

Zespół Chrome pracuje nad ciekawymi aktualizacjami interfejsu Speculation Rules API, który służy do zwiększania wydajności nawigacji przez wstępne pobieranie lub renderowanie przyszłych nawigacji. Te dodatkowe ulepszenia są teraz dostępne w Chrome 122 (niektóre funkcje są dostępne w starszych wersjach).
Te zmiany znacznie ułatwiają wdrażanie i ograniczają marnotrawstwo zasobów podczas wstępnego pobierania i renderowania stron, co, mamy nadzieję, zachęci do dalszego korzystania z tych funkcji.
Dodatkowe funkcje
Na początek wyjaśnimy, jakie nowe elementy dodaliśmy do interfejsu Speculation Rules API i jak z nich korzystać. Następnie pokażemy Ci wersję demonstracyjną, abyś mógł zobaczyć, jak działają.
Reguły dotyczące dokumentów
Wcześniej interfejs Speculation Rules API działał przez określenie listy adresów URL do pobrania z wyprzedzeniem lub wyrenderowania z wyprzedzeniem:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Reguły spekulacji były częściowo dynamiczne, ponieważ można było dodawać nowe skrypty reguł spekulacji i usuwać stare skrypty, aby odrzucać te spekulacje (pamiętaj, że aktualizacja listy urls w istniejącym skrypcie reguł spekulacji nie powoduje zmiany spekulacji). Jednak nadal pozostawiało to wybór adresów URL witrynie – mogła ona wysyłać je z serwera w momencie wysłania żądania strony lub dynamicznie tworzyć tę listę za pomocą JavaScriptu po stronie klienta.
Reguły listy pozostają opcją w przypadku prostszych zastosowań (gdy następna nawigacja pochodzi z niewielkiego zestawu oczywistych opcji) lub bardziej zaawansowanych zastosowań (gdy lista adresów URL jest obliczana dynamicznie na podstawie dowolnych heurystyk, których właściciel witryny chce użyć, a następnie wstawiana na stronę).
Zamiast tego z przyjemnością przedstawiamy nową opcję automatycznego wyszukiwania linków za pomocą reguł dokumentu. Działa to na podstawie adresów URL pochodzących z samego dokumentu, które są wybierane na podstawie where warunku. Może to zależeć od samych linków:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Selektory CSS mogą być też używane jako alternatywa lub w połączeniu z dopasowaniami href do znajdowania linków na bieżącej stronie:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
Dzięki temu w całej witrynie można używać jednego zestawu reguł spekulacyjnych, a nie osobnych reguł dla każdej strony. Ułatwia to witrynom wdrażanie reguł spekulacyjnych.
Wstępne renderowanie wszystkich linków na stronie byłoby oczywiście marnotrawstwem, dlatego wprowadziliśmy nowe ustawienie eagerness.
chęć,
W przypadku wszelkiego rodzaju spekulacji istnieje kompromis między precyzją a czułością oraz czasem wyprzedzenia. Wstępne renderowanie wszystkich linków podczas wczytywania strony oznacza, że prawie na pewno wstępnie wyrenderujesz link, który kliknie użytkownik (zakładając, że kliknie on link do tej samej witryny na stronie), i to z jak największym wyprzedzeniem, ale może to spowodować ogromne marnotrawstwo przepustowości.
Z drugiej strony wstępne renderowanie tylko po kliknięciu linku przez użytkownika zapobiega marnowaniu zasobów, ale kosztem znacznie krótszego czasu oczekiwania. Oznacza to, że jest mało prawdopodobne, aby wstępne renderowanie zostało zakończone, zanim przeglądarka przełączy się na tę stronę.
Ustawienie eagerness pozwala określić, kiedy mają być uruchamiane spekulacje, oddzielając kiedy spekulować od tego, na których adresach URL mają być przeprowadzane spekulacje. Ustawienie eagerness jest dostępne w przypadku reguł źródła list i document. Ma 4 ustawienia, dla których Chrome stosuje te heurystyki:
immediate: służy do spekulacji tak szybko, jak to możliwe, czyli od razu po zaobserwowaniu reguł spekulacyjnych.eager: obecnie działa tak samo jak ustawienieimmediate, ale w przyszłości planujemy umieścić je między ustawieniamiimmediateimoderate.moderate: funkcja ta wykonuje spekulacje, jeśli najedziesz kursorem na link na 200 milisekund (lub w przypadku zdarzeniapointerdown, jeśli nastąpi ono wcześniej, a także na urządzeniach mobilnych, na których nie występuje zdarzeniehover).conservative: – spekulacja dotycząca naciśnięcia wskaźnika lub ekranu dotykowego.
Domyślna wartość eagerness dla reguł list to immediate. Opcje moderate i conservative mogą służyć do ograniczenia reguł list do adresów URL, z którymi użytkownik wchodzi w interakcję, do określonej listy. W wielu przypadkach bardziej odpowiednie mogą być jednak documentreguły z odpowiednim wherewarunkiem.
Domyślna wartość eagerness dla reguł document to conservative. Dokument może zawierać wiele adresów URL, dlatego używanie tagów immediate lub eager w przypadku reguł document powinno być ostrożne (patrz też sekcja Limity Chrome poniżej).
Które ustawienie eagerness wybrać, zależy od Twojej witryny. W przypadku bardzo prostej witryny statycznej bardziej agresywne spekulowanie może być mało kosztowne i korzystne dla użytkowników. Witryny o bardziej złożonej architekturze i większych rozmiarach stron mogą ograniczyć marnotrawstwo, rzadziej spekulując, dopóki nie uzyskają od użytkowników bardziej pozytywnego sygnału intencji.
Opcja moderate to rozwiązanie pośrednie. Wiele witryn może skorzystać z tej prostej reguły spekulacji, która wstępnie renderuje wszystkie linki po najechaniu na nie wskaźnikiem lub kliknięciu ich. Jest to podstawowe, ale skuteczne wdrożenie reguł spekulacji:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Limity Chrome
Nawet w przypadku wyboru eagerness Chrome ma ograniczenia, które zapobiegają nadmiernemu korzystaniu z tego interfejsu API:
eagerness |
Pobieranie z wyprzedzeniem | Prerender |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
Ustawienia moderate i conservative, które zależą od interakcji użytkownika, działają w kolejności FIFO (First In, First Out). Po osiągnięciu limitu nowa spekulacja spowoduje anulowanie najstarszej spekulacji i zastąpienie jej nowszą, aby oszczędzać pamięć.
Fakt, że spekulacje moderate i conservative są wywoływane przez użytkowników, pozwala nam używać mniejszego progu 2, aby oszczędzać pamięć. Ustawienia immediate i eager nie są wywoływane przez działanie użytkownika, więc mają wyższy limit, ponieważ przeglądarka nie może wiedzieć, które z nich są potrzebne i kiedy.
Spekulację, która została anulowana przez przesunięcie poza kolejkę FIFO, można ponownie wywołać, np. przez ponowne najechanie kursorem na link. Spowoduje to ponowne spekulowanie adresu URL. W takim przypadku poprzednie spekulacje prawdopodobnie spowodowały, że przeglądarka zapisała w pamięci podręcznej HTTP niektóre zasoby dla tego adresu URL, więc powtórzenie spekulacji powinno wiązać się ze znacznie mniejszymi kosztami sieciowymi i czasowymi.
Limity immediate i eager również są dynamiczne. Usunięcie elementu skryptu reguł spekulacji przy użyciu tych poziomów gotowości spowoduje utworzenie pojemności przez anulowanie usuniętych spekulacji. Te adresy URL można też ponownie uwzględnić w prognozie, jeśli znajdują się w nowym skrypcie adresów URL, a limit nie został osiągnięty.
Chrome będzie też zapobiegać używaniu spekulacji w określonych warunkach, w tym:
- Save-Data.
- Oszczędzanie energii.
- ograniczenia pamięci,
- Gdy ustawienie „Wstępnie ładuj strony” jest wyłączone (co jest też wyraźnie wyłączane przez rozszerzenia Chrome, takie jak uBlock Origin).
- Strony otwarte na kartach w tle.
Wszystkie te warunki mają na celu ograniczenie wpływu nadmiernej spekulacji, gdy może ona być szkodliwa dla użytkowników.
Opcjonalne source
W Chrome 122 klucz source jest opcjonalny, ponieważ można go wywnioskować na podstawie obecności kluczy url lub where. Te 2 reguły spekulacyjne są zatem identyczne:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules Nagłówek HTTP
Reguły spekulacyjne można też dostarczać za pomocą Speculation-Rules nagłówka HTTP, zamiast umieszczać je bezpośrednio w HTML-u dokumentu. Ułatwia to wdrażanie przez sieci CDN bez konieczności zmiany zawartości dokumentów.
Nagłówek HTTP Speculation-Rules jest zwracany z dokumentem i wskazuje lokalizację pliku JSON zawierającego reguły spekulacji:
Speculation-Rules: "/speculationrules.json"
Ten zasób musi używać prawidłowego typu MIME, a jeśli jest zasobem pochodzącym z innej domeny, musi przejść sprawdzanie CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Jeśli chcesz używać względnych adresów URL, możesz uwzględnić klucz "relative_to": "document" w regułach spekulacji. W przeciwnym razie adresy URL będą względne względem adresu URL pliku JSON z regułami spekulacji. Może to być szczególnie przydatne, jeśli musisz wybrać niektóre lub wszystkie linki z tej samej domeny.
Lepsze ponowne wykorzystanie pamięci podręcznej
Wprowadziliśmy w Chrome szereg ulepszeń dotyczących pamięci podręcznej, dzięki czemu wstępne pobieranie (a nawet wstępne renderowanie) dokumentu będzie powodować zapisywanie i ponowne wykorzystywanie zasobów w pamięci podręcznej HTTP. Oznacza to, że spekulacje mogą nadal przynosić korzyści w przyszłości, nawet jeśli nie są wykorzystywane.
Sprawia to również, że ponowne spekulowanie (np. w przypadku reguł dokumentów z ustawieniem moderate eagerness) jest znacznie tańsze, ponieważ Chrome będzie używać pamięci podręcznej HTTP w przypadku zasobów, które można w niej przechowywać.
Popieramy też nową No-Vary-Search propozycję, która ma na celu dalsze zwiększenie ponownego wykorzystania pamięci podręcznej.
No-Vary-Search – pomoc
Podczas wstępnego pobierania lub wstępnego renderowania strony niektóre parametry URL (technicznie znane jako parametry wyszukiwania) mogą być nieistotne dla strony faktycznie dostarczanej przez serwer i używane tylko przez JavaScript po stronie klienta.
Na przykład parametry UTM są używane przez Google Analytics do pomiaru kampanii, ale zwykle nie powodują, że serwer dostarcza różne strony. Oznacza to, że page1.html?utm_content=123 i page1.html?utm_content=456 będą dostarczać tę samą stronę z serwera, więc tę samą stronę można ponownie wykorzystać z pamięci podręcznej.
Podobnie aplikacje mogą używać innych parametrów adresu URL, które są obsługiwane tylko po stronie klienta.
Propozycja No-Vary-Search umożliwia serwerowi określenie parametrów, które nie powodują różnicy w dostarczanym zasobie, a tym samym pozwalają przeglądarce na ponowne wykorzystanie wcześniej zapisanych w pamięci podręcznej wersji dokumentu, które różnią się tylko tymi parametrami. Uwaga: obecnie ta funkcja jest obsługiwana tylko w przypadku spekulacji dotyczących nawigacji z wstępnym pobieraniem w Chrome (i przeglądarkach opartych na Chromium).
Reguły spekulacyjne obsługują używanie expects_no_vary_search do wskazywania, gdzie ma być zwracany nagłówek HTTP No-Vary-Search. Pomoże to uniknąć niepotrzebnych pobrań.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
W tym przykładzie /products początkowy kod HTML strony jest taki sam w przypadku obu identyfikatorów produktów 123 i 124. Zawartość strony różni się jednak w zależności od renderowania po stronie klienta, które wykorzystuje JavaScript do pobierania danych o produktach za pomocą parametru wyszukiwania id. Dlatego wstępnie pobieramy ten adres URL i powinien on zwracać nagłówek HTTP No-Vary-Search wskazujący, że strona może być używana w przypadku dowolnego parametru wyszukiwania id.
Jeśli jednak użytkownik kliknie któryś z linków, zanim wstępne pobieranie się zakończy, przeglądarka może nie otrzymać strony /products. W tym przypadku przeglądarka nie wie, czy będzie zawierać nagłówek HTTP No-Vary-Search. Przeglądarka musi wtedy zdecydować, czy ponownie pobrać link, czy poczekać na zakończenie wstępnego pobierania, aby sprawdzić, czy zawiera on nagłówek HTTP No-Vary-Search. Ustawienie expects_no_vary_search informuje przeglądarkę, że odpowiedź strony powinna zawierać nagłówek HTTP No-Vary-Search, i nakazuje jej poczekać na zakończenie wstępnego pobierania.
Prezentacja
Przygotowaliśmy wersję demonstracyjną na stronie https://chrome.dev/speculative-loading/common-fruits.html, która pokazuje działanie reguł dokumentów z ustawieniem moderate:
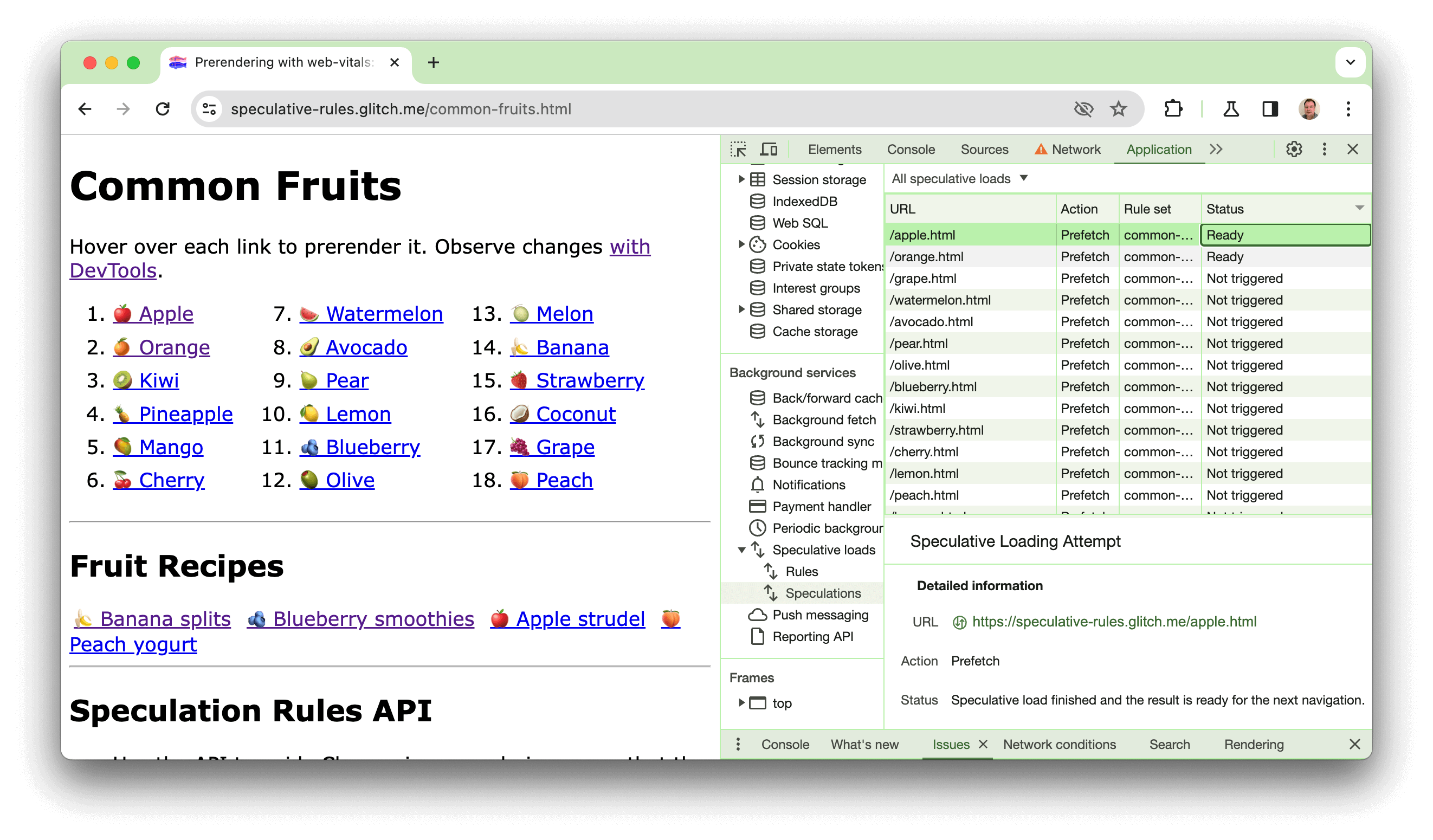
Otwórz Narzędzia deweloperskie i kliknij panel Aplikacja. Następnie w sekcji Usługi w tle kliknij Spekulacyjne wczytywanie, a potem panel Spekulacje i posortuj dane według kolumny Stan.
Gdy najedziesz kursorem na owoce, zobaczysz wstępne renderowanie stron. Kliknięcie ich spowoduje wyświetlenie znacznie krótszego czasu LCP niż w przypadku przepisów, które nie są wstępnie renderowane. Prezentację tę omówiliśmy również w tym filmie:
Więcej informacji o tym, jak używać Narzędzi deweloperskich do debugowania reguł spekulacyjnych, znajdziesz w poprzednim poście na blogu o debugowaniu reguł spekulacyjnych.
Obsługa platformy w przypadku reguł spekulacyjnych
Reguły spekulacyjne są stosunkowo proste do wdrożenia przez wstrzyknięcie ich do elementu <script type="speculationrules">, ale obsługa platformy może sprawić, że będzie to wymagało tylko jednego kliknięcia. Współpracujemy z różnymi platformami i partnerami, aby ułatwić wdrażanie reguł dotyczących spekulacji.
Intensywnie pracujemy też nad standaryzacją interfejsu API w ramach Web Incubator Community Group (WICG), aby umożliwić innym przeglądarkom wdrożenie tego interfejsu API, jeśli zdecydują się na to.
WordPress
Zespół ds. wydajności WordPressa (w tym programiści z Google) stworzył wtyczkę Speculation Rules. Ta wtyczka umożliwia proste dodanie obsługi reguł dokumentów do dowolnej witryny WordPress za pomocą jednego kliknięcia. Tę wtyczkę można też zainstalować za pomocą wtyczki WordPress Performance Lab, którą również warto zainstalować, ponieważ będzie ona informować Cię o powiązanych wtyczkach dotyczących wydajności.
Dostępne są 2 grupy ustawień: Tryb spekulacji i Chęć:

W przypadku bardziej skomplikowanych konfiguracji, np. aby wykluczyć określone adresy URL z wstępnego pobierania lub wstępnego renderowania, zapoznaj się z dokumentacją.
Akamai
Akamai to jeden z największych na świecie dostawców sieci CDN, który od jakiegoś czasu aktywnie eksperymentuje z interfejsem Speculation Rules API. Firma Akamai opublikowała dokumentację, która opisuje, jak klienci mogą włączyć ten interfejs API w ustawieniach sieci CDN. Udostępnili też wcześniej imponujące wyniki, jakie można osiągnąć dzięki temu nowemu interfejsowi API.
Uxify
Uxify (wcześniej część Nitropack) to rozwiązanie do optymalizacji wydajności, które wykorzystuje niestandardową sztuczną inteligencję do przewidywania, które strony należy dodać do reguł spekulacji. Ma to zapewnić dłuższy czas oczekiwania niż w przypadku najechania kursorem na link, ale bez marnowania zasobów na niepotrzebne spekulacje dotyczące wszystkich zaobserwowanych linków. Więcej informacji znajdziesz w dokumentacji interfejsu Uxify Speculation Rules API. To innowacyjne rozwiązanie pokazuje, że starsze reguły list w połączeniu z informacjami o konkretnych witrynach nadal mają wiele do zaoferowania.
Zespół Chrome współpracował też z zespołem ds. interfejsu Speculation Rules API przy tworzeniu webinaru na temat tego interfejsu dla osób, które chcą uzyskać więcej informacji, w tym szczegółowe omówienie kwestii, które należy wziąć pod uwagę przy spekulowaniu wcześnie i często oraz późno i rzadziej.
Astro
W wersji 4.2 platforma Astro dodała eksperymentalną funkcję wstępnego renderowania stron za pomocą interfejsu Speculation Rules API, dzięki czemu deweloperzy korzystający z Astro mogą łatwo włączyć tę funkcję, a w przypadku przeglądarek, które nie obsługują interfejsu Speculation Rules API, mogą wrócić do standardowego pobierania wstępnego. Więcej informacji znajdziesz w dokumentacji dotyczącej wstępnego renderowania po stronie klienta.
Podsumowanie
Te dodatki do interfejsu Speculation Rules API znacznie ułatwiają korzystanie z tej nowej, interesującej funkcji zwiększającej wydajność witryn i zmniejszają ryzyko marnowania zasobów na nieużywane spekulacje. Cieszy nas, że platformy już korzystają z tego interfejsu API. Mamy nadzieję, że w 2024 r. ten interfejs API będzie szerzej stosowany, co przełoży się na lepsze działanie usług dla użytkowników.
Oprócz wzrostu wydajności, jaki zapewnia Speculation Rules API, cieszymy się też z nowych możliwości, jakie otwiera. View Transitions to nowy interfejs API, który ułatwia deweloperom określanie przejść między nawigacjami. Obecnie jest ona dostępna w przypadku aplikacji jednostronicowych, ale wersja wielostronicowa jest w trakcie opracowywania (i jest dostępna w Chrome za pomocą flagi). Wstępne renderowanie jest naturalnym uzupełnieniem tej funkcji, ponieważ zapewnia brak opóźnień, które mogłyby pogorszyć wygodę użytkowników, a nie ją zwiększyć. Widzieliśmy już witryny, które eksperymentowały z tą kombinacją.
W 2024 roku spodziewamy się dalszego upowszechnienia interfejsu Speculation Rules API. Będziemy Cię informować o wszystkich jego ulepszeniach.
Podziękowania
Miniatura autorstwa Robbiego Downa z Unsplash