
تستكشف هذه المشاركة واجهة برمجة التطبيقات التجريبية WebGPU من خلال أمثلة وتساعدك في بدء تنفيذ عمليات حسابية متوازية للبيانات باستخدام وحدة معالجة الرسومات.

تاريخ النشر: 28 آب (أغسطس) 2019، تاريخ آخر تعديل: 12 آب (أغسطس) 2025
الخلفية
كما تعلم على الأرجح، فإنّ وحدة معالجة الرسومات (GPU) هي نظام فرعي إلكتروني ضمن جهاز كمبيوتر، وقد تم تصميمها في الأصل لمعالجة الرسومات. ومع ذلك، تطورت هذه التقنية خلال السنوات العشر الماضية لتصبح أكثر مرونة، ما يتيح للمطوّرين تنفيذ أنواع عديدة من الخوارزميات، وليس فقط عرض الرسومات الثلاثية الأبعاد، مع الاستفادة من البنية الفريدة لوحدة معالجة الرسومات. يُشار إلى هذه الإمكانات باسم "حوسبة وحدة معالجة الرسومات"، ويُطلق على استخدام وحدة معالجة الرسومات كمعالج مساعد للحوسبة العلمية للأغراض العامة اسم "برمجة وحدة معالجة الرسومات للأغراض العامة" (GPGPU).
ساهمت ميزة "حوسبة وحدة معالجة الرسومات" بشكل كبير في الازدهار الأخير لتعلُّم الآلة، إذ يمكن للشبكات العصبية الالتفافية والنماذج الأخرى الاستفادة من البنية لتنفيذ العمليات بكفاءة أكبر على وحدات معالجة الرسومات. بما أنّ "منصة الويب" الحالية تفتقر إلى إمكانات الحوسبة باستخدام وحدة معالجة الرسومات، يعمل فريق "وحدة معالجة الرسومات للويب" التابع لمجموعة W3C على تصميم واجهة برمجة تطبيقات لعرض واجهات برمجة تطبيقات حديثة لوحدة معالجة الرسومات المتوفّرة على معظم الأجهزة الحالية. تُسمى واجهة برمجة التطبيقات هذه WebGPU.
WebGPU هي واجهة برمجة تطبيقات منخفضة المستوى، مثل WebGL. وهي قوية جدًا ومفصّلة، كما سترى. ولكن لا بأس. ما يهمّنا هو الأداء.
في هذه المقالة، سأركّز على جزء "الحوسبة على وحدة معالجة الرسومات" في WebGPU، وبصراحة، سأقدّم لك معلومات أساسية فقط لتتمكّن من البدء في استكشاف هذه الميزة بنفسك. سأتعمّق أكثر في هذا الموضوع وأتناول عرض WebGPU (اللوحة، والملمس، وما إلى ذلك) في المقالات القادمة.
الوصول إلى وحدة معالجة الرسومات
يمكن الوصول إلى وحدة معالجة الرسومات بسهولة في WebGPU. يؤدي استدعاء navigator.gpu.requestAdapter()
إلى عرض وعد JavaScript سيتم تنفيذه بشكل غير متزامن باستخدام محوّل GPU. يمكنك اعتبار هذا المحوّل بمثابة بطاقة الرسومات. يمكن أن تكون مدمجة (على الشريحة نفسها التي تضم وحدة المعالجة المركزية) أو منفصلة (عادةً ما تكون بطاقة PCIe ذات أداء أفضل ولكنها تستهلك طاقة أكبر).
بعد الحصول على محوّل وحدة معالجة الرسومات، استدعِ الدالة adapter.requestDevice() للحصول على وعد سيتم تنفيذه باستخدام جهاز وحدة معالجة الرسومات الذي ستستخدمه لإجراء بعض عمليات الحوسبة على وحدة معالجة الرسومات.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
تتضمّن كلتا الدالتين خيارات تتيح لك تحديد نوع المحوّل (الأولوية للطاقة) والجهاز (الإضافات والحدود) الذي تريده. للتسهيل، سنستخدم الخيارات التلقائية في هذه المقالة.
ذاكرة التخزين المؤقتة للكتابة
لنطّلِع على كيفية استخدام JavaScript لكتابة البيانات في ذاكرة وحدة معالجة الرسومات. هذه العملية ليست مباشرة بسبب نموذج وضع الحماية الذي تستخدمه متصفّحات الويب الحديثة.
يوضّح المثال أدناه كيفية كتابة أربعة بايتات إلى ذاكرة المخزن المؤقت التي يمكن الوصول إليها
من وحدة معالجة الرسومات. يتم استدعاء device.createBuffer() الذي يأخذ حجم المخزن المؤقت واستخدامه. على الرغم من أنّ علامة الاستخدام GPUBufferUsage.MAP_WRITE غير مطلوبة لهذا الاستدعاء المحدّد، لنوضّح أنّنا نريد الكتابة إلى هذا المخزن المؤقت. يؤدي ذلك إلى إنشاء عنصر مخزن مؤقت لوحدة معالجة الرسومات (GPU) تم ربطه عند الإنشاء، وذلك بفضل ضبط قيمة mappedAtCreation على "صحيح". بعد ذلك، يمكن استرداد مخزن البيانات الثنائية الأولية المرتبط من خلال استدعاء طريقة مخزن GPU getMappedRange().
ستكون كتابة وحدات البايت مألوفة إذا سبق لك استخدام ArrayBuffer، ما عليك سوى استخدام TypedArray ونسخ القيم إليه.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
في هذه المرحلة، يتم ربط المخزن المؤقت لوحدة معالجة الرسومات، ما يعني أنّ وحدة المعالجة المركزية تملك المخزن المؤقت، ويمكن الوصول إليه للقراءة والكتابة من JavaScript. ولكي تتمكّن وحدة معالجة الرسومات من الوصول إلى الذاكرة، يجب إلغاء ربطها، وهو أمر بسيط يتم من خلال استدعاء gpuBuffer.unmap().
مفهوم الربط/عدم الربط ضروري لمنع حدوث حالات تعارض حيث يمكن لوحدة معالجة الرسومات ووحدة المعالجة المركزية الوصول إلى الذاكرة في الوقت نفسه.
سعة ذاكرة التخزين المؤقتة للقراءة
لنطّلِع الآن على كيفية نسخ مخزن مؤقت لوحدة معالجة الرسومات إلى مخزن مؤقت آخر لوحدة معالجة الرسومات وإعادة قراءته.
بما أنّنا نكتب في المخزن المؤقت الأول لوحدة معالجة الرسومات ونريد نسخه إلى مخزن مؤقت ثانٍ لوحدة معالجة الرسومات، يجب توفير علامة استخدام جديدة GPUBufferUsage.COPY_SRC. يتم إنشاء المخزن المؤقت الثاني لوحدة معالجة الرسومات في حالة غير مرتبطة هذه المرة باستخدام device.createBuffer(). علامة الاستخدام هي GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ لأنّه سيتم استخدامها كوجهة لأول مخزن مؤقت لوحدة معالجة الرسومات (GPU) وقراءتها في JavaScript بعد تنفيذ أوامر النسخ الخاصة بوحدة معالجة الرسومات.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
وبما أنّ وحدة معالجة الرسومات هي معالج مساعد مستقل، يتم تنفيذ جميع أوامر وحدة معالجة الرسومات بشكل غير متزامن. لهذا السبب، يتم إنشاء قائمة بأوامر وحدة معالجة الرسومات وإرسالها على شكل دفعات عند الحاجة. في WebGPU، برنامج ترميز أوامر وحدة معالجة الرسومات الذي يتم عرضه بواسطة
device.createCommandEncoder()هو عنصر JavaScript الذي ينشئ مجموعة من الأوامر "المخزّنة مؤقتًا" التي سيتم إرسالها إلى وحدة معالجة الرسومات في وقت ما. من ناحية أخرى، فإنّ الطرق في GPUBuffer تكون "غير مخزّنة مؤقتًا"، ما يعني أنّها يتم تنفيذها بشكل ذري في وقت استدعائها.
بعد الحصول على أداة ترميز أوامر وحدة معالجة الرسومات، استدعِ الدالة copyEncoder.copyBufferToBuffer()
كما هو موضّح أدناه لإضافة هذا الأمر إلى قائمة انتظار الأوامر لتنفيذه لاحقًا.
أخيرًا، أكمِل ترميز الأوامر من خلال استدعاء copyEncoder.finish() وإرسالها إلى قائمة انتظار أوامر جهاز وحدة معالجة الرسومات. تكون قائمة الانتظار مسؤولة عن معالجة عمليات الإرسال التي تتم من خلال device.queue.submit() مع أوامر وحدة معالجة الرسومات كوسيطات.
سيؤدي ذلك إلى تنفيذ جميع الأوامر المخزّنة في المصفوفة بشكل ذري بالترتيب.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
في هذه المرحلة، يتم إرسال أوامر قائمة انتظار وحدة معالجة الرسومات، ولكن لا يتم تنفيذها بالضرورة.
لقراءة المخزن المؤقت الثاني لوحدة معالجة الرسومات، استخدِم الدالة gpuReadBuffer.mapAsync() مع
GPUMapMode.READ. تعرض هذه الطريقة وعدًا سيتم تنفيذه عند ربط المخزن المؤقت لوحدة معالجة الرسومات. بعد ذلك، احصل على النطاق الذي تم ربطه باستخدام gpuReadBuffer.getMappedRange() والذي يحتوي على القيم نفسها الموجودة في المخزن المؤقت الأول لوحدة معالجة الرسومات بعد تنفيذ جميع أوامر وحدة معالجة الرسومات التي تم وضعها في قائمة الانتظار.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
يمكنك تجربة هذا النموذج.
باختصار، إليك ما يجب تذكّره بشأن عمليات ذاكرة التخزين المؤقت:
- يجب إلغاء ربط مخازن GPU المؤقتة لاستخدامها في إرسال قائمة انتظار الأجهزة.
- عند ربطها، يمكن قراءة مخازن GPU المؤقتة وكتابتها في JavaScript.
- يتم ربط مخازن GPU المؤقتة عند استدعاء
mapAsync()وcreateBuffer()مع ضبطmappedAtCreationعلى "صحيح".
برمجة Shader
تُعرف البرامج التي تعمل على وحدة معالجة الرسومات والتي تُجري العمليات الحسابية فقط (ولا ترسم المثلثات) باسم برامج تظليل العمليات الحسابية. ويتم تنفيذها بالتوازي من خلال مئات من نوى وحدة معالجة الرسومات (GPU) (وهي أصغر من نوى وحدة المعالجة المركزية (CPU)) التي تعمل معًا لمعالجة البيانات. وتكون المدخلات والمخرجات عبارة عن مخازن مؤقتة في WebGPU.
لتوضيح كيفية استخدام برامج التظليل الحسابية في WebGPU، سنتعامل مع عملية ضرب المصفوفات، وهي خوارزمية شائعة في تعلُّم الآلة موضّحة أدناه.
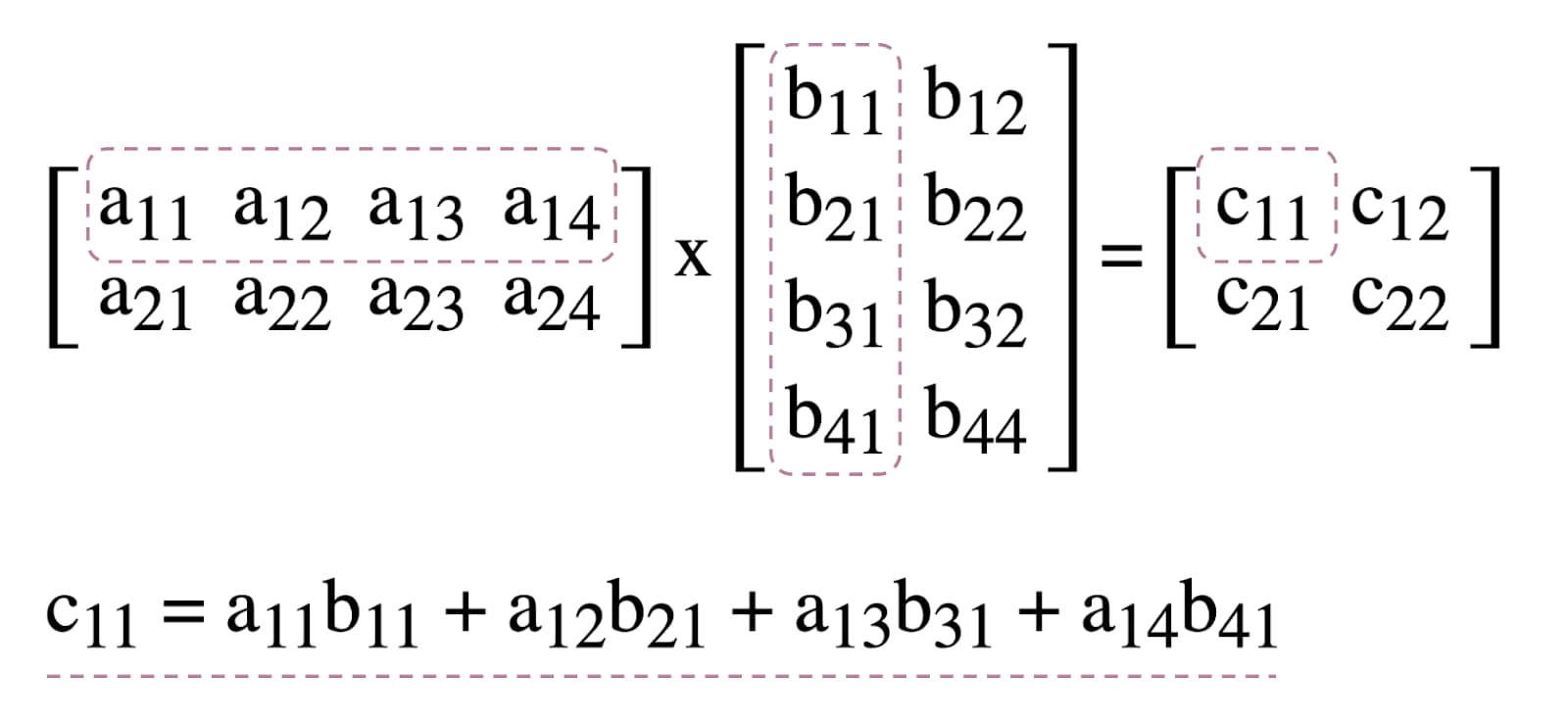
باختصار، إليك ما سنفعله:
- إنشاء ثلاث مخازن مؤقتة لوحدة معالجة الرسومات (اثنان للمصفوفات المطلوب ضربها وواحد لمصفوفة النتائج)
- وصف المدخلات والمخرجات لبرنامج التظليل الحسابي
- تجميع رمز برنامج التظليل الحسابي
- إعداد مسار حوسبة
- إرسال الأوامر المرمّزة إلى وحدة معالجة الرسومات (GPU) في حِزم
- قراءة المخزن المؤقت لوحدة معالجة الرسومات لمصفوفة النتائج
إنشاء مخازن مؤقتة لوحدة معالجة الرسومات
ولتبسيط الأمر، سيتم تمثيل المصفوفات كقائمة من الأرقام النقطية العائمة. العنصر الأول هو عدد الصفوف، والعنصر الثاني هو عدد الأعمدة، وبقية العناصر هي الأرقام الفعلية للمصفوفة.

مخازن GPU المؤقتة الثلاثة هي مخازن مؤقتة للتخزين لأنّنا نحتاج إلى تخزين البيانات واسترجاعها في برنامج التظليل الحسابي. يوضّح هذا السبب تضمين علامات استخدام مخزن البيانات المؤقت لوحدة معالجة الرسومات
GPUBufferUsage.STORAGE في جميعها. يحتوي علم استخدام مصفوفة النتائج أيضًا على
GPUBufferUsage.COPY_SRC لأنّه سيتم نسخه إلى مخزن مؤقت آخر
للقراءة بعد تنفيذ جميع أوامر قائمة انتظار وحدة معالجة الرسومات.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
تنسيق مجموعة الربط ومجموعة الربط
تتفرّد WebGPU بمفهومَي تخطيط مجموعة الربط ومجموعة الربط. يحدّد تنسيق مجموعة الربط واجهة الإدخال/الإخراج المتوقّعة من برنامج التظليل، بينما تمثّل مجموعة الربط بيانات الإدخال/الإخراج الفعلية لبرنامج التظليل.
في المثال أدناه، يتوقّع تنسيق مجموعة الربط مخزنَي بيانات للقراءة فقط عند روابط الإدخال المرقمة 0 و1، ومخزن بيانات عند 2 لبرنامج التظليل الحسابي.
من ناحية أخرى، تربط مجموعة الربط، المحدّدة لتصميم مجموعة الربط هذا، مخازن مؤقتة لوحدة معالجة الرسومات بالإدخالات: gpuBufferFirstMatrix بالربط 0، وgpuBufferSecondMatrix بالربط 1، وresultMatrixBuffer بالربط 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: gpuBufferFirstMatrix
},
{
binding: 1,
resource: gpuBufferSecondMatrix
},
{
binding: 2,
resource: resultMatrixBuffer
}
]
});
رمز برنامج التظليل الحسابي
تتم كتابة رمز التظليل الحسابي الخاص بضرب المصفوفات بلغة WGSL، وهي لغة تظليل WebGPU، التي يمكن ترجمتها بسهولة إلى SPIR-V. بدون الخوض في التفاصيل، يمكنك الاطّلاع أدناه على مخازن البيانات الثلاثة المحدّدة باستخدام var<storage>. سيستخدم البرنامج firstMatrix وsecondMatrix كمدخلات وresultMatrix كمخرجات.
يُرجى العِلم أنّ كل مخزن مؤقت للتخزين يتضمّن عنصر binding زخرفي مستخدَم يتوافق مع الفهرس نفسه المحدّد في تنسيقات مجموعات الربط ومجموعات الربط المعرَّفة أعلاه.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
إعداد مسار الإجراءات
إنّ مسار الحساب هو العنصر الذي يصف عملية الحساب التي سننفذها. يمكنك إنشاء هذا الاختصار من خلال قول device.createComputePipeline().
تتلقّى هذه الدالة وسيطتَين: تخطيط مجموعة الربط الذي أنشأناه سابقًا، ومرحلة حسابية تحدّد نقطة الدخول إلى برنامج التظليل الحسابي (دالة main WGSL) ووحدة برنامج التظليل الحسابي الفعلية التي تم إنشاؤها باستخدام device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule
}
});
إرسال الطلبات
بعد إنشاء مجموعة ربط باستخدام مخازن مؤقتة الثلاثة لوحدة معالجة الرسومات (GPU) وخط أنابيب حسابي مع تخطيط مجموعة ربط، حان الوقت لاستخدامها.
لنبدأ برنامج ترميز تمرير حساب قابل للبرمجة باستخدام
commandEncoder.beginComputePass(). سنستخدم هذا الإجراء لترميز أوامر وحدة معالجة الرسومات التي ستنفّذ عملية ضرب المصفوفة. اضبط مسارها باستخدام
passEncoder.setPipeline(computePipeline) ومجموعة الربط الخاصة بها في الفهرس 0 باستخدام
passEncoder.setBindGroup(0, bindGroup). يتوافق الفهرس 0 مع الزخرفة group(0) في رمز WGSL.
والآن، لنتحدّث عن كيفية تشغيل برنامج التظليل الحسابي هذا على وحدة معالجة الرسومات. هدفنا هو تنفيذ هذا البرنامج بالتوازي لكل خلية من مصفوفة النتائج، خطوة بخطوة. بالنسبة إلى مصفوفة نتائج بحجم 16 × 32 مثلاً، لتشفير أمر التنفيذ، على @workgroup_size(8, 8)، سنطلب passEncoder.dispatchWorkgroups(2, 4) أو passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
الوسيطة الأولى "x" هي البُعد الأول، والوسيطة الثانية "y" هي البُعد الثاني،
والوسيطة الأخيرة "z" هي البُعد الثالث الذي يتم ضبطه تلقائيًا على 1 لأنّنا لا نحتاج إليه هنا.
في عالم الحوسبة على وحدة معالجة الرسومات، يُطلق على ترميز أمر لتنفيذ دالة نواة على مجموعة من البيانات اسم الإرسال.
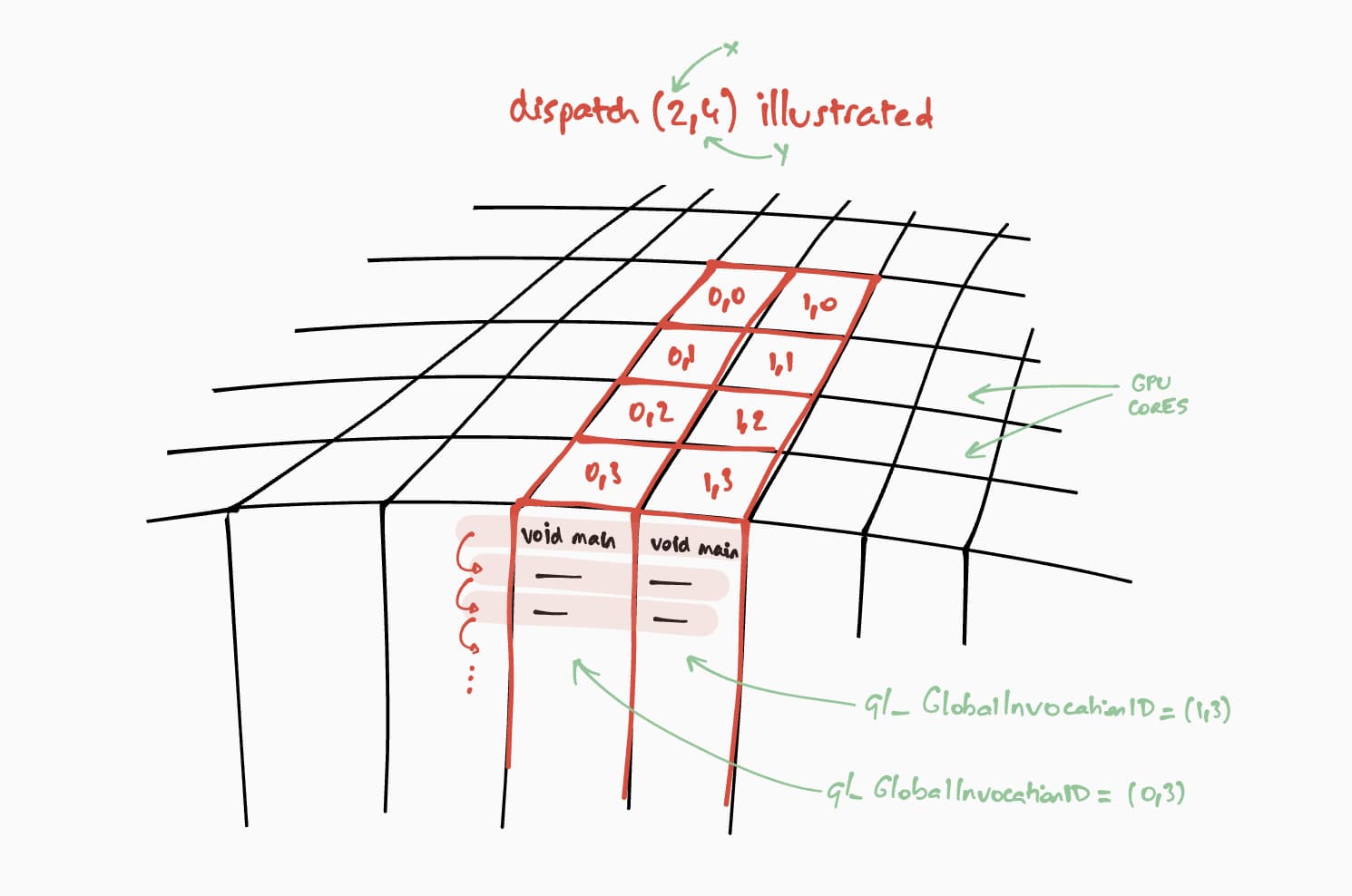
يبلغ حجم شبكة مجموعة العمل الخاصة ببرنامج التظليل الحسابي (8, 8) في رمز WGSL. لهذا السبب، سيتم تقسيم "x" و "y"، وهما على التوالي عدد صفوف المصفوفة الأولى وعدد أعمدة المصفوفة الثانية، على 8. بعد ذلك، يمكننا إرسال طلب حساب باستخدام passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). عدد شبكات مجموعات العمل التي سيتم تشغيلها هي وسيطات dispatchWorkgroups().
كما هو موضّح في الرسم أعلاه، سيتمكّن كل برنامج تظليل من الوصول إلى كائن builtin(global_invocation_id)فريد
سيتم استخدامه لمعرفة خلية مصفوفة النتائج التي يجب احتسابها.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
لإنهاء برنامج ترميز تمرير الحساب، استدعِ passEncoder.end(). بعد ذلك، أنشئ مخزنًا مؤقتًا لوحدة معالجة الرسومات لاستخدامه كوجهة لنسخ المخزن المؤقت لمصفوفة النتائج باستخدام copyBufferToBuffer. أخيرًا، أنهِ ترميز الأوامر باستخدام copyEncoder.finish() وأرسِلها إلى قائمة انتظار جهاز وحدة معالجة الرسومات من خلال استدعاء device.queue.submit() مع أوامر وحدة معالجة الرسومات.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
قراءة مصفوفة النتائج
قراءة مصفوفة النتائج سهلة مثل استدعاء gpuReadBuffer.mapAsync() باستخدام
GPUMapMode.READ والانتظار إلى أن يتم حل الوعد الذي تم إرجاعه، ما يشير إلى
أنّه تم الآن ربط مخزن البيانات المؤقت لوحدة معالجة الرسومات. في هذه المرحلة، يمكن الحصول على النطاق الذي تم ربطه باستخدام gpuReadBuffer.getMappedRange().
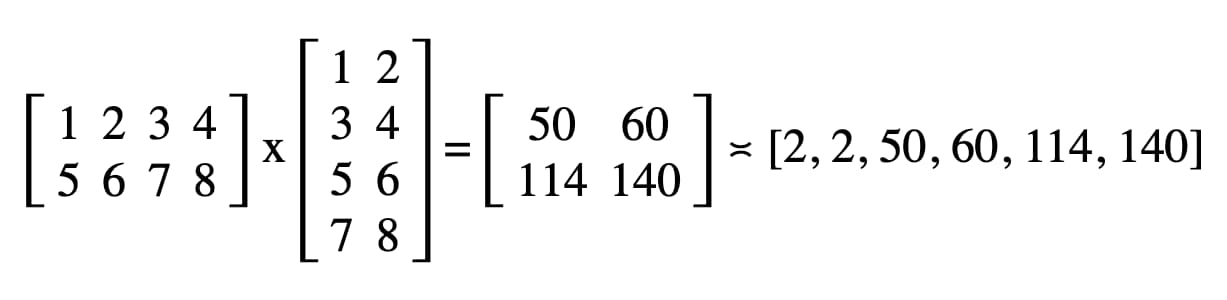
في الرمز البرمجي، النتيجة التي تم تسجيلها في وحدة تحكّم JavaScript في "أدوات المطوّرين" هي "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
تهانينا! فهذا يعني أن العملية تمت بنجاح. يمكنك اللعب باستخدام العيّنة.
خدعة أخيرة
إحدى طرق تسهيل قراءة التعليمات البرمجية هي استخدام طريقة getBindGroupLayout المريحة في مسار الحوسبة من أجل استنتاج تخطيط مجموعة الربط من وحدة التظليل. تزيل هذه الحيلة الحاجة إلى إنشاء
تنسيق مخصّص لمجموعة الربط وتحديد تنسيق مسار في مسار الحساب
كما هو موضّح أدناه.
تتوفّر صورة توضيحية لـ getBindGroupLayout في العيّنة السابقة.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
نتائج الأداء
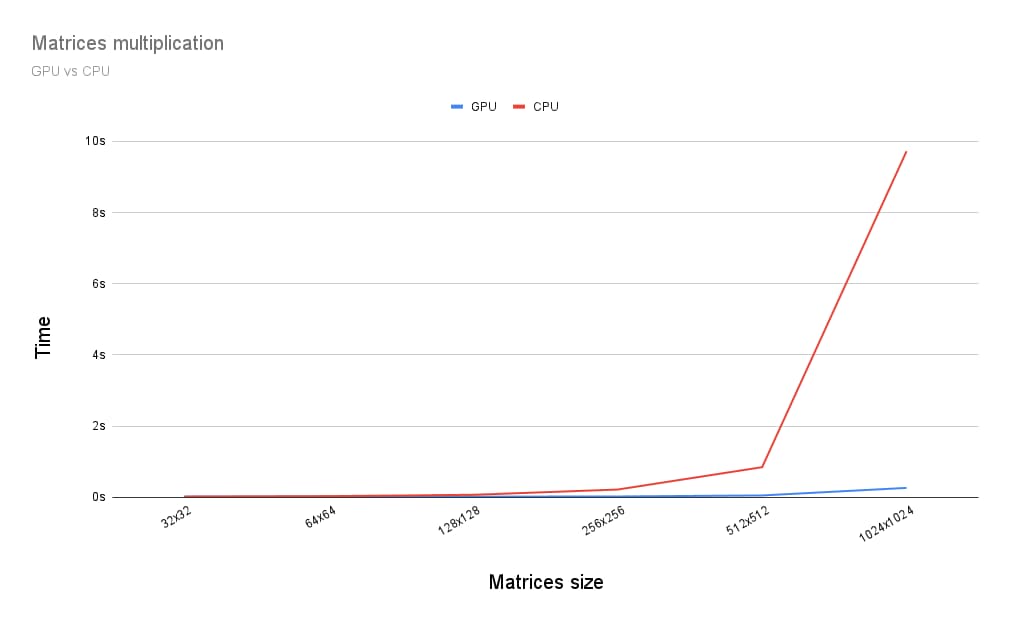
إذًا، ما الفرق بين تنفيذ عملية ضرب المصفوفة على وحدة معالجة الرسومات وتنفيذها على وحدة المعالجة المركزية؟ لمعرفة ذلك، كتبتُ البرنامج الموصوف للتو لوحدة معالجة مركزية. وكما يظهر في الرسم البياني أدناه، يبدو أنّ استخدام كامل قدرة وحدة معالجة الرسومات هو الخيار الأفضل عندما يكون حجم المصفوفات أكبر من 256 × 256.
كانت هذه المقالة مجرد بداية لرحلتي في استكشاف WebGPU. نتوقّع نشر المزيد من المقالات قريبًا التي تتضمّن المزيد من التفاصيل حول GPU Compute وطريقة عمل العرض (اللوحة، والنسيج، وأداة اختيار العيّنات) في WebGPU.