

Puppeteer et son approche des sélecteurs
Puppeteer est une bibliothèque d'automatisation de navigateur pour Node. Elle vous permet de contrôler un navigateur à l'aide d'une API JavaScript simple et moderne.
La tâche la plus courante d'un navigateur est bien sûr la navigation sur les pages Web. L'automatisation de cette tâche revient essentiellement à automatiser les interactions avec la page Web.
Dans Puppeteer, cela se fait en interrogeant les éléments DOM à l'aide de sélecteurs basés sur des chaînes et en effectuant des actions telles que cliquer ou saisir du texte sur les éléments. Par exemple, un script qui ouvre developer.google.com, recherche le champ de recherche et recherche puppetaria peut se présenter comme suit:
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://developers.google.com/', { waitUntil: 'load' });
// Find the search box using a suitable CSS selector.
const search = await page.$('devsite-search > form > div.devsite-search-container');
// Click to expand search box and focus it.
await search.click();
// Enter search string and press Enter.
await search.type('puppetaria');
await search.press('Enter');
})();
La façon dont les éléments sont identifiés à l'aide de sélecteurs de requêtes est donc une partie déterminante de l'expérience Puppeteer. Jusqu'à présent, les sélecteurs de Puppeteer étaient limités aux sélecteurs CSS et XPath, qui, bien que très puissants en termes d'expression, peuvent présenter des inconvénients pour la persistance des interactions du navigateur dans les scripts.
Sélecteurs syntaxiques et sémantiques
Les sélecteurs CSS sont de nature syntaxique. Ils sont étroitement liés au fonctionnement interne de la représentation textuelle de l'arborescence DOM, dans le sens où ils font référence aux ID et aux noms de classe du DOM. Ils constituent donc un outil essentiel pour les développeurs Web qui souhaitent modifier ou ajouter des styles à un élément d'une page. Dans ce contexte, le développeur a un contrôle total sur la page et son arbre DOM.
D'un autre côté, un script Puppeteer est un observateur externe d'une page. Par conséquent, lorsque des sélecteurs CSS sont utilisés dans ce contexte, ils introduisent des hypothèses cachées sur la façon dont la page est implémentée, sur lesquelles le script Puppeteer n'a aucun contrôle.
Par conséquent, ces scripts peuvent être fragiles et sensibles aux modifications du code source. Supposons, par exemple, que vous utilisiez des scripts Puppeteer pour les tests automatisés d'une application Web contenant le nœud <button>Submit</button> comme troisième enfant de l'élément body. Un extrait d'un cas de test peut ressembler à ceci:
const button = await page.$('body:nth-child(3)'); // problematic selector
await button.click();
Ici, nous utilisons le sélecteur 'body:nth-child(3)' pour trouver le bouton de soumission, mais celui-ci est étroitement lié à cette version exacte de la page Web. Si un élément est ajouté ultérieurement au-dessus du bouton, ce sélecteur ne fonctionne plus.
Ce n'est pas une surprise pour les rédacteurs de tests: les utilisateurs de Puppeteer tentent déjà de choisir des sélecteurs résistants à de tels changements. Avec Puppetaria, nous offrons aux utilisateurs un nouvel outil pour cette quête.
Puppeteer est désormais fourni avec un gestionnaire de requêtes alternatif basé sur l'interrogation de l'arborescence d'accessibilité plutôt que sur les sélecteurs CSS. La philosophie sous-jacente est que si l'élément concret que nous souhaitons sélectionner n'a pas changé, le nœud d'accessibilité correspondant ne devrait pas non plus avoir changé.
Nous appelons ces sélecteurs "sélecteurs ARIA" et permettons de demander le nom et le rôle accessibles calculés de l'arborescence d'accessibilité. Contrairement aux sélecteurs CSS, ces propriétés sont de nature sémantique. Ils ne sont pas liés aux propriétés syntaxiques du DOM, mais décrivent la façon dont la page est observée à l'aide de technologies d'assistance telles que les lecteurs d'écran.
Dans l'exemple de script de test ci-dessus, nous pourrions utiliser le sélecteur aria/Submit[role="button"] pour sélectionner le bouton souhaité, où Submit fait référence au nom accessible de l'élément:
const button = await page.$('aria/Submit[role="button"]');
await button.click();
Si nous décidons plus tard de remplacer le contenu textuel de notre bouton de Submit par Done, le test échouera à nouveau, mais dans ce cas, c'est souhaitable. En modifiant le nom du bouton, nous modifions le contenu de la page, par opposition à sa présentation visuelle ou à la façon dont elle est structurée dans le DOM. Nos tests devraient nous avertir de ces modifications pour nous assurer qu'elles sont intentionnelles.
Pour en revenir à l'exemple plus vaste de la barre de recherche, nous pourrions exploiter le nouveau gestionnaire aria et remplacer
const search = await page.$('devsite-search > form > div.devsite-search-container');
avec
const search = await page.$('aria/Open search[role="button"]');
pour trouver la barre de recherche.
Plus généralement, nous pensons que l'utilisation de tels sélecteurs ARIA peut offrir les avantages suivants aux utilisateurs de Puppeteer:
- Renforcez la résilience des sélecteurs dans les scripts de test face aux modifications du code source.
- Rendre les scripts de test plus lisibles (les noms accessibles sont des descripteurs sémantiques).
- Expliquez les bonnes pratiques à suivre pour attribuer des propriétés d'accessibilité aux éléments.
La suite de cet article décrit en détail comment nous avons implémenté le projet Puppetaria.
Le processus de conception
Contexte
Comme indiqué ci-dessus, nous souhaitons permettre d'interroger les éléments par leur nom et leur rôle accessibles. Il s'agit de propriétés de l'arborescence d'accessibilité, qui est l'équivalent de l'arborescence DOM habituelle et qui est utilisée par des appareils tels que les lecteurs d'écran pour afficher des pages Web.
En examinant la spécification pour calculer le nom accessible, il est clair que calculer le nom d'un élément est une tâche non triviale. Nous avons donc décidé dès le départ de réutiliser l'infrastructure existante de Chromium pour ce faire.
Comment nous avons procédé à l'implémentation
Même en nous limitant à l'utilisation de l'arborescence d'accessibilité de Chromium, il existe de nombreuses façons d'implémenter des requêtes ARIA dans Puppeteer. Pour comprendre pourquoi, voyons d'abord comment Puppeteer contrôle le navigateur.
Le navigateur expose une interface de débogage via un protocole appelé protocole Chrome DevTools (CDP). Cela permet d'exposer des fonctionnalités telles que "Rafraîchir la page" ou "Exécuter ce code JavaScript sur la page et renvoyer le résultat" via une interface indépendante du langage.
Le frontend DevTools et Puppeteer utilisent CDP pour communiquer avec le navigateur. Pour implémenter les commandes CDP, une infrastructure DevTools est intégrée à tous les composants de Chrome: dans le navigateur, dans le moteur de rendu, etc. Le CDP se charge d'acheminer les commandes au bon endroit.
Les actions Puppeteer telles que l'interrogation, le clic et l'évaluation des expressions sont effectuées en exploitant des commandes CDP telles que Runtime.evaluate, qui évalue JavaScript directement dans le contexte de la page et renvoie le résultat. D'autres actions Puppeteer, telles que l'émulation de déficience visuelle des couleurs, la capture d'écran ou la capture de traces, utilisent CDP pour communiquer directement avec le processus de rendu Blink.
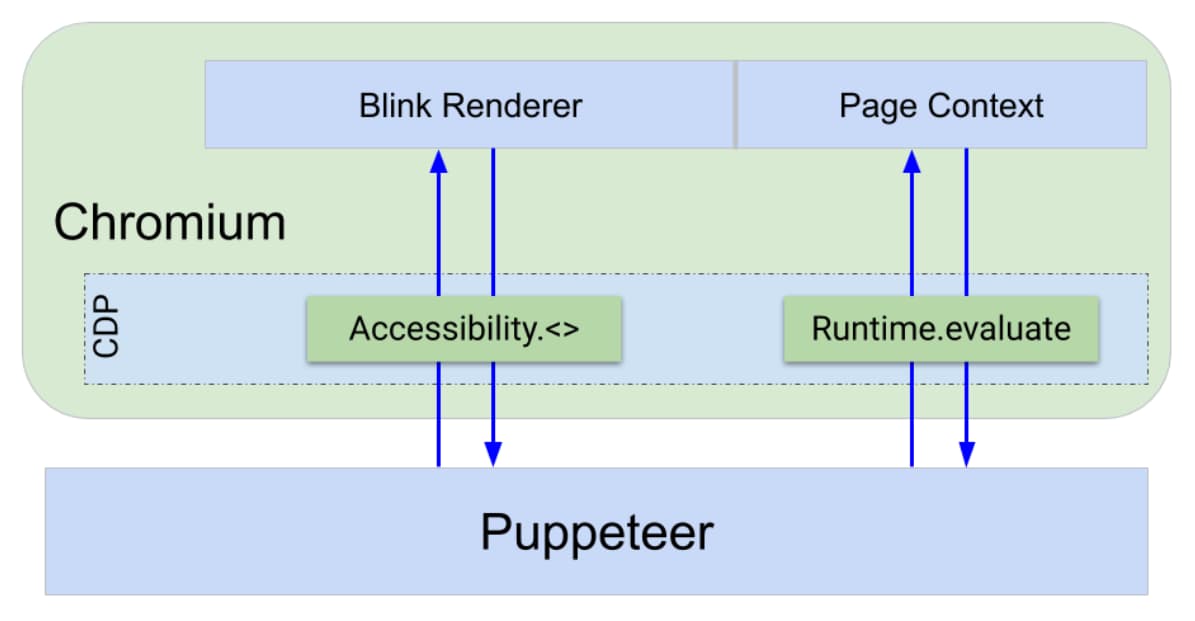
Nous avons donc déjà deux options pour implémenter notre fonctionnalité de requête:
- Écrire notre logique de requête en JavaScript et l'injecter dans la page à l'aide de
Runtime.evaluate, ou - Utilisez un point de terminaison CDP pouvant accéder à l'arborescence d'accessibilité et l'interroger directement dans le processus Blink.
Nous avons implémenté trois prototypes:
- Parcours du DOM JavaScript : basé sur l'injection de code JavaScript dans la page
- Parcours AXTree Puppeteer : basé sur l'utilisation de l'accès CDP existant à l'arborescence d'accessibilité
- Parcours DOM du CDP : utilisation d'un nouveau point de terminaison CDP conçu pour interroger l'arborescence d'accessibilité.
Parcours du DOM JS
Ce prototype effectue une traversée complète du DOM et utilise element.computedName et element.computedRole, contrôlés par l'indicateur de lancement ComputedAccessibilityInfo, pour récupérer le nom et le rôle de chaque élément lors de la traversée.
Parcours AXTree Puppeteer
Ici, nous récupérons l'arborescence d'accessibilité complète via CDP et la parcourons dans Puppeteer. Les nœuds d'accessibilité qui en résultent sont ensuite mappés sur des nœuds DOM.
Parcours DOM CDP
Pour ce prototype, nous avons implémenté un nouveau point de terminaison CDP spécifiquement pour interroger l'arborescence d'accessibilité. De cette façon, les requêtes peuvent être effectuées sur le backend via une implémentation C++ au lieu d'être exécutées dans le contexte de la page via JavaScript.
Benchmark de test unitaire
La figure suivante compare le temps d'exécution total de la requête de quatre éléments 1 000 fois pour les trois prototypes. Le benchmark a été exécuté dans trois configurations différentes, en modifiant la taille de la page et en activant ou non la mise en cache des éléments d'accessibilité.

Il est clair qu'il existe un écart de performances considérable entre le mécanisme de requêtes basé sur le CDP et les deux autres implémentés uniquement dans Puppeteer. La différence relative semble augmenter considérablement avec la taille de la page. Il est intéressant de constater que le prototype de parcours DOM JS répond si bien à l'activation de la mise en cache d'accessibilité. Lorsque la mise en cache est désactivée, l'arborescence d'accessibilité est calculée à la demande et supprimée après chaque interaction si le domaine est désactivé. Si vous activez le domaine, Chromium met en cache l'arborescence calculée à la place.
Pour l'exploration du DOM JS, nous demandons le nom et le rôle accessibles pour chaque élément lors de l'exploration. Par conséquent, si la mise en cache est désactivée, Chromium calcule et supprime l'arborescence d'accessibilité pour chaque élément que nous consultons. En revanche, pour les approches basées sur le CDP, l'arbre n'est supprimé qu'entre chaque appel au CDP, c'est-à-dire pour chaque requête. Ces approches bénéficient également de l'activation de la mise en cache, car l'arborescence d'accessibilité est ensuite conservée entre les appels CDP, mais l'amélioration des performances est donc relativement plus faible.
Même si l'activation du cache semble souhaitable ici, elle entraîne une utilisation supplémentaire de la mémoire. Cela peut poser problème pour les scripts Puppeteer qui, par exemple, enregistrent des fichiers de suivi. Nous avons donc décidé de ne pas activer le cache de l'arborescence d'accessibilité par défaut. Les utilisateurs peuvent activer eux-mêmes la mise en cache en activant le domaine d'accessibilité du CDP.
Benchmark de la suite de tests DevTools
Le benchmark précédent a montré que l'implémentation de notre mécanisme de requête au niveau de la couche CDP améliore les performances dans un scénario de test unitaire clinique.
Pour voir si la différence est suffisamment prononcée pour être perceptible dans un scénario plus réaliste d'exécution d'une suite de tests complète, nous avons corrigé la suite de tests de bout en bout DevTools pour utiliser les prototypes JavaScript et basés sur le CDP, puis comparé les temps d'exécution. Dans ce benchmark, nous avons remplacé 43 sélecteurs [aria-label=…] par un gestionnaire de requêtes personnalisé aria/…, que nous avons ensuite implémenté à l'aide de chacun des prototypes.
Certains sélecteurs sont utilisés plusieurs fois dans les scripts de test. Le nombre réel d'exécutions du gestionnaire de requêtes aria était donc de 113 par exécution de la suite. Le nombre total de sélections de requêtes était de 2 253. Par conséquent, seule une fraction des sélections de requêtes a été effectuée via les prototypes.

Comme le montre la figure ci-dessus, il existe une différence perceptible dans la durée d'exécution totale. Les données sont trop bruyantes pour tirer des conclusions spécifiques, mais il est clair que l'écart de performances entre les deux prototypes se manifeste également dans ce scénario.
Un nouveau point de terminaison CDP
Compte tenu des benchmarks ci-dessus et étant donné que l'approche basée sur le flag de lancement était indésirable en général, nous avons décidé de mettre en œuvre une nouvelle commande CDP pour interroger l'arborescence d'accessibilité. Nous avons ensuite dû déterminer l'interface de ce nouveau point de terminaison.
Pour notre cas d'utilisation dans Puppeteer, le point de terminaison doit prendre l'argument RemoteObjectIds et, pour nous permettre de trouver les éléments DOM correspondants par la suite, il doit renvoyer une liste d'objets contenant le backendNodeIds des éléments DOM.
Comme le montre le graphique ci-dessous, nous avons essayé de nombreuses approches pour répondre à cette interface. Nous avons constaté que la taille des objets renvoyés, c'est-à-dire si nous renvoyons des nœuds d'accessibilité complets ou uniquement backendNodeIds, n'avait aucune différence perceptible. D'un autre côté, nous avons constaté que l'utilisation de NextInPreOrderIncludingIgnored existante était un mauvais choix pour implémenter la logique de parcours ici, car cela entraînait un ralentissement notable.

Conclusion
Maintenant que le point de terminaison CDP est en place, nous avons implémenté le gestionnaire de requêtes du côté Puppeteer. L'essentiel du travail consistait à restructurer le code de gestion des requêtes pour permettre aux requêtes de se résoudre directement via le CDP au lieu de les interroger via JavaScript évalué dans le contexte de la page.
Étape suivante
Le nouveau gestionnaire aria est fourni avec Puppeteer v5.4.0 en tant que gestionnaire de requêtes intégré. Nous avons hâte de voir comment les utilisateurs l'intégreront à leurs scripts de test et nous sommes impatients de connaître vos idées pour l'améliorer.
Télécharger les canaux de prévisualisation
Envisagez d'utiliser Chrome Canary, Dev ou Bêta comme navigateur de développement par défaut. Ces canaux de prévisualisation vous donnent accès aux dernières fonctionnalités de DevTools, vous permettent de tester les API de plate-forme Web de pointe et vous aident à détecter les problèmes sur votre site avant vos utilisateurs.
Contacter l'équipe des outils pour les développeurs Chrome
Utilisez les options suivantes pour discuter des nouvelles fonctionnalités, des mises à jour ou de tout autre élément lié aux outils pour les développeurs.
- Envoyez-nous vos commentaires et vos demandes de fonctionnalités sur crbug.com.
- Signalez un problème dans les outils de développement à l'aide de l'icône Plus d'options > Aide > Signaler un problème dans les outils de développement dans les outils de développement.
- Envoyez un tweet à @ChromeDevTools.
- Laissez des commentaires sur les vidéos YouTube sur les nouveautés des outils pour les développeurs ou sur les vidéos YouTube sur les conseils concernant les outils pour les développeurs.