
新しい JavaScript の Web Speech API を使用すると、ウェブページに音声認識を簡単に追加できます。この API を使用すると、Chrome バージョン 25 以降の音声認識機能を柔軟に細かく制御できます。以下は、音声入力中に認識されたテキストがほぼ即座に表示される例です。
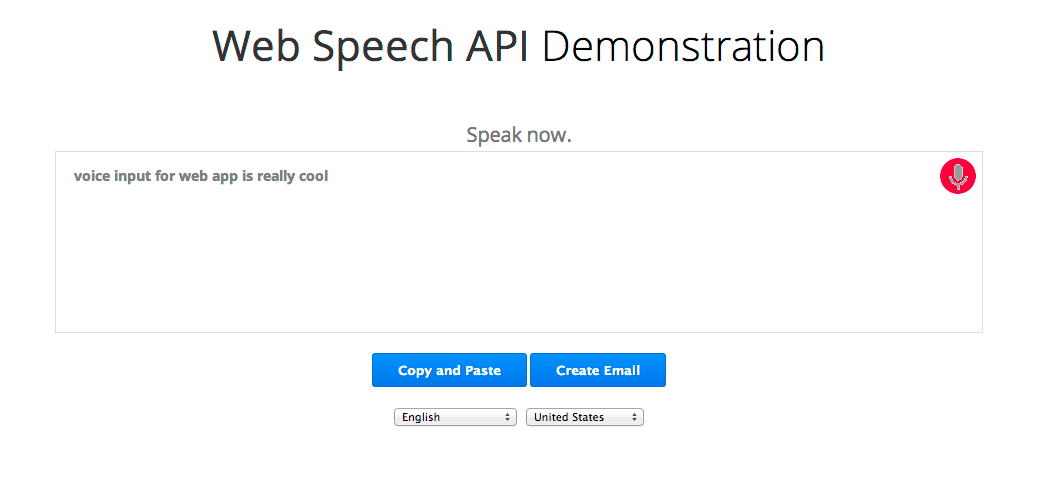
仕組みを見てみましょう。まず、webkitSpeechRecognition オブジェクトが存在するかどうかを確認して、ブラウザが Web Speech API をサポートしているかどうかを確認します。そうでない場合は、ブラウザのアップグレードをご案内します。(この API はまだ試験運用版であるため、現在はベンダー接頭辞が付いています)。最後に、音声インターフェースを提供する webkitSpeechRecognition オブジェクトを作成し、その属性とイベント ハンドラの一部を設定します。
if (!('webkitSpeechRecognition' in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
continuous のデフォルト値は false です。つまり、ユーザーが話すのをやめると、音声認識が終了します。このモードは、短い入力フィールドなどの単純なテキストに適しています。このデモでは、ユーザーが話している間に一時停止しても認識が続行されるように、この値を true に設定しています。
interimResults のデフォルト値は false です。つまり、認識機能から返される結果は最終的なものであり、変更されることはありません。デモでは true に設定されているため、変更される可能性のある早期の暫定的な結果が得られます。デモをよく見てください。グレーのテキストは暫定的なテキストで、変更されることがあります。黒のテキストは、認識ツールからのレスポンスで、最終的なものとマークされ、変更されません。
開始するには、ユーザーがマイクボタンをクリックします。これにより、次のコードがトリガーされます。
function startButton(event) {
...
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
音声認識ツールの「lang」の言語は、ユーザーが選択プルダウン リストから選択した BCP-47 値に設定します(例: 英語(米国)の場合は「en-US」)。設定されていない場合、デフォルトは HTML ドキュメントのルート要素と階層の lang になります。Chrome 音声認識は、さまざまな言語(デモソースの「langs」の表を参照)に対応しています。また、このデモには含まれていませんが、右横書きの言語(he-IL や ar-EG など)もサポートしています。
言語を設定したら、recognition.start() を呼び出して音声認識ツールを有効にします。音声の取り込みが開始されると、onstart イベント ハンドラが呼び出され、新しい結果セットごとに onresult イベント ハンドラが呼び出されます。
recognition.onresult = function(event) {
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
このハンドラは、これまでに受信したすべての結果を final_transcript と interim_transcript の 2 つの文字列に連結します。生成された文字列には、「新しい段落」とユーザーが話したときに「\n」が含まれる場合があります。そのため、linebreak 関数を使用して、これらの文字列を HTML タグ <br> または <p> に変換します。最後に、これらの文字列を、対応する <span> 要素(黒いテキストのスタイル設定が適用された final_span と、灰色のテキストのスタイル設定が適用された interim_span)の innerHTML として設定します。
interim_transcript はローカル変数であり、最後の onresult イベント以降にすべての中間結果が変更されている可能性があるため、このイベントが呼び出されるたびに完全に再ビルドされます。final_transcript でも、for ループを 0 から開始するだけで同じことができます。ただし、最終的なテキストは変更されないため、final_transcript をグローバルにすることで、このコードを少し効率化しました。これにより、このイベントは event.resultIndex で for ループを開始し、新しい最終テキストのみを追加できます。
これで完了です。残りのコードは、すべてを美しく見せるためのものです。状態を維持し、ユーザーに有益なメッセージを表示し、マイクボタンの GIF 画像を静止したマイク、マイク スラッシュ画像、赤い点が点滅するマイク アニメーションの間で切り替えます。
recognition.start() が呼び出されると、マイク スラッシュの画像が表示され、onstart がトリガーされると、マイク アニメーションに置き換えられます。通常、この処理は非常に速く行われるため、スラッシュは認識されませんが、音声認識を初めて使用する場合は、Chrome がマイクを使用する権限をユーザーに尋ねる必要があります。この場合、onstart はユーザーが権限を許可した場合にのみトリガーされます。HTTPS でホストされているページでは、HTTP でホストされているページとは異なり、権限を繰り返しリクエストする必要はありません。
ウェブページでユーザーの声を聴く機能を有効にして、ウェブページをより魅力的にしましょう。
皆様からのご意見をお待ちしております。
- W3C Web Speech API 仕様に関するコメント: メール、メール アーカイブ、コミュニティ グループ
- Chrome でのこの仕様の実装に関するコメント: メール、メール アーカイブ
Google がこの API からの音声データをどのように処理しているかについては、Chrome のプライバシー ホワイトペーパーをご覧ください。