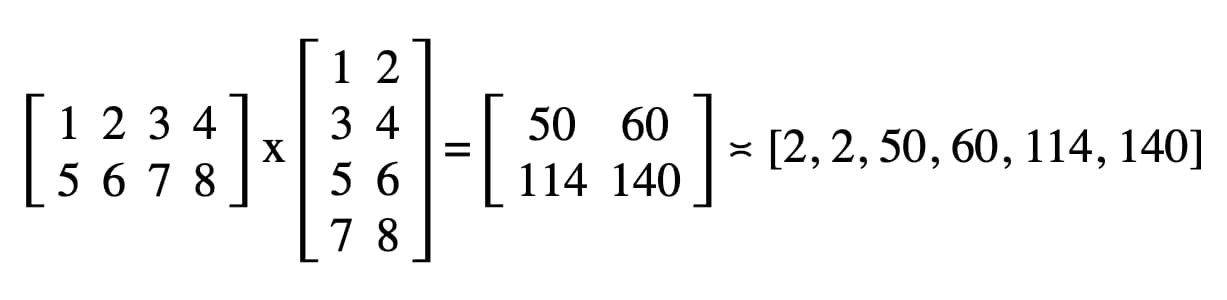
No nosso código, o resultado registrado no console JavaScript do DevTools é "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Parabéns! Você conseguiu. Você pode testar a amostra.
Um último truque
Uma maneira de facilitar a leitura do código é usar o método getBindGroupLayout do pipeline de computação para inferir o layout do grupo de vinculação do módulo de shader. Esse truque elimina a necessidade de criar um
layout de grupo de vinculação personalizado e especificar um layout de pipeline no pipeline de
computação, conforme mostrado abaixo.
Uma ilustração de getBindGroupLayout para o exemplo anterior está disponível.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Descobertas de performance
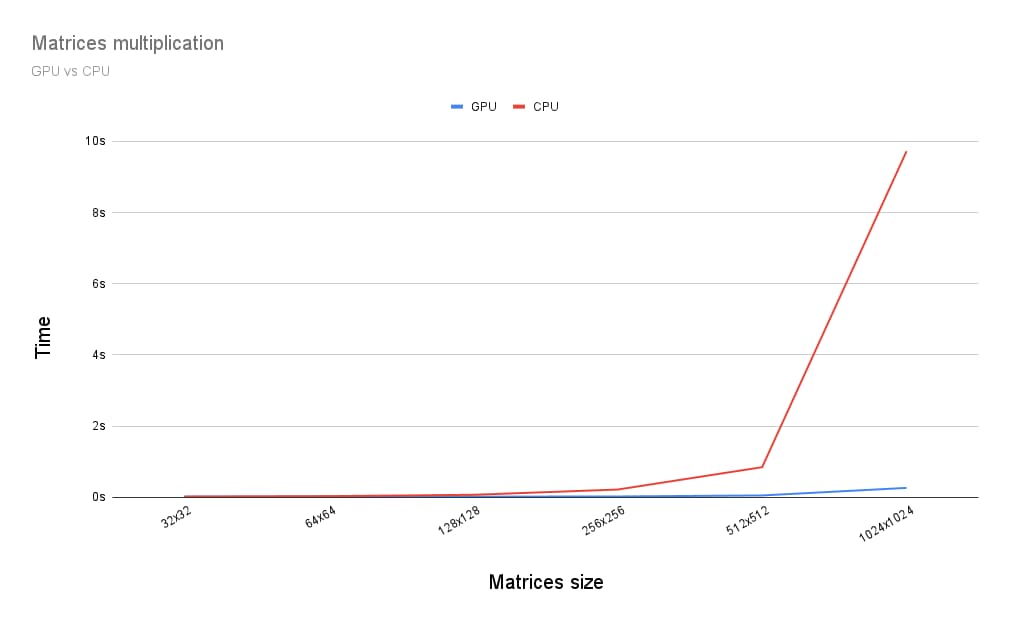
Então, como é executar a multiplicação de matrizes em uma GPU em comparação com uma CPU? Para descobrir, escrevi o programa descrito para uma CPU. Como você pode ver no gráfico abaixo, usar toda a capacidade da GPU parece uma escolha óbvia quando o tamanho das matrizes é maior que 256 por 256.
Este artigo foi apenas o começo da minha jornada explorando o WebGPU. Em breve, vamos publicar mais artigos com análises detalhadas sobre computação de GPU e como a renderização (canvas, textura, amostrador) funciona no WebGPU.