

ทีม Chrome ได้ทำการอัปเดตที่น่าสนใจบางอย่างใน Speculation Rules API ซึ่งใช้เพื่อปรับปรุงประสิทธิภาพการนำทางโดยการดึงข้อมูลล่วงหน้าหรือแม้แต่การแสดงผลล่วงหน้าของการนำทางในอนาคต การปรับปรุงเพิ่มเติมเหล่านี้พร้อมให้ใช้งานแล้วใน Chrome 122 (โดยฟีเจอร์บางอย่างพร้อมให้ใช้งานตั้งแต่เวอร์ชันก่อนหน้า)
การเปลี่ยนแปลงเหล่านี้ทำให้การติดตั้งใช้งานการดึงข้อมูลล่วงหน้าและการแสดงผลล่วงหน้าของหน้าเว็บง่ายขึ้นมากและลดการสิ้นเปลือง ซึ่งเราหวังว่าจะกระตุ้นให้มีการนำไปใช้มากขึ้น
ฟีเจอร์เพิ่มเติม
ก่อนอื่นเราจะอธิบายการเพิ่มข้อมูลใหม่ลงใน Speculation Rules API และวิธีใช้ หลังจากนี้ เราจะแสดงการสาธิตเพื่อให้คุณเห็นการทำงานของฟีเจอร์เหล่านี้
กฎของเอกสาร
ก่อนหน้านี้ Speculation Rules API ทำงานโดยการระบุรายการ URL ที่จะดึงข้อมูลล่วงหน้าหรือแสดงผลล่วงหน้า ดังนี้
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
กฎการคาดการณ์เป็นแบบกึ่งไดนามิก กล่าวคือ สามารถเพิ่มสคริปต์กฎการคาดการณ์ใหม่และนำสคริปต์เก่าออกเพื่อทิ้งการคาดการณ์เหล่านั้นได้ (โปรดทราบว่าการอัปเดตurlsรายการสคริปต์กฎการคาดการณ์ที่มีอยู่จะไม่ทําให้เกิดการเปลี่ยนแปลงในการคาดการณ์) อย่างไรก็ตาม เว็บไซต์ยังคงมีสิทธิ์เลือก URL ได้ ไม่ว่าจะโดยการส่งจากเซิร์ฟเวอร์เมื่อมีการขอหน้าเว็บ หรือโดยการสร้างรายการนี้แบบไดนามิกผ่าน JavaScript ฝั่งไคลเอ็นต์
กฎรายการยังคงเป็นตัวเลือกสำหรับกรณีการใช้งานที่ง่ายกว่า (ซึ่งการนำทางถัดไปมาจากชุดการนำทางที่เห็นได้ชัดเพียงไม่กี่รายการ) หรือกรณีการใช้งานขั้นสูงกว่า (ซึ่งระบบจะคำนวณรายการ URL แบบไดนามิกตามฮิวริสติกที่เจ้าของเว็บไซต์ต้องการใช้ แล้วแทรกลงในหน้า)
เราจึงยินดีที่จะเสนอตัวเลือกใหม่ในการค้นหาลิงก์อัตโนมัติโดยใช้กฎของเอกสาร โดยจะทำงานด้วยการจัดหา URL จากเอกสารเองตามwhereเงื่อนไข ซึ่งอาจอิงตามลิงก์เอง ดังนี้
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
นอกจากนี้ คุณยังใช้ตัวเลือก CSS เป็นทางเลือกแทน หรือใช้ร่วมกับการจับคู่ href เพื่อค้นหาลิงก์ในหน้าปัจจุบันได้ด้วย
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
ซึ่งจะช่วยให้ใช้ชุดกฎการคาดคะเนชุดเดียวได้ทั่วทั้งเว็บไซต์ แทนที่จะต้องมีชุดกฎเฉพาะสำหรับแต่ละหน้า ทำให้เว็บไซต์นำกฎการคาดคะเนไปใช้ได้ง่ายขึ้นมาก
แน่นอนว่าการแสดงผลล่วงหน้าของลิงก์ทั้งหมดในหน้าเว็บจะสิ้นเปลืองอย่างแน่นอน ดังนั้นเราจึงได้เปิดตัวeagernessการตั้งค่าพร้อมความสามารถใหม่นี้
ความกระตือรือร้น
การคาดการณ์ทุกประเภทจะมีการทดแทนกันระหว่างความแม่นยำและความอ่อนไหว รวมถึงเวลานำ การแสดงผลล่วงหน้าของลิงก์ทั้งหมดในหน้าเว็บเมื่อโหลดหมายความว่าคุณจะแสดงผลล่วงหน้าของลิงก์ที่ผู้ใช้คลิกอย่างแน่นอน (สมมติว่าผู้ใช้คลิกลิงก์ในเว็บไซต์เดียวกันในหน้าเว็บ) และมีระยะเวลานำที่มากที่สุดเท่าที่จะเป็นไปได้ แต่ก็อาจทำให้สิ้นเปลืองแบนด์วิดท์เป็นอย่างมาก
ในทางกลับกัน การแสดงผลล่วงหน้าเฉพาะเมื่อผู้ใช้คลิกลิงก์จะช่วยป้องกันการสิ้นเปลือง แต่ก็ต้องแลกมาด้วยระยะเวลารอคอยที่ลดลงอย่างมาก ซึ่งหมายความว่าหน้าเว็บดังกล่าวไม่น่าจะแสดงผลล่วงหน้าเสร็จก่อนที่เบราว์เซอร์จะเปลี่ยนไปที่หน้าเว็บนั้น
การตั้งค่า eagerness ช่วยให้คุณกำหนดได้ว่าควรเรียกใช้การคาดคะเนเมื่อใด โดยแยกเมื่อใดที่จะคาดคะเนออกจาก URL ที่จะทำการคาดคะเน eagerness การตั้งค่าพร้อมใช้งานสำหรับทั้งกฎแหล่งที่มาของ list และ document โดยมีการตั้งค่า 4 รายการ ซึ่ง Chrome มีฮิวริสติกต่อไปนี้
immediate: ใช้เพื่อคาดเดาโดยเร็วที่สุด ซึ่งก็คือทันทีที่พบกฎการคาดเดาeager: ปัจจุบันการตั้งค่านี้ทำงานเหมือนกับการตั้งค่าimmediateทุกประการ แต่ในอนาคตเราจะพิจารณาให้การตั้งค่านี้อยู่ระหว่างimmediateกับmoderatemoderate: ฟีเจอร์นี้จะทำการคาดคะเนหากคุณวางเมาส์เหนือลิงก์เป็นเวลา 200 มิลลิวินาที (หรือในเหตุการณ์pointerdownหากเกิดขึ้นก่อน และในอุปกรณ์เคลื่อนที่ที่ไม่มีเหตุการณ์hover)conservative: การคาดการณ์การแตะหรือการวางเคอร์เซอร์
eagerness เริ่มต้นสำหรับกฎ list คือ immediate คุณสามารถใช้ตัวเลือก moderate และ conservative เพื่อจำกัดกฎ list ให้ใช้กับ URL ที่ผู้ใช้โต้ตอบด้วยในรายการที่เฉพาะเจาะจง แม้ว่าในหลายกรณี document กฎที่มีเงื่อนไขwhereที่เหมาะสมอาจเหมาะสมกว่า
eagerness เริ่มต้นสำหรับกฎ document คือ conservative เนื่องจากเอกสารอาจประกอบด้วย URL จำนวนมาก การใช้ immediate หรือ eager สำหรับกฎ document จึงควรใช้อย่างระมัดระวัง (ดูส่วนขีดจำกัดของ Chrome ถัดไป)
eagernessการตั้งค่าที่จะใช้ขึ้นอยู่กับเว็บไซต์ของคุณ สำหรับเว็บไซต์แบบคงที่ที่เรียบง่ายมาก การคาดการณ์อย่างกระตือรือร้นมากขึ้นอาจมีต้นทุนเพียงเล็กน้อยและเป็นประโยชน์ต่อผู้ใช้ เว็บไซต์ที่มีสถาปัตยกรรมซับซ้อนกว่าและเพย์โหลดของหน้าเว็บมีขนาดใหญ่กว่าอาจต้องการลดการสิ้นเปลืองด้วยการคาดการณ์น้อยลงจนกว่าคุณจะได้รับสัญญาณเชิงบวกมากขึ้นเกี่ยวกับความตั้งใจของผู้ใช้เพื่อจำกัดการสิ้นเปลือง
moderate เป็นตัวเลือกที่อยู่ตรงกลาง และเว็บไซต์จำนวนมากอาจได้รับประโยชน์จากกฎการคาดคะเนอย่างง่ายต่อไปนี้ ซึ่งจะแสดงผลล่วงหน้าลิงก์ทั้งหมดเมื่อวางเมาส์เหนือหรือเมื่อเกิดเหตุการณ์ pointerdown เป็นการใช้กฎการคาดคะเนขั้นพื้นฐานแต่มีประสิทธิภาพ
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
ขีดจำกัดของ Chrome
แม้ว่าจะมีตัวเลือก eagerness แต่ Chrome ก็มีข้อจำกัดเพื่อป้องกันการใช้ API นี้มากเกินไป ดังนี้
eagerness |
ดึงข้อมูลล่วงหน้า | Prerender |
|---|---|---|
immediate / eager |
50 | 10 |
moderate / conservative |
2 (FIFO) | 2 (FIFO) |
การตั้งค่า moderate และ conservative ซึ่งขึ้นอยู่กับการโต้ตอบของผู้ใช้ จะทำงานในลักษณะแบบเข้าก่อนออกก่อน (FIFO) หลังจากถึงขีดจำกัดแล้ว การคาดคะเนใหม่จะทำให้ระบบยกเลิกการคาดคะเนที่เก่าที่สุดและแทนที่ด้วยการคาดคะเนใหม่กว่าเพื่อประหยัดหน่วยความจำ
การที่ระบบจะทริกเกอร์การคาดคะเน moderate และ conservative เมื่อผู้ใช้ดำเนินการช่วยให้เราใช้เกณฑ์ที่ต่ำกว่าที่ 2 เพื่อประหยัดหน่วยความจำได้ การตั้งค่า immediate และ eager จะไม่ทริกเกอร์โดยการดำเนินการของผู้ใช้ จึงมีขีดจำกัดที่สูงกว่า เนื่องจากเบราว์เซอร์ไม่สามารถทราบว่าต้องใช้คุกกี้ใดและเมื่อใด
การคาดคะเนที่ถูกยกเลิกโดยการนำออกจากคิว FIFO จะทริกเกอร์ได้อีกครั้ง เช่น โดยการวางเมาส์เหนือลิงก์นั้นอีกครั้ง ซึ่งจะส่งผลให้มีการคาดคะเน URL นั้นอีกครั้ง ในกรณีดังกล่าว การคาดคะเนก่อนหน้านี้อาจทำให้เบราว์เซอร์แคชทรัพยากรบางอย่างในแคช HTTP สำหรับ URL นั้น ดังนั้นการคาดคะเนซ้ำควรลดต้นทุนด้านเครือข่ายและเวลาลงได้มาก
ขีดจำกัด immediate และ eager ยังเป็นแบบไดนามิกด้วย การนำองค์ประกอบสคริปต์ของกฎการคาดคะเนออกโดยใช้ระดับความกระตือรือร้นเหล่านี้จะสร้างความจุด้วยการยกเลิกการคาดคะเนที่นำออก นอกจากนี้ คุณยังคาดการณ์ URL เหล่านี้อีกครั้งได้หากรวมอยู่ในสคริปต์ URL ใหม่และยังไม่ถึงขีดจํากัด
นอกจากนี้ Chrome ยังป้องกันไม่ให้มีการใช้การคาดเดาในบางกรณีด้วย ซึ่งรวมถึง
- Save-Data
- โหมดประหยัดพลังงาน
- ข้อจำกัดด้านหน่วยความจำ
- เมื่อปิดการตั้งค่า "โหลดหน้าเว็บล่วงหน้า" (ซึ่งส่วนขยาย Chrome เช่น uBlock Origin จะปิดอย่างชัดเจนด้วย)
- เปิดหน้าเว็บในแท็บพื้นหลัง
เงื่อนไขทั้งหมดนี้มีจุดมุ่งหมายเพื่อลดผลกระทบของการคาดการณ์มากเกินไปเมื่ออาจเป็นอันตรายต่อผู้ใช้
ไม่บังคับ source
Chrome 122 ทำให้คีย์ source เป็นคีย์ที่ไม่บังคับ เนื่องจากสามารถอนุมานได้จากการมีคีย์ url หรือ where ดังนั้นกฎการคาดเดาทั้ง 2 ข้อนี้จึงเหมือนกัน
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
ส่วนหัว HTTP ของ Speculation-Rules
นอกจากนี้ คุณยังส่งกฎการคาดคะเนได้โดยใช้ส่วนหัว Speculation-Rules HTTP แทนที่จะรวมไว้ใน HTML ของเอกสารโดยตรง ซึ่งช่วยให้ CDN ทำให้ใช้งานได้ง่ายขึ้นโดยไม่ต้องแก้ไขเนื้อหาของเอกสาร
Speculation-Rules ส่วนหัว HTTP จะแสดงพร้อมกับเอกสารและชี้ไปยังตำแหน่งของไฟล์ JSON ที่มีกฎการคาดคะเน
Speculation-Rules: "/speculationrules.json"
ทรัพยากรนี้ต้องใช้ประเภท MIME ที่ถูกต้อง และหากเป็นทรัพยากรข้ามโดเมน จะต้องผ่านการตรวจสอบ CORS
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
หากต้องการใช้ URL แบบสัมพัทธ์ คุณอาจต้องรวมคีย์ "relative_to": "document" ไว้ในกฎการคาดการณ์ ไม่เช่นนั้น URL ที่เกี่ยวข้องจะเกี่ยวข้องกับ URL ของไฟล์ JSON ของกฎการคาดคะเน ซึ่งอาจมีประโยชน์อย่างยิ่งหากคุณต้องการเลือกลิงก์ที่มาจากต้นทางเดียวกันบางลิงก์หรือทั้งหมด
การนำแคชกลับมาใช้ใหม่ได้ดียิ่งขึ้น
เราได้ทำการปรับปรุงการแคชใน Chrome หลายอย่างเพื่อให้การดึงข้อมูลล่วงหน้า (หรือแม้แต่การแสดงผลล่วงหน้า) ของเอกสารจะจัดเก็บและนำทรัพยากรกลับมาใช้ใหม่ในแคช HTTP ซึ่งหมายความว่าการคาดการณ์ยังคงมีประโยชน์ในอนาคตได้ แม้ว่าจะไม่ได้ใช้การคาดการณ์นั้นก็ตาม
นอกจากนี้ยังทำให้การคาดเดาซ้ำ (เช่น สำหรับกฎของเอกสารที่มีmoderateการตั้งค่าความกระตือรือร้น) มีค่าใช้จ่ายน้อยลงอย่างมาก เนื่องจาก Chrome จะใช้แคช HTTP สำหรับทรัพยากรที่แคชได้
นอกจากนี้ เรายังรองรับNo-Vary-Searchข้อเสนอใหม่เพื่อปรับปรุงการนำแคชกลับมาใช้ซ้ำให้ดียิ่งขึ้น
ทีมสนับสนุนของ No-Vary-Search
เมื่อทำการดึงข้อมูลล่วงหน้าหรือแสดงหน้าเว็บล่วงหน้า พารามิเตอร์ URL บางรายการ (ในทางเทคนิคเรียกว่าพารามิเตอร์การค้นหา) อาจไม่สำคัญต่อหน้าเว็บที่เซิร์ฟเวอร์ส่งจริง และใช้โดย JavaScript ฝั่งไคลเอ็นต์เท่านั้น
เช่น Google Analytics ใช้พารามิเตอร์ UTM เพื่อการวัดผลแคมเปญ แต่โดยปกติแล้วจะไม่ส่งผลให้มีการแสดงหน้าเว็บที่แตกต่างกันจากเซิร์ฟเวอร์ ซึ่งหมายความว่า page1.html?utm_content=123 และ page1.html?utm_content=456 จะแสดงหน้าเดียวกันจากเซิร์ฟเวอร์ ดังนั้นจึงสามารถนำหน้าเดียวกันมาใช้ซ้ำจากแคชได้
ในทำนองเดียวกัน แอปพลิเคชันอาจใช้พารามิเตอร์ URL อื่นๆ ที่จัดการเฉพาะฝั่งไคลเอ็นต์
ข้อเสนอ No-Vary-Search ช่วยให้เซิร์ฟเวอร์ระบุพารามิเตอร์ที่ไม่ได้ส่งผลให้ทรัพยากรที่ส่งมีความแตกต่างกัน และช่วยให้เบราว์เซอร์นำเอกสารเวอร์ชันที่แคชไว้ก่อนหน้านี้กลับมาใช้ใหม่ได้ ซึ่งเอกสารดังกล่าวจะแตกต่างกันก็ต่อเมื่อมีพารามิเตอร์เหล่านี้ หมายเหตุ: ปัจจุบันฟีเจอร์นี้รองรับเฉพาะใน Chrome (และเบราว์เซอร์ที่พัฒนาบน Chromium) สำหรับการคาดการณ์การนำทางแบบดึงข้อมูลล่วงหน้า
กฎการคาดการณ์รองรับการใช้ expects_no_vary_search เพื่อระบุตำแหน่งที่คาดว่าจะมีการส่งส่วนหัว HTTP ของ No-Vary-Search กลับมา การดำเนินการดังกล่าวจะช่วยหลีกเลี่ยงการดาวน์โหลดที่ไม่จำเป็นได้
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
ในตัวอย่างนี้ /products HTML ของหน้าเริ่มต้นจะเหมือนกันสำหรับรหัสผลิตภัณฑ์ทั้ง 2 รายการ 123 และ 124 อย่างไรก็ตาม ในที่สุดเนื้อหาของหน้าเว็บจะแตกต่างกันไปตามการแสดงผลฝั่งไคลเอ็นต์โดยใช้ JavaScript เพื่อดึงข้อมูลผลิตภัณฑ์โดยใช้idพารามิเตอร์การค้นหา ดังนั้นเราจึงดึงข้อมูล URL นั้นล่วงหน้าอย่างรวดเร็ว และควรส่งคืนส่วนหัว HTTP No-Vary-Search ที่แสดงว่าสามารถใช้หน้าเว็บสำหรับพารามิเตอร์การค้นหา id ใดก็ได้
อย่างไรก็ตาม หากผู้ใช้คลิกลิงก์ใดก็ตามก่อนที่การดึงข้อมูลล่วงหน้าจะเสร็จสมบูรณ์ เบราว์เซอร์อาจไม่ได้รับหน้า /products ในกรณีนี้ เบราว์เซอร์จะไม่ทราบว่าการตอบสนองจะมีส่วนหัว HTTP No-Vary-Search หรือไม่ จากนั้นเบราว์เซอร์จะมีตัวเลือกว่าจะดึงข้อมูลลิงก์อีกครั้งหรือรอให้การดึงข้อมูลล่วงหน้าเสร็จสมบูรณ์เพื่อดูว่ามีส่วนหัว HTTP ของ No-Vary-Search หรือไม่ การตั้งค่า expects_no_vary_search ช่วยให้เบราว์เซอร์ทราบว่าการตอบกลับของหน้าเว็บควรมีส่วนหัว HTTP No-Vary-Search และรอให้การดึงข้อมูลล่วงหน้าดังกล่าวเสร็จสมบูรณ์
สาธิต
เราได้สร้างการสาธิตที่ https://chrome.dev/speculative-loading/common-fruits.html ซึ่งสามารถใช้เพื่อดูกฎของเอกสารที่มีการตั้งค่าความกระตือรือร้น moderate ได้
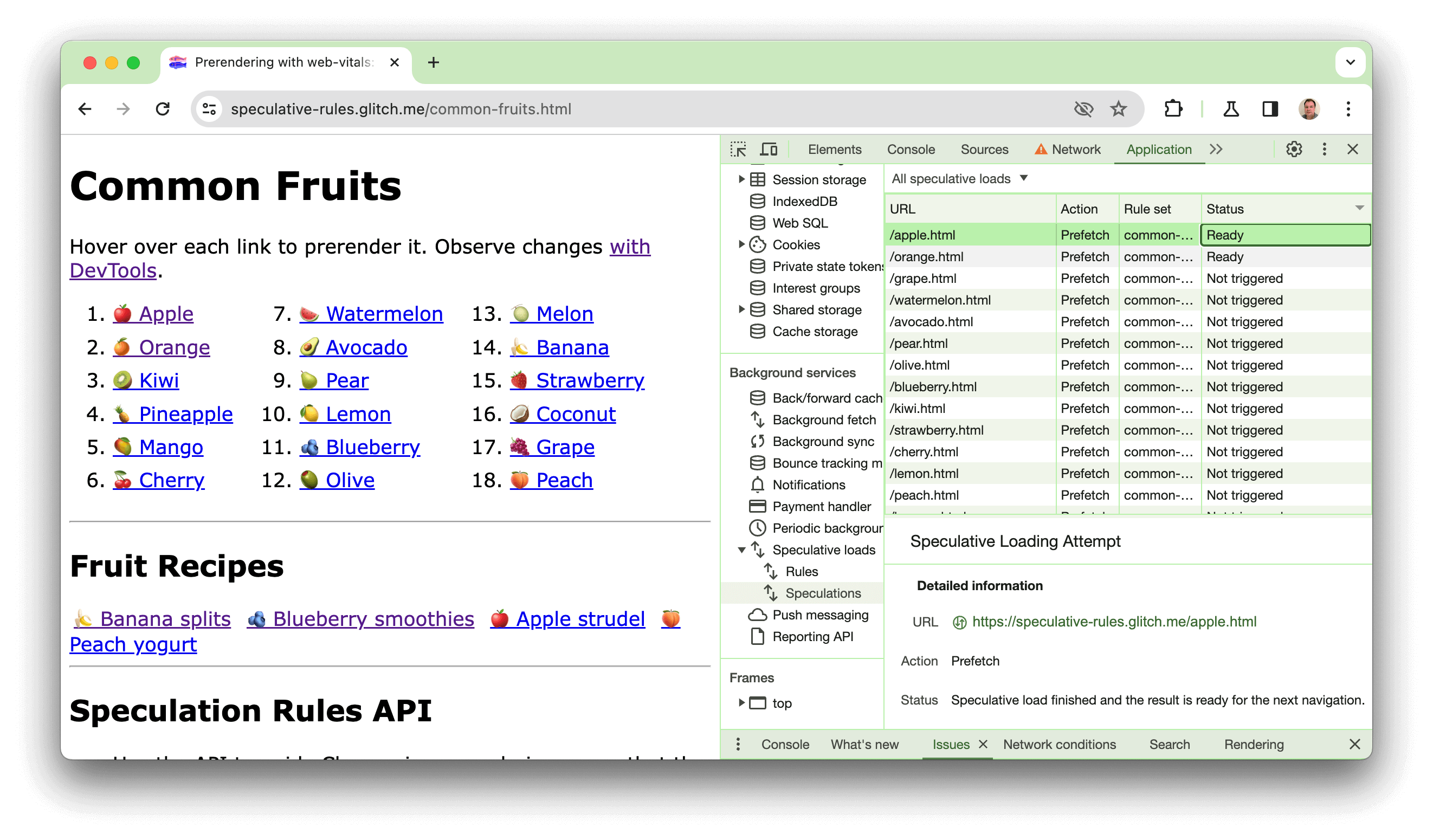
เปิดเครื่องมือสำหรับนักพัฒนาเว็บ แล้วคลิกแผงแอปพลิเคชัน จากนั้นในส่วนบริการที่ทำงานเบื้องหลัง ให้คลิกการโหลดแบบคาดการณ์ แล้วคลิกแผงการคาดการณ์ และจัดเรียงตามคอลัมน์สถานะ
เมื่อวางเมาส์เหนือผลไม้ คุณจะเห็นว่าระบบกำลังแสดงหน้าเว็บล่วงหน้า การคลิกจะแสดงเวลา LCP ที่เร็วกว่าสูตรอาหารที่ไม่ได้แสดงผลล่วงหน้ามาก วิดีโอต่อไปนี้มีคำอธิบายเกี่ยวกับการสาธิตนี้ด้วยเช่นกัน
นอกจากนี้ คุณยังดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้เครื่องมือสำหรับนักพัฒนาเว็บเพื่อแก้ไขข้อบกพร่องของกฎการคาดคะเนได้ในบล็อกโพสต์การแก้ไขข้อบกพร่องของกฎการคาดคะเนก่อนหน้านี้
การสนับสนุนแพลตฟอร์มสำหรับกฎการคาดเดา
แม้ว่าการใช้กฎการคาดเดาจะค่อนข้างง่ายโดยการแทรกกฎลงในองค์ประกอบ <script type="speculationrules"> แต่การรองรับของแพลตฟอร์มจะช่วยให้การดำเนินการนี้ทำได้ในคลิกเดียว เราได้ทำงานร่วมกับแพลตฟอร์มและพาร์ทเนอร์ต่างๆ เพื่อให้การเปิดตัวกฎการคาดการณ์เป็นไปได้ง่ายขึ้น
นอกจากนี้ เรายังมุ่งมั่นสร้างมาตรฐาน API ผ่านกลุ่มชุมชน Web Incubator (WICG) เพื่อให้เบราว์เซอร์อื่นๆ สามารถใช้ API ที่น่าสนใจนี้ได้ด้วยหากต้องการ
WordPress
ทีมประสิทธิภาพหลักของ WordPress (รวมถึงนักพัฒนาซอฟต์แวร์จาก Google) ได้สร้างปลั๊กอินกฎการคาดคะเน ปลั๊กอินนี้ช่วยให้เพิ่มการรองรับกฎเอกสารลงในเว็บไซต์ WordPress ได้อย่างง่ายดายในคลิกเดียว นอกจากนี้ คุณยังติดตั้งปลั๊กอินนี้ผ่านปลั๊กอิน WordPress Performance Lab ได้ด้วย ซึ่งคุณควรพิจารณาติดตั้งเช่นกัน เนื่องจากจะช่วยให้คุณได้รับข้อมูลล่าสุดเกี่ยวกับปลั๊กอินประสิทธิภาพที่เกี่ยวข้องจากทีม
การตั้งค่ามี 2 กลุ่ม ได้แก่ การตั้งค่าโหมดคาดการณ์และการตั้งค่าความกระตือรือร้น

สำหรับการตั้งค่าที่ซับซ้อนกว่านี้ เช่น การยกเว้น URL บางรายการไม่ให้มีการดึงข้อมูลล่วงหน้าหรือการแสดงผลล่วงหน้า โปรดอ่านเอกสารประกอบ
Akamai
Akamai เป็นหนึ่งในผู้ให้บริการ CDN ชั้นนำของโลก และได้ทดสอบ Speculation Rules API อย่างต่อเนื่องมาระยะหนึ่งแล้ว Akamai ได้เผยแพร่เอกสารประกอบเกี่ยวกับวิธีที่ลูกค้าจะเปิดใช้ API นี้ในการตั้งค่า CDN ได้ นอกจากนี้ ยังเคยแชร์ผลลัพธ์ที่น่าประทับใจซึ่งเป็นไปได้ด้วย API ใหม่นี้ด้วย
Uxify
Uxify (เดิมเป็นส่วนหนึ่งของ Nitropack) เป็นโซลูชันการเพิ่มประสิทธิภาพที่ใช้ AI การนำทางที่กำหนดเองเพื่อคาดการณ์หน้าเว็บที่จะเพิ่มลงในกฎการคาดการณ์ ซึ่งมีเป้าหมายเพื่อให้ระยะเวลารอคอยนานกว่าการวางเมาส์เหนือลิงก์ แต่ไม่ต้องคาดการณ์ลิงก์ทั้งหมดที่สังเกตเห็นโดยไม่จำเป็น ดูข้อมูลเพิ่มเติมได้ที่เอกสารประกอบเกี่ยวกับ Uxify Speculation Rules API โซลูชันนวัตกรรมนี้แสดงให้เห็นว่ากฎรายการเก่าๆ ยังมีประโยชน์มากมายเมื่อใช้ร่วมกับข้อมูลเชิงลึกเฉพาะเว็บไซต์
นอกจากนี้ ทีม Chrome ยังทำงานร่วมกับทีมเกี่ยวกับการสัมมนาผ่านเว็บสำหรับ Speculation Rules API สำหรับผู้ที่ต้องการข้อมูลเพิ่มเติม ซึ่งรวมถึงการอภิปรายที่ดีเกี่ยวกับข้อควรพิจารณาที่จำเป็นระหว่างการคาดการณ์ตั้งแต่เนิ่นๆ และบ่อยครั้ง รวมถึงการคาดการณ์ในภายหลังและไม่บ่อยนัก
โหมดถ่ายภาพดวงดาว
Astro ได้เพิ่มการแสดงหน้าเว็บล่วงหน้าโดยใช้ Speculation Rules API ในเวอร์ชัน 4.2 ในระดับทดลอง ซึ่งช่วยให้นักพัฒนาแอปที่ใช้ Astro เปิดใช้ฟีเจอร์นี้ได้อย่างง่ายดาย ในขณะเดียวกันก็กลับไปใช้การดึงข้อมูลล่วงหน้าแบบมาตรฐานสำหรับเบราว์เซอร์ที่ไม่รองรับ Speculation Rules API อ่านข้อมูลเพิ่มเติมได้ในเอกสารประกอบเกี่ยวกับการแสดงผลล่วงหน้าฝั่งไคลเอ็นต์
บทสรุป
การเพิ่ม API กฎการคาดคะเนเหล่านี้ช่วยให้เว็บไซต์ใช้ฟีเจอร์ประสิทธิภาพใหม่ที่น่าสนใจนี้ได้ง่ายขึ้นมาก โดยมีความเสี่ยงน้อยลงที่จะสิ้นเปลืองทรัพยากรไปกับการคาดคะเนที่ไม่ได้ใช้ เราตื่นเต้นที่ได้เห็นแพลตฟอร์มต่างๆ หันมาใช้ API นี้ เราหวังว่าจะได้เห็นการนำ API นี้ไปใช้ในวงกว้างมากขึ้นในปี 2024 และท้ายที่สุดแล้วผู้ใช้ปลายทางจะได้รับประสิทธิภาพที่ดีขึ้น
นอกเหนือจากการเพิ่มประสิทธิภาพที่ Speculation Rules API มอบให้แล้ว เรายังตื่นเต้นที่จะได้เห็นโอกาสใหม่ๆ ที่ API นี้จะเปิดให้ด้วย การเปลี่ยนมุมมองเป็น API ใหม่ที่ช่วยให้นักพัฒนาแอประบุการเปลี่ยนระหว่างการนำทางได้ง่ายขึ้น ปัจจุบันฟีเจอร์นี้ใช้ได้กับ Single Page Application (SPA) แต่เวอร์ชันหลายหน้าเว็บอยู่ระหว่างดำเนินการ (และพร้อมใช้งานหลัง Flag ใน Chrome) การแสดงผลล่วงหน้าเป็นส่วนเสริมที่เหมาะสมกับฟีเจอร์ดังกล่าวเพื่อให้มั่นใจว่าจะไม่มีความล่าช้า ซึ่งอาจขัดขวางการปรับปรุงประสบการณ์ของผู้ใช้ที่การเปลี่ยนผ่านนี้มีจุดประสงค์เพื่อมอบให้ เราเห็นเว็บไซต์ทดสอบการผสมผสานนี้แล้ว
เราหวังว่าจะมีการนำ Speculation Rules API ไปใช้มากขึ้นตลอดปี 2024 และจะแจ้งให้คุณทราบเกี่ยวกับการปรับปรุงเพิ่มเติมที่เราทำกับ API
การรับทราบ
ภาพปกโดย Robbie Down บน Unsplash