

Chrome 团队一直在努力为 Speculation Rules API 推出一些令人兴奋的更新,该 API 可通过预提取甚至预渲染未来的导航来提升导航性能。这些额外的改进现已全部在 Chrome 122 中提供(部分功能在更早的版本中已提供)。
这些更改使预提取和预渲染网页的部署变得更加简单,并减少了浪费,我们希望这能鼓励更多人采用这些技术。
其他功能
首先,我们将说明 Speculation Rules API 中新增的功能以及如何使用这些功能。之后,我们将向您展示演示,以便您了解这些功能在实际应用中的效果。
文档规则
以前,Speculation Rules API 通过指定要预提取或预渲染的网址列表来工作:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
推测规则是半动态的,因为可以添加新的推测规则脚本,也可以移除旧脚本来舍弃这些推测(请注意,更新现有推测规则脚本的 urls 列表不会触发推测更改)。不过,它仍然允许网站自行选择网址,无论是通过在网页请求时从服务器发送网址,还是通过客户端 JavaScript 动态创建此列表。
对于更简单的用例(下一个导航来自一小部分显而易见的网址),或更高级的用例(网址列表根据网站所有者想要使用的任何启发式方法动态计算,然后插入到网页中),列表规则仍然是一个选项。
不过,我们很高兴推出一项新选项,即使用文档规则自动查找链接。此功能会根据where条件从文档本身获取网址。这可以基于链接本身:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
CSS 选择器也可用作 href 匹配的替代方案或与之搭配使用,以查找当前网页中的链接:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
这样一来,整个网站都可以使用单个推测规则集,而无需为每个网页使用特定的推测规则集,从而使网站能够更轻松地部署推测规则。
当然,预渲染网页上的所有链接肯定会浪费资源,因此我们推出了这项新功能,并引入了 eagerness 设置。
热切程度
任何类型的推测都会在精确率和召回率与提前时间之间做出权衡。在网页加载时预渲染所有链接意味着,您几乎肯定会预渲染用户点击的链接(假设用户点击的是网页上的同网站链接),并且会尽可能提前预渲染,但可能会造成巨大的带宽浪费。
另一方面,仅在用户点击链接后进行一次预渲染可防止浪费,但会大大缩短准备时间。这意味着,在浏览器切换到该网页之前,该网页不太可能已完成预渲染。
借助 eagerness 设置,您可以定义何时运行推测,从而将何时进行推测与对哪些网址进行推测分开。eagerness 设置适用于 list 和 document 源规则,并有四种设置,Chrome 具有以下启发式方法:
immediate:该设置用于尽快进行推测,即观察到推测规则后立即进行推测。eager:该设置的行为目前与immediate设置相同,但是以后,我们会将它定位为介于immediate和moderate之间的设置。moderate:当您将光标悬停在链接上达到 200 毫秒时(或者发生pointerdown事件时,以更快者为准;在移动设备上没有hover事件),该设置会执行推测。conservative:在发生指针点击或轻触时,该设置会执行推测。
list 规则的默认 eagerness 为 immediate。moderate 和 conservative 选项可用于将 list 规则限制为用户与之互动的网址的特定列表。不过在许多情况下,采用具有适当 where 条件的 document 规则可能更为合适。
document 规则的默认 eagerness 为 conservative。鉴于一个文档可能包含许多网址,因此在 document 规则中使用 immediate 或 eager 时应谨慎(另请参阅下文中的 Chrome 限制部分)。
具体使用哪种 eagerness 设置取决于您的网站。对于非常简单的静态网站,更积极地推测可能几乎没有成本,并且对用户有益。对于架构更复杂、网页有效内容更大的网站,为了减少浪费,可以降低推测频率,直到从用户那里获得更多积极的意向信号,从而限制浪费。
moderate 选项是一种中间方案,许多网站都可以受益于以下简单的推测规则,该规则会在悬停或 pointerdown 时预渲染所有链接,作为推测规则的基本但功能强大的实现:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Chrome 限制
即使选择了 eagerness,Chrome 也会设置限制来防止过度使用此 API:
eagerness |
预取 | 预渲染 |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
moderate 和 conservative 设置(取决于用户互动)以先进先出 (FIFO) 方式运行。达到上限后,新的推测会导致最旧的推测被取消并替换为较新的推测,以节省内存。
由于 moderate 和 conservative 推测是由用户触发的,因此我们可以使用更低的阈值(即 2)来节省内存。immediate 和 eager 设置不是由用户操作触发的,因此具有更高的限制,因为浏览器无法知道哪些是需要的以及何时需要。
被推出 FIFO 队列而取消的推测可以再次触发,例如通过再次将鼠标悬停在该链接上,这将导致重新推测该网址。在这种情况下,之前的推测很可能导致浏览器在 HTTP 缓存中缓存了相应网址的一些资源,因此重复推测应该会大大减少网络和时间开销。
immediate 和 eager 限制也是动态的。使用这些急切程度级别移除推测规则脚本元素将通过取消移除的推测来创建容量。如果这些网址包含在新的网址脚本中,且未达到上限,则也可以重新进行推测。
Chrome 还将在某些情况下阻止使用推测,包括:
所有这些条件旨在减少过度推测对用户造成的负面影响。
可选 source
Chrome 122 使 source 键成为可选键,因为可以从 url 或 where 键的存在推断出该键。因此,这两个推测规则是相同的:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules HTTP 标头
还可以使用 Speculation-Rules HTTP 标头来传递推测规则,而不是直接将其包含在文档的 HTML 中。这样,CDN 可以更轻松地进行部署,而无需更改文档内容本身。
Speculation-Rules HTTP 标头随文档一起返回,并指向包含推测规则的 JSON 文件的位置:
Speculation-Rules: "/speculationrules.json"
此资源必须使用正确的 MIME 类型,并且如果是跨源资源,则必须通过 CORS 检查。
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
如果您想使用相对网址,不妨在推测规则中添加 "relative_to": "document" 键。否则,相对网址将相对于推测规则 JSON 文件的网址。如果您需要选择一些(或全部)同源链接,此功能可能特别有用。
更好地重用缓存
我们对 Chrome 中的缓存功能进行了一些改进,以便预提取(甚至预渲染)文档时,系统会将资源存储在 HTTP 缓存中并重复使用。这意味着,即使推测未被使用,仍可能在未来带来好处。
这还可大幅降低重新推测的成本(例如,对于急切程度设置为 moderate 的文档规则),因为 Chrome 会使用 HTTP 缓存来缓存资源。
我们还支持新的 No-Vary-Search 提案,以进一步提高缓存重用率。
No-Vary-Search 支持
在预提取或预渲染网页时,某些网址参数(技术上称为搜索参数)对于服务器实际传送的网页可能并不重要,而仅由客户端 JavaScript 使用。
例如,Google Analytics 使用 UTM 参数来衡量广告系列效果,但通常不会导致服务器传送不同的网页。这意味着 page1.html?utm_content=123 和 page1.html?utm_content=456 将从服务器传送同一网页,因此可以从缓存中重复使用同一网页。
同样,应用可能会使用仅在客户端处理的其他网址参数。
No-Vary-Search 提案允许服务器指定不会导致所交付资源发生差异的参数,因此允许浏览器重复使用之前缓存的文档版本,这些版本仅在这些参数上有所不同。注意:目前,此功能仅在 Chrome(以及基于 Chromium 的浏览器)中受支持,用于预提取导航推测。
推测规则支持使用 expects_no_vary_search 来指明预期返回 No-Vary-Search HTTP 标头的位置。这样做有助于进一步避免不必要的下载。
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
在此示例中,商品 ID 123 和 124 的 /products 初始网页 HTML 相同。不过,网页内容最终会因客户端渲染而有所不同,因为客户端渲染会使用 JavaScript 通过 id 搜索参数提取商品数据。因此,我们会预提取该网址,并且该网址应返回一个 No-Vary-Search HTTP 标头,表明该网页可用于任何 id 搜索参数。
不过,如果用户在预提取完成之前点击了任何链接,浏览器可能尚未收到 /products 网页。在这种情况下,浏览器不知道响应是否会包含 No-Vary-Search HTTP 标头。然后,浏览器可以选择再次提取链接,也可以等待预提取完成,以查看其中是否包含 No-Vary-Search HTTP 标头。expects_no_vary_search 设置可让浏览器知道网页响应应包含 No-Vary-Search HTTP 标头,并等待该预提取完成。
演示
我们创建了一个演示,网址为 https://chrome.dev/speculative-loading/common-fruits.html,您可以使用该演示来查看将热切度设置为 moderate 的文档规则的实际效果:
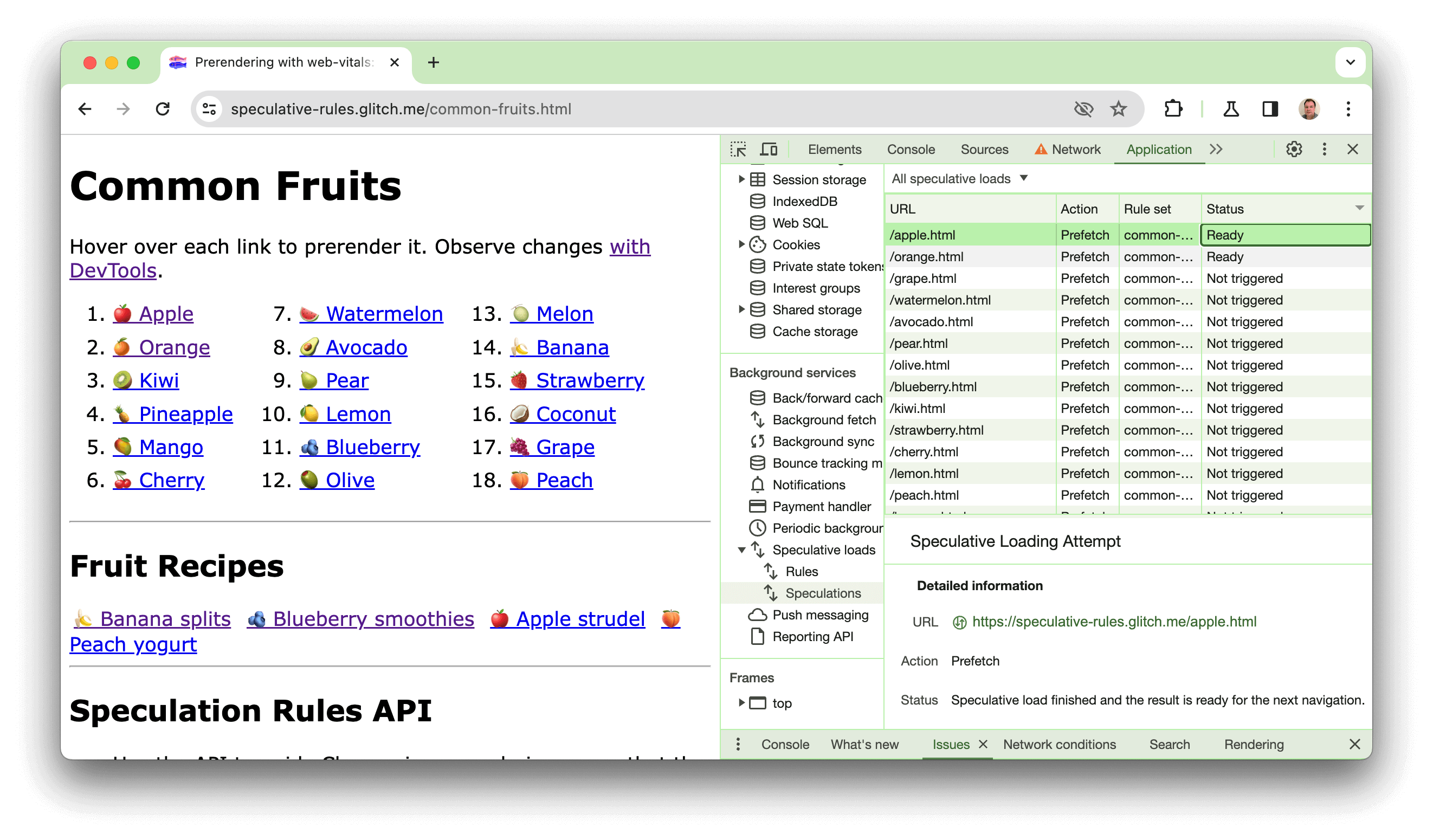
打开开发者工具,然后点击应用面板。然后,在后台服务部分中,依次点击推测性加载和推测窗格,并按状态列进行排序。
当您将光标悬停在水果上时,您会看到网页预渲染。点击这些链接后,您会发现 LCP 时间比未预渲染的食谱快得多。以下视频中也对该演示进行了说明:
您还可以查看之前的调试推测规则博文,详细了解如何使用开发者工具调试推测规则。
推测规则的平台支持
虽然通过将推测规则注入 <script type="speculationrules"> 元素中,可以相对轻松地实现推测规则,但平台支持可以使这一过程只需点击一下即可完成。我们一直在与各种平台和合作伙伴合作,以简化推测规则的推出流程。
我们也在努力通过 Web Incubator Community Group (WICG)实现 API 标准化,以便其他浏览器也能选择实现这一令人兴奋的 API。
WordPress
WordPress 核心性能团队(包括 Google 的开发者)创建了一个 Speculation Rules 插件。此插件允许您只需点击一下,即可为任何 WordPress 网站添加文档规则支持。您还可以通过 WordPress Performance Lab 插件安装此插件,建议您也考虑安装该插件,因为它可以让您及时了解团队发布的相关性能插件。
有两组设置:推测模式和积极性设置:

对于更复杂的设置(例如,要排除某些不进行预提取或预渲染的网址),请参阅相关文档。
Akamai
Akamai 是全球领先的 CDN 提供商之一,他们已经积极尝试使用 Speculation Rules API 一段时间了。Akamai 已发布文档,其中介绍了客户如何在 CDN 设置中启用此 API。他们之前还分享了使用此新 API 可以取得的令人印象深刻的成果。
Uxify
Uxify(之前是 Nitropack 的一部分)是一种性能优化解决方案,它使用自定义的导航 AI 来预测要将哪些网页添加到推测规则中,旨在提供比悬停在链接上更长的提前时间,但不会浪费时间来不必要地推测所有观察到的链接。如需了解详情,请参阅 Uxify 推测规则 API 文档。这一创新解决方案表明,如果将旧版列表规则与特定于网站的分析洞见相结合,仍能发挥巨大作用。
Chrome 团队还与相关团队合作,为寻求更多信息的开发者举办了 Speculation Rules API 网络研讨会,其中详细讨论了在早猜测和频繁猜测与晚猜测和较少猜测之间需要考虑的事项。
天文
Astro 在 4.2 中以实验性方式使用 Speculation Rules API 添加了预渲染页面功能,让使用 Astro 的开发者能够轻松启用此功能,同时针对不支持 Speculation Rules API 的浏览器回退到标准预提取。如需了解详情,请参阅其客户端预渲染文档。
总结
Speculation Rules API 的这些新增功能可让网站更轻松地使用这项令人兴奋的新性能功能,同时降低因未使用推测而浪费资源的风险。很高兴看到平台已经开始使用此 API。我们希望在 2024 年看到此 API 得到更广泛的应用,并最终为最终用户带来更好的性能。
除了 Speculation Rules API 带来的性能提升之外,我们还很高兴看到它带来的新机遇。视图过渡是一项新的 API,可让开发者更轻松地指定导航之间的过渡。该功能目前仅适用于单页应用 (SPA),但多页版本正在开发中(可在 Chrome 中通过标志启用)。预渲染是该功能的自然附加功能,可确保不会出现延迟,否则会妨碍过渡功能本应提供的用户体验改进。我们已经看到一些网站在尝试这种组合。
我们期待在 2024 年进一步推广 Speculation Rules API,并将及时向您通报我们对该 API 所做的任何进一步改进。
致谢
缩略图由 Unsplash 上的 Robbie Down 提供