
इस पोस्ट में, WebGPU एपीआई के एक्सपेरिमेंट के बारे में बताया गया है. इसमें उदाहरणों की मदद से, जीपीयू का इस्तेमाल करके डेटा-पैरलल कंप्यूटेशन शुरू करने के बारे में बताया गया है.

पब्लिश किया गया: 28 अगस्त, 2019, पिछली बार अपडेट किया गया: 12 अगस्त, 2025
बैकग्राउंड
आपको शायद पहले से ही पता होगा कि ग्राफ़िक प्रोसेसिंग यूनिट (जीपीयू), कंप्यूटर में मौजूद एक इलेक्ट्रॉनिक सबसिस्टम है. इसे मूल रूप से ग्राफ़िक को प्रोसेस करने के लिए बनाया गया था. हालांकि, पिछले 10 सालों में यह ज़्यादा बेहतर हो गया है. अब डेवलपर, जीपीयू के यूनीक आर्किटेक्चर का फ़ायदा उठाकर, कई तरह के एल्गोरिदम लागू कर सकते हैं. सिर्फ़ 3D ग्राफ़िक रेंडर करने के लिए नहीं. इन क्षमताओं को जीपीयू कंप्यूट कहा जाता है. साथ ही, सामान्य वैज्ञानिक कंप्यूटिंग के लिए जीपीयू को कोप्रोसेसर के तौर पर इस्तेमाल करने को सामान्य जीपीयू (जीपीजीपीयू) प्रोग्रामिंग कहा जाता है.
हाल ही में मशीन लर्निंग के क्षेत्र में हुई तरक्की में, जीपीयू कंप्यूट का अहम योगदान है. इसकी वजह यह है कि कनवोल्यूशन न्यूरल नेटवर्क और अन्य मॉडल, आर्किटेक्चर का फ़ायदा उठा सकते हैं. इससे वे जीपीयू पर ज़्यादा असरदार तरीके से काम कर पाते हैं. मौजूदा वेब प्लैटफ़ॉर्म में जीपीयू कंप्यूट की सुविधाओं की कमी है. इसलिए, W3C का "GPU for the Web" कम्यूनिटी ग्रुप, एक ऐसा एपीआई डिज़ाइन कर रहा है जो ज़्यादातर मौजूदा डिवाइसों पर उपलब्ध आधुनिक जीपीयू एपीआई को दिखाता है. इस एपीआई को WebGPU कहा जाता है.
WebGPU, WebGL की तरह एक लो-लेवल एपीआई है. यह बहुत ज़्यादा जानकारी देने वाला और असरदार है. हालांकि, कोई बात नहीं. हम परफ़ॉर्मेंस को ध्यान में रखते हैं.
इस लेख में, मैं WebGPU के GPU Compute वाले हिस्से पर फ़ोकस करने जा रहा हूं. साथ ही, मैं आपको बता दूं कि मैंने सिर्फ़ बुनियादी जानकारी दी है, ताकि आप खुद से खेलना शुरू कर सकें. आने वाले लेखों में, मैं WebGPU रेंडरिंग (कैनवस, टेक्सचर वगैरह) के बारे में ज़्यादा जानकारी दूंगा.
जीपीयू को ऐक्सेस करना
WebGPU में जीपीयू को ऐक्सेस करना आसान है. navigator.gpu.requestAdapter() को कॉल करने पर, JavaScript प्रॉमिस मिलता है. यह एसिंक्रोनस तरीके से GPU अडैप्टर के साथ हल हो जाएगा. इस अडैप्टर को ग्राफ़िक्स कार्ड की तरह समझें. इसे इंटिग्रेट किया जा सकता है (सीपीयू वाले एक ही चिप पर) या अलग से लगाया जा सकता है. आम तौर पर, यह एक PCIe कार्ड होता है, जो ज़्यादा बेहतर परफ़ॉर्म करता है, लेकिन ज़्यादा बैटरी खर्च करता है.
GPU अडैप्टर मिलने के बाद, adapter.requestDevice() को कॉल करें. इससे आपको एक प्रॉमिस मिलेगा. यह प्रॉमिस, उस GPU डिवाइस के साथ रिज़ॉल्व होगा जिसका इस्तेमाल आपको GPU कंप्यूटेशन के लिए करना है.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
दोनों फ़ंक्शन ऐसे विकल्प लेते हैं जिनसे आपको यह तय करने में मदद मिलती है कि आपको किस तरह का अडैप्टर (पावर प्रेफ़रेंस) और डिवाइस (एक्सटेंशन, सीमाएं) चाहिए. आसानी से समझने के लिए, हम इस लेख में डिफ़ॉल्ट विकल्पों का इस्तेमाल करेंगे.
बफ़र मेमोरी में डेटा सेव करने की अनुमति दें
आइए, देखते हैं कि GPU के लिए मेमोरी में डेटा लिखने के लिए, JavaScript का इस्तेमाल कैसे किया जाता है. यह प्रोसेस आसान नहीं है, क्योंकि मॉडर्न वेब ब्राउज़र में सैंडबॉक्सिंग मॉडल का इस्तेमाल किया जाता है.
नीचे दिए गए उदाहरण में, जीपीयू से ऐक्सेस की जा सकने वाली बफ़र मेमोरी में चार बाइट लिखने का तरीका बताया गया है. यह device.createBuffer() को कॉल करता है, जो बफ़र के साइज़ और उसके इस्तेमाल की जानकारी लेता है. भले ही, इस खास कॉल के लिए इस्तेमाल का फ़्लैग GPUBufferUsage.MAP_WRITE ज़रूरी नहीं है, लेकिन हम इस बफ़र में लिखना चाहते हैं. इसकी वजह से, बनाए जाने पर GPU बफ़र ऑब्जेक्ट मैप हो जाता है. ऐसा mappedAtCreation को सही पर सेट करने की वजह से होता है. इसके बाद, इससे जुड़े रॉ बाइनरी डेटा बफ़र को, GPU बफ़र के getMappedRange() तरीके को कॉल करके वापस पाया जा सकता है.
अगर आपने पहले से ही ArrayBuffer का इस्तेमाल किया है, तो आपको बाइट लिखने के बारे में पता होगा. TypedArray का इस्तेमाल करें और उसमें वैल्यू कॉपी करें.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
इस पॉइंट पर, जीपीयू बफ़र को मैप किया जाता है. इसका मतलब है कि इसका मालिकाना हक सीपीयू के पास होता है. साथ ही, इसे JavaScript से पढ़ा/लिखा जा सकता है. जीपीयू को इसका ऐक्सेस देने के लिए, इसे अनमैप करना होगा. इसके लिए, gpuBuffer.unmap() को कॉल करना होगा.
मैप किए गए/मैप नहीं किए गए का कॉन्सेप्ट, रेस की स्थितियों को रोकने के लिए ज़रूरी है. रेस की स्थितियां तब होती हैं, जब जीपीयू और सीपीयू एक ही समय में मेमोरी को ऐक्सेस करते हैं.
बफ़र मेमोरी को ऐक्सेस करना
अब देखते हैं कि किसी जीपीयू बफ़र को दूसरे जीपीयू बफ़र में कैसे कॉपी किया जाता है और उसे वापस कैसे पढ़ा जाता है.
हम पहले जीपीयू बफ़र में लिख रहे हैं और हमें इसे दूसरे जीपीयू बफ़र में कॉपी करना है. इसलिए, इस्तेमाल का नया फ़्लैग GPUBufferUsage.COPY_SRC ज़रूरी है. इस बार, दूसरे जीपीयू बफ़र को device.createBuffer() के साथ अनमैप किए गए स्टेटस में बनाया जाता है. इसके इस्तेमाल का फ़्लैग GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ है, क्योंकि इसका इस्तेमाल पहले GPU बफ़र के डेस्टिनेशन के तौर पर किया जाएगा. साथ ही, GPU कॉपी करने के निर्देश पूरे होने के बाद, इसे JavaScript में पढ़ा जाएगा.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
GPU एक स्वतंत्र कोप्रोसेसर है. इसलिए, GPU के सभी निर्देश एसिंक्रोनस तरीके से लागू होते हैं. इसलिए, जीपीयू कमांड की एक सूची बनाई जाती है और ज़रूरत पड़ने पर बैच में भेजी जाती है. WebGPU में, device.createCommandEncoder() से मिला GPU कमांड एनकोडर, JavaScript ऑब्जेक्ट होता है. यह "बफ़र की गई" कमांड का एक बैच बनाता है. इन कमांड को किसी समय जीपीयू को भेजा जाएगा. दूसरी ओर, GPUBuffer के तरीके "अनबफ़र किए गए" होते हैं. इसका मतलब है कि ये तरीके, कॉल किए जाने के समय एक साथ लागू होते हैं.
जीपीयू कमांड एनकोडर मिलने के बाद, इस कमांड को कमांड क्यू में जोड़ने के लिए, नीचे दिखाए गए तरीके से copyEncoder.copyBufferToBuffer() कॉल करें, ताकि इसे बाद में लागू किया जा सके.
आखिर में, copyEncoder.finish() को कॉल करके एन्कोडिंग के निर्देश पूरे करें. इसके बाद, उन्हें जीपीयू डिवाइस के निर्देश वाली कतार में सबमिट करें. यह कतार, device.queue.submit() के ज़रिए सबमिट किए गए अनुरोधों को मैनेज करती है. इनमें GPU कमांड को आर्ग्युमेंट के तौर पर इस्तेमाल किया जाता है.
इससे ऐरे में सेव किए गए सभी कमांड, क्रम से एक साथ लागू हो जाएंगे.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
इस समय, GPU क्यू कमांड भेजी जा चुकी हैं. हालांकि, यह ज़रूरी नहीं है कि इन्हें लागू किया गया हो.
दूसरे जीपीयू बफ़र को पढ़ने के लिए, GPUMapMode.READ के साथ gpuReadBuffer.mapAsync() को कॉल करें. यह एक प्रॉमिस दिखाता है, जो GPU बफ़र के मैप होने पर रिज़ॉल्व हो जाएगा. इसके बाद, gpuReadBuffer.getMappedRange() की मदद से मैप की गई रेंज पाएं. इसमें वे ही वैल्यू शामिल होती हैं जो सभी क्यू की गई जीपीयू कमांड के पूरा होने के बाद, पहले जीपीयू बफ़र में शामिल होती हैं.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
बफ़र मेमोरी के ऑपरेशन के बारे में, आपको इन बातों का ध्यान रखना होगा:
- डिवाइस की कतार में सबमिट करने के लिए, GPU बफ़र को अनमैप करना होगा.
- मैप किए जाने पर, GPU बफ़र को JavaScript में पढ़ा और लिखा जा सकता है.
mapAsync()औरcreateBuffer()कोmappedAtCreationके साथ 'सही है' पर सेट करने पर, GPU बफ़र मैप किए जाते हैं.
शेडर प्रोग्रामिंग
जीपीयू पर चलने वाले ऐसे प्रोग्राम जो सिर्फ़ कंप्यूटेशन करते हैं (और ट्राएंगल नहीं बनाते) उन्हें कंप्यूट शेडर कहा जाता है. इन्हें सैकड़ों जीपीयू कोर (जो सीपीयू कोर से छोटे होते हैं) एक साथ प्रोसेस करते हैं. ये कोर, डेटा को प्रोसेस करने के लिए एक साथ काम करते हैं. इनके इनपुट और आउटपुट, WebGPU में बफ़र होते हैं.
WebGPU में कंप्यूट शेडर के इस्तेमाल को दिखाने के लिए, हम मैट्रिक्स मल्टिप्लिकेशन का इस्तेमाल करेंगे. यह मशीन लर्निंग में इस्तेमाल होने वाला एक सामान्य एल्गोरिदम है. इसके बारे में यहां बताया गया है.
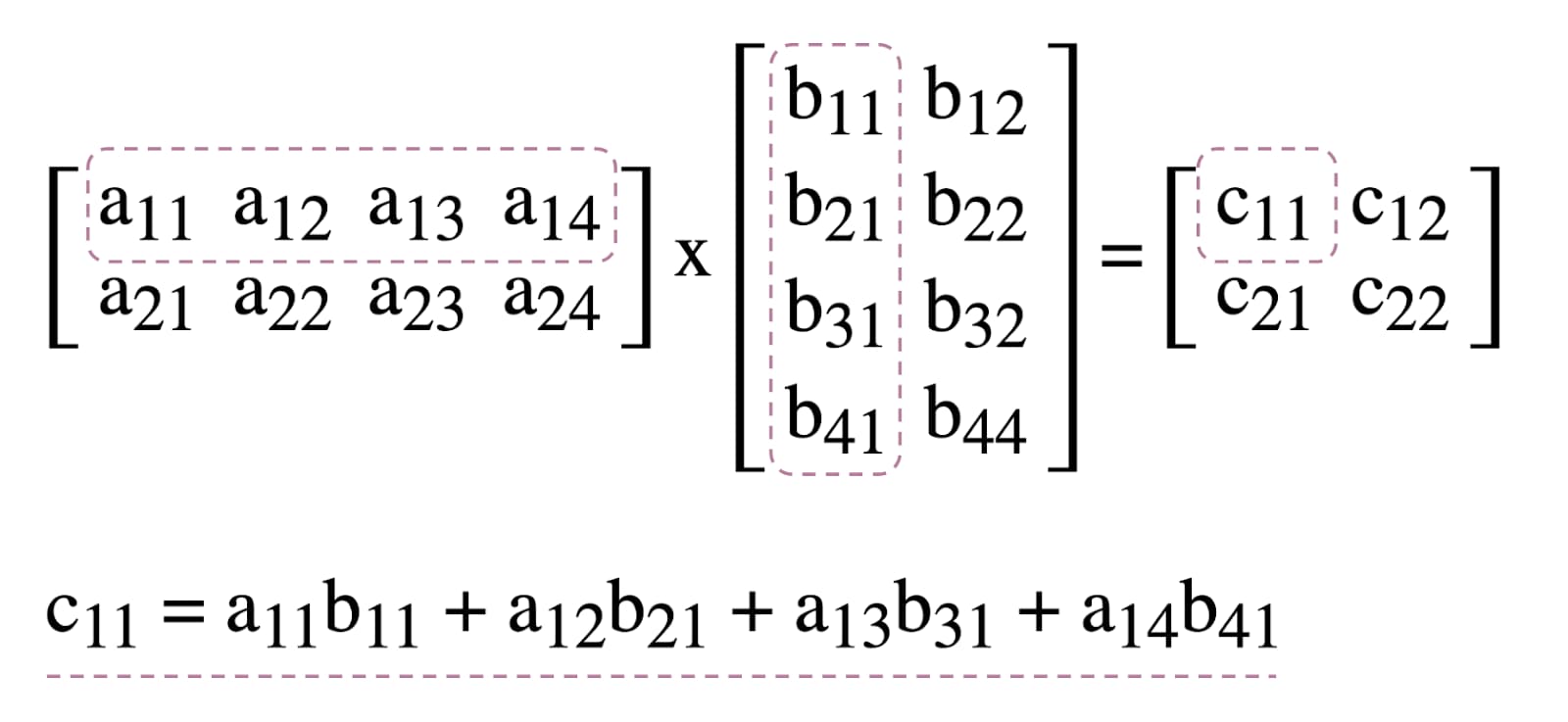
कम शब्दों में कहें, तो हम ये बदलाव करने जा रहे हैं:
- तीन GPU बफ़र बनाएं. इनमें से दो बफ़र, गुणा की जाने वाली मैट्रिक्स के लिए और एक बफ़र, नतीजे वाली मैट्रिक्स के लिए होगा
- कंप्यूट शेडर के लिए इनपुट और आउटपुट के बारे में जानकारी
- कंप्यूट शेडर कोड को कंपाइल करना
- कंप्यूट पाइपलाइन सेट अप करना
- जीपीयू को एन्कोड की गई कमांड बैच में सबमिट करना
- नतीजे के मैट्रिक्स के जीपीयू बफ़र को पढ़ता है
जीपीयू बफ़र बनाना
आसानी से समझने के लिए, मैट्रिक्स को फ़्लोटिंग पॉइंट नंबर की सूची के तौर पर दिखाया जाएगा. पहला एलिमेंट, पंक्तियों की संख्या, दूसरा एलिमेंट कॉलम की संख्या, और बाकी मैट्रिक्स की असल संख्याएं होती हैं.

तीनों जीपीयू बफ़र, स्टोरेज बफ़र हैं. ऐसा इसलिए, क्योंकि हमें कंप्यूट शेडर में डेटा को सेव और वापस पाना होता है. इससे पता चलता है कि GPU बफ़र के इस्तेमाल से जुड़े फ़्लैग में, सभी के लिए GPUBufferUsage.STORAGE क्यों शामिल है. नतीजे वाली मैट्रिक्स के इस्तेमाल के फ़्लैग में भी GPUBufferUsage.COPY_SRC है, क्योंकि जीपीयू की सभी कतार वाली कमांड के लागू होने के बाद, इसे पढ़ने के लिए दूसरे बफ़र में कॉपी किया जाएगा.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
ग्रुप लेआउट और बाइंड ग्रुप को बाइंड करना
बाइंड ग्रुप लेआउट और बाइंड ग्रुप के कॉन्सेप्ट, WebGPU के लिए खास तौर पर बनाए गए हैं. बाइंड ग्रुप लेआउट, शेडर के लिए ज़रूरी इनपुट/आउटपुट इंटरफ़ेस तय करता है. वहीं, बाइंड ग्रुप, शेडर के लिए असल इनपुट/आउटपुट डेटा दिखाता है.
यहां दिए गए उदाहरण में, बाइंड ग्रुप लेआउट को कंप्यूट शेडर के लिए, 0 और 1 नंबर वाली एंट्री बाइंडिंग पर दो रीड ओनली स्टोरेज बफ़र और 2 पर एक स्टोरेज बफ़र की ज़रूरत होती है.
दूसरी ओर, इस बाइंड ग्रुप लेआउट के लिए तय किया गया बाइंड ग्रुप, एंट्री के साथ GPU बफ़र को जोड़ता है: gpuBufferFirstMatrix को बाइंडिंग 0 से, gpuBufferSecondMatrix को बाइंडिंग 1 से, और resultMatrixBuffer को बाइंडिंग 2 से.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
कंप्यूट शेडर कोड
मैट्रिक्स को गुणा करने के लिए, कंप्यूट शेडर कोड को WGSL में लिखा गया है. यह WebGPU शेडर लैंग्वेज है. इसे आसानी से SPIR-V में बदला जा सकता है. ज़्यादा जानकारी दिए बिना, यहां आपको var<storage> से पहचाने गए तीन स्टोरेज बफ़र मिलेंगे. प्रोग्राम, firstMatrix और secondMatrix को इनपुट के तौर पर इस्तेमाल करेगा और resultMatrix को आउटपुट के तौर पर इस्तेमाल करेगा.
ध्यान दें कि हर स्टोरेज बफ़र में, binding डेकोरेशन का इस्तेमाल किया जाता है. यह ऊपर बताए गए बाइंड ग्रुप लेआउट और बाइंड ग्रुप में तय किए गए इंडेक्स से मेल खाता है.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
पाइपलाइन सेटअप करना
कंप्यूट पाइपलाइन वह ऑब्जेक्ट है जो असल में उस कंप्यूट ऑपरेशन के बारे में बताता है जिसे हमें पूरा करना है. इसे device.createComputePipeline() को कॉल करके बनाया जाता है.
इसमें दो आर्ग्युमेंट होते हैं: पहला, हमने पहले जो बाइंड ग्रुप लेआउट बनाया था वह और दूसरा, कंप्यूट स्टेज. कंप्यूट स्टेज, हमारे कंप्यूट शेडर (main WGSL फ़ंक्शन) के एंट्री पॉइंट और device.createShaderModule() की मदद से बनाए गए असल कंप्यूट शेडर मॉड्यूल को तय करता है.
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
निर्देश सबमिट करना
हमारे तीन जीपीयू बफ़र और बाइंड ग्रुप लेआउट वाले कंप्यूट पाइपलाइन के साथ बाइंड ग्रुप को इंस्टैंटिएट करने के बाद, अब उनका इस्तेमाल करने का समय आ गया है.
आइए, commandEncoder.beginComputePass() की मदद से प्रोग्राम किए जा सकने वाले कंप्यूट पास एन्कोडर को शुरू करें. हम इसका इस्तेमाल, मैट्रिक्स को गुणा करने वाली जीपीयू कमांड को एन्कोड करने के लिए करेंगे. इसकी पाइपलाइन को passEncoder.setPipeline(computePipeline) पर सेट करें. साथ ही, इसके बाइंड ग्रुप को इंडेक्स 0 पर passEncoder.setBindGroup(0, bindGroup) पर सेट करें. इंडेक्स 0, WGSL कोड में मौजूद group(0) डेकोरेशन से मेल खाता है.
अब बात करते हैं कि यह कंप्यूट शेडर, जीपीयू पर कैसे चलेगा. हमारा मकसद, इस प्रोग्राम को नतीजे वाली मैट्रिक्स के हर सेल के लिए, एक के बाद एक करके लागू करना है. उदाहरण के लिए, अगर नतीजे की मैट्रिक्स का साइज़ 16 x 32 है, तो @workgroup_size(8, 8) पर कमांड को एन्कोड करने के लिए, हम passEncoder.dispatchWorkgroups(2, 4) या passEncoder.dispatchWorkgroups(16 / 8, 32 / 8) को कॉल करेंगे.
पहला तर्क "x" पहला डाइमेंशन है, दूसरा तर्क "y" दूसरा डाइमेंशन है, और तीसरा तर्क "z" तीसरा डाइमेंशन है. इसकी डिफ़ॉल्ट वैल्यू 1 होती है, क्योंकि हमें इसकी ज़रूरत नहीं है.
जीपीयू कंप्यूटिंग की दुनिया में, डेटा के सेट पर कर्नल फ़ंक्शन को लागू करने के लिए किसी कमांड को कोड में बदलने की प्रोसेस को डिस्पैचिंग कहा जाता है.
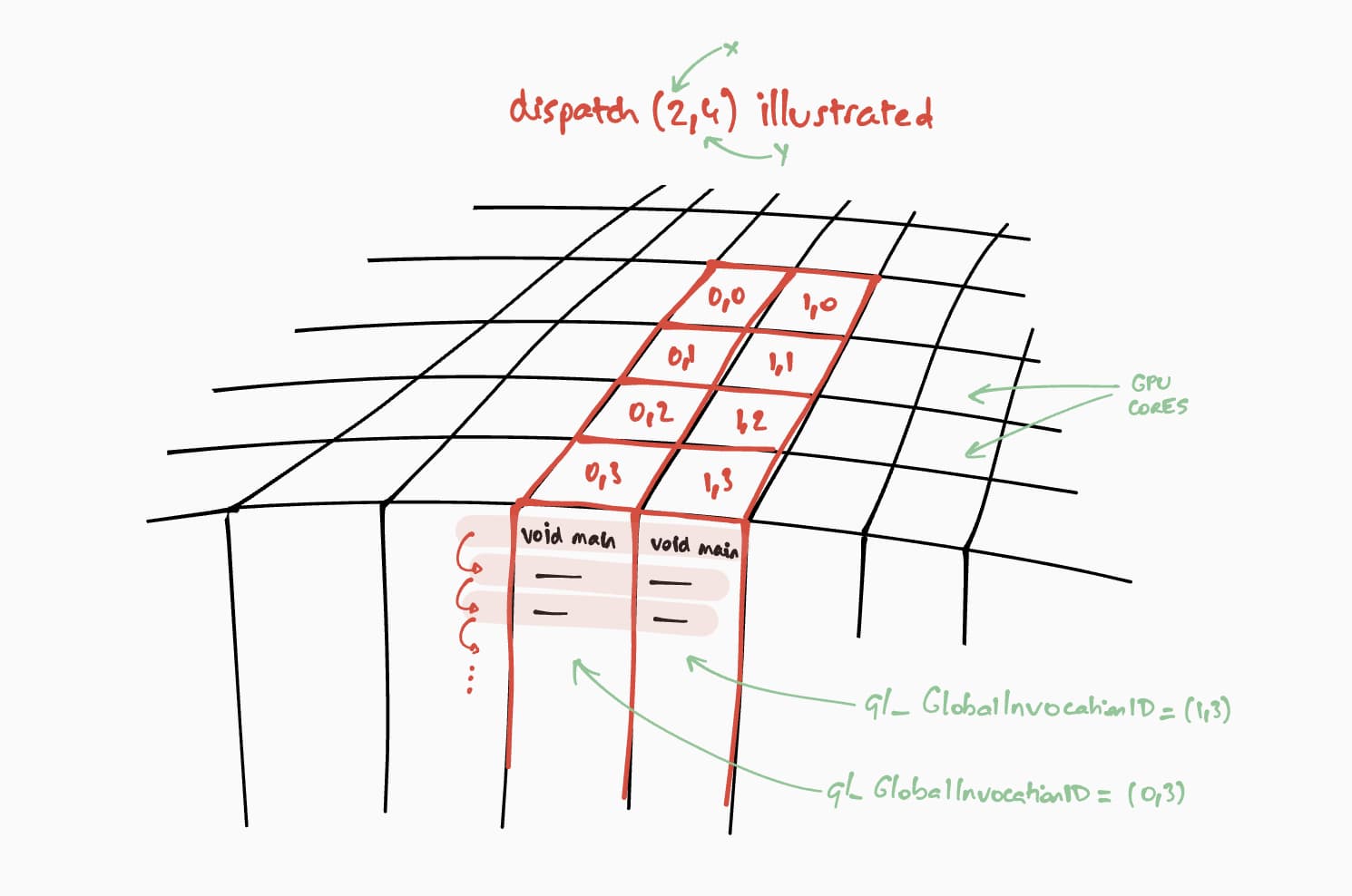
हमारे WGSL कोड में, कंप्यूट शेडर के लिए वर्कग्रुप ग्रिड का साइज़ (8, 8) है. इस वजह से, पहले मैट्रिक्स की लाइनों की संख्या "x" और दूसरे मैट्रिक्स के कॉलम की संख्या "y" को 8 से भाग दिया जाएगा. अब हम passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) के साथ कंप्यूट कॉल भेज सकते हैं. dispatchWorkgroups() आर्ग्युमेंट, वर्कग्रुप ग्रिड की संख्या होते हैं.
ऊपर दी गई इमेज में दिखाया गया है कि हर शेडर के पास एक यूनीक builtin(global_invocation_id) ऑब्जेक्ट का ऐक्सेस होगा. इसका इस्तेमाल यह जानने के लिए किया जाएगा कि किस नतीजे वाली मैट्रिक्स सेल का हिसाब लगाना है.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
कंप्यूट पास एन्कोडर को खत्म करने के लिए, passEncoder.end() को कॉल करें. इसके बाद, copyBufferToBuffer की मदद से नतीजे वाली मैट्रिक्स बफ़र को कॉपी करने के लिए, डेस्टिनेशन के तौर पर इस्तेमाल करने के लिए एक जीपीयू बफ़र बनाएं. आखिर में, copyEncoder.finish() की मदद से एन्कोडिंग कमांड पूरी करें. इसके बाद, GPU डिवाइस की कतार में उन्हें सबमिट करें. इसके लिए, GPU कमांड के साथ device.queue.submit() को कॉल करें.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
नतीजे की मैट्रिक्स पढ़ना
नतीजे की मैट्रिक्स को पढ़ना उतना ही आसान है जितना gpuReadBuffer.mapAsync() को GPUMapMode.READ के साथ कॉल करना और वापस आने वाले प्रॉमिस के हल होने का इंतज़ार करना. इससे पता चलता है कि GPU बफ़र अब मैप हो गया है. इस समय, gpuReadBuffer.getMappedRange() की मदद से मैप की गई रेंज को पाया जा सकता है.
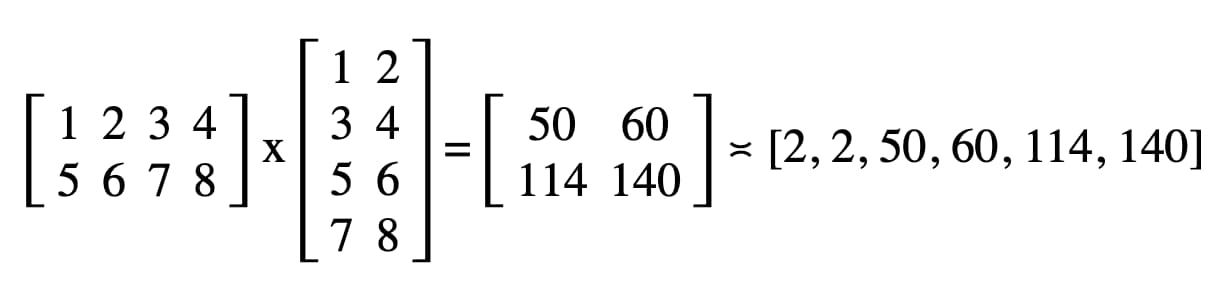
हमारे कोड में, DevTools JavaScript कंसोल में लॉग किया गया नतीजा "2, 2, 50, 60, 114, 140" है.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
बधाई हो! आपने कर लिया. सैंपल के साथ एक्सपेरिमेंट किया जा सकता है.
एक आखिरी तरीका
अपने कोड को आसानी से पढ़ने लायक बनाने का एक तरीका यह है कि कंप्यूट पाइपलाइन के काम के getBindGroupLayout तरीके का इस्तेमाल करके, शेडर मॉड्यूल से बाइंड ग्रुप लेआउट का अनुमान लगाया जाए. इस ट्रिक से, कस्टम बाइंड ग्रुप लेआउट बनाने और अपनी कंप्यूट पाइपलाइन में पाइपलाइन लेआउट तय करने की ज़रूरत नहीं पड़ती. इसके बारे में यहां बताया गया है.
पिछले सैंपल के लिए, getBindGroupLayout का उदाहरण उपलब्ध है.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
परफ़ॉर्मेंस से जुड़ी समस्याएं
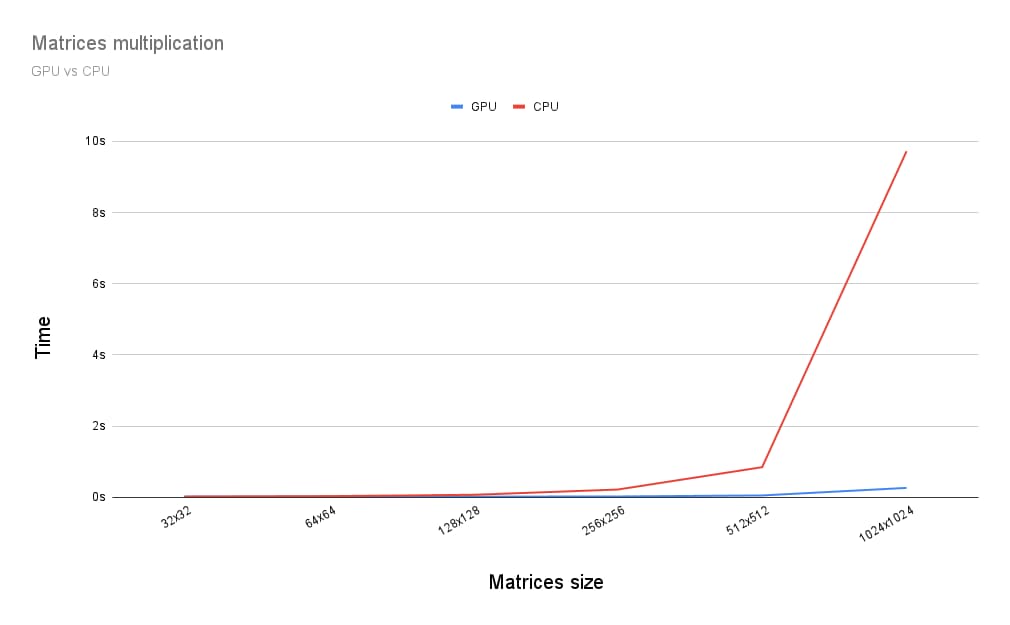
इसलिए, मैट्रिक्स मल्टिप्लिकेशन को जीपीयू पर चलाने की तुलना में, सीपीयू पर चलाने में कितना समय लगता है? यह पता लगाने के लिए, मैंने सीपीयू के लिए ऊपर बताया गया प्रोग्राम लिखा. नीचे दिए गए ग्राफ़ में देखा जा सकता है कि जब मैट्रिक्स का साइज़ 256 x 256 से ज़्यादा होता है, तब जीपीयू की पूरी क्षमता का इस्तेमाल करना एक बेहतर विकल्प होता है.
यह लेख, WebGPU के बारे में जानने की मेरी यात्रा की शुरुआत थी. जल्द ही, आपको और लेख मिलेंगे. इनमें जीपीयू कंप्यूट और WebGPU में रेंडरिंग (कैनवस, टेक्सचर, सैंपलर) के काम करने के तरीके के बारे में ज़्यादा जानकारी दी जाएगी.