
Postingan ini membahas WebGPU API eksperimental melalui contoh dan membantu Anda mulai melakukan komputasi paralel data menggunakan GPU.

Dipublikasikan: 28 Agustus 2019, Terakhir diperbarui: 12 Agustus 2025
Latar belakang
Seperti yang mungkin sudah Anda ketahui, Unit Pemrosesan Grafis (GPU) adalah subsistem elektronik dalam komputer yang awalnya dikhususkan untuk memproses grafis. Namun, dalam 10 tahun terakhir, Vulkan telah berkembang menjadi arsitektur yang lebih fleksibel, sehingga memungkinkan developer menerapkan berbagai jenis algoritma, bukan hanya merender grafik 3D, sekaligus memanfaatkan arsitektur GPU yang unik. Kemampuan ini disebut sebagai GPU Compute, dan penggunaan GPU sebagai koprosesor untuk komputasi ilmiah serbaguna disebut pemrograman GPU serbaguna (GPGPU).
GPU Compute telah memberikan kontribusi yang signifikan terhadap booming machine learning baru-baru ini, karena jaringan saraf konvolusional dan model lainnya dapat memanfaatkan arsitektur ini untuk berjalan lebih efisien di GPU. Dengan kurangnya kemampuan Komputasi GPU di Platform Web saat ini, Grup Komunitas "GPU untuk Web" W3C sedang mendesain API untuk mengekspos API GPU modern yang tersedia di sebagian besar perangkat saat ini. API ini disebut WebGPU.
WebGPU adalah API level rendah, seperti WebGL. Alat ini sangat canggih dan cukup verbose, seperti yang akan Anda lihat. Tapi tidak masalah. Yang kami cari adalah performa.
Dalam artikel ini, saya akan berfokus pada bagian GPU Compute WebGPU dan, terus terang, saya baru menyentuh permukaannya, sehingga Anda dapat mulai bereksperimen sendiri. Saya akan membahas lebih dalam dan mengulas rendering WebGPU (canvas, tekstur, dll.) dalam artikel mendatang.
Mengakses GPU
Mengakses GPU sangat mudah di WebGPU. Memanggil navigator.gpu.requestAdapter()
akan menampilkan promise JavaScript yang akan diselesaikan secara asinkron dengan adaptor GPU. Anggap adaptor ini sebagai kartu grafis. GPU dapat berupa GPU terintegrasi
(pada chip yang sama dengan CPU) atau GPU diskrit (biasanya kartu PCIe yang memiliki performa lebih baik, tetapi menggunakan lebih banyak daya).
Setelah memiliki adaptor GPU, panggil adapter.requestDevice() untuk mendapatkan janji yang akan diselesaikan dengan perangkat GPU yang akan Anda gunakan untuk melakukan beberapa komputasi GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Kedua fungsi mengambil opsi yang memungkinkan Anda menentukan jenis adaptor (preferensi daya) dan perangkat (ekstensi, batas) yang Anda inginkan. Untuk memudahkan, kita akan menggunakan opsi default dalam artikel ini.
Menulis memori buffer
Mari kita lihat cara menggunakan JavaScript untuk menulis data ke memori untuk GPU. Proses ini tidak mudah karena model sandbox yang digunakan di browser web modern.
Contoh di bawah menunjukkan cara menulis empat byte ke memori buffer yang dapat diakses
dari GPU. Fungsi ini memanggil device.createBuffer() yang mengambil ukuran
buffer dan penggunaannya. Meskipun tanda penggunaan GPUBufferUsage.MAP_WRITE tidak diperlukan untuk panggilan khusus ini, mari kita nyatakan secara eksplisit bahwa kita ingin menulis ke buffer ini. Hal ini menghasilkan objek buffer GPU yang dipetakan saat pembuatan berkat mappedAtCreation yang ditetapkan ke benar (true). Kemudian, buffer data biner mentah terkait dapat diambil dengan memanggil metode buffer GPU getMappedRange().
Menulis byte sudah tidak asing lagi jika Anda sudah pernah menggunakan ArrayBuffer; gunakan
TypedArray dan salin nilainya ke dalamnya.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
Pada tahap ini, buffer GPU dipetakan, yang berarti dimiliki oleh CPU, dan
dapat diakses dalam baca/tulis dari JavaScript. Agar GPU dapat mengaksesnya, GPU harus dibatalkan pemetaannya yang semudah memanggil gpuBuffer.unmap().
Konsep dipetakan/tidak dipetakan diperlukan untuk mencegah kondisi persaingan saat GPU dan CPU mengakses memori secara bersamaan.
Membaca memori buffer
Sekarang mari kita lihat cara menyalin buffer GPU ke buffer GPU lain dan membacanya kembali.
Karena kita menulis di buffer GPU pertama dan ingin menyalinnya ke buffer GPU kedua, diperlukan flag penggunaan baru GPUBufferUsage.COPY_SRC. Buffer GPU kedua dibuat dalam status tidak dipetakan kali ini dengan
device.createBuffer(). Flag penggunaannya adalah GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ karena akan digunakan sebagai tujuan buffer GPU pertama
dan dibaca di JavaScript setelah perintah salinan GPU dieksekusi.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Karena GPU adalah koprosesor independen, semua perintah GPU dieksekusi secara asinkron. Itulah sebabnya ada daftar perintah GPU yang dibuat dan dikirim dalam
batch jika diperlukan. Di WebGPU, encoder perintah GPU yang ditampilkan oleh
device.createCommandEncoder()adalah objek JavaScript yang membuat batch perintah "ber-buffer" yang akan dikirim ke GPU pada suatu saat. Sebaliknya, metode di
GPUBuffer bersifat "tidak di-buffer", yang berarti metode tersebut dijalankan secara atomik
pada saat dipanggil.
Setelah Anda memiliki encoder perintah GPU, panggil copyEncoder.copyBufferToBuffer()
seperti yang ditunjukkan di bawah untuk menambahkan perintah ini ke antrean perintah untuk dieksekusi nanti.
Terakhir, selesaikan perintah encoding dengan memanggil copyEncoder.finish() dan kirimkan
perintah tersebut ke antrean perintah perangkat GPU. Antrean bertanggung jawab untuk menangani pengiriman yang dilakukan melalui device.queue.submit() dengan perintah GPU sebagai argumen.
Tindakan ini akan menjalankan semua perintah yang disimpan dalam array secara atomik secara berurutan.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
Pada tahap ini, perintah antrean GPU telah dikirim, tetapi belum tentu dieksekusi.
Untuk membaca buffer GPU kedua, panggil gpuReadBuffer.mapAsync() dengan
GPUMapMode.READ. Fungsi ini menampilkan promise yang akan di-resolve saat buffer GPU dipetakan. Kemudian, dapatkan rentang yang dipetakan dengan gpuReadBuffer.getMappedRange() yang
berisi nilai yang sama dengan buffer GPU pertama setelah semua perintah GPU yang diantrekan
dieksekusi.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Anda dapat mencoba sampel ini.
Singkatnya, berikut hal yang perlu Anda ingat terkait operasi memori buffer:
- Buffer GPU harus di-unmap agar dapat digunakan dalam pengiriman antrean perangkat.
- Saat dipetakan, buffer GPU dapat dibaca dan ditulis di JavaScript.
- Buffer GPU dipetakan saat
mapAsync()dancreateBuffer()denganmappedAtCreationditetapkan ke benar (true) dipanggil.
Pemrograman shader
Program yang berjalan di GPU yang hanya melakukan komputasi (dan tidak menggambar segitiga) disebut shader komputasi. Kernel ini dijalankan secara paralel oleh ratusan core GPU (yang lebih kecil daripada core CPU) yang beroperasi bersama untuk memproses data. Input dan outputnya adalah buffer di WebGPU.
Untuk mengilustrasikan penggunaan shader komputasi di WebGPU, kita akan bermain-main dengan perkalian matriks, algoritma umum dalam machine learning yang diilustrasikan di bawah.
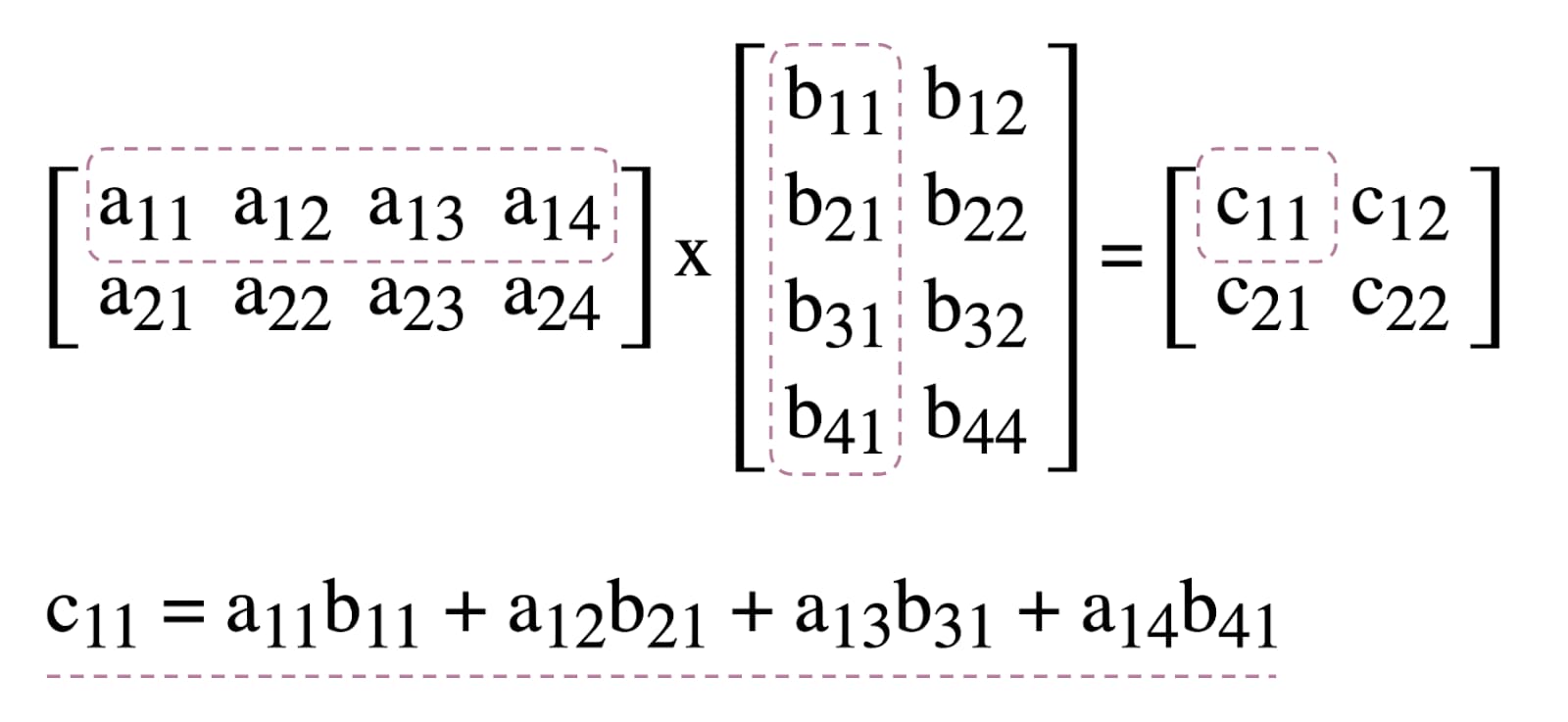
Singkatnya, berikut yang akan kita lakukan:
- Buat tiga buffer GPU (dua untuk matriks yang akan dikalikan dan satu untuk matriks hasil)
- Menjelaskan input dan output untuk shader komputasi
- Kompilasi kode shader komputasi
- Menyiapkan pipeline komputasi
- Mengirimkan perintah yang dienkode dalam batch ke GPU
- Membaca buffer GPU matriks hasil
Pembuatan Buffer GPU
Demi kesederhanaan, matriks akan direpresentasikan sebagai daftar bilangan floating point. Elemen pertama adalah jumlah baris, elemen kedua adalah jumlah kolom, dan sisanya adalah angka matriks yang sebenarnya.

Tiga buffer GPU adalah buffer penyimpanan karena kita perlu menyimpan dan mengambil data di shader komputasi. Hal ini menjelaskan mengapa tanda penggunaan buffer GPU mencakup
GPUBufferUsage.STORAGE untuk semuanya. Flag penggunaan matriks hasil juga memiliki
GPUBufferUsage.COPY_SRC karena akan disalin ke buffer lain untuk
dibaca setelah semua perintah antrean GPU dieksekusi.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Tata letak bind group dan bind group
Konsep tata letak grup bind dan grup bind khusus untuk WebGPU. Tata letak grup pengikatan menentukan antarmuka input/output yang diharapkan oleh shader, sedangkan grup pengikatan merepresentasikan data input/output aktual untuk shader.
Dalam contoh di bawah, tata letak bind group mengharapkan dua buffer penyimpanan hanya baca pada
binding entri bernomor 0, 1, dan buffer penyimpanan di 2 untuk shader komputasi.
Sebaliknya, grup pengikatan yang ditentukan untuk tata letak grup pengikatan ini, mengaitkan buffer GPU ke entri: gpuBufferFirstMatrix ke pengikatan 0, gpuBufferSecondMatrix ke pengikatan 1, dan resultMatrixBuffer ke pengikatan 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
Kode shader komputasi
Kode shader komputasi untuk mengalikan matriks ditulis dalam WGSL, yaitu
WebGPU Shader Language, yang dapat diterjemahkan dengan mudah ke SPIR-V. Tanpa
membahas secara mendetail, Anda akan menemukan tiga buffer penyimpanan yang diidentifikasi
dengan var<storage> di bawah. Program akan menggunakan firstMatrix dan secondMatrix sebagai
input dan resultMatrix sebagai output-nya.
Perhatikan bahwa setiap buffer penyimpanan memiliki dekorasi binding yang digunakan dan sesuai dengan
indeks yang sama yang ditentukan dalam tata letak bind group dan bind group yang dideklarasikan di atas.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Penyiapan pipeline
Pipeline komputasi adalah objek yang sebenarnya menjelaskan operasi komputasi
yang akan kita lakukan. Buat dengan memanggil device.createComputePipeline().
Fungsi ini memerlukan dua argumen: tata letak grup pengikatan yang kita buat sebelumnya, dan tahap komputasi yang menentukan titik entri shader komputasi (fungsi WGSL main) dan modul shader komputasi sebenarnya yang dibuat dengan device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
Pengiriman perintah
Setelah membuat instance bind group dengan tiga buffer GPU dan pipeline komputasi dengan tata letak bind group, saatnya menggunakannya.
Mari kita mulai encoder pass komputasi yang dapat diprogram dengan
commandEncoder.beginComputePass(). Kita akan menggunakannya untuk mengenkode perintah GPU
yang akan melakukan perkalian matriks. Tetapkan pipeline-nya dengan
passEncoder.setPipeline(computePipeline) dan grup pengikatnya pada indeks 0 dengan
passEncoder.setBindGroup(0, bindGroup). Indeks 0 sesuai dengan
dekorasi group(0) dalam kode WGSL.
Sekarang, mari kita bahas cara shader komputasi ini akan berjalan di GPU. Tujuan
kita adalah menjalankan program ini secara paralel untuk setiap sel matriks hasil, langkah demi langkah. Misalnya, untuk matriks hasil berukuran 16 x 32, untuk mengenkode
perintah eksekusi, di @workgroup_size(8, 8), kita akan memanggil
passEncoder.dispatchWorkgroups(2, 4) atau passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
Argumen pertama "x" adalah dimensi pertama, argumen kedua "y" adalah dimensi kedua, dan argumen terakhir "z" adalah dimensi ketiga yang secara default bernilai 1 karena kita tidak memerlukannya di sini.
Dalam dunia komputasi GPU, mengenkode perintah untuk mengeksekusi fungsi kernel pada sekumpulan data disebut pengiriman.
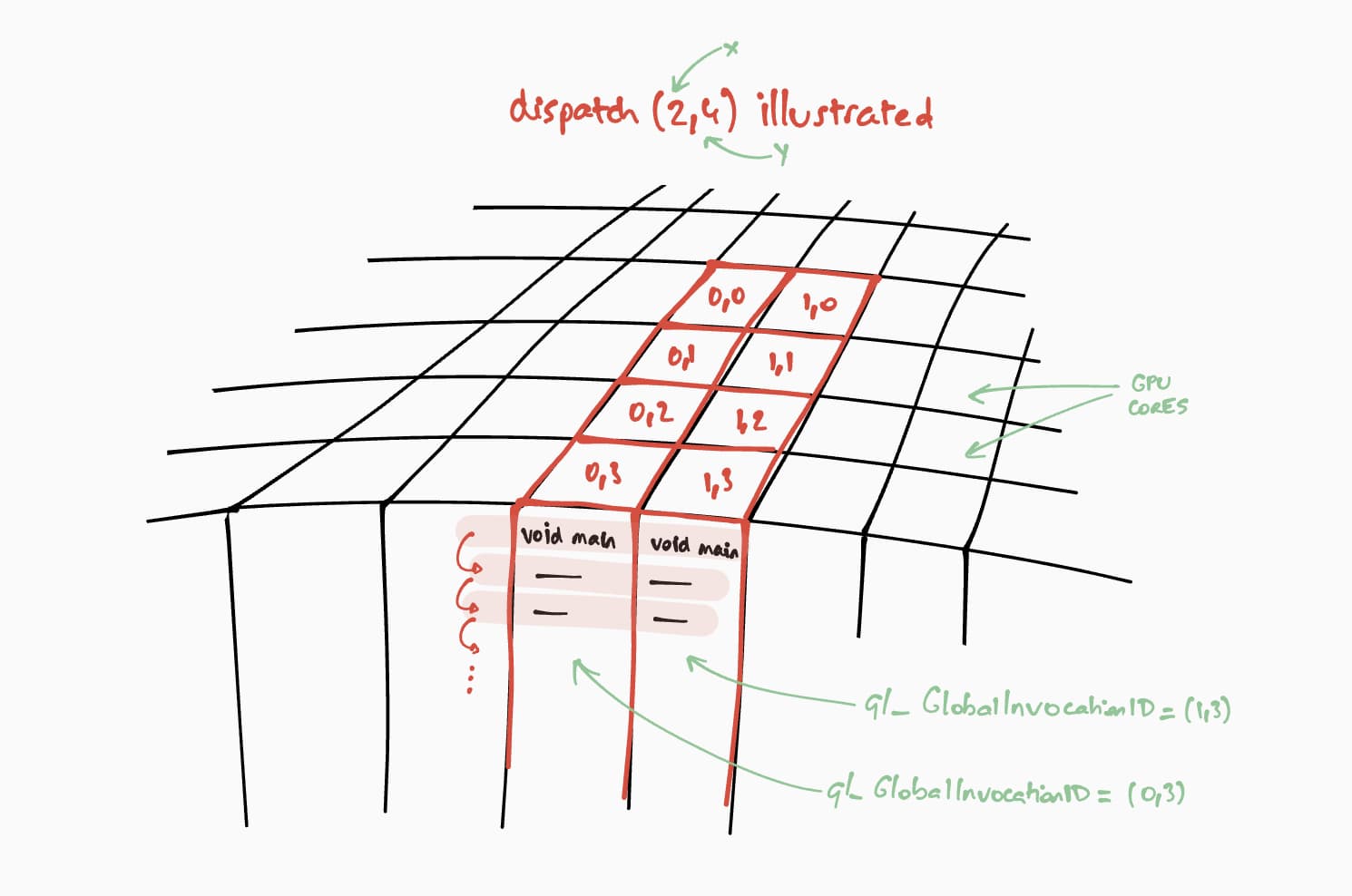
Ukuran petak workgroup untuk shader komputasi kita adalah (8, 8) dalam kode WGSL
kita. Oleh karena itu, "x" dan "y" yang masing-masing merupakan jumlah baris matriks pertama dan jumlah kolom matriks kedua akan dibagi dengan 8. Dengan begitu, kita sekarang dapat mengirimkan panggilan komputasi dengan
passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). Jumlah petak grup kerja yang akan dijalankan adalah argumen dispatchWorkgroups().
Seperti yang terlihat pada gambar di atas, setiap shader akan memiliki akses ke objek
builtin(global_invocation_id) unik yang akan digunakan untuk mengetahui sel matriks
hasil mana yang akan dihitung.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Untuk mengakhiri encoder compute pass, panggil passEncoder.end(). Kemudian, buat buffer GPU untuk digunakan sebagai tujuan menyalin buffer matriks hasil dengan copyBufferToBuffer. Terakhir, selesaikan perintah encoding dengan
copyEncoder.finish() dan kirimkan perintah tersebut ke antrean perangkat GPU dengan memanggil
device.queue.submit() dengan perintah GPU.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Membaca matriks hasil
Membaca matriks hasil semudah memanggil gpuReadBuffer.mapAsync() dengan
GPUMapMode.READ dan menunggu promise yang ditampilkan diselesaikan yang menunjukkan
buffer GPU kini dipetakan. Pada tahap ini, rentang yang dipetakan dapat diperoleh dengan gpuReadBuffer.getMappedRange().
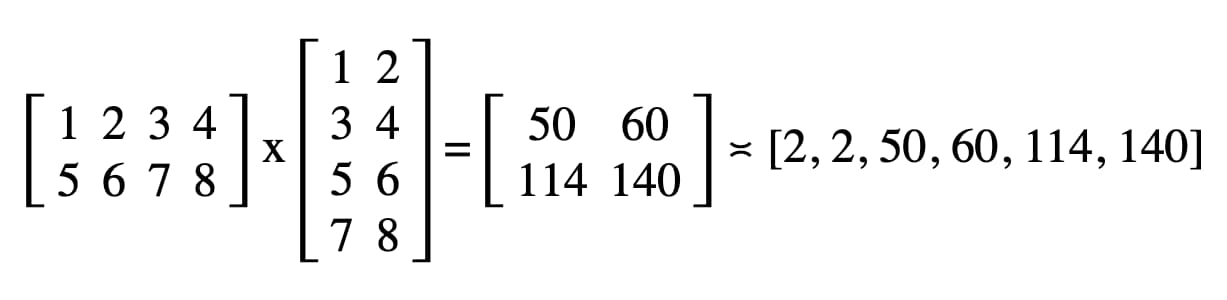
Dalam kode kita, hasil yang dicatat di konsol JavaScript DevTools adalah "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Selamat! Anda berhasil. Anda dapat bermain dengan sampel.
Trik terakhir
Salah satu cara untuk membuat kode Anda lebih mudah dibaca adalah dengan menggunakan metode getBindGroupLayout praktis dari pipeline komputasi untuk menyimpulkan tata letak grup pengikatan dari modul shader. Trik ini menghilangkan kebutuhan untuk membuat tata letak bind group kustom dan menentukan tata letak pipeline dalam pipeline komputasi seperti yang dapat Anda lihat di bawah.
Ilustrasi getBindGroupLayout untuk contoh sebelumnya tersedia.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Temuan performa
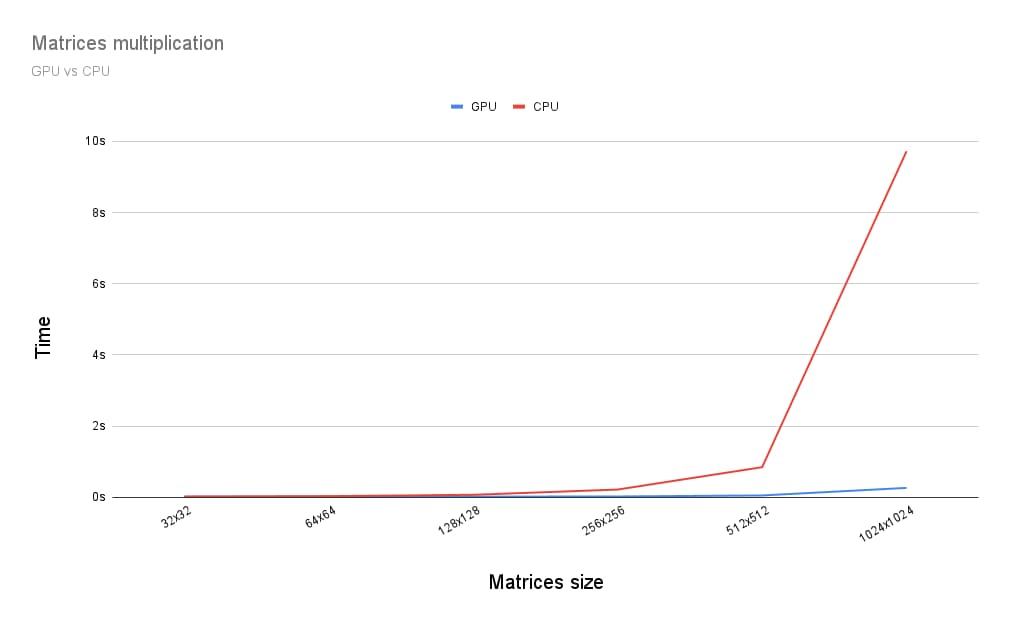
Jadi, bagaimana perbandingan menjalankan perkalian matriks di GPU dengan menjalankannya di CPU? Untuk mengetahuinya, saya menulis program yang baru saja dijelaskan untuk CPU. Seperti yang dapat Anda lihat pada grafik di bawah, penggunaan daya GPU penuh tampaknya merupakan pilihan yang jelas jika ukuran matriks lebih besar dari 256 x 256.
Artikel ini hanyalah awal dari perjalanan saya menjelajahi WebGPU. Nantikan artikel lainnya yang akan segera hadir yang membahas lebih dalam Komputasi GPU dan cara kerja rendering (kanvas, tekstur, sampler) di WebGPU.