


Quel que soit le type d'application que vous développez, il est essentiel d'optimiser ses performances, de s'assurer qu'elle se charge rapidement et qu'elle offre des interactions fluides pour l'expérience utilisateur et le succès de l'application. Pour ce faire, vous pouvez inspecter l'activité d'une application à l'aide d'outils de profilage afin de voir ce qui se passe en coulisses lorsqu'elle s'exécute pendant une période donnée. Le panneau "Performances" des outils de développement est un excellent outil de profilage permettant d'analyser et d'optimiser les performances des applications Web. Si votre application s'exécute dans Chrome, elle vous offre un aperçu visuel détaillé de ce que fait le navigateur lors de l'exécution de votre application. Comprendre cette activité peut vous aider à identifier les modèles, les goulots d'étranglement et les points chauds de performances sur lesquels vous pouvez agir pour améliorer les performances.
L'exemple suivant vous explique comment utiliser le panneau Performances.
Configurer et recréer notre scénario de profilage
Nous nous sommes récemment fixé pour objectif d'améliorer les performances du panneau Performances. En particulier, nous voulions qu'il charge plus rapidement de grands volumes de données sur les performances. C'est le cas, par exemple, lorsque vous profilez des processus complexes ou de longue durée, ou que vous capturez des données très précises. Pour ce faire, il fallait d'abord comprendre comment l'application fonctionnait et pourquoi elle fonctionnait de cette manière. Pour cela, un outil de profilage a été utilisé.
Comme vous le savez peut-être, les outils pour les développeurs sont eux-mêmes une application Web. Il peut donc être profilé à l'aide du panneau Performances. Pour profiler ce panneau lui-même, vous pouvez ouvrir les outils de développement, puis ouvrir une autre instance des outils de développement qui y est associée. Chez Google, cette configuration est appelée DevTools-on-DevTools.
Une fois la configuration prête, le scénario à profiler doit être recréé et enregistré. Pour éviter toute confusion, la fenêtre d'origine des outils de développement sera appelée"première instance des outils de développement", et la fenêtre qui inspecte la première instance sera appelée "deuxième instance des outils de développement".
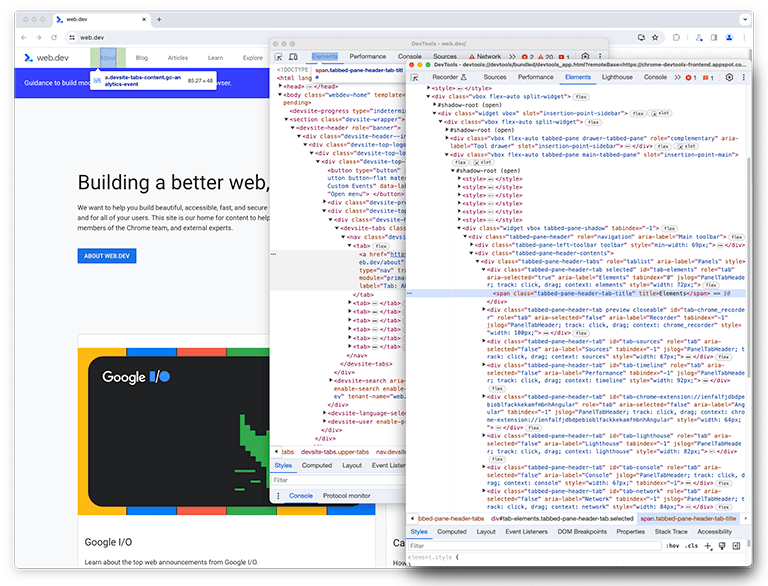
Dans la deuxième instance des outils de développement, le panneau Performances (que nous appellerons panneau "perf" à partir de maintenant) observe la première instance des outils de développement pour recréer le scénario, qui charge un profil.
Sur la deuxième instance DevTools, un enregistrement en direct est lancé, tandis que sur la première instance, un profil est chargé à partir d'un fichier sur le disque. Un fichier volumineux est chargé afin de profiler précisément les performances du traitement des entrées volumineuses. Une fois les deux instances chargées, les données de profilage des performances (appelées trace) s'affichent dans la deuxième instance des outils de développement du panneau "Performances", qui charge un profil.
État initial : identifier les opportunités d'amélioration
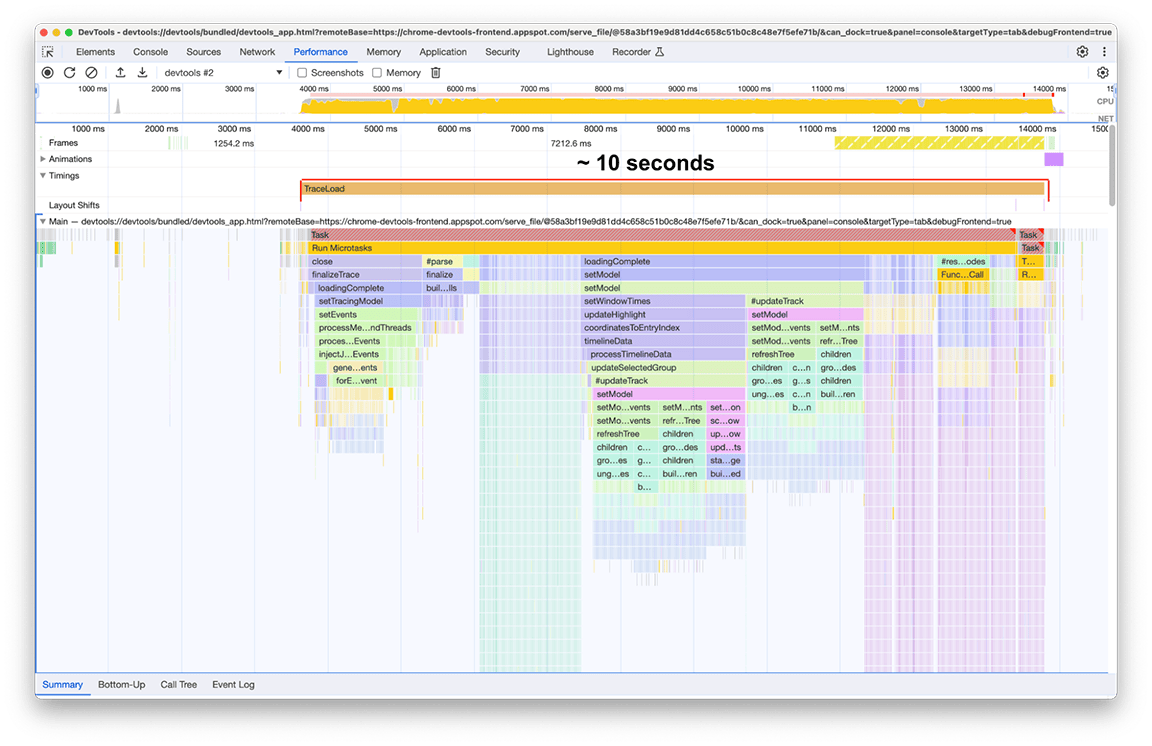
Une fois le chargement terminé, les éléments suivants ont été observés dans notre deuxième instance du panneau des performances, comme illustré dans la capture d'écran ci-dessous. Concentrez-vous sur l'activité du thread principal, qui est visible sous la piste intitulée Main. On peut voir qu'il y a cinq grands groupes d'activités dans le graphique en flammes. Il s'agit des tâches dont le chargement prend le plus de temps. La durée totale de ces tâches était d'environ 10 secondes. Dans la capture d'écran suivante, le panneau "Performances" est utilisé pour se concentrer sur chacun de ces groupes d'activités et voir ce qui peut être trouvé.
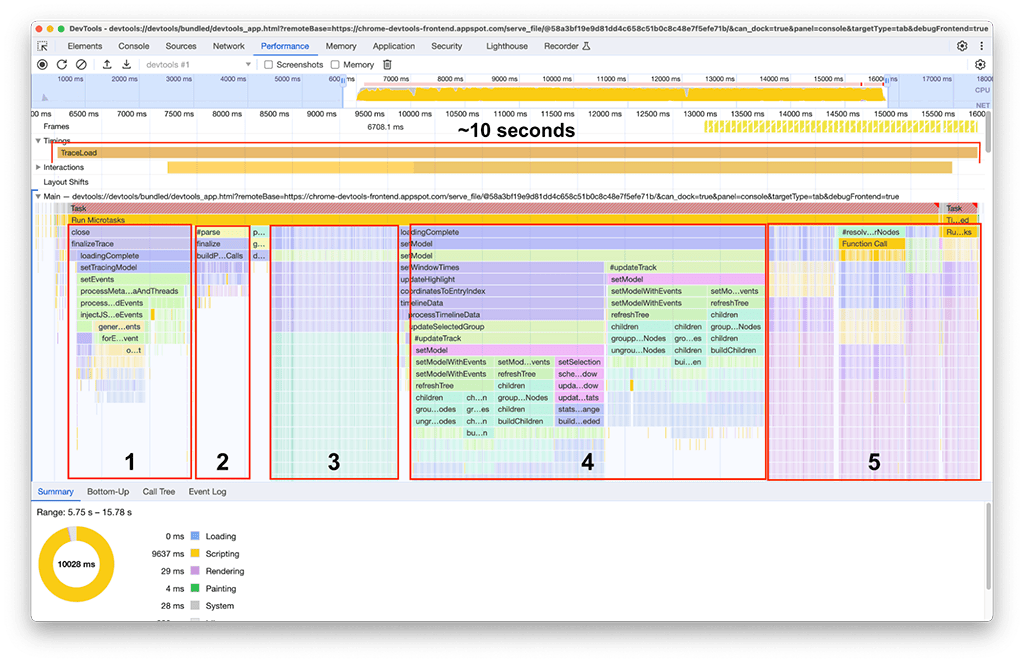
Premier groupe d'activités : travail inutile
Il est apparu que le premier groupe d'activités était un ancien code qui s'exécutait toujours, mais qui n'était pas vraiment nécessaire. En gros, tout ce qui se trouve sous le bloc vert intitulé processThreadEvents était une perte de temps. C'était une victoire rapide. La suppression de cet appel de fonction a permis de gagner environ 1,5 seconde. C'est parfait !
Deuxième groupe d'activités
Dans le deuxième groupe d'activités, la solution n'était pas aussi simple que dans le premier. L'buildProfileCalls a pris environ 0,5 seconde, et cette tâche ne pouvait pas être évitée.
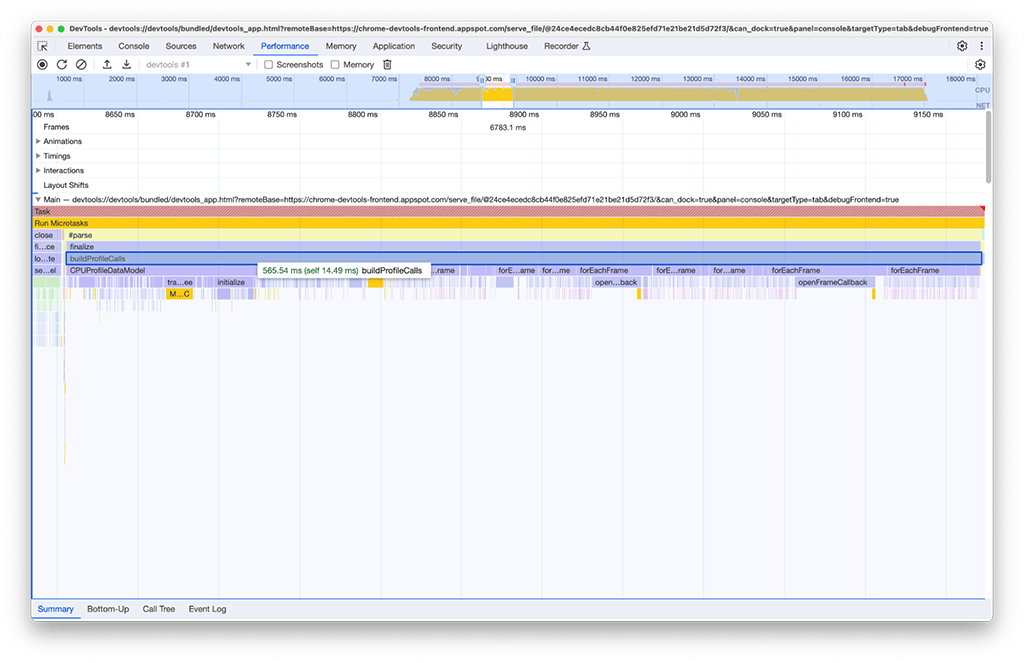
Par curiosité, nous avons activé l'option Mémoire dans le panneau "Performances" pour en savoir plus. Nous avons alors constaté que l'activité buildProfileCalls utilisait également beaucoup de mémoire. Ici, vous pouvez voir comment le graphique en courbes bleues augmente soudainement au moment où buildProfileCalls est exécuté, ce qui suggère une fuite de mémoire potentielle.
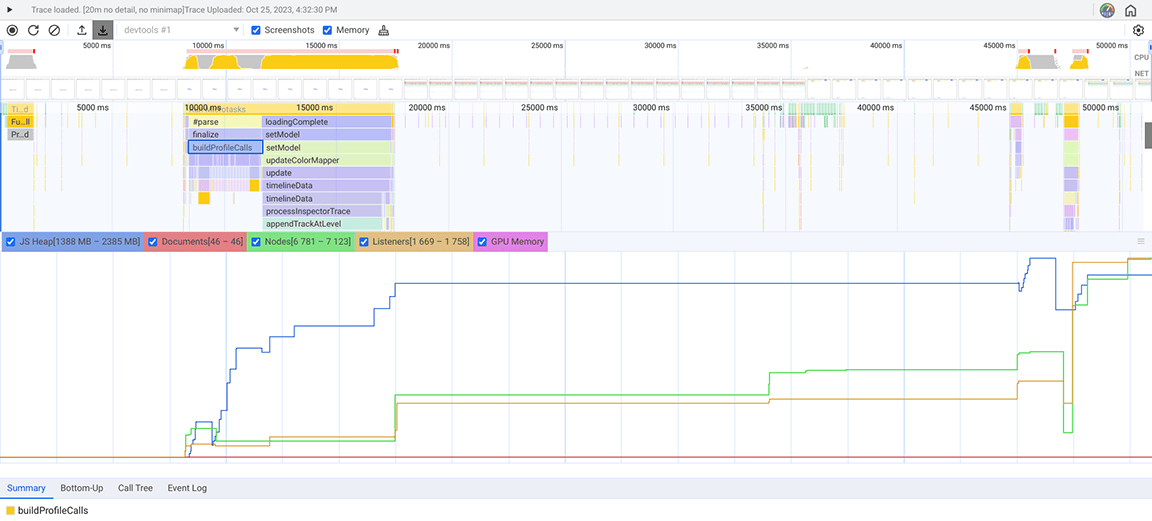
Pour confirmer cette hypothèse, nous avons utilisé le panneau "Mémoire" (un autre panneau de DevTools, différent du tiroir "Mémoire" du panneau "Performances") pour examiner le problème. Dans le panneau "Mémoire", le type de profilage "Échantillonnage de l'allocation" a été sélectionné, ce qui a permis d'enregistrer l'instantané du tas pour le panneau "Performances" chargeant le profil CPU.
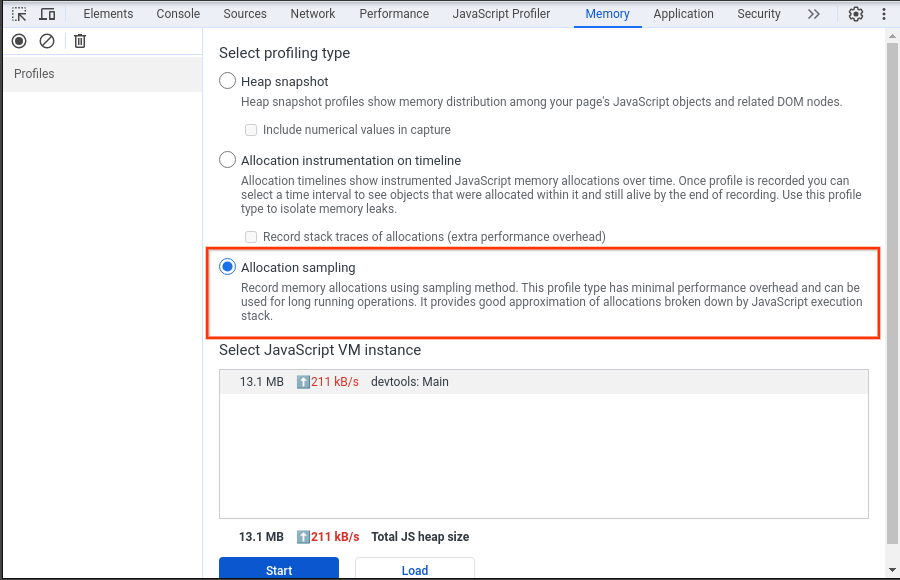
La capture d'écran suivante montre le snapshot du tas qui a été collecté.
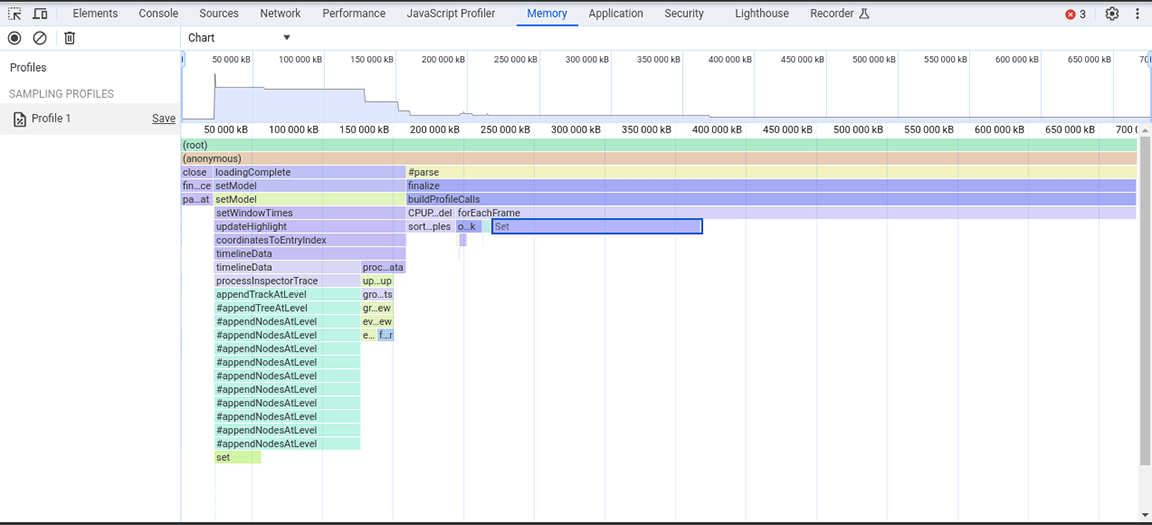
À partir de cet instantané du tas, nous avons observé que la classe Set consommait beaucoup de mémoire. En vérifiant les points d'appel, nous avons constaté que nous attribuions inutilement des propriétés de type Set à des objets créés en grand nombre. Ce coût s'accumulait et beaucoup de mémoire était consommée, au point qu'il était courant que l'application plante sur des entrées volumineuses.
Les ensembles sont utiles pour stocker des éléments uniques et fournir des opérations qui utilisent l'unicité de leur contenu, comme la déduplication des ensembles de données et la fourniture de recherches plus efficaces. Toutefois, ces fonctionnalités n'étaient pas nécessaires, car les données stockées étaient garanties comme étant uniques par rapport à la source. Les ensembles n'étaient donc pas nécessaires au départ. Pour améliorer l'allocation de mémoire, le type de propriété est passé de Set à un tableau simple. Après avoir appliqué cette modification, un autre instantané du tas a été pris et une réduction de l'allocation de mémoire a été observée. Bien que ce changement n'ait pas permis d'améliorer considérablement la vitesse, il a eu pour avantage secondaire de réduire la fréquence des plantages de l'application.
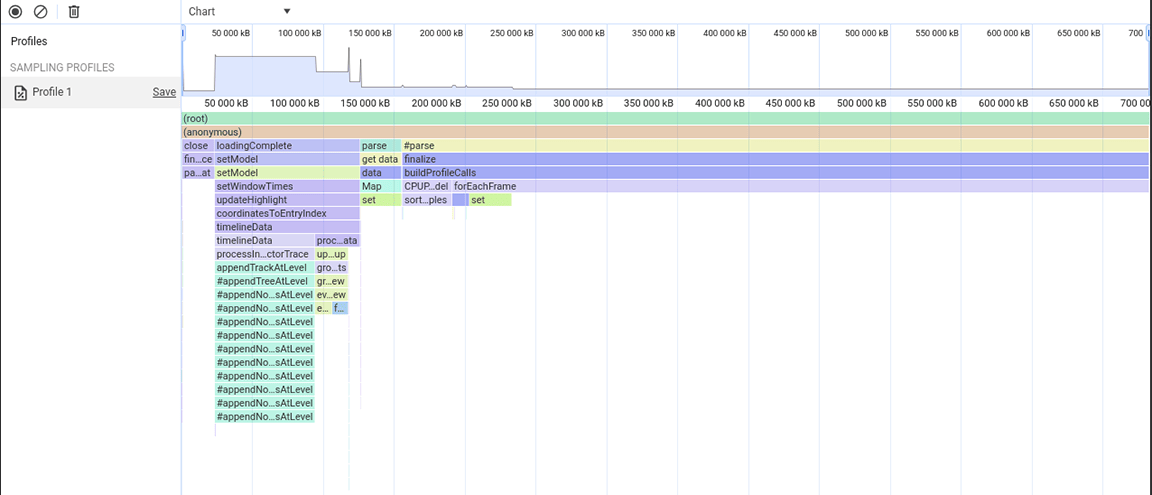
Troisième groupe d'activités : peser les compromis de la structure des données
La troisième section est particulière : vous pouvez voir dans le graphique de type "flamme" qu'elle se compose de colonnes étroites mais hautes, qui désignent des appels de fonction profonds et des récursions profondes dans ce cas. Au total, cette section a duré environ 1,4 seconde. En regardant en bas de cette section, il est apparu que la largeur de ces colonnes était déterminée par la durée d'une fonction : appendEventAtLevel, ce qui suggérait qu'il pouvait s'agir d'un goulot d'étranglement.
Dans l'implémentation de la fonction appendEventAtLevel, une chose s'est démarquée. Pour chaque entrée de données dans l'entrée (appelée "événement" dans le code), un élément a été ajouté à une carte qui suivait la position verticale des entrées de la chronologie. Cela posait problème, car la quantité d'éléments stockés était très importante. Les cartes sont rapides pour les recherches basées sur des clés, mais cet avantage n'est pas sans frais. À mesure qu'une carte s'agrandit, l'ajout de données peut, par exemple, devenir coûteux en raison du rehashage. Ce coût devient perceptible lorsque de grandes quantités d'éléments sont ajoutées à la carte de manière successive.
/**
* Adds an event to the flame chart data at a defined vertical level.
*/
function appendEventAtLevel (event, level) {
// ...
const index = data.length;
data.push(event);
this.indexForEventMap.set(event, index);
// ...
}
Nous avons testé une autre approche qui ne nous obligeait pas à ajouter un élément dans une carte pour chaque entrée du graphique en flammes. L'amélioration a été significative, ce qui confirme que le problème était bien lié à la surcharge occasionnée par l'ajout de toutes les données à la carte. La durée du groupe d'activités est passée d'environ 1,4 seconde à environ 200 millisecondes.
Avant :
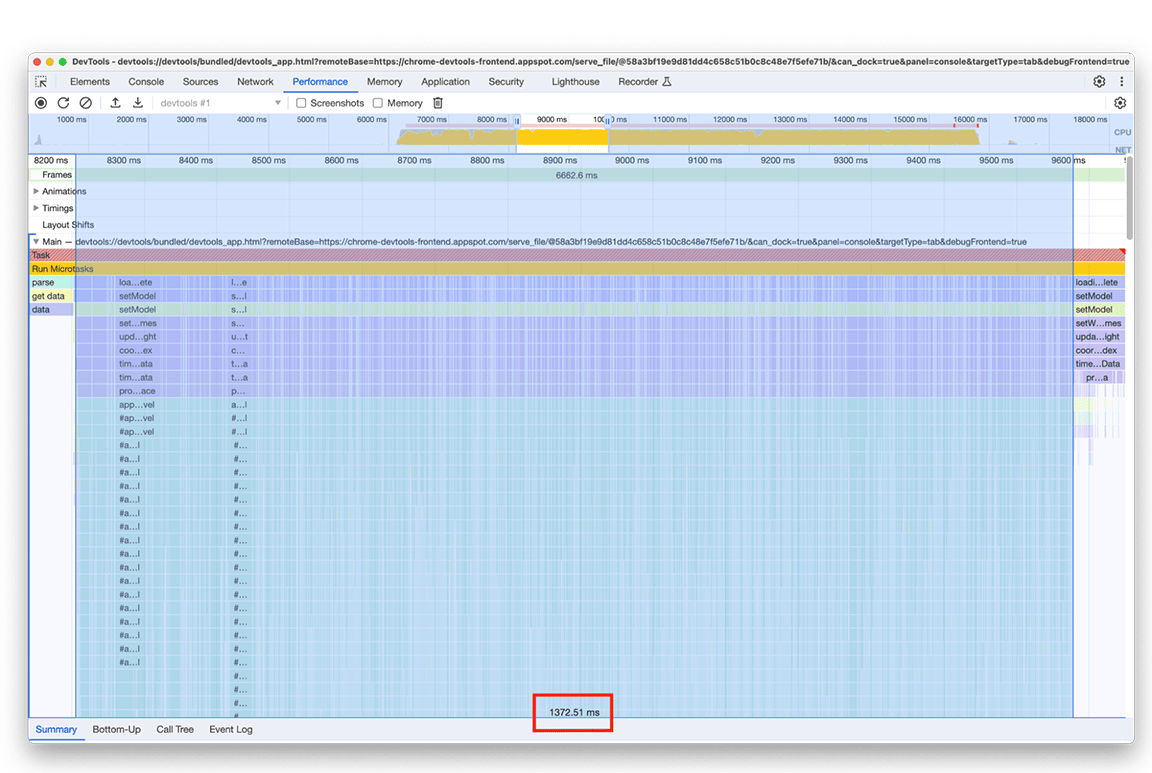
Après :
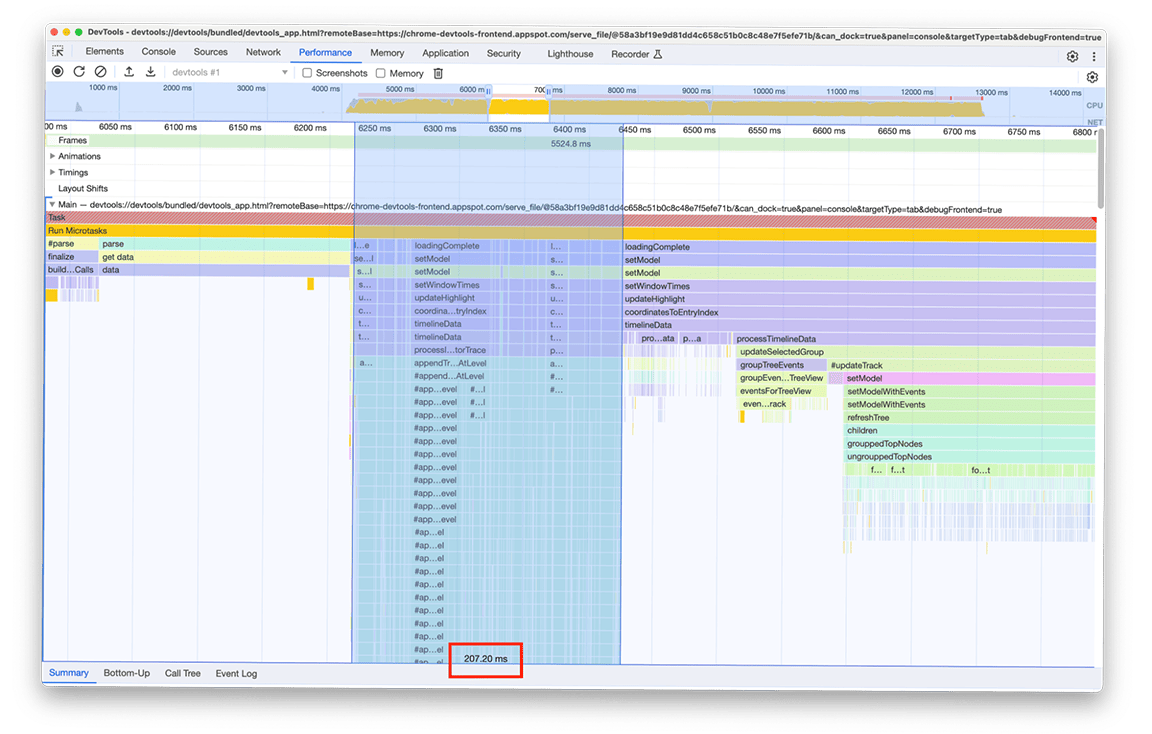
Quatrième groupe d'activités : différer les tâches non critiques et mettre en cache les données pour éviter les tâches en double
En zoomant sur cette fenêtre, on peut voir qu'il existe deux blocs d'appels de fonction presque identiques. En examinant le nom des fonctions appelées, vous pouvez déduire que ces blocs sont constitués de code qui crée des arborescences (par exemple, avec des noms tels que refreshTree ou buildChildren). En fait, le code associé est celui qui crée les arborescences dans le tiroir inférieur du panneau. Il est intéressant de noter que ces arborescences ne s'affichent pas immédiatement après le chargement. L'utilisateur doit sélectionner une vue arborescente (les onglets "De bas en haut", "Arborescence des appels" et "Journal des événements" dans le tiroir) pour que les arborescences s'affichent. De plus, comme vous pouvez le voir sur la capture d'écran, le processus de création de l'arborescence a été exécuté deux fois.
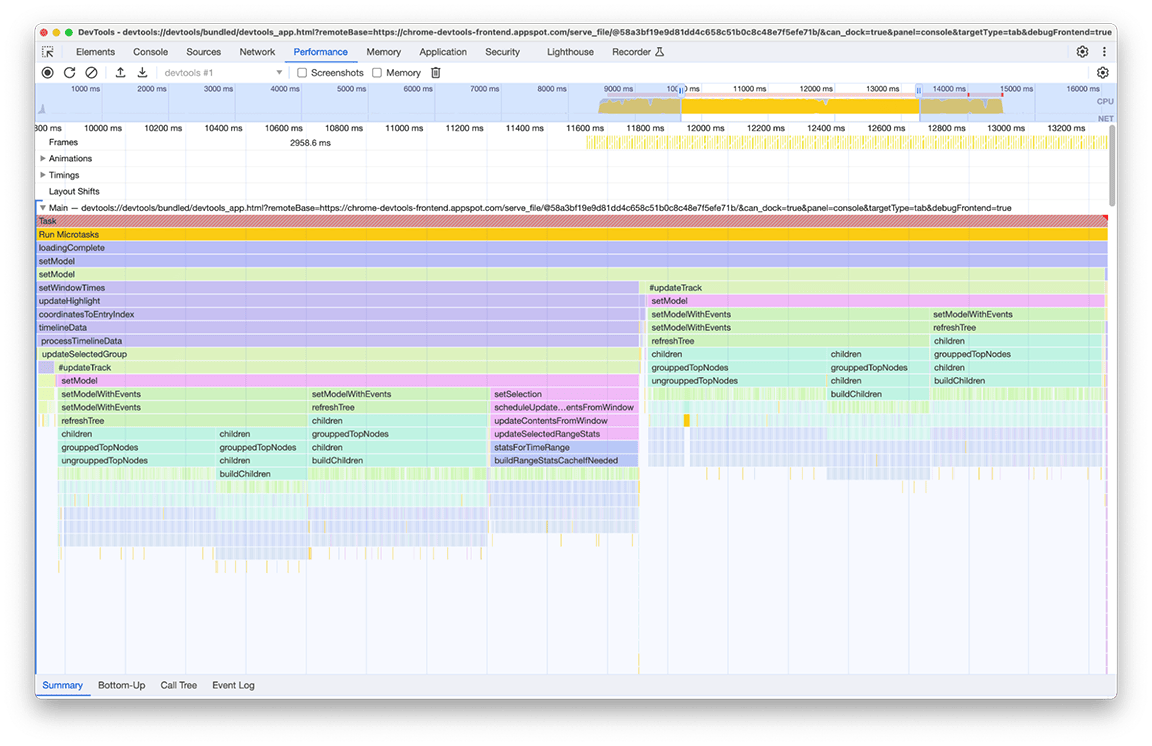
Nous avons identifié deux problèmes avec cette image :
- Une tâche non critique entravait les performances du temps de chargement. Les utilisateurs n'ont pas toujours besoin de sa sortie. Par conséquent, la tâche n'est pas essentielle au chargement du profil.
- Le résultat de ces tâches n'a pas été mis en cache. C'est pourquoi les arbres ont été calculés deux fois, même si les données n'ont pas changé.
Nous avons commencé par différer le calcul de l'arborescence jusqu'à ce que l'utilisateur ouvre manuellement la vue arborescence. Ce n'est qu'alors que la création de ces arbres vaut la peine. Le temps total d'exécution de cette opération deux fois était d'environ 3, 4 secondes.Le report a donc fait une différence significative dans le temps de chargement. Nous étudions également la possibilité de mettre en cache ces types de tâches.
Cinquième groupe d'activités : éviter les hiérarchies d'appels complexes si possible
En examinant attentivement ce groupe, il est apparu clairement qu'une chaîne d'appels particulière était invoquée à plusieurs reprises. Le même schéma est apparu six fois à différents endroits du graphique en flammes, et la durée totale de cette fenêtre était d'environ 2,4 secondes.
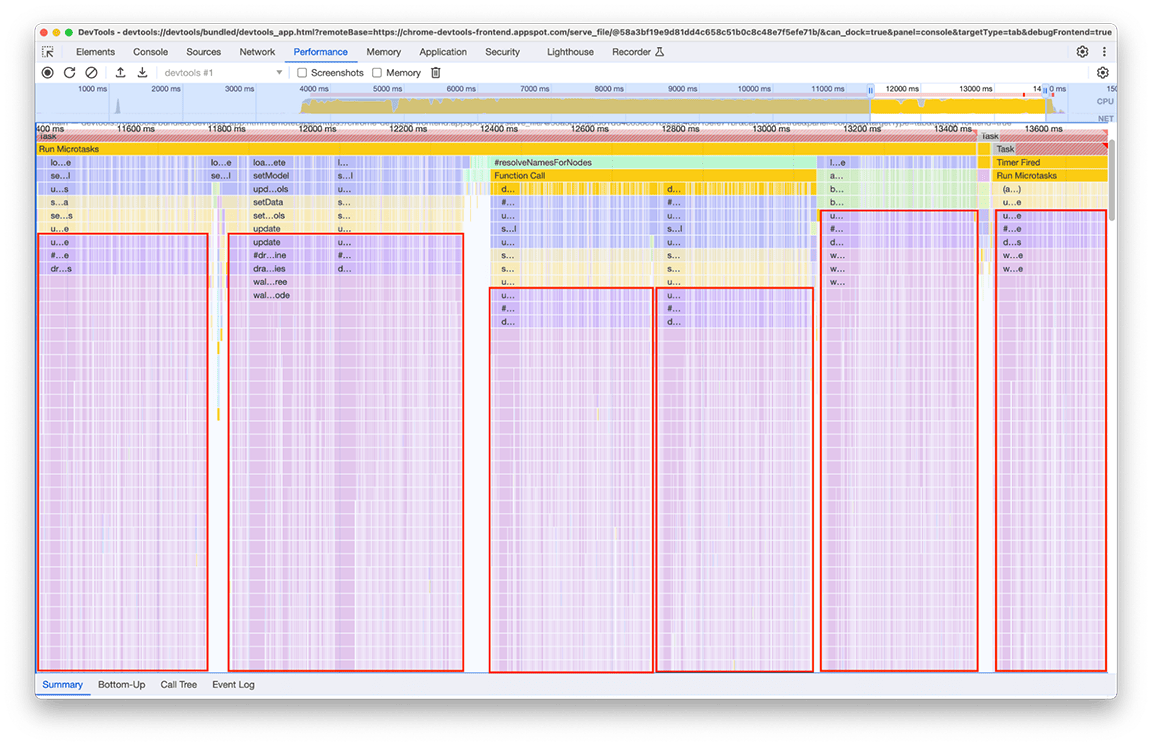
Le code associé appelé plusieurs fois est la partie qui traite les données à afficher sur la "minimap" (l'aperçu de l'activité de la timeline en haut du panneau). Je ne comprenais pas pourquoi cela se produisait plusieurs fois, mais il n'y avait certainement pas besoin de le faire six fois ! En fait, le résultat du code doit rester à jour si aucun autre profil n'est chargé. En théorie, le code ne devrait s'exécuter qu'une seule fois.
Après examen, il a été constaté que le code associé était appelé en raison de plusieurs parties du pipeline de chargement appelant directement ou indirectement la fonction qui calcule la carte miniature. En effet, la complexité du graphique d'appel du programme a évolué au fil du temps, et d'autres dépendances à ce code ont été ajoutées à l'insu des développeurs. Il n'existe aucune solution rapide à ce problème. La façon de résoudre ce problème dépend de l'architecture de la base de code en question. Dans notre cas, nous avons dû réduire un peu la complexité de la hiérarchie des appels et ajouter une vérification pour empêcher l'exécution du code si les données d'entrée restaient inchangées. Après avoir implémenté cela, nous avons obtenu cette vue de la timeline :
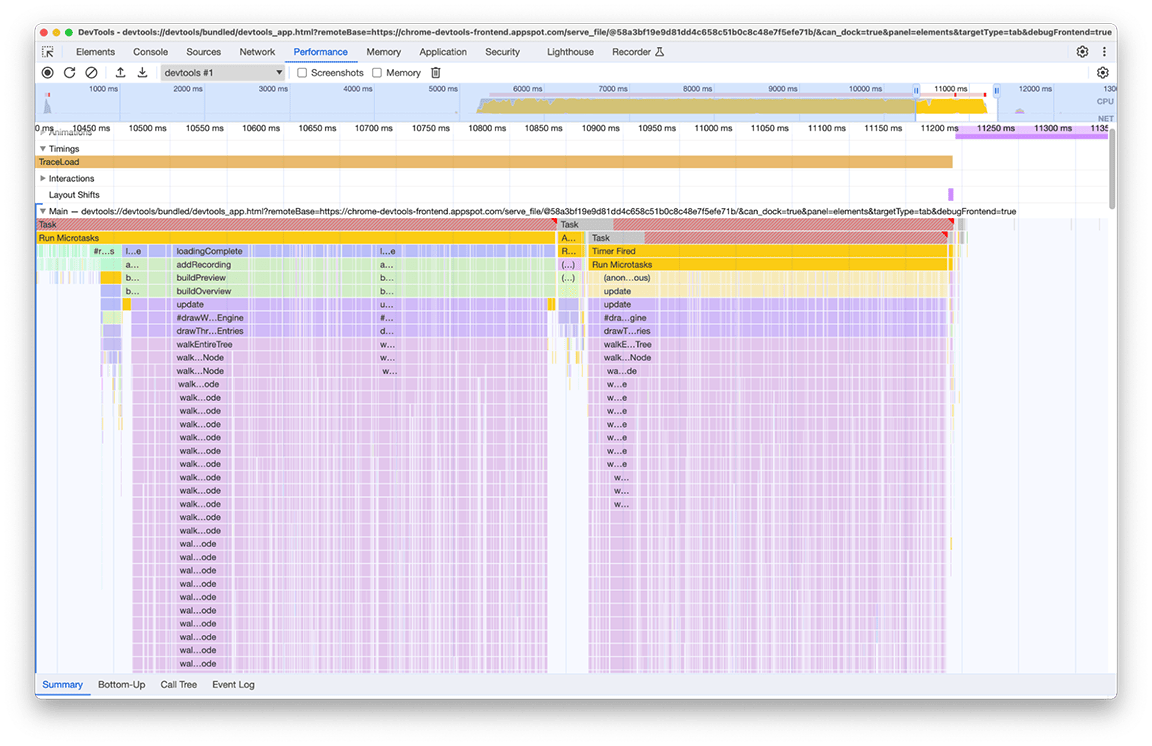
Notez que l'exécution du rendu de la minimap a lieu deux fois, et non une seule. En effet, deux cartes miniatures sont dessinées pour chaque profil : une pour l'aperçu en haut du panneau et une autre pour le menu déroulant qui sélectionne le profil actuellement visible dans l'historique (chaque élément de ce menu contient un aperçu du profil qu'il sélectionne). Néanmoins, ces deux types de contenus sont identiques. Il est donc possible de réutiliser l'un pour l'autre.
Comme ces cartes miniatures sont des images dessinées sur un canevas, il suffisait d'utiliser l'utilitaire de canevas drawImage, puis d'exécuter le code une seule fois pour gagner du temps. Grâce à cet effort, la durée du groupe a été réduite de 2,4 secondes à 140 millisecondes.
Conclusion
Après avoir appliqué tous ces correctifs (et quelques autres plus petits ici et là), le changement de la chronologie de chargement du profil s'est présenté comme suit :
Avant :
Après :
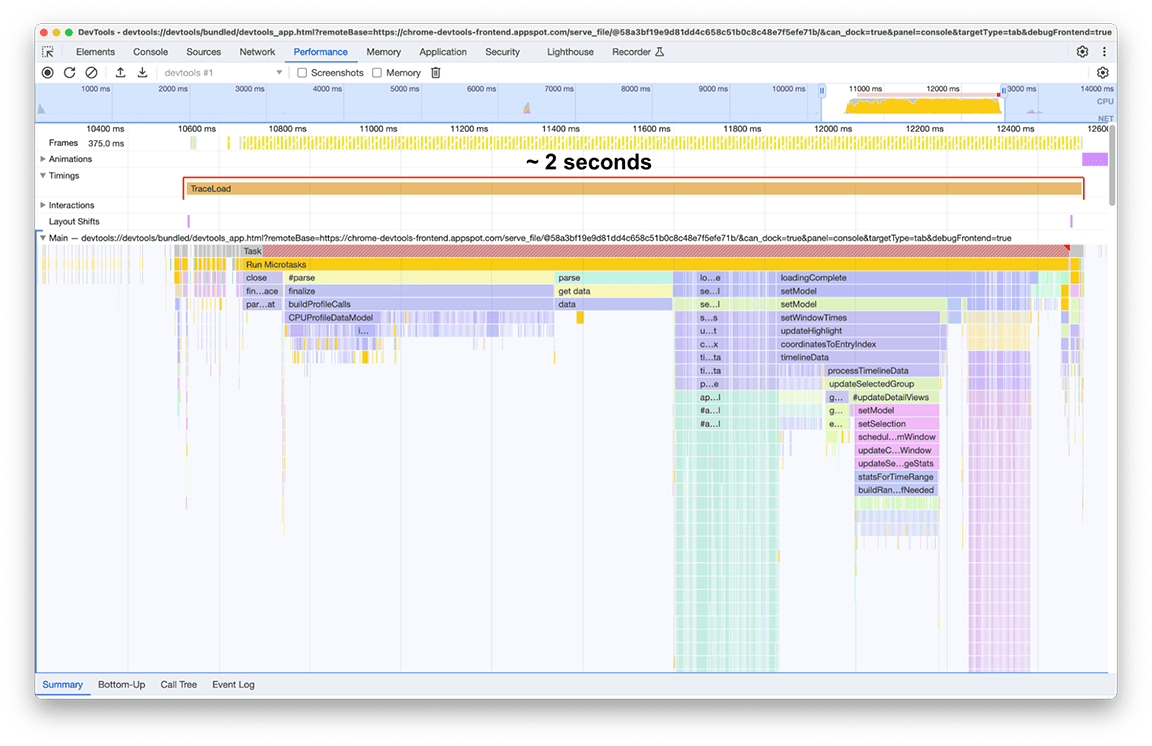
Après les améliorations, le temps de chargement était de deux secondes, ce qui représente une amélioration d'environ 80 % avec un effort relativement faible, car la plupart des actions effectuées consistaient en des corrections rapides. Bien sûr, il était essentiel d'identifier correctement ce qu'il fallait faire au départ, et le panneau "Performances" était l'outil idéal pour cela.
Il est également important de souligner que ces chiffres sont propres à un profil utilisé comme sujet d'étude. Ce profil nous intéressait, car il était particulièrement volumineux. Néanmoins, comme le pipeline de traitement est le même pour tous les profils, l'amélioration significative obtenue s'applique à tous les profils chargés dans le panneau "Performances".
Points à retenir
Ces résultats vous permettent de tirer quelques leçons en termes d'optimisation des performances de votre application :
1. Utiliser des outils de profilage pour identifier les modèles de performances d'exécution
Les outils de profilage sont extrêmement utiles pour comprendre ce qui se passe dans votre application pendant son exécution, en particulier pour identifier les possibilités d'améliorer les performances. Le panneau "Performances" des outils pour les développeurs Chrome est une excellente option pour les applications Web, car il s'agit de l'outil de profilage Web natif du navigateur. Il est également mis à jour régulièrement pour être compatible avec les dernières fonctionnalités de la plate-forme Web. De plus, il est désormais beaucoup plus rapide. 😉
Utilisez des exemples pouvant servir de charges de travail représentatives et voyez ce que vous pouvez trouver.
2. Évitez les hiérarchies d'appels complexes
Dans la mesure du possible, évitez de rendre votre graphique d'appel trop compliqué. Avec des hiérarchies d'appels complexes, il est facile d'introduire des régressions de performances et difficile de comprendre pourquoi votre code s'exécute de cette manière, ce qui rend difficile l'amélioration des performances.
3. Identifier les tâches inutiles
Il est courant que les bases de code vieillissantes contiennent du code qui n'est plus nécessaire. Dans notre cas, le code obsolète et inutile représentait une part importante du temps de chargement total. La suppression de cette fonctionnalité était la solution la plus simple.
4. Utiliser les structures de données de manière appropriée
Utilisez des structures de données pour optimiser les performances, mais comprenez également les coûts et les compromis que chaque type de structure de données implique lorsque vous décidez lesquelles utiliser. Il ne s'agit pas seulement de la complexité spatiale de la structure de données elle-même, mais aussi de la complexité temporelle des opérations applicables.
5. Mettre en cache les résultats pour éviter les tâches dupliquées pour les opérations complexes ou répétitives
Si l'opération est coûteuse à exécuter, il est judicieux de stocker ses résultats pour la prochaine fois que vous en aurez besoin. Il est également judicieux de le faire si l'opération est effectuée plusieurs fois, même si chaque fois n'est pas particulièrement coûteuse.
6. Reportez les tâches non critiques.
Si le résultat d'une tâche n'est pas nécessaire immédiatement et que l'exécution de la tâche prolonge le chemin critique, envisagez de la différer en l'appelant de manière différée lorsque son résultat est réellement nécessaire.
7. Utiliser des algorithmes efficaces sur des entrées volumineuses
Pour les entrées volumineuses, les algorithmes de complexité temporelle optimale deviennent essentiels. Nous n'avons pas examiné cette catégorie dans cet exemple, mais son importance ne peut être sous-estimée.
8. Bonus : comparer vos pipelines
Pour vous assurer que votre code en constante évolution reste rapide, il est judicieux de surveiller son comportement et de le comparer aux normes. Vous pouvez ainsi identifier de manière proactive les régressions et améliorer la fiabilité globale, ce qui vous permettra de réussir sur le long terme.