

Puppeteer 及其选择器方法
Puppeteer 是适用于 Node 的浏览器自动化库:借助它,您可以使用简单且现代的 JavaScript API 控制浏览器。
浏览器最主要的任务当然是浏览网页。自动执行此任务本质上就是自动与网页互动。
在 Puppeteer 中,可通过使用基于字符串的选择器查询 DOM 元素并执行操作(例如点击元素或在元素上输入文本)来实现此目的。例如,以下脚本会打开 developer.google.com,找到搜索框,然后搜索 puppetaria:
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://developers.google.com/', { waitUntil: 'load' });
// Find the search box using a suitable CSS selector.
const search = await page.$('devsite-search > form > div.devsite-search-container');
// Click to expand search box and focus it.
await search.click();
// Enter search string and press Enter.
await search.type('puppetaria');
await search.press('Enter');
})();
因此,使用查询选择器识别元素的方式是 Puppeteer 体验的决定性因素。到目前为止,Puppeteer 中的选择器仅限于 CSS 和 XPath 选择器,虽然这些选择器的表达能力非常强大,但在脚本中保留浏览器互动时可能会存在缺点。
语法选择器与语义选择器
CSS 选择器本质上是语法选择器;它们与 DOM 树的文本表示的内部运作紧密相关,因为它们会引用 DOM 中的 ID 和类名称。因此,它们为 Web 开发者提供了一种不可或缺的工具,可用于修改或为网页中的元素添加样式,但在这种情况下,开发者可以完全控制网页及其 DOM 树。
另一方面,Puppeteer 脚本是网页的外部观察器,因此在这种情况下使用 CSS 选择器时,会引入有关网页实现方式的隐式假设,而 Puppeteer 脚本无法控制这些假设。
这样一来,此类脚本可能会变得脆弱,并且容易受到源代码更改的影响。例如,假设某人使用 Puppeteer 脚本对某个 Web 应用进行自动化测试,其中包含的节点 <button>Submit</button> 是 body 元素的第三个子元素。测试用例中的某个代码段可能如下所示:
const button = await page.$('body:nth-child(3)'); // problematic selector
await button.click();
在这里,我们使用选择器 'body:nth-child(3)' 来查找提交按钮,但这与此网页的确切版本紧密相关。如果稍后在按钮上方添加了元素,此选择器将无法再使用!
这对测试编写者来说并不新鲜:Puppeteer 用户已经尝试选择对此类更改具有强大鲁棒性的选择器。通过 Puppetaria,我们为用户提供了一款全新工具来帮助他们完成这项任务。
Puppeteer 现在附带一个基于查询无障碍功能树(而非依赖 CSS 选择器)的替代查询处理程序。这里的底层理念是,如果我们要选择的具体元素没有更改,则相应的无障碍功能节点也不应更改。
我们将此类选择器称为“ARIA 选择器”,并支持查询计算出的无障碍树的可访问名称和角色。与 CSS 选择器相比,这些属性具有语义性。它们与 DOM 的语法属性无关,而是描述如何通过屏幕阅读器等辅助技术观察网页。
在上面的测试脚本示例中,我们可以改用选择器 aria/Submit[role="button"] 来选择所需的按钮,其中 Submit 是指元素的可访问名称:
const button = await page.$('aria/Submit[role="button"]');
await button.click();
现在,如果我们稍后决定将按钮的文字内容从 Submit 更改为 Done,测试将再次失败,但在本例中,这是我们想要的结果;通过更改按钮的名称,我们更改的是网页的内容,而不是其视觉呈现或在 DOM 中的结构。我们的测试应该会提醒我们注意此类更改,以确保此类更改是有意为之。
回到包含搜索栏的较大示例,我们可以利用新的 aria 处理程序,并替换
const search = await page.$('devsite-search > form > div.devsite-search-container');
,这可以通过
const search = await page.$('aria/Open search[role="button"]');
找到搜索栏!
更广泛地说,我们认为使用此类 ARIA 选择器可为 Puppeteer 用户带来以下好处:
- 使测试脚本中的选择器更能适应源代码更改。
- 提高测试脚本的可读性(可访问的名称是语义描述符)。
- 鼓励采用为元素分配无障碍功能属性的良好做法。
本文的其余部分将详细介绍我们如何实现 Puppetaria 项目。
设计流程
背景
如上所述,我们希望能够按可访问的名称和角色查询元素。这些是无障碍树的属性,与常规 DOM 树相对应,屏幕阅读器等设备会使用该树来显示网页。
从计算可访问名称的规范中可以看出,计算元素的名称是一项不简单的任务,因此我们从一开始就决定要重复使用 Chromium 的现有基础架构来实现此目的。
我们如何实现该功能
即使仅限于使用 Chromium 的无障碍树,我们也可以通过多种方式在 Puppeteer 中实现 ARIA 查询。为了了解原因,我们先来看看 Puppeteer 如何控制浏览器。
浏览器通过名为 Chrome DevTools Protocol (CDP) 的协议公开调试接口。这样,您就可以通过不依赖于语言的接口公开“重新加载网页”或“在网页中执行这段 JavaScript 并返回结果”等功能。
开发者工具前端和 Puppeteer 都使用 CDP 与浏览器通信。为了实现 CDP 命令,Chrome 的所有组件(浏览器、渲染程序等)中都包含 DevTools 基础架构。CDP 负责将命令路由到正确的位置。
您可以利用 CDP 命令(例如 Runtime.evaluate)执行 Puppeteer 操作,例如查询、点击和求值表达式,这些命令会直接在页面上下文中对 JavaScript 求值并返回结果。其他 Puppeteer 操作(例如模拟色盲、截取屏幕截图或捕获轨迹)使用 CDP 直接与 Blink 渲染进程通信。
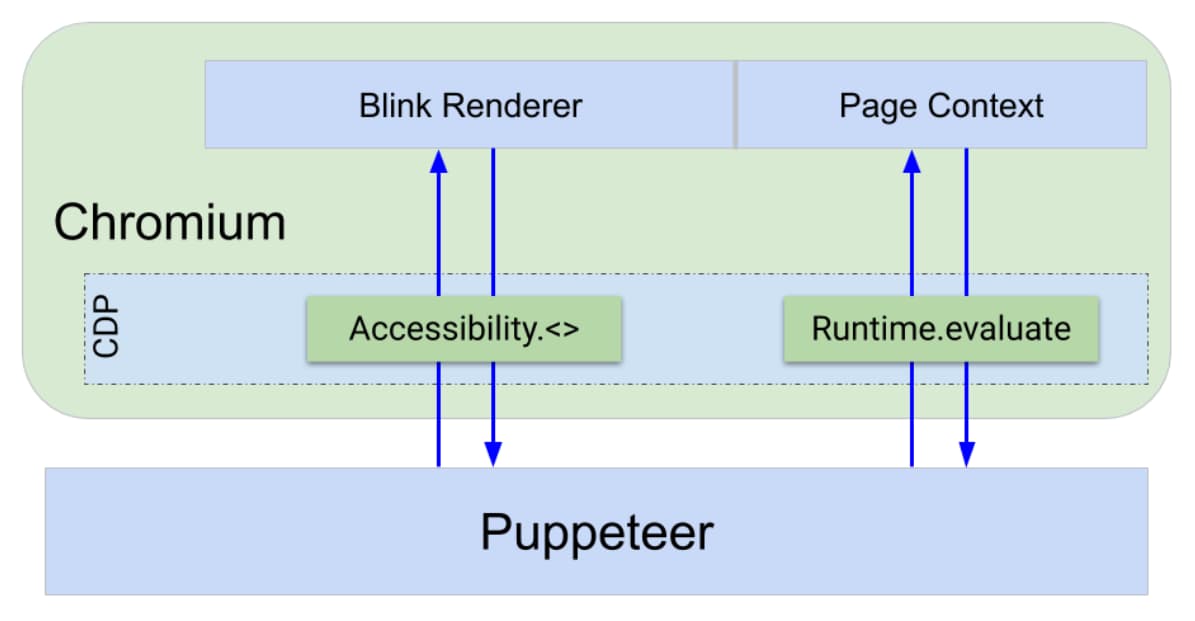
这样,我们已经有两种实现查询功能的方法:
- 使用 JavaScript 编写查询逻辑,并使用
Runtime.evaluate将其注入页面中,或者 - 使用可直接在 Blink 进程中访问和查询无障碍功能树的 CDP 端点。
我们实现了 3 个原型:
- JS DOM 遍历 - 基于将 JavaScript 注入网页
- Puppeteer AXTree 遍历 - 基于使用现有的 CDP 访问无障碍功能树
- CDP DOM 遍历 - 使用专门用于查询无障碍树的新 CDP 端点
JS DOM 遍历
此原型会对 DOM 进行完整遍历,并使用 element.computedName 和 element.computedRole(受 ComputedAccessibilityInfo 启动标志控制)在遍历过程中检索每个元素的名称和角色。
Puppeteer AXTree 遍历
在这里,我们改为通过 CDP 检索完整的无障碍功能树,并在 Puppeteer 中对其进行遍历。然后,系统会将生成的无障碍节点映射到 DOM 节点。
CDP DOM 遍历
对于此原型,我们实现了一个专门用于查询无障碍树的新 CDP 端点。这样,查询就可以通过 C++ 实现在后端进行,而不是在页面上下文中通过 JavaScript 进行。
单元测试基准
下图比较了针对 3 个原型对 4 个元素执行 1,000 次查询的总运行时间。基准测试是在 3 种不同的配置下执行的,这些配置的区别在于页面大小和是否启用了无障碍功能元素缓存。

很明显,CDP 支持的查询机制与仅在 Puppeteer 中实现的其他两个机制之间存在明显的性能差距,并且相对差异似乎会随着网页大小而大幅增加。有趣的是,JS DOM 遍历原型在启用无障碍功能缓存后表现出如此出色的响应能力。停用缓存后,系统会按需计算无障碍功能树,并在每次互动后丢弃该树(如果网域处于停用状态)。启用该网域后,Chromium 会改为缓存计算出的树。
对于 JS DOM 遍历,我们会在遍历过程中请求每个元素的可访问名称和角色,因此如果停用了缓存,Chromium 会计算并舍弃我们访问的每个元素的无障碍功能树。另一方面,对于基于 CDP 的方法,只有在每次调用 CDP(即每次查询)之间才会丢弃树。启用缓存后,这些方法也会受益,因为无障碍树会在各个 CDP 调用中保留,但性能提升幅度相对较小。
虽然启用缓存似乎很有用,但会增加内存用量。对于例如记录轨迹文件的 Puppeteer 脚本,这可能会造成问题。因此,我们决定默认不启用无障碍功能树缓存。用户可以通过启用 CDP 无障碍功能网域来自行启用缓存。
开发者工具测试套件基准测试
上一个基准测试表明,在 CDP 层实现我们的查询机制可在临床单元测试场景中提升性能。
为了了解差异是否足够明显,以至于在运行完整测试套件的更现实场景中也能明显感受到,我们修补了 DevTools 端到端测试套件,以便使用基于 JavaScript 和 CDP 的原型,并比较了运行时。在此基准测试中,我们将总计 43 个选择器从 [aria-label=…] 更改为自定义查询处理程序 aria/…,然后使用每个原型实现了该处理程序。
部分选择器在测试脚本中被多次使用,因此每次运行套件时,aria 查询处理程序的实际执行次数为 113 次。查询选择总数为 2253,因此只有一小部分查询选择是通过原型完成的。

如上图所示,总运行时间存在明显差异。数据噪声太大,无法得出任何具体结论,但很明显,在这类情况下,两个原型的性能差距也存在。
新的 CDP 端点
鉴于上述基准测试,并且由于基于启动标志的方法通常不适用,我们决定继续实现用于查询无障碍功能树的新 CDP 命令。现在,我们必须弄清楚这个新端点的接口。
对于 Puppeteer 中的用例,我们需要将端点作为所谓的 RemoteObjectIds 的参数,并且为了便于我们之后找到相应的 DOM 元素,它应返回包含 DOM 元素的 backendNodeIds 的对象列表。
如下图所示,我们尝试了许多方法来满足此接口的要求。从中我们发现,返回对象的大小(即我们是否返回完整的无障碍功能节点或仅返回 backendNodeIds)没有明显差异。另一方面,我们发现,在本例中使用现有的 NextInPreOrderIncludingIgnored 来实现遍历逻辑是一个错误的选择,因为这样会导致明显的速度下降。

总结
现在,CDP 端点已就绪,我们在 Puppeteer 端实现了查询处理程序。这里的主要工作是重构查询处理代码,以便查询能够直接通过 CDP 解析,而不是通过在页面上下文中评估的 JavaScript 进行查询。
后续操作
新的 aria 处理程序随 Puppeteer v5.4.0 一起提供,作为内置查询处理程序。我们期待看到用户如何将其纳入测试脚本中,也非常期待听取您关于如何让其变得更实用的想法!
下载预览渠道
不妨考虑将 Chrome Canary 版、开发者版或 Beta 版用作默认开发浏览器。通过这些预览渠道,您可以使用最新的 DevTools 功能、测试尖端的 Web 平台 API,并在用户发现问题之前发现您网站上的问题!
与 Chrome 开发者工具团队联系
您可以使用以下选项讨论与 DevTools 相关的新功能、更新或任何其他内容。
- 请访问 crbug.com 向我们提交反馈和功能请求。
- 在 DevTools 中,依次选择 More options > Help > Report a DevTools issue 以报告 DevTools 问题。
- 向 @ChromeDevTools 发送推文。
- 在 “开发者工具的新变化”YouTube 视频或 “开发者工具提示”YouTube 视频中留言。