
本文將透過範例探討實驗性的 WebGPU API,協助您開始使用 GPU 執行資料平行運算。

發布時間:2019 年 8 月 28 日,上次更新時間:2025 年 8 月 12 日
背景
如您所知,圖形處理器 (GPU) 是電腦中的電子子系統,原本專門用於處理圖形。不過,在過去 10 年間,GPU 逐漸演變成更具彈性的架構,開發人員不僅能利用 GPU 的獨特架構算繪 3D 圖像,還能實作多種演算法。這些功能稱為 GPU 運算,而將 GPU 做為通用科學運算的協同處理器,則稱為通用 GPU (GPGPU) 程式設計。
GPU 運算在近期的機器學習熱潮中扮演重要角色,因為捲積神經網路和其他模型可充分利用架構,在 GPU 上更有效率地執行。由於目前的 Web Platform 缺乏 GPU 運算功能,W3C 的「GPU for the Web」社群團體正在設計 API,以公開大多數現有裝置提供的現代 GPU API。這個 API 稱為 WebGPU。
WebGPU 是低階 API,類似於 WebGL。如您所見,這個指令非常強大,而且相當詳細。但沒關係,我們要的是效能。
在本文中,我將著重於 WebGPU 的 GPU 計算部分,但說實話,我只是淺談,讓您可以自行開始玩玩。在後續文章中,我會深入探討並介紹 WebGPU 算繪 (畫布、紋理等)。
存取 GPU
在 WebGPU 中存取 GPU 非常簡單。呼叫 navigator.gpu.requestAdapter() 會傳回 JavaScript Promise,該 Promise 會以非同步方式解析為 GPU 配接器。你可以將這個轉接器視為顯示卡。可以是整合式 (與 CPU 位於同一晶片上),也可以是獨立式 (通常是 PCIe 卡,效能較高但耗電量較大)。
取得 GPU 介面卡後,請呼叫 adapter.requestDevice() 取得 Promise,該 Promise 會解析為您用來執行某些 GPU 計算的 GPU 裝置。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
這兩個函式都會採用選項,讓您指定想要的轉接器類型 (電源偏好設定) 和裝置 (擴充功能、限制)。為求簡單起見,本文將使用預設選項。
寫入緩衝記憶體
接下來,我們將瞭解如何使用 JavaScript 將資料寫入 GPU 的記憶體。由於現代網頁瀏覽器使用的沙箱模型,這個程序並不簡單。
以下範例說明如何將四個位元組寫入可從 GPU 存取的緩衝區記憶體。這會呼叫 device.createBuffer(),該函式會取得緩衝區的大小和用量。即使這個特定呼叫不需要使用旗標 GPUBufferUsage.MAP_WRITE,我們仍要明確指出要寫入這個緩衝區。由於 mappedAtCreation 設為 true,因此在建立時會對應 GPU 緩衝區物件。接著,呼叫 GPU 緩衝區方法 getMappedRange() 即可擷取相關聯的原始二進位資料緩衝區。
如果您已使用 ArrayBuffer,應該很熟悉如何寫入位元組;請使用 TypedArray 並將值複製到其中。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
此時 GPU 緩衝區已對應,表示緩衝區由 CPU 擁有,且可透過 JavaScript 讀取/寫入。為了讓 GPU 存取該記憶體,必須取消對應,只要呼叫 gpuBuffer.unmap() 即可。
為避免 GPU 和 CPU 同時存取記憶體而造成競爭情況,需要使用對應/未對應的概念。
讀取緩衝記憶體
現在,我們來看看如何將 GPU 緩衝區複製到另一個 GPU 緩衝區,並讀回該緩衝區。
由於我們要在第一個 GPU 緩衝區中寫入內容,並將其複製到第二個 GPU 緩衝區,因此需要新的使用情形標記 GPUBufferUsage.COPY_SRC。這次建立的第二個 GPU 緩衝區處於未對應狀態,並使用 device.createBuffer()。由於這個緩衝區會做為第一個 GPU 緩衝區的目的地,並在執行 GPU 複製指令後以 JavaScript 讀取,因此使用情形標記為 GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ。
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
由於 GPU 是獨立的協同處理器,因此所有 GPU 指令都會以非同步方式執行。因此,系統會建立 GPU 指令清單,並視需要分批傳送。在 WebGPU 中,device.createCommandEncoder() 傳回的 GPU 指令編碼器是 JavaScript 物件,可建構一批「緩衝」指令,這些指令會在某個時間點傳送至 GPU。另一方面,GPUBuffer 的方法是「未緩衝」,也就是說,這些方法會在呼叫時自動執行。
取得 GPU 指令編碼器後,請呼叫 copyEncoder.copyBufferToBuffer(),如下所示,將這項指令新增至指令佇列,以便稍後執行。最後,呼叫 copyEncoder.finish() 完成編碼指令,並將這些指令提交至 GPU 裝置指令佇列。佇列負責處理透過 device.queue.submit() 提交的內容,並將 GPU 指令做為引數。這會依序執行陣列中儲存的所有指令。
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
此時,GPU 佇列指令已傳送,但不一定會執行。
如要讀取第二個 GPU 緩衝區,請使用 GPUMapMode.READ 呼叫 gpuReadBuffer.mapAsync()。這個方法會傳回 promise,並在對應 GPU 緩衝區時解析。然後,在所有已排入佇列的 GPU 指令執行完畢後,使用 gpuReadBuffer.getMappedRange() 取得對應的範圍,其中包含與第一個 GPU 緩衝區相同的值。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
您可以試用這個範例。
簡而言之,緩衝區記憶體作業的注意事項如下:
- GPU 緩衝區必須取消對應,才能用於裝置佇列提交。
- 對應後,即可在 JavaScript 中讀取及寫入 GPU 緩衝區。
- 呼叫
mapAsync()和createBuffer()時,如果mappedAtCreation設為 true,系統就會對應 GPU 緩衝區。
著色器程式設計
在 GPU 上執行的程式只會執行運算 (不會繪製三角形),這類程式稱為運算著色器。數百個 GPU 核心 (比 CPU 核心小) 會平行執行這些作業,共同運作來處理資料。輸入和輸出內容是 WebGPU 中的緩衝區。
為說明如何在 WebGPU 中使用運算著色器,我們將運用矩陣乘法 (機器學習中常見的演算法,如下所示)。
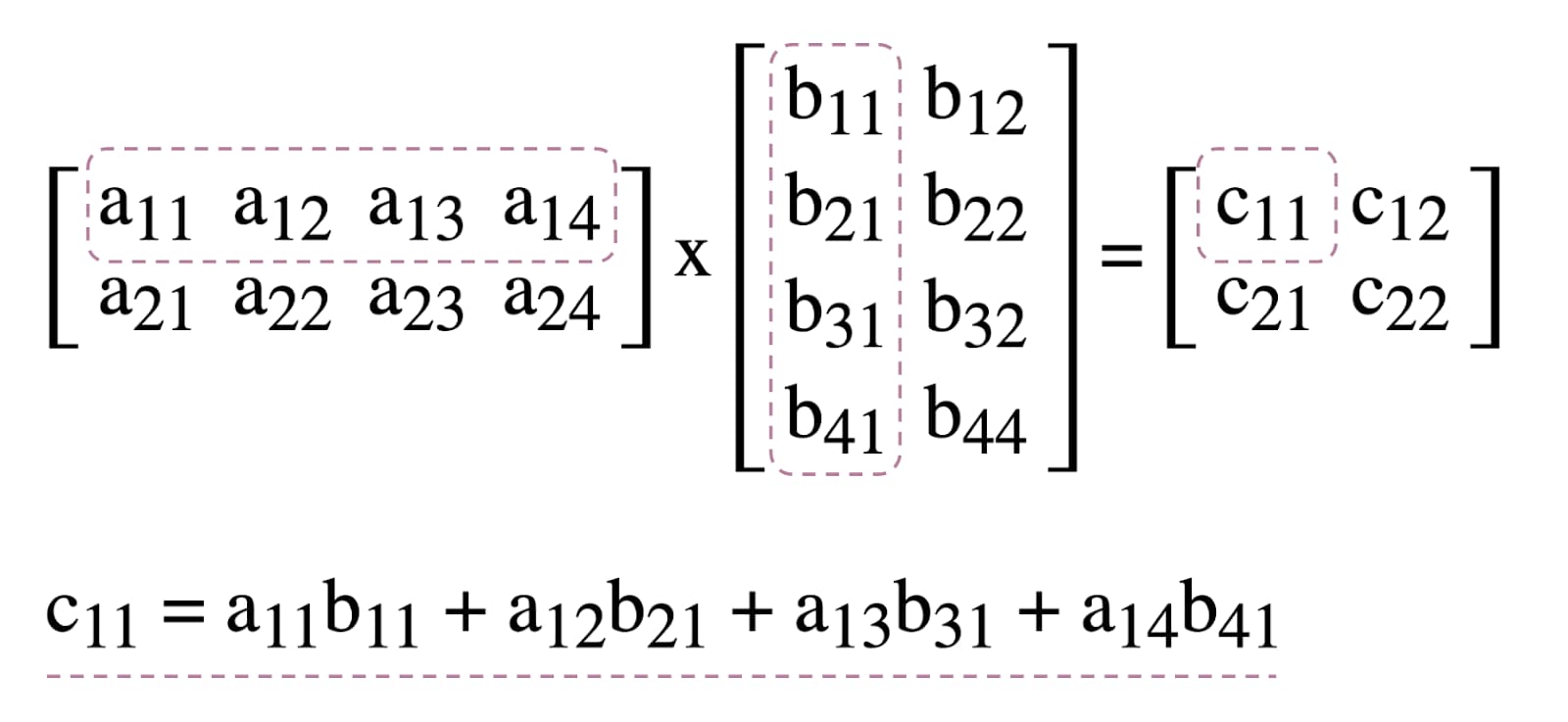
簡單來說,我們將進行下列事項:
- 建立三個 GPU 緩衝區 (兩個用於要相乘的矩陣,一個用於結果矩陣)
- 說明運算著色器的輸入和輸出
- 編譯運算著色器程式碼
- 設定運算管道
- 將編碼指令批次提交至 GPU
- 讀取結果矩陣 GPU 緩衝區
建立 GPU 緩衝區
為求簡單,矩陣會以浮點數清單表示。第一個元素是列數,第二個元素是欄數,其餘則是矩陣的實際數字。

這三個 GPU 緩衝區都是儲存緩衝區,因為我們需要在運算著色器中儲存及擷取資料。這說明瞭為何所有 GPU 緩衝區用量標記都包含 GPUBufferUsage.STORAGE。結果矩陣使用情形標記也會有
GPUBufferUsage.COPY_SRC,因為所有 GPU 佇列指令執行完畢後,系統會將其複製到另一個緩衝區以供讀取。
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
繫結群組版面配置和繫結群組
綁定群組版面配置和綁定群組的概念是 WebGPU 專屬。繫結群組版面配置會定義著色器預期的輸入/輸出介面,而繫結群組則代表著色器的實際輸入/輸出資料。
在下列範例中,繫結群組版面配置會在編號項目繫結 0、1 預期兩個唯讀儲存空間緩衝區,並在 2 預期一個儲存空間緩衝區,供運算著色器使用。另一方面,為這個繫結群組版面配置定義的繫結群組,會將 GPU 緩衝區與項目建立關聯:gpuBufferFirstMatrix 與繫結 0 建立關聯、gpuBufferSecondMatrix 與繫結 1 建立關聯,以及 resultMatrixBuffer 與繫結 2 建立關聯。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
運算著色器程式碼
矩陣相乘的運算著色器程式碼是以 WGSL (WebGPU 著色器語言) 編寫,可輕鬆轉換為 SPIR-V。以下是標示為 var<storage> 的三個儲存空間緩衝區,詳細說明請見下文。程式會使用 firstMatrix 和 secondMatrix 做為輸入內容,並以 resultMatrix 做為輸出內容。
請注意,每個儲存空間緩衝區都有一個 binding 裝飾項目,對應至上方宣告的繫結群組版面配置和繫結群組中定義的相同索引。
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
設定 pipeline
運算管道是實際描述要執行運算作業的物件。呼叫 device.createComputePipeline() 即可建立該物件。
這個方法會採用兩個引數:我們稍早建立的繫結群組版面配置,以及定義運算著色器進入點 (main WGSL 函式) 的運算階段,以及使用 device.createShaderModule() 建立的實際運算著色器模組。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
提交指令
使用三個 GPU 緩衝區和具有繫結群組版面配置的運算管道例項化繫結群組後,就可以使用這些項目。
我們將使用 commandEncoder.beginComputePass() 啟動可程式化運算傳遞編碼器。我們會使用這個項目編碼 GPU 指令,執行矩陣乘法。使用 passEncoder.setPipeline(computePipeline) 設定管道,並使用 passEncoder.setBindGroup(0, bindGroup) 在索引 0 處繫結群組。索引 0 對應至 WGSL 程式碼中的 group(0) 裝飾。
現在,我們來談談這個運算著色器如何在 GPU 上執行。我們的目標是逐步為結果矩陣的每個儲存格平行執行這個程式。舉例來說,如果結果矩陣的大小為 16 x 32,如要在 @workgroup_size(8, 8) 上編碼執行指令,我們會呼叫 passEncoder.dispatchWorkgroups(2, 4) 或 passEncoder.dispatchWorkgroups(16 / 8, 32 / 8)。第一個引數「x」是第一個維度,第二個引數「y」是第二個維度,而最後一個引數「z」是第三個維度,由於我們不需要這個維度,因此預設為 1。在 GPU 運算領域中,將指令編碼,以便在一組資料上執行核心函式,稱為「分派」。
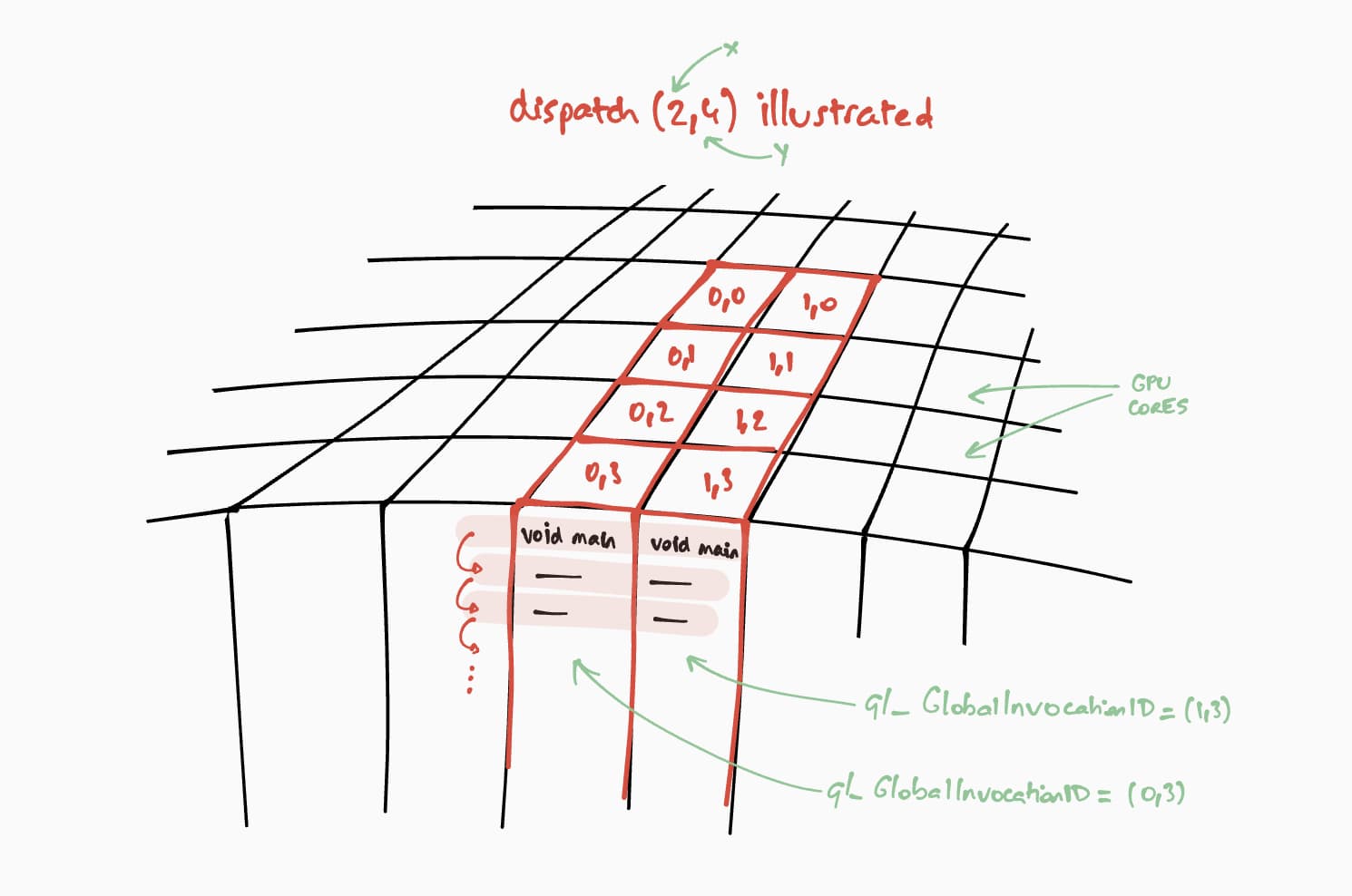
運算著色器的工作群組格線大小在 WGSL 程式碼中為 (8, 8)。因此,分別代表第一個矩陣列數和第二個矩陣欄數的「x」和「y」會除以 8。這樣一來,我們現在就能使用 passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) 傳送運算呼叫。要執行的工作群組格線數量是 dispatchWorkgroups() 引數。
如上圖所示,每個著色器都會存取專屬的 builtin(global_invocation_id) 物件,用來判斷要計算哪個結果矩陣儲存格。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
如要結束運算傳遞編碼器,請呼叫 passEncoder.end()。接著,建立 GPU 緩衝區,做為複製結果矩陣緩衝區的目的地 (使用 copyBufferToBuffer)。最後,使用 copyEncoder.finish() 完成編碼指令,並透過呼叫 device.queue.submit() 和 GPU 指令,將這些指令提交至 GPU 裝置佇列。
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
讀取結果矩陣
讀取結果矩陣非常簡單,只要使用 GPUMapMode.READ 呼叫 gpuReadBuffer.mapAsync(),並等待傳回的 Promise 解決即可,這表示 GPU 緩衝區現在已對應。此時,您可以使用 gpuReadBuffer.getMappedRange() 取得對應的範圍。
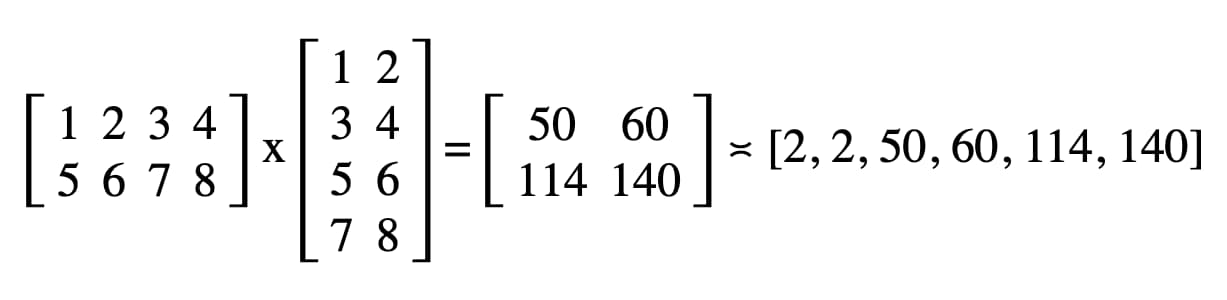
在我們的程式碼中,記錄在開發人員工具 JavaScript 控制台中的結果是「2, 2, 50, 60, 114, 140」。
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
恭喜!你做到了。您可以試玩範例。
最後一個訣竅
如要讓程式碼更容易閱讀,其中一個方法是使用計算管道的便利 getBindGroupLayout 方法,從著色器模組推斷繫結群組版面配置。這個訣竅可讓您不必建立自訂繫結群組版面配置,也不必在運算管道中指定管道版面配置,如下所示。
如要查看先前範例的 getBindGroupLayout 說明,請參閱這篇文章。
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
效能發現項目
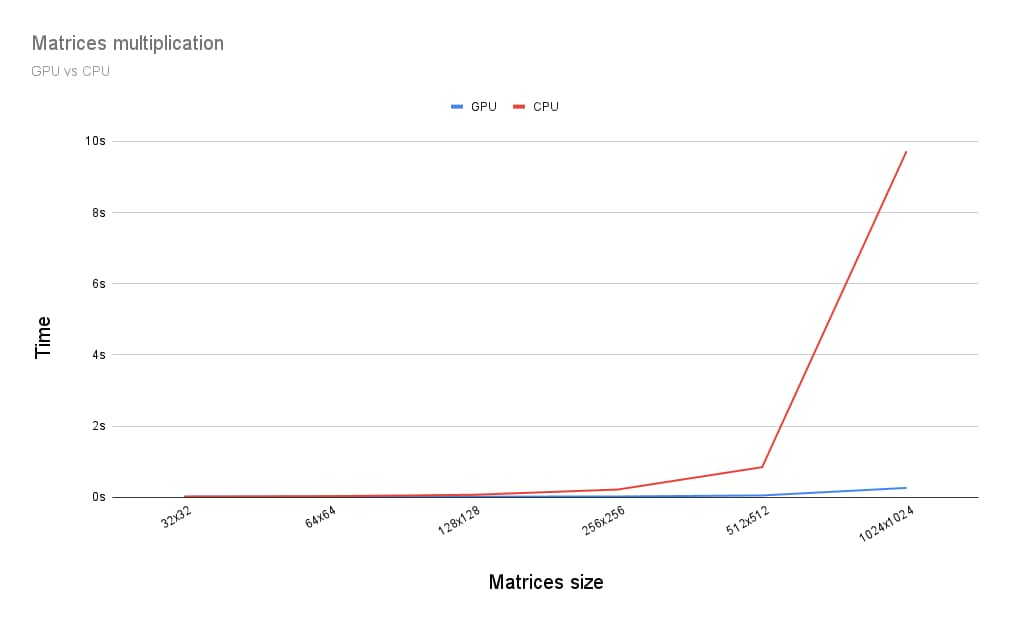
那麼,在 GPU 上執行矩陣乘法與在 CPU 上執行有何不同?為此,我為 CPU 編寫了上述程式。如下圖所示,當矩陣大小大於 256 x 256 時,充分運用 GPU 效能似乎是顯而易見的選擇。
這篇文章只是我探索 WebGPU 的開端。我們很快就會發布更多文章,深入探討 GPU 運算,以及 WebGPU 中算繪 (畫布、紋理、取樣器) 的運作方式。