
이 게시물에서는 실험적인 WebGPU API를 예시를 통해 살펴보고 GPU를 사용하여 데이터 병렬 계산을 시작하는 방법을 알아봅니다.

게시: 2019년 8월 28일, 최종 업데이트: 2025년 8월 12일
배경
이미 알고 계시겠지만 그래픽 처리 장치 (GPU)는 원래 그래픽 처리에 특화된 컴퓨터 내 전자 하위 시스템입니다. 하지만 지난 10년 동안 GPU의 고유한 아키텍처를 활용하면서 개발자가 3D 그래픽을 렌더링할 뿐만 아니라 다양한 유형의 알고리즘을 구현할 수 있는 보다 유연한 아키텍처로 발전했습니다. 이러한 기능을 GPU 컴퓨팅이라고 하며, 범용 과학 컴퓨팅을 위한 보조 프로세서로 GPU를 사용하는 것을 범용 GPU (GPGPU) 프로그래밍이라고 합니다.
GPU 컴퓨팅은 최근 머신러닝 붐에 크게 기여했습니다. 컨볼루션 신경망과 기타 모델이 아키텍처를 활용하여 GPU에서 더 효율적으로 실행될 수 있기 때문입니다. 현재 웹 플랫폼에는 GPU 컴퓨팅 기능이 부족하므로 W3C의 '웹용 GPU' 커뮤니티 그룹에서는 대부분의 현재 기기에서 사용할 수 있는 최신 GPU API를 노출하는 API를 설계하고 있습니다. 이 API의 이름은 WebGPU입니다.
WebGPU는 WebGL과 같은 하위 수준 API입니다. 매우 강력하고 장황합니다. 하지만 괜찮습니다. 우리가 원하는 것은 성능입니다.
이 도움말에서는 WebGPU의 GPU 컴퓨팅 부분에 중점을 둘 것입니다. 솔직히 말해, 여러분이 직접 사용해 볼 수 있도록 기본적인 내용만 다루겠습니다. 향후 게시물에서는 WebGPU 렌더링 (캔버스, 텍스처 등)을 자세히 다룰 예정입니다.
GPU 액세스
WebGPU에서는 GPU에 쉽게 액세스할 수 있습니다. navigator.gpu.requestAdapter()를 호출하면 GPU 어댑터로 비동기적으로 확인되는 JavaScript 프라미스가 반환됩니다. 이 어댑터를 그래픽 카드라고 생각하면 됩니다. 통합(CPU와 동일한 칩에 있음) 또는 개별 (일반적으로 성능이 더 우수하지만 전력을 더 많이 사용하는 PCIe 카드)일 수 있습니다.
GPU 어댑터가 있으면 adapter.requestDevice()를 호출하여 GPU 연산을 실행하는 데 사용할 GPU 기기로 확인되는 프로미스를 가져옵니다.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
두 함수 모두 원하는 어댑터 (전원 기본 설정)와 기기 (확장 프로그램, 제한)를 구체적으로 지정할 수 있는 옵션을 사용합니다. 간단하게 설명하기 위해 이 도움말에서는 기본 옵션을 사용합니다.
쓰기 버퍼 메모리
JavaScript를 사용하여 GPU의 메모리에 데이터를 쓰는 방법을 살펴보겠습니다. 최신 웹브라우저에서 사용되는 샌드박스 모델로 인해 이 프로세스는 간단하지 않습니다.
아래 예에서는 GPU에서 액세스할 수 있는 버퍼 메모리에 4바이트를 쓰는 방법을 보여줍니다. 버퍼의 크기와 사용량을 가져오는 device.createBuffer()를 호출합니다. 이 특정 호출에는 사용 플래그 GPUBufferUsage.MAP_WRITE가 필요하지 않지만 이 버퍼에 쓰기를 원한다고 명시적으로 지정해 보겠습니다. mappedAtCreation가 true로 설정되어 생성 시 매핑된 GPU 버퍼 객체가 생성됩니다. 그러면 GPU 버퍼 메서드 getMappedRange()를 호출하여 연결된 원시 바이너리 데이터 버퍼를 검색할 수 있습니다.
ArrayBuffer를 사용해 본 적이 있다면 바이트 쓰기가 익숙할 것입니다. TypedArray를 사용하고 값을 복사하세요.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
이 시점에서 GPU 버퍼가 매핑됩니다. 즉, CPU가 소유하고 JavaScript에서 읽기/쓰기로 액세스할 수 있습니다. GPU가 액세스할 수 있도록 매핑을 해제해야 하며 이는 gpuBuffer.unmap()를 호출하는 것만큼 간단합니다.
매핑됨/매핑되지 않음 개념은 GPU와 CPU가 동시에 메모리에 액세스하는 경합 상태를 방지하는 데 필요합니다.
버퍼 메모리 읽기
이제 GPU 버퍼를 다른 GPU 버퍼에 복사하고 다시 읽는 방법을 살펴보겠습니다.
첫 번째 GPU 버퍼에 쓰고 두 번째 GPU 버퍼에 복사하려고 하므로 새 사용 플래그 GPUBufferUsage.COPY_SRC가 필요합니다. 두 번째 GPU 버퍼는 이번에는 device.createBuffer()를 사용하여 매핑되지 않은 상태로 생성됩니다. 첫 번째 GPU 버퍼의 대상으로 사용되고 GPU 복사 명령어가 실행되면 JavaScript에서 읽히므로 사용 플래그는 GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ입니다.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
GPU는 독립적인 보조 프로세서이므로 모든 GPU 명령어는 비동기식으로 실행됩니다. 이러한 이유로 필요할 때 GPU 명령어 목록이 빌드되고 일괄적으로 전송됩니다. WebGPU에서 device.createCommandEncoder()에 의해 반환되는 GPU 명령어 인코더는 언젠가 GPU로 전송될 '버퍼링된' 명령어의 일괄 처리를 빌드하는 JavaScript 객체입니다. 반면 GPUBuffer의 메서드는 '버퍼링되지 않음'입니다. 즉, 호출될 때 원자적으로 실행됩니다.
GPU 명령어 인코더가 있으면 아래와 같이 copyEncoder.copyBufferToBuffer()를 호출하여 나중에 실행할 명령어 대기열에 이 명령어를 추가합니다.
마지막으로 copyEncoder.finish()를 호출하여 인코딩 명령어를 완료하고 GPU 기기 명령어 대기열에 제출합니다. 이 대기열은 GPU 명령어를 인수로 사용하여 device.queue.submit()를 통해 제출된 항목을 처리합니다.
이렇게 하면 배열에 저장된 모든 명령어가 순서대로 원자적으로 실행됩니다.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
이 시점에서 GPU 대기열 명령어가 전송되었지만 반드시 실행되지는 않습니다.
두 번째 GPU 버퍼를 읽으려면 GPUMapMode.READ로 gpuReadBuffer.mapAsync()를 호출합니다. GPU 버퍼가 매핑될 때 확인되는 프라미스를 반환합니다. 그런 다음 대기열에 추가된 모든 GPU 명령어가 실행되면 첫 번째 GPU 버퍼와 동일한 값이 포함된 gpuReadBuffer.getMappedRange()로 매핑된 범위를 가져옵니다.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
간단히 말해 버퍼 메모리 작업과 관련하여 기억해야 할 사항은 다음과 같습니다.
- GPU 버퍼는 기기 대기열 제출에 사용하려면 매핑 해제해야 합니다.
- 매핑되면 JavaScript에서 GPU 버퍼를 읽고 쓸 수 있습니다.
mappedAtCreation이 true로 설정된mapAsync()및createBuffer()가 호출되면 GPU 버퍼가 매핑됩니다.
셰이더 프로그래밍
GPU에서 실행되며 연산만 실행하는 프로그램 (삼각형을 그리지 않음)을 컴퓨트 셰이더라고 합니다. 데이터를 처리하기 위해 함께 작동하는 수백 개의 GPU 코어 (CPU 코어보다 작음)에 의해 병렬로 실행됩니다. 입력과 출력은 WebGPU의 버퍼입니다.
WebGPU에서 컴퓨트 셰이더의 사용을 설명하기 위해 아래에 설명된 머신러닝의 일반적인 알고리즘인 행렬 곱셈을 사용해 보겠습니다.
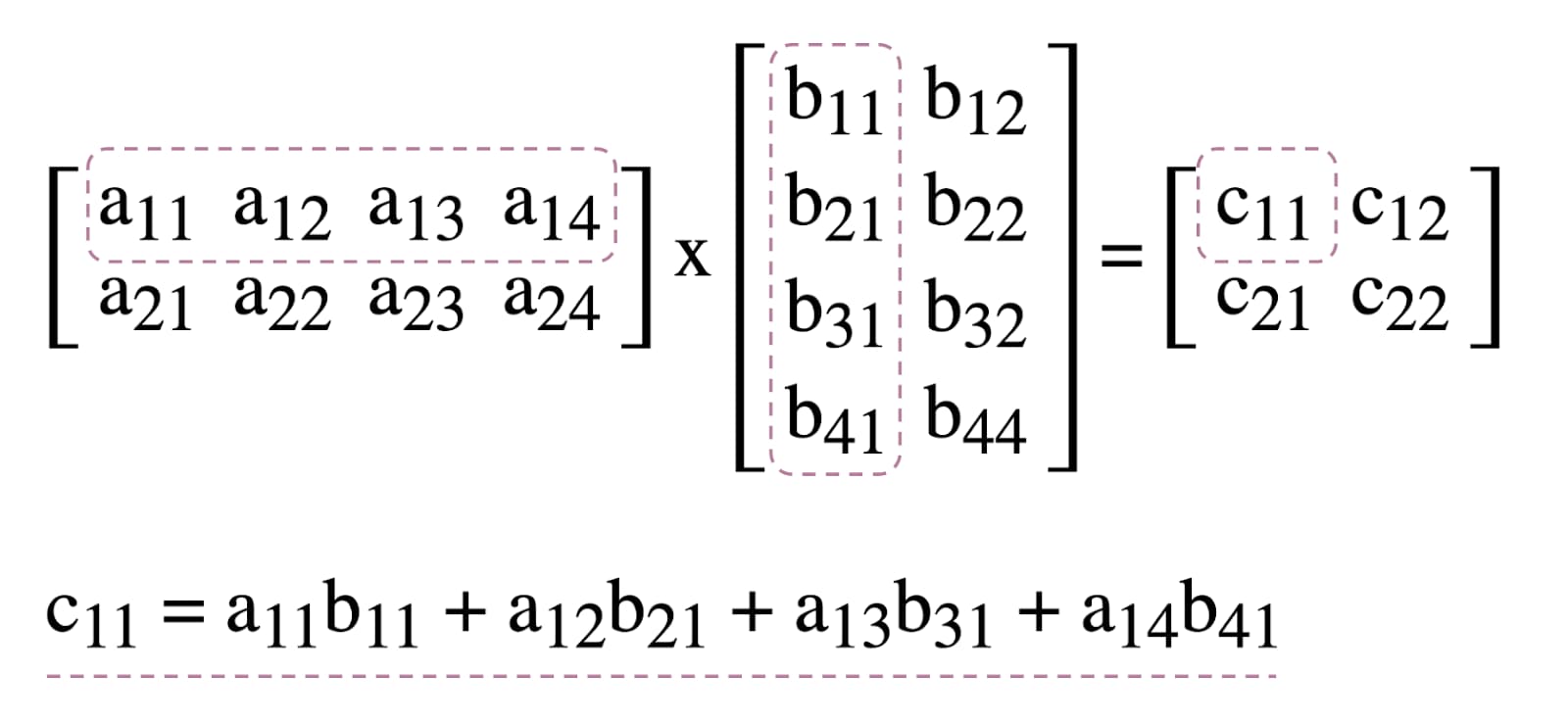
간단히 말해 다음과 같은 작업을 수행할 예정입니다.
- GPU 버퍼 3개 (곱할 행렬용 2개, 결과 행렬용 1개)를 만듭니다.
- 컴퓨트 셰이더의 입력 및 출력 설명
- 컴퓨팅 셰이더 코드 컴파일
- 컴퓨팅 파이프라인 설정
- 인코딩된 명령어를 GPU에 일괄 제출
- 결과 매트릭스 GPU 버퍼 읽기
GPU 버퍼 생성
간단하게 하기 위해 행렬은 부동 소수점 숫자의 목록으로 표현됩니다. 첫 번째 요소는 행 수, 두 번째 요소는 열 수, 나머지는 행렬의 실제 숫자입니다.

3개의 GPU 버퍼는 컴퓨트 셰이더에서 데이터를 저장하고 검색해야 하므로 스토리지 버퍼입니다. 이로 인해 GPU 버퍼 사용 플래그에 모두 GPUBufferUsage.STORAGE가 포함됩니다. 결과 행렬 사용 플래그에도 GPUBufferUsage.COPY_SRC가 있습니다. 모든 GPU 대기열 명령어가 실행되면 읽기를 위해 다른 버퍼에 복사되기 때문입니다.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
바인드 그룹 레이아웃 및 바인드 그룹
바인드 그룹 레이아웃과 바인드 그룹의 개념은 WebGPU에만 해당합니다. 바인드 그룹 레이아웃은 셰이더에서 예상하는 입력/출력 인터페이스를 정의하는 반면 바인드 그룹은 셰이더의 실제 입력/출력 데이터를 나타냅니다.
아래 예시에서 바인드 그룹 레이아웃은 번호가 지정된 항목 바인딩 0, 1에 읽기 전용 저장소 버퍼 두 개와 컴퓨트 셰이더용 2에 저장소 버퍼 하나를 예상합니다.
반면 이 바인드 그룹 레이아웃에 정의된 바인드 그룹은 GPU 버퍼를 항목에 연결합니다. gpuBufferFirstMatrix을 바인드 0에, gpuBufferSecondMatrix을 바인드 1에, resultMatrixBuffer을 바인드 2에 연결합니다.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
컴퓨팅 셰이더 코드
행렬을 곱하는 컴퓨팅 셰이더 코드는 SPIR-V로 쉽게 변환할 수 있는 WebGPU 셰이더 언어인 WGSL로 작성됩니다. 자세히 설명하지는 않겠지만 아래에 var<storage>로 식별된 세 개의 스토리지 버퍼가 있습니다. 프로그램은 firstMatrix 및 secondMatrix을 입력으로 사용하고 resultMatrix을 출력으로 사용합니다.
각 스토리지 버퍼에는 위에 선언된 바인드 그룹 레이아웃 및 바인드 그룹에 정의된 동일한 인덱스에 해당하는 binding 데코레이션이 사용됩니다.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
파이프라인 설정
컴퓨팅 파이프라인은 실제로 실행할 컴퓨팅 작업을 설명하는 객체입니다. device.createComputePipeline()를 호출하여 만듭니다.
이 함수는 두 개의 인수를 사용합니다. 하나는 앞에서 만든 바인드 그룹 레이아웃이고 다른 하나는 컴퓨트 셰이더의 진입점 (main WGSL 함수)과 device.createShaderModule()로 만든 실제 컴퓨트 셰이더 모듈을 정의하는 컴퓨트 단계입니다.
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
명령어 제출
3개의 GPU 버퍼와 바인드 그룹 레이아웃이 있는 컴퓨팅 파이프라인으로 바인드 그룹을 인스턴스화한 후에는 이를 사용할 수 있습니다.
commandEncoder.beginComputePass()로 프로그래밍 가능한 컴퓨팅 패스 인코더를 시작해 보겠습니다. 이를 사용하여 행렬 곱셈을 실행하는 GPU 명령어를 인코딩합니다. passEncoder.setPipeline(computePipeline)로 파이프라인을 설정하고 passEncoder.setBindGroup(0, bindGroup)로 색인 0에서 바인드 그룹을 설정합니다. 인덱스 0은 WGSL 코드의 group(0) 데코레이션에 해당합니다.
이제 이 컴퓨트 셰이더가 GPU에서 어떻게 실행되는지 살펴보겠습니다. 목표는 결과 행렬의 각 셀에 대해 이 프로그램을 단계별로 병렬로 실행하는 것입니다. 예를 들어 크기가 16x32인 결과 행렬의 경우 @workgroup_size(8, 8)에서 실행 명령어를 인코딩하려면 passEncoder.dispatchWorkgroups(2, 4) 또는 passEncoder.dispatchWorkgroups(16 / 8, 32 / 8)를 호출합니다.
첫 번째 인수 'x'는 첫 번째 차원이고, 두 번째 인수 'y'는 두 번째 차원이며, 마지막 인수 'z'는 세 번째 차원입니다. 여기서는 필요하지 않으므로 기본값은 1입니다.
GPU 컴퓨팅 세계에서 데이터 세트에서 커널 함수를 실행하는 명령어를 인코딩하는 것을 디스패치라고 합니다.
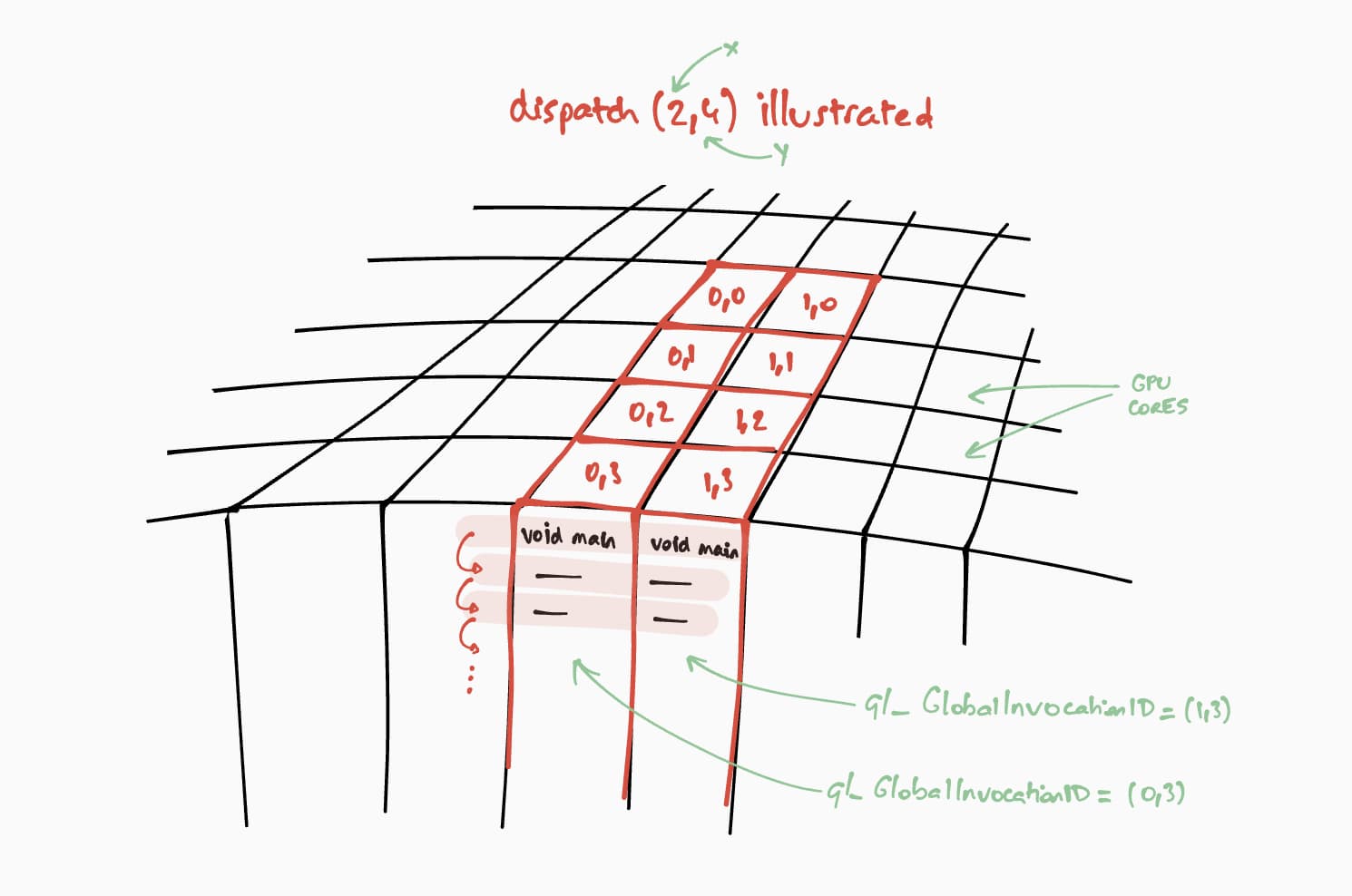
컴퓨팅 셰이더의 작업 그룹 그리드 크기는 WGSL 코드에서 (8, 8)입니다. 따라서 첫 번째 행렬의 행 수와 두 번째 행렬의 열 수인 'x'와 'y'는 각각 8로 나뉩니다. 이제 passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8)로 컴퓨팅 호출을 디스패치할 수 있습니다. 실행할 작업 그룹 그리드 수는 dispatchWorkgroups() 인수입니다.
위 그림에서 볼 수 있듯이 각 셰이더는 어떤 결과 행렬 셀을 계산해야 하는지 알기 위해 사용되는 고유한 builtin(global_invocation_id) 객체에 액세스할 수 있습니다.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
컴퓨트 패스 인코더를 종료하려면 passEncoder.end()를 호출합니다. 그런 다음 copyBufferToBuffer를 사용하여 결과 행렬 버퍼를 복사할 대상으로 사용할 GPU 버퍼를 만듭니다. 마지막으로 copyEncoder.finish()로 인코딩 명령어를 완료하고 GPU 명령어를 사용하여 device.queue.submit()를 호출하여 GPU 기기 대기열에 제출합니다.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
결과 행렬 읽기
결과 행렬을 읽는 것은 GPUMapMode.READ로 gpuReadBuffer.mapAsync()를 호출하고 반환되는 프로미스가 해결되기를 기다리는 것만큼 쉽습니다. 이는 GPU 버퍼가 이제 매핑되었음을 나타냅니다. 이 시점에서 gpuReadBuffer.getMappedRange()를 사용하여 매핑된 범위를 가져올 수 있습니다.
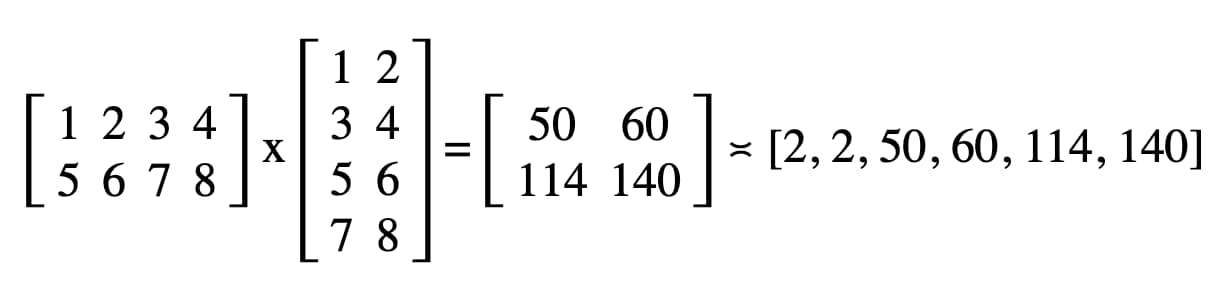
코드에서 DevTools JavaScript 콘솔에 기록된 결과는 '2, 2, 50, 60, 114, 140'입니다.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
축하합니다. 기본 검색 엔진이 Google로 설정된 것입니다. 샘플을 사용해 볼 수 있습니다.
마지막 트릭
코드를 더 쉽게 읽을 수 있는 한 가지 방법은 컴퓨트 파이프라인의 편리한 getBindGroupLayout 메서드를 사용하여 셰이더 모듈에서 바인드 그룹 레이아웃을 추론하는 것입니다. 이 방법을 사용하면 아래와 같이 맞춤 바인드 그룹 레이아웃을 만들고 컴퓨팅 파이프라인에서 파이프라인 레이아웃을 지정할 필요가 없습니다.
이전 샘플의 getBindGroupLayout 그림을 확인할 수 있습니다.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
성능 발견 항목
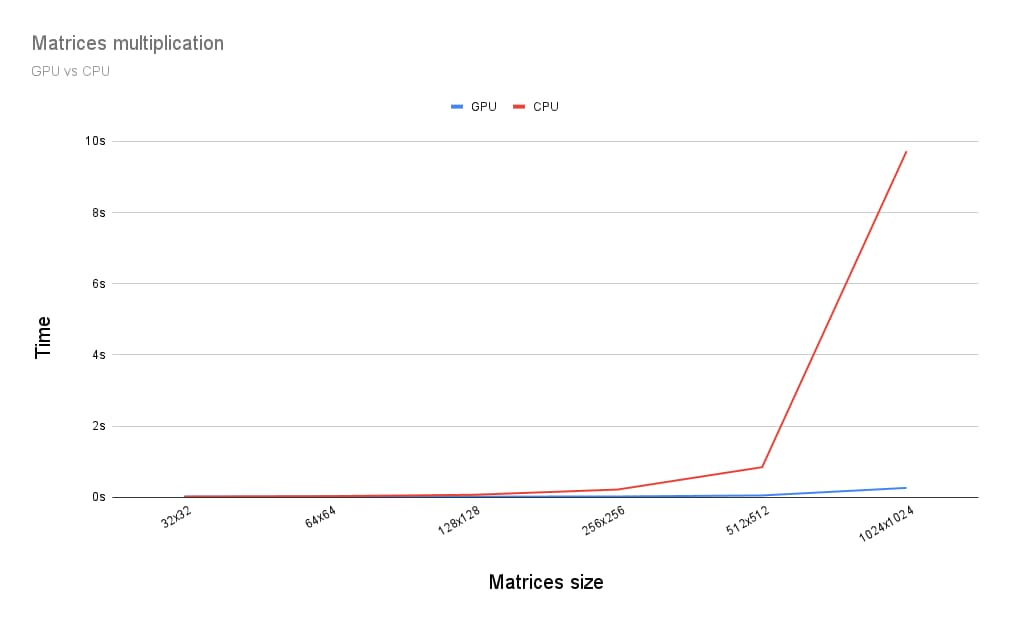
GPU에서 행렬 곱셈을 실행하는 것은 CPU에서 실행하는 것과 어떻게 다를까요? 이를 확인하기 위해 CPU용으로 방금 설명한 프로그램을 작성했습니다. 아래 그래프에서 볼 수 있듯이 행렬의 크기가 256x256보다 큰 경우 GPU의 모든 성능을 사용하는 것이 명백한 선택인 것 같습니다.
이 도움말은 WebGPU를 탐색하는 여정의 시작에 불과했습니다. GPU 컴퓨팅과 WebGPU에서 렌더링(캔버스, 텍스처, 샘플러)이 작동하는 방식에 관한 자세한 내용을 다루는 아티클이 곧 게시될 예정입니다.