


Независимо от типа разрабатываемого приложения, оптимизация его производительности, быстрая загрузка и плавное взаимодействие критически важны для удобства пользователя и успешности приложения. Один из способов сделать это — исследовать активность приложения с помощью инструментов профилирования, чтобы увидеть, что происходит «под капотом» во время его работы в течение определённого временного окна. Панель « Производительность» в DevTools — отличный инструмент профилирования для анализа и оптимизации производительности веб-приложений. Если ваше приложение работает в Chrome, она предоставляет подробный визуальный обзор действий браузера во время выполнения приложения. Понимание этой активности поможет вам выявить закономерности, узкие места и проблемные зоны производительности, которые можно устранить для повышения производительности.
Следующий пример демонстрирует использование панели «Производительность» .
Настройка и воссоздание нашего сценария профилирования
Недавно мы поставили перед собой цель повысить производительность панели «Производительность» . В частности, мы хотели, чтобы она быстрее загружала большие объёмы данных о производительности. Это актуально, например, при профилировании длительных или сложных процессов или сборе высокодетализированных данных. Для этого сначала требовалось понять, как работает приложение и почему оно работает именно так, что было достигнуто с помощью инструмента профилирования.
Как вы, возможно, знаете, DevTools — это веб-приложение. Поэтому его можно профилировать с помощью панели «Производительность» . Чтобы профилировать саму панель, откройте DevTools, а затем откройте другой экземпляр DevTools, подключенный к ней. В Google такая конфигурация называется DevTools-on-DevTools .
После завершения настройки необходимо заново создать и записать сценарий для профилирования. Во избежание путаницы исходное окно DevTools будет называться « первым экземпляром DevTools», а окно, проверяющее первый экземпляр, — « вторым экземпляром DevTools».
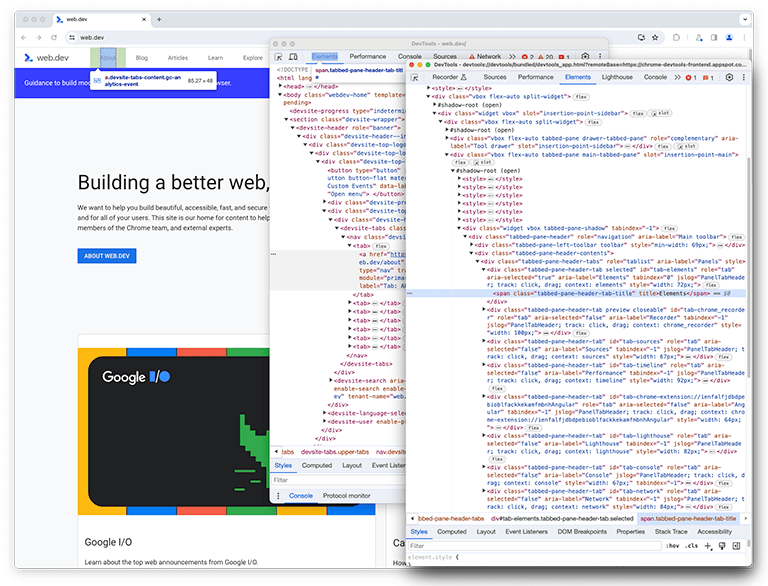
На втором экземпляре DevTools панель «Performance» (которая далее будет называться панелью perf ) наблюдает за первым экземпляром DevTools, чтобы заново создать сценарий, который загружает профиль.
Во втором экземпляре DevTools запускается запись в реальном времени, а в первом — загружается профиль из файла на диске. Для точного профилирования производительности обработки больших объёмов входных данных загружается большой файл. После завершения загрузки обоих экземпляров данные профилирования производительности, обычно называемые трассировкой , отображаются во втором экземпляре DevTools на панели производительности, загружающей профиль.
Исходное состояние: выявление возможностей для улучшения
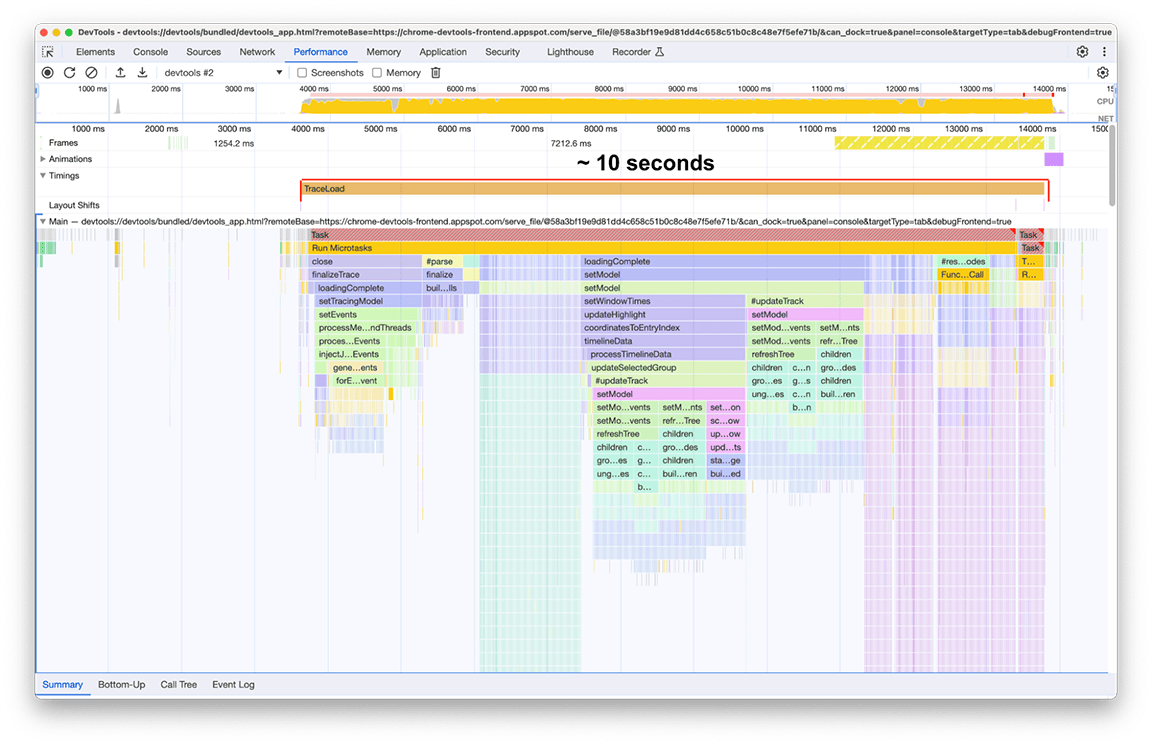
После завершения загрузки на нашем втором экземпляре панели производительности (см. следующий снимок экрана) наблюдалось следующее. Обратите внимание на активность основного потока, которая отображается под дорожкой с надписью Main . На диаграмме Flame Chart можно увидеть пять больших групп активности. Они состоят из задач, загрузка которых занимает больше всего времени. Общее время выполнения этих задач составило около 10 секунд . На следующем снимке экрана панель производительности используется для фокусировки на каждой из этих групп активности, чтобы увидеть, что можно найти.
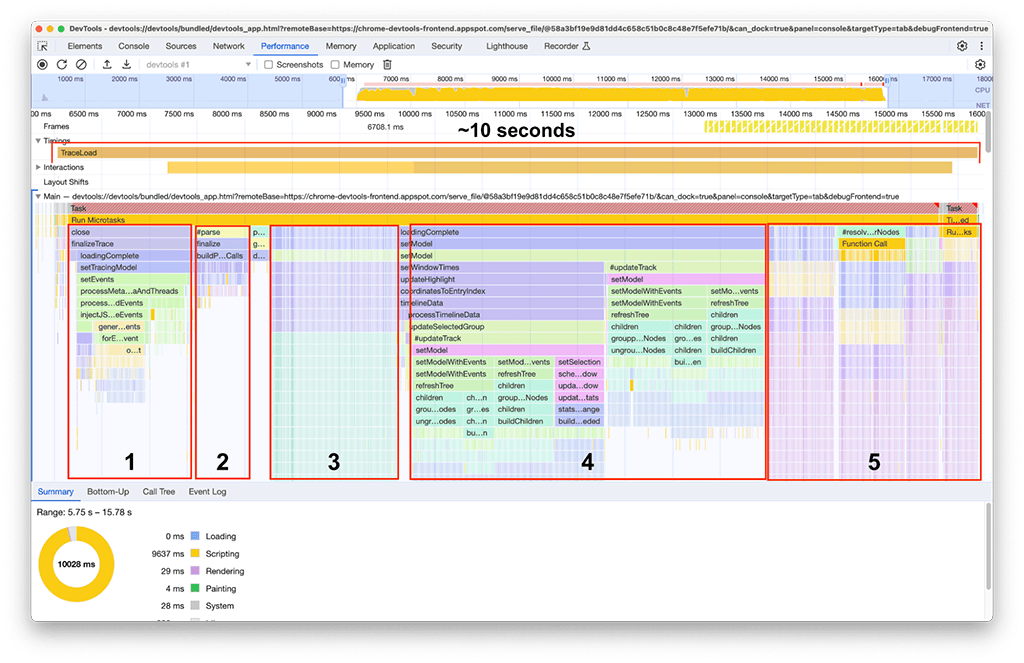
Первая группа занятий: ненужная работа
Стало очевидно, что первая группа активности представляла собой устаревший код, который всё ещё выполнялся, но был не особо нужен. По сути, всё, что находилось под зелёным блоком processThreadEvents , было потрачено впустую. Это стало быстрой победой. Удаление этого вызова функции сэкономило около 1,5 секунд. Круто!
Вторая группа активности
Во второй группе заданий решение оказалось не таким простым, как в первой. Вызов buildProfileCalls занял около 0,5 секунды, и избежать этой задачи было невозможно.
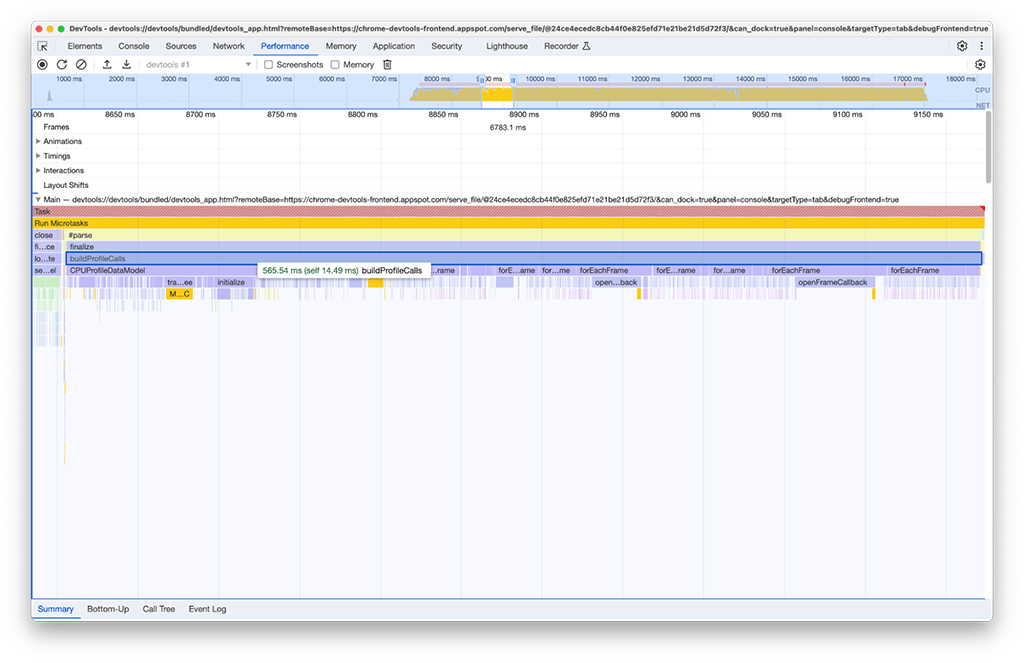
Из любопытства мы включили опцию «Память» на панели производительности для дальнейшего исследования и обнаружили, что функция buildProfileCalls также потребляла много памяти. Здесь видно, как синяя линия графика резко подпрыгивает примерно в момент запуска buildProfileCalls , что указывает на потенциальную утечку памяти.
Чтобы проверить это подозрение, мы воспользовались панелью «Память» (ещё одной панелью в DevTools, отличной от раздела «Память» на панели «Производительность»). На панели «Память» был выбран тип профилирования «Выборка распределения», который регистрировал снимок кучи для панели «Производительность», загружающей профиль ЦП.
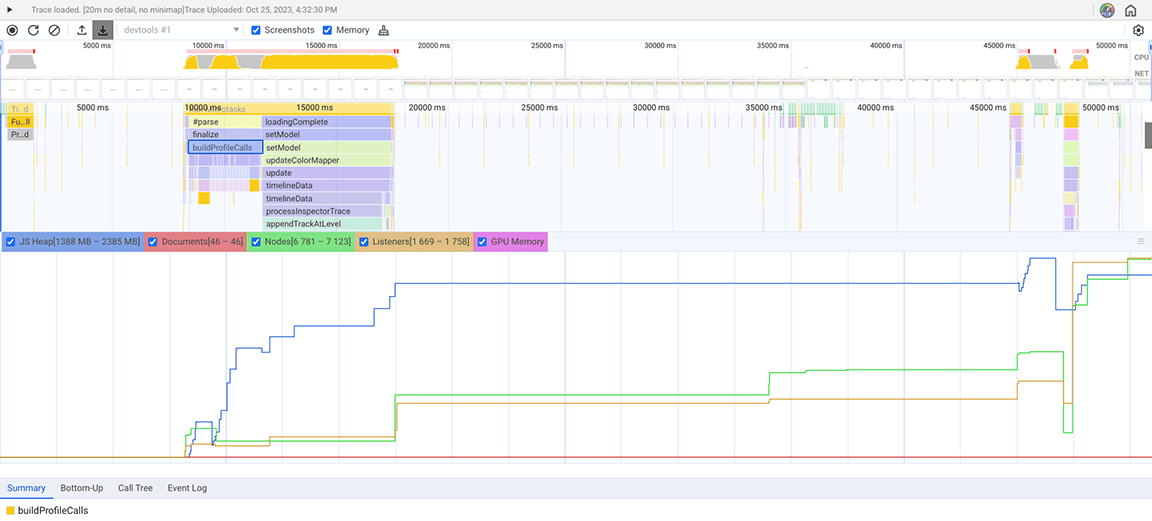
На следующем снимке экрана показан собранный снимок кучи.
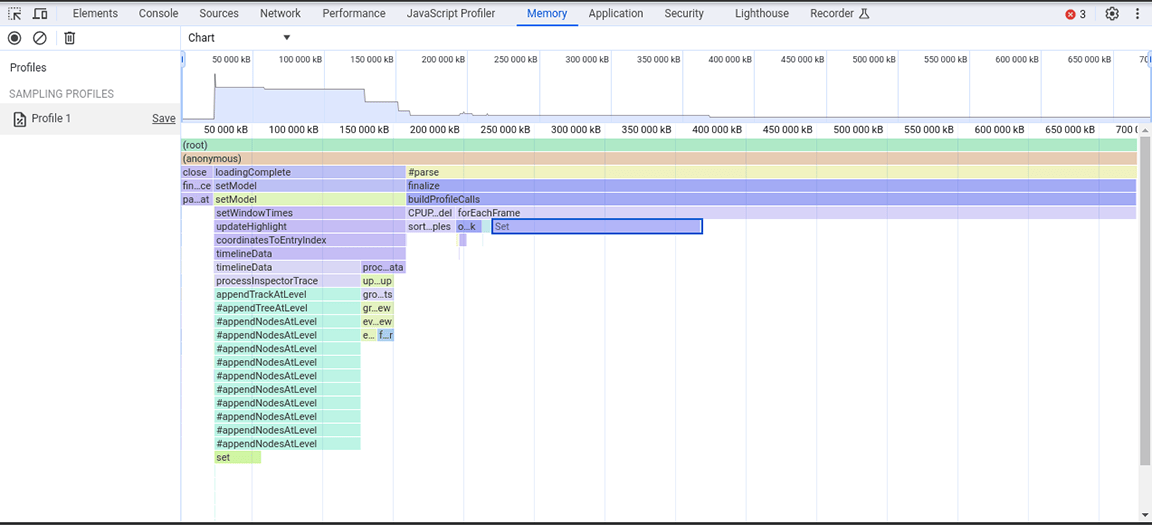
Из этого снимка кучи было видно, что класс Set потребляет большой объём памяти. Проверка точек вызова показала, что мы без необходимости присваивали свойства типа Set объектам, создаваемым в больших объёмах. Эти затраты накапливались, и потреблялся большой объём памяти, вплоть до того, что приложение часто аварийно завершало работу при больших объёмах входных данных.
Наборы полезны для хранения уникальных элементов и предоставляют операции, использующие уникальность их содержимого, такие как дедупликация наборов данных и повышение эффективности поиска. Однако эти функции не были необходимы, поскольку сохраняемые данные гарантированно были уникальными с самого источника. Таким образом, наборы изначально не были нужны. Для оптимизации распределения памяти тип свойства был изменён с Set на обычный массив. После применения этого изменения был сделан ещё один снимок кучи, и было отмечено уменьшение объёма выделяемой памяти. Несмотря на то, что это изменение не привело к значительному повышению скорости, дополнительным преимуществом стало снижение частоты сбоев приложения.
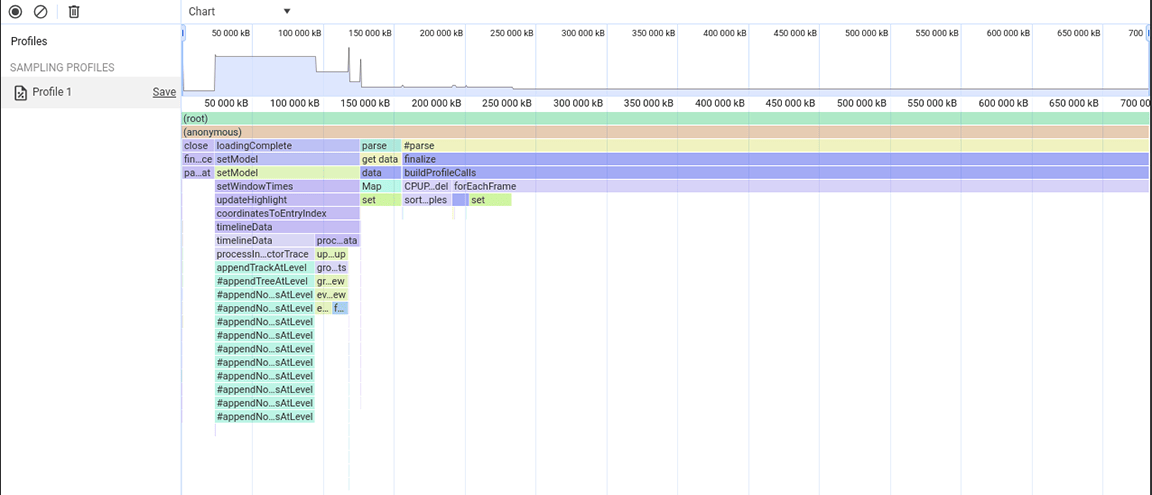
Третья группа действий: взвешивание компромиссов в отношении структуры данных
Третий раздел интересен: на диаграмме пламени видно, что он состоит из узких, но высоких столбцов, обозначающих глубокие вызовы функций, в данном случае — глубокие рекурсии. В общей сложности этот раздел длился около 1,4 секунды. Взглянув на нижнюю часть этого раздела, можно было заметить, что ширина этих столбцов определяется длительностью выполнения одной функции: appendEventAtLevel , что наводило на мысль, что это может быть узким местом.
В реализации функции appendEventAtLevel обращал на себя внимание один момент. Для каждого отдельного элемента данных во входных данных (который в коде называется «событием») добавлялся элемент на карту, которая отслеживала вертикальное положение элементов временной шкалы. Это создавало проблемы, поскольку объём хранимых элементов был очень большим. Карты быстро выполняют поиск по ключам, но это преимущество не даёт ничего хорошего. По мере роста карты добавление данных на неё может, например, стать дорогостоящим из-за повторного хеширования. Эти затраты становятся заметны, когда на карту последовательно добавляется большое количество элементов.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
Мы экспериментировали с другим подходом, не требующим добавления элемента на карту для каждой записи в диаграмме Flame Chart. Улучшение оказалось значительным, что подтвердило, что узкое место действительно было связано с накладными расходами, возникающими при добавлении всех данных на карту. Время, затрачиваемое группой активности, сократилось с примерно 1,4 секунды до примерно 200 миллисекунд.
До:
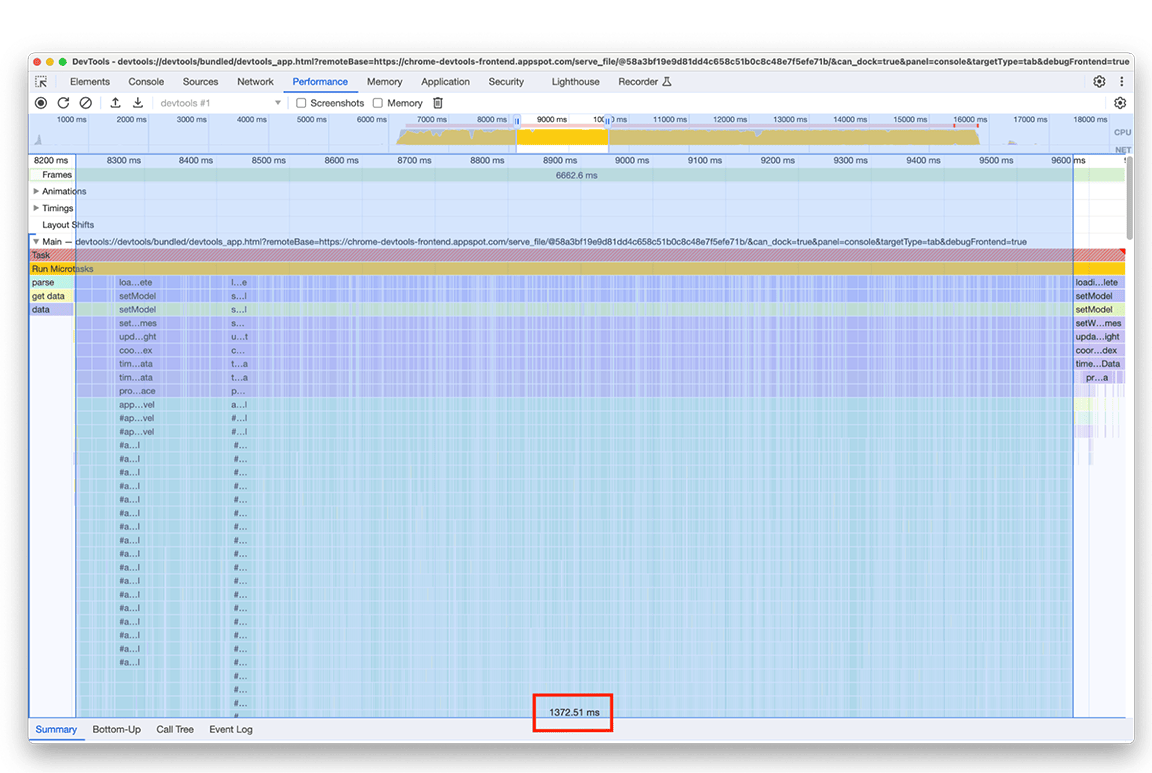
После:
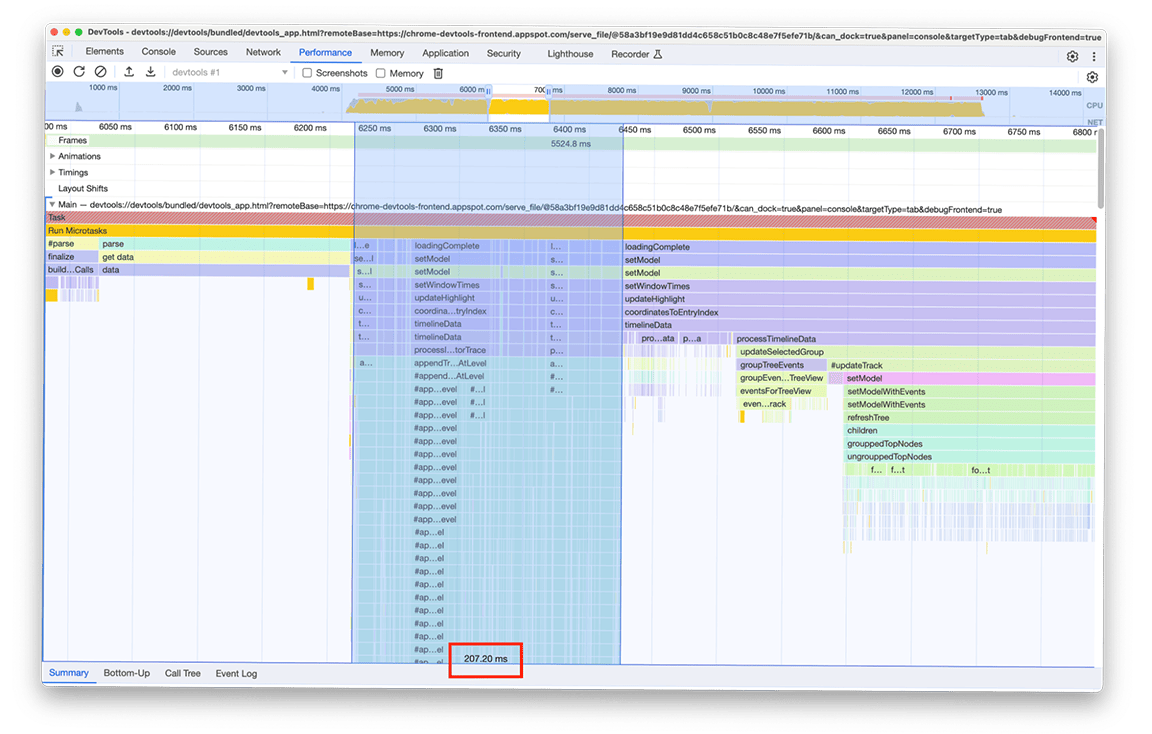
Четвертая группа действий: откладывание некритической работы и кэширование данных для предотвращения дублирования работы
Увеличивая масштаб этого окна, можно увидеть два практически идентичных блока вызовов функций. Судя по названиям вызываемых функций, можно сделать вывод, что эти блоки содержат код, строящий деревья (например, с именами refreshTree или buildChildren ). Фактически, соответствующий код создаёт древовидные представления в нижней части панели. Интересно, что эти древовидные представления отображаются не сразу после загрузки. Вместо этого пользователю необходимо выбрать древовидное представление (вкладки «Снизу вверх», «Дерево вызовов» и «Журнал событий» в нижней части панели), чтобы деревья отображались. Более того, как видно на снимке экрана, процесс построения дерева выполнялся дважды.
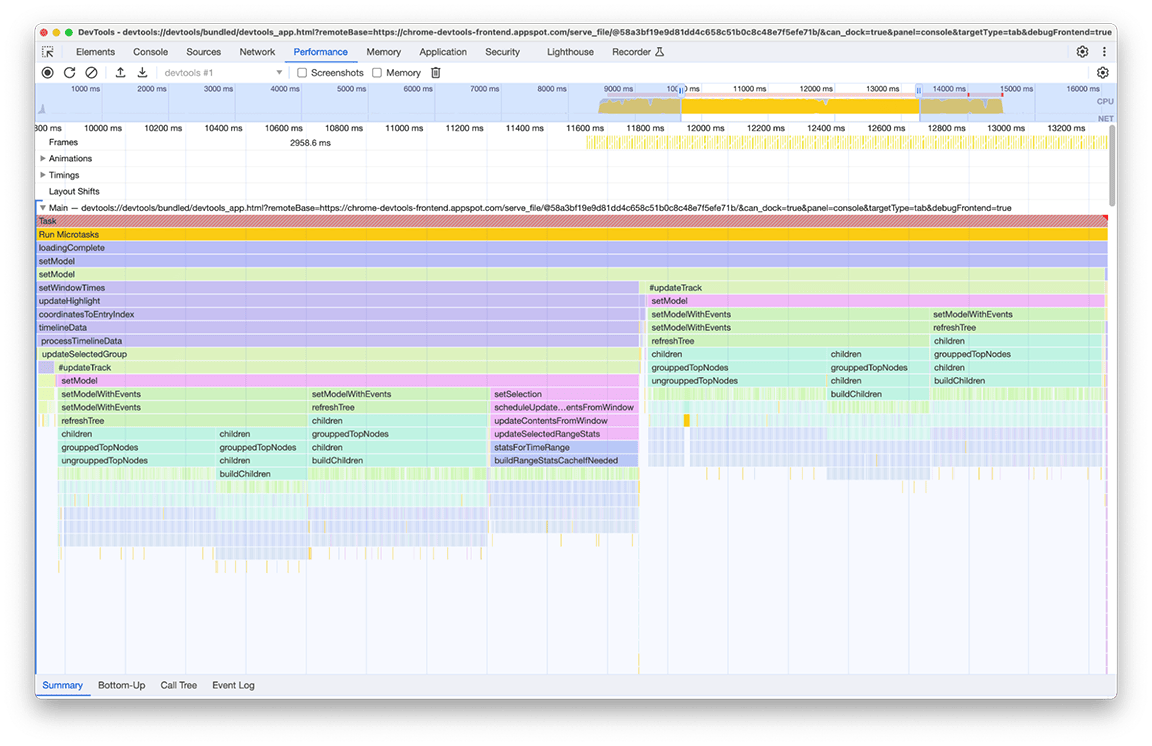
На этом снимке мы выявили две проблемы:
- Некритическая задача тормозила загрузку. Пользователям не всегда нужны её результаты. Таким образом, эта задача не является критичной для загрузки профиля.
- Результат этих задач не кэшировался. Поэтому деревья были рассчитаны дважды, несмотря на то, что данные не менялись.
Мы начали с отсрочки вычисления дерева до момента, когда пользователь вручную откроет его. Только тогда имеет смысл тратиться на создание этих деревьев. Общее время выполнения этого дважды составило около 3,4 секунды, поэтому отсрочка существенно повлияла на время загрузки. Мы всё ещё изучаем возможность кэширования таких задач.
Пятая группа действий: по возможности избегайте сложных иерархий вызовов
При внимательном рассмотрении этой группы стало ясно, что определённая цепочка вызовов повторяется многократно. Один и тот же шаблон повторялся 6 раз в разных местах диаграммы пламени, а общая продолжительность этого окна составила около 2,4 секунды!
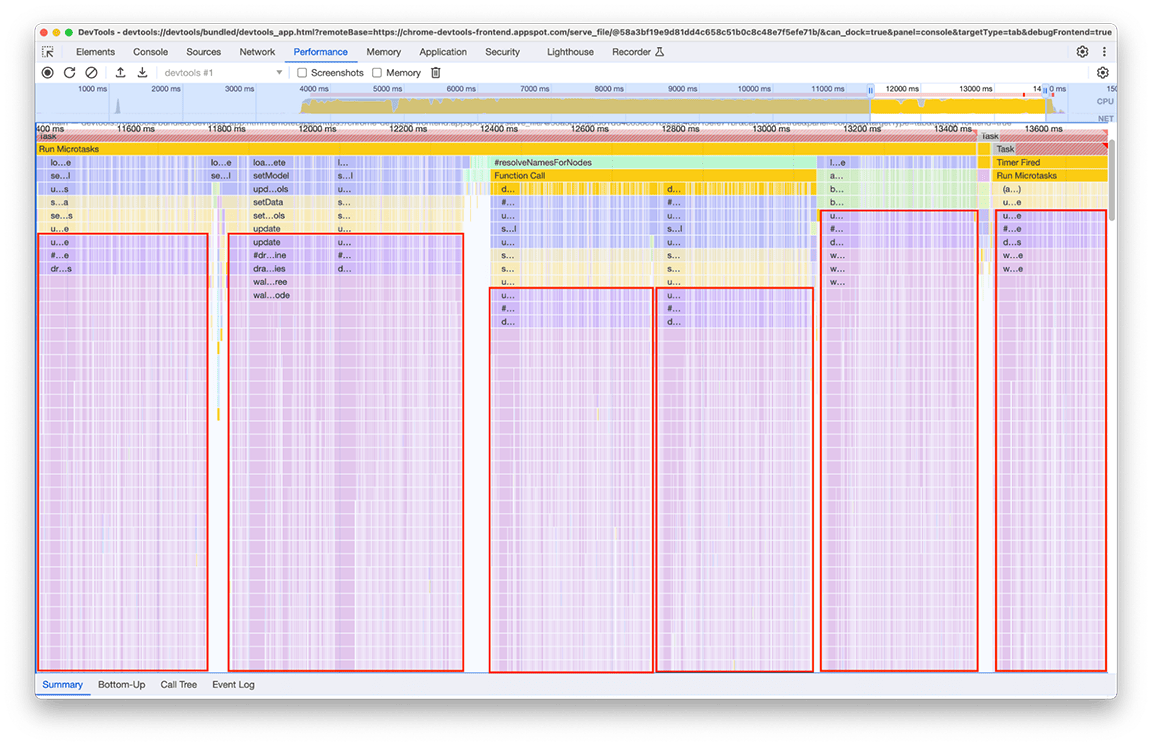
Связанный код, вызываемый несколько раз, обрабатывает данные для отображения на «миникарте» (обзоре активности временной шкалы в верхней части панели). Было непонятно, почему это происходит несколько раз, но это точно не обязательно должно было происходить 6 раз! Фактически, вывод кода должен оставаться актуальным, даже если не загружен другой профиль. Теоретически, код должен запускаться только один раз.
В ходе расследования было обнаружено, что связанный код был вызван в результате того, что несколько частей конвейера загрузки напрямую или косвенно вызывали функцию, вычисляющую мини-карту. Это связано с тем, что сложность графа вызовов программы со временем увеличивалась, и к этому коду непреднамеренно добавлялись новые зависимости. Быстрого решения этой проблемы не существует. Способ её решения зависит от архитектуры рассматриваемой кодовой базы. В нашем случае нам пришлось немного снизить сложность иерархии вызовов и добавить проверку, предотвращающую выполнение кода, если входные данные остались неизменными. После реализации этого мы получили следующий вид временной шкалы:
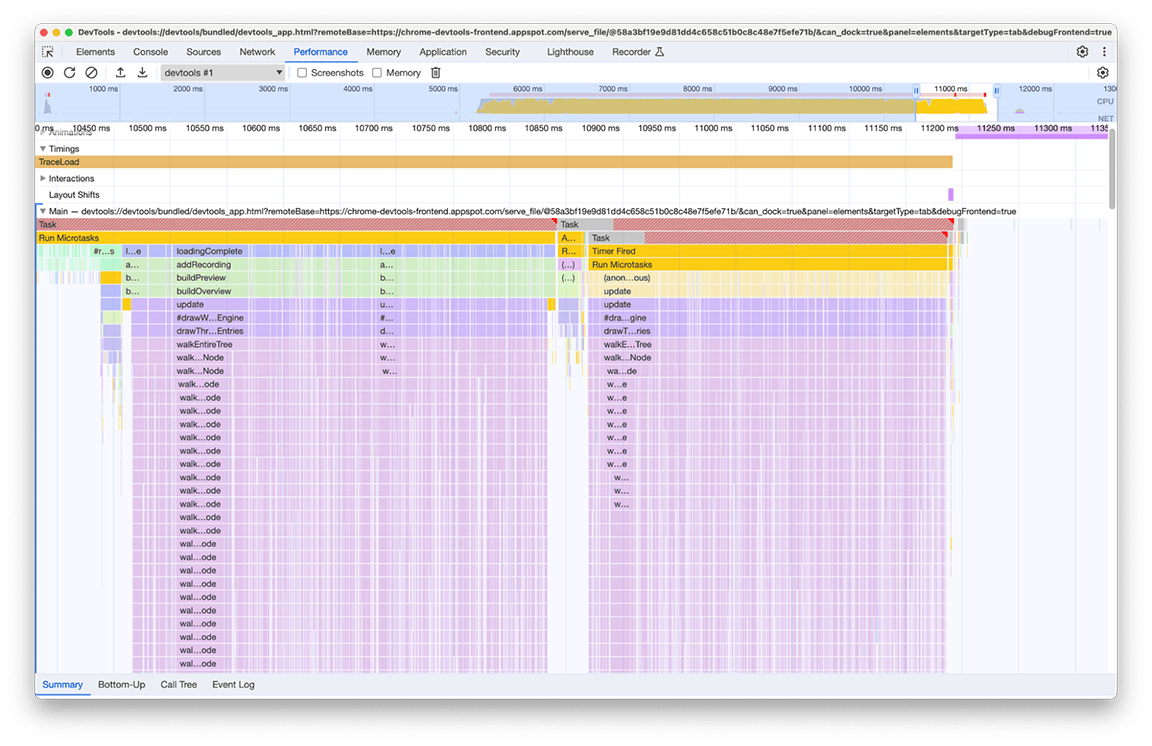
Обратите внимание, что отрисовка мини-карты выполняется дважды, а не один раз. Это связано с тем, что для каждого профиля отрисовываются две мини-карты: одна для обзора в верхней части панели, а другая — для раскрывающегося меню, в котором можно выбрать текущий видимый профиль из истории (каждый пункт этого меню содержит обзор выбранного профиля). Тем не менее, эти два элемента имеют одинаковое содержимое, поэтому один из них можно использовать для другого.
Поскольку обе мини-карты представляют собой изображения, нарисованные на холсте, пришлось использовать утилиту drawImage и затем запускать код только один раз, чтобы сэкономить время. В результате длительность группы сократилась с 2,4 секунды до 140 миллисекунд.
Заключение
После применения всех этих исправлений (и еще пары более мелких тут и там) изменение временной шкалы загрузки профиля выглядело следующим образом:
До:
После:
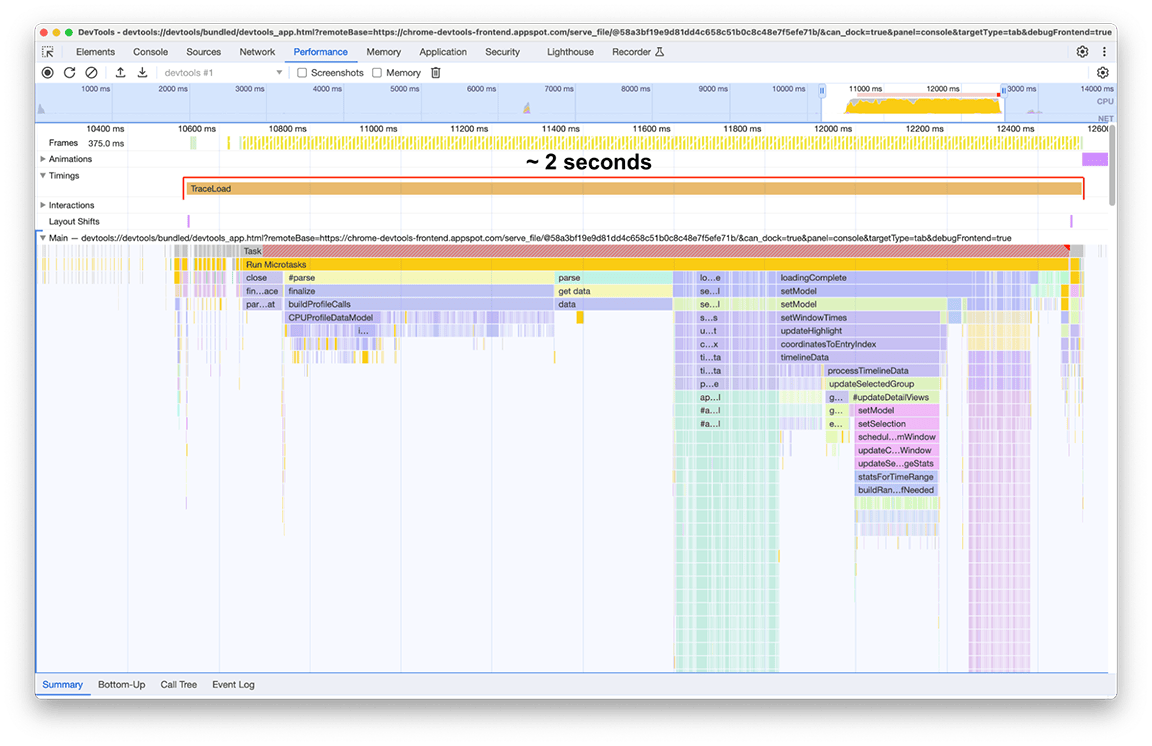
Время загрузки после внесения улучшений составило 2 секунды, что означает, что улучшение примерно на 80% было достигнуто при относительно небольших усилиях, поскольку большая часть работы состояла из быстрых исправлений. Конечно, ключевым моментом было правильное определение того, что нужно сделать изначально, и панель производительности оказалась подходящим инструментом для этого.
Важно также подчеркнуть, что эти показатели относятся к профилю, используемому в качестве объекта исследования. Профиль представлял для нас интерес, поскольку был особенно большим. Тем не менее, поскольку конвейер обработки одинаков для всех профилей, достигнутое значительное улучшение относится ко всем профилям, загруженным в панель производительности.
Еда на вынос
Из этих результатов можно извлечь несколько уроков с точки зрения оптимизации производительности вашего приложения:
1. Используйте инструменты профилирования для выявления закономерностей производительности во время выполнения.
Инструменты профилирования невероятно полезны для понимания того, что происходит в вашем приложении во время его работы, особенно для выявления возможностей повышения производительности. Панель «Производительность» в Chrome DevTools — отличный вариант для веб-приложений, поскольку это встроенный инструмент веб-профилирования в браузере, который постоянно обновляется и соответствует последним функциям веб-платформы. Кроме того, он стал значительно быстрее! 😉
Используйте образцы, которые можно использовать в качестве репрезентативных рабочих нагрузок, и посмотрите, что вы сможете найти!
2. Избегайте сложных иерархий вызовов
По возможности избегайте чрезмерного усложнения графа вызовов. Сложная иерархия вызовов легко приводит к снижению производительности и затрудняет понимание причин работы кода, что затрудняет внесение улучшений.
3. Определите ненужную работу
Стареющие кодовые базы часто содержат ненужный код. В нашем случае устаревший и ненужный код занимал значительную часть общего времени загрузки. Удаление его было самым простым решением.
4. Используйте структуры данных правильно
Используйте структуры данных для оптимизации производительности, но при выборе каждого типа структуры данных учитывайте затраты и компромиссы, которые возникают при выборе. Речь идёт не только о пространственной сложности самой структуры данных, но и о временной сложности соответствующих операций.
5. Кэшируйте результаты, чтобы избежать дублирования работы при сложных или повторяющихся операциях.
Если выполнение операции требует больших затрат, имеет смысл сохранить её результаты для следующего использования. Это также имеет смысл делать, если операция выполняется много раз, даже если каждый раз затраты не слишком велики.
6. Отложите некритическую работу
Если результат задачи не требуется немедленно, а ее выполнение удлиняет критический путь, рассмотрите возможность отсрочки ее путем ленивого вызова, когда ее результат действительно необходим.
7. Используйте эффективные алгоритмы для больших объемов входных данных.
Для больших объёмов входных данных алгоритмы оптимальной временной сложности становятся критически важными. Мы не рассматривали эту категорию в данном примере, но их важность трудно переоценить.
8. Бонус: сравните свои конвейеры
Чтобы ваш развивающийся код оставался быстрым, разумно отслеживать его поведение и сравнивать его со стандартами. Это позволит вам заблаговременно выявлять регрессии и повышать общую надёжность, обеспечивая долгосрочный успех.