

Puppeteer i sposób jego działania w przypadku selektorów
Puppeteer to biblioteka automatyzacji przeglądarki dla Node.js, która umożliwia sterowanie przeglądarką za pomocą prostego i nowoczesnego interfejsu JavaScript API.
Najważniejszym zadaniem przeglądarki jest oczywiście przeglądanie stron internetowych. Automatyzacja tego zadania polega w istocie na automatyzacji interakcji ze stroną internetową.
W Puppeteer uzyskuje się to, wysyłając zapytanie o elementy DOM za pomocą selektorów opartych na ciągach znaków i wykonując działania takie jak klikanie lub wpisywanie tekstu na elementach. Na przykład skrypt, który otwiera stronę developer.google.com, znajduje pole wyszukiwania i wyszukuje puppetaria, może wyglądać tak:
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://developers.google.com/', { waitUntil: 'load' });
// Find the search box using a suitable CSS selector.
const search = await page.$('devsite-search > form > div.devsite-search-container');
// Click to expand search box and focus it.
await search.click();
// Enter search string and press Enter.
await search.type('puppetaria');
await search.press('Enter');
})();
Sposób identyfikowania elementów za pomocą selektorów zapytań jest więc kluczowym elementem działania Puppeteer. Do tej pory selektory w Puppeteer były ograniczone do selektorów CSS i XPath, które, choć bardzo wydajne, mogą mieć wady w przypadku trwałych interakcji z przeglądarką w skryptach.
Selektory syntaktyczne a selektory semantyczne
Selektory CSS mają charakter syntaktyczny. Są ściśle powiązane z wewnętrzną reprezentacją tekstową drzewa DOM w tym sensie, że odwołują się do identyfikatorów i nazwy klasy z DOM. Stanowią one integralne narzędzie dla programistów stron internetowych do modyfikowania lub dodawania stylów do elementu na stronie, ale w tym kontekście deweloper ma pełną kontrolę nad stroną i jej drzewem DOM.
Z drugiej strony skrypt Puppeteer jest zewnętrznym obserwatorem strony, więc gdy w tym kontekście używa się selektorów CSS, wprowadza on ukryte założenia dotyczące sposobu implementacji strony, nad którymi skrypt Puppeteer nie ma kontroli.
W efekcie takie skrypty mogą być niestabilne i wrażliwe na zmiany w kodzie źródłowym. Załóżmy na przykład, że do automatycznego testowania aplikacji internetowej zawierającej węzeł <button>Submit</button> jako trzeci element podrzędny elementu body używasz skryptów Puppeteer. Oto przykładowy fragment kodu z przypadku testowego:
const button = await page.$('body:nth-child(3)'); // problematic selector
await button.click();
Aby znaleźć przycisk przesyłania, używamy selektora 'body:nth-child(3)', ale jest on ściśle powiązany z tą wersją strony internetowej. Jeśli później nad przyciskiem dodasz element, selektor przestanie działać.
Nie jest to nowość dla autorów testów: użytkownicy Puppeteer już teraz próbują wybierać selektory, które są odporne na takie zmiany. Puppetaria to nowe narzędzie, które pomoże użytkownikom w realizacji tego zadania.
Puppeteer zawiera teraz alternatywny moduł obsługi zapytań, który wysyła zapytania do drzewa ułatwień dostępu zamiast korzystać z selektorów CSS. Zasada jest taka, że jeśli konkretny element, który chcemy wybrać, się nie zmienił, to odpowiedni węzeł dostępności też nie powinien się zmienić.
Takie selektory nazywamy „ARIA” i obsługujemy zapytania o obliczony czytelny identyfikator oraz rolę w drzewie ułatwień dostępu. W porównaniu z selektorami arkusza CSS te właściwości mają charakter semantyczny. Nie są one powiązane z właściwościami syntaktycznymi DOM, ale są opisami sposobu, w jaki strona jest obserwowana przez technologie wspomagające, takie jak czytniki ekranu.
W przykładowym skrypcie testowym powyżej do wybrania odpowiedniego przycisku możemy użyć selektora aria/Submit[role="button"], gdzie Submit odnosi się do nazwy elementu:
const button = await page.$('aria/Submit[role="button"]');
await button.click();
Jeśli później zdecydujesz się zmienić tekst przycisku z Submit na Done, test znów się nie powiedzie, ale w tym przypadku jest to pożądane. Zmiana nazwy przycisku powoduje zmianę zawartości strony, a nie jej wizualnej prezentacji ani sposobu jej ustrukturyzowania w DOM. Testy powinny nas ostrzec przed takimi zmianami, aby mieć pewność, że są one zamierzone.
Wracając do większego przykładu z paskiem wyszukiwania, możemy wykorzystać nowy moduł aria i zastąpić
const search = await page.$('devsite-search > form > div.devsite-search-container');
z
const search = await page.$('aria/Open search[role="button"]');
aby znaleźć pasek wyszukiwania.
Ogólnie uważamy, że korzystanie z takich selektorów ARIA może przynieść użytkownikom Puppeteer następujące korzyści:
- Ułatwienie selekcji w skryptach testowych w sytuacji, gdy zmienia się kod źródłowy.
- Spraw, aby skrypty testowe były bardziej czytelne (nazwy na potrzeby ułatwień dostępu to deskryptory semantyczne).
- Zachęcaj do stosowania sprawdzonych metod przypisywania elementom właściwości ułatwień dostępu.
Z dalszej części tego artykułu dowiesz się, jak wdrożone zostały rozwiązania z projektu Puppetaria.
Proces projektowania
Tło
Jak już wspomnieliśmy, chcemy umożliwić wysyłanie zapytań o elementy według ich nazwy i odpowiedniej roli. Są to właściwości drzewa ułatwień dostępu, które jest odpowiednikiem zwykłego drzewa DOM i jest używane przez urządzenia takie jak czytniki ekranu do wyświetlania stron internetowych.
Ze specyfikacji obliczania nazwy dostępnej wynika, że obliczenie nazwy elementu nie jest trywialnym zadaniem, dlatego od początku chcieliśmy użyć do tego celu istniejącej już infrastruktury Chromium.
Jak podeszliśmy do wdrożenia
Nawet ograniczając się do korzystania z drzewa dostępności w Chromium, można zaimplementować zapytania ARIA w Puppeteer na kilka sposobów. Aby to zrozumieć, najpierw sprawdź, jak Puppeteer kontroluje przeglądarkę.
Przeglądarka udostępnia interfejs debugowania za pomocą protokołu Chrome DevTools Protocol (CDP). Dzięki temu można udostępniać funkcje takie jak „odśwież stronę” lub „wykonaj ten fragment kodu JavaScript na stronie i zwracaj wynik” za pomocą interfejsu niezależnego od języka.
Zarówno interfejs DevTools, jak i Puppeteer korzystają z interfejsu CDP do komunikacji z przeglądarką. Aby zaimplementować polecenia CDP, we wszystkich komponentach Chrome (w przeglądarce, w renderowaniu itp.) jest infrastruktura Narzędzi deweloperskich. CDP kieruje polecenia do właściwego miejsca.
Działania Puppeteer, takie jak wysyłanie zapytań, klikanie i interpretowanie wyrażeń, są wykonywane za pomocą poleceń CDP, np. Runtime.evaluate, które interpretuje JavaScript bezpośrednio w kontekście strony i zwraca wynik. Inne działania Puppeteer, takie jak emulowanie niedoboru widzenia kolorów, robienie zrzutów ekranu czy rejestrowanie śladów, korzystają z CDP do bezpośredniej komunikacji z procesem renderowania Blink.
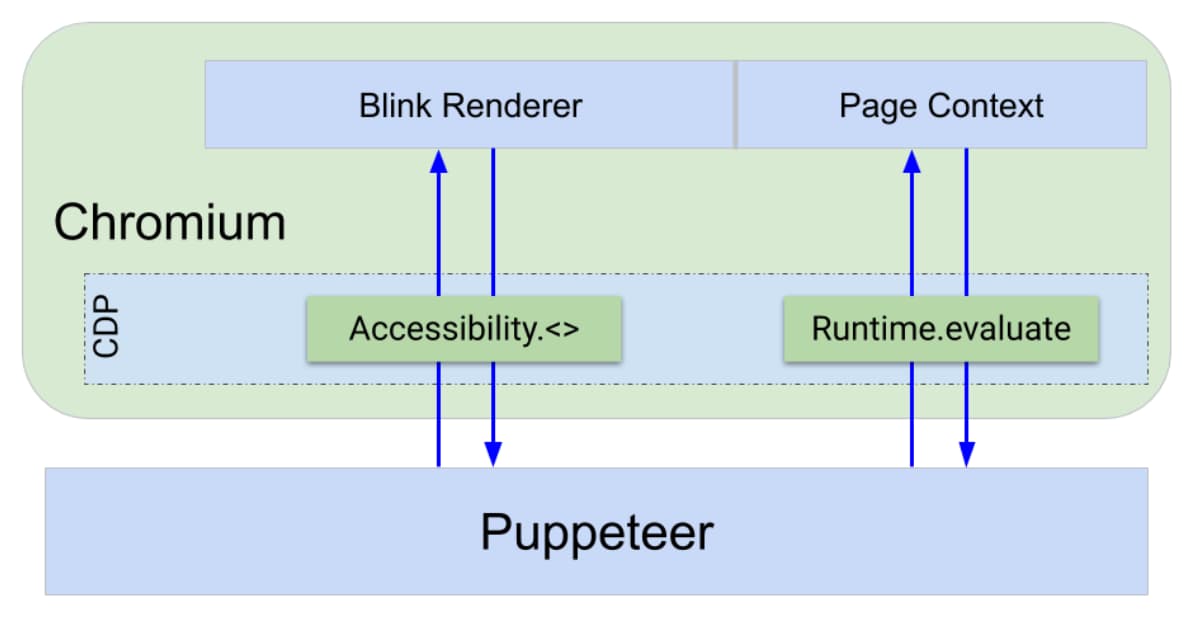
Pozostają nam 2 ścieżki implementacji funkcji zapytań:
- Napisać logikę zapytań w JavaScript i wstrzyknąć ją do strony za pomocą funkcji
Runtime.evaluatelub - Użyj punktu końcowego CDP, który może bezpośrednio uzyskiwać dostęp do drzewa ułatwień dostępu i wysyłać do niego zapytania w ramach procesu Blink.
Wdrożyliśmy 3 prototypy:
- Przeszukiwanie DOM w JS – polega na wstrzyknięciu JavaScriptu do strony.
- Przeglądanie za pomocą Puppeteer AXTree – na podstawie używania istniejącego dostępu CDP do drzewa ułatwień dostępu.
- Przeszukiwanie DOM w CDP – korzystanie z nowego punktu końcowego CDP, który został stworzony specjalnie do wykonywania zapytań do drzewa dostępności.
Przeszukiwanie DOM-u JS
Ten prototyp wykonuje pełne przejście przez DOM i korzysta z elementów element.computedName i element.computedRole, które są ograniczone flagą ComputedAccessibilityInfo, aby pobierać nazwę i rolę każdego elementu podczas przechodzenia.
Przeszukiwanie AXTree za pomocą Puppeteer
W tym przypadku zamiast tego pobieramy pełne drzewo ułatwień dostępu za pomocą CDP i przechodzimy przez nie w Puppeteer. Uzyskane w ten sposób węzły ułatwień dostępu są następnie mapowane na węzły modelu DOM.
Przeszukiwanie CDP DOM
W tym prototypie wdrożyliśmy nowy punkt końcowy CDP specjalnie do zapytań dotyczących drzewa dostępności. Dzięki temu zapytania mogą być wysyłane na zapleczu za pomocą implementacji w C++, a nie w kontekście strony za pomocą JavaScriptu.
Test jednostkowy – test porównawczy
Na poniższym rysunku porównano łączny czas wykonywania zapytań do 4 elementów 1000 razy w przypadku 3 prototypów. Test porównawczy został przeprowadzony w 3 różnych konfiguracjach z różnym rozmiarem strony i z włączonym lub wyłączonym buforowaniem elementów ułatwień dostępu.

Wyraźnie widać, że mechanizm wysyłania zapytań oparty na CDP i dwa inne mechanizmy zaimplementowane wyłącznie w Puppeteer różnią się znacznie pod względem wydajności. Różnica ta wydaje się gwałtownie rosnąć wraz z rozmiarem strony. Ciekawe, że prototyp JS DOM traversal reaguje tak dobrze na włączanie pamięci podręcznej ułatwień dostępu. Gdy buforowanie jest wyłączone, drzewo ułatwień dostępu jest obliczane na żądanie i usuwane po każdej interakcji, jeśli domena jest wyłączona. Włączenie domeny powoduje, że Chromium zamiast tego przechowuje w pamięci podręcznej wygenerowane drzewo.
W przypadku przeglądania DOM w JS prosimy o dostępną nazwę i rolę każdego elementu podczas przeglądania, więc jeśli buforowanie jest wyłączone, Chromium oblicza i odrzuca drzewo ułatwień dostępu dla każdego odwiedzanego elementu. W przypadku metod opartych na CDP drzewo jest odrzucane tylko między każdym wywołaniem CDP, czyli po każdym zapytaniu. Te podejścia również korzystają z włączenia buforowania, ponieważ drzewo dostępności jest wtedy przechowywane w ramach wywołań CDP, ale wzrost wydajności jest w tym przypadku stosunkowo mniejszy.
Włączenie pamięci podręcznej wydaje się tu dobrym pomysłem, ale wiąże się z dodatkowym wykorzystaniem pamięci. W przypadku skryptów Puppeteer, które na przykład rejestrują pliki śledzenia, może to być problematyczne. Dlatego postanowiliśmy domyślnie nie włączać buforowania drzewa ułatwień dostępu. Użytkownicy mogą sami włączyć buforowanie, aktywując domenę dostępności w CDP.
Zestaw testów DevTools
Poprzednie testy porównawcze wykazały, że implementacja naszego mechanizmu zapytań na poziomie CDP zwiększa wydajność w sytuacji testu jednostkowego w klinice.
Aby sprawdzić, czy różnica jest wystarczająco wyraźna, aby była zauważalna w bardziej realistycznym scenariuszu uruchamiania pełnego zestawu testów, wprowadziliśmy poprawki w całościowym zestawie testów DevTools, aby wykorzystać prototypy oparte na JavaScript i CDP, i porównać czasy działania. W ramach tego testu porównawczego zmieniliśmy łącznie 43 selektory z [aria-label=…] na niestandardowy moduł obsługi zapytań aria/…, który następnie wdrożyliśmy za pomocą każdego z prototypów.
Niektóre selektory są używane wielokrotnie w skryptach testowych, więc rzeczywista liczba uruchomień modułu obsługi zapytania aria wynosiła 113 na każde uruchomienie zestawu. Łączna liczba wyborów zapytań wyniosła 2253, więc tylko niewielka część wyborów zapytań została dokonana za pomocą prototypów.

Jak widać na rysunku powyżej, jest wyraźna różnica w łącznym czasie działania. Dane są zbyt niejednoznaczne, aby można było wyciągnąć z nich konkretne wnioski, ale w tym scenariuszu również widać różnicę w skuteczności między dwoma prototypami.
Nowy punkt końcowy CDP
Z uwagi na powyższe wyniki i fakt, że podejście oparte na flagach uruchomienia było ogólnie niepożądane, zdecydowaliśmy się wdrożyć nowe polecenie CDP do zapytania drzewa ułatwień dostępu. Musieliśmy się dowiedzieć, jak wygląda interfejs tego nowego punktu końcowego.
W przypadku Puppeteer potrzebujemy punktu końcowego, który przyjmuje jako argument tzw. RemoteObjectIds, a aby umożliwić nam późniejsze znajdowanie odpowiednich elementów DOM, powinien zwracać listę obiektów zawierającą backendNodeIds dla elementów DOM.
Jak widać na wykresie poniżej, wypróbowaliśmy kilka rozwiązań, które spełniają wymagania dotyczące tego interfejsu. Na tej podstawie stwierdziliśmy, że rozmiar zwracanych obiektów, czyli to, czy zwróciliśmy pełne węzły dostępności, czy tylko węzły backendNodeIds, nie miało żadnego zauważalnego wpływu. Z drugiej strony stwierdziliśmy, że użycie dotychczasowej funkcji NextInPreOrderIncludingIgnored nie było dobrym pomysłem na implementację logiki przeszukiwania, ponieważ spowodowało to zauważalne spowolnienie.

Podsumowanie
Teraz, gdy punkt końcowy CDP jest już dostępny, wdrożyliśmy moduł obsługi zapytań po stronie Puppeteer. Głównym zadaniem było przekształcenie kodu obsługującego zapytania, aby umożliwić ich rozwiązywanie bezpośrednio przez CDP zamiast wysyłania zapytań za pomocą kodu JavaScript ocenianego w kontekście strony.
Co dalej?
Nowy moduł obsługi aria jest dostarczany z Puppeteer w wersji 5.4.0 jako wbudowany moduł obsługi zapytań. Czekamy na to, jak użytkownicy wykorzystają tę funkcję w swoich skryptach testowych, i z niecierpliwością czekamy na Wasze pomysły na to, jak możemy ją jeszcze bardziej udoskonalić.
Pobieranie kanałów podglądu
Rozważ użycie jako domyślnej przeglądarki deweloperskiej przeglądarki Chrome w wersji Canary, Dev lub Beta. Te kanały wersji wstępnej zapewniają dostęp do najnowszych funkcji DevTools, umożliwiają testowanie najnowocześniejszych interfejsów API platformy internetowej i pomagają znaleźć problemy w witrynie, zanim zrobią to użytkownicy.
Kontakt z zespołem Narzędzi deweloperskich w Chrome
Aby omówić nowe funkcje, aktualizacje lub inne kwestie związane z Narzędziami deweloperskimi, skorzystaj z tych opcji.
- Przesyłaj opinie i prośby o dodanie funkcji na stronie crbug.com.
- Zgłoś problem z Narzędziami deweloperskimi, klikając Więcej opcji > Pomoc > Zgłoś problem z Narzędziami deweloperskimi w Narzędziach deweloperskich.
- Wyślij tweeta do @ChromeDevTools.
- Dodaj komentarze do filmów w YouTube z serii „Co nowego w Narzędziach deweloperskich” lub Wskazówki dotyczące Narzędzi deweloperskich.