
โพสต์นี้จะสำรวจ API ของ WebGPU เวอร์ชันทดลองผ่านตัวอย่างและช่วยให้คุณเริ่มต้นใช้งานการคำนวณแบบขนานข้อมูลโดยใช้ GPU

เผยแพร่: 28 ส.ค. 2019, อัปเดตล่าสุด: 12 ส.ค. 2025
ฉากหลัง
อย่างที่คุณอาจทราบ หน่วยประมวลผลกราฟิก (GPU) คือระบบย่อยอิเล็กทรอนิกส์ ภายในคอมพิวเตอร์ที่เดิมออกแบบมาเพื่อประมวลผล กราฟิกโดยเฉพาะ อย่างไรก็ตาม ในช่วง 10 ปีที่ผ่านมานี้ ได้มีการพัฒนาไปสู่สถาปัตยกรรมที่ยืดหยุ่นมากขึ้น ซึ่งช่วยให้นักพัฒนาซอฟต์แวร์สามารถใช้การติดตั้งใช้งานอัลกอริทึมได้หลายประเภท ไม่ใช่แค่ การแสดงผลกราฟิก 3 มิติเท่านั้น ในขณะที่ใช้ประโยชน์จากสถาปัตยกรรมที่เป็นเอกลักษณ์ของ GPU ความสามารถเหล่านี้เรียกว่าการประมวลผล GPU และการใช้ GPU เป็น ตัวประมวลผลร่วมสำหรับการประมวลผลทางวิทยาศาสตร์แบบอเนกประสงค์เรียกว่าการเขียนโปรแกรม GPU แบบอเนกประสงค์ (GPGPU)
การประมวลผล GPU มีส่วนสำคัญอย่างยิ่งต่อการเติบโตของแมชชีนเลิร์นนิงในช่วงที่ผ่านมา เนื่องจากโครงข่ายประสาทแบบคอนโวลูชันและโมเดลอื่นๆ สามารถใช้ประโยชน์จาก สถาปัตยกรรมเพื่อเรียกใช้บน GPU ได้อย่างมีประสิทธิภาพมากขึ้น เนื่องจากแพลตฟอร์มเว็บปัจจุบัน ยังขาดความสามารถในการประมวลผล GPU กลุ่มชุมชน "GPU สำหรับเว็บ" ของ W3C จึงออกแบบ API เพื่อแสดง API ของ GPU สมัยใหม่ที่มีให้บริการในอุปกรณ์ปัจจุบันส่วนใหญ่ API นี้เรียกว่า WebGPU
WebGPU เป็น API ระดับต่ำเช่นเดียวกับ WebGL ซึ่งมีประสิทธิภาพมากและค่อนข้างละเอียดอย่างที่คุณจะเห็น แต่ก็ไม่เป็นไร สิ่งที่เรามองหาคือประสิทธิภาพ
ในบทความนี้ ฉันจะมุ่งเน้นไปที่ส่วนการคำนวณ GPU ของ WebGPU และพูดตามตรงว่าฉันเพิ่งเริ่มต้นเท่านั้น เพื่อให้คุณเริ่มเล่นได้ด้วยตัวเอง เราจะเจาะลึกและครอบคลุมการแสดงผล WebGPU (Canvas, Texture ฯลฯ) ในบทความที่จะเผยแพร่ในอนาคต
เข้าถึง GPU
การเข้าถึง GPU ใน WebGPU นั้นทำได้ง่าย การเรียก navigator.gpu.requestAdapter()
จะแสดงผลสัญญา JavaScript ที่จะแก้ไขแบบไม่พร้อมกันด้วยอแดปเตอร์ GPU
ให้คิดว่าอะแดปเตอร์นี้เป็นเหมือนกราฟิกการ์ด โดยอาจเป็นแบบผสานรวม
(บนชิปเดียวกับ CPU) หรือแบบแยก (โดยปกติคือการ์ด PCIe ที่มีประสิทธิภาพมากกว่า
แต่ใช้พลังงานมากกว่า)
เมื่อมี GPU Adapter แล้ว ให้เรียกใช้ adapter.requestDevice() เพื่อรับสัญญา
ที่จะทำงานกับอุปกรณ์ GPU ที่คุณจะใช้ในการคำนวณ GPU
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
ทั้ง 2 ฟังก์ชันมีตัวเลือกที่ช่วยให้คุณระบุประเภท อะแดปเตอร์ (ค่ากำหนดพลังงาน) และอุปกรณ์ (ส่วนขยาย ขีดจำกัด) ที่ต้องการได้ เพื่อความสะดวก เราจะใช้ตัวเลือกเริ่มต้นในบทความนี้
หน่วยความจำบัฟเฟอร์การเขียน
มาดูวิธีใช้ JavaScript เพื่อเขียนข้อมูลลงในหน่วยความจำสำหรับ GPU กัน กระบวนการนี้ ไม่ตรงไปตรงมาเนื่องจากโมเดลแซนด์บ็อกซ์ที่ใช้ในเว็บเบราว์เซอร์ สมัยใหม่
ตัวอย่างด้านล่างแสดงวิธีเขียน 4 ไบต์ลงในหน่วยความจำบัฟเฟอร์ที่ GPU เข้าถึงได้
โดยจะเรียกใช้ device.createBuffer() ซึ่งจะใช้ขนาดของ
บัฟเฟอร์และการใช้งาน แม้ว่าการตั้งค่าสถานะการใช้งาน GPUBufferUsage.MAP_WRITE จะไม่จำเป็นสำหรับการเรียกนี้โดยเฉพาะ แต่เราจะระบุอย่างชัดเจนว่าต้องการเขียนไปยังบัฟเฟอร์นี้
ซึ่งจะส่งผลให้มีการแมปออบเจ็กต์บัฟเฟอร์ GPU เมื่อสร้างขึ้นเนื่องจาก
mappedAtCreation ตั้งค่าเป็น true จากนั้นจะเรียกข้อมูลบัฟเฟอร์ข้อมูลไบนารีดิบที่เชื่อมโยงได้โดยเรียกใช้เมธอดบัฟเฟอร์ GPU getMappedRange()
การเขียนไบต์จะคุ้นเคยหากคุณเคยเล่นกับ ArrayBuffer มาก่อน ให้ใช้ TypedArray และคัดลอกค่าลงในนั้น
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
ตอนนี้บัฟเฟอร์ GPU จะได้รับการแมป ซึ่งหมายความว่า CPU เป็นเจ้าของบัฟเฟอร์ และ
สามารถเข้าถึงได้ในโหมดอ่าน/เขียนจาก JavaScript ดังนั้น GPU จึงจะเข้าถึงได้ คุณต้องยกเลิกการแมป ซึ่งทำได้ง่ายๆ เพียงแค่เรียกใช้ gpuBuffer.unmap()
แนวคิดของหน่วยความจำที่แมป/ไม่ได้แมปเป็นสิ่งจำเป็นเพื่อป้องกันสภาวะการแข่งขันที่ GPU และ CPU เข้าถึงหน่วยความจำพร้อมกัน
หน่วยความจำบัฟเฟอร์การอ่าน
ตอนนี้มาดูวิธีคัดลอกบัฟเฟอร์ GPU ไปยังบัฟเฟอร์ GPU อื่นและอ่านกลับ
เนื่องจากเรากำลังเขียนในบัฟเฟอร์ GPU แรกและต้องการคัดลอกไปยังบัฟเฟอร์ GPU ที่สอง
จึงต้องมีแฟล็กการใช้งานใหม่ GPUBufferUsage.COPY_SRC คราวนี้เราจะสร้างบัฟเฟอร์ GPU ที่ 2 ในสถานะที่ไม่ได้แมปด้วย
device.createBuffer() โดยมีแฟล็กการใช้งานเป็น GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ เนื่องจากจะใช้เป็นปลายทางของบัฟเฟอร์ GPU แรกและอ่านใน JavaScript เมื่อเรียกใช้คำสั่งคัดลอก GPU แล้ว
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
เนื่องจาก GPU เป็นตัวประมวลผลร่วมอิสระ คำสั่ง GPU ทั้งหมดจึงทำงานแบบอะซิงโครนัส
ด้วยเหตุนี้จึงมีรายการคำสั่ง GPU ที่สร้างขึ้นและส่งเป็นชุดเมื่อจำเป็น ใน WebGPU ตัวเข้ารหัสคำสั่ง GPU ที่ส่งคืนโดย
device.createCommandEncoder()คือออบเจ็กต์ JavaScript ที่สร้างชุดคำสั่ง "บัฟเฟอร์"
ซึ่งจะส่งไปยัง GPU ในเวลาใดเวลาหนึ่ง ส่วนเมธอดใน
GPUBufferนั้น "ไม่มีการบัฟเฟอร์" ซึ่งหมายความว่าเมธอดจะดำเนินการแบบอะตอม
ในเวลาที่เรียกใช้
เมื่อมีตัวเข้ารหัสคำสั่ง GPU แล้ว ให้เรียกใช้ copyEncoder.copyBufferToBuffer()
ตามที่แสดงด้านล่างเพื่อเพิ่มคำสั่งนี้ลงในคิวคำสั่งเพื่อดำเนินการในภายหลัง
สุดท้าย ให้เรียกใช้ copyEncoder.finish() เพื่อสิ้นสุดคำสั่งการเข้ารหัส และส่งคำสั่งเหล่านั้นไปยังคิวคำสั่งของอุปกรณ์ GPU คิวมีหน้าที่จัดการการส่งที่ทำผ่าน device.queue.submit() โดยใช้คำสั่ง GPU เป็นอาร์กิวเมนต์
ซึ่งจะเรียกใช้คำสั่งทั้งหมดที่จัดเก็บไว้ในอาร์เรย์ตามลำดับโดยอัตโนมัติ
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
ในขั้นตอนนี้ ระบบได้ส่งคำสั่งคิว GPU แล้ว แต่ไม่จำเป็นต้องดำเนินการ
หากต้องการอ่านบัฟเฟอร์ GPU ที่ 2 ให้เรียกใช้ gpuReadBuffer.mapAsync() ด้วย
GPUMapMode.READ โดยจะแสดงผล Promise ที่จะได้รับการแก้ไขเมื่อมีการแมปบัฟเฟอร์ GPU
จากนั้นรับช่วงที่แมปด้วย gpuReadBuffer.getMappedRange() ที่มีค่าเดียวกับบัฟเฟอร์ GPU แรกเมื่อคำสั่ง GPU ที่จัดคิวทั้งหมด
ได้รับการดำเนินการแล้ว
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
คุณลองใช้ตัวอย่างนี้ได้
โดยสรุป สิ่งที่คุณต้องจำเกี่ยวกับการดำเนินการหน่วยความจำบัฟเฟอร์มีดังนี้
- ต้องยกเลิกการแมปบัฟเฟอร์ GPU เพื่อใช้ในการส่งคิวของอุปกรณ์
- เมื่อแมปแล้ว คุณจะอ่านและเขียนบัฟเฟอร์ GPU ใน JavaScript ได้
- ระบบจะแมปบัฟเฟอร์ GPU เมื่อเรียกใช้
mapAsync()และcreateBuffer()โดยตั้งค่าmappedAtCreationเป็น true
การเขียนโปรแกรม Shader
โปรแกรมที่ทำงานบน GPU ซึ่งดำเนินการคำนวณเท่านั้น (และไม่ได้วาดสามเหลี่ยม) เรียกว่า Compute Shader โดยจะทำงานแบบคู่ขนานกันด้วยแกน GPU หลายร้อยแกน (ซึ่งมีขนาดเล็กกว่าแกน CPU) ที่ทำงานร่วมกันเพื่อประมวลผลข้อมูล อินพุตและเอาต์พุตของฟังก์ชันนี้คือบัฟเฟอร์ใน WebGPU
เพื่อแสดงให้เห็นการใช้ Compute Shader ใน WebGPU เราจะมาลองใช้การคูณเมทริกซ์ ซึ่งเป็นอัลกอริทึมทั่วไปในแมชชีนเลิร์นนิงดังที่แสดงด้านล่าง
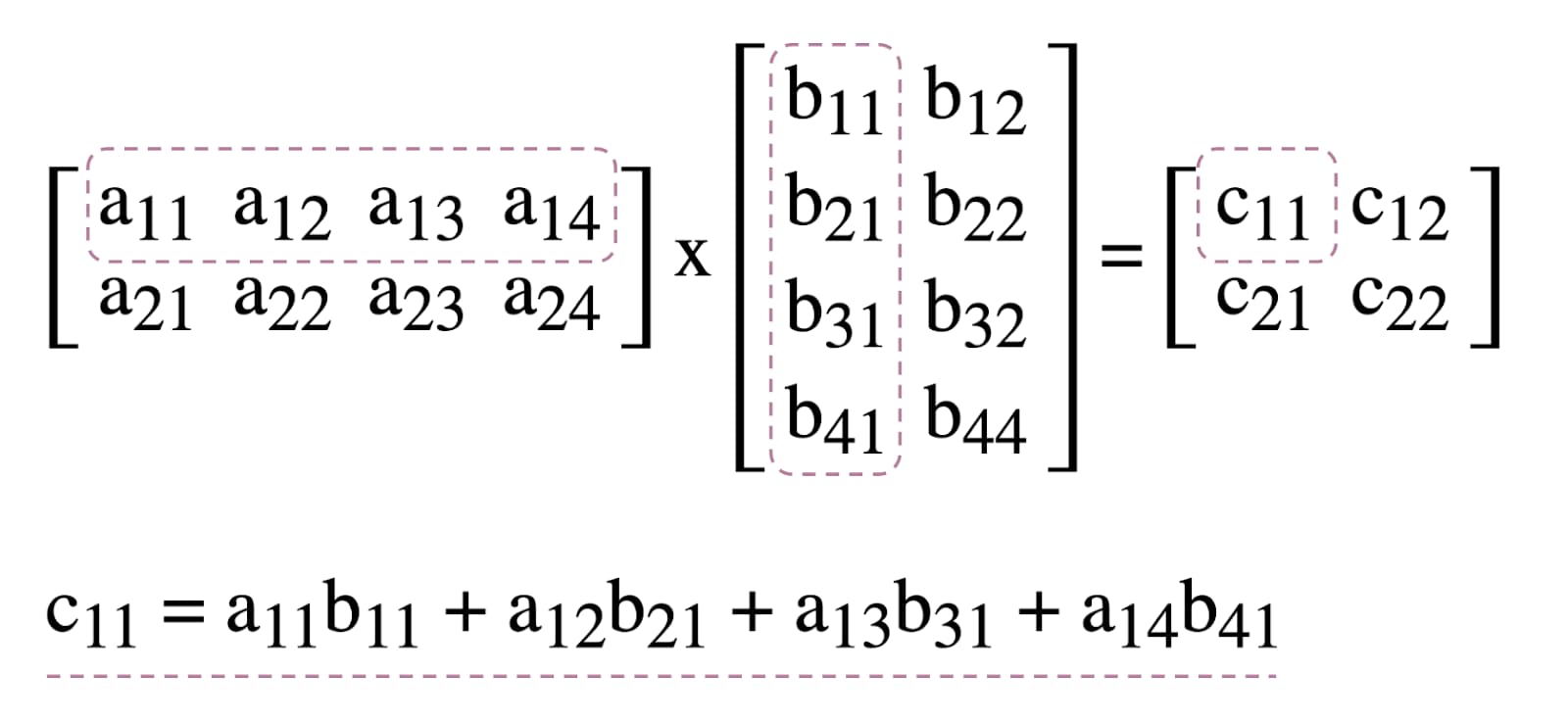
โดยสรุปแล้ว สิ่งที่เราจะทำมีดังนี้
- สร้างบัฟเฟอร์ GPU 3 รายการ (2 รายการสำหรับเมทริกซ์ที่จะคูณ และ 1 รายการสำหรับ เมทริกซ์ผลลัพธ์)
- อธิบายอินพุตและเอาต์พุตสำหรับ Compute Shader
- คอมไพล์โค้ด Compute Shader
- ตั้งค่าไปป์ไลน์การประมวลผล
- ส่งคำสั่งที่เข้ารหัสไปยัง GPU เป็นชุด
- อ่านบัฟเฟอร์ GPU ของเมทริกซ์ผลลัพธ์
การสร้างบัฟเฟอร์ GPU
เพื่อความเรียบง่าย เราจะแสดงเมทริกซ์เป็นรายการของจำนวนทศนิยม องค์ประกอบแรกคือจำนวนแถว องค์ประกอบที่ 2 คือจำนวนคอลัมน์ และองค์ประกอบที่เหลือคือตัวเลขจริงของเมทริกซ์

บัฟเฟอร์ GPU ทั้ง 3 รายการเป็นบัฟเฟอร์พื้นที่เก็บข้อมูลเนื่องจากเราต้องจัดเก็บและดึงข้อมูลใน Compute Shader ซึ่งอธิบายได้ว่าทำไมแฟล็กการใช้บัฟเฟอร์ GPU จึงมี
GPUBufferUsage.STORAGE สำหรับทั้งหมด Flag การใช้งานเมทริกซ์ผลลัพธ์ยังมี
GPUBufferUsage.COPY_SRC เนื่องจากจะมีการคัดลอกไปยังบัฟเฟอร์อื่นเพื่อ
อ่านเมื่อดำเนินการคำสั่งคิว GPU ทั้งหมดเสร็จแล้ว
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
เลย์เอาต์กลุ่มที่เชื่อมโยงและกลุ่มที่เชื่อมโยง
แนวคิดของเลย์เอาต์กลุ่มการเชื่อมโยงและกลุ่มการเชื่อมโยงเป็นแนวคิดเฉพาะของ WebGPU เลย์เอาต์กลุ่ม Bind จะกำหนดอินเทอร์เฟซอินพุต/เอาต์พุตที่ Shader คาดหวัง ในขณะที่กลุ่ม Bind จะแสดงข้อมูลอินพุต/เอาต์พุตจริงสำหรับ Shader
ในตัวอย่างด้านล่างนี้ เลย์เอาต์ของกลุ่มการเชื่อมโยงคาดหวังว่าจะมีบัฟเฟอร์พื้นที่เก็บข้อมูลแบบอ่านอย่างเดียว 2 รายการที่
การเชื่อมโยงรายการที่มีหมายเลข 0, 1 และบัฟเฟอร์พื้นที่เก็บข้อมูลที่ 2 สำหรับ Compute Shader
ในทางกลับกัน กลุ่มการเชื่อมโยงที่กำหนดไว้สำหรับเลย์เอาต์กลุ่มการเชื่อมโยงนี้จะเชื่อมโยงบัฟเฟอร์ GPU กับรายการต่างๆ ดังนี้ gpuBufferFirstMatrix กับการเชื่อมโยง 0
gpuBufferSecondMatrix กับการเชื่อมโยง 1 และ resultMatrixBuffer กับ
การเชื่อมโยง 2
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
โค้ด Compute Shader
โค้ด Compute Shader สำหรับการคูณเมทริกซ์เขียนด้วย WGSL ซึ่งเป็นภาษา Shader ของ WebGPU ที่แปลเป็น SPIR-V ได้อย่างง่ายดาย คุณจะเห็นบัฟเฟอร์พื้นที่เก็บข้อมูล 3 รายการที่ระบุด้วย var<storage> ด้านล่างโดยไม่ต้องลงรายละเอียด โปรแกรมจะใช้ firstMatrix และ secondMatrix เป็น
อินพุต และ resultMatrix เป็นเอาต์พุต
โปรดทราบว่าบัฟเฟอร์พื้นที่เก็บข้อมูลแต่ละรายการมีbindingตกแต่งที่สอดคล้องกับ
ดัชนีเดียวกันที่กำหนดไว้ในเลย์เอาต์กลุ่มที่เชื่อมโยงและกลุ่มที่เชื่อมโยงที่ประกาศไว้ข้างต้น
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
การตั้งค่าไปป์ไลน์
ไปป์ไลน์การประมวลผลคือออบเจ็กต์ที่อธิบายการดำเนินการประมวลผล
ที่เราจะทำจริงๆ สร้างโดยโทรหา device.createComputePipeline()
โดยรับอาร์กิวเมนต์ 2 รายการ ได้แก่ เลย์เอาต์กลุ่มการเชื่อมโยงที่เราสร้างไว้ก่อนหน้านี้ และขั้นตอนการประมวลผล
ที่กำหนดจุดแรกเข้าของ Compute Shader (ฟังก์ชัน main WGSL)
และโมดูล Compute Shader จริงที่สร้างด้วย device.createShaderModule()
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
การส่งคำสั่ง
หลังจากสร้างอินสแตนซ์ของกลุ่มการเชื่อมโยงด้วยบัฟเฟอร์ GPU 3 รายการและไปป์ไลน์การคำนวณ ที่มีเลย์เอาต์กลุ่มการเชื่อมโยงแล้ว ก็ถึงเวลาใช้งาน
มาเริ่มโปรแกรมเปลี่ยนไฟล์ที่ส่งผ่านการคำนวณที่ตั้งโปรแกรมได้ด้วย
commandEncoder.beginComputePass() เราจะใช้ข้อมูลนี้เพื่อเข้ารหัสคำสั่ง GPU
ที่จะทำการคูณเมทริกซ์ ตั้งค่าไปป์ไลน์ด้วย
passEncoder.setPipeline(computePipeline) และกลุ่มการเชื่อมโยงที่ดัชนี 0 ด้วย
passEncoder.setBindGroup(0, bindGroup) ดัชนี 0 สอดคล้องกับ
group(0) ในโค้ด WGSL
ทีนี้เรามาพูดถึงวิธีที่ Compute Shader นี้จะทำงานบน GPU กัน
เป้าหมายของเราคือการดำเนินการโปรแกรมนี้แบบขนานสำหรับแต่ละเซลล์ของเมทริกซ์ผลลัพธ์
ทีละขั้นตอน เช่น สำหรับเมทริกซ์ผลลัพธ์ขนาด 16x32 ในการเข้ารหัส
คำสั่งการดำเนินการใน @workgroup_size(8, 8) เราจะเรียกใช้
passEncoder.dispatchWorkgroups(2, 4) หรือ passEncoder.dispatchWorkgroups(16 / 8, 32 / 8)
อาร์กิวเมนต์แรก "x" คือมิติข้อมูลแรก อาร์กิวเมนต์ที่สอง "y" คือมิติข้อมูลที่สอง
และอาร์กิวเมนต์ล่าสุด "z" คือมิติข้อมูลที่สามซึ่งมีค่าเริ่มต้นเป็น 1 เนื่องจากเราไม่จำเป็นต้องใช้ที่นี่
ในโลกของการประมวลผล GPU การเข้ารหัสคำสั่งเพื่อเรียกใช้ฟังก์ชันเคอร์เนลในชุดข้อมูลเรียกว่าการส่ง
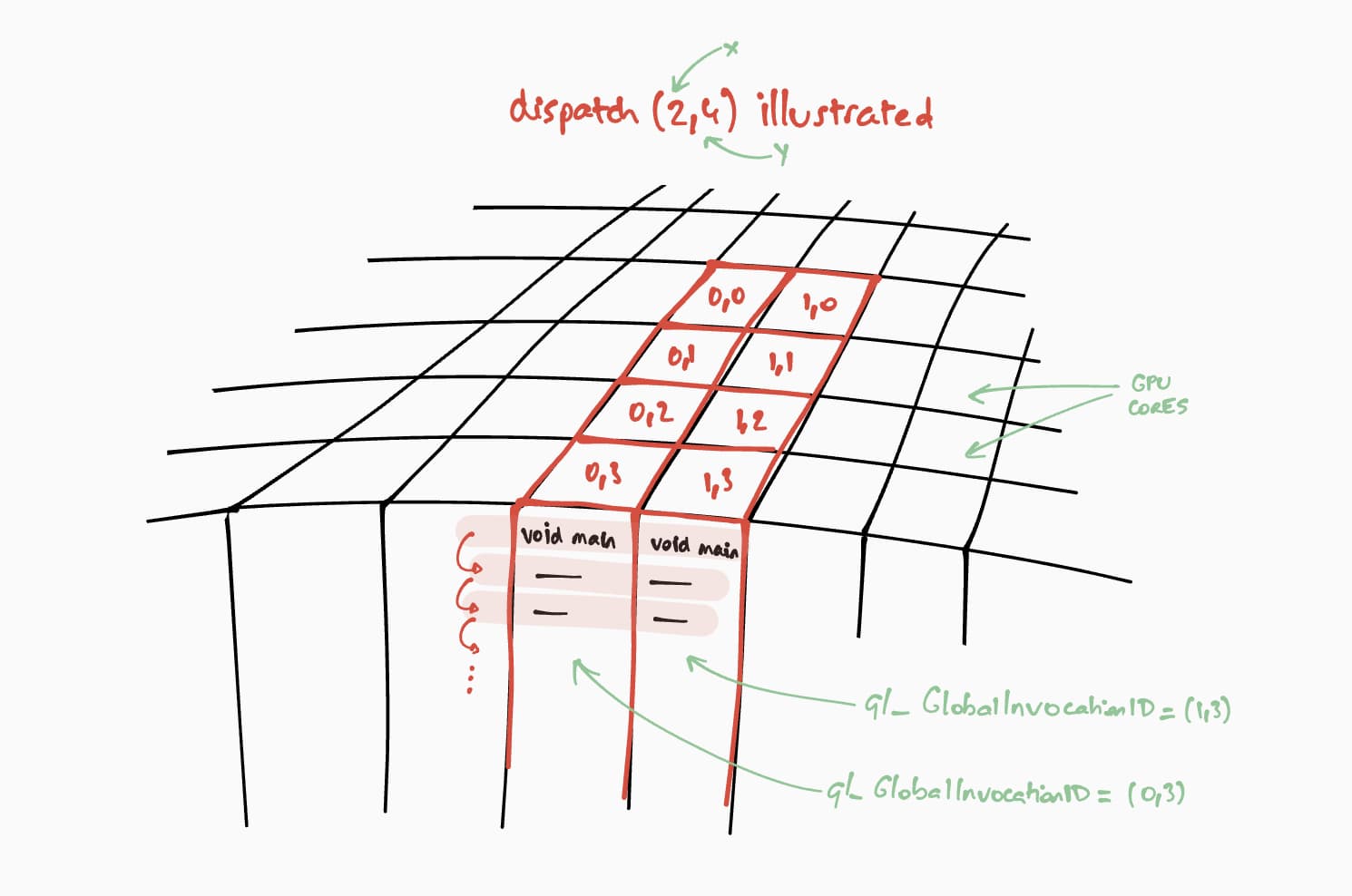
ขนาดของตารางกริดของเวิร์กกรุ๊ปสำหรับ Compute Shader คือ (8, 8) ในโค้ด WGSL
ด้วยเหตุนี้ "x" และ "y" ซึ่งเป็นจำนวนแถวของเมทริกซ์แรกและจำนวนคอลัมน์ของเมทริกซ์ที่ 2 ตามลำดับจะถูกหารด้วย 8
ด้วยเหตุนี้ เราจึงสามารถส่งการเรียกใช้การคำนวณด้วย
passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8)
จำนวนตารางกริดของเวิร์กกรุ๊ปที่จะเรียกใช้คืออาร์กิวเมนต์ dispatchWorkgroups()
ดังที่เห็นในภาพวาดด้านบน เชดเดอร์แต่ละรายการจะมีสิทธิ์เข้าถึงออบเจ็กต์ที่ไม่ซ้ำกัน
builtin(global_invocation_id) ซึ่งจะใช้เพื่อทราบว่าต้องคำนวณเซลล์เมทริกซ์ผลลัพธ์ใด
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
หากต้องการสิ้นสุดโปรแกรมเปลี่ยนไฟล์แบบหลายรอบ ให้เรียกใช้ passEncoder.end() จากนั้นสร้าง
บัฟเฟอร์ GPU เพื่อใช้เป็นปลายทางในการคัดลอกบัฟเฟอร์เมทริกซ์ผลลัพธ์ด้วย
copyBufferToBuffer สุดท้าย ให้สิ้นสุดคำสั่งการเข้ารหัสด้วย
copyEncoder.finish() และส่งคำสั่งเหล่านั้นไปยังคิวอุปกรณ์ GPU โดยเรียกใช้
device.queue.submit() ด้วยคำสั่ง GPU
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
อ่านเมทริกซ์ผลลัพธ์
การอ่านเมทริกซ์ผลลัพธ์ทำได้ง่ายๆ เพียงเรียก gpuReadBuffer.mapAsync() ด้วย
GPUMapMode.READ แล้วรอให้สัญญาที่ส่งคืนได้รับการแก้ไข ซึ่งจะบ่งบอกว่าตอนนี้ได้แมปบัฟเฟอร์ GPU แล้ว ในตอนนี้ คุณสามารถรับช่วงที่แมปได้ด้วย gpuReadBuffer.getMappedRange()
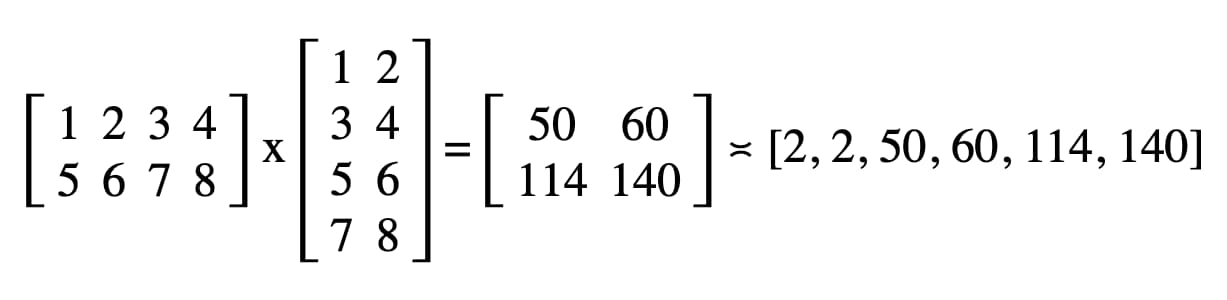
ในโค้ดของเรา ผลลัพธ์ที่บันทึกไว้ในคอนโซล JavaScript ของเครื่องมือสำหรับนักพัฒนาเว็บคือ "2, 2, 50, 60, 114, 140"
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
ยินดีด้วย คุณทำสำเร็จแล้ว คุณเล่นกับตัวอย่างได้
เคล็ดลับสุดท้าย
วิธีหนึ่งที่ช่วยให้โค้ดอ่านง่ายขึ้นคือการใช้getBindGroupLayoutเมธอดที่สะดวกของไปป์ไลน์การคำนวณเพื่ออนุมานเลย์เอาต์กลุ่มการเชื่อมโยงจากโมดูล Shader เทคนิคนี้ช่วยให้คุณไม่ต้องสร้าง
เลย์เอาต์กลุ่มการเชื่อมโยงที่กำหนดเองและระบุเลย์เอาต์ไปป์ไลน์ในไปป์ไลน์การประมวลผล
ดังที่เห็นด้านล่าง
ภาพประกอบของ getBindGroupLayout สำหรับตัวอย่างก่อนหน้าพร้อมใช้งานแล้ว
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
ผลการค้นหาด้านประสิทธิภาพ
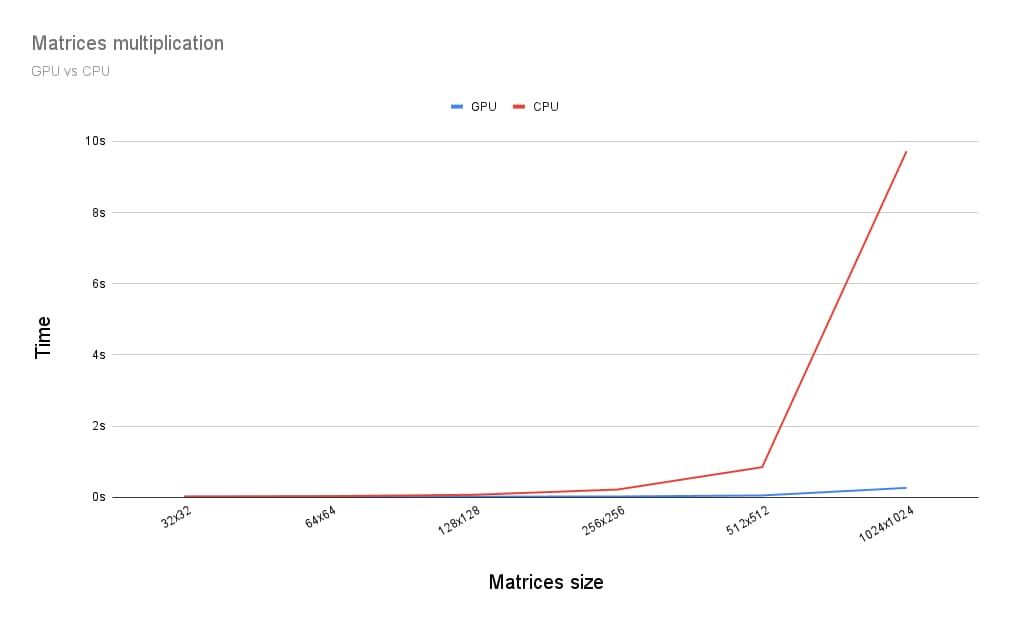
การคูณเมทริกซ์บน GPU เป็นอย่างไรเมื่อเทียบกับการคูณเมทริกซ์บน CPU ฉันจึงเขียนโปรแกรมที่เพิ่งอธิบายไปสำหรับ CPU เพื่อหาคำตอบ และดังที่เห็นในกราฟด้านล่าง การใช้พลังเต็มที่ของ GPU ดูเหมือนจะเป็นตัวเลือกที่ชัดเจนเมื่อขนาดของเมทริกซ์มากกว่า 256x256
บทความนี้เป็นเพียงจุดเริ่มต้นของการเดินทางสำรวจ WebGPU โปรดติดตามบทความเพิ่มเติมเร็วๆ นี้ ซึ่งจะเจาะลึกเรื่องการประมวลผล GPU และวิธีการแสดงผล (Canvas, Texture, Sampler) ใน WebGPU