

Chrome 團隊致力於為 Speculation Rules API 推出令人期待的更新,透過預先擷取或預先算繪未來的瀏覽作業,提升瀏覽效能。現在起,Chrome 122 以上版本都提供這些額外改良功能 (部分功能適用於較舊版本)。
這些變更可大幅簡化預先擷取和預先轉譯網頁的部署作業,並減少浪費,希望有助於進一步推廣這項技術。
其他功能
首先,我們將說明 Speculation Rules API 新增的內容,以及如何使用這些內容。接著,我們會進行示範,讓您瞭解實際運作情形。
文件規則
先前,Speculation Rules API 的運作方式是指定要預先擷取或預先算繪的網址清單:
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next2.html"]
}
]
}
</script>
推測規則是半動態的,因為可以新增推測規則指令碼,也可以移除舊指令碼來捨棄這些推測 (請注意,更新現有推測規則指令碼的 urls 清單不會觸發推測變更)。不過,網站仍可自行選擇網址,方法是在網頁要求時從伺服器傳送網址,或透過用戶端 JavaScript 動態建立這份清單。
清單規則仍適用於較簡單的用途 (下一個導覽來自一小組顯而易見的網址),或更進階的用途 (網址清單會根據網站擁有者想使用的任何啟發式方法動態計算,然後插入網頁)。
我們很榮幸推出替代方案,也就是使用文件規則自動尋找連結的新選項。這項功能會根據 where 條件,從文件本身取得網址。這項資訊可能來自連結本身:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/logout/*"}}
]
},
"eagerness": "moderate"
}]
}
</script>
您也可以使用 CSS 選取器,或搭配 href 比對,在目前網頁中尋找連結:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"and": [
{ "selector_matches": ".prerender" },
{ "not": {"selector_matches": ".do-not-prerender"}}
]
},
"eagerness": "moderate"
}]
}
</script>
這樣一來,整個網站就能使用單一推測規則集,不必為每個網頁指定規則,網站部署推測規則時會輕鬆許多。
當然,預先算繪網頁上的所有連結絕對會浪費資源,因此我們推出了 eagerness 設定,讓您能善用這項新功能。
Eagerness
任何形式的推測都會在精確度和喚回度之間取捨,並影響前置時間。在網頁載入時預先算繪所有連結,幾乎可以確保使用者點選連結時 (假設他們點選網頁上的同網站連結),系統會預先算繪該連結,並盡可能爭取時間,但可能會浪費大量頻寬。
另一方面,只有在使用者點按連結後才預先算繪,可避免浪費資源,但會大幅縮短前置時間。也就是說,瀏覽器切換至該網頁前,不太可能完成預先算繪作業。
eagerness 設定可讓您定義應執行推測的時間,並區分推測時間和要執行推測的網址。eagerness 設定適用於 list 和 document 來源規則,並提供四種設定,Chrome 則會採用下列啟發式方法:
immediate:用於盡快推測,亦即發現推測規則時就開始推測。eager:這與immediate設定的運作方式相同,但我們之後會在immediate和moderate間增加這個程度的設定。moderate:如果您將游標懸停在連結上 200 毫秒,或者發生pointerdown事件 (以較快者為準,在行動裝置上沒有hover事件),那麼就執行推測。conservative:在點下游標或觸碰時推測。
list 規則的預設 eagerness 為 immediate。moderate 和 conservative 選項可用於將 list 規則限制為使用者與特定清單互動的網址。不過在許多情況下,使用適當 where 條件的 document 規則可能更合適。
document 規則的預設 eagerness 為 conservative。由於文件可能包含許多網址,因此使用 immediate 或 eager 建立 document 規則時,請務必謹慎 (另請參閱下方的「Chrome 限制」一節)。
請根據網站選擇要使用的 eagerness 設定。如果是非常簡單的靜態網站,積極預測的成本可能不高,且對使用者有益。如果網站架構較複雜,網頁有效負載較重,建議您減少預測次數,直到使用者提供更多正向意圖信號,藉此減少浪費。
moderate 選項是折衷方案,許多網站都能受益於下列簡單的推測規則,只要將滑鼠懸停在連結上或按下指標,即可預先算繪所有連結,做為推測規則的基本但強大的實作方式:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Chrome 限制
即使選擇 eagerness,Chrome 仍會設下限制,避免過度使用這項 API:
eagerness |
預先擷取 | 預先算繪 |
|---|---|---|
immediate/eager |
50 | 10 |
moderate/conservative |
2 (FIFO) | 2 (FIFO) |
moderate 和 conservative 設定 (取決於使用者互動) 會以先進先出 (FIFO) 方式運作。達到上限後,新的推測會導致系統取消最舊的推測,並以較新的推測取代,以節省記憶體。
由於 moderate 和 conservative 推測是由使用者觸發,因此我們可以使用較低的 2 個推測門檻,以節省記憶體。immediate 和 eager 設定不會因使用者動作而觸發,因此上限較高,因為瀏覽器無法判斷需要哪些設定,以及何時需要。
如果推離 FIFO 佇列而取消推測,可以再次觸發推測 (例如再次將游標懸停在該連結上),系統會重新推測該網址。在這種情況下,先前的推測可能已導致瀏覽器將該網址的部分資源儲存在 HTTP 快取中,因此重複推測應可大幅減少網路和時間成本。
immediate 和 eager 的限制也是動態的。使用這些急切程度移除推測規則指令碼元素,會取消移除的推測,藉此建立容量。如果這些網址包含在新的網址指令碼中,且未達上限,也可以重新推測。
Chrome 也會在特定情況下禁止使用推測,包括:
這些條件的目標是減少過度投機的影響,避免對使用者造成損害。
選填 source
Chrome 122 將 source 鍵設為選用,因為這可從 url 或 where 鍵的存在推斷出來。因此,這兩項推測規則完全相同:
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
<script type="speculationrules">
{
"prerender": [{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}]
}
</script>
Speculation-Rules HTTP 標頭
您也可以使用 Speculation-Rules HTTP 標頭傳送推測規則,不必直接將規則納入文件的 HTML 中。這樣一來,CDN 就能更輕鬆地部署,不必變更文件內容本身。
Speculation-Rules HTTP 標頭會連同文件一併傳回,並指向包含推測規則的 JSON 檔案位置:
Speculation-Rules: "/speculationrules.json"
這項資源必須使用正確的 MIME 類型,如果是跨來源資源,則必須通過 CORS 檢查。
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
如要使用相對網址,建議在推測規則中加入 "relative_to": "document" 鍵。否則,相對網址會與推測規則 JSON 檔案的網址相關。如果您需要選取部分或所有同源連結,這項功能就特別實用。
提升快取重複使用率
我們在 Chrome 中進行了多項快取改善作業,因此預先擷取 (甚至預先算繪) 文件時,系統會將資源儲存在 HTTP 快取中並重複使用。也就是說,即使推測結果未派上用場,推測仍可能在日後帶來好處。
此外,由於 Chrome 會對可快取的資源使用 HTTP 快取,因此重新推測 (例如,針對具有 moderate 積極程度設定的文件規則) 的成本也會大幅降低。
我們也支援新的 No-Vary-Search 提案,進一步改善快取重複使用率。
「No-Vary-Search」支援頁面
預先擷取或預先算繪網頁時,某些網址參數 (技術上稱為搜尋參數) 對伺服器實際提供的網頁可能並不重要,只會由用戶端 JavaScript 使用。
舉例來說,Google Analytics 會使用 Urchin 流量監視器 (UTM) 參數評估廣告活動,但通常不會導致伺服器傳送不同的網頁。這表示 page1.html?utm_content=123 和 page1.html?utm_content=456 會從伺服器提供相同網頁,因此可重複使用快取中的相同網頁。
同樣地,應用程式可能會使用其他僅在用戶端處理的網址參數。
No-Vary-Search 提案允許伺服器指定不會導致所傳送資源有所差異的參數,因此瀏覽器可以重複使用先前快取的檔案版本,這些版本只會因這些參數而有所不同。注意:目前只有 Chrome (和以 Chromium 為基礎的瀏覽器) 支援預先擷取導覽推測。
推測規則支援使用 expects_no_vary_search,指出預期傳回 No-Vary-Search HTTP 標頭的位置。這樣做有助於進一步避免不必要的下載。
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
在本範例中,產品 ID 123 和 124 的/products初始網頁 HTML 相同。不過,網頁內容最終會有所不同,因為系統會使用 JavaScript 透過 id 搜尋參數擷取產品資料,並在用戶端進行算繪。因此我們會預先擷取該網址,且該網址應會傳回 No-Vary-Search HTTP 標頭,顯示該網頁可用於任何 id 搜尋參數。
不過,如果使用者在預先擷取完成前點按任何連結,瀏覽器可能不會收到 /products 網頁。在這種情況下,瀏覽器不知道是否會包含 No-Vary-Search HTTP 標頭。瀏覽器接著會選擇是否要再次擷取連結,或是等待預先擷取作業完成,看看是否包含 No-Vary-Search HTTP 標頭。expects_no_vary_search 設定可讓瀏覽器瞭解網頁回應應包含 No-Vary-Search HTTP 標頭,並等待預先擷取完成。
示範
我們在 https://chrome.dev/speculative-loading/common-fruits.html 建立了一個示範,可用於查看文件規則和 moderate 積極程度設定的實際運作情形:
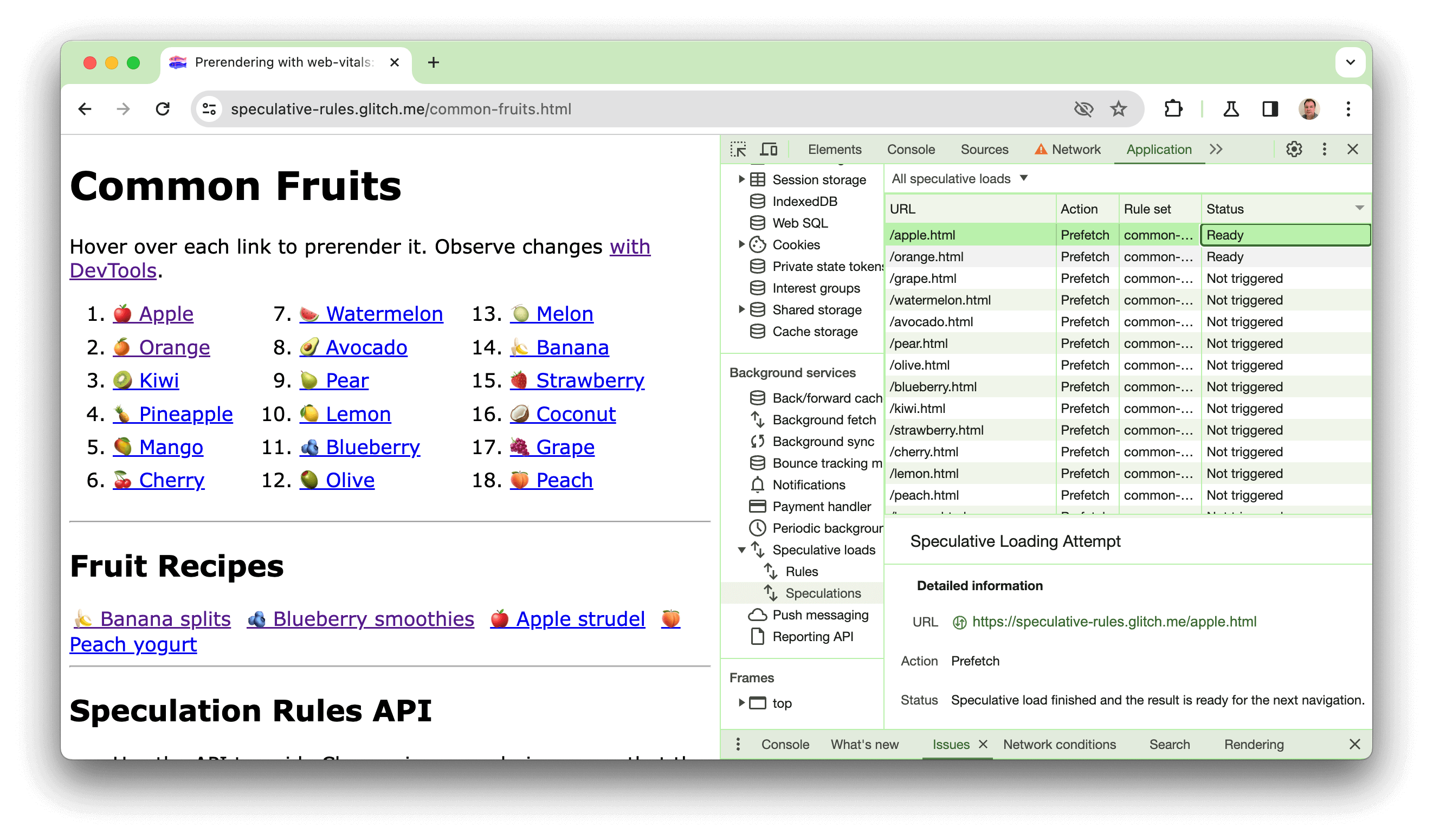
開啟開發人員工具,然後按一下「應用程式」面板。然後在「背景服務」部分中,依序點選「推測載入」、「推測」窗格,並依「狀態」欄排序。
將滑鼠游標懸停在水果上時,您會看到網頁預先算繪。點選這些連結後,您會發現 LCP 時間比未預先算繪的食譜快得多。如要瞭解這項示範,請觀看下列影片:
如要進一步瞭解如何使用開發人員工具偵錯推測規則,請參閱先前的偵錯推測規則網誌文章。
平台支援推測規則
雖然將規則插入 <script type="speculationrules"> 元素即可輕鬆實作推測規則,但平台支援功能可讓您一鍵完成這項作業。我們與各種平台和合作夥伴合作,讓您更輕鬆地推出推測規則。
我們也正努力透過 Web Incubator Community Group (WICG) 標準化 API,讓其他瀏覽器也能選擇實作這項令人期待的 API。
WordPress
WordPress Core Performance 團隊 (包括 Google 開發人員) 建立了 Speculation Rules 外掛程式。這個外掛程式可讓您輕鬆地在任何 WordPress 網站中,一鍵新增文件規則支援功能。您也可以透過 WordPress Performance Lab 外掛程式安裝這個外掛程式,建議您也安裝這個外掛程式,因為團隊會透過這個外掛程式,提供相關成效外掛程式的最新資訊。
您可以使用兩組設定:「推測模式」和「急切度」設定:

如需更複雜的設定 (例如排除特定網址的預先擷取或預先算繪作業),請參閱說明文件。
Akamai
Akamai 是全球頂尖的 CDN 供應商之一,他們已積極實驗 Speculation Rules API 一段時間。Akamai 已發布說明文件,說明客戶如何在 CDN 設定中啟用這項 API。他們先前也分享了這項新 API 的驚人成果。
Uxify
Uxify (先前是 Nitropack 的一部分) 是一種效能最佳化解決方案,可使用自訂的 Navigation AI 預測要加入推測規則的網頁,目標是提供比將滑鼠游標懸停在連結上更長的準備時間,但不會浪費資源,對所有觀察到的連結進行不必要的推測。詳情請參閱 Uxify Speculation Rules API 說明文件。這項創新解決方案顯示,只要搭配網站專屬洞察資料,舊版規則清單仍有許多用途。
Chrome 團隊也與該團隊合作,為需要更多資訊的使用者舉辦 Speculation Rules API 網路研討會,深入探討提早且頻繁推測,以及延後且較少推測之間需要考量的因素。
天文攝影
Astro 在 4.2 版中以實驗性質新增了使用 Speculation Rules API 預先算繪頁面的功能,讓使用 Astro 的開發人員輕鬆啟用這項功能,並在不支援 Speculation Rules API 的瀏覽器中,改用標準預先擷取功能。詳情請參閱用戶端預先算繪說明文件。
結論
Speculation Rules API 的這些新增功能可大幅簡化網站使用這項全新效能功能的程序,並降低因未使用的推測而浪費資源的風險。很高興看到平台已開始採用這項 API。我們希望這項 API 在 2024 年能獲得更廣泛的採用,最終為使用者帶來更優異的效能。
除了 Speculation Rules API 帶來的效能提升,我們也很期待這項技術開創的新商機。檢視區塊轉場效果是新的 API,可讓開發人員更輕鬆地指定導覽之間的轉場效果。這項功能目前適用於單頁應用程式 (SPA),但多頁版本正在開發中 (且可透過 Chrome 中的旗標啟用)。預先算繪是這項功能的自然附加元件,可確保不會發生延遲,否則轉換功能就無法提供預期中的使用者體驗改善效果。我們已看到有網站嘗試使用這項組合。
我們期待在 2024 年進一步推廣 Speculation Rules API,並會隨時向您說明 API 的最新改善措施。
特別銘謝
縮圖:Robbie Down (Unsplash)