
In dit bericht verkennen we de experimentele WebGPU API aan de hand van voorbeelden en helpen we u op weg met het uitvoeren van dataparallelle berekeningen met behulp van de GPU.

Gepubliceerd: 28 aug. 2019, Laatst bijgewerkt: 12 aug. 2025
Achtergrond
Zoals u wellicht al weet, is de grafische processor (GPU) een elektronisch subsysteem in een computer dat oorspronkelijk gespecialiseerd was in het verwerken van graphics. In de afgelopen 10 jaar heeft deze zich echter ontwikkeld tot een flexibelere architectuur, waardoor ontwikkelaars vele soorten algoritmen kunnen implementeren, niet alleen voor het renderen van 3D-graphics, maar ook kunnen profiteren van de unieke architectuur van de GPU. Deze mogelijkheden worden GPU Compute genoemd, en het gebruik van een GPU als coprocessor voor algemeen wetenschappelijk rekenwerk wordt General Purpose GPU (GPGPU)-programmering genoemd.
GPU Compute heeft aanzienlijk bijgedragen aan de recente opkomst van machine learning, doordat convolutionele neurale netwerken en andere modellen de architectuur kunnen benutten om efficiënter op GPU's te werken. Omdat het huidige webplatform niet over GPU Compute-mogelijkheden beschikt, ontwerpt de "GPU for the Web" Community Group van het W3C een API om de moderne GPU API's die op de meeste apparaten beschikbaar zijn, beschikbaar te stellen. Deze API heet WebGPU .
WebGPU is een low-level API, net als WebGL. Hij is erg krachtig en behoorlijk uitgebreid, zoals je zult zien. Maar dat is oké. Waar we naar op zoek zijn, zijn prestaties.
In dit artikel ga ik me richten op het GPU-berekeningsgedeelte van WebGPU en, eerlijk gezegd, begin ik nog maar net, zodat je zelf aan de slag kunt. Ik zal in toekomstige artikelen dieper ingaan op WebGPU-rendering (canvas, texture, enz.).
Toegang tot de GPU
Toegang tot de GPU is eenvoudig in WebGPU. Het aanroepen van navigator.gpu.requestAdapter() retourneert een JavaScript-promise die asynchroon wordt omgezet met een GPU-adapter. Beschouw deze adapter als de grafische kaart. Deze kan geïntegreerd zijn (op dezelfde chip als de CPU) of afzonderlijk (meestal een PCIe-kaart die beter presteert, maar meer stroom verbruikt).
Zodra u de GPU-adapter hebt, roept u adapter.requestDevice() aan om een belofte te krijgen die wordt omgezet naar een GPU-apparaat dat u gaat gebruiken om GPU-berekeningen uit te voeren.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Beide functies bieden opties waarmee u specifieke informatie kunt geven over het type adapter (stroomvoorkeur) en het apparaat (extensies, limieten). Om het overzichtelijk te houden, gebruiken we in dit artikel de standaardopties.
Schrijfbuffergeheugen
Laten we eens kijken hoe we JavaScript kunnen gebruiken om gegevens naar het geheugen van de GPU te schrijven. Dit proces is niet eenvoudig vanwege het sandboxmodel dat in moderne webbrowsers wordt gebruikt.
Het onderstaande voorbeeld laat zien hoe u vier bytes naar buffergeheugen schrijft dat toegankelijk is vanaf de GPU. Het roept device.createBuffer() aan, wat de grootte van de buffer en het gebruik ervan bepaalt. Hoewel de gebruiksvlag GPUBufferUsage.MAP_WRITE niet vereist is voor deze specifieke aanroep, laten we expliciet aangeven dat we naar deze buffer willen schrijven. Dit resulteert in een GPU-bufferobject dat bij het aanmaken is toegewezen dankzij mappedAtCreation ingesteld op true. Vervolgens kan de bijbehorende ruwe binaire databuffer worden opgehaald door de GPU-buffermethode getMappedRange() aan te roepen.
Het schrijven van bytes is bekend als u al met ArrayBuffer hebt gespeeld; gebruik een TypedArray en kopieer de waarden erin.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
Op dit punt is de GPU-buffer toegewezen, wat betekent dat deze eigendom is van de CPU en toegankelijk is voor lezen en schrijven vanuit JavaScript. Om de GPU er toegang toe te geven, moet deze worden ontkoppeld. Dit is net zo eenvoudig als het aanroepen van gpuBuffer.unmap() .
Het concept van mapped/unmapped is nodig om race-omstandigheden te voorkomen, waarbij de GPU en CPU tegelijkertijd toegang hebben tot het geheugen.
Leesbuffergeheugen
Laten we nu eens kijken hoe we een GPU-buffer naar een andere GPU-buffer kopiëren en deze teruglezen.
Omdat we in de eerste GPU-buffer schrijven en deze naar een tweede GPU-buffer willen kopiëren, is een nieuwe gebruiksvlag GPUBufferUsage.COPY_SRC vereist. De tweede GPU-buffer wordt dit keer in een niet-toegewezen staat aangemaakt met device.createBuffer() . De gebruiksvlag is GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ , omdat deze als bestemming voor de eerste GPU-buffer wordt gebruikt en in JavaScript wordt ingelezen zodra de GPU-kopieeropdrachten zijn uitgevoerd.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Omdat de GPU een onafhankelijke coprocessor is, worden alle GPU-opdrachten asynchroon uitgevoerd. Daarom wordt er een lijst met GPU-opdrachten samengesteld en indien nodig in batches verzonden. In WebGPU is de GPU-opdracht-encoder die wordt geretourneerd door device.createCommandEncoder() het JavaScript-object dat een batch 'gebufferde' opdrachten bouwt die op een bepaald moment naar de GPU worden verzonden. De methoden in GPUBuffer zijn daarentegen 'ongebufferd', wat betekent dat ze atomair worden uitgevoerd op het moment dat ze worden aangeroepen.
Zodra u de GPU-opdracht-encoder hebt, roept u copyEncoder.copyBufferToBuffer() aan zoals hieronder weergegeven om deze opdracht aan de opdrachtwachtrij toe te voegen voor latere uitvoering. Voltooi ten slotte de codering van opdrachten door copyEncoder.finish() aan te roepen en deze naar de opdrachtwachtrij van het GPU-apparaat te verzenden. De wachtrij is verantwoordelijk voor het verwerken van verzendingen via device.queue.submit() met de GPU-opdrachten als argumenten. Dit voert atomisch alle opdrachten uit die in de array zijn opgeslagen, in de juiste volgorde.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
Op dit punt zijn de GPU-wachtrijopdrachten verzonden, maar nog niet noodzakelijkerwijs uitgevoerd. Om de tweede GPU-buffer te lezen, roept u gpuReadBuffer.mapAsync() aan met GPUMapMode.READ . Dit retourneert een promise die wordt omgezet wanneer de GPU-buffer wordt toegewezen. Haal vervolgens het toegewezen bereik op met gpuReadBuffer.getMappedRange() dat dezelfde waarden bevat als de eerste GPU-buffer zodra alle GPU-wachtrijopdrachten zijn uitgevoerd.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
U kunt dit voorbeeld uitproberen .
Kortom, dit is wat u moet onthouden met betrekking tot buffergeheugenbewerkingen:
- GPU-buffers moeten worden losgekoppeld om te kunnen worden gebruikt bij het indienen van apparaten in de wachtrij.
- Wanneer GPU-buffers zijn toegewezen, kunnen ze in JavaScript worden gelezen en geschreven.
- GPU-buffers worden toegewezen wanneer
mapAsync()encreateBuffer()metmappedAtCreationingesteld op true worden aangeroepen.
Shader-programmering
Programma's die op de GPU draaien en alleen berekeningen uitvoeren (en geen driehoeken tekenen), worden compute shaders genoemd. Ze worden parallel uitgevoerd door honderden GPU-cores (die kleiner zijn dan CPU-cores) die samenwerken om data te verwerken. Hun invoer en uitvoer zijn buffers in WebGPU.
Om het gebruik van compute shaders in WebGPU te illustreren, experimenteren we met matrixvermenigvuldiging, een veelgebruikt algoritme in machine learning dat hieronder wordt geïllustreerd.
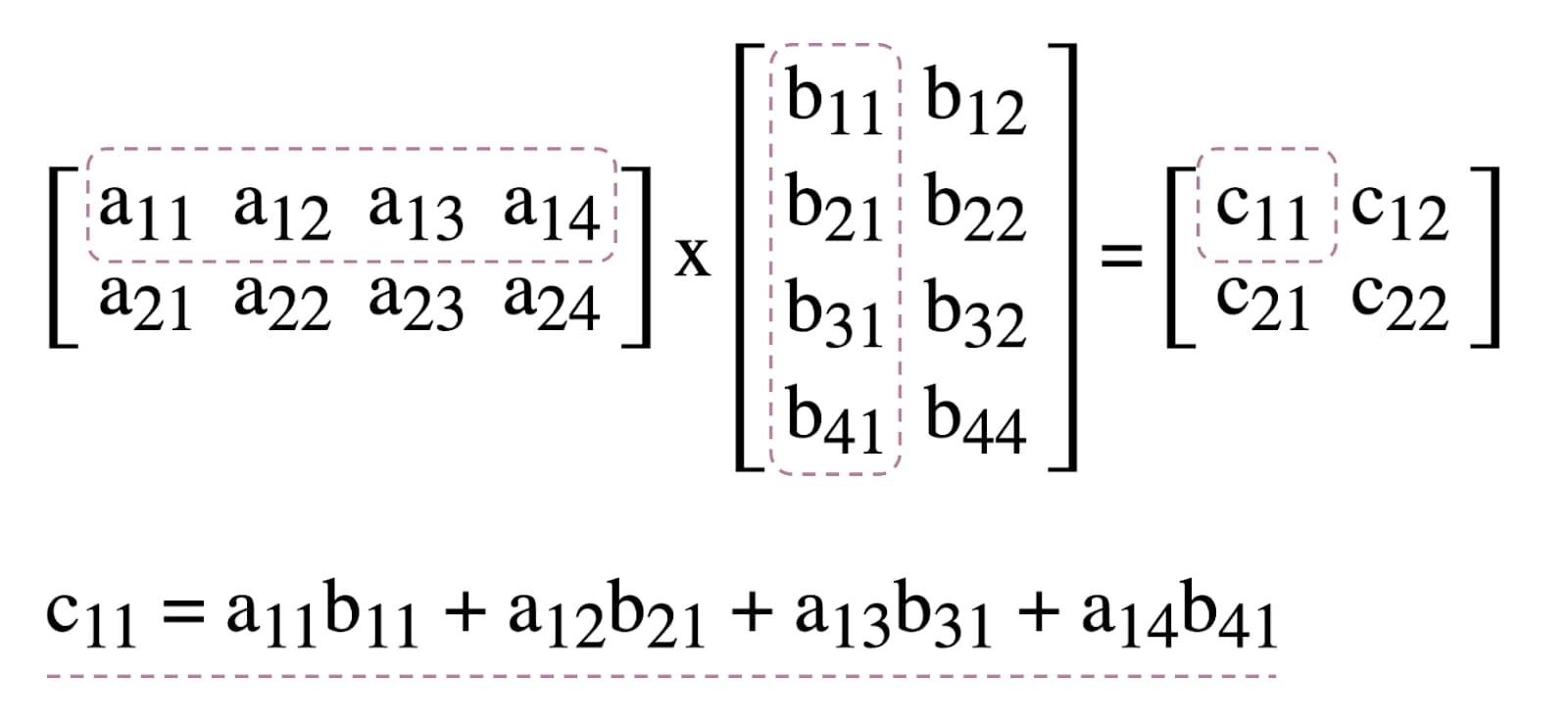
Kort gezegd gaan we het volgende doen:
- Maak drie GPU-buffers (twee voor de te vermenigvuldigen matrices en één voor de resultaatmatrix)
- Beschrijf de invoer en uitvoer voor de compute shader
- Compileer de compute shader-code
- Een rekenpijplijn opzetten
- Stuur de gecodeerde opdrachten in batch naar de GPU
- Lees de resultaatmatrix GPU-buffer
GPU-buffers aanmaken
Voor de eenvoud worden matrices weergegeven als een lijst met drijvendekommagetallen. Het eerste element is het aantal rijen, het tweede element het aantal kolommen en de rest zijn de werkelijke getallen van de matrix.

De drie GPU-buffers zijn opslagbuffers, omdat we gegevens in de compute shader moeten opslaan en ophalen. Dit verklaart waarom de GPU-buffergebruiksvlaggen GPUBufferUsage.STORAGE bevatten. De resultaatmatrixgebruiksvlag bevat ook GPUBufferUsage.COPY_SRC , omdat deze naar een andere buffer wordt gekopieerd om te lezen zodra alle GPU-wachtrijopdrachten zijn uitgevoerd.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Groepsindeling binden en groep binden
De concepten bind group layout en bind group zijn specifiek voor WebGPU. Een bind group layout definieert de input/output interface die een shader verwacht, terwijl een bind group de daadwerkelijke input/output data voor een shader vertegenwoordigt.
In het onderstaande voorbeeld verwacht de bindgroepindeling twee alleen-lezen opslagbuffers met de genummerde invoerbindingen 0 en 1 en een opslagbuffer met 2 voor de compute shader. De bindgroep daarentegen, gedefinieerd voor deze bindgroepindeling, koppelt GPU-buffers aan de invoer: gpuBufferFirstMatrix aan binding 0 , gpuBufferSecondMatrix aan binding 1 en resultMatrixBuffer aan binding 2 .
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
Bereken shadercode
De compute shadercode voor het vermenigvuldigen van matrices is geschreven in WGSL , de WebGPU Shader Language, en is eenvoudig te vertalen naar SPIR-V . Zonder in detail te treden, vindt u hieronder de drie opslagbuffers, aangeduid met var<storage> . Het programma gebruikt firstMatrix en secondMatrix als invoer en resultMatrix als uitvoer.
Houd er rekening mee dat voor elke opslagbuffer een binding wordt gebruikt die overeenkomt met dezelfde index die is gedefinieerd in de bindgroeplay-outs en bindgroepen die hierboven zijn gedeclareerd.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Pijpleidinginstallatie
De compute pipeline is het object dat de rekenbewerking die we gaan uitvoeren, daadwerkelijk beschrijft. Maak deze aan door device.createComputePipeline() aan te roepen. Deze vereist twee argumenten: de bind group layout die we eerder hebben gemaakt en een compute stage die het startpunt definieert van onze compute shader (de main WGSL-functie) en de daadwerkelijke compute shader module die met device.createShaderModule() is gemaakt.
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
Opdrachten indienen
Nadat we een bindgroep hebben geïnstantieerd met onze drie GPU-buffers en een compute-pijplijn met een bindgroepindeling, is het tijd om deze te gebruiken.
Laten we een programmeerbare compute pass encoder starten met commandEncoder.beginComputePass() . We gebruiken dit om GPU-opdrachten te coderen die de matrixvermenigvuldiging uitvoeren. Stel de pipeline in met passEncoder.setPipeline(computePipeline) en de bindgroep op index 0 met passEncoder.setBindGroup(0, bindGroup) . Index 0 komt overeen met de group(0) -decoratie in de WGSL-code.
Laten we het nu hebben over hoe deze compute shader op de GPU zal werken. Ons doel is om dit programma stapsgewijs parallel uit te voeren voor elke cel van de resultaatmatrix. Voor een resultaatmatrix van bijvoorbeeld 16 bij 32 pixels zouden we passEncoder.dispatchWorkgroups(2, 4) @workgroup_size(8, 8) passEncoder.dispatchWorkgroups(16 / 8, 32 / 8) aanroepen om de uitvoeringsopdracht te coderen. Het eerste argument "x" is de eerste dimensie, het tweede "y" is de tweede dimensie en het laatste "z" is de derde dimensie die standaard op 1 staat, omdat we die hier niet nodig hebben. In de wereld van GPU-computing wordt het coderen van een opdracht om een kernelfunctie uit te voeren op een dataset dispatching genoemd.
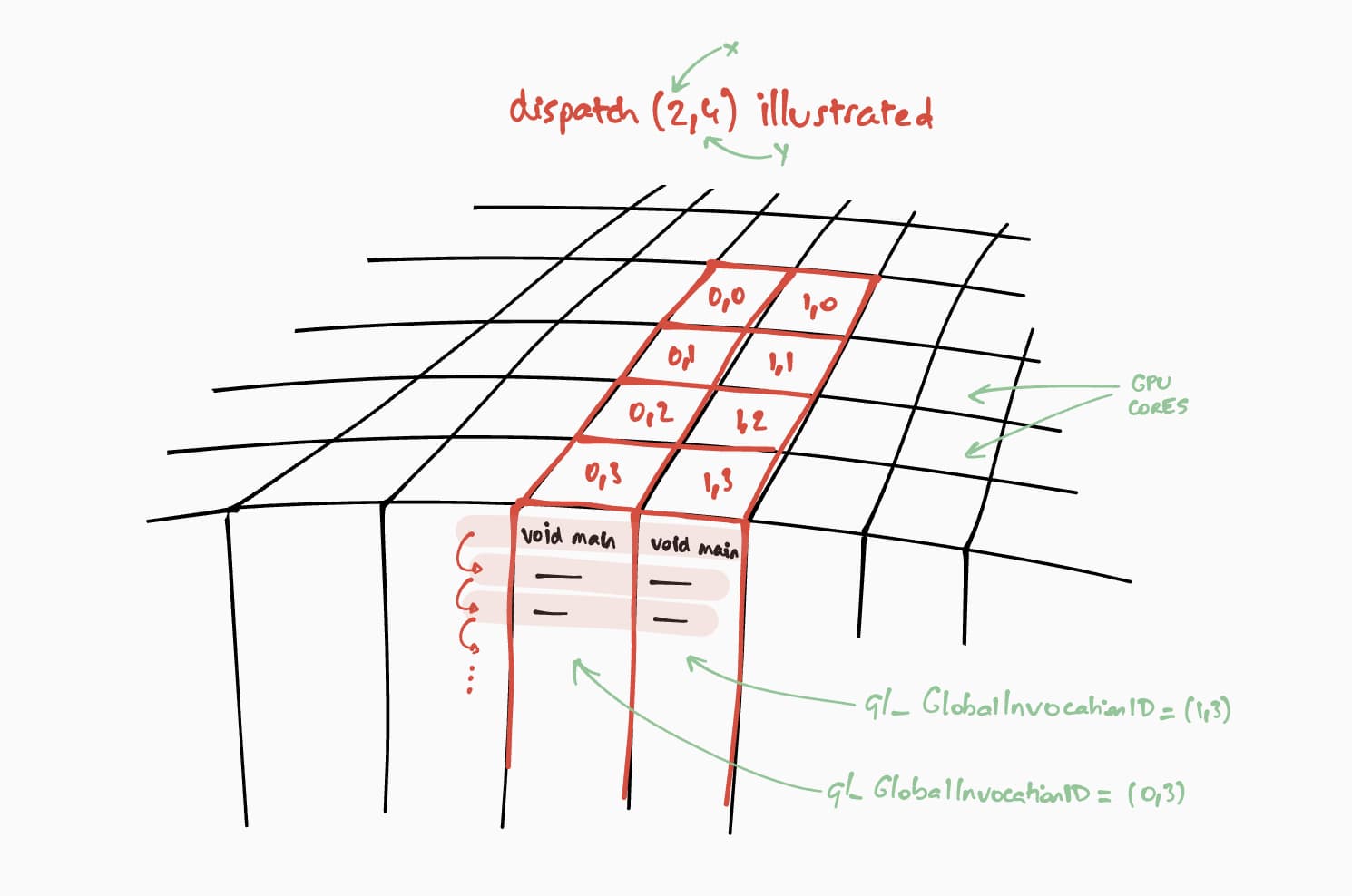
De grootte van het werkgroepraster voor onze compute shader is (8, 8) in onze WGSL-code. Hierdoor worden "x" en "y", respectievelijk het aantal rijen van de eerste matrix en het aantal kolommen van de tweede matrix, gedeeld door 8. Hiermee kunnen we nu een compute call uitvoeren met passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) . Het aantal uit te voeren werkgroeprasters zijn de dispatchWorkgroups() argumenten.
Zoals u in de bovenstaande tekening kunt zien, heeft elke shader toegang tot een uniek builtin(global_invocation_id) dat wordt gebruikt om te bepalen welke resultaatmatrixcel moet worden berekend.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Om de compute pass encoder te beëindigen, roept u passEncoder.end() aan. Maak vervolgens een GPU-buffer aan om te gebruiken als bestemming voor het kopiëren van de resultaatmatrixbuffer met copyBufferToBuffer . Voltooi ten slotte de coderingsopdrachten met copyEncoder.finish() en verstuur deze naar de GPU-apparaatwachtrij door device.queue.submit() aan te roepen met de GPU-opdrachten.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Lees resultaatmatrix
Het lezen van de resultaatmatrix is net zo eenvoudig als het aanroepen van gpuReadBuffer.mapAsync() met GPUMapMode.READ en wachten tot de terugkerende promise is opgelost, wat aangeeft dat de GPU-buffer nu is toegewezen. Op dit punt is het mogelijk om het toegewezen bereik te verkrijgen met gpuReadBuffer.getMappedRange() .
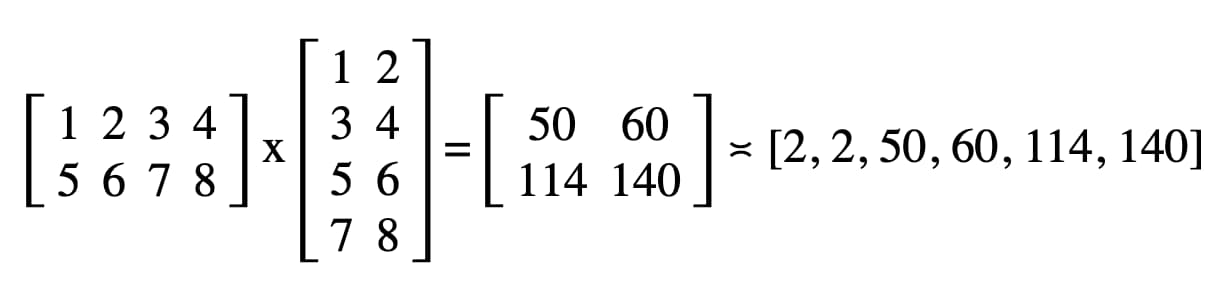
In onze code is het resultaat dat in de DevTools JavaScript-console wordt vastgelegd "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Gefeliciteerd! Je hebt het gehaald. Je kunt met het voorbeeld spelen .
Nog een laatste truc
Een manier om je code leesbaarder te maken, is door de handige getBindGroupLayout -methode van de compute pipeline te gebruiken om de bind group-indeling af te leiden uit de shadermodule . Deze truc maakt het niet langer nodig om een aangepaste bind group-indeling te maken en een pipeline-indeling in je compute pipeline te specificeren, zoals je hieronder kunt zien.
Er is een illustratie van getBindGroupLayout voor het vorige voorbeeld beschikbaar .
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Prestatiebevindingen
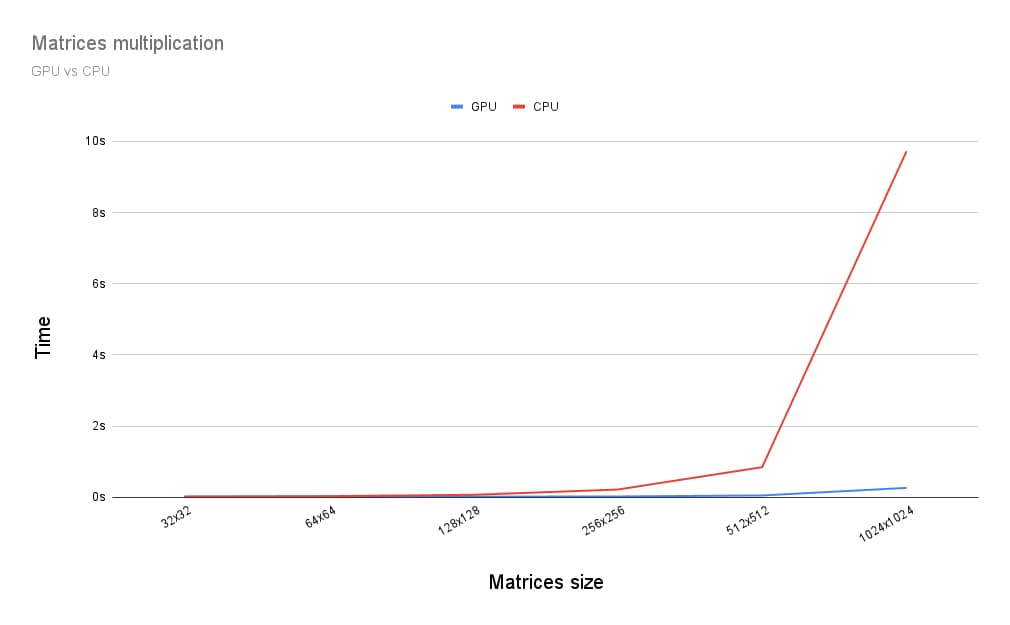
Dus hoe verhoudt matrixvermenigvuldiging zich tot een CPU? Om daarachter te komen, heb ik het zojuist beschreven programma geschreven voor een CPU. En zoals je in de onderstaande grafiek kunt zien, lijkt het een voor de hand liggende keuze om de volledige kracht van de GPU te benutten wanneer de matrices groter zijn dan 256 bij 256.
Dit artikel was slechts het begin van mijn verkenning van WebGPU . Binnenkort meer artikelen met meer diepgaande analyses van GPU Compute en hoe rendering (canvas, texture, sampler) werkt in WebGPU.