


Niezależnie od tego, jaki typ aplikacji tworzysz, optymalizacja jej wydajności oraz zapewnienie szybkiego ładowania i płynnych interakcji ma kluczowe znaczenie dla komfortu użytkowników i sukcesu aplikacji. Jednym ze sposobów jest sprawdzenie aktywności aplikacji za pomocą narzędzi do profilowania, aby zobaczyć, co się dzieje w jej wnętrzu podczas działania w określonym przedziale czasu. Panel Wydajność w Narzędziach deweloperskich to doskonałe narzędzie do profilowania, które umożliwia analizowanie i optymalizowanie wydajności aplikacji internetowych. Jeśli aplikacja działa w Chrome, narzędzie to zapewnia szczegółowy wizualny przegląd działań przeglądarki podczas wykonywania aplikacji. Analiza tej aktywności może pomóc w identyfikowaniu wzorców, wąskich gardeł i obszarów o największej aktywności, które możesz wykorzystać do poprawy skuteczności.
W przykładzie poniżej pokazujemy, jak korzystać z panelu Wydajność.
Konfigurowanie i odtwarzanie scenariusza profilowania
Niedawno wyznaczyliśmy sobie cel, jakim jest zwiększenie wydajności panelu Skuteczność. Zależało nam zwłaszcza na tym, aby szybciej wczytywać duże ilości danych o skuteczności. Dzieje się tak na przykład w przypadku profilowania długotrwałych lub złożonych procesów albo rejestrowania danych o wysokiej szczegółowości. Aby to osiągnąć, najpierw trzeba było zrozumieć, jak działa aplikacja i dlaczego działa w taki sposób. W tym celu użyto narzędzia do profilowania.
Jak zapewne wiesz, Narzędzia deweloperskie to aplikacja internetowa. Dlatego można go profilować za pomocą panelu Wydajność. Aby profilować ten panel, możesz otworzyć Narzędzia deweloperskie, a następnie otworzyć kolejną instancję Narzędzi deweloperskich dołączoną do niego. W Google ta konfiguracja jest znana jako Narzędzia deweloperskie w Narzędziach deweloperskich.
Po przygotowaniu konfiguracji należy odtworzyć i zarejestrować scenariusz, który ma zostać profilowany. Aby uniknąć nieporozumień, oryginalne okno Narzędzi deweloperskich będziemy nazywać „pierwszą instancją Narzędzi deweloperskich”, a okno, w którym sprawdzana jest pierwsza instancja, będziemy nazywać „drugą instancją Narzędzi deweloperskich”.
W drugim oknie Narzędzi deweloperskich panel Wydajność – od tej pory będziemy go nazywać panelem wydajności – obserwuje pierwsze okno Narzędzi deweloperskich, aby odtworzyć scenariusz, który wczytuje profil.
Na drugiej instancji Narzędzi deweloperskich rozpoczyna się nagrywanie na żywo, a na pierwszej instancji profil jest wczytywany z pliku na dysku. Ładowany jest duży plik, aby dokładnie określić wydajność przetwarzania dużych danych wejściowych. Gdy oba wystąpienia zakończą wczytywanie, dane profilowania wydajności, czyli tzw. ślad, będą widoczne w drugim wystąpieniu Narzędzi deweloperskich na panelu wydajności, który wczytuje profil.
Stan początkowy: identyfikowanie możliwości ulepszeń
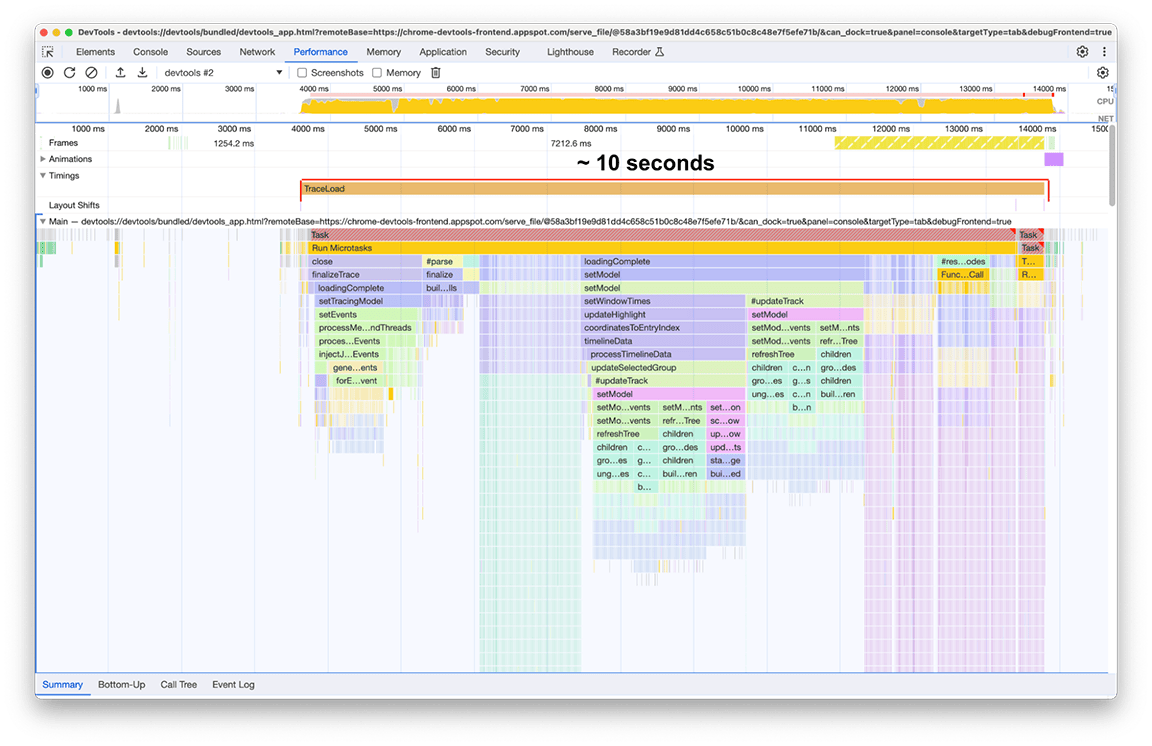
Po zakończeniu wczytywania na drugim panelu wydajności zaobserwowaliśmy to, co widać na zrzucie ekranu poniżej. Skup się na aktywności głównego wątku, która jest widoczna na ścieżce oznaczonej jako Główny. Na wykresie płomieniowym widać 5 głównych grup aktywności. Obejmują one zadania, których wczytywanie trwa najdłużej. Łączny czas wykonania tych zadań wyniósł około 10 sekund. Na zrzucie ekranu poniżej panel Skuteczność służy do skupienia się na każdej z tych grup aktywności, aby sprawdzić, co można w nich znaleźć.
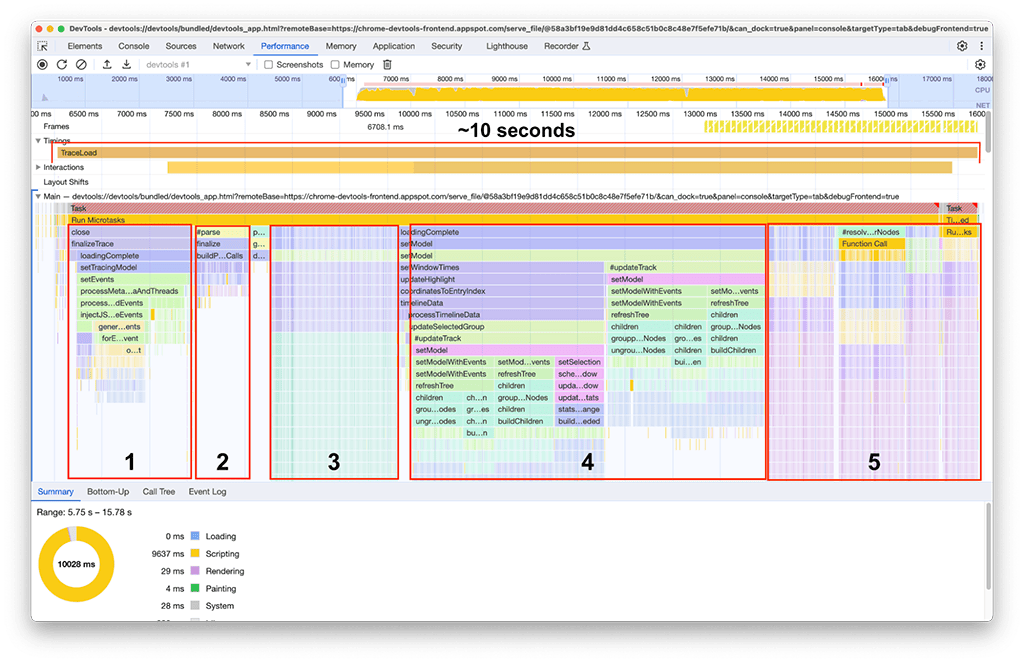
Pierwsza grupa aktywności: niepotrzebna praca
Okazało się, że pierwsza grupa działań to starszy kod, który nadal działał, ale nie był już potrzebny. Wszystko, co znajduje się pod zielonym blokiem oznaczonym symbolem processThreadEvents, było w zasadzie stratą czasu. To była szybka wygrana. Usunięcie tego wywołania funkcji pozwoliło zaoszczędzić około 1,5 sekundy. Super!
Druga grupa aktywności
W przypadku drugiej grupy działań rozwiązanie nie było tak proste jak w przypadku pierwszej. buildProfileCalls zajęło około 0, 5 sekundy i nie można było tego uniknąć.
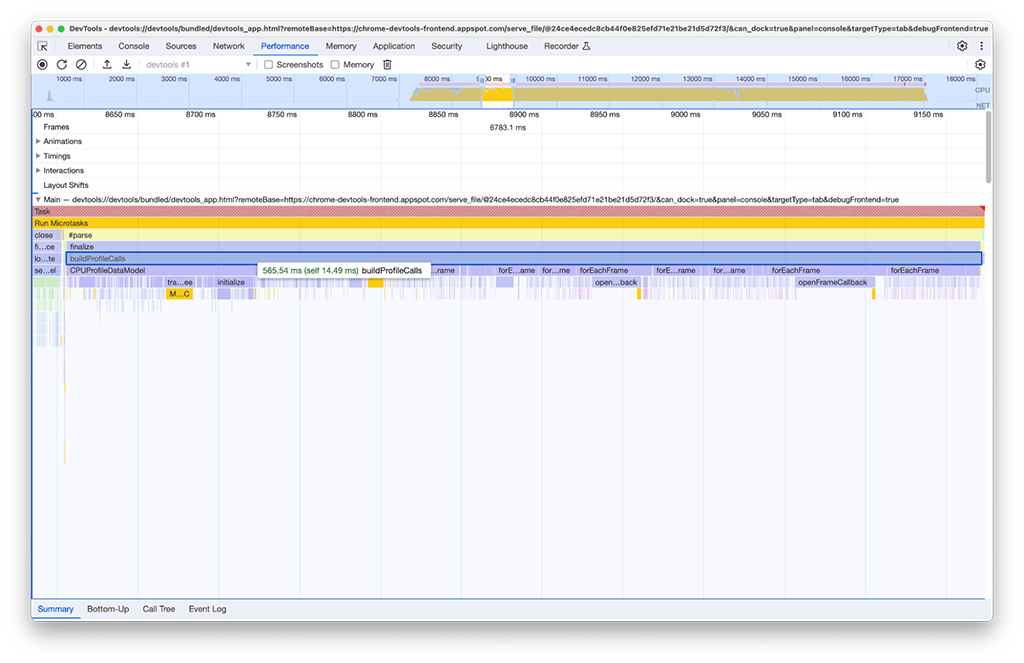
Z ciekawości włączyliśmy w panelu wydajności opcję Pamięć, aby dokładniej zbadać problem. Okazało się, że aktywność buildProfileCalls również zużywa dużo pamięci. Widać tu, jak wykres niebieskiej linii nagle skacze w okolicach czasu uruchomienia funkcji buildProfileCalls, co sugeruje potencjalny wyciek pamięci.
Aby sprawdzić to podejrzenie, użyliśmy panelu Pamięć (innego panelu w Narzędziach deweloperskich, różniącego się od panelu Pamięć w panelu wydajności). W panelu Pamięć wybrano typ profilowania „Próbkowanie przydziału”, który zarejestrował zrzut sterty na potrzeby panelu wydajności podczas wczytywania profilu procesora.
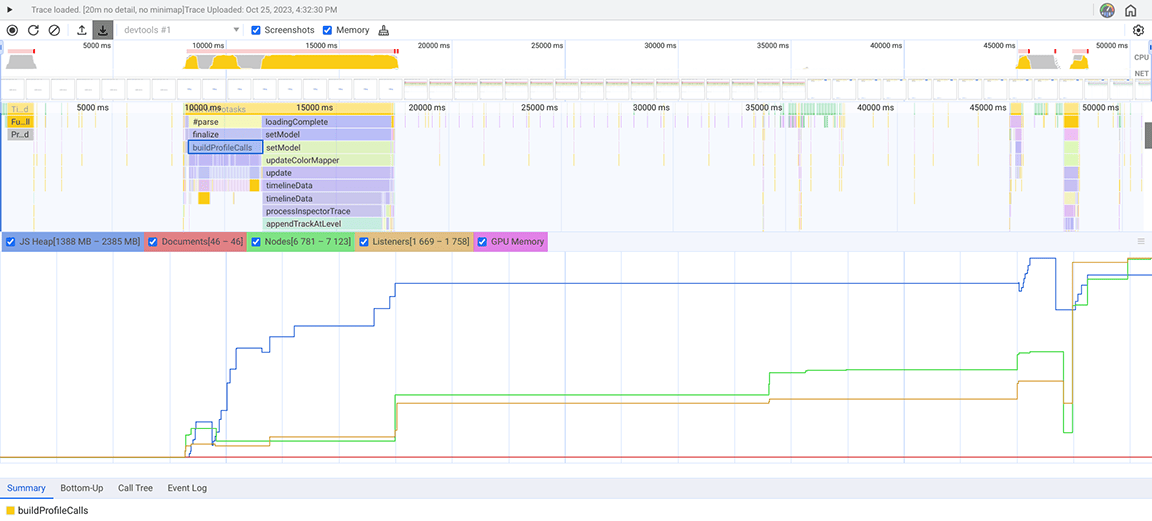
Na zrzucie ekranu poniżej widać zebrany zrzut sterty.
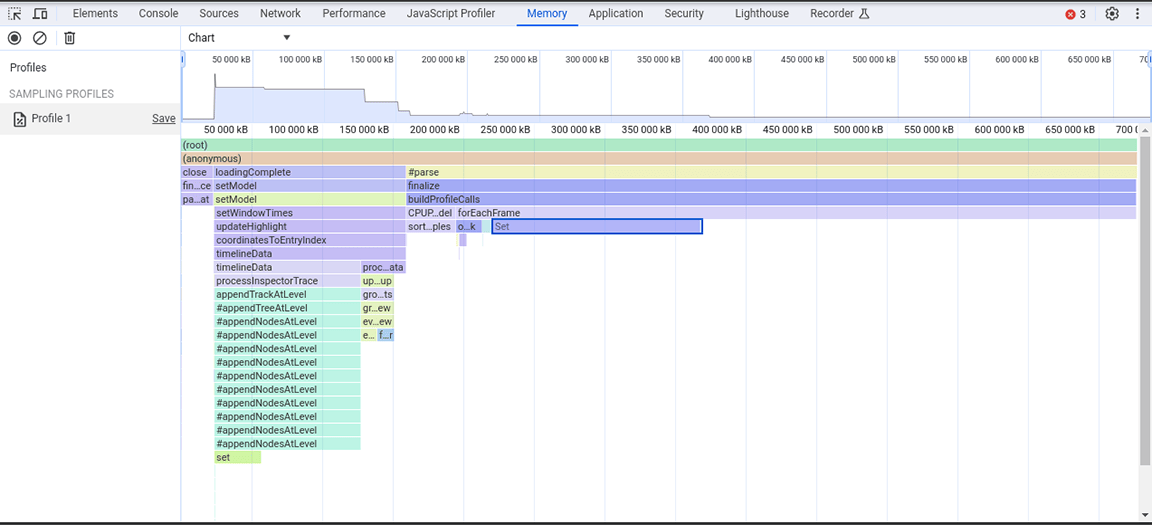
Na podstawie tego zrzutu sterty zaobserwowano, że klasa Set zużywa dużo pamięci. Po sprawdzeniu punktów wywołania stwierdziliśmy, że niepotrzebnie przypisywaliśmy właściwości typu Set do obiektów, które były tworzone w dużych ilościach. Koszty rosły, a pamięć była wykorzystywana w dużym stopniu, do tego stopnia, że aplikacja często ulegała awarii w przypadku dużych danych wejściowych.
Zbiory są przydatne do przechowywania unikalnych elementów i zapewniają operacje, które wykorzystują unikalność ich zawartości, takie jak usuwanie duplikatów ze zbiorów danych i zapewnianie wydajniejszych wyszukiwań. Nie były one jednak konieczne, ponieważ przechowywane dane były unikalne w stosunku do źródła. W związku z tym zestawy nie były w ogóle potrzebne. Aby poprawić przydział pamięci, zmieniliśmy typ właściwości z Set na zwykłą tablicę. Po wprowadzeniu tej zmiany wykonano kolejną migawkę sterty, w której zaobserwowano zmniejszoną alokację pamięci. Chociaż ta zmiana nie przyniosła znacznej poprawy szybkości, jej dodatkową zaletą było rzadsze zawieszanie się aplikacji.
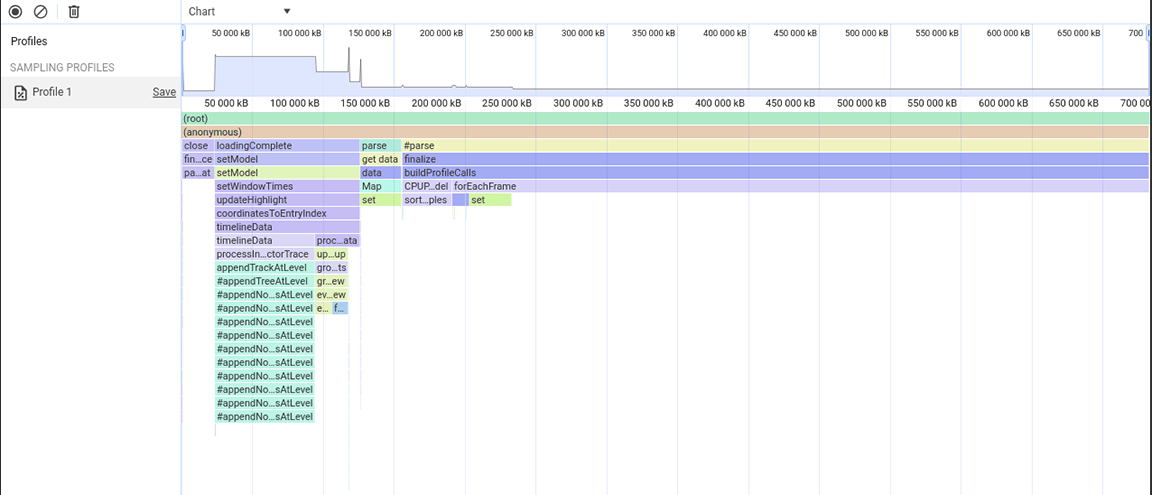
Trzecia grupa aktywności: rozważanie kompromisów dotyczących struktury danych
Trzecia sekcja jest szczególna: na wykresie płomieniowym widać, że składa się z wąskich, ale wysokich kolumn, które oznaczają głębokie wywołania funkcji, a w tym przypadku głębokie rekursje. Łącznie ta sekcja trwała około 1, 4 sekundy. Na dole tej sekcji widać, że szerokość tych kolumn jest określana przez czas trwania jednej funkcji: appendEventAtLevel, co sugeruje, że może to być wąskie gardło.
W implementacji funkcji appendEventAtLevel jedna rzecz rzucała się w oczy. Do każdego wpisu danych wejściowych (w kodzie znanego jako „zdarzenie”) dodano element do mapy, która śledziła pionowe położenie wpisów na osi czasu. Było to problematyczne, ponieważ liczba przechowywanych elementów była bardzo duża. Mapy są szybkie w przypadku wyszukiwania na podstawie klucza, ale ta zaleta nie jest bezpłatna. Wraz ze wzrostem rozmiaru mapy dodawanie do niej danych może stać się kosztowne, np. ze względu na ponowne mieszanie. Ten koszt staje się zauważalny, gdy do mapy dodawana jest duża liczba elementów.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
Wypróbowaliśmy inne podejście, które nie wymagało dodawania elementu na mapie dla każdego wpisu na wykresie płomieniowym. Poprawa była znacząca, co potwierdziło, że wąskie gardło było rzeczywiście związane z narzutem wynikającym z dodania wszystkich danych do mapy. Czas trwania grupy aktywności skrócił się z około 1,4 sekundy do około 200 milisekund.
Przed:
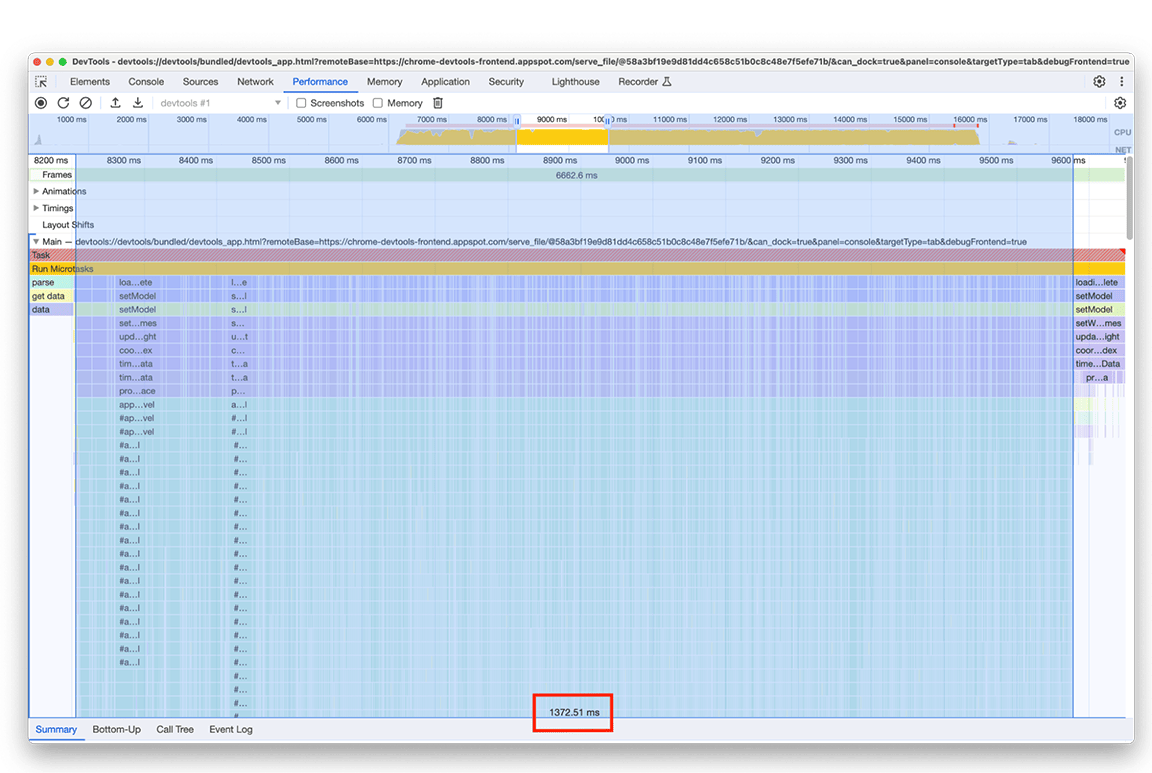
Po:
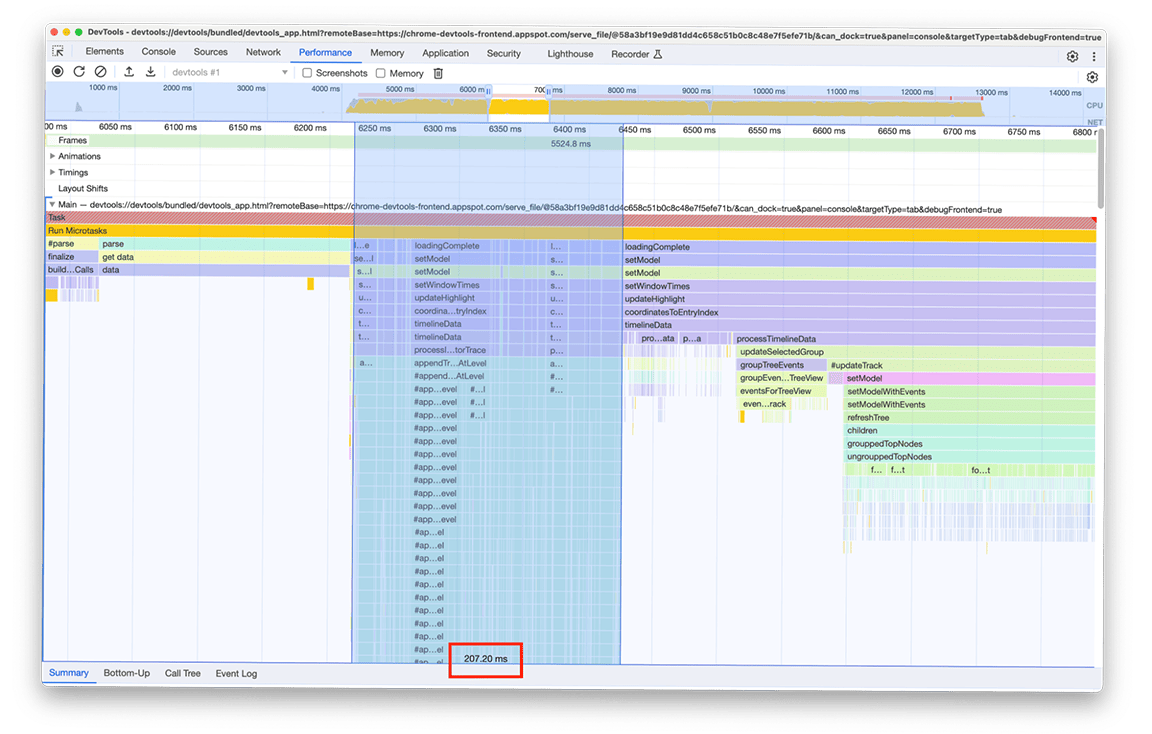
Czwarta grupa działań: odraczanie zadań niekrytycznych i buforowanie danych, aby zapobiegać duplikowaniu pracy
Po powiększeniu tego okna widać, że znajdują się w nim 2 niemal identyczne bloki wywołań funkcji. Na podstawie nazw wywoływanych funkcji możesz wywnioskować, że te bloki składają się z kodu, który tworzy drzewa (np. z nazwami refreshTree lub buildChildren). W rzeczywistości powiązany kod tworzy widoki drzew w dolnym panelu. Ciekawostką jest to, że te widoki drzewa nie są wyświetlane od razu po wczytaniu. Aby wyświetlić drzewa, użytkownik musi wybrać widok drzewa (karty „Od dołu do góry”, „Drzewo wywołań” i „Dziennik zdarzeń” w panelu). Jak widać na zrzucie ekranu, proces tworzenia drzewa został wykonany dwukrotnie.
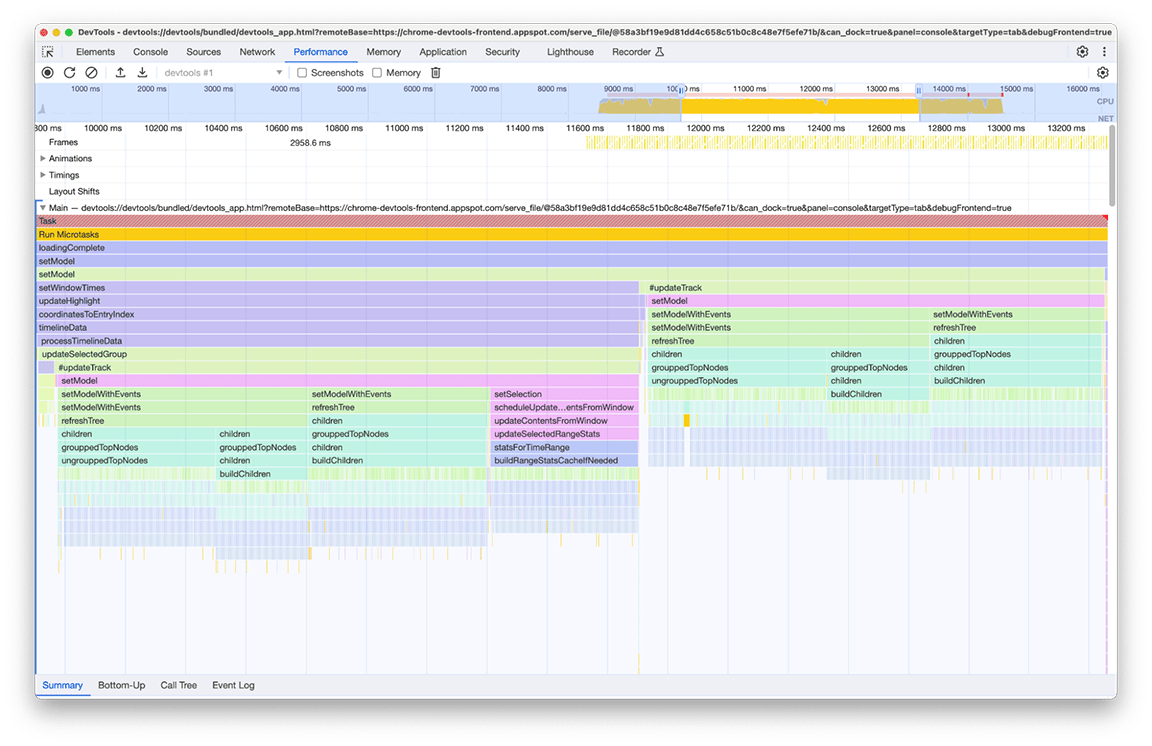
W przypadku tego zdjęcia zidentyfikowaliśmy 2 problemy:
- Zadanie o mniejszym znaczeniu utrudniało osiągnięcie optymalnego czasu wczytywania. Użytkownicy nie zawsze potrzebują jego danych wyjściowych. Dlatego to zadanie nie jest kluczowe dla ładowania profilu.
- Wynik tych zadań nie został zapisany w pamięci podręcznej. Dlatego drzewa zostały obliczone dwukrotnie, mimo że dane się nie zmieniły.
Zaczęliśmy od odraczania obliczania drzewa do momentu, gdy użytkownik ręcznie otworzy widok drzewa. Dopiero wtedy warto ponieść koszt utworzenia tych drzew. Łączny czas dwukrotnego wykonania tej operacji wyniósł około 3,4 sekundy, więc odroczenie jej miało znaczący wpływ na czas wczytywania. Nadal analizujemy też możliwość buforowania tego typu zadań.
Piąta grupa aktywności: w miarę możliwości unikaj złożonych hierarchii połączeń
Po dokładnym przyjrzeniu się tej grupie okazało się, że określony łańcuch wywołań jest wywoływany wielokrotnie. Ten sam wzorzec pojawił się 6 razy w różnych miejscach na wykresie płomieniowym, a łączny czas trwania tego okna wyniósł około 2,4 sekundy.
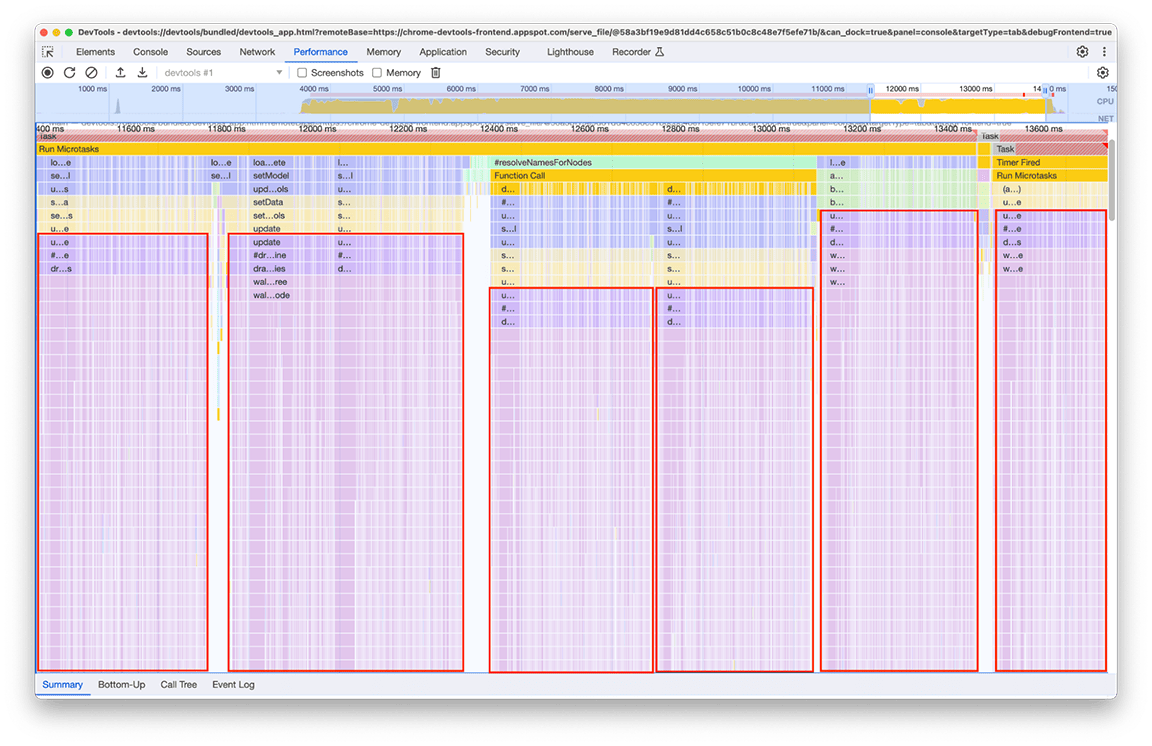
Wielokrotne wywoływanie powiązanego kodu to część, która przetwarza dane do wyświetlenia na „minimapie” (przegląd aktywności na osi czasu u góry panelu). Nie było jasne, dlaczego zdarzało się to wielokrotnie, ale na pewno nie musiało się zdarzyć 6 razy. W rzeczywistości dane wyjściowe kodu powinny pozostać aktualne, jeśli nie zostanie wczytany żaden inny profil. Teoretycznie kod powinien być uruchamiany tylko raz.
Podczas analizy okazało się, że powiązany kod był wywoływany w wyniku tego, że wiele części potoku wczytywania bezpośrednio lub pośrednio wywoływało funkcję obliczającą minimapę. Wynika to z faktu, że złożoność wykresu wywołań programu zmieniała się z czasem, a do tego kodu nieświadomie dodano więcej zależności. Nie ma szybkiego rozwiązania tego problemu. Sposób rozwiązania tego problemu zależy od architektury danego kodu. W naszym przypadku musieliśmy nieco zmniejszyć złożoność hierarchii wywołań i dodać sprawdzenie, które zapobiega wykonaniu kodu, jeśli dane wejściowe pozostaną niezmienione. Po wdrożeniu tej zmiany oś czasu wyglądała tak:
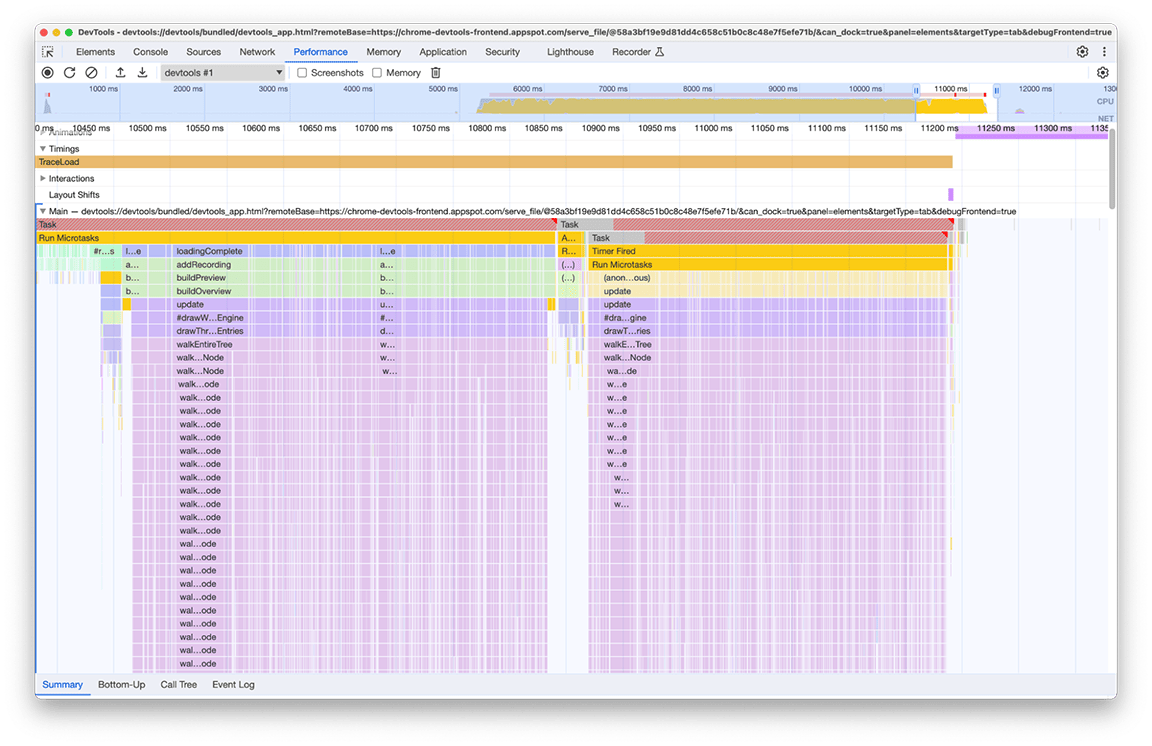
Pamiętaj, że renderowanie minimapy odbywa się 2 razy, a nie raz. Dzieje się tak, ponieważ dla każdego profilu rysowane są 2 minimapy: jedna w widoku ogólnym u góry panelu, a druga w menu, które pozwala wybrać aktualnie widoczny profil z historii (każdy element tego menu zawiera widok ogólny profilu, który wybiera). Oba te pliki mają jednak dokładnie taką samą zawartość, więc jeden z nich powinien być możliwy do ponownego wykorzystania w przypadku drugiego.
Ponieważ obie minimapy to obrazy narysowane na płótnie, wystarczyło użyć drawImage narzędzia do obsługi płótna, a następnie uruchomić kod tylko raz, aby zaoszczędzić trochę czasu. Dzięki temu czas trwania grupy został skrócony z 2, 4 sekundy do 140 milisekund.
Podsumowanie
Po zastosowaniu wszystkich tych poprawek (i kilku innych mniejszych) zmiana osi czasu wczytywania profilu wyglądała tak:
Przed:
Po:
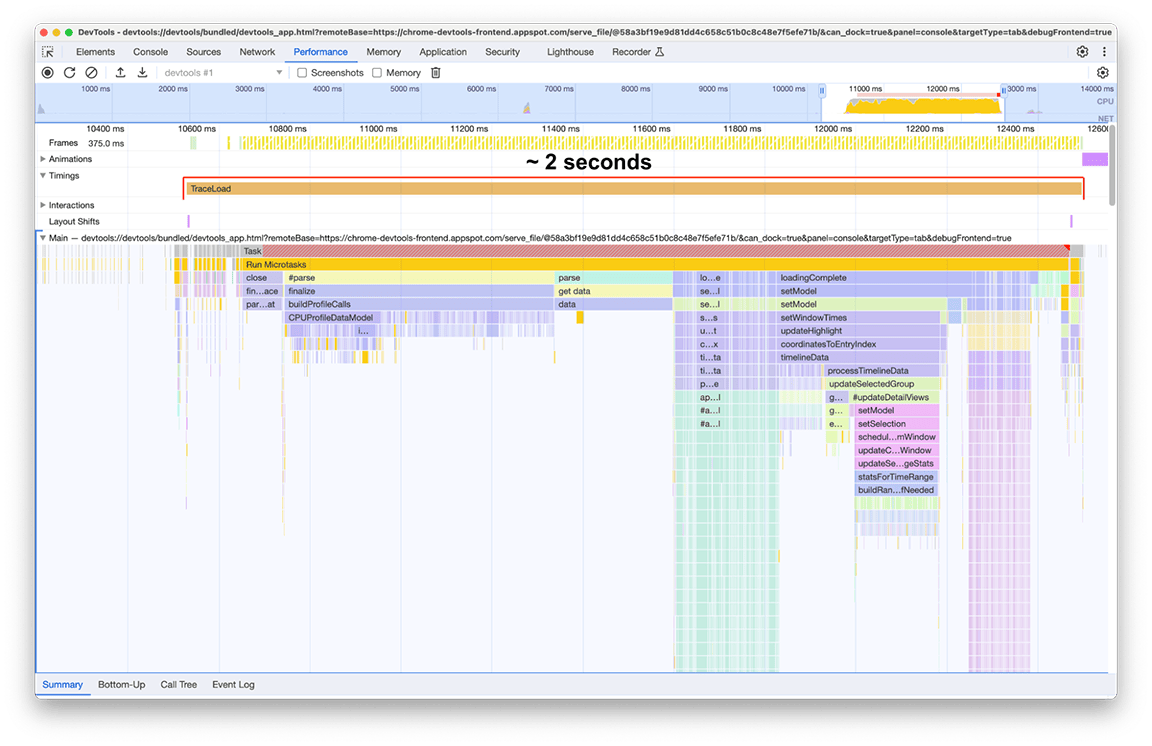
Po wprowadzeniu ulepszeń czas ładowania wyniósł 2 sekundy, co oznacza, że osiągnięto poprawę o około 80% przy stosunkowo niewielkim wysiłku, ponieważ większość wprowadzonych zmian to szybkie poprawki. Oczywiście kluczowe było prawidłowe określenie co należy zrobić na początku, a panel wydajności był do tego odpowiednim narzędziem.
Warto też podkreślić, że te liczby dotyczą konkretnego profilu używanego jako obiekt badania. Profil był dla nas interesujący, ponieważ był wyjątkowo duży. Ponieważ jednak potok przetwarzania jest taki sam w przypadku każdego profilu, znacząca poprawa dotyczy każdego profilu wczytanego w panelu wydajności.
Wnioski
Z tych wyników można wyciągnąć pewne wnioski dotyczące optymalizacji wydajności aplikacji:
1. Korzystaj z narzędzi do profilowania, aby identyfikować wzorce wydajności w czasie działania.
Narzędzia do profilowania są niezwykle przydatne do analizowania tego, co dzieje się w aplikacji podczas jej działania, zwłaszcza do identyfikowania możliwości poprawy wydajności. Panel Wydajność w Narzędziach deweloperskich w Chrome to świetna opcja w przypadku aplikacji internetowych, ponieważ jest to natywne narzędzie do profilowania w przeglądarce, które jest aktywnie aktualizowane, aby było zgodne z najnowszymi funkcjami platformy internetowej. Jest też teraz znacznie szybsza. 😉
Użyj próbek, które mogą służyć jako reprezentatywne zbiory zadań, i sprawdź, co możesz znaleźć.
2. Unikaj złożonych hierarchii połączeń
Jeśli to możliwe, unikaj zbyt skomplikowanego grafu połączeń. W przypadku złożonych hierarchii wywołań łatwo jest wprowadzić regresje wydajności i trudno zrozumieć, dlaczego kod działa w określony sposób, co utrudnia wprowadzanie ulepszeń.
3. Identyfikowanie niepotrzebnej pracy
Starsze bazy kodu często zawierają kod, który nie jest już potrzebny. W naszym przypadku starszy i niepotrzebny kod zajmował znaczną część całkowitego czasu wczytywania. Usunięcie tego elementu było najprostszym rozwiązaniem.
4. Odpowiednie używanie struktur danych
Używaj struktur danych do optymalizacji wydajności, ale pamiętaj też o kosztach i kompromisach związanych z każdym typem struktury danych, gdy decydujesz, których z nich użyć. Nie chodzi tylko o złożoność pamięciową samej struktury danych, ale także o złożoność czasową odpowiednich operacji.
5. buforowanie wyników, aby uniknąć duplikowania pracy w przypadku złożonych lub powtarzalnych operacji;
Jeśli wykonanie operacji jest kosztowne, warto zapisać jej wyniki, aby można było z nich skorzystać w przyszłości. Warto to zrobić również wtedy, gdy operacja jest wykonywana wiele razy, nawet jeśli pojedyncze wykonanie nie jest szczególnie kosztowne.
6. Odłóż pracę, która nie jest pilna
Jeśli wynik zadania nie jest potrzebny od razu, a jego wykonanie wydłuża ścieżkę krytyczną, rozważ odroczenie go przez leniwe wywołanie, gdy jego wynik będzie rzeczywiście potrzebny.
7. Używanie wydajnych algorytmów w przypadku dużych danych wejściowych
W przypadku dużych danych wejściowych kluczowe stają się algorytmy o optymalnej złożoności czasowej. W tym przykładzie nie analizowaliśmy tej kategorii, ale jej znaczenie jest nie do przecenienia.
8. Bonus: porównywanie potoków
Aby mieć pewność, że rozwijany kod pozostanie szybki, warto monitorować jego działanie i porównywać je ze standardami. Dzięki temu możesz aktywnie identyfikować regresje i zwiększać ogólną niezawodność, co zapewni Ci długoterminowy sukces.