

Het Chrome-team heeft gewerkt aan een aantal interessante updates voor de Speculation Rules API, die wordt gebruikt om de navigatieprestaties te verbeteren door toekomstige navigatie vooraf op te halen of zelfs te renderen. Deze extra verbeteringen zijn nu allemaal beschikbaar in Chrome 122 (met enkele functies die al in eerdere versies beschikbaar waren).
Dankzij deze wijzigingen is het veel eenvoudiger om pagina's vooraf op te halen en te renderen en is er minder verspilling. Hopelijk zal dit de verdere acceptatie ervan stimuleren.
Extra functies
Eerst leggen we uit welke nieuwe functies we hebben toegevoegd aan de Speculation Rules API en hoe je ze kunt gebruiken. Daarna laten we je een demo zien, zodat je ze in actie kunt zien.
Documentregels
Voorheen werkte de Speculation Rules API door een lijst met URL's op te geven die u wilde prefetchen of prerenderen:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
De speculatieregels waren semi-dynamisch, in die zin dat nieuwe scripts voor speculatieregels konden worden toegevoegd en oude scripts konden worden verwijderd om die speculaties te verwijderen (merk op dat het bijwerken van de urls -lijst van een bestaand script voor speculatieregels geen wijziging in de speculaties teweegbrengt). De keuze van URL's werd echter nog steeds aan de site overgelaten, hetzij door ze vanaf de server te versturen op het moment van de pagina-aanvraag, hetzij door deze lijst dynamisch aan te maken via client-side JavaScript.
Lijstregels blijven een optie voor eenvoudigere gebruiksgevallen (waarbij de volgende navigatie afkomstig is uit een kleine set van voor de hand liggende URL's) of geavanceerdere gebruiksgevallen (waarbij de lijst met URL's dynamisch wordt berekend op basis van de heuristiek die de site-eigenaar wil gebruiken, en vervolgens op de pagina wordt ingevoegd).
Als alternatief bieden we met trots een nieuwe optie aan voor het automatisch zoeken naar links met behulp van documentregels . Dit werkt door URL's uit het document zelf te halen op basis van een where voorwaarde. Dit kan op basis van de links zelf:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
CSS-selectors kunnen ook worden gebruikt als alternatief voor, of in combinatie met, href-overeenkomsten om links op de huidige pagina te vinden:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Hierdoor kan één enkele set speculatieregels op de hele site worden gebruikt, in plaats van specifieke regels per pagina. Hierdoor kunnen sites veel eenvoudiger speculatieregels implementeren.
Het vooraf weergeven van alle links op een pagina zou natuurlijk verspilling zijn. Daarom hebben we voor deze nieuwe mogelijkheid een instelling eagerness geïntroduceerd.
Gretigheid
Bij elke vorm van speculatie is er een afweging tussen precisie, recall en doorlooptijd. Door alle links vooraf te renderen bij het laden van de pagina, is de kans groot dat een link waarop een gebruiker klikt (ervan uitgaande dat ze op een link naar dezelfde site op de pagina klikken) vooraf wordt gerenderd, met zoveel mogelijk doorlooptijd, maar met een potentieel enorme verspilling van bandbreedte.
Aan de andere kant voorkomt pre-rendering pas nádat een gebruiker op een link heeft geklikt verspilling, maar dit gaat wel ten koste van een aanzienlijk kortere doorlooptijd. Dit betekent dat het onwaarschijnlijk is dat de pre-rendering voltooid is voordat de browser naar die pagina overschakelt.
Met de instelling eagerness kunt u bepalen wanneer speculaties moeten worden uitgevoerd, waarbij u onderscheid maakt tussen wanneer er moet worden gespeculeerd en op welke URL's er speculaties moeten worden uitgevoerd. De instelling eagerness is beschikbaar voor zowel list als document en heeft vier instellingen, waarvoor Chrome de volgende heuristieken hanteert:
-
immediate: Dit wordt gebruikt om zo snel mogelijk te speculeren, dat wil zeggen zodra de speculatieregels in acht worden genomen. -
eager: Momenteel gedraagt dit zich hetzelfde als de instellingimmediate, maar in de toekomst willen we dit ergens tussenimmediateenmoderateplaatsen. -
moderate: Hiermee worden speculaties uitgevoerd als u 200 milliseconden boven een link zweeft (of op depointerdown-gebeurtenis als dat eerder is, en op mobiele apparaten waar geenhoveris). -
conservative: Hierbij wordt gespeculeerd over een aanwijzer of een touchdown.
De eagerness voor list is immediate . De opties moderate en conservative kunnen worden gebruikt om list te beperken tot URL's waarmee een gebruiker interactie heeft met een specifieke lijst. In veel gevallen zijn document met een geschikte where voorwaarde echter geschikter.
De eagerness voor document is conservative . Aangezien een document uit meerdere URL's kan bestaan, is het gebruik van immediate of eager voor document met de nodige voorzichtigheid vereist (zie ook de sectie 'Chrome-limieten' hierna).
Welke instelling voor eagerness u moet gebruiken, hangt af van uw site. Voor een zeer eenvoudige statische site kan het speculeren met meer gretigheid weinig kosten en gunstig zijn voor gebruikers. Sites met een complexere architectuur en een zwaardere pagina-payload geven er misschien de voorkeur aan om minder vaak te speculeren totdat u positievere signalen van gebruikers ontvangt om verspilling te beperken.
De moderate optie is een middenweg, en veel sites zouden baat kunnen hebben bij de volgende eenvoudige speculatieregel die alle links vooraf zou weergeven bij hover of pointerdown als een basis- maar krachtige implementatie van speculatieregels:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Chrome-limieten
Zelfs met de keuze voor eagerness heeft Chrome beperkingen om overmatig gebruik van deze API te voorkomen:
eagerness | Vooraf ophalen | Vooraf renderen |
|---|---|---|
immediate / eager | 50 | 10 |
moderate / conservative | 2 (FIFO) | 2 (FIFO) |
De moderate en conservative instellingen – die afhankelijk zijn van gebruikersinteractie – werken volgens het First In, First Out (FIFO)-principe . Nadat de limiet is bereikt, wordt bij een nieuwe speculatie de oudste speculatie geannuleerd en vervangen door de nieuwere om geheugen te besparen.
Het feit dat moderate en conservative speculaties door gebruikers worden geactiveerd, stelt ons in staat om een lagere drempelwaarde van 2 te gebruiken om geheugen te besparen. De immediate en eager instellingen worden niet geactiveerd door een gebruikersactie en hebben daarom een hogere limiet, omdat de browser niet kan weten welke nodig zijn en wanneer ze nodig zijn.
Een speculatie die wordt geannuleerd doordat deze uit de FIFO-wachtrij wordt gepusht, kan opnieuw worden geactiveerd – bijvoorbeeld door opnieuw met de muis over die link te bewegen – waardoor die URL opnieuw wordt gespeculeerd. In dat geval heeft de eerdere speculatie er waarschijnlijk toe geleid dat de browser bronnen in de HTTP-cache voor die URL heeft gecached. Het herhalen van de speculatie zou dus veel minder netwerk- en tijdkosten met zich meebrengen.
De immediate en eager limieten zijn ook dynamisch. Het verwijderen van een scriptelement met speculatieregels met behulp van deze gretigheidsniveaus creëert capaciteit door de verwijderde speculaties te annuleren. Deze URL's kunnen ook opnieuw worden gespeculeerd als ze in een nieuw URL-script zijn opgenomen en de limiet nog niet is bereikt.
Chrome voorkomt ook dat er speculaties worden gebruikt in bepaalde omstandigheden, waaronder:
- Gegevens opslaan .
- Energiebesparing .
- Geheugenbeperkingen.
- Wanneer de instelling "Pagina's vooraf laden" is uitgeschakeld (wat ook expliciet is uitgeschakeld door Chrome-extensies zoals uBlock Origin).
- Pagina's worden geopend in tabbladen op de achtergrond.
Al deze voorwaarden zijn bedoeld om de impact van overspeculatie te verminderen wanneer dit schadelijk zou zijn voor gebruikers.
Optionele source
Chrome 122 maakt de source optioneel, omdat deze kan worden afgeleid uit de aanwezigheid van de url of where -code. Deze twee speculatieregels zijn daarom identiek:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules HTTP-header
Speculatieregels kunnen ook worden aangeleverd via een Speculation-Rules HTTP-header, in plaats van ze rechtstreeks in de HTML van het document op te nemen. Dit maakt implementatie door CDN's eenvoudiger zonder dat de inhoud van het document zelf hoeft te worden gewijzigd.
De Speculation-Rules HTTP-header wordt samen met het document geretourneerd en verwijst naar een locatie van een JSON-bestand met de speculatieregels:
Speculation-Rules: "/speculationrules.json"
Deze resource moet het juiste MIME-type gebruiken en, als het een cross-origin resource is, een CORS-controle doorstaan.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Als u relatieve URL's wilt gebruiken, kunt u de sleutel "relative_to": "document" opnemen in uw speculatieregels. Anders zijn relatieve URL's relatief ten opzichte van de URL van het JSON-bestand met speculatieregels. Dit kan met name handig zijn als u enkele (of alle) links met dezelfde oorsprong wilt selecteren.
Beter cache-hergebruik
We hebben een aantal verbeteringen aangebracht aan de caching in Chrome, zodat het prefetchen (of zelfs prerenderen) van een document resources in de HTTP-cache opslaat en hergebruikt. Dit betekent dat speculeren in de toekomst nog steeds voordelen kan hebben, zelfs als die speculatie niet wordt gebruikt.
Hierdoor wordt het opnieuw speculeren (bijvoorbeeld voor documentregels met een moderate gretigheidsinstelling) aanzienlijk goedkoper, omdat Chrome de HTTP-cache gebruikt voor cachebare bronnen.
We ondersteunen ook het nieuwe No-Vary-Search voorstel om het hergebruik van caches verder te verbeteren.
No-Vary-Search ondersteuning
Bij het prefetchen of prerenderen van een pagina zijn bepaalde URL-parameters (technisch bekend als zoekparameters ) mogelijk niet belangrijk voor de pagina die daadwerkelijk door de server wordt geleverd. Deze worden alleen gebruikt door JavaScript aan de clientzijde.
UTM-parameters worden bijvoorbeeld door Google Analytics gebruikt voor campagnemeting, maar resulteren meestal niet in het leveren van verschillende pagina's vanaf de server. Dit betekent dat page1.html?utm_content=123 en page1.html?utm_content=456 dezelfde pagina vanaf de server leveren, zodat dezelfde pagina vanuit de cache kan worden hergebruikt.
Op vergelijkbare wijze kunnen toepassingen andere URL-parameters gebruiken die alleen aan de clientzijde worden verwerkt.
Met het No-Vary-Search- voorstel kan een server parameters specificeren die niet leiden tot een verschil met de geleverde bron. Zo kan een browser eerder gecachte versies van een document hergebruiken die alleen verschillen door deze parameters. Let op: dit wordt momenteel alleen ondersteund in Chrome (en Chromium-gebaseerde browsers) voor prefetch navigatiespeculaties.
Speculatieregels ondersteunen het gebruik van expects_no_vary_search om aan te geven waar een No-Vary-Search HTTP-header naar verwachting wordt geretourneerd. Dit kan onnodige downloads verder helpen voorkomen.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
In dit voorbeeld is de HTML van de initiële pagina /products hetzelfde voor beide product-id's 123 en 124 De pagina-inhoud verschilt echter uiteindelijk afhankelijk van client-side rendering met JavaScript om productgegevens op te halen met behulp van de zoekparameter id . Daarom prefetchen we die URL gretig en zou deze een No-Vary-Search HTTP-header moeten retourneren die aangeeft dat de pagina voor elke id zoekparameter kan worden gebruikt.
Als de gebruiker echter op een van de links klikt voordat de prefetch is voltooid, heeft de browser de pagina /products mogelijk niet ontvangen. In dat geval weet de browser niet of deze de HTTP-header No-Vary-Search bevat. De browser heeft dan de keuze om de link opnieuw op te halen of te wachten tot de prefetch is voltooid om te controleren of deze een HTTP-header No-Vary-Search bevat. De instelling expects_no_vary_search stelt de browser in staat om te weten dat de paginarespons naar verwachting een HTTP-header No-Vary-Search bevat en te wachten tot die prefetch is voltooid.
Demonstratie
We hebben een demo gemaakt op https://chrome.dev/speculative-loading/common-fruits.html waarmee u documentregels met een moderate gretigheidsinstelling in actie kunt zien:
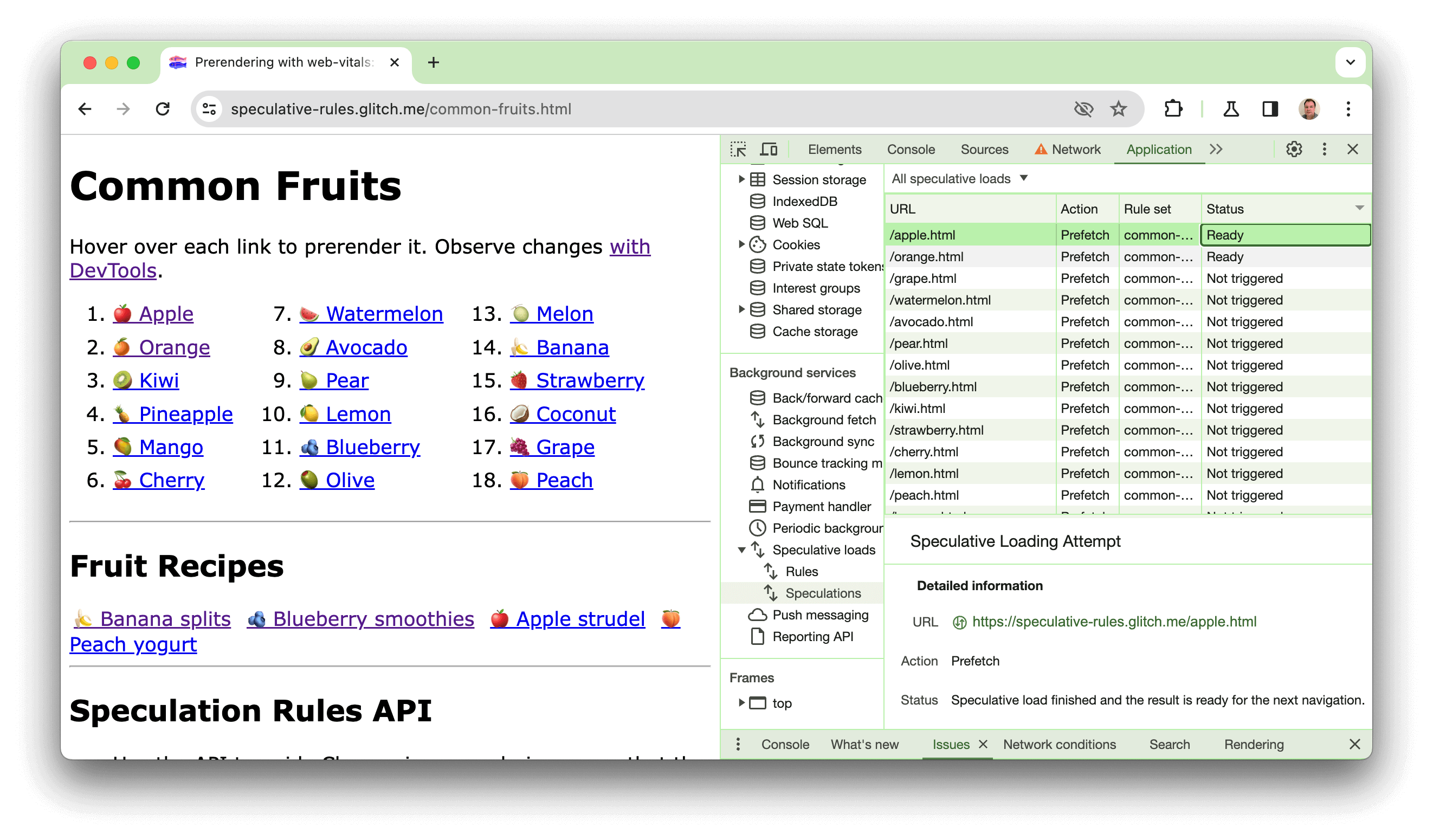
Open DevTools, klik op het paneel 'Toepassing' . Klik vervolgens in het gedeelte 'Achtergrondservices' op 'Speculatieve ladingen' , vervolgens op het paneel ' Speculaties ' en sorteer op de kolom 'Status' .
Als je met je muis over het fruit beweegt, zie je de pagina's pre-renderen. Als je erop klikt, zie je een veel snellere LCP-tijd dan bij een van de recepten, die niet pre-renderen. Deze demo wordt ook uitgelegd in de volgende video :
U kunt ook de vorige blogpost over het debuggen van speculatieregels bekijken voor meer informatie over het gebruik van DevTools om speculatieregels te debuggen.
Platformondersteuning voor speculatieregels
Hoewel speculatieregels relatief eenvoudig te implementeren zijn door ze in een <script type="speculationrules"> element te injecteren, kan platformondersteuning dit met één klik doen. We hebben samengewerkt met verschillende platforms en partners om de uitrol van speculatieregels te vereenvoudigen.
We werken er ook hard aan om de API te standaardiseren via de Web Incubator Community Group (WICG), zodat andere browsers deze interessante API ook kunnen implementeren als ze dat willen.
WordPress
Het WordPress Core Performance-team (inclusief ontwikkelaars van Google) heeft een Speculation Rules-plugin ontwikkeld. Deze plugin maakt het mogelijk om met één klik ondersteuning voor documentregels toe te voegen aan elke WordPress-site. Deze plugin is ook te installeren via de WordPress Performance Lab- plugin. Deze is ook zeker de moeite waard om te overwegen, omdat deze u op de hoogte houdt van de nieuwste prestatieplugins van het team.
Er zijn twee groepen instellingen beschikbaar: de Speculatiemodus en de Gretigheidsinstelling :

Voor ingewikkeldere configuraties, bijvoorbeeld om te voorkomen dat bepaalde URL's vooraf worden opgehaald of gerenderd, kunt u de documentatie raadplegen.
Akamai
Akamai is een van 's werelds toonaangevende CDN-providers en experimenteert al enige tijd actief met de Speculation Rules API. Akamai heeft documentatie gepubliceerd over hoe klanten deze API in hun CDN-instellingen kunnen inschakelen. Eerder hebben ze ook al de indrukwekkende resultaten gedeeld die met deze nieuwe API mogelijk zijn .
Uxify
Uxify (voorheen onderdeel van Nitropack) is een oplossing voor prestatieoptimalisatie die gebruikmaakt van hun eigen navigatie-AI om te voorspellen welke pagina's aan speculatieregels moeten worden toegevoegd. Dit zorgt voor een langere doorlooptijd dan wanneer u met de muis over een link beweegt, maar zonder de verspilling van onnodig speculeren over alle bekeken links. Raadpleeg de documentatie van de Uxify Speculation Rules API voor meer informatie. Deze innovatieve oplossing laat zien dat de oudere lijstregels nog steeds veel te bieden hebben in combinatie met sitespecifieke inzichten.
Het Chrome-team heeft ook met het team samengewerkt aan een webinar voor de Speculation Rules API, voor mensen die meer informatie zochten. Hierbij werd onder andere gesproken over de overwegingen die moeten worden gemaakt tussen vroeg en vaak speculeren, en laat en minder vaak speculeren.
Astro
Astro heeft in versie 4.2 op experimentele basis pagina's met behulp van de Speculation Rules API geprerenderd , waardoor ontwikkelaars die Astro gebruiken deze functie eenvoudig kunnen inschakelen, terwijl ze terugvallen op een standaard prefetch voor browsers die de Speculation Rules API niet ondersteunen. Lees de documentatie van hun client prerender voor meer informatie.
Conclusie
Deze toevoegingen aan de Speculation Rules API maken het gebruik van deze nieuwe, veelbelovende prestatiefunctie voor websites veel eenvoudiger, met minder risico op verspilling van resources door ongebruikte speculaties. Het is veelbelovend om te zien dat platforms deze API al inzetten. We hopen op een bredere acceptatie van deze API in 2024, met uiteindelijk betere prestaties voor eindgebruikers als resultaat.
Naast de prestatieverbeteringen die de Speculation Rules API biedt, zijn we ook benieuwd naar de nieuwe mogelijkheden die dit biedt. View Transitions is een nieuwe API waarmee ontwikkelaars eenvoudiger overgangen tussen navigaties kunnen specificeren. Deze is momenteel beschikbaar voor Single Page Applications (SPA's), maar de versie voor meerdere pagina's is nog in ontwikkeling (en beschikbaar achter een vlaggetje in Chrome). Prerender is een natuurlijke toevoeging aan deze functie om te voorkomen dat er vertraging optreedt, wat anders de beoogde verbetering van de gebruikerservaring zou belemmeren. We hebben al websites zien experimenteren met deze combinatie .
We kijken uit naar de verdere invoering van de Speculation Rules API in 2024 en houden u op de hoogte van eventuele verdere verbeteringen die we aan de API doorvoeren.
Dankbetuigingen
Miniatuur door Robbie Down op Unsplash