

Il team di Chrome ha lavorato ad alcuni aggiornamenti entusiasmanti dell'API Speculation Rules, utilizzata per migliorare le prestazioni di navigazione tramite il recupero anticipato o il prerendering delle navigazioni future. Questi miglioramenti aggiuntivi sono ora tutti disponibili a partire da Chrome 122 (alcune funzionalità sono disponibili a partire dalle versioni precedenti).
Queste modifiche rendono il prefetching e il prerendering delle pagine notevolmente più facili da implementare e meno dispendiosi, il che ci auguriamo incoraggerà un'ulteriore adozione.
Altre funzionalità
Innanzitutto, spiegheremo le nuove aggiunte che abbiamo apportato all'API Speculation Rules e come utilizzarle. Dopodiché, ti mostreremo una demo per vederli in azione.
Regole per i documenti
In precedenza, l'API Speculation Rules funzionava specificando un elenco di URL da precaricare o prerenderizzare:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Le regole di speculazione erano semi-dinamiche in quanto era possibile aggiungere nuovi script di regole di speculazione e rimuovere quelli vecchi per scartare le speculazioni (tieni presente che l'aggiornamento dell'elenco urls di uno script di regole di speculazione esistente non attiva una modifica delle speculazioni). Tuttavia, lasciava comunque la scelta degli URL al sito, inviandoli dal server al momento della richiesta della pagina o creando dinamicamente questo elenco tramite JavaScript lato client.
Le regole di elenco rimangono un'opzione per i casi d'uso più semplici (in cui la navigazione successiva avviene da un piccolo insieme di opzioni ovvie) o per i casi d'uso più avanzati (in cui l'elenco degli URL viene calcolato dinamicamente in base alle euristiche che il proprietario del sito vuole utilizzare e poi inserito nella pagina).
In alternativa, siamo felici di offrire una nuova opzione per la ricerca automatica dei link utilizzando le regole per i documenti. A questo scopo, gli URL vengono recuperati dal documento stesso in base a una condizione where. Ciò può essere basato sui link stessi:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
I selettori CSS possono essere utilizzati anche in alternativa o in combinazione con le corrispondenze href per trovare i link nella pagina corrente:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
In questo modo è possibile utilizzare un unico insieme di regole di speculazione per l'intero sito, anziché averne di specifiche per pagina, il che rende molto più semplice per i siti implementare le regole di speculazione.
Naturalmente, il prerendering di tutti i link di una pagina sarebbe sicuramente uno spreco, quindi con questa nuova funzionalità abbiamo introdotto un'impostazione eagerness.
Entusiasmo
Con qualsiasi tipo di speculazione, esiste un compromesso tra precisione e richiamo e lead time. Il pre-rendering di tutti i link al caricamento della pagina significa che quasi certamente verrà eseguito il pre-rendering di un link su cui fa clic un utente (supponendo che faccia clic su un link dello stesso sito nella pagina) e con il massimo anticipo possibile, ma con un potenziale enorme spreco di larghezza di banda.
D'altra parte, il prerendering solo dopo che un utente ha fatto clic su un link evita gli sprechi, ma a costo di un lead time molto ridotto. Ciò significa che è improbabile che il prerendering sia stato completato prima che il browser passi a quella pagina.
L'impostazione eagerness ti consente di definire quando devono essere eseguite le speculazioni, separando quando eseguire le speculazioni dagli URL su cui eseguirle. L'impostazione eagerness è disponibile per le regole di origine list e document e ha quattro impostazioni, per le quali Chrome ha le seguenti euristiche:
immediate: viene utilizzato per la speculazione il prima possibile, ovvero non appena vengono osservate le regole di speculazione.eager:al momento si comporta in modo identico all'impostazioneimmediate, ma in futuro prevediamo di posizionarla a metà strada traimmediateemoderate.moderate: esegue speculazioni se passi il mouse sopra un link per 200 millisecondi (o sull'eventopointerdownse si verifica prima e sui dispositivi mobili dove non è presente l'eventohover).conservative: questa specifica si basa sul puntatore o sul tocco.
Il valore predefinito di eagerness per le regole list è immediate. Le opzioni moderate e conservative possono essere utilizzate per limitare le regole list agli URL con cui un utente interagisce in un elenco specifico. Tuttavia, in molti casi, le regole document con una condizione where appropriata potrebbero essere più adatte.
Il valore predefinito di eagerness per le regole document è conservative. Poiché un documento può essere costituito da molti URL, l'utilizzo di immediate o eager per le regole document deve essere utilizzato con cautela (vedi anche la sezione Limiti di Chrome di seguito).
L'impostazione eagerness da utilizzare dipende dal tuo sito. Per un sito statico molto semplice, la speculazione più entusiasta può avere un costo minimo ed essere vantaggiosa per gli utenti. I siti con architetture più complesse e payload di pagina più pesanti potrebbero preferire ridurre gli sprechi speculando meno spesso finché non si ottiene un segnale di intento più positivo da parte degli utenti per limitare gli sprechi.
L'opzione moderate è una via di mezzo e molti siti potrebbero trarre vantaggio dalla seguente semplice regola di speculazione che pre-renderizza tutti i link al passaggio del mouse o al puntatore verso il basso come implementazione di base, ma potente, delle regole di speculazione:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Limiti di Chrome
Anche con la scelta di eagerness, Chrome ha dei limiti per impedire l'uso eccessivo di questa API:
eagerness |
Precaricamento | Prerender |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
Le impostazioni moderate e conservative, che dipendono dall'interazione utente, funzionano in modalità First In, First Out (FIFO). Una volta raggiunto il limite, una nuova speculazione causerà l'annullamento della speculazione meno recente, che verrà sostituita da quella più recente per risparmiare memoria.
Il fatto che le speculazioni moderate e conservative vengano attivate dagli utenti ci consente di utilizzare una soglia più modesta di 2 per risparmiare memoria. Le impostazioni immediate e eager non vengono attivate da un'azione dell'utente e pertanto hanno un limite superiore, in quanto il browser non può sapere quali sono necessarie e quando.
Una speculazione annullata perché è stata spostata fuori dalla coda FIFO può essere attivata di nuovo, ad esempio passando di nuovo il mouse sopra il link, il che comporterà una nuova speculazione dell'URL. In questo caso, la precedente speculazione avrà probabilmente causato la memorizzazione nella cache di alcune risorse nella cache HTTP per quell'URL, quindi la ripetizione della speculazione dovrebbe comportare costi di rete e di tempo molto ridotti.
Anche i limiti immediate e eager sono dinamici. La rimozione di un elemento di script delle regole di speculazione utilizzando questi livelli di impazienza creerà capacità annullando le speculazioni rimosse. Questi URL possono anche essere nuovamente ipotizzati se sono inclusi in un nuovo script di URL e il limite non è stato raggiunto.
Chrome impedirà inoltre l'utilizzo di speculazioni in determinate condizioni, tra cui:
- Save-Data.
- Risparmio energetico.
- Vincoli di memoria.
- Quando l'impostazione "Precarica pagine" è disattivata (e disattivata anche esplicitamente da estensioni di Chrome come uBlock Origin).
- Pagine aperte nelle schede in background.
Tutte queste condizioni mirano a ridurre l'impatto della speculazione eccessiva quando sarebbe dannosa per gli utenti.
Facoltativo source
Chrome 122 rende facoltativo il tasto source, in quanto può essere dedotto dalla presenza dei tasti url o where. Queste due regole di speculazione sono quindi identiche:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Intestazione HTTP Speculation-Rules
Le regole di speculazione possono essere pubblicate anche utilizzando un'intestazione HTTP Speculation-Rules, anziché includerle direttamente nell'HTML del documento. Ciò consente una distribuzione più semplice da parte delle CDN senza la necessità di modificare i contenuti dei documenti stessi.
L'intestazione HTTP Speculation-Rules viene restituita con il documento e rimanda a un percorso di un file JSON contenente le regole di speculazione:
Speculation-Rules: "/speculationrules.json"
Questa risorsa deve utilizzare il tipo MIME corretto e, se è una risorsa multiorigine, superare un controllo CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Se vuoi utilizzare gli URL relativi, ti consigliamo di includere la chiave "relative_to": "document" nelle regole di speculazione. In caso contrario, gli URL relativi saranno relativi all'URL del file JSON delle regole di speculazione. Questa opzione può essere particolarmente utile se devi selezionare alcuni o tutti i link della stessa origine.
Riutilizzo migliore della cache
Abbiamo apportato una serie di miglioramenti alla memorizzazione nella cache in Chrome, in modo che il recupero anticipato (o anche il prerendering) di un documento memorizzi e riutilizzi le risorse nella cache HTTP. Ciò significa che la speculazione può comunque avere vantaggi futuri, anche se non viene utilizzata.
In questo modo, anche la nuova specifica (ad esempio, per le regole dei documenti con un'impostazione di moderate) risulta notevolmente più economica, in quanto Chrome utilizzerà la cache HTTP per le risorse memorizzabili nella cache.
Supportiamo anche la nuova proposta No-Vary-Search per migliorare ulteriormente il riutilizzo della cache.
Assistenza No-Vary-Search
Quando viene eseguito il prefetching o il prerendering di una pagina, alcuni parametri URL (tecnicamente noti come parametri di ricerca) potrebbero non essere importanti per la pagina effettivamente pubblicata dal server e utilizzati solo da JavaScript lato client.
Ad esempio, i parametri UTM vengono utilizzati da Google Analytics per la misurazione delle campagne, ma in genere non comportano la pubblicazione di pagine diverse dal server. Ciò significa che page1.html?utm_content=123 e page1.html?utm_content=456 forniranno la stessa pagina dal server, quindi la stessa pagina può essere riutilizzata dalla cache.
Allo stesso modo, le applicazioni possono utilizzare altri parametri URL gestiti solo lato client.
La proposta No-Vary-Search consente a un server di specificare parametri che non comportano una differenza nella risorsa fornita e quindi consentono a un browser di riutilizzare le versioni memorizzate nella cache di un documento che differiscono solo per questi parametri. Nota: al momento questa funzionalità è supportata solo in Chrome (e nei browser basati su Chromium) per le specifiche di navigazione prefetch.
Le regole di speculazione supportano l'utilizzo di expects_no_vary_search per indicare dove è previsto che venga restituita un'intestazione HTTP No-Vary-Search. In questo modo, puoi evitare ulteriormente download non necessari.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
In questo esempio, il codice HTML della pagina iniziale /products è lo stesso per entrambi gli ID prodotto 123 e 124. Tuttavia, i contenuti della pagina alla fine differiscono in base al rendering lato client che utilizza JavaScript per recuperare i dati di prodotto utilizzando il parametro di ricerca id. Pertanto, precarichiamo questo URL in modo rapido e dovrebbe restituire un'intestazione HTTP No-Vary-Search che indica che la pagina può essere utilizzata per qualsiasi parametro di ricerca id.
Tuttavia, se l'utente fa clic su uno dei link prima del completamento del recupero, il browser potrebbe non aver ricevuto la pagina /products. In questo caso, il browser non sa se conterrà l'intestazione HTTP No-Vary-Search. Il browser può scegliere se recuperare di nuovo il link o attendere il completamento del prefetch per verificare se contiene un'intestazione HTTP No-Vary-Search. L'impostazione expects_no_vary_search consente al browser di sapere che la risposta della pagina dovrebbe contenere un'intestazione HTTP No-Vary-Search e di attendere il completamento del recupero preliminare.
Demo
Abbiamo creato una demo all'indirizzo https://chrome.dev/speculative-loading/common-fruits.html che può essere utilizzata per visualizzare le regole del documento con un'impostazione di moderate in azione:
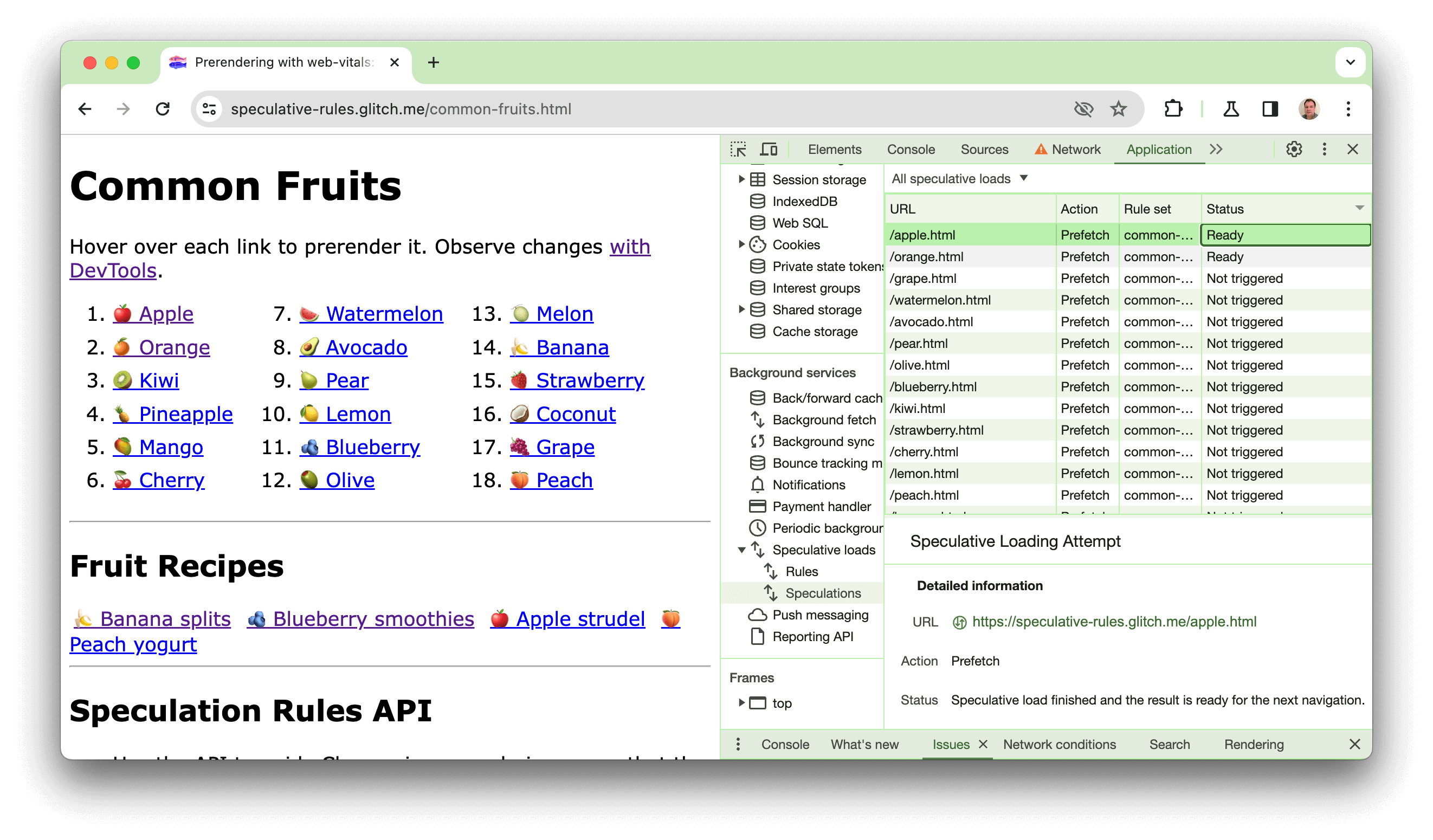
Apri DevTools e fai clic sul riquadro Applicazione. Poi, nella sezione Servizi in background, fai clic su Caricamenti speculativi, poi sul riquadro Speculazioni e ordina per la colonna Stato.
Quando passi il mouse sopra i frutti, vedrai il prerendering delle pagine. Se fai clic su uno di questi elementi, il tempo LCP sarà molto più rapido rispetto a quello di una delle ricette, che non vengono pre-renderizzate. Questa demo è spiegata anche nel video seguente:
Per ulteriori informazioni su come utilizzare DevTools per eseguire il debug delle regole di speculazione, puoi anche consultare il precedente post del blog sul debug delle regole di speculazione.
Supporto della piattaforma per le regole di speculazione
Sebbene le regole di speculazione siano relativamente semplici da implementare inserendole in un elemento <script type="speculationrules">, il supporto della piattaforma può rendere questa operazione un gioco da ragazzi. Abbiamo collaborato con varie piattaforme e partner per semplificare l'implementazione delle regole sulla speculazione.
Stiamo anche lavorando duramente per standardizzare l'API tramite il Web Incubator Community Group (WICG) per consentire anche ad altri browser di implementare questa entusiasmante API, se lo desiderano.
WordPress
Il team WordPress Core Performance (inclusi gli sviluppatori di Google) ha creato un plug-in Speculation Rules. Questo plug-in consente di aggiungere con un semplice clic il supporto delle regole dei documenti a qualsiasi sito WordPress. Questo plug-in è disponibile anche per l'installazione tramite il plug-in WordPress Performance Lab, che ti consigliamo di installare per rimanere aggiornato sui plug-in per il rendimento correlati del team.
Sono disponibili due gruppi di impostazioni: la modalità Speculazione e l'impostazione Entusiasmo:

Per configurazioni più complesse, ad esempio per escludere determinati URL dal precaricamento o dal prerendering, leggi la documentazione.
Akamai
Akamai è uno dei principali fornitori di CDN al mondo e da tempo sperimenta attivamente l'API Speculation Rules. Akamai ha pubblicato la documentazione su come i clienti possono attivare questa API nelle impostazioni CDN. In precedenza, hanno anche condiviso gli impressionanti risultati possibili con questa nuova API.
Uxify
Uxify (in precedenza parte di Nitropack) è una soluzione di ottimizzazione delle prestazioni che utilizza la sua AI di navigazione personalizzata per prevedere quali pagine aggiungere alle regole di speculazione, con l'obiettivo di fornire un lead time più lungo rispetto al passaggio del mouse sopra un link, ma senza lo spreco di speculazioni inutili su tutti i link osservati. Per saperne di più, consulta la documentazione dell'API Uxify Speculation Rules. Questa soluzione innovativa dimostra che le regole degli elenchi precedenti hanno ancora molto da offrire se abbinate a approfondimenti specifici per il sito.
Il team di Chrome ha anche collaborato con il team per un webinar sull'API Speculation Rules per chi cerca maggiori informazioni, tra cui una buona discussione sulle considerazioni necessarie tra la speculazione anticipata e frequente, nonché quella tardiva e meno frequente.
Astrofotografia
Astro ha aggiunto il prerendering delle pagine utilizzando l'API Speculation Rules nella versione 4.2 in via sperimentale, consentendo agli sviluppatori che utilizzano Astro di attivare facilmente questa funzionalità, mentre viene eseguito il fallback a un prefetch standard per i browser che non supportano l'API Speculation Rules. Per saperne di più, leggi la documentazione sul prerendering del client.
Conclusione
Queste aggiunte all'API Speculation Rules consentono un utilizzo molto più semplice di questa nuova entusiasmante funzionalità di rendimento per i siti, con un rischio minore di sprecare risorse con speculazioni inutilizzate. È entusiasmante vedere che le piattaforme si appoggiano già a questa API. Ci auguriamo di vedere una più ampia adozione di questa API nel 2024 e, di conseguenza, un miglioramento delle prestazioni per gli utenti finali.
Oltre ai miglioramenti delle prestazioni offerti dall'API Speculation Rules, siamo entusiasti di vedere le nuove opportunità che si aprono. View Transitions è una nuova API che consente agli sviluppatori di specificare più facilmente le transizioni tra le navigazioni. Al momento è disponibile per le applicazioni a pagina singola (SPA), ma la versione multipagina è in fase di sviluppo (e disponibile dietro un flag in Chrome). Il prerendering è un'estensione naturale di questa funzionalità per garantire che non ci siano ritardi, il che altrimenti impedirebbe il miglioramento dell'esperienza utente che la transizione intende fornire. Abbiamo già visto siti sperimentare questa combinazione.
Ci auguriamo che l'API Speculation Rules venga adottata sempre più nel corso del 2024 e ti terremo aggiornato su eventuali ulteriori miglioramenti apportati all'API.
Ringraziamenti
Miniatura di Robbie Down su Unsplash