


開発するアプリケーションの種類に関係なく、パフォーマンスを最適化し、高速な読み込みとスムーズなインタラクションを実現することは、ユーザー エクスペリエンスとアプリケーションの成功にとって非常に重要です。これを行う方法の 1 つは、プロファイリング ツールを使用してアプリのアクティビティを検査し、時間枠内で実行されているときに何が起こっているかを確認することです。DevTools の [パフォーマンス] パネルは、ウェブ アプリケーションのパフォーマンスを分析して最適化するための優れたプロファイリング ツールです。アプリが Chrome で実行されている場合、アプリの実行中にブラウザが何をしているかについて、詳細な視覚的概要が表示されます。このアクティビティを理解すると、パフォーマンスを改善するために対応できるパターン、ボトルネック、パフォーマンスのホットスポットを特定できます。
次の例では、[パフォーマンス] パネルの使用方法について説明します。
プロファイリング シナリオのセットアップと再作成
最近、Google は [パフォーマンス] パネルのパフォーマンスを向上させることを目標に掲げました。特に、大量のパフォーマンス データをより迅速に読み込むことを目的としていました。たとえば、長時間実行される複雑なプロセスをプロファイリングする場合や、高粒度のデータをキャプチャする場合などです。これを実現するには、まずアプリケーションのパフォーマンスと、そのパフォーマンスの理由を理解する必要がありました。これは、プロファイリング ツールを使用して実現しました。
ご存じのとおり、DevTools 自体はウェブ アプリケーションです。そのため、パフォーマンス パネルを使用してプロファイリングできます。このパネル自体をプロファイリングするには、DevTools を開き、それにアタッチされた別の DevTools インスタンスを開きます。Google では、この設定を DevTools-on-DevTools と呼んでいます。
セットアップが完了したら、プロファイリングするシナリオを再作成して記録する必要があります。混乱を避けるため、元の DevTools ウィンドウを「最初の DevTools インスタンス」、最初のインスタンスを検証しているウィンドウを「2 番目の DevTools インスタンス」と呼びます。
2 つ目の DevTools インスタンスの [パフォーマンス] パネル(以降、perf パネルと呼びます)は、最初の DevTools インスタンスを監視してシナリオを再現し、プロファイルを読み込みます。
2 つ目の DevTools インスタンスではライブ録画が開始され、1 つ目のインスタンスではディスク上のファイルからプロファイルが読み込まれます。大きな入力の処理のパフォーマンスを正確にプロファイリングするために、大きなファイルが読み込まれます。両方のインスタンスの読み込みが完了すると、パフォーマンス プロファイリング データ(一般にトレースと呼ばれます)が、プロファイルを読み込む 2 番目の DevTools インスタンスの perf パネルに表示されます。
初期状態: 改善の機会を特定する
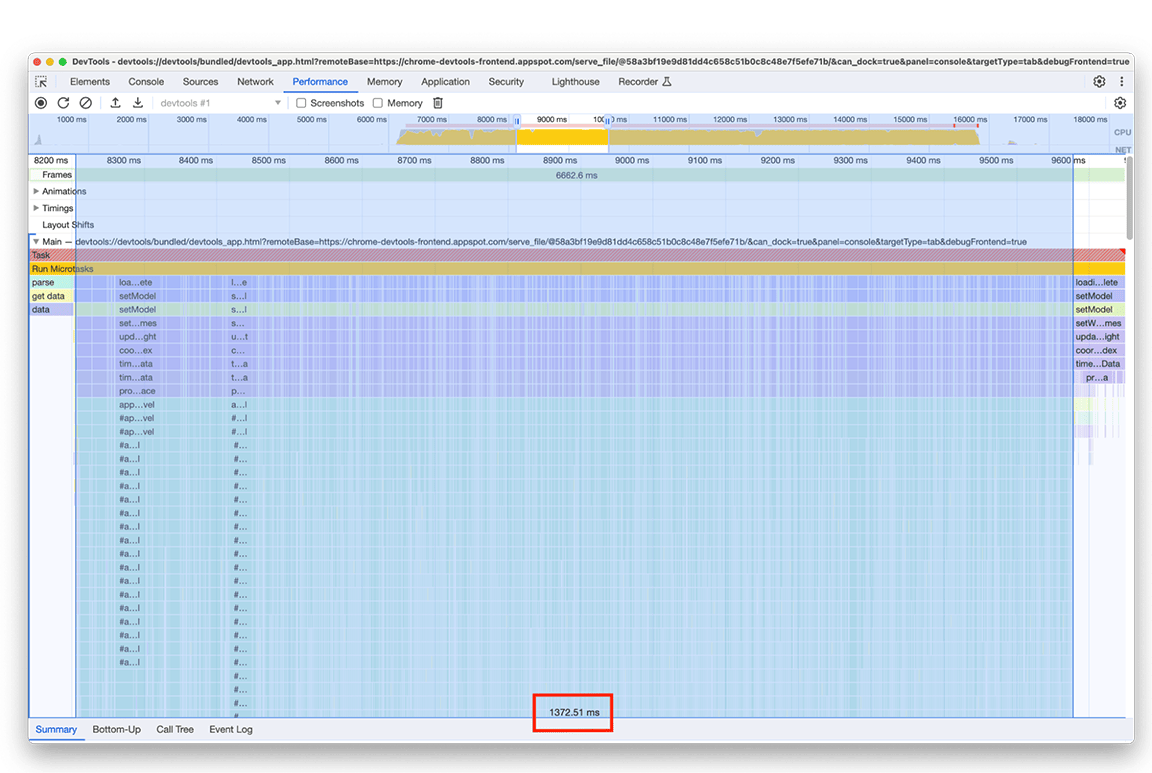
読み込みが完了すると、次のスクリーンショットに示すように、2 番目のパフォーマンス パネル インスタンスに次の内容が表示されます。Main というラベルの付いたトラックの下に表示されるメインスレッドのアクティビティに注目します。フレーム チャートには 5 つのアクティビティ グループがあることがわかります。これらは、読み込みに最も時間がかかっているタスクで構成されます。これらのタスクの合計時間は約 10 秒でした。次のスクリーンショットでは、パフォーマンス パネルを使用して、これらのアクティビティ グループのそれぞれに焦点を当て、何が見つかるかを確認しています。
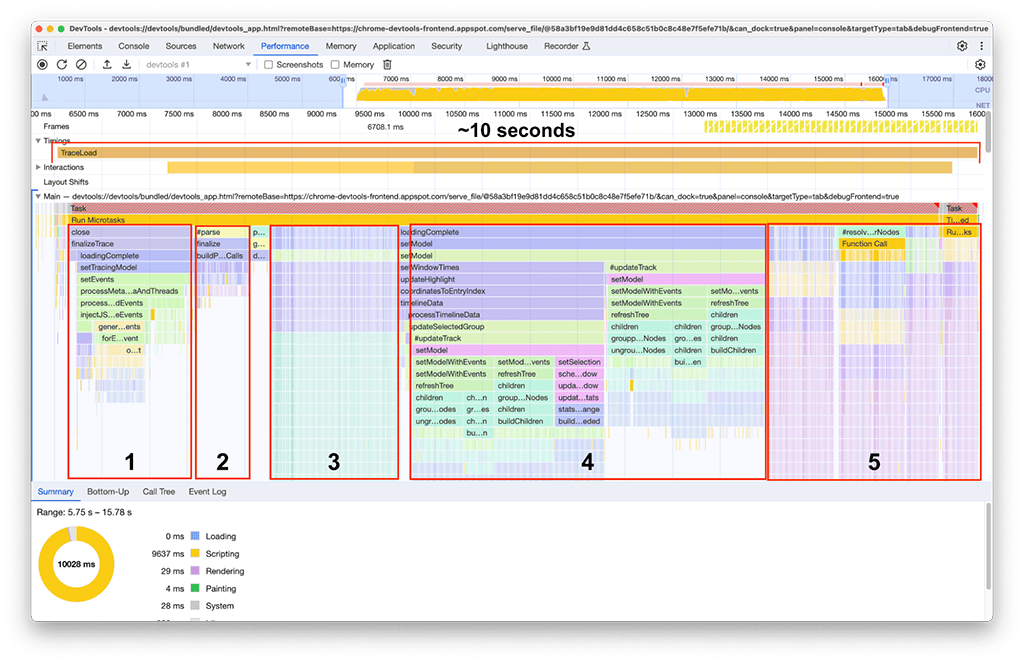
最初のアクティビティ グループ: 不要な作業
最初のアクティビティ グループは、まだ実行されているものの、実際には必要のないレガシー コードであることがわかりました。基本的に、processThreadEvents というラベルの付いた緑色のブロックの下にあるものはすべて無駄な作業でした。これは短期間で成果を出すことができました。この関数呼び出しを削除することで、約 1.5 秒の時間を節約できました。すばらしいですね!
2 番目のアクティビティ グループ
2 つ目のアクティビティ グループでは、1 つ目のアクティビティ グループほど単純な解決策ではありませんでした。buildProfileCalls には約 0.5 秒かかり、そのタスクは回避できませんでした。
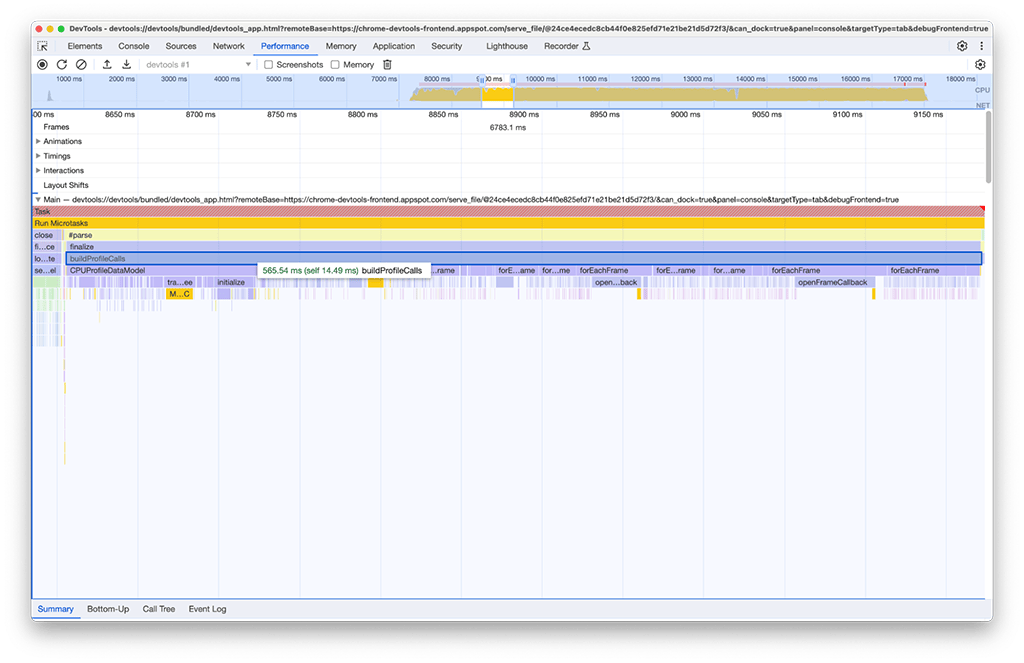
さらに調査するため、パフォーマンス パネルで [メモリ] オプションを有効にすると、buildProfileCalls アクティビティも大量のメモリを使用していることがわかりました。ここでは、buildProfileCalls の実行時に青い折れ線グラフが急激に変動していることがわかります。これは、メモリリークの可能性があることを示しています。
この疑念を検証するため、メモリ パネル(パフォーマンス パネルのメモリ ドロワーとは異なる DevTools の別のパネル)を使用して調査しました。[メモリ] パネルで、[割り当てサンプリング] プロファイリング タイプが選択され、CPU プロファイルを読み込むパフォーマンス パネルのヒープ スナップショットが記録されました。
![メモリ プロファイラの初期状態のスクリーンショット。[割り当てサンプリング] オプションが赤いボックスでハイライト表示され、このオプションが JavaScript メモリ プロファイリングに最適であることが示されています。](https://developer.chrome.google.cn/static/blog/perf-panel-4x-faster/image/fig-5.png?authuser=4&hl=ja)
次のスクリーンショットは、収集されたヒープ スナップショットを示しています。
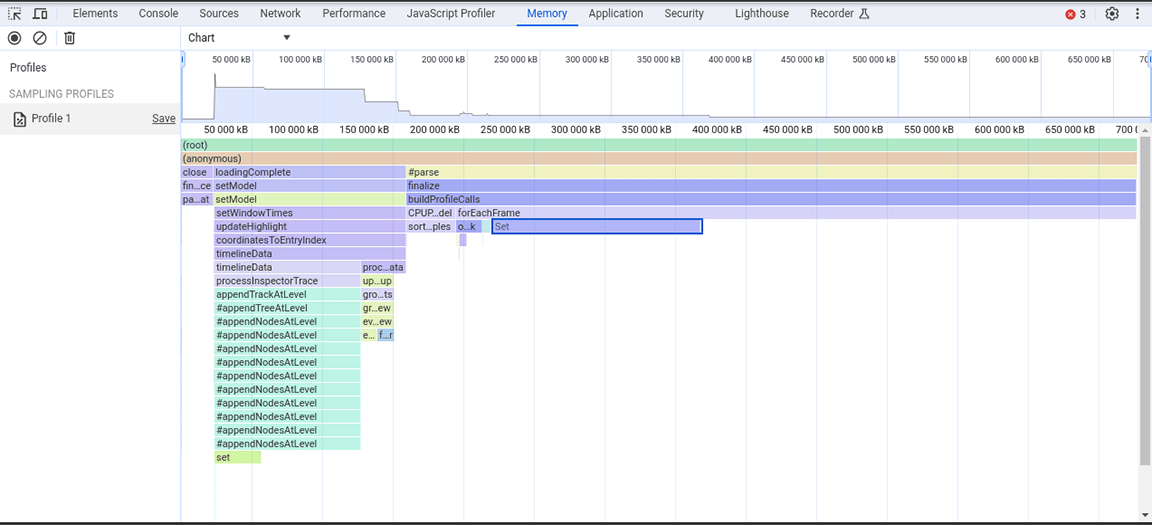
このヒープ スナップショットから、Set クラスが大量のメモリを消費していることがわかりました。呼び出しポイントを確認したところ、大量に作成されたオブジェクトに Set 型のプロパティが不必要に割り当てられていることがわかりました。このコストは増加し、メモリが大量に消費されたため、大規模な入力でアプリケーションがクラッシュすることがよくありました。
セットは、一意のアイテムを保存するのに便利です。また、データセットの重複除去や、より効率的なルックアップなど、コンテンツの一意性を使用するオペレーションを提供します。ただし、保存されたデータはソースから一意であることが保証されていたため、これらの機能は必要ありませんでした。そのため、そもそもセットは必要ありませんでした。メモリ割り当てを改善するため、プロパティ型が Set からプレーン配列に変更されました。この変更を適用した後、別のヒープ スナップショットが取得され、メモリ割り当ての削減が確認されました。この変更では大幅な速度改善は実現できませんでしたが、アプリケーションのクラッシュ頻度が減少するという副次的な効果がありました。
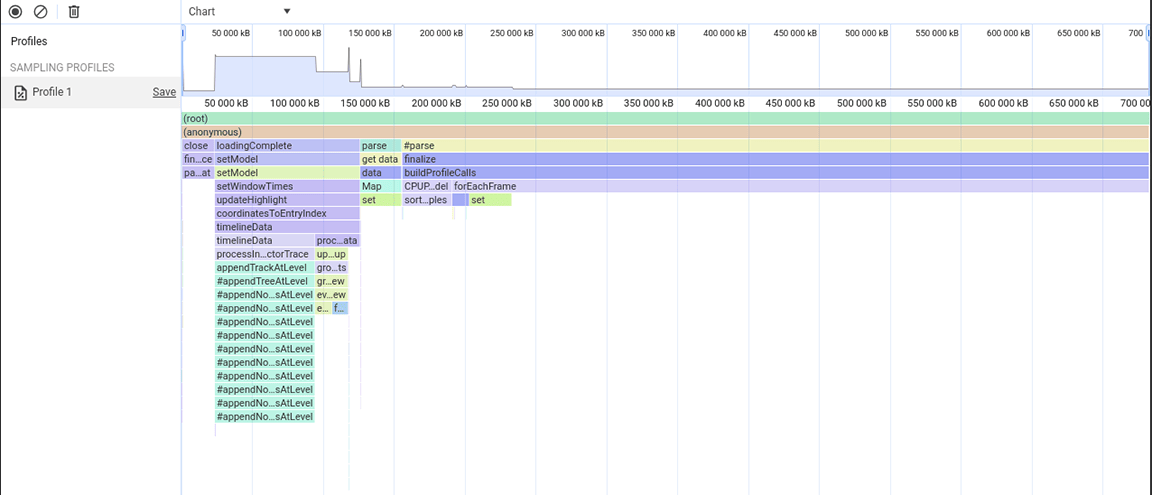
3 番目のアクティビティ グループ: データ構造のトレードオフの重み付け
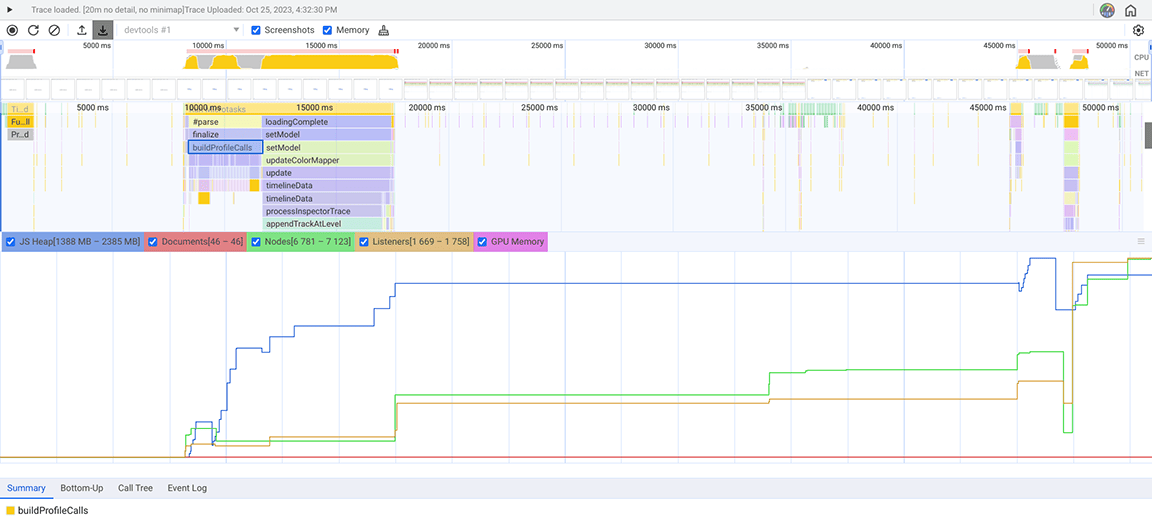
3 番目のセクションは特殊です。フレームグラフを見ると、細くて高い列で構成されていることがわかります。これは、深い関数呼び出し、この場合は深い再帰を示しています。このセクションの合計時間は約 1.4 秒です。このセクションの下部を見ると、これらの列の幅は 1 つの関数 appendEventAtLevel の期間によって決まっていることがわかりました。これは、ボトルネックになる可能性があることを示しています。
appendEventAtLevel 関数の実装の中で、1 つだけ目立つものがありました。入力の各データ エントリ(コードでは「イベント」と呼ばれます)について、タイムライン エントリの垂直位置を追跡するマップにアイテムが追加されました。保存されたアイテムの量が非常に多かったため、これは問題でした。マップはキーベースのルックアップでは高速ですが、このメリットは無料ではありません。マップが大きくなると、たとえば、再ハッシュ処理のためにデータの追加にコストがかかることがあります。このコストは、大量のアイテムがマップに連続して追加される場合に顕著になります。
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
フレーム グラフの各エントリに対してマップにアイテムを追加する必要がない別のアプローチを試しました。この改善は顕著であり、ボトルネックがマップにすべてのデータを追加する際に発生するオーバーヘッドに関連していることが確認されました。アクティビティ グループにかかる時間は約 1.4 秒から約 200 ミリ秒に短縮されました。
変換前:
変換後:
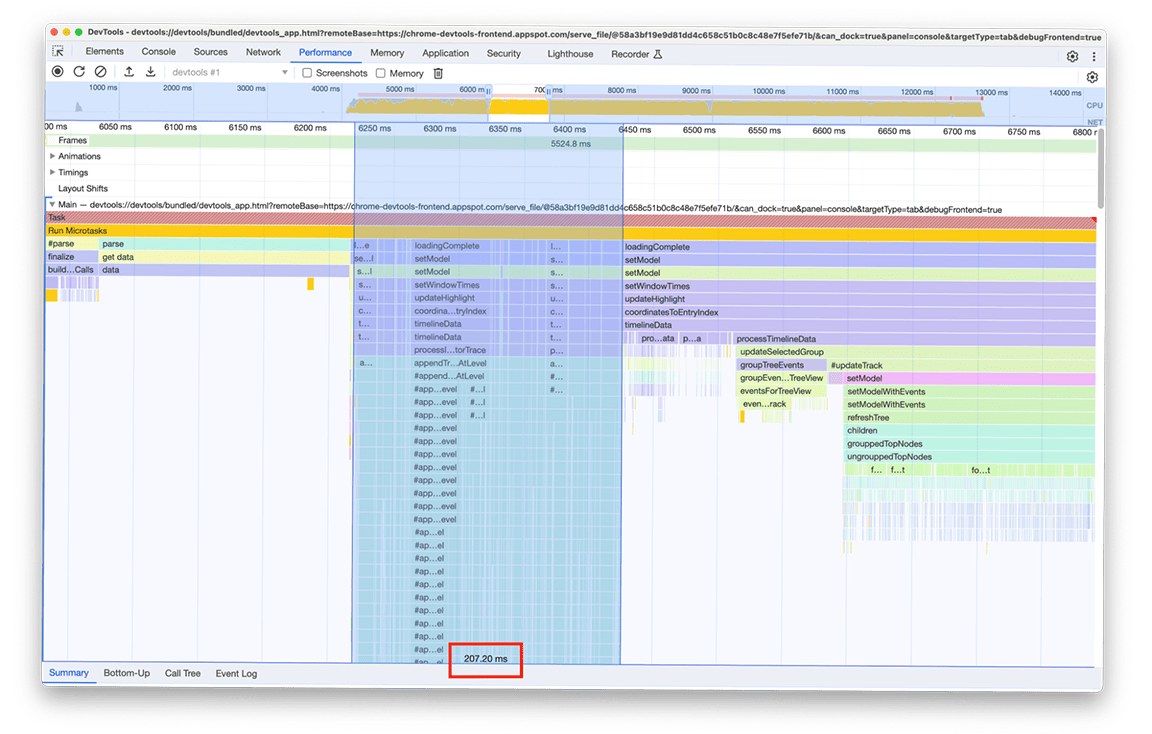
4 つ目のアクティビティ グループ: 重要でない作業を延期し、データをキャッシュに保存して作業の重複を回避する
このウィンドウを拡大すると、ほぼ同じ関数呼び出しのブロックが 2 つあることがわかります。呼び出された関数の名前を見ると、これらのブロックがツリーを構築するコード(refreshTree や buildChildren などの名前)で構成されていることがわかります。実際、関連するコードは、パネルの下部ドロワーにツリービューを作成するコードです。興味深いのは、これらのツリービューは読み込み直後には表示されないことです。代わりに、ツリーを表示するには、ユーザーがツリービュー(ドロワーの [Bottom-up]、[Call Tree]、[Event Log] タブ)を選択する必要があります。さらに、スクリーンショットからわかるように、ツリー構築プロセスが 2 回実行されています。
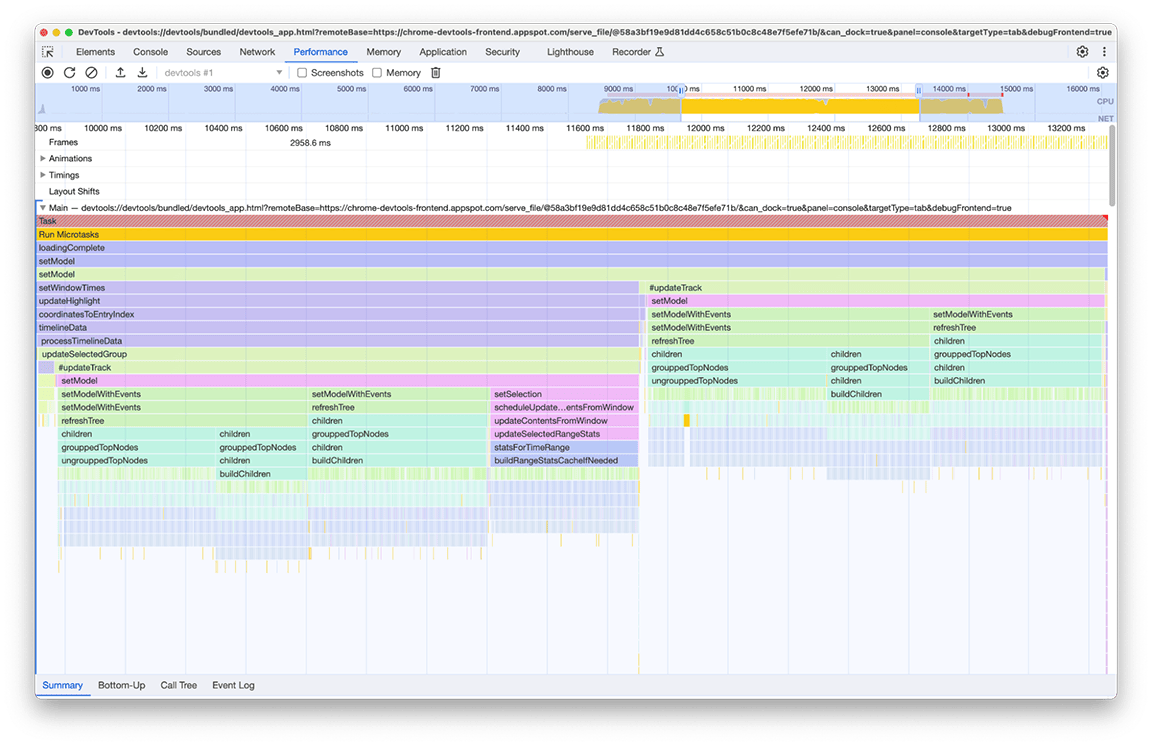
この写真には次の 2 つの問題があることがわかりました。
- 重要でないタスクが読み込み時間のパフォーマンスを妨げていた。ユーザーが常にその出力を必要とするとは限りません。そのため、このタスクはプロファイルの読み込みに不可欠ではありません。
- これらのタスクの結果はキャッシュに保存されませんでした。そのため、データが変更されていないにもかかわらず、ツリーが 2 回計算されました。
まず、ユーザーがツリービューを手動で開いたときにツリーの計算を延期することから始めました。このような場合にのみ、これらのツリーを作成するコストを支払う価値があります。この関数を 2 回実行するのにかかった時間は約 3.4 秒でした。そのため、この関数を遅延することで、読み込み時間に大きな差が生じました。これらのタイプのタスクのキャッシュ保存についても、現在調査中です。
5 番目のアクティビティ グループ: 可能であれば複雑な呼び出し階層を避ける
このグループを詳しく調べたところ、特定のコールチェーンが繰り返し呼び出されていることがわかりました。同じパターンがフレームグラフのさまざまな場所に 6 回出現し、このウィンドウの合計時間は約 2.4 秒でした。
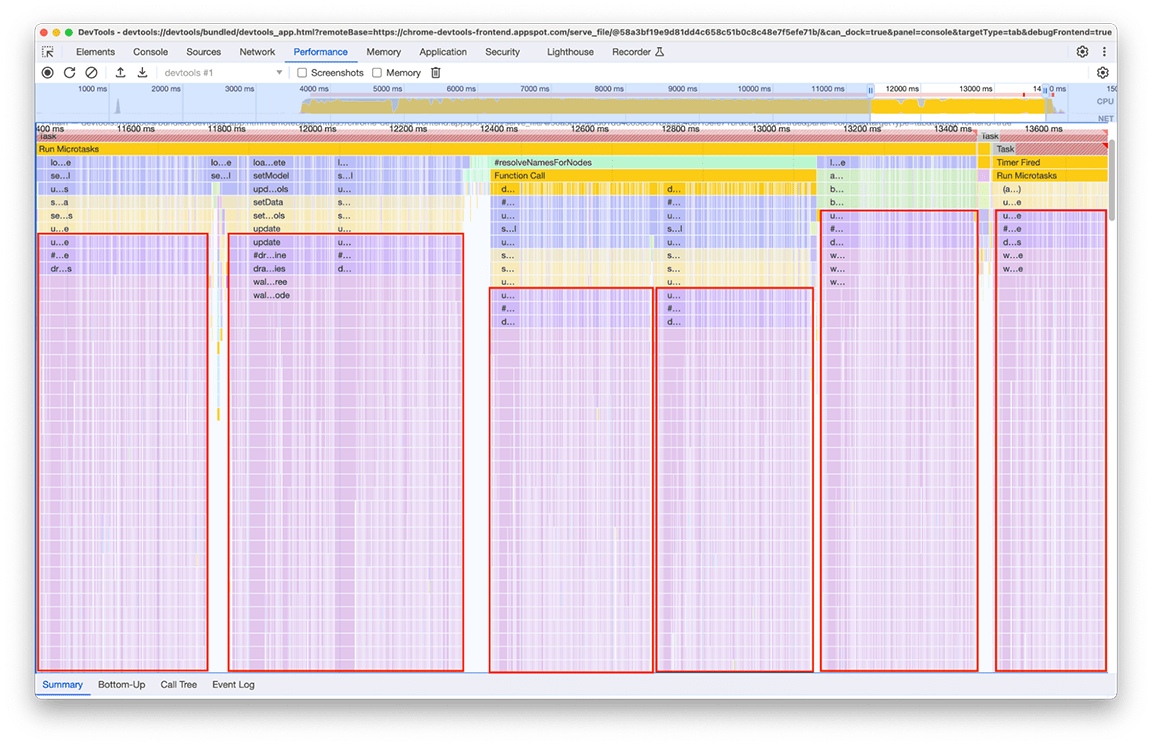
関連するコードが複数回呼び出されているのは、「ミニマップ」(パネル上部のタイムライン アクティビティの概要)にレンダリングされるデータを処理する部分です。なぜ何度も発生するのかは不明でしたが、6 回も発生する必要はなかったはずです。実際、他のプロファイルが読み込まれていない場合、コードの出力は最新の状態を維持する必要があります。理論上、コードは 1 回だけ実行されるはずです。
調査の結果、読み込みパイプラインの複数の部分がミニマップを計算する関数を直接または間接的に呼び出した結果、関連するコードが呼び出されたことが判明しました。これは、プログラムの呼び出しグラフの複雑さが時間の経過とともに増大し、このコードへの依存関係が知らず知らずのうちに追加されたためです。この問題の迅速な解決策はありません。解決方法は、問題のコードベースのアーキテクチャによって異なります。このケースでは、呼び出し階層の複雑さを少し軽減し、入力データが変更されていない場合にコードの実行を防止するチェックを追加する必要がありました。これを実装すると、タイムラインは次のようになります。
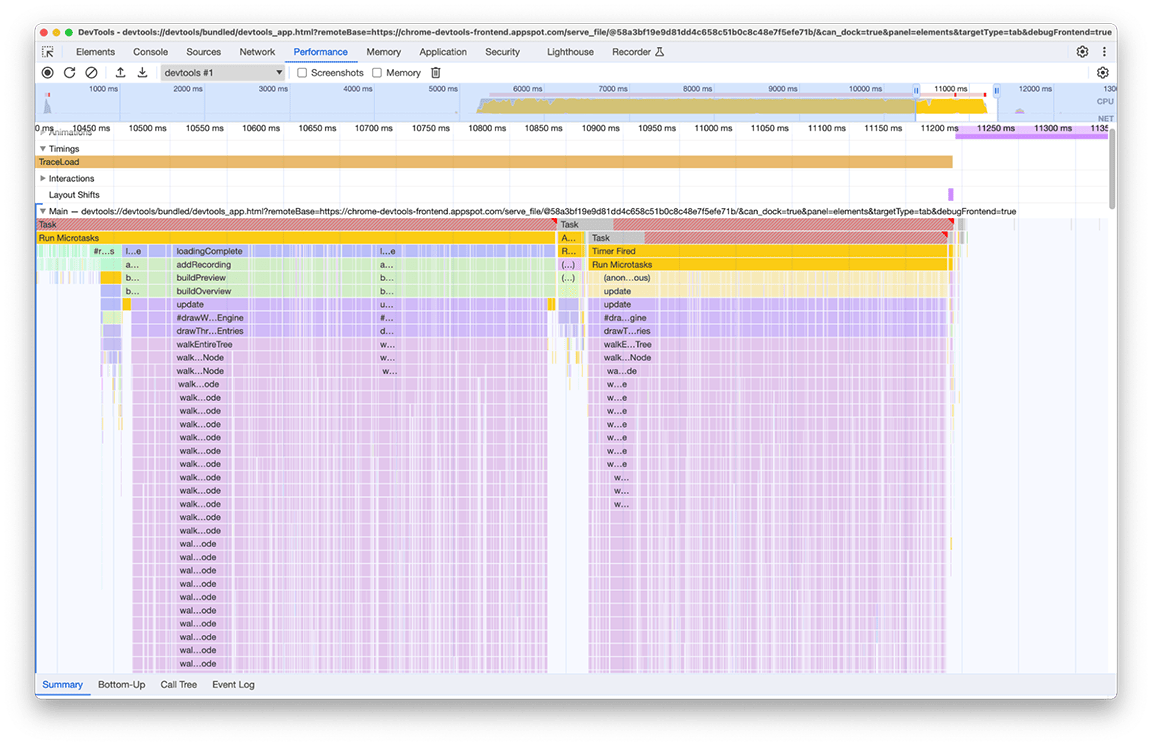
ミニマップのレンダリングの実行は 1 回ではなく 2 回行われます。これは、すべてのプロファイルに対して 2 つのミニマップが描画されるためです。1 つはパネルの上部の概要用、もう 1 つは履歴から現在表示されているプロファイルを選択するプルダウン メニュー用です(このメニューの各項目には、選択するプロファイルの概要が含まれています)。ただし、この 2 つはまったく同じコンテンツであるため、一方を他方で再利用できるはずです。
これらのミニマップはどちらもキャンバスに描画された画像であるため、drawImage キャンバス ユーティリティを使用し、その後コードを 1 回だけ実行して時間を節約しました。この取り組みの結果、グループの所要時間は 2.4 秒から 140 ミリ秒に短縮されました。
まとめ
これらの修正(およびその他の小さな修正)をすべて適用した後、プロファイルの読み込みタイムラインの変更は次のようになりました。
変換前:
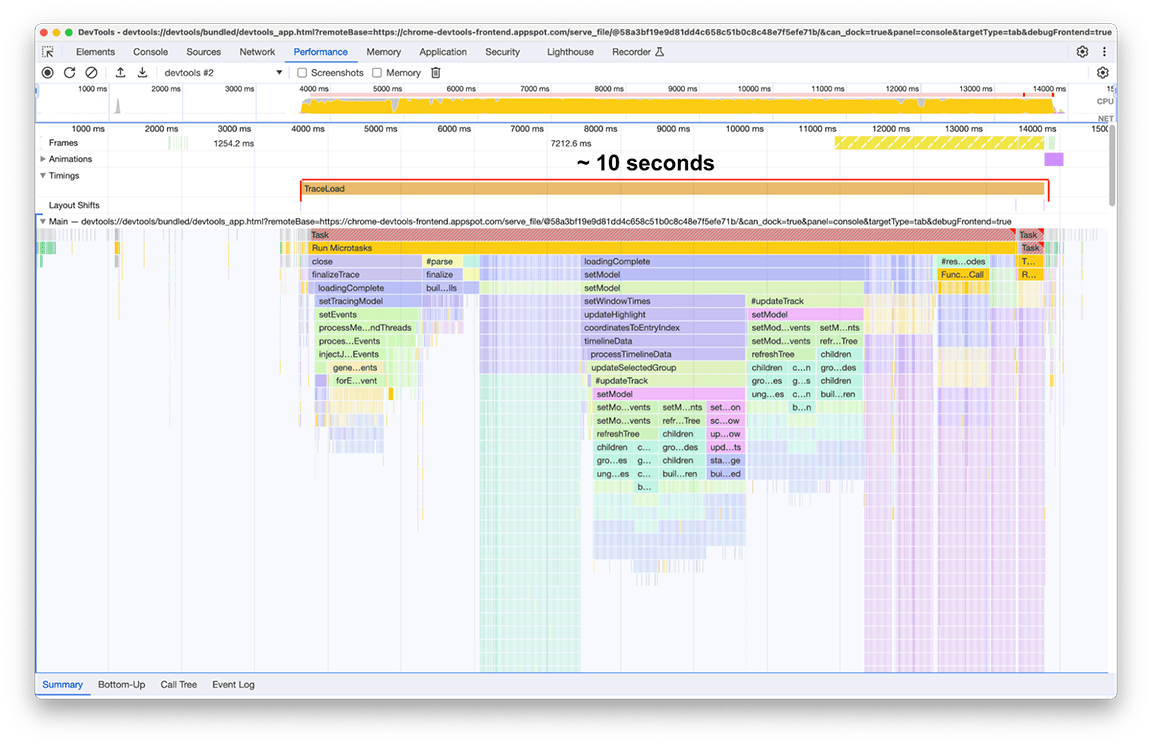
変換後:
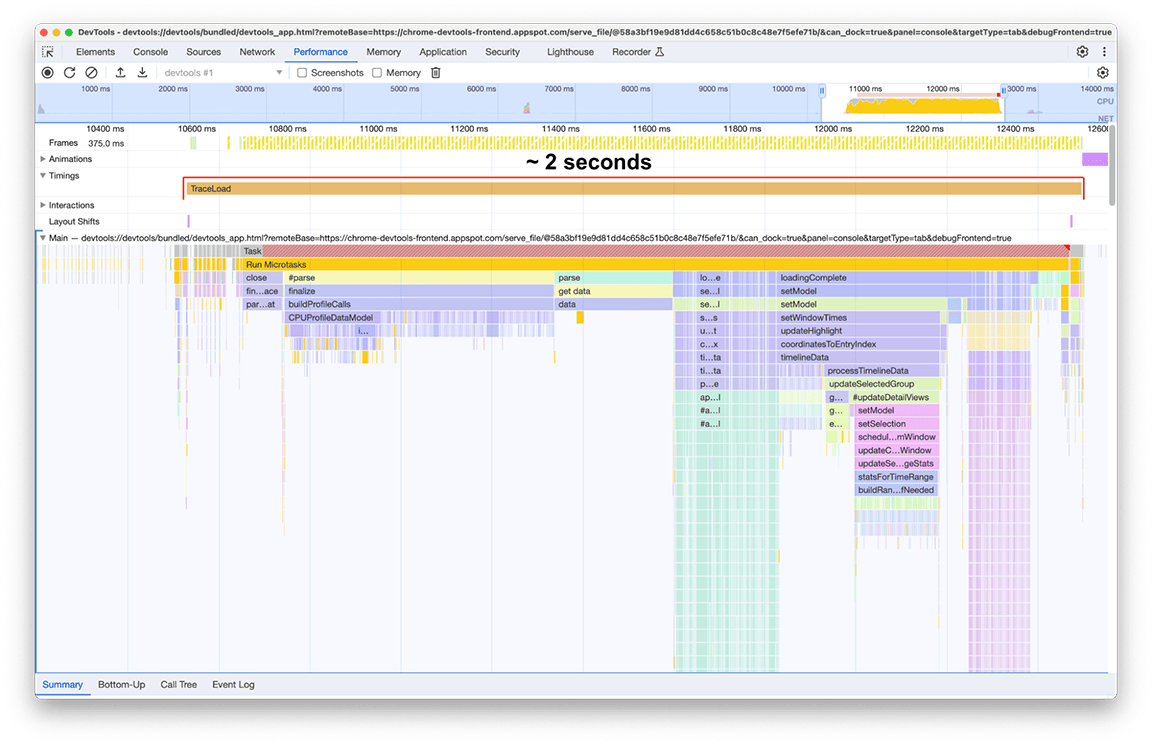
改善後の読み込み時間は 2 秒でした。これは、ほとんどが簡単な修正で済んだため、比較的少ない労力で約 80%の改善を達成できたことを意味します。もちろん、最初に何をすべきかを正しく特定することが重要であり、パフォーマンス パネルはそのための適切なツールでした。
また、これらの数値は、調査の対象として使用されているプロファイルに固有のものであることも強調しておく必要があります。このプロファイルは特に大きかったため、興味深いものでした。ただし、処理パイプラインはすべてのプロファイルで同じであるため、達成された大幅な改善は、パフォーマンス パネルに読み込まれたすべてのプロファイルに適用されます。
要点
これらの結果から、アプリケーションのパフォーマンス最適化に関して次の教訓が得られます。
1. プロファイリング ツールを使用してランタイム パフォーマンス パターンを特定する
プロファイリング ツールは、実行中のアプリケーションで何が起こっているかを把握するうえで非常に便利です。特に、パフォーマンスを改善できる箇所を特定するのに役立ちます。Chrome DevTools のパフォーマンス パネルは、ブラウザのネイティブ ウェブ プロファイリング ツールであり、最新のウェブ プラットフォーム機能に対応するように積極的にメンテナンスされているため、ウェブ アプリケーションに最適なオプションです。また、大幅に高速化されました。😉
代表的なワークロードとして使用できるサンプルを使用して、何が見つかるかを確認してください。
2. 複雑な呼び出し階層を避ける
可能な限り、コールグラフが複雑になりすぎないようにしてください。複雑な呼び出し階層では、パフォーマンスの回帰が簡単に発生し、コードがどのように実行されているかを理解するのが難しく、改善を実装するのが困難になります。
3. 不要な作業を特定する
古いコードベースには、不要になったコードが含まれていることがよくあります。このケースでは、レガシー コードと不要なコードが読み込み時間の大部分を占めていました。削除するのが最も簡単な方法でした。
4. データ構造を適切に使用する
データ構造を使用してパフォーマンスを最適化しますが、どのデータ構造を使用するかを決定する際には、各データ構造の費用とトレードオフも理解してください。これは、データ構造自体の空間複雑性だけでなく、適用可能なオペレーションの時間複雑性も含まれます。
5. 結果をキャッシュに保存して、複雑なオペレーションや反復オペレーションの重複を回避する
実行にコストがかかるオペレーションの場合は、次回必要になったときに使用できるように結果を保存するのが妥当です。個々の処理のコストはそれほど高くなくても、処理が何度も実行される場合も、この方法が有効です。
6. 重要でない作業を遅延させる
タスクの出力がすぐに必要ではなく、タスクの実行がクリティカル パスを延長している場合は、出力が実際に必要になったときに遅延呼び出しすることで、タスクの実行を遅延させることを検討してください。
7. 大きな入力に対して効率的なアルゴリズムを使用する
入力が大きい場合は、最適な時間複雑性アルゴリズムが重要になります。この例ではこのカテゴリについては説明しませんでしたが、その重要性は言うまでもありません。
8. ボーナス: パイプラインのベンチマークを設定する
進化するコードの速度を維持するには、動作をモニタリングして標準と比較することをおすすめします。このようにして、回帰を事前に特定し、全体的な信頼性を高めることで、長期的な成功につながります。