

Puppeteer e a abordagem dele em relação aos seletores
O Puppeteer é uma biblioteca de automação de navegador para Node.js que permite controlar um navegador usando uma API JavaScript simples e moderna.
A tarefa mais importante do navegador é, claro, navegar por páginas da Web. Automatizar essa tarefa significa automatizar as interações com a página da Web.
No Puppeteer, isso é feito consultando elementos DOM usando seletores baseados em string e realizando ações como clicar ou digitar texto nos elementos. Por exemplo, um script que abre developer.google.com, encontra a caixa de pesquisa e procura puppetaria pode ter esta aparência:
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://developers.google.com/', { waitUntil: 'load' });
// Find the search box using a suitable CSS selector.
const search = await page.$('devsite-search > form > div.devsite-search-container');
// Click to expand search box and focus it.
await search.click();
// Enter search string and press Enter.
await search.type('puppetaria');
await search.press('Enter');
})();
A forma como os elementos são identificados usando seletores de consulta é uma parte definidora da experiência do Puppeteer. Até agora, os seletores no Puppeteer eram limitados a seletores CSS e XPath que, embora sejam muito poderosos, podem ter desvantagens para manter as interações do navegador em scripts.
Seletores sintáticos x semânticos
Os seletores CSS são sintáticos por natureza. Eles estão intimamente ligados ao funcionamento interno da representação textual da árvore DOM, no sentido de que eles fazem referência a IDs e nomes de classe do DOM. Como tal, eles fornecem uma ferramenta essencial para desenvolvedores da Web para modificar ou adicionar estilos a um elemento em uma página, mas, nesse contexto, o desenvolvedor tem controle total sobre a página e a árvore DOM dela.
Por outro lado, um script do Puppeteer é um observador externo de uma página. Portanto, quando os seletores CSS são usados nesse contexto, eles introduzem suposições ocultas sobre como a página é implementada, sobre as quais o script do Puppeteer não tem controle.
O efeito é que esses scripts podem ser frágeis e suscetíveis a mudanças no código-fonte. Suponha, por exemplo, que alguém use scripts do Puppeteer para testes automatizados de um aplicativo da Web que contenha o nó <button>Submit</button> como o terceiro filho do elemento body. Um snippet de um caso de teste pode ser assim:
const button = await page.$('body:nth-child(3)'); // problematic selector
await button.click();
Aqui, estamos usando o seletor 'body:nth-child(3)' para encontrar o botão de envio, mas ele está vinculado exatamente a essa versão da página da Web. Se um elemento for adicionado acima do botão, esse seletor não vai mais funcionar.
Isso não é novidade para os autores de testes: os usuários do Puppeteer já tentam escolher seletores que sejam robustos para essas mudanças. Com o Puppetaria, oferecemos aos usuários uma nova ferramenta nessa missão.
O Puppeteer agora vem com um gerenciador de consulta alternativo baseado em consultas à árvore de acessibilidade, em vez de depender de seletores de CSS. O conceito por trás disso é que, se o elemento concreto que queremos selecionar não mudou, o nó de acessibilidade correspondente também não deve ter mudado.
Chamamos esses seletores de "seletores ARIA" e oferecemos suporte a consultas para o nome acessível e a função computados da árvore de acessibilidade. Em comparação com os seletores de CSS, essas propriedades são semânticas por natureza. Eles não estão vinculados a propriedades sintáticas do DOM, mas são descritores de como a página é observada por tecnologias adaptativas, como leitores de tela.
No exemplo de script de teste acima, poderíamos usar o seletor aria/Submit[role="button"] para selecionar o botão desejado, em que Submit se refere ao nome acessível do elemento:
const button = await page.$('aria/Submit[role="button"]');
await button.click();
Agora, se decidirmos mudar o conteúdo de texto do botão de Submit para Done, o teste vai falhar novamente, mas nesse caso isso é desejável. Ao mudar o nome do botão, mudamos o conteúdo da página, em vez da apresentação visual ou da forma como ele é estruturado no DOM. Nossos testes devem nos alertar sobre essas mudanças para garantir que elas sejam intencionais.
Voltando ao exemplo maior com a barra de pesquisa, podemos aproveitar o novo gerenciador aria e substituir
const search = await page.$('devsite-search > form > div.devsite-search-container');
com
const search = await page.$('aria/Open search[role="button"]');
para encontrar a barra de pesquisa.
De modo geral, acreditamos que o uso desses seletores ARIA pode oferecer os seguintes benefícios aos usuários do Puppeteer:
- Torne os seletores em scripts de teste mais resistentes a mudanças no código-fonte.
- Tornar os scripts de teste mais legíveis (nomes acessíveis são descritores semânticos).
- Motivar boas práticas para atribuir propriedades de acessibilidade a elementos.
O restante deste artigo detalha como implementamos o projeto Puppetaria.
O processo de design
Contexto
Como motivado acima, queremos permitir a consulta de elementos pelo nome e papel acessíveis. Essas são propriedades da árvore de acessibilidade, uma dupla da árvore DOM usual, que é usada por dispositivos como leitores de tela para mostrar páginas da Web.
Analisando a especificação para calcular o nome acessível, fica claro que calcular o nome de um elemento é uma tarefa não trivial. Portanto, desde o início, decidimos reutilizar a infraestrutura atual do Chromium para isso.
Como abordamos a implementação
Mesmo nos limitando a usar a árvore de acessibilidade do Chromium, há várias maneiras de implementar a consulta ARIA no Puppeteer. Para entender o motivo, vamos ver como o Puppeteer controla o navegador.
O navegador expõe uma interface de depuração por um protocolo chamado Chrome DevTools Protocol (CDP). Isso expõe funcionalidades como "recarregar a página" ou "executar este trecho de JavaScript na página e retornar o resultado" por uma interface independente do idioma.
Tanto o front-end das Ferramentas do desenvolvedor quanto o Puppeteer usam o CDP para se comunicar com o navegador. Para implementar comandos do CDP, há uma infraestrutura do DevTools em todos os componentes do Chrome: no navegador, no renderizador e assim por diante. O CDP cuida do roteamento dos comandos para o lugar certo.
As ações do Puppeteer, como consultar, clicar e avaliar expressões, são realizadas usando comandos CDP, como Runtime.evaluate, que avalia o JavaScript diretamente no contexto da página e retorna o resultado. Outras ações do Puppeteer, como emular deficiência de visão de cores, fazer capturas de tela ou capturar rastros, usam o CDP para se comunicar diretamente com o processo de renderização do Blink.
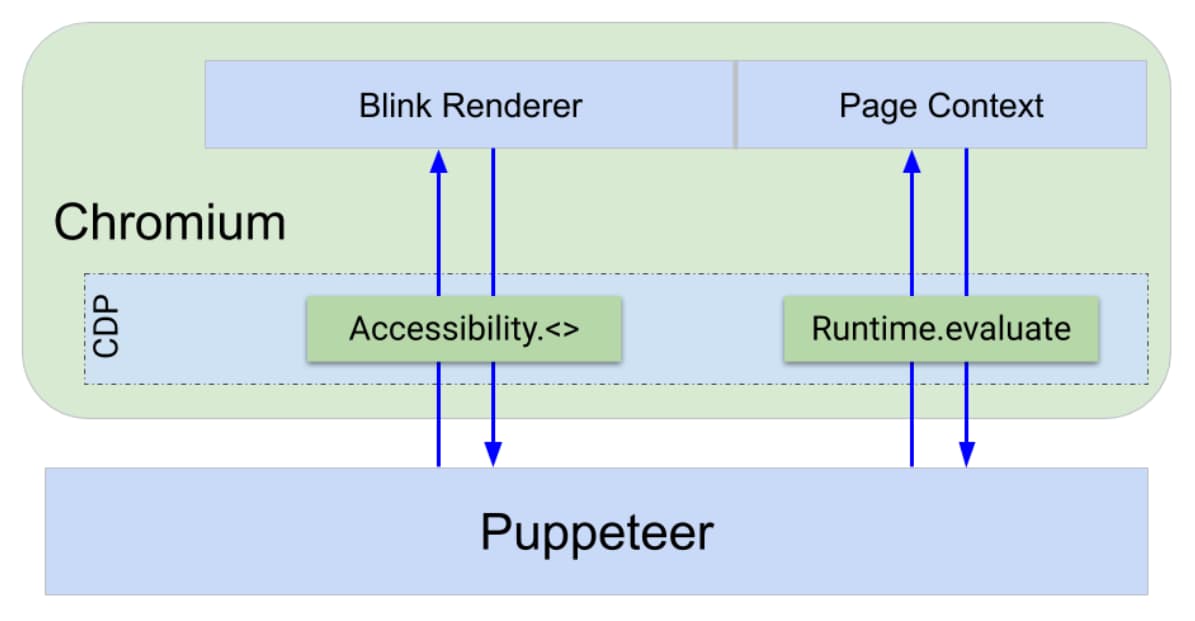
Isso já nos deixa com duas opções para implementar a funcionalidade de consulta:
- Escreva nossa lógica de consulta em JavaScript e injete-a na página usando
Runtime.evaluateou - Use um endpoint do CDP que possa acessar e consultar a árvore de acessibilidade diretamente no processo do Blink.
Implementamos três protótipos:
- Percurso de DOM do JS: baseado na injeção de JavaScript na página.
- Transposição de AXTree do Puppeteer: baseada no uso do acesso CDP atual à árvore de acessibilidade.
- Transposição de DOM do CDP: use um novo endpoint do CDP criado especificamente para consultar a árvore de acessibilidade.
Percurso do DOM do JS
Esse protótipo faz uma travessia completa do DOM e usa element.computedName e element.computedRole, bloqueados na flag de lançamento ComputedAccessibilityInfo, para recuperar o nome e a função de cada elemento durante a travessia.
Transposição de AXTree do Puppeteer
Aqui, extraímos a árvore de acessibilidade completa pelo CDP e a percorremos no Puppeteer. Os nós de acessibilidade resultantes são mapeados para nós DOM.
Percurso do DOM do CDP
Para esse protótipo, implementamos um novo endpoint do CDP especificamente para consultar a árvore de acessibilidade. Dessa forma, a consulta pode acontecer no back-end por uma implementação em C++ em vez de no contexto da página pelo JavaScript.
Comparativo de testes de unidade
A figura a seguir compara o tempo de execução total da consulta de quatro elementos 1.000 vezes para os três protótipos. O comparativo foi executado em três configurações diferentes, variando o tamanho da página e se o armazenamento em cache de elementos de acessibilidade estava ativado ou não.

É bastante claro que há uma diferença considerável no desempenho entre o mecanismo de consulta com suporte do CDP e os outros dois implementados apenas no Puppeteer, e a diferença relativa parece aumentar drasticamente com o tamanho da página. É interessante ver que o protótipo de passagem de DOM do JS responde tão bem à ativação do armazenamento em cache de acessibilidade. Com o armazenamento em cache desativado, a árvore de acessibilidade é calculada sob demanda e descartada após cada interação se o domínio estiver desativado. Ativar o domínio faz com que o Chromium armazene em cache a árvore computada.
Para a travessia de DOM JS, solicitamos o nome e o papel acessíveis para cada elemento durante a travessia. Portanto, se o armazenamento em cache estiver desativado, o Chromium vai calcular e descartar a árvore de acessibilidade para cada elemento que visitarmos. Já nas abordagens baseadas no CDP, a árvore é descartada apenas entre cada chamada para o CDP, ou seja, para cada consulta. Essas abordagens também se beneficiam da ativação do armazenamento em cache, já que a árvore de acessibilidade é mantida em todas as chamadas de CDP, mas o aumento de desempenho é relativamente menor.
Ativar o armazenamento em cache pode parecer uma boa ideia, mas isso tem um custo de uso de memória extra. Para scripts do Puppeteer que, por exemplo, registram arquivos de rastreamento, isso pode ser problemático. Portanto, decidimos não ativar o armazenamento em cache da árvore de acessibilidade por padrão. Os usuários podem ativar o armazenamento em cache ativando o domínio de acessibilidade do CDP.
Comparação de mercado do pacote de testes do DevTools
O comparativo anterior mostrou que a implementação do mecanismo de consulta na camada CDP aumenta a performance em um cenário de teste de unidade clínica.
Para saber se a diferença é pronunciada o suficiente para ser notada em um cenário mais realista de execução de um conjunto completo de testes, fizemos um patch no conjunto de testes completo do DevTools para usar os protótipos baseados em JavaScript e CDP e comparamos os tempos de execução. Neste comparativo de mercado, mudamos um total de 43 seletores de [aria-label=…] para um gerenciador de consulta personalizado aria/…, que implementamos usando cada um dos protótipos.
Alguns dos seletores são usados várias vezes em scripts de teste. Portanto, o número real de execuções do gerenciador de consultas aria foi de 113 por execução do pacote. O número total de seleções de consulta foi 2.253, então apenas uma fração das seleções de consulta aconteceu nos protótipos.

Como mostrado na figura acima, há uma diferença perceptível no tempo de execução total. Os dados são muito confusos para concluir algo específico, mas é claro que a diferença de desempenho entre os dois protótipos também aparece nesse cenário.
Um novo endpoint do CDP
Com base nos comparativos acima e porque a abordagem baseada em flags de lançamento não era desejável em geral, decidimos implementar um novo comando do CDP para consultar a árvore de acessibilidade. Agora, precisamos descobrir a interface desse novo endpoint.
Para nosso caso de uso no Puppeteer, precisamos que o endpoint use o chamado RemoteObjectIds como argumento e, para que possamos encontrar os elementos DOM correspondentes depois, ele precisa retornar uma lista de objetos que contenha o backendNodeIds para os elementos DOM.
Como mostrado no gráfico abaixo, testamos várias abordagens para atender a essa interface. Com isso, descobrimos que o tamanho dos objetos retornados, ou seja, se retornamos nós de acessibilidade completos ou apenas o backendNodeIds, não fez diferença perceptível. Por outro lado, descobrimos que usar o NextInPreOrderIncludingIgnored atual era uma escolha ruim para implementar a lógica de travessia aqui, porque isso resultava em uma lentidão perceptível.

Resumo
Agora, com o endpoint do CDP em vigor, implementamos o gerenciador de consultas no lado do Puppeteer. O trabalho aqui foi reestruturar o código de processamento de consultas para permitir que as consultas sejam resolvidas diretamente pelo CDP, em vez de consultar pelo JavaScript avaliado no contexto da página.
A seguir
O novo gerenciador aria foi enviado com o Puppeteer v5.4.0 como um gerenciador de consulta integrado. Estamos ansiosos para saber como os usuários vão adotar esse recurso nos scripts de teste e queremos saber suas ideias para torná-lo ainda mais útil.
Fazer o download dos canais de visualização
Use o Chrome Canary, Dev ou Beta como navegador de desenvolvimento padrão. Esses canais de visualização dão acesso aos recursos mais recentes do DevTools, permitem testar APIs de plataforma da Web de última geração e ajudam a encontrar problemas no seu site antes dos usuários.
Entre em contato com a equipe do Chrome DevTools
Use as opções a seguir para discutir os novos recursos, atualizações ou qualquer outra coisa relacionada ao DevTools.
- Envie feedback e solicitações de recursos para crbug.com.
- Informe um problema do DevTools usando o Mais opções > Ajuda > Informar um problema do DevTools no DevTools.
- Envie um tweet para @ChromeDevTools.
- Deixe comentários nos vídeos Novidades do DevTools no YouTube ou Dicas do DevTools no YouTube.