

Puppeteer 및 선택기에 대한 접근 방식
Puppeteer는 Node용 브라우저 자동화 라이브러리로, 간단하고 최신 JavaScript API를 사용하여 브라우저를 제어할 수 있습니다.
가장 중요한 브라우저 작업은 웹페이지를 탐색하는 것입니다. 이 작업을 자동화하는 것은 본질적으로 웹페이지와의 상호작용을 자동화하는 것과 같습니다.
Puppeteer에서는 문자열 기반 선택기를 사용하여 DOM 요소를 쿼리하고 요소에서 텍스트를 클릭하거나 입력하는 등의 작업을 실행하여 이를 실행합니다. 예를 들어 developer.google.com을 열고 검색창을 찾은 다음 puppetaria를 검색하는 스크립트는 다음과 같습니다.
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://developers.google.com/', { waitUntil: 'load' });
// Find the search box using a suitable CSS selector.
const search = await page.$('devsite-search > form > div.devsite-search-container');
// Click to expand search box and focus it.
await search.click();
// Enter search string and press Enter.
await search.type('puppetaria');
await search.press('Enter');
})();
따라서 쿼리 선택기를 사용하여 요소를 식별하는 방법은 Puppeteer 환경을 정의하는 부분입니다. 지금까지 Puppeteer의 선택기는 CSS 및 XPath 선택기로 제한되어 있었습니다. 이러한 선택기는 표현력이 매우 뛰어나지만 스크립트에서 브라우저 상호작용을 유지하는 데는 단점이 있을 수 있습니다.
구문 선택기와 시맨틱 선택기 비교
CSS 선택자는 본질적으로 문법적입니다. DOM의 ID 및 클래스 이름을 참조한다는 점에서 DOM 트리의 텍스트 표현의 내부 작동 방식에 밀접하게 연결되어 있습니다. 따라서 웹 개발자가 페이지의 요소에 스타일을 수정하거나 추가하는 데 필수적인 도구를 제공하지만, 이 맥락에서 개발자는 페이지와 DOM 트리를 완전히 제어할 수 있습니다.
반면 Puppeteer 스크립트는 페이지의 외부 관찰자이므로 이 컨텍스트에서 CSS 선택기가 사용되면 Puppeteer 스크립트에서 제어할 수 없는 페이지 구현 방식에 관한 숨겨진 가정이 도입됩니다.
이러한 스크립트는 취약하고 소스 코드 변경사항에 민감할 수 있습니다. 예를 들어 <button>Submit</button> 노드를 body 요소의 세 번째 하위 요소로 포함하는 웹 애플리케이션의 자동 테스트에 Puppeteer 스크립트를 사용한다고 가정해 보겠습니다. 테스트 사례의 스니펫은 다음과 같습니다.
const button = await page.$('body:nth-child(3)'); // problematic selector
await button.click();
여기서는 선택기 'body:nth-child(3)'를 사용하여 제출 버튼을 찾고 있지만, 이 버튼은 정확히 이 버전의 웹페이지에 밀접하게 연결되어 있습니다. 나중에 버튼 위에 요소가 추가되면 이 선택기가 더 이상 작동하지 않습니다.
이는 테스트 작성자에게는 새로운 소식이 아닙니다. Puppeteer 사용자는 이미 이러한 변경사항에 견고한 선택기를 선택하려고 시도합니다. Puppetaria를 통해 사용자는 이 탐색의 새로운 도구를 사용할 수 있습니다.
이제 Puppeteer에는 CSS 선택기를 사용하는 대신 접근성 트리를 쿼리하는 대체 쿼리 핸들러가 제공됩니다. 여기서 기본적인 철학은 선택하려는 구체적인 요소가 변경되지 않았다면 해당 접근성 노드도 변경되지 않아야 한다는 것입니다.
이러한 선택자를 'ARIA 선택자'라고 부르며 접근성 트리의 계산된 접근 가능한 이름과 역할을 쿼리하는 것을 지원합니다. CSS 선택자와 비교할 때 이러한 속성은 본질적으로 의미론적입니다. 이러한 속성은 DOM의 문법적 속성과 연결되지 않으며 대신 스크린 리더와 같은 보조 기술을 통해 페이지가 관찰되는 방식을 나타내는 설명자입니다.
위의 테스트 스크립트 예시에서는 대신 선택기 aria/Submit[role="button"]를 사용하여 원하는 버튼을 선택할 수 있습니다. 여기서 Submit는 요소의 액세스 가능한 이름을 나타냅니다.
const button = await page.$('aria/Submit[role="button"]');
await button.click();
이제 나중에 버튼의 텍스트 콘텐츠를 Submit에서 Done로 변경하면 테스트가 다시 실패하지만 이 경우에는 바람직합니다. 버튼의 이름을 변경하면 시각적 표현이나 DOM에서의 구조가 아닌 페이지의 콘텐츠가 변경되기 때문입니다. 테스트에서 이러한 변경사항이 의도적인 것인지 확인할 수 있도록 경고해야 합니다.
검색창이 있는 더 큰 예로 돌아가면 새 aria 핸들러를 활용하고
const search = await page.$('devsite-search > form > div.devsite-search-container');
이 동영상에서는
const search = await page.$('aria/Open search[role="button"]');
를 탭하여 검색창을 찾습니다.
더 일반적으로 이러한 ARIA 선택기를 사용하면 Puppeteer 사용자에게 다음과 같은 이점이 제공될 수 있습니다.
- 테스트 스크립트의 선택기를 소스 코드 변경에 더 탄력적으로 만듭니다.
- 테스트 스크립트의 가독성을 높입니다 (액세스 가능한 이름은 시맨틱 설명자임).
- 요소에 접근성 속성을 할당하기 위한 권장사항을 제공합니다.
이 도움말의 나머지 부분에서는 Puppetaria 프로젝트를 구현한 방법을 자세히 살펴봅니다.
설계 프로세스
배경
위에서 설명한 것처럼 액세스 가능한 이름과 역할로 요소를 쿼리할 수 있도록 합니다. 이는 일반적인 DOM 트리의 이중인 접근성 트리의 속성으로, 스크린 리더와 같은 기기에서 웹페이지를 표시하는 데 사용됩니다.
접근 가능한 이름 계산 사양을 살펴보면 요소의 이름을 계산하는 것이 간단한 작업이 아님이 분명하므로 처음부터 Chromium의 기존 인프라를 재사용하기로 결정했습니다.
구현 방법
Chromium의 접근성 트리를 사용하는 것으로 제한하더라도 Puppeteer에서 ARIA 쿼리를 구현하는 방법은 여러 가지가 있습니다. 그 이유를 알아보려면 먼저 Puppeteer가 브라우저를 제어하는 방법을 살펴보겠습니다.
브라우저는 Chrome DevTools 프로토콜 (CDP)이라는 프로토콜을 통해 디버깅 인터페이스를 노출합니다. 이렇게 하면 언어에 관계없는 인터페이스를 통해 '페이지 새로고침' 또는 '페이지에서 이 JavaScript를 실행하고 결과를 다시 전달'과 같은 기능이 노출됩니다.
DevTools 프런트엔드와 Puppeteer 모두 CDP를 사용하여 브라우저와 통신합니다. CDP 명령어를 구현하기 위해 Chrome의 모든 구성요소(브라우저, 렌더러 등) 내에 DevTools 인프라가 있습니다. CDP는 명령어를 올바른 위치로 라우팅합니다.
쿼리, 클릭, 표현식 평가와 같은 Puppeteer 작업은 페이지 컨텍스트에서 JavaScript를 직접 평가하고 결과를 반환하는 Runtime.evaluate와 같은 CDP 명령어를 활용하여 실행됩니다. 색맹 에뮬레이션, 스크린샷 찍기, 트레이스 캡처와 같은 다른 Puppeteer 작업은 CDP를 사용하여 Blink 렌더링 프로세스와 직접 통신합니다.
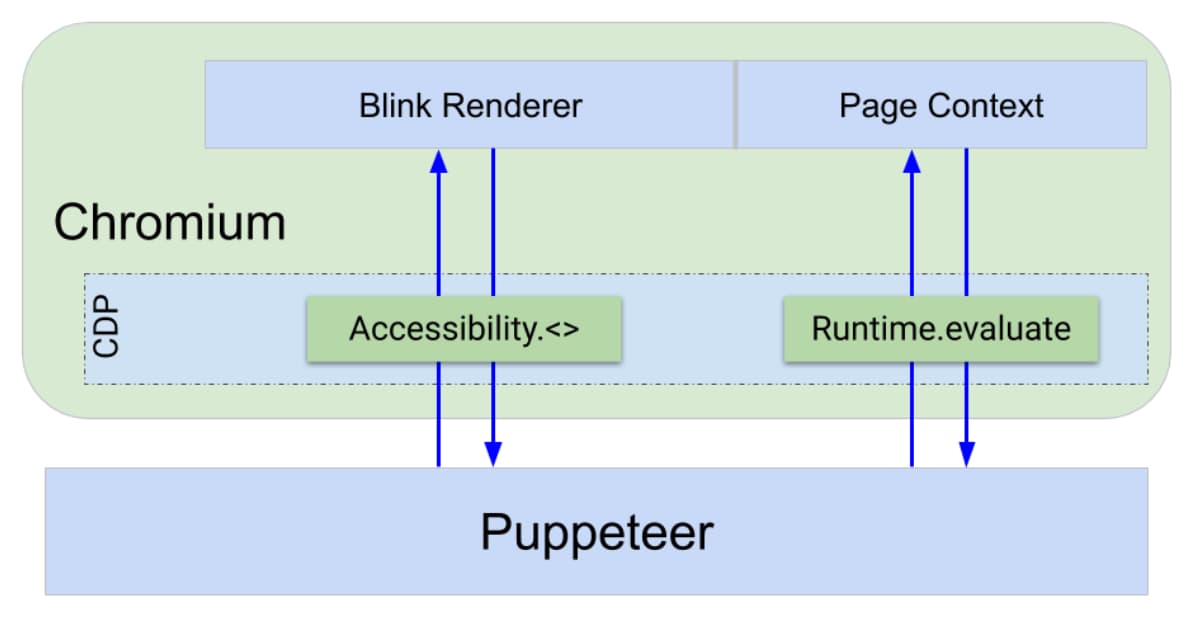
이제 쿼리 기능을 구현하는 두 가지 경로가 있습니다.
- JavaScript로 쿼리 로직을 작성하고
Runtime.evaluate를 사용하여 페이지에 삽입합니다. - Blink 프로세스에서 직접 접근성 트리에 액세스하고 쿼리할 수 있는 CDP 엔드포인트를 사용합니다.
다음과 같은 3가지 프로토타입을 구현했습니다.
- JS DOM 탐색 - 페이지에 JavaScript를 삽입하는 방식
- Puppeteer AXTree traversal: 접근성 트리에 대한 기존 CDP 액세스를 사용하는 방식
- CDP DOM 탐색 - 접근성 트리를 쿼리하기 위해 특별히 설계된 새 CDP 엔드포인트 사용
JS DOM 탐색
이 프로토타입은 DOM을 전체적으로 탐색하고 ComputedAccessibilityInfo 실행 플래그에서 제어되는 element.computedName 및 element.computedRole를 사용하여 탐색 중에 각 요소의 이름과 역할을 가져옵니다.
Puppeteer AXTree 탐색
여기서는 대신 CDP를 통해 전체 접근성 트리를 가져와 Puppeteer에서 트리를 탐색합니다. 그러면 결과 접근성 노드가 DOM 노드에 매핑됩니다.
CDP DOM 탐색
이 프로토타입에서는 접근성 트리를 쿼리하기 위한 새로운 CDP 엔드포인트를 구현했습니다. 이렇게 하면 JavaScript를 통한 페이지 컨텍스트가 아닌 C++ 구현을 통해 백엔드에서 쿼리할 수 있습니다.
단위 테스트 벤치마크
다음 그림은 프로토타입 3개에 대해 4개의 요소를 1,000번 쿼리하는 총 런타임을 비교합니다. 벤치마크는 페이지 크기와 접근성 요소 캐싱 사용 여부를 달리하는 3가지 구성으로 실행되었습니다.

CDP 지원 쿼리 메커니즘과 Puppeteer에서만 구현된 다른 두 메커니즘 간에 상당한 성능 격차가 있음이 분명하며, 상대적 차이는 페이지 크기에 따라 급격히 증가하는 것으로 보입니다. JS DOM 탐색 프로토타입이 접근성 캐싱을 사용 설정하는 데 매우 잘 반응한다는 점은 다소 흥미롭습니다. 캐싱이 사용 중지된 경우 접근성 트리는 필요에 따라 계산되며 도메인이 사용 중지된 경우 각 상호작용 후에 트리가 삭제됩니다. 도메인을 사용 설정하면 Chromium에서 계산된 트리를 대신 캐시합니다.
JS DOM 탐색의 경우 탐색 중에 모든 요소의 액세스 가능한 이름과 역할을 요청하므로 캐싱이 사용 중지된 경우 Chromium은 방문하는 모든 요소의 접근성 트리를 계산하고 삭제합니다. 반면 CDP 기반 접근 방식의 경우 트리는 CDP를 호출할 때마다, 즉 모든 쿼리에 대해만 삭제됩니다. 이러한 접근 방식은 캐싱을 사용 설정하면 접근성 트리가 CDP 호출 전반에서 유지되므로 이점도 있지만 성능 향상은 상대적으로 적습니다.
여기서는 캐싱을 사용 설정하는 것이 좋지만 메모리 사용량이 추가로 증가한다는 단점이 있습니다. 예를 들어 트레이스 파일을 기록하는 Puppeteer 스크립트의 경우 문제가 될 수 있습니다. 따라서 기본적으로 접근성 트리 캐싱을 사용 설정하지 않기로 결정했습니다. 사용자는 CDP 접근성 도메인을 사용 설정하여 캐싱을 직접 사용 설정할 수 있습니다.
DevTools 테스트 모음 벤치마크
이전 벤치마크에서는 CDP 레이어에서 쿼리 메커니즘을 구현하면 임상 단위 테스트 시나리오에서 성능이 향상된다는 것을 보여 주었습니다.
전체 테스트 모음을 실행하는 보다 현실적인 시나리오에서 차이가 눈에 띄게 나타날 만큼 확실한지 확인하기 위해 JavaScript 및 CDP 기반 프로토타입을 활용하도록 DevTools 엔드 투 엔드 테스트 모음을 패치하고 런타임을 비교했습니다. 이 벤치마크에서는 총 43개의 선택기를 [aria-label=…]에서 맞춤 쿼리 핸들러 aria/…로 변경한 후 각 프로토타입을 사용하여 구현했습니다.
일부 선택기는 테스트 스크립트에서 여러 번 사용되므로 aria 쿼리 핸들러의 실제 실행 횟수는 모음 실행당 113회였습니다. 총 쿼리 선택 수는 2, 253개이므로 프로토타입을 통해 선택된 쿼리는 일부에 불과했습니다.

위의 그림에서 볼 수 있듯이 총 런타임에 눈에 띄는 차이가 있습니다. 데이터에 노이즈가 너무 많아 구체적인 결론을 내릴 수는 없지만, 이 시나리오에서도 두 프로토타입 간의 성능 격차가 분명히 나타납니다.
새 CDP 엔드포인트
위의 벤치마크를 고려하고 일반적으로 출시 플래그 기반 접근 방식이 바람직하지 않으므로 접근성 트리를 쿼리하는 새로운 CDP 명령어를 구현하기로 결정했습니다. 이제 이 새 엔드포인트의 인터페이스를 파악해야 했습니다.
Puppeteer의 사용 사례에서는 엔드포인트가 소위 RemoteObjectIds를 인수로 받아야 하며, 나중에 상응하는 DOM 요소를 찾을 수 있도록 DOM 요소의 backendNodeIds가 포함된 객체 목록을 반환해야 합니다.
아래 차트에서 볼 수 있듯이 이 인터페이스를 충족하는 여러 가지 접근 방식을 시도했습니다. 이를 통해 반환된 객체의 크기, 즉 전체 접근성 노드를 반환했는지 아니면 backendNodeIds만 반환했는지에 따라 눈에 띄는 차이가 없음을 확인했습니다. 반면 기존 NextInPreOrderIncludingIgnored를 사용하면 여기에서 탐색 로직을 구현하기에 적절하지 않은 것으로 나타났습니다. 눈에 띄게 속도가 느려졌기 때문입니다.

마무리
이제 CDP 엔드포인트가 있으므로 Puppeteer 측에서 쿼리 핸들러를 구현했습니다. 여기서 중요한 작업은 페이지 컨텍스트에서 평가된 JavaScript를 통해 쿼리하는 대신 CDP를 통해 쿼리를 직접 확인할 수 있도록 쿼리 처리 코드를 재구성하는 것이었습니다.
다음 단계
새 aria 핸들러가 Puppeteer v5.4.0과 함께 내장 쿼리 핸들러로 제공되었습니다. 사용자가 이 기능을 테스트 스크립트에 어떻게 적용할지 기대하고 있으며, 이 기능을 더욱 유용하게 만드는 방법에 관한 아이디어도 기다리고 있습니다.
미리보기 채널 다운로드
Chrome Canary, Dev 또는 베타를 기본 개발 브라우저로 사용하는 것이 좋습니다. 이러한 미리보기 채널을 사용하면 최신 DevTools 기능에 액세스하고, 최신 웹 플랫폼 API를 테스트하고, 사용자가 문제를 발견하기 전에 사이트에서 문제를 찾을 수 있습니다.
Chrome DevTools팀에 문의하기
다음 옵션을 사용하여 DevTools와 관련된 새로운 기능, 업데이트 또는 기타 사항을 논의하세요.
- crbug.com에서 의견 및 기능 요청을 제출하세요.
- DevTools에서 옵션 더보기 > 도움말 > DevTools 문제 신고를 사용하여 DevTools 문제를 신고합니다.
- @ChromeDevTools에 트윗하세요.
- DevTools의 새로운 기능 YouTube 동영상 또는 DevTools 도움말 YouTube 동영상에 댓글을 남겨주세요.