


לא משנה איזה סוג אפליקציה אתם מפתחים, חשוב מאוד לבצע אופטימיזציה של הביצועים שלה, לוודא שהיא נטענת במהירות ומציעה אינטראקציות חלקות, כדי לשפר את חוויית המשתמש ולהבטיח את הצלחת האפליקציה. אחת הדרכים לעשות זאת היא לבדוק את הפעילות של אפליקציה באמצעות כלי פרופילים כדי לראות מה קורה מתחת לפני השטח בזמן שהיא פועלת במהלך חלון זמן. החלונית Performance בכלי הפיתוח היא כלי מצוין ליצירת פרופילים לצורך ניתוח ואופטימיזציה של הביצועים של אפליקציות אינטרנט. אם האפליקציה פועלת ב-Chrome, תקבלו סקירה כללית ויזואלית מפורטת של מה שהדפדפן עושה בזמן שהאפליקציה מופעלת. הבנת הפעילות הזו יכולה לעזור לכם לזהות דפוסים, צווארי בקבוק ונקודות חמות של ביצועים שתוכלו לפעול לגביהם כדי לשפר את הביצועים.
בדוגמה הבאה מוסבר איך להשתמש בחלונית ביצועים.
הגדרה ויצירה מחדש של תרחיש הפרופיל שלנו
לאחרונה הגדרנו מטרה לשפר את הביצועים של החלונית ביצועים. רצינו במיוחד שהיא תטען במהירות נפחים גדולים של נתוני ביצועים. זה קורה, למשל, כשיוצרים פרופיל של תהליכים מורכבים או של תהליכים שפועלים לאורך זמן, או כשמצלמים נתונים ברמת פירוט גבוהה. כדי להשיג את המטרה הזו, היה צריך קודם להבין איך האפליקציה פעלה ולמה היא פעלה בצורה הזו. לשם כך נעשה שימוש בכלי ליצירת פרופילים.
כפי שאתם יודעים, כלי הפיתוח עצמם הם אפליקציית אינטרנט. לכן, אפשר ליצור פרופיל באמצעות החלונית ביצועים. כדי ליצור פרופיל של החלונית הזו עצמה, אפשר לפתוח את כלי הפיתוח, ואז לפתוח עוד מופע של כלי הפיתוח שמצורף אליו. ב-Google, ההגדרה הזו נקראת כלי פיתוח בכלי פיתוח.
אחרי שההגדרה מוכנה, צריך ליצור מחדש את התרחיש שרוצים ליצור לו פרופיל ולתעד אותו. כדי למנוע בלבול, נתייחס לחלון המקורי של כלי הפיתוח כאל "מופע ראשון של כלי הפיתוח", ולחלון שבודק את המופע הראשון כאל "מופע שני של כלי הפיתוח".
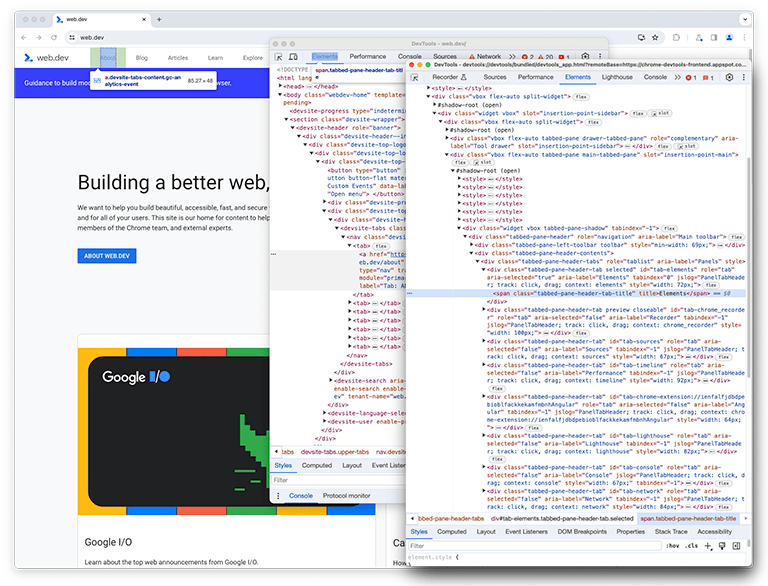
במופע השני של DevTools, החלונית Performance – שנקרא לה מכאן ואילך חלונית הביצועים – מתבוננת במופע הראשון של DevTools כדי ליצור מחדש את התרחיש, שבו נטען פרופיל.
במופע השני של כלי הפיתוח מתחילה הקלטה בזמן אמת, ובמופע הראשון נטען פרופיל מקובץ בדיסק. קובץ גדול נטען כדי ליצור פרופיל מדויק של ביצועי העיבוד של קלטים גדולים. כששני המקרים מסיימים להיטען, נתוני פרופיל הביצועים – שנקראים בדרך כלל trace – מוצגים במופע השני של כלי הפיתוח של חלונית הביצועים שבה נטען פרופיל.
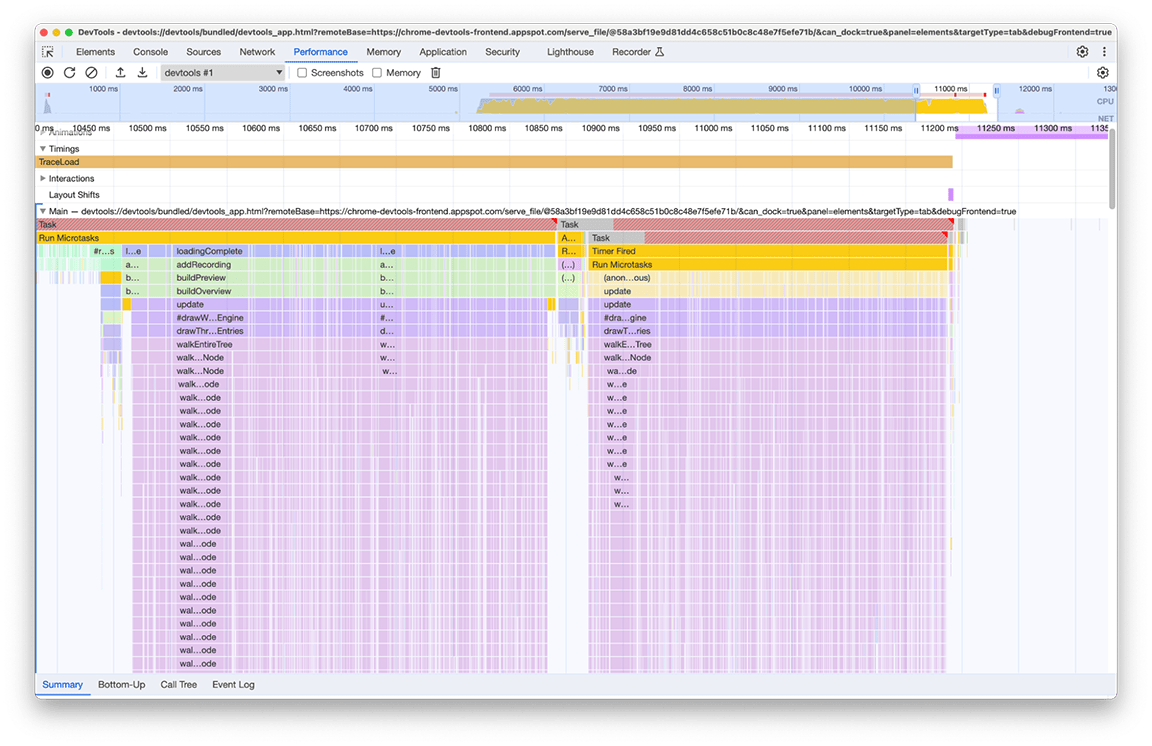
המצב ההתחלתי: זיהוי הזדמנויות לשיפור
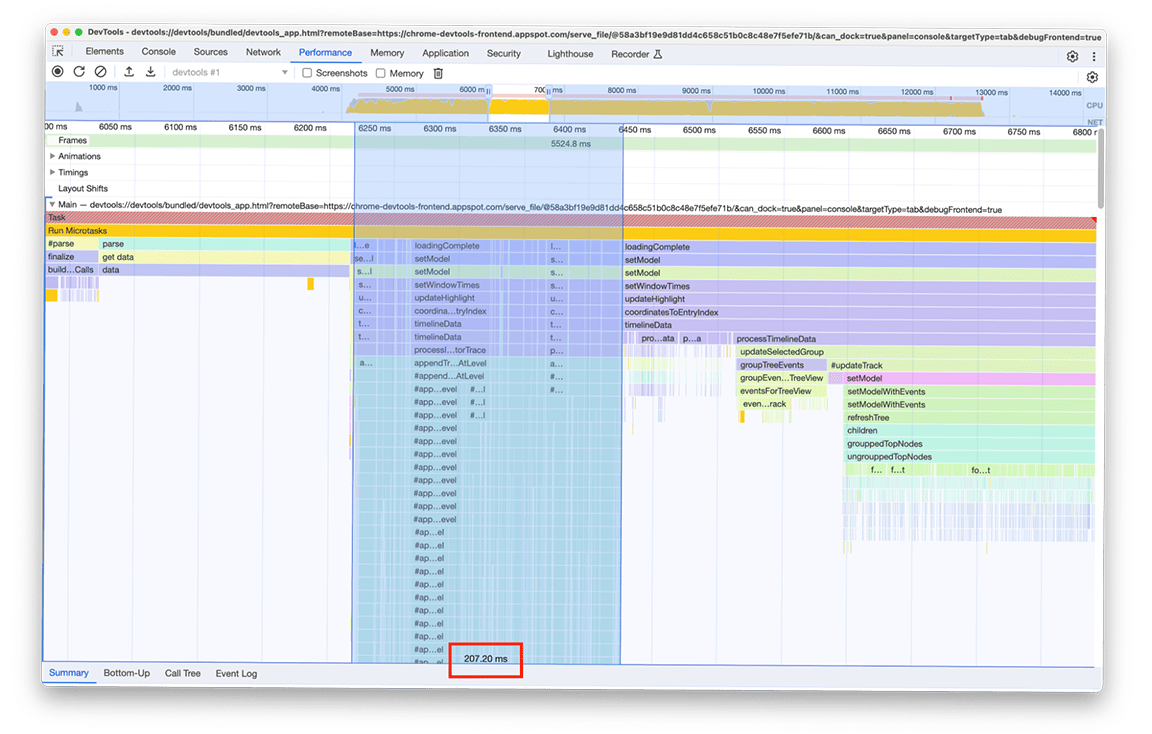
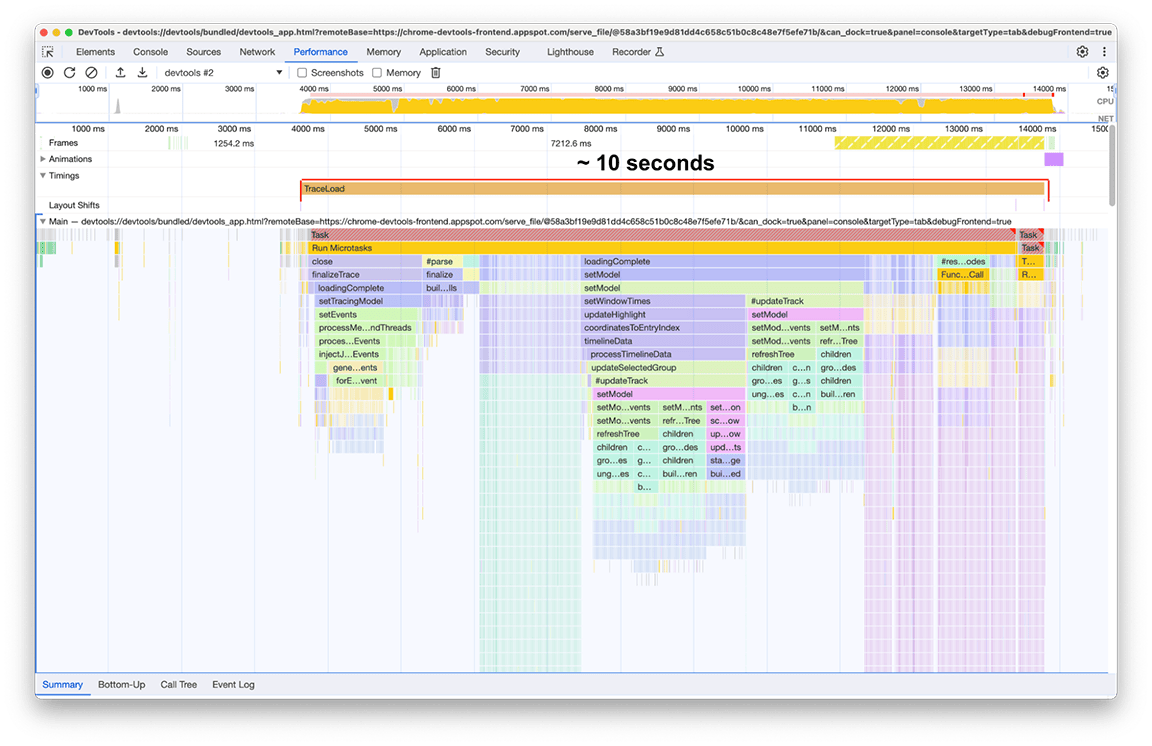
אחרי שהטעינה הסתיימה, אפשר לראות בצילום המסך הבא את מה שנצפה במופע השני של חלונית הביצועים. מתמקדים בפעילות של השרשור הראשי, שמופיעה מתחת לטראק עם התווית Main (ראשי). אפשר לראות בתרשים הלהבות חמש קבוצות גדולות של פעילות. הן כוללות את המשימות שבהן הטעינה אורכת הכי הרבה זמן. הזמן הכולל של המשימות האלה היה בערך 10 שניות. בצילום המסך הבא, חלונית הביצועים משמשת להתמקדות בכל אחת מקבוצות הפעילות האלה כדי לראות מה אפשר למצוא.
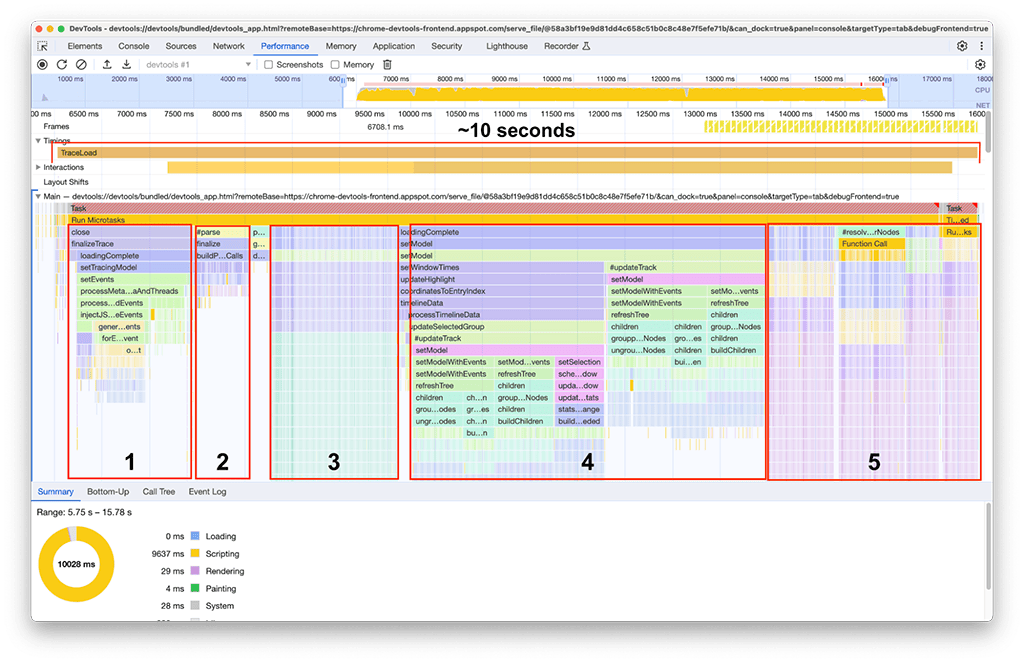
קבוצת הפעילות הראשונה: עבודה מיותרת
התברר שהקבוצה הראשונה של הפעילות הייתה קוד מדור קודם שעדיין פעל, אבל לא היה בו צורך. בעצם, כל מה שמתחת לבלוק הירוק עם התווית processThreadEvents היה מאמץ מיותר. זה היה ניצחון מהיר. הסרת הקריאה לפונקציה חסכה בערך 1.5 שניות. מגניב!
קבוצת הפעילות השנייה
בקבוצת הפעילויות השנייה, הפתרון לא היה פשוט כמו בקבוצה הראשונה. הפעולה buildProfileCalls נמשכה כ-0.5 שניות, ואי אפשר היה להימנע מהמשימה הזו.
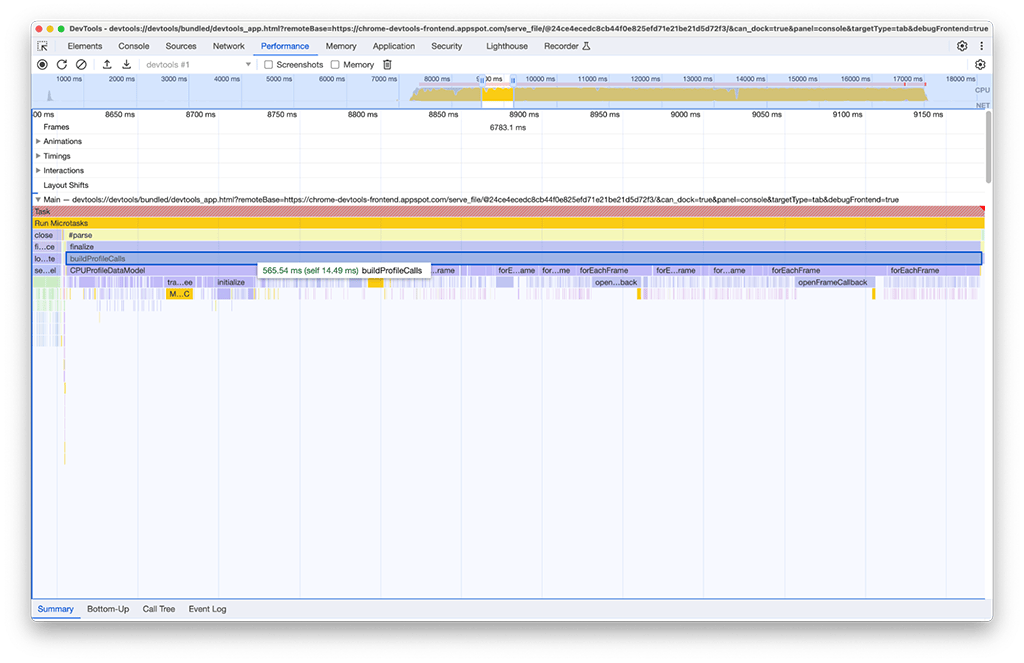
מתוך סקרנות, הפעלנו את האפשרות זיכרון בחלונית הביצועים כדי לחקור את הנושא לעומק, וראינו שגם הפעילות של buildProfileCalls השתמשה בהרבה זיכרון. בתרשים הקו הכחול אפשר לראות קפיצות פתאומיות בזמן ההרצה של buildProfileCalls, מה שמצביע על דליפת זיכרון פוטנציאלית.
כדי לבדוק את החשד הזה, השתמשנו בחלונית Memory (חלונית נוספת ב-DevTools, שונה מהחלונית Memory במגירת perf) כדי לבצע בדיקה. בתוך חלונית הזיכרון, נבחר סוג הפרופיל 'דגימת הקצאה', שתעד את תמונת מצב הערימה לטעינת פרופיל המעבד בחלונית הביצועים.
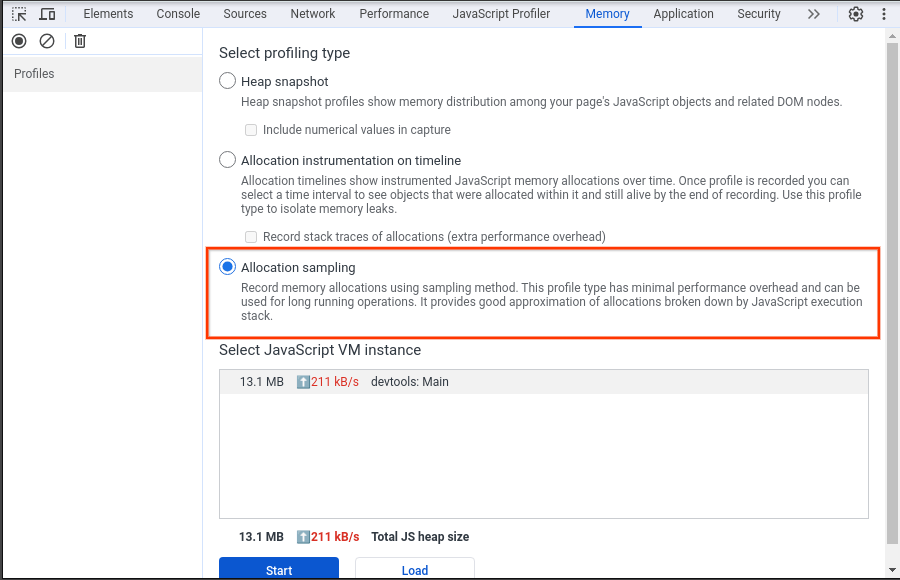
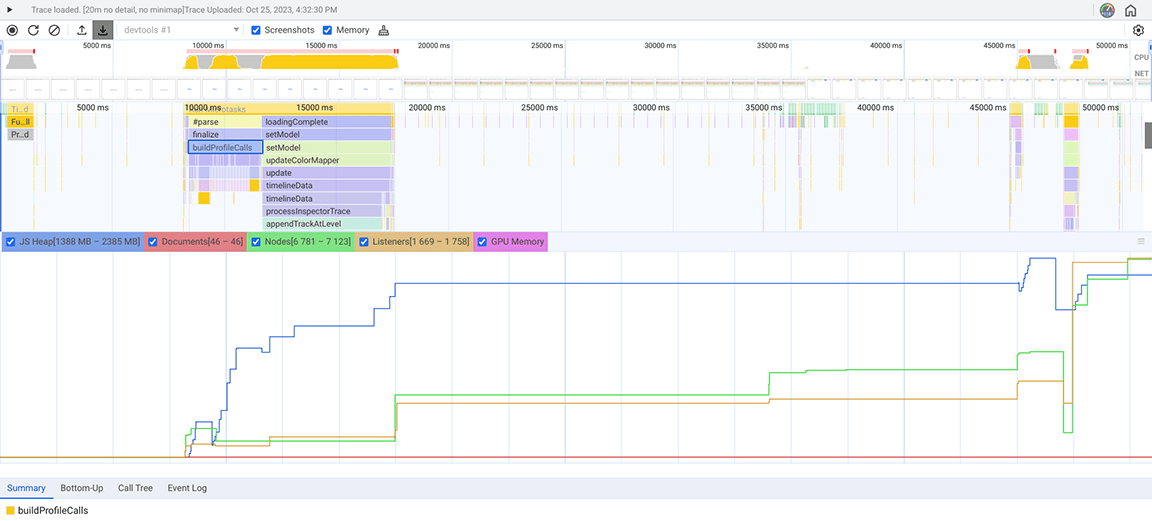
בצילום המסך הבא מוצג צילום מצב של הערימה שנאסף.
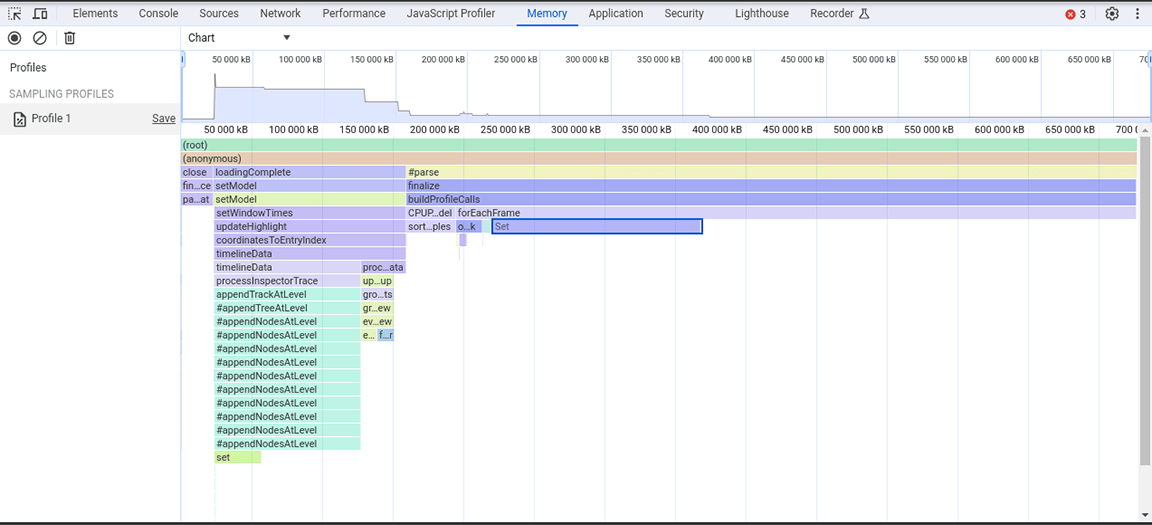
מצילום המצב של הערימה הזה, אפשר לראות שהמחלקה Set צורכת הרבה זיכרון. בבדיקה של נקודות הקריאה, גילינו שהקצנו שלא לצורך מאפיינים מהסוג Set לאובייקטים שנוצרו בכמויות גדולות. העלות הזו הצטברה והאפליקציה צרכה הרבה זיכרון, עד למצב שבו היא קרסה לעיתים קרובות כשקיבלה קלט גדול.
קבוצות שימושיות לאחסון פריטים ייחודיים, והן מספקות פעולות שמתבססות על הייחודיות של התוכן שלהן, כמו ביטול כפילויות במערכי נתונים וביצוע חיפושים יעילים יותר. עם זאת, התכונות האלה לא היו נחוצות כי הנתונים שאוחסנו היו ייחודיים בהשוואה למקור. לכן, לא היה צורך להגדיר סטים מלכתחילה. כדי לשפר את הקצאת הזיכרון, סוג הנכס השתנה מ-Set למערך פשוט. אחרי שהשינוי הזה הוחל, צולמה תמונת מצב נוספת של הערימה, ונצפתה הקצאת זיכרון מופחתת. למרות שהשינוי הזה לא הביא לשיפורים משמעותיים במהירות, היתרון המשני היה שהאפליקציה קרסה בתדירות נמוכה יותר.
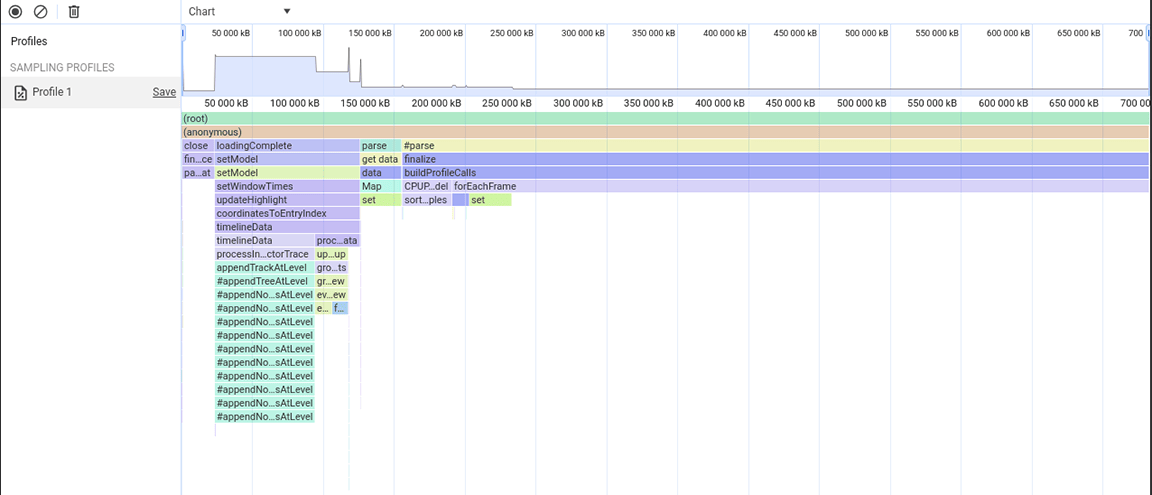
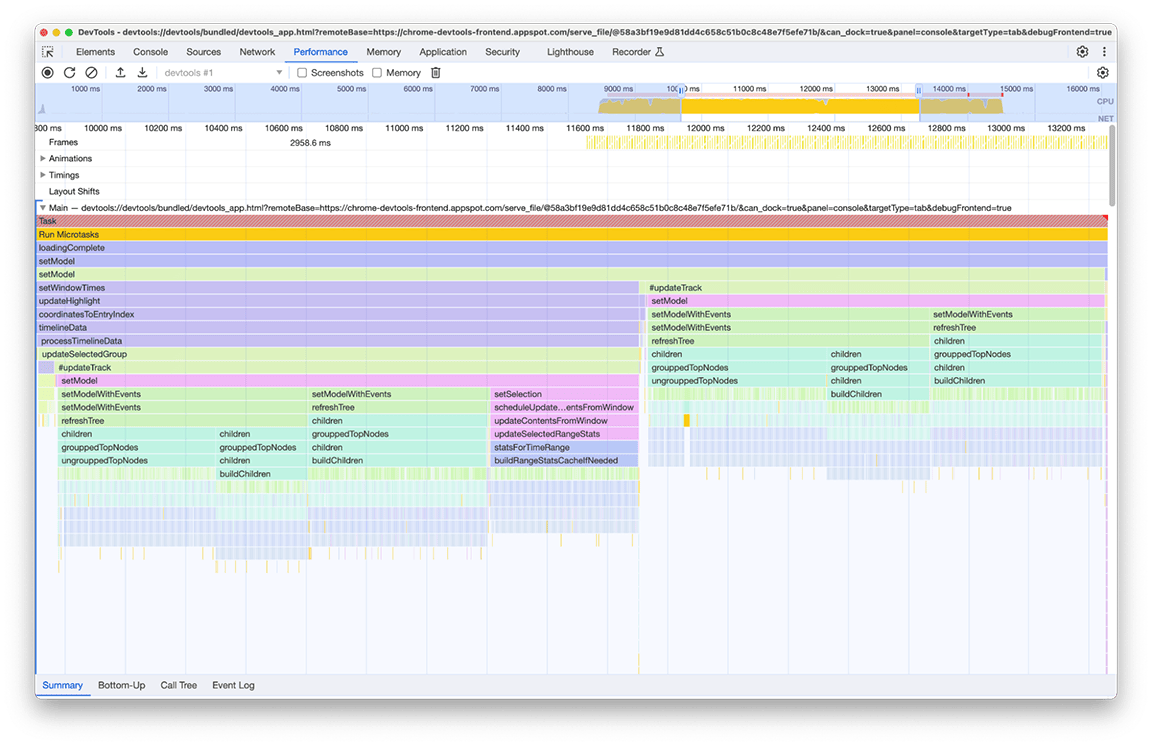
קבוצת הפעילות השלישית: שקילת היתרונות והחסרונות של מבנה הנתונים
החלק השלישי הוא יוצא דופן: אפשר לראות בתרשים הלהבות שהוא מורכב מעמודות צרות אבל גבוהות, שמציינות קריאות עמוקות לפונקציות, ובמקרה הזה גם רקורסיות עמוקות. בסך הכול, הקטע הזה נמשך כ-1.4 שניות. כשמסתכלים על החלק התחתון של הקטע הזה, אפשר לראות שהרוחב של העמודות האלה נקבע לפי משך הזמן של פונקציה אחת: appendEventAtLevel, מה שמצביע על כך שאולי מדובר בצוואר בקבוק
בתוך ההטמעה של הפונקציה appendEventAtLevel, דבר אחד בלט במיוחד. לכל רשומה של נתונים בקלט (שנקראת בקוד 'אירוע'), נוסף פריט למפה שעוקבת אחרי המיקום האנכי של הערכים בציר הזמן. הבעיה הייתה שכמות הפריטים שאוחסנו הייתה גדולה מאוד. מפות הן מהירות לחיפושים שמבוססים על מפתח, אבל היתרון הזה לא מגיע בחינם. ככל שהמפה גדלה, הוספת נתונים אליה יכולה להיות יקרה, למשל בגלל גיבוב מחדש. העלות הזו בולטת כשמוסיפים למפה כמויות גדולות של פריטים ברצף.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
ניסינו גישה אחרת שלא דרשה מאיתנו להוסיף פריט במפה לכל רשומה בתרשים הלהבות. השיפור היה משמעותי, וזה אישר שהצוואר בקבוק אכן קשור לתקורה שנוצרת כתוצאה מהוספת כל הנתונים למפה. הזמן שלקח לקבוצת הפעילויות הצטמצם מכ-1.4 שניות לכ-200 אלפיות השנייה.
לפני:
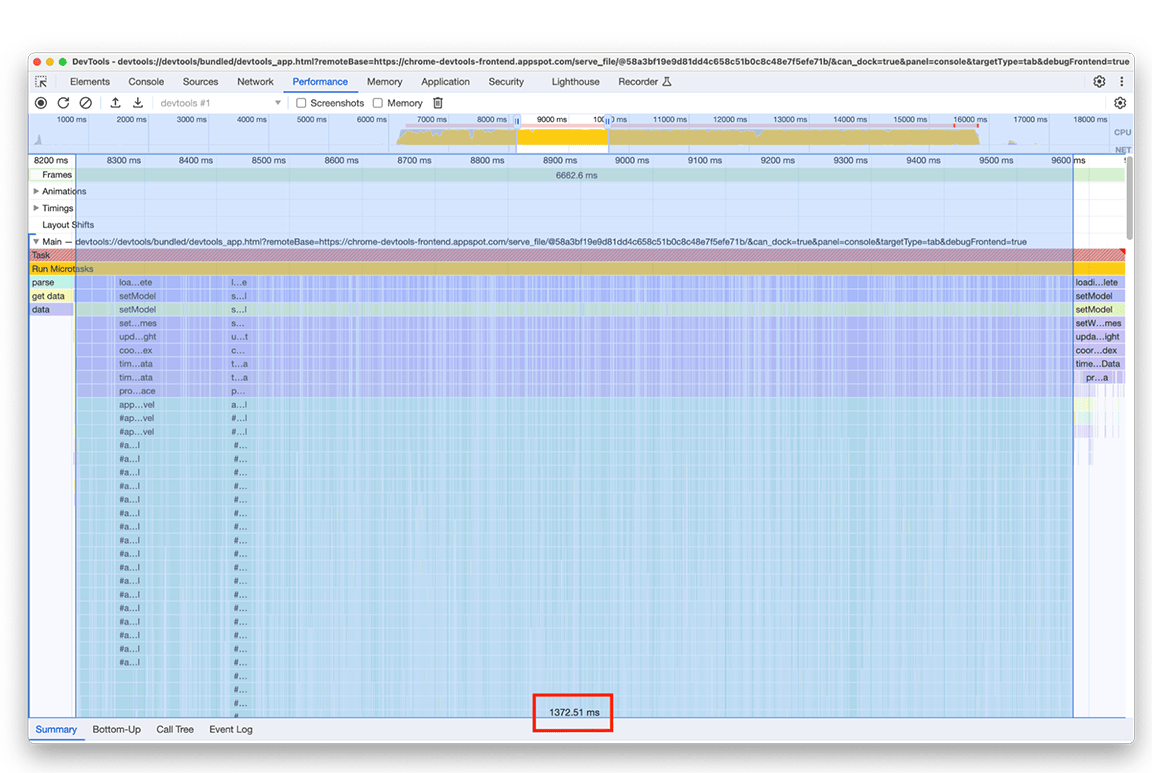
אחרי:
קבוצת הפעילות הרביעית: דחיית עבודה לא קריטית ונתוני מטמון כדי למנוע עבודה כפולה
אם נתמקד בחלון הזה, נוכל לראות שיש שני בלוקים כמעט זהים של קריאות לפונקציות. אם מסתכלים על השם של הפונקציות שמופעלות, אפשר להסיק שהבלוקים האלה מכילים קוד שיוצר עצים (לדוגמה, עם שמות כמו refreshTree או buildChildren). למעשה, הקוד שקשור לזה הוא הקוד שיוצר את תצוגות העץ במגירה התחתונה של החלונית. מה שמעניין הוא שתצוגות העץ האלה לא מוצגות מיד אחרי הטעינה. במקום זאת, המשתמש צריך לבחור תצוגת עץ (הכרטיסיות 'מלמטה למעלה', 'עץ שיחות' ו'יומן אירועים' במגירה) כדי שהעצים יוצגו. בנוסף, כפי שאפשר לראות בצילום המסך, תהליך בניית העץ בוצע פעמיים.
זיהינו שתי בעיות בתמונה הזו:
- משימה לא קריטית פגעה בביצועים של זמן הטעינה. המשתמשים לא תמיד צריכים את הפלט שלו. לכן, המשימה לא קריטית לטעינת הפרופיל.
- התוצאה של המשימות האלה לא נשמרה במטמון. לכן העצים חושבו פעמיים, למרות שהנתונים לא השתנו.
התחלנו לדחות את חישוב העץ עד שהמשתמש פותח ידנית את תצוגת העץ. רק אז כדאי לשלם את המחיר של יצירת העצים האלה. הזמן הכולל של הפעלת הפונקציה הזו פעמיים היה בערך 3.4 שניות, כך שהדחייה שלה יצרה הבדל משמעותי בזמן הטעינה. אנחנו עדיין בודקים אפשרות לשמירת משימות מהסוג הזה במטמון.
קבוצת הפעילות החמישית: כדאי להימנע מהיררכיות מורכבות של שיחות כשאפשר
בבדיקה מדוקדקת של הקבוצה הזו, היה ברור ששרשרת קריאות מסוימת מופעלת שוב ושוב. אותו דפוס הופיע 6 פעמים במקומות שונים בתרשים הלהבה, והמשך הכולל של החלון הזה היה בערך 2.4 שניות.
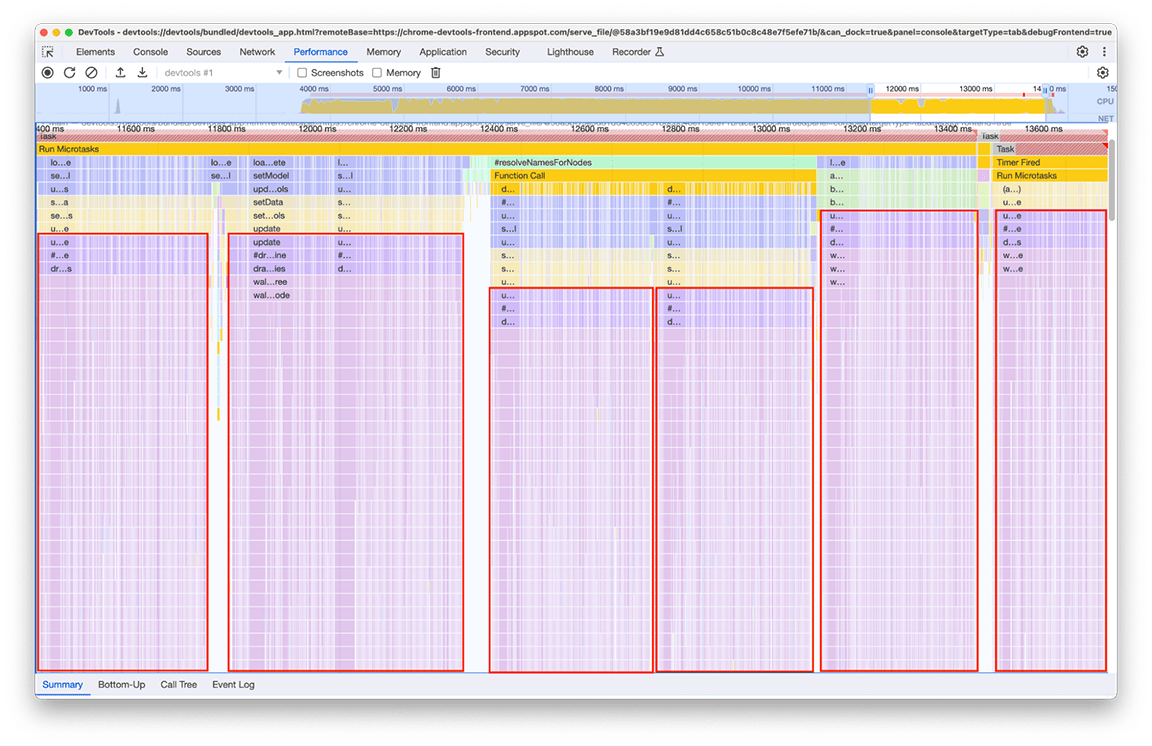
הקוד שקשור לזה ומופעל כמה פעמים הוא החלק שמבצע את עיבוד הנתונים כדי להציג אותם ב'מפה המינימלית' (סקירה כללית של הפעילות בציר הזמן בחלק העליון של החלונית). לא היה ברור למה זה קורה כמה פעמים, אבל ברור שזה לא צריך לקרות 6 פעמים! למעשה, הפלט של הקוד צריך להישאר עדכני אם לא נטען פרופיל אחר. באופן תיאורטי, הקוד אמור לפעול רק פעם אחת.
במהלך הבדיקה התגלה שהקוד שקשור לבעיה הופעל כתוצאה מכך שחלקים שונים בצינור הטעינה הפעילו באופן ישיר או עקיף את הפונקציה שמחשבת את המפה הממוזערת. הסיבה לכך היא שמורכבות גרף הקריאות של התוכנית השתנתה עם הזמן, והתווספו עוד תלויות לקוד הזה בלי שהמשתמש ידע. אין פתרון מהיר לבעיה הזו. הדרך לפתור את הבעיה תלויה בארכיטקטורה של בסיס הקוד הרלוונטי. במקרה שלנו, היינו צריכים לצמצם קצת את המורכבות של היררכיית הקריאות ולהוסיף בדיקה כדי למנוע את ההרצה של הקוד אם נתוני הקלט לא השתנו. אחרי ההטמעה, ציר הזמן נראה כך:
שימו לב שהרנדור של המפה הקטנה מתבצע פעמיים, ולא פעם אחת. הסיבה לכך היא שמוצגות שתי מפות קטנות לכל פרופיל: אחת לסקירה הכללית בחלק העליון של החלונית, ואחת לתפריט הנפתח שבו בוחרים את הפרופיל שמוצג כרגע מתוך ההיסטוריה (כל פריט בתפריט הזה מכיל סקירה כללית של הפרופיל שנבחר). עם זאת, התוכן של שניהם זהה לחלוטין, ולכן אפשר להשתמש באחד מהם גם בשביל השני.
מכיוון ששתי המפות הממוזערות הן תמונות ששורטטו על בד ציור, השתמשנו בdrawImage כלי בד הציור, ואז הפעלנו את הקוד רק פעם אחת כדי לחסוך זמן. כתוצאה מהמאמץ הזה, משך הזמן של הקבוצה קוצר מ-2.4 שניות ל-140 אלפיות השנייה.
סיכום
אחרי שהחלנו את כל התיקונים האלה (ועוד כמה קטנים פה ושם), השינוי בציר הזמן של טעינת הפרופיל נראה כך:
לפני:
אחרי:
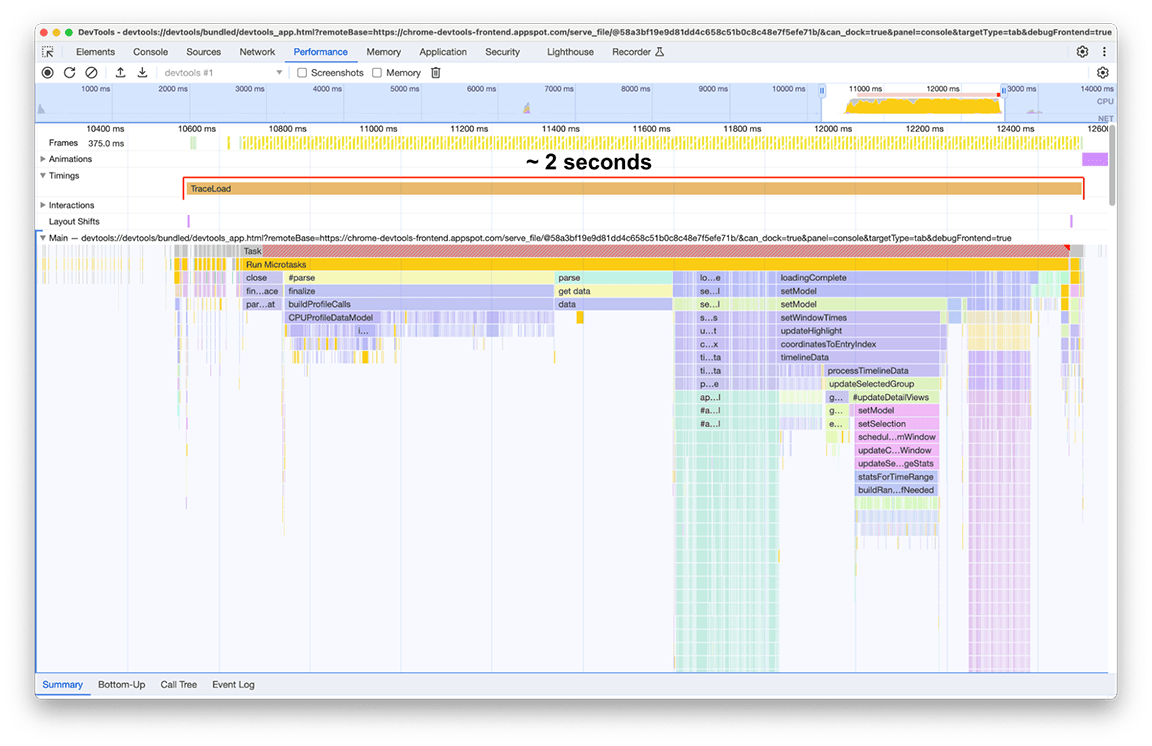
זמן הטעינה אחרי השיפורים היה 2 שניות, כלומר הושג שיפור של כ-80% במאמץ נמוך יחסית, כי רוב הפעולות שבוצעו היו תיקונים מהירים. כמובן, היה חשוב לזהות מה צריך לעשות בהתחלה, והחלונית 'ביצועים' הייתה הכלי המתאים לכך.
חשוב גם להדגיש שהמספרים האלה מתייחסים לפרופיל ספציפי שמשמש כנושא המחקר. הפרופיל עניין אותנו כי הוא היה גדול במיוחד. עם זאת, מכיוון שצינור העיבוד זהה לכל פרופיל, השיפור המשמעותי שהושג חל על כל פרופיל שנטען בחלונית הביצועים.
חטיפות דסקית
אפשר ללמוד מהתוצאות האלה כמה דברים על אופטימיזציה של הביצועים של האפליקציה:
1. שימוש בכלי פרופילים כדי לזהות דפוסי ביצוע בזמן ריצה
כלי פרופילים שימושיים מאוד להבנת מה שקורה באפליקציה בזמן שהיא פועלת, במיוחד לזיהוי הזדמנויות לשיפור הביצועים. החלונית Performance בכלי הפיתוח ל-Chrome היא אפשרות מצוינת לאפליקציות אינטרנט, כי זהו כלי פרופיל האינטרנט המקורי בדפדפן, והוא מתעדכן באופן פעיל כדי להתאים לתכונות העדכניות ביותר של פלטפורמת האינטרנט. בנוסף, עכשיו הוא מהיר משמעותית! 😉
אפשר להשתמש בדוגמאות שאפשר להשתמש בהן כעומסי עבודה מייצגים ולראות מה אפשר למצוא!
2. מומלץ להימנע מהיררכיות מורכבות של שיחות
אם אפשר, כדאי להימנע מגרף שיחות מורכב מדי. בהיררכיות מורכבות של קריאות, קל לגרום לירידה בביצועים וקשה להבין למה הקוד פועל כמו שהוא פועל, ולכן קשה לשפר את הביצועים.
3. זיהוי עבודה מיותרת
בדרך כלל, בבסיסי קוד ישנים יש קוד שכבר לא נחוץ. במקרה שלנו, קוד מדור קודם וקוד מיותר תפסו חלק משמעותי מזמן הטעינה הכולל. הסרת הקישור הייתה הפתרון הכי פשוט.
4. שימוש במבני נתונים בצורה מתאימה
כדאי להשתמש במבני נתונים כדי לשפר את הביצועים, אבל חשוב גם להבין את העלויות והפשרות שכל סוג של מבנה נתונים מביא איתו כשמחליטים באילו מבנים להשתמש. המורכבות הזו לא מתייחסת רק למורכבות המרחבית של מבנה הנתונים עצמו, אלא גם למורכבות הזמנית של הפעולות הרלוונטיות.
5. שמירת תוצאות במטמון כדי להימנע מעבודה כפולה בפעולות מורכבות או חוזרות
אם הפעולה יקרה לביצוע, כדאי לאחסן את התוצאות שלה כדי להשתמש בהן בפעם הבאה שצריך. כדאי לעשות את זה גם אם הפעולה מתבצעת הרבה פעמים, גם אם כל פעם בנפרד היא לא יקרה במיוחד.
6. דחיית עבודה לא קריטית
אם הפלט של משימה לא נדרש באופן מיידי והביצוע של המשימה מאריך את הנתיב הקריטי, כדאי לדחות את הביצוע שלה על ידי קריאה עצלה שלה כשהפלט שלה נדרש בפועל.
7. שימוש באלגוריתמים יעילים בקלט גדול
במקרים של קלט גדול, אלגוריתמים עם מורכבות זמן אופטימלית הופכים לחיוניים. בדוגמה הזו לא בדקנו את הקטגוריה הזו, אבל חשיבותה רבה מאוד.
8. בונוס: השוואת צינורות עיבוד נתונים
כדי לוודא שהקוד המתפתח שלכם יישאר מהיר, מומלץ לעקוב אחרי ההתנהגות שלו ולהשוות אותה לתקנים. כך תוכלו לזהות רגרסיות באופן פרואקטיבי ולשפר את האמינות הכוללת, ולהגדיל את הסיכויים להצלחה לטווח ארוך.