

הצוות של Chrome עבד על כמה עדכונים מעניינים ל-Speculation Rules API, שמשמש לשיפור ביצועי הניווט על ידי אחזור מראש או אפילו עיבוד מראש של ניווטים עתידיים. כל השיפורים הנוספים האלה זמינים עכשיו מגרסה Chrome 122 (חלק מהתכונות זמינות מגרסאות קודמות).
השינויים האלה מקלים מאוד על הטמעה של אחזור מראש וטרום-עיבוד של דפים, ומצמצמים את הבזבוז, ואנחנו מקווים שהם יעודדו עוד אנשים להשתמש בהם.
תכונות נוספות
קודם כל, נסביר על התוספות החדשות שהוספנו ל-Speculation Rules API ואיך משתמשים בהן. לאחר מכן, נציג הדגמה כדי שתוכלו לראות את הפעולות בפועל.
כללים לגבי מסמכים
בעבר, Speculation Rules API פעל על ידי ציון רשימה של כתובות URL לאחזור מראש או לעיבוד מראש:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
כללי הניחוש היו דינמיים למחצה, כי אפשר היה להוסיף סקריפטים חדשים של כללי ניחוש ולהסיר סקריפטים ישנים כדי לבטל את הניחושים האלה (חשוב לדעת שעדכון רשימת urls של סקריפט קיים של כללי ניחוש לא מפעיל שינוי בניחושים). עם זאת, עדיין נשארת הבחירה של כתובות ה-URL בידי האתר, או על ידי שליחתן מהשרת בזמן בקשת הדף, או על ידי יצירת הרשימה הזו באופן דינמי באמצעות JavaScript בצד הלקוח.
כללי רשימה עדיין זמינים לתרחישי שימוש פשוטים יותר (שבהם הניווט הבא הוא מתוך קבוצה קטנה של אפשרויות ברורות), או לתרחישי שימוש מתקדמים יותר (שבהם רשימת כתובות ה-URL מחושבת באופן דינמי על סמך היוריסטיקות שבעל האתר רוצה להשתמש בהן, ואז מוכנסת לדף).
כחלופה, אנחנו שמחים להציע אפשרות חדשה למציאת קישורים אוטומטית באמצעות כללי מסמך. התהליך הזה מתבצע על ידי איתור כתובות URL מתוך המסמך עצמו על סמך תנאי where. ההחלטה יכולה להתבסס על הקישורים עצמם:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
אפשר גם להשתמש בבוררי CSS כחלופה להתאמות של href, או בשילוב איתן, כדי למצוא קישורים בדף הנוכחי:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
כך אפשר להשתמש בקבוצת כללים אחת של ניחושים בכל האתר, במקום להשתמש בקבוצות כללים ספציפיות לכל דף. זה מקל מאוד על אתרים להטמיע כללי ניחושים.
ברור שעיבוד מראש של כל הקישורים בדף יהיה בזבוז משאבים, ולכן הוספנו את ההגדרה eagerness.
Eagerness
בכל סוג של ספקולציה, יש פשרה בין דיוק לבין היקף החיזוי לבין זמן ההמתנה. טרום-עיבוד של כל הקישורים בטעינת הדף אומר שסביר מאוד שיתבצע טרום-עיבוד של קישור שהמשתמש ילחץ עליו (בהנחה שהוא ילחץ על קישור לאותו אתר בדף), ועם כמה שיותר זמן מראש, אבל עם בזבוז פוטנציאלי עצום של רוחב פס.
מצד שני, אם מבצעים טרום-עיבוד רק אחרי שהמשתמש לוחץ על קישור, לא מבזבזים משאבים, אבל זמן ההמתנה ארוך יותר. כלומר, סביר להניח שהטעינה מראש לא תושלם לפני שהדפדפן יעבור לדף הזה.
ההגדרה eagerness מאפשרת להגדיר מתי צריך להריץ ספקולציות, ולהפריד בין מתי לבצע ספקולציות לבין כתובות ה-URL שבהן צריך לבצע ספקולציות. ההגדרה eagerness זמינה גם לכללי מקור list וגם לכללי מקור document, ויש לה ארבע הגדרות. Chrome משתמש בהיוריסטיקה הבאה כדי לקבוע את ההגדרה:
-
immediate: נעשה שימוש בערך הזה כדי לשער כמה שיותר מהר, כלומר ברגע שמתגלים כללי הספקולציה. -
eager: בשלב הזה, ההגדרה הזו פועלת בדיוק כמו ההגדרהimmediate, אבל בעתיד אנחנו מתכננים למקם אותה ביןimmediateלביןmoderate. -
moderate: המערכת מבצעת ספקולציות אם מעבירים את העכבר מעל קישור למשך 200 מילי-שניות (או באירועpointerdownאם הוא מתרחש מוקדם יותר, ובנייד שבו אין אירועhover). -
conservative: מדובר בניחוש לגבי מיקום הסמן או נקודת המגע.
ערך ברירת המחדל של eagerness לכללי list הוא immediate. אפשר להשתמש באפשרויות moderate ו-conservative כדי להגביל את כללי list לכתובות URL שמשתמש מקיים איתן אינטראקציה ברשימה ספציפית. עם זאת, במקרים רבים, document כללים עם תנאי where מתאים עשויים להיות מתאימים יותר.
ערך ברירת המחדל של eagerness לכללי document הוא conservative. מסמך יכול לכלול הרבה כתובות URL, ולכן צריך להשתמש בזהירות בכללי immediate או eager עבור document (ראו גם את הקטע מגבלות ב-Chrome בהמשך).
ההגדרה eagerness שבה כדאי להשתמש תלויה באתר שלכם. באתר סטטי פשוט מאוד, יכול להיות שאין עלות גבוהה לניחוש מוקדם, והוא יכול להועיל למשתמשים. באתרים עם ארכיטקטורות מורכבות יותר ומטענים כבדים יותר של דפים, כדאי לצמצם את הבזבוז על ידי צמצום התדירות של הניחושים עד שתקבלו אותות חיוביים יותר לגבי כוונת המשתמשים.
האפשרות moderate היא פשרה, ואתרים רבים יכולים להפיק תועלת מכלל הספקולציה הפשוט הבא, שיבצע עיבוד מראש של כל הקישורים בהעברת העכבר או באירוע pointerdown כהטמעה בסיסית אך יעילה של כללי ספקולציה:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
מגבלות ב-Chrome
גם אם בוחרים באפשרות eagerness, יש ב-Chrome מגבלות שנועדו למנוע שימוש יתר ב-API הזה:
eagerness |
שליפה מראש (prefetch) | עיבוד מראש |
|---|---|---|
immediate / eager |
50 | 10 |
moderate / conservative |
2 (FIFO) | 2 (FIFO) |
ההגדרות moderate ו-conservative – שתלויות באינטראקציה של המשתמש – פועלות בשיטת נכנס ראשון, יוצא ראשון (FIFO). אחרי שמגיעים למגבלה, אם מנסים להוסיף השערה חדשה, ההשערה הישנה ביותר מבוטלת ומוחלפת בהשערה החדשה כדי לחסוך בזיכרון.
העובדה שהספקולציות moderate ו-conservative מופעלות על ידי משתמשים מאפשרת לנו להשתמש בסף צנוע יותר של 2 כדי לחסוך בזיכרון. ההגדרות של immediate ושל eager לא מופעלות על ידי פעולת משתמש, ולכן יש להן מגבלה גבוהה יותר כי הדפדפן לא יכול לדעת אילו מהן נדרשות ומתי הן נדרשות.
אפשר להפעיל מחדש ספקולציה שמבוטלת כי היא נדחפת מחוץ לתור FIFO – למשל, על ידי ריחוף מעל הקישור הזה שוב – וכתוצאה מכך תתבצע ספקולציה מחדש של כתובת ה-URL הזו. במקרה כזה, סביר להניח שהספקולציה הקודמת גרמה לדפדפן לשמור במטמון חלק מהמשאבים במטמון ה-HTTP של כתובת ה-URL הזו, ולכן חזרה על הספקולציה תצמצם משמעותית את העלויות של הרשת והזמן.
גם המגבלות של immediate ו-eager הן דינמיות. הסרה של רכיב script של כללי ספקולציה באמצעות רמות המוכנות האלה תיצור קיבולת על ידי ביטול הספקולציות שהוסרו. אפשר גם לשער מחדש את כתובות ה-URL האלה אם הן נכללות בסקריפט חדש של כתובות URL, ולא הגעתם למגבלה.
Chrome גם ימנע שימוש בספקולציות בתנאים מסוימים, כולל:
- Save-Data.
- חיסכון באנרגיה.
- מגבלות זיכרון.
- כשההגדרה 'טעינה מראש של דפים' מושבתת (היא מושבתת גם באופן מפורש על ידי תוספי Chrome כמו uBlock Origin).
- דפים שנפתחו בכרטיסיות ברקע.
כל התנאים האלה נועדו לצמצם את ההשפעה של ספקולציות מוגזמות במקרים שבהם הן עלולות לפגוע במשתמשים.
אופציונלי source
ב-Chrome 122, המפתח source הוא אופציונלי כי אפשר להסיק אותו מהנוכחות של המפתחות url או where. לכן, שני כללי הספקולציה האלה זהים:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules כותרת HTTP
אפשר גם להעביר כללי ספקולציה באמצעות כותרת HTTP של Speculation-Rules, במקום לכלול אותם ישירות ב-HTML של המסמך. כך קל יותר לפרוס את המסמכים באמצעות רשתות CDN בלי לשנות את התוכן שלהם.
כותרת ה-HTTP Speculation-Rules מוחזרת עם המסמך, ומצביעה על מיקום של קובץ JSON שמכיל את כללי הניחוש:
Speculation-Rules: "/speculationrules.json"
למשאב הזה צריך להיות סוג ה-MIME הנכון, ואם הוא משאב חוצה מקורות, הוא צריך לעבור בדיקת CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
אם רוצים להשתמש בכתובות URL יחסיות, כדאי לכלול את המפתח "relative_to": "document" בכללי הניחוש. אחרת, כתובות URL יחסיות יהיו יחסיות לכתובת ה-URL של קובץ ה-JSON של כללי הניחוש. האפשרות הזו שימושית במיוחד אם אתם צריכים לבחור חלק מהקישורים מאותו מקור או את כולם.
שימוש חוזר טוב יותר במטמון
ביצענו מספר שיפורים במטמון ב-Chrome, כך שאחזור מראש (או אפילו טרום-עיבוד) של מסמך יאחסן ויעשה שימוש חוזר במשאבים במטמון HTTP. כלומר, גם אם לא משתמשים בספקולציה, היא עדיין יכולה להניב יתרונות בעתיד.
בנוסף, הפעולה הזו מוזילה משמעותית את העלות של חיזויים חוזרים (לדוגמה, עבור כללי מסמכים עם הגדרת moderate eagerness), כי Chrome ישתמש במטמון HTTP עבור משאבים שניתנים לשמירה במטמון.
אנחנו גם תומכים בהצעה החדשה No-Vary-Search לשיפור נוסף של השימוש החוזר במטמון.
התמיכה של No-Vary-Search
כשמבצעים אחזור מראש או עיבוד מראש של דף, יכול להיות שפרמטרים מסוימים של כתובת URL (שנקראים טכנית פרמטרים של חיפוש) לא חשובים לדף שמועבר בפועל על ידי השרת, ומשמשים רק ל-JavaScript בצד הלקוח.
לדוגמה, מערכת Google Analytics משתמשת בפרמטרים של UTM למדידת קמפיינים, אבל בדרך כלל לא מציגה דפים שונים מהשרת. המשמעות היא שגם page1.html?utm_content=123 וגם page1.html?utm_content=456 יציגו את אותו דף מהשרת, כך שאפשר לעשות שימוש חוזר באותו דף מהמטמון.
באופן דומה, אפליקציות עשויות להשתמש בפרמטרים אחרים של כתובות URL שמטופלים רק בצד הלקוח.
ההצעה No-Vary-Search מאפשרת לשרת לציין פרמטרים שלא גורמים להבדל במשאב שמועבר, ולכן מאפשרת לדפדפן לעשות שימוש חוזר בגרסאות קודמות של מסמך שנשמרו במטמון, ששונות רק בפרמטרים האלה. הערה: בשלב הזה, התכונה הזו נתמכת רק ב-Chrome (ובדפדפנים שמבוססים על Chromium) לניווט מראש.
כללי ניחוש תומכים בשימוש ב-expects_no_vary_search כדי לציין איפה צפויה לחזור כותרת HTTP של No-Vary-Search. כך תוכלו להימנע מהורדות מיותרות.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
בדוגמה הזו, קוד ה-HTML הראשוני של הדף /products זהה לשני מזהי המוצרים 123 ו-124. עם זאת, התוכן של הדף משתנה בסופו של דבר על סמך עיבוד בצד הלקוח באמצעות JavaScript כדי לאחזר נתוני מוצרים באמצעות פרמטר החיפוש id. לכן אנחנו מבצעים אחזור מראש של כתובת ה-URL הזו, והיא אמורה להחזיר כותרת HTTP No-Vary-Search שמראה שאפשר להשתמש בדף לכל פרמטר חיפוש id.
עם זאת, אם המשתמש ילחץ על אחד מהקישורים לפני שההבאה מראש תושלם, יכול להיות שהדפדפן לא יקבל את הדף /products. במקרה הזה, הדפדפן לא יודע אם הוא יכיל את כותרת ה-HTTP No-Vary-Search. בשלב הזה, הדפדפן צריך להחליט אם לאחזר את הקישור שוב או להמתין לסיום האחזור המקדים כדי לבדוק אם הוא מכיל כותרת HTTP No-Vary-Search. ההגדרה expects_no_vary_search מאפשרת לדפדפן לדעת שתגובת הדף צפויה להכיל כותרת HTTP No-Vary-Search, ולהמתין עד לסיום האחזור המקדים.
הדגמה (דמו)
יצרנו הדגמה בכתובת https://chrome.dev/speculative-loading/common-fruits.html שבה אפשר לראות את פעולת הכללים של המסמך עם הגדרת moderate eagerness:
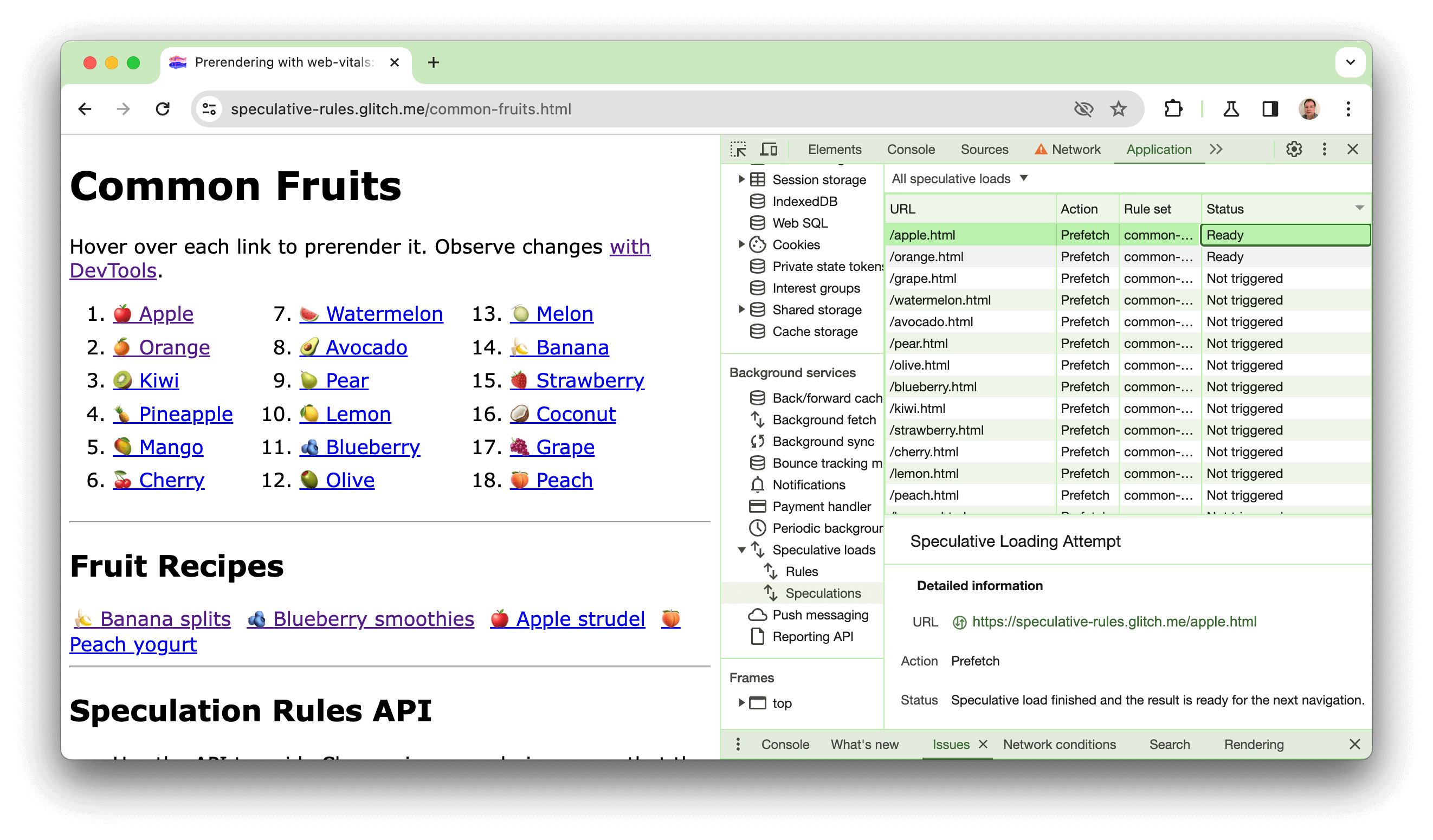
פותחים את כלי הפיתוח ולוחצים על החלונית Application (אפליקציה). לאחר מכן, בקטע Background services (שירותים ברקע), לוחצים על Speculative loads (טעינות ספקולטיביות), ואז על החלונית Speculations (ספקולציות) וממיינים לפי העמודה Status (סטטוס).
כשמעבירים את העכבר מעל הפירות, אפשר לראות את הטעינה המקדימה של הדפים. אם תלחצו על אחת מהן, תוכלו לראות שזמן ה-LCP שלה מהיר בהרבה מזה של אחת מההצעות, שלא עברו טרום-עיבוד. בסרטון הבא מוסבר גם איך להשתמש בהדגמה הזו:
אפשר גם לעיין בפוסט הקודם בבלוג בנושא ניפוי באגים בכללי ניחוש כדי לקבל מידע נוסף על השימוש בכלי הפיתוח לניפוי באגים בכללי ניחוש.
תמיכה בכללי ספקולציות בפלטפורמה
כללי ספקולציה הם פשוטים יחסית להטמעה, באמצעות הוספת הכללים לרכיב <script type="speculationrules">, אבל תמיכה בפלטפורמה יכולה להפוך את ההטמעה לפעולה של קליק אחד. אנחנו עובדים עם פלטפורמות ושותפים שונים כדי להקל על הטמעת כללי הספקולציה.
אנחנו גם פועלים במרץ כדי לתקנן את ה-API באמצעות קבוצת הקהילה של Web Incubator (WICG), כדי לאפשר לדפדפנים אחרים להטמיע גם הם את ה-API המעניין הזה אם יבחרו לעשות זאת.
WordPress
צוות הביצועים של WordPress Core (כולל מפתחים מ-Google) יצר פלאגין של כללי ניחוש. הפלאגין הזה מאפשר להוסיף תמיכה בכללי מסמכים לכל אתר WordPress בלחיצה אחת פשוטה. אפשר להתקין את הפלאגין הזה גם דרך הפלאגין WordPress Performance Lab, שכדאי להתקין אותו כדי לקבל עדכונים על פלאגינים קשורים לביצועים מהצוות.
יש שתי קבוצות של הגדרות: מצב ספקולציה והגדרה של רמת הדחיפות:

להגדרות מורכבות יותר – למשל, כדי להחריג כתובות URL מסוימות מהטעינה מראש או מהרינדור מראש – אפשר לקרוא את התיעוד.
Akamai
Akamai היא אחת מספקי ה-CDN המובילים בעולם, והיא עורכת ניסויים פעילים ב-Speculation Rules API כבר זמן מה. חברת Akamai פרסמה תיעוד שמסביר ללקוחות איך להפעיל את ה-API הזה בהגדרות ה-CDN שלהם. בנוסף, הם שיתפו בעבר את התוצאות המרשימות שאפשר להשיג באמצעות ה-API החדש הזה.
Uxify
Uxify (שבעבר היה חלק מ-Nitropack) הוא פתרון לאופטימיזציה של הביצועים שמשתמש ב-AI מותאם אישית לניווט כדי לחזות אילו דפים להוסיף לכללי הניחוש. המטרה היא לספק זמן הקדמה ארוך יותר מאשר ריחוף מעל קישור, אבל בלי לבזבז משאבים על ניחוש מיותר של כל הקישורים שנצפו. מידע נוסף מופיע במאמרי העזרה של Uxify Speculation Rules API. הפתרון החדשני הזה מראה שעדיין יש הרבה מה להציע לכללי הרשימה הישנים בשילוב עם תובנות ספציפיות לאתר.
צוות Chrome גם שיתף פעולה עם הצוות כדי ליצור סמינר אינטרנטי בנושא Speculation Rules API למי שמחפש מידע נוסף, כולל דיון מעניין על השיקולים שצריך לקחת בחשבון בין ניחוש מוקדם ותכוף לבין ניחוש מאוחר ופחות תכוף.
צילום אסטרונומי
ב-Astro נוספה תכונה לטרום-עיבוד של דפים באמצעות Speculation Rules API בגרסה 4.2 על בסיס ניסיוני. התכונה הזו מאפשרת למפתחים שמשתמשים ב-Astro להפעיל אותה בקלות, ובמקביל להשתמש בטרום-אחזור רגיל בדפדפנים שלא תומכים ב-Speculation Rules API. מידע נוסף זמין בתיעוד של טרום-עיבוד בצד הלקוח.
סיכום
התוספות האלה ל-Speculation Rules API מאפשרות להשתמש בתכונת הביצועים החדשה והמעניינת הזו באתרים בצורה הרבה יותר פשוטה, עם פחות סיכון לבזבוז משאבים בחיזויים שלא נעשה בהם שימוש. מרגש לראות שפלטפורמות כבר משתמשות בממשק ה-API הזה. אנחנו מקווים לראות שימוש נרחב יותר ב-API הזה בשנת 2024, ובסופו של דבר ליהנות מביצועים טובים יותר למשתמשי הקצה.
בנוסף לשיפורים בביצועים ש-Speculation Rules API מספק, אנחנו גם שמחים לראות אילו הזדמנויות חדשות הוא פותח. View Transitions הוא API חדש שמאפשר למפתחים לציין מעברים בין ניווטים בקלות רבה יותר. התכונה הזו זמינה כרגע לאפליקציות של דף יחיד (SPA), אבל גרסת ריבוי הדפים נמצאת בתהליך פיתוח (והיא זמינה מאחורי דגל ב-Chrome). הטכנולוגיה Prerender היא תוספת טבעית לתכונה הזו, והיא מבטיחה שלא יהיה עיכוב, שעלול למנוע את שיפור חוויית המשתמש שהמעבר הזה אמור לספק. כבר ראינו אתרים שמנסים את השילוב הזה.
אנחנו מצפים להטמעה נרחבת יותר של Speculation Rules API במהלך שנת 2024, ונעדכן אתכם לגבי שיפורים נוספים שנערוך ב-API.
תודות
תמונה ממוזערת מאת Robbie Down ב-Unsplash