

Chrome チームは、今後のナビゲーションをプリフェッチまたはプリレンダリングしてナビゲーションのパフォーマンスを改善するために使用される Speculation Rules API のエキサイティングなアップデートに取り組んでいます。これらの追加の改善は、Chrome 122 からすべて利用できるようになりました(一部の機能は以前のバージョンから利用できます)。
これらの変更により、ページのプリフェッチとプリレンダリングのデプロイが大幅に容易になり、無駄が減るため、さらなる普及が期待されます。
その他の機能
まず、Speculation Rules API に追加された新しい機能とその使い方について説明します。その後、デモでこれらの機能の動作を確認します。
ドキュメント ルール
以前の投機ルール API は、プリフェッチまたはプリレンダリングする URL のリストを指定することで機能していました。
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
投機ルールは半動的であり、新しい投機ルール スクリプトを追加したり、古いスクリプトを削除して投機を破棄したりできました(既存の投機ルール スクリプトの urls リストを更新しても、投機は変更されません)。ただし、URL の選択はサイトに委ねられており、ページ リクエスト時にサーバーから送信するか、クライアントサイドの JavaScript を使用してこのリストを動的に作成するかのいずれかでした。
リストルールは、単純なユースケース(次のナビゲーションが明らかな小さなセットから選択される場合)や、高度なユースケース(URL のリストがサイト所有者が使用したいヒューリスティックに基づいて動的に計算され、ページに挿入される場合)のオプションとして残ります。
代わりに、ドキュメント ルールを使用した自動リンク検索の新しいオプションをご利用いただけるようになりました。これは、where 条件に基づいてドキュメント自体から URL を取得することで機能します。これは、リンク自体に基づいて判断できます。
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
CSS セレクタは、現在のページ内のリンクを見つけるために、href の一致の代替として、または href の一致と組み合わせて使用することもできます。
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
これにより、ページごとに特定のルールセットを用意するのではなく、サイト全体で 1 つの投機ルールセットを使用できるようになり、サイトで投機ルールを簡単にデプロイできるようになります。
もちろん、ページ上のすべてのリンクを事前レンダリングするのは無駄なので、この新機能では eagerness 設定を導入しました。
Eagerness
どのような予測にも、適合率と再現率、リードタイムのトレードオフがあります。ページ読み込み時にすべてのリンクを事前レンダリングすると、ユーザーがクリックするリンク(ページ上の同一サイトのリンクをクリックすると仮定)をほぼ確実に、できるだけ長いリードタイムで事前レンダリングできますが、帯域幅の無駄が大きくなる可能性があります。
一方、ユーザーがリンクをクリックした後に 1 回だけプリレンダリングすると、無駄を省くことができますが、リードタイムが大幅に短縮されます。つまり、ブラウザがそのページに切り替わる前に事前レンダリングが完了する可能性は低いということです。
eagerness 設定では、投機的読み込みを実行するタイミングを定義できます。投機的読み込みを実行するタイミングと、投機的読み込みを実行する URL を分離できます。eagerness 設定は list と document の両方のソースルールで使用でき、4 つの設定があります。Chrome では、次のヒューリスティックが使用されます。
immediate: できるだけ早く、つまり、投機ルールが検出されたらすぐに投機を行う場合に使用します。eager: 現在はimmediateの設定とまったく同じように動作しますが、今後、immediateとmoderateの中間の動作が設定される予定です。moderate: ユーザーがリンクにカーソルを 200 ミリ秒合わせた場合(またはpointerdownイベントがそれより早く発生した場合やhoverイベントのないモバイルで発生した場合)に投機を行います。conservative: ユーザーがポインタダウンまたはタッチダウンしたときに投機を行います。
list ルールのデフォルトの eagerness は immediate です。moderate オプションと conservative オプションを使用すると、ユーザーが操作する URL を特定のリストに限定する list ルールを作成できます。ただし、多くの場合、適切な where 条件を含む document ルールの方が適切です。
document ルールのデフォルトの eagerness は conservative です。ドキュメントは多くの URL で構成される可能性があるため、document ルールに immediate または eager を使用する場合は注意が必要です(次の Chrome の上限セクションも参照してください)。
使用する eagerness 設定は、サイトによって異なります。非常にシンプルな静的サイトの場合、より積極的に投機を行ってもコストはほとんどかからず、ユーザーにとって有益な可能性があります。アーキテクチャが複雑で、ページ ペイロードが大きいサイトでは、ユーザーの意図を示すポジティブなシグナルがより多く得られるまで推測の頻度を減らし、無駄を減らすことを優先する場合があります。
moderate オプションは中間的な方法です。多くのサイトでは、ホバーまたは pointerdown でリンクをすべてプリレンダリングする次のシンプルな推測ルールを、推測ルールの基本的ながらも強力な実装として活用できます。
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Chrome の上限
eagerness を選択した場合でも、Chrome には API の過剰な使用を防ぐための制限が設けられています。
eagerness |
Prefetch | Prerender |
|---|---|---|
immediate / eager |
50 | 10 |
moderate / conservative |
2(FIFO) | 2(FIFO) |
moderate と conservative の設定(ユーザー操作に依存)は、先入れ先出し(FIFO)方式で動作します。上限に達すると、新しい投機により、最も古い投機がキャンセルされ、新しい投機に置き換えられてメモリが節約されます。
moderate と conservative の推測はユーザーによってトリガーされるため、メモリを節約するために、より控えめな 2 というしきい値を使用できます。immediate と eager の設定はユーザー アクションによってトリガーされないため、上限が高くなっています。ブラウザはどの設定がいつ必要になるかを把握できないためです。
FIFO キューから押し出されてキャンセルされた投機は、たとえばそのリンクに再度カーソルを合わせることで再度トリガーできます。これにより、その URL が再度投機されます。その場合、前の投機によって、ブラウザがその URL の HTTP キャッシュに一部のリソースをキャッシュに保存している可能性が高いため、投機を繰り返すと、ネットワークと時間のコストが大幅に削減されるはずです。
immediate と eager の上限も動的です。これらの積極性レベルを使用して投機ルール スクリプト要素を削除すると、削除された投機をキャンセルすることで容量が作成されます。これらの URL は、新しい URL スクリプトに含まれていて、上限に達していない場合、再投機することもできます。
また、Chrome では、次のような特定の条件下で投機的実行が使用されないようにします。
- Save-Data。
- [省エネツール] を選択します。
- メモリの制約。
- 「ページをプリロードする」の設定がオフになっている場合(uBlock Origin などの Chrome 拡張機能によって明示的にオフにされている場合も含む)。
- バックグラウンド タブで開かれたページ。
これらの条件はすべて、過剰な投機がユーザーに悪影響を及ぼす場合に、その影響を軽減することを目的としています。
省略可 source
Chrome 122 では、url キーまたは where キーの存在から推測できるため、source キーが省略可能になりました。したがって、次の 2 つの投機ルールは同じです。
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules HTTP ヘッダー
推測ルールは、ドキュメントの HTML に直接含めるのではなく、Speculation-Rules HTTP ヘッダーを使用して配信することもできます。これにより、ドキュメントの内容自体を変更することなく、CDN によるデプロイを容易に行うことができます。
Speculation-Rules HTTP ヘッダーがドキュメントとともに返され、投機ルールを含む JSON ファイルの場所を指します。
Speculation-Rules: "/speculationrules.json"
このリソースは正しい MIME タイプを使用し、クロスオリジン リソースの場合は CORS チェックに合格する必要があります。
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
相対 URL を使用する場合は、投機的実行ルールの "relative_to": "document" キーを含めることをおすすめします。それ以外の場合、相対 URL は投機ルール JSON ファイルの URL を基準とします。これは、同じオリジンのリンクの一部またはすべてを選択する必要がある場合に特に便利です。
キャッシュの再利用率の向上
Chrome のキャッシュ保存機能が大幅に改善され、ドキュメントのプリフェッチ(またはプリレンダリング)を行うと、HTTP キャッシュにリソースが保存され、再利用されるようになりました。つまり、投機が使用されなくても、投機には将来的なメリットが残る可能性があります。
また、Chrome はキャッシュ可能なリソースに HTTP キャッシュを使用するため、再投機(moderate の積極性設定があるドキュメント ルールなど)のコストも大幅に削減されます。
また、キャッシュの再利用をさらに改善する新しい No-Vary-Search 提案もサポートしています。
No-Vary-Search のサポート
ページをプリフェッチまたはプリレンダリングする際、特定の URL パラメータ(技術的には検索パラメータと呼ばれます)は、サーバーから実際に配信されるページにとって重要ではなく、クライアントサイドの JavaScript でのみ使用される場合があります。
たとえば、Google アナリティクスではキャンペーンの測定に UTM パラメータが使用されますが、通常、サーバーから異なるページが配信されることはありません。つまり、page1.html?utm_content=123 と page1.html?utm_content=456 はサーバーから同じページを配信するため、同じページをキャッシュから再利用できます。
同様に、アプリケーションではクライアントサイドでのみ処理される他の URL パラメータが使用されることがあります。
No-Vary-Search 提案では、サーバーが配信されるリソースに違いをもたらさないパラメータを指定できます。これにより、ブラウザはこれらのパラメータのみが異なるドキュメントの以前にキャッシュに保存されたバージョンを再利用できます。注: 現在、この機能は Chrome(および Chromium ベースのブラウザ)でのみ、プリフェッチ ナビゲーションの投機的実行でサポートされています。
投機ルールでは、expects_no_vary_search を使用して No-Vary-Search HTTP ヘッダーが返されることが想定される場所を指定できます。これにより、不要なダウンロードをさらに回避できます。
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
この例では、/products の初期ページ HTML は商品 ID 123 と 124 の両方で同じです。ただし、最終的には、JavaScript を使用して id 検索パラメータで商品データを取得するクライアントサイド レンダリングに基づいてページの内容が異なります。そのため、その URL を積極的にプリフェッチし、id 検索パラメータにページを使用できることを示す No-Vary-Search HTTP ヘッダーを返す必要があります。
ただし、プリフェッチが完了する前にユーザーがリンクをクリックすると、ブラウザが /products ページを受信していない可能性があります。この場合、ブラウザは No-Vary-Search HTTP ヘッダーが含まれるかどうかを認識しません。ブラウザは、リンクを再度取得するか、プリフェッチが完了するまで待って No-Vary-Search HTTP ヘッダーが含まれているかどうかを確認するかを選択します。expects_no_vary_search 設定により、ブラウザはページ レスポンスに No-Vary-Search HTTP ヘッダーが含まれることが想定されることを認識し、そのプリフェッチが完了するまで待機します。
デモ
https://chrome.dev/speculative-loading/common-fruits.html でデモを作成しました。このデモでは、moderate の積極的な設定でドキュメント ルールが動作する様子を確認できます。
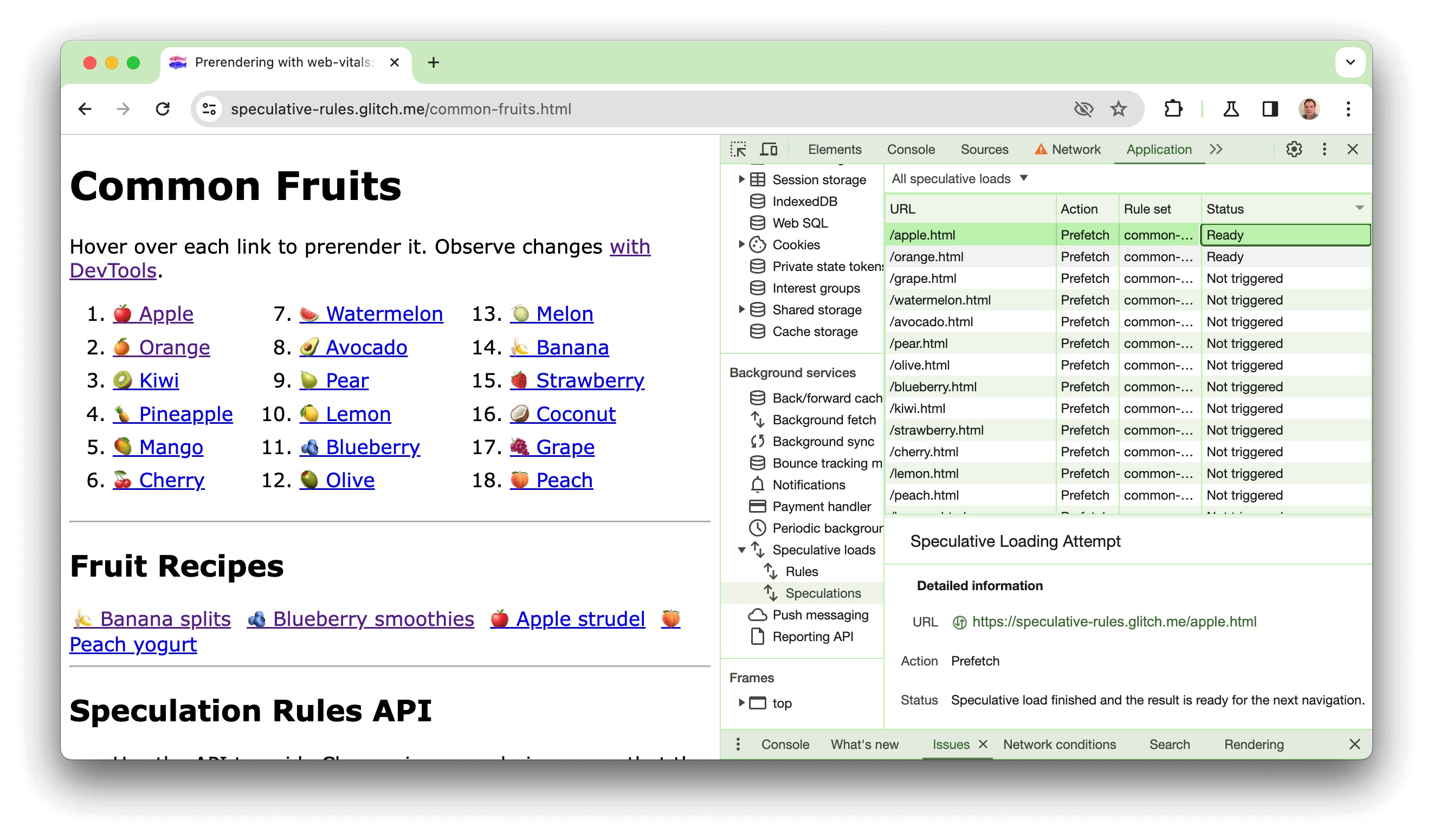
DevTools を開き、[アプリケーション] パネルをクリックします。次に、[バックグラウンド サービス] セクションで [投機的読み込み]、[投機] ペインの順にクリックし、[ステータス] 列で並べ替えます。
果物にカーソルを合わせると、ページがプリレンダリングされるのがわかります。クリックすると、プリレンダリングされていないレシピよりも LCP の時間が大幅に短縮されます。このデモについては、次の動画でも説明しています。
DevTools を使用して投機ルールのデバッグを行う方法については、以前の投機ルールのデバッグに関するブログ投稿もご覧ください。
推測ルールのプラットフォーム サポート
投機的実行ルールは、<script type="speculationrules"> 要素にルールを挿入することで比較的簡単に実装できますが、プラットフォームのサポートにより、ワンクリックで実行できるようになります。投機的実行ルールのロールアウトを容易にするため、さまざまなプラットフォームやパートナーと連携して取り組んでいます。
また、Web Incubator Community Group(WICG)を通じて API を標準化し、他のブラウザもこのエキサイティングな API を実装できるようにする取り組みも進めています。
WordPress
WordPress Core Performance チーム(Google のデベロッパーを含む)は、Speculation Rules プラグインを作成しました。このプラグインを使用すると、ドキュメント ルールのサポートをワンクリックで WordPress サイトに追加できます。このプラグインは WordPress Performance Lab プラグインからインストールすることもできます。このプラグインをインストールすると、チームから関連するパフォーマンス プラグインの最新情報が届くため、インストールを検討することをおすすめします。
投機モードと積極性設定の 2 つの設定グループがあります。
![投機ルールの設定が表示された WordPress の [設定] の [表示設定] パネルのスクリーンショット。投機モード(プリフェッチまたはプリレンダリングのオプション付き)と、保守的、中程度、積極的のいずれかの設定を指定できる積極性設定の 2 つのオプションがあります。](https://developer.chrome.google.cn/static/blog/speculation-rules-improvements/images/wordpress-speculation-rules.png?authuser=9&hl=ja)
特定の URL をプリフェッチやプリレンダリングの対象から除外するなど、より複雑な設定については、ドキュメントをご覧ください。
Akamai
Akamai は世界有数の CDN プロバイダであり、Speculation Rules API のテストを積極的に行っています。Akamai は、お客様が CDN 設定でこの API を有効にする方法に関するドキュメントをリリースしました。また、この新しい API で実現できる優れた結果も共有しています。
Uxify
Uxify(以前は Nitropack の一部)は、カスタムの Navigation AI を使用して推測ルールに追加するページを予測するパフォーマンス最適化ソリューションです。リンクにカーソルを合わせたときよりも長いリードタイムを提供することを目的としていますが、観察されたすべてのリンクを無駄に推測することはありません。詳しくは、Uxify Speculation Rules API のドキュメントをご覧ください。この革新的なソリューションは、サイト固有の分析情報と組み合わせることで、古いリストルールにもまだ多くのメリットがあることを示しています。
Chrome チームは、より詳しい情報を求めるユーザー向けに、投機ルール API に関するウェビナーをチームと共同で開催しました。このウェビナーでは、早期かつ頻繁な投機と、遅延かつ頻度の低い投機の間で必要な考慮事項について、有益な議論が行われました。
天体写真
Astro は、Speculation Rules API を使用したページのプリレンダリングを 4.2 で試験的に追加しました。これにより、Astro を使用するデベロッパーは、この機能を簡単に有効にできます。また、Speculation Rules API をサポートしていないブラウザでは、標準のプリフェッチにフォールバックします。詳しくは、クライアントのプリレンダリングに関するドキュメントをご覧ください。
まとめ
Speculation Rules API にこれらの機能が追加されたことで、サイトのパフォーマンスを向上させるこの新しい機能をより簡単に使用できるようになり、未使用の投機によってリソースが無駄になるリスクも軽減されます。プラットフォームがすでにこの API を活用していることは、非常に喜ばしいことです。2024 年にはこの API が広く採用され、その結果としてエンドユーザーのパフォーマンスが向上することを期待しています。
Speculation Rules API によってパフォーマンスが向上するだけでなく、この API によってどのような新しい機会が生まれるのかも楽しみです。View Transitions は、デベロッパーがナビゲーション間のトランジションをより簡単に指定できるようにする新しい API です。現在、これはシングルページ アプリケーション(SPA)で利用できますが、マルチページ バージョンが開発中です(Chrome のフラグの背後で利用できます)。プリレンダリングは、遅延をなくすためのこの機能の自然なアドオンです。遅延があると、移行によって提供されるユーザー エクスペリエンスの改善が妨げられる可能性があります。この組み合わせをテストしているサイトはすでに確認されています。
2024 年には Speculation Rules API の導入がさらに進むことを期待しています。API のさらなる改善については、随時お知らせいたします。
謝辞
サムネイル: Robbie Down 氏(Unsplash)