
本文档是对WebAssembly 和 WebGPU 增强功能(第 1 部分)的续篇。我们建议您先阅读这篇文章或观看 2024 年 IO 大会上的演讲,然后再继续操作。



WebGPU
WebGPU 可让 Web 应用访问客户端的 GPU 硬件,以执行高效的高度并行计算。自 在 Chrome 中推出 WebGPU 以来,我们已经看到了 Web 上令人惊叹的人工智能 (AI) 和机器学习 (ML) 演示。
例如,Web Stable Diffusion 演示了可以使用 AI 直接在浏览器中根据文本生成图片。今年早些时候,Google 自己的 Mediapipe 团队发布了对大型语言模型推理的实验性支持。
以下动画展示了 Google 的开源大语言模型 (LLM) Gemma 在 Chrome 中完全在设备端实时运行。
以下是 Meta 的“Segment Anything”模型的 Hugging Face 演示,该演示完全在客户端生成高质量的对象遮罩。
以上只是一些展示 WebGPU 在 AI 和机器学习方面的强大能力的出色项目。借助 WebGPU,这些模型和其他模型的运行速度比在 CPU 上运行时快得多。
与使用 CPU 实现相同模型相比,Hugging Face 的文本嵌入 WebGPU 基准测试证明了速度显著提升。在 Apple M1 Max 笔记本电脑上,WebGPU 的速度提高了 30 多倍。其他人则报告说,WebGPU 可将基准测试的速度提高 120 倍以上。
改进了 WebGPU 功能,以便更好地支持 AI 和机器学习
WebGPU 非常适合 AI 和机器学习模型,因为它支持计算着色器,而这些模型可能包含数十亿个参数。计算着色器在 GPU 上运行,可帮助对大量数据运行并行数组操作。
在过去一年对 WebGPU 进行的众多改进中,我们一直在添加更多功能,以提升 Web 上的机器学习 (ML) 和 AI 性能。我们最近推出了两项新功能:16 位浮点数和打包整数点积。
16 位浮点数
请注意,机器学习工作负载不需要精确性。shader-f16 是一项功能,可在 WebGPU 着色语言中使用 f16 类型。这种浮点类型占用 16 位,而不是通常的 32 位。f16 的范围较小且精度较低,但对于许多机器学习模型来说,这已经足够了。
此功能通过以下几种方式提高效率:
减少内存用量:使用 f16 元素的张量占用的空间减半,从而将内存用量减半。GPU 计算通常会受内存带宽限制,因此内存减半通常意味着着色器运行速度会翻倍。从技术层面来说,您无需使用 f16 即可节省内存带宽。您可以将数据存储为低精度格式,然后在着色器中将其展开为完整的 f32 以进行计算。不过,GPU 需要额外的计算能力来打包和解压缩数据。
减少数据转换:f16 通过最大限度减少数据转换来减少计算量。低精度数据可以存储,然后直接使用,而无需转换。
并行性更高:新型 GPU 能够在 GPU 的执行单元中同时容纳更多值,从而执行更多并行计算。例如,一个每秒最多支持 5 万亿次 f32 浮点运算的 GPU 可能支持每秒 10 万亿次 f16 浮点运算。
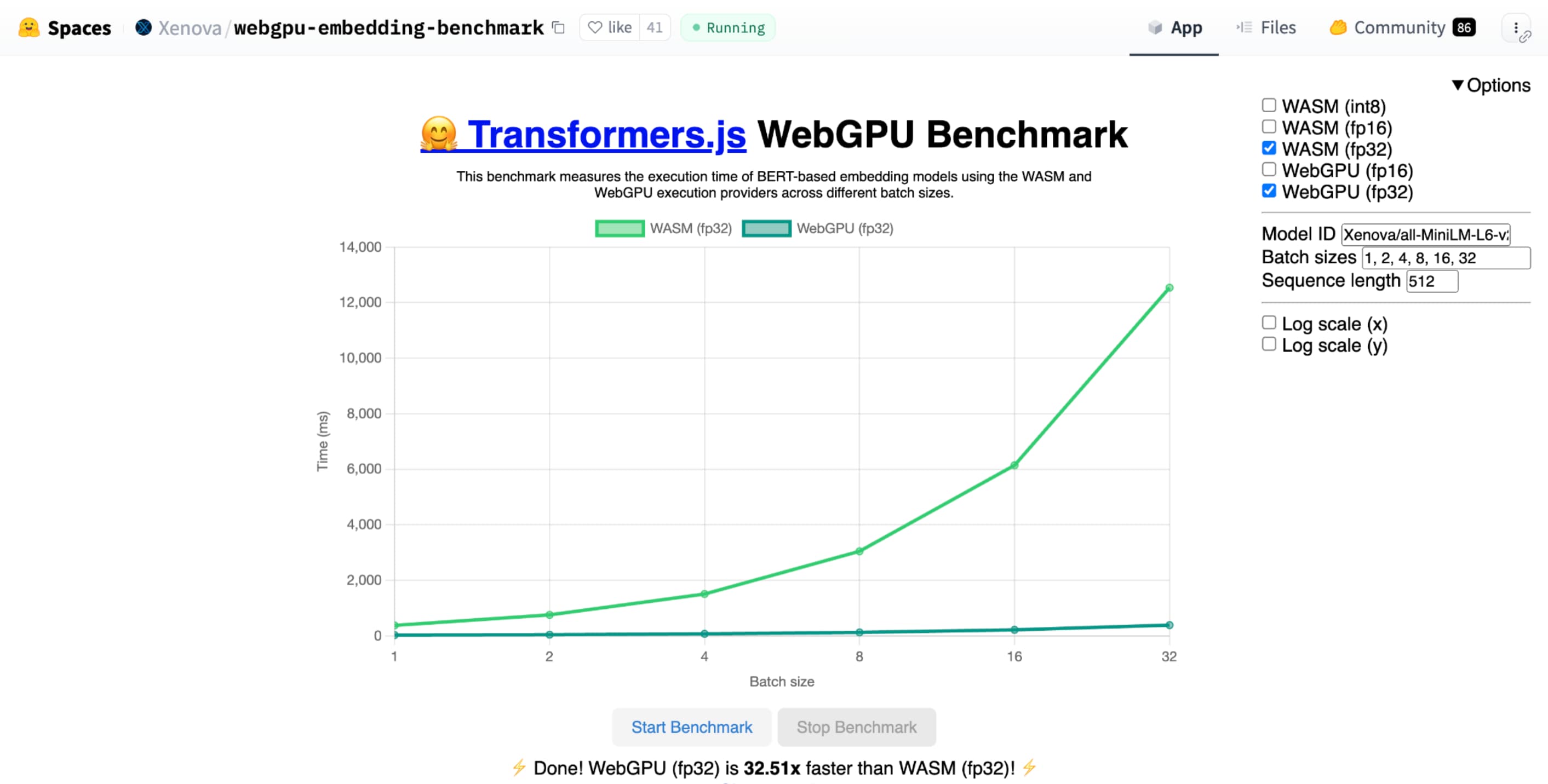
shader-f16 时,Hugging Face 的文本嵌入 WebGPU 基准测试基准测试在 Apple M1 Max 笔记本电脑上运行基准测试的速度是 f32 的 3 倍。
WebLLM 是一个可以运行多个大型语言模型的项目。它使用 Apache TVM,这是一个开源机器学习编译器框架。
我让 WebLLM 使用 Llama 3 八十亿参数模型规划了一次巴黎之旅。结果表明,在模型的预填充阶段,f16 的速度是 f32 的 2.1 倍。在解码阶段,速度提高了 1.3 倍以上。
应用必须先确认 GPU 适配器是否支持 f16,如果支持,则在请求 GPU 设备时明确启用它。如果不支持 f16,您将无法在 requiredFeatures 数组中请求它。
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
然后,在 WebGPU 着色器中,您必须在顶部明确启用 f16。之后,您就可以像使用任何其他浮点数据类型一样在着色器中使用它了。
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
打包整数点积
许多模型在仅使用 8 位精度(f16 的一半)时仍能正常运行。这在 LLM 和图像模型中用于分割和对象识别,非常受欢迎。不过,随着精度的降低,模型的输出质量也会下降,因此 8 位量化并不适用于所有应用。
只有少数 GPU 原生支持 8 位值。这时,就需要用到打包整数点积运算。我们在 Chrome 123 中发布了 DP4a。
现代 GPU 具有特殊指令,可接受两个 32 位整数,将它们分别解读为 4 个连续打包的 8 位整数,并计算其各个组成部分之间的点积。
这对于 AI 和机器学习尤其有用,因为矩阵乘法核由许多点积组成。
例如,我们将 4 x 8 的矩阵与 8 x 1 的向量相乘。计算此值需要进行 4 次点积,以计算输出矢量中的每个值:A、B、C 和 D。
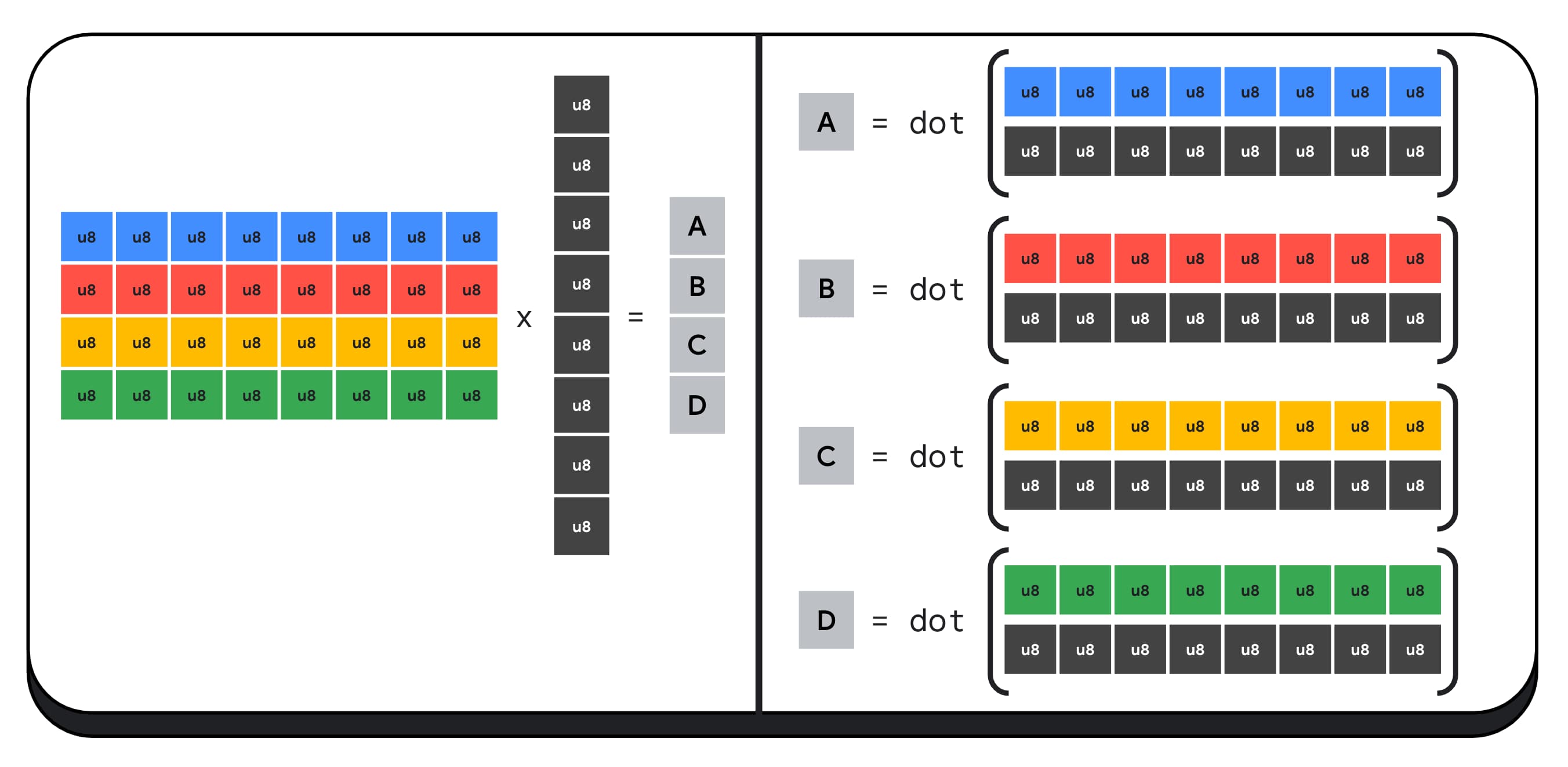
计算这些输出的流程是相同的;我们将介绍计算其中一个输出所涉及的步骤。在进行任何计算之前,我们首先需要将 8 位整数数据转换为可用于执行算术运算的类型,例如 f16。然后,我们执行元素级乘法,最后将所有乘积相加。总的来说,对于整个矩阵-向量乘法,我们执行了 40 次整数转换为浮点转换来解封装数据、32 次浮点乘法和 28 次浮点加法。
对于包含更多运算的较大矩阵,打包整数点积有助于减少工作量。
对于结果矢量中的每个输出,我们使用 WebGPU 着色语言内置的 dot4U8Packed 执行两个压缩点积运算,然后将结果相加。总的来说,对于整个矩阵-向量乘法,我们不会执行任何数据转换。我们执行 8 次压缩点积运算和 4 次整数加法运算。
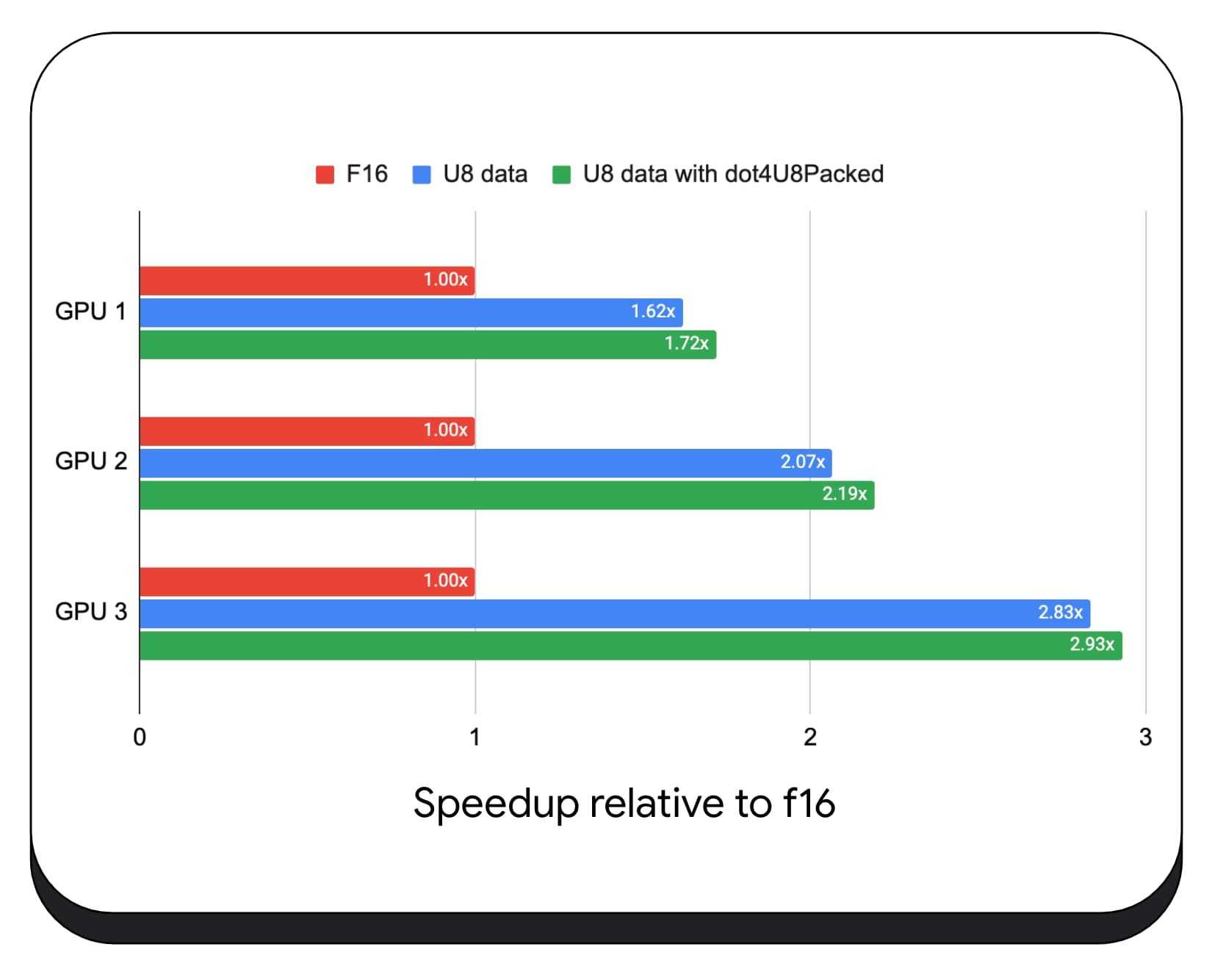
我们在各种消费类 GPU 上测试了使用 8 位数据的压缩整数点积运算。与 16 位浮点数相比,我们可以看到,8 位浮点数的速度是 1.6 到 2.8 倍。如果我们还使用了压缩整数点积,性能会更好。速度提高了 1.7 到 2.9 倍。
使用 wgslLanguageFeatures 属性检查浏览器支持情况。如果 GPU 不支持原生打包点积运算,则浏览器会对自己的实现进行 polyfill。
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
以下代码段差异(差异)突出显示了在 WebGPU 着色器中使用压缩整数乘积所需的更改。
之前 - WebGPU 着色器,用于将部分点积累积到变量 `sum` 中。在循环结束时,`sum` 会保留矢量与输入矩阵的一行之间的完整点积。
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
后 - 编写为使用压缩整数点积的 WebGPU 着色器。主要区别在于,此着色器会加载单个 32 位整数,而不是从矢量和矩阵中加载 4 个浮点值。此 32 位整数用于存储四个 8 位整数值的数据。然后,我们调用 dot4U8Packed 来计算这两个值的点积。
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
16 位浮点数和打包整数点积都是 Chrome 中已发布的功能,可加速 AI 和机器学习。当硬件支持时,16 位浮点数可用,并且 Chrome 会在所有设备上实现打包整数点积。
您现在就可以在 Chrome 稳定版中使用这些功能,以提升性能。
拟建地图项
今后,我们将研究另外两项功能:子群和协作矩阵乘法。
子群组功能支持 SIMD 级并行通信或执行集体数学运算,例如对超过 16 个数字求和。这样可以高效地跨线程共享数据。新型 GPU API 支持子组,名称各异且形式略有不同。
我们将这组常见功能提炼成了一份提案,并提交给了 WebGPU 标准化组织。此外,我们在实验标志后面在 Chrome 中对子群组进行了原型设计,并将初步结果纳入了讨论范围。主要问题是如何确保可移植行为。
协同矩阵乘法是 GPU 中较新添加的功能。大型矩阵乘法可以拆分为多个较小的矩阵乘法。协作矩阵乘法会在单个逻辑步骤中对这些较小的固定大小块执行乘法。在此步骤中,一组线程高效协作来计算结果。
我们调查了底层 GPU API 中的支持情况,并计划向 WebGPU 标准化组织提交一项提案。与子群组一样,我们预计大部分讨论将围绕可移植性展开。
为了评估子组操作的性能,我们在真实应用中将对子组的实验性支持集成到 MediaPipe 中,并使用 Chrome 的子组操作原型对其进行了测试。
我们在大语言模型预填充阶段的 GPU 内核中使用了子群组,因此我只会报告预填充阶段的加速效果。在 Intel GPU 上,我们发现子群组的速度比基准速度快了两倍半。不过,这些改进在不同 GPU 上的效果并不一致。
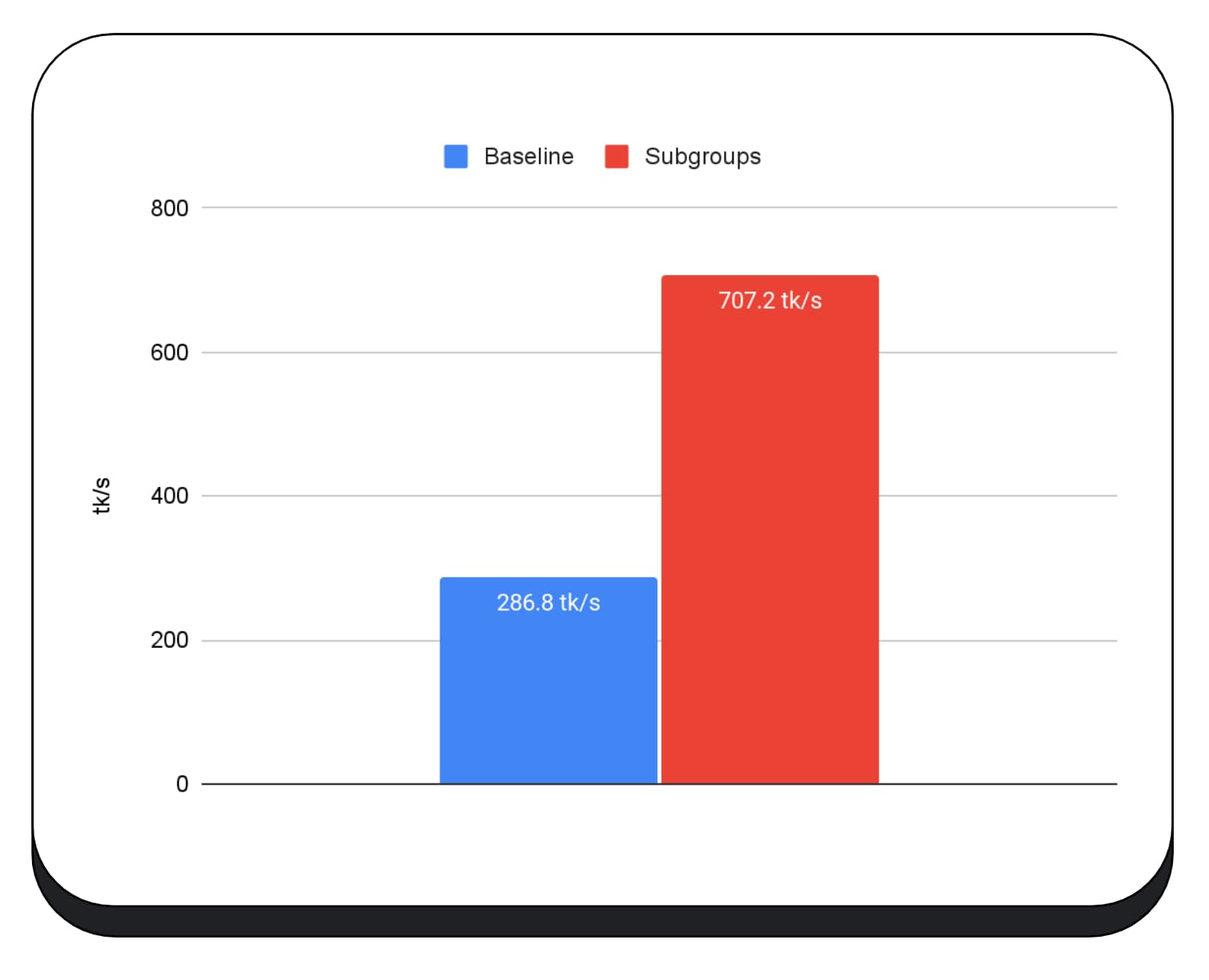
下图显示了在多个消费类 GPU 上应用子群组来优化矩阵乘法微基准测试的结果。矩阵乘法是大语言模型中较重的运算之一。数据显示,在许多 GPU 上,子群组的速度是基准速度的 2 倍、5 倍甚至 13 倍。不过,请注意,在第一个 GPU 上,子群组的效果并不明显。
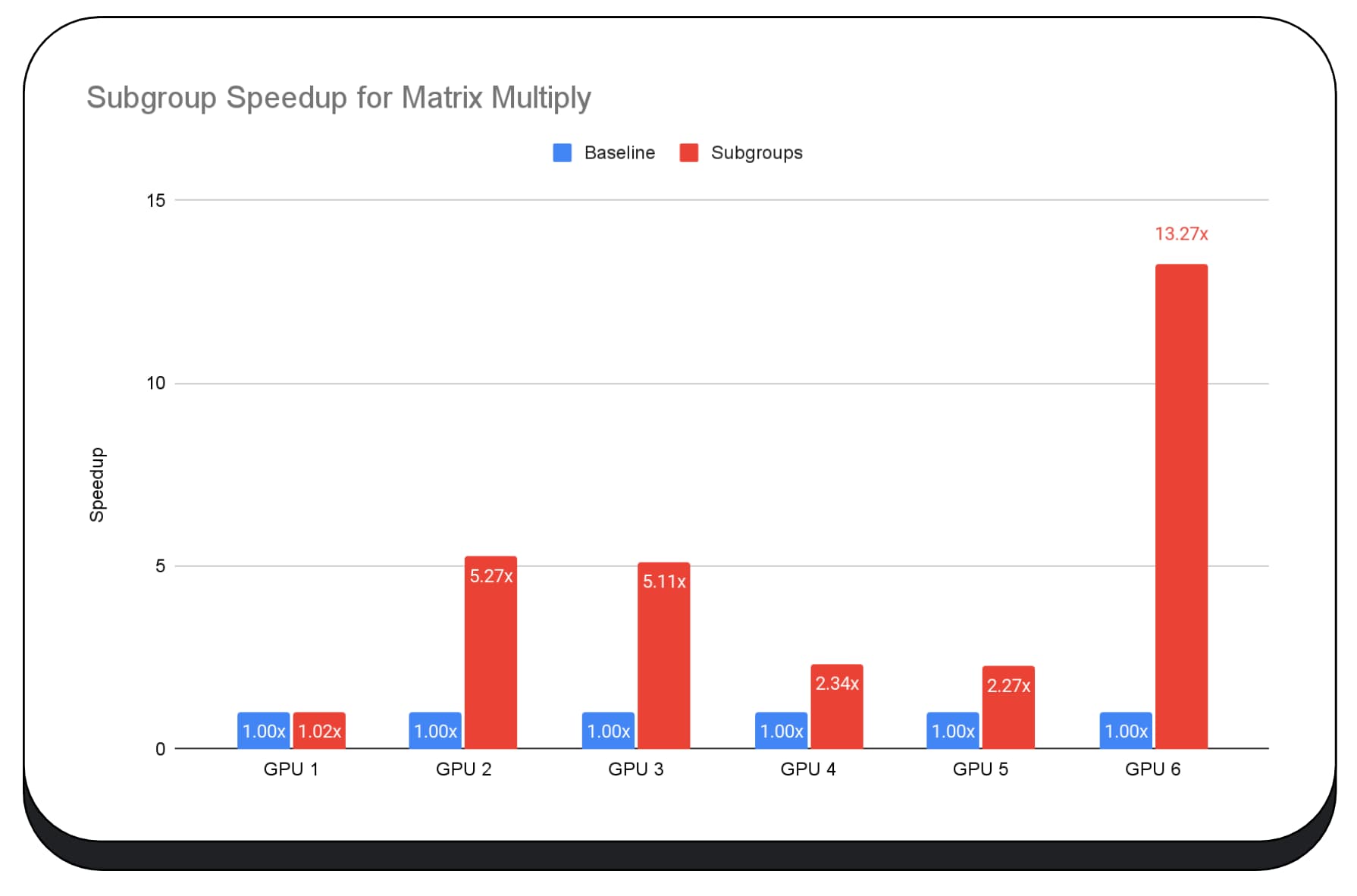
GPU 优化难度较高
最终,优化 GPU 的最佳方式取决于客户提供的 GPU。使用新奇的 GPU 功能并不总能带来预期的效果,因为其中可能涉及许多复杂因素。适用于某个 GPU 的最佳优化策略未必适用于另一个 GPU。
您希望尽可能减少内存带宽,同时充分利用 GPU 的计算线程。
内存访问模式也非常重要。当计算线程以对硬件最优的模式访问内存时,GPU 的性能往往会显著提升。重要提示:不同 GPU 硬件上的性能特性应该有所不同。您可能需要根据 GPU 运行不同的优化。
在下图中,我们使用了相同的矩阵乘法算法,但添加了另一个维度,以进一步展示各种优化策略的影响,以及不同 GPU 的复杂性和差异。我们在此处引入了一种新技术,称为“Swizzle”。混洗会优化内存访问模式,使其更适合硬件。
您可以看到,内存交换有很大影响;有时,其影响甚至比子组更大。在 GPU 6 上,swizzle 可将速度提高 12 倍,而子组可将速度提高 13 倍。两者结合使用,速度可提升 26 倍。对于其他 GPU,有时结合使用交换和子组的效果会比单独使用任一方法更好。在其他 GPU 上,仅使用 swizzle 的性能最佳。
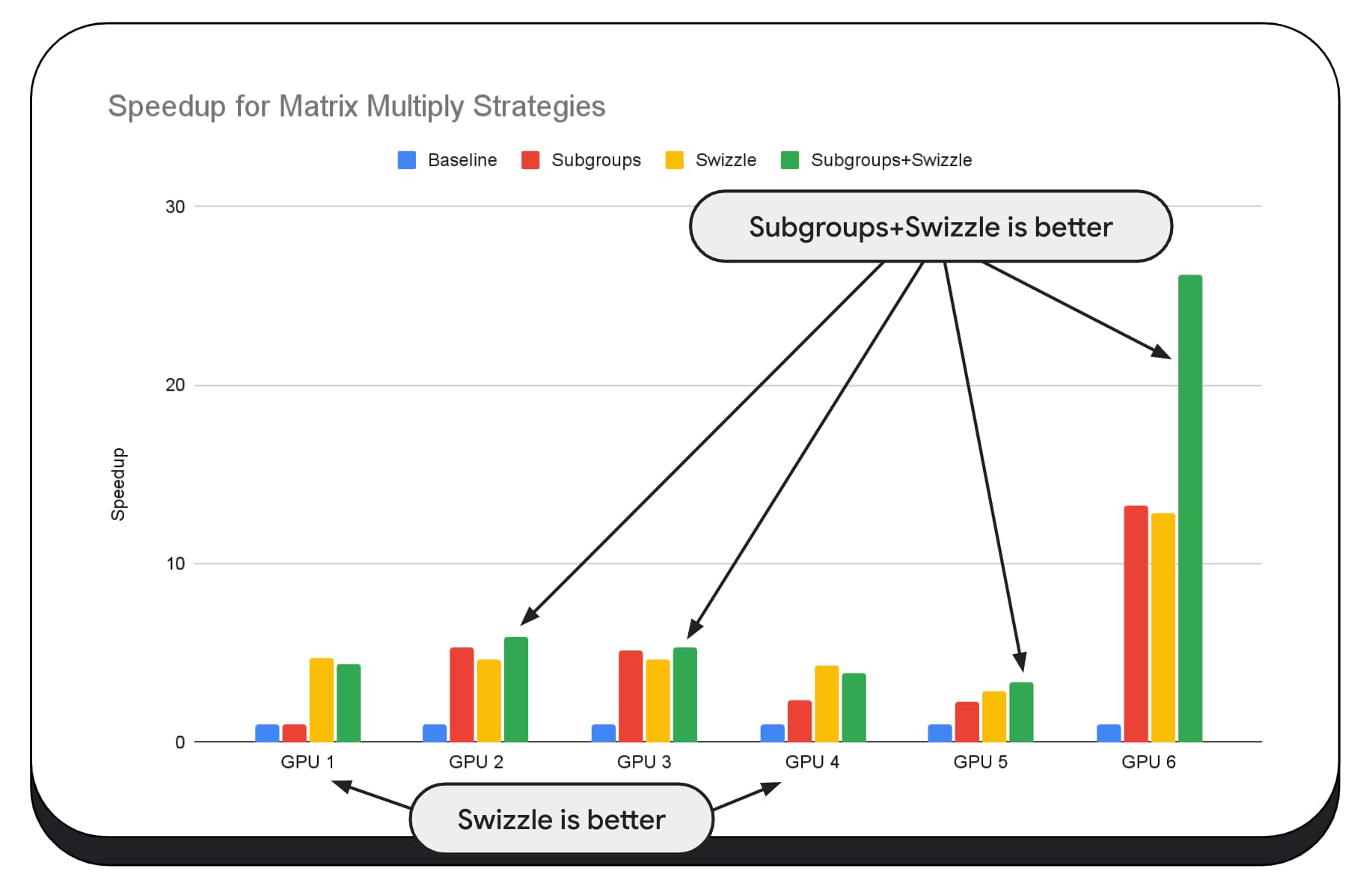
为了让 GPU 算法能够在每部硬件上正常运行,需要具备丰富的专业知识。但值得庆幸的是,有大量优秀的开发者在致力于构建更高级别的库框架,例如 Mediapipe、Transformers.js、Apache TVM、ONNX Runtime Web 等。
库和框架非常适合处理管理多样化 GPU 架构的复杂性,并生成可在客户端上正常运行的平台专用代码。
要点总结
Chrome 团队将继续帮助改进 WebAssembly 和 WebGPU 标准,以便为机器学习工作负载改进 Web 平台。我们正在投资于更快的计算基元、更好的跨 Web 标准互操作性,并确保各种大小的模型都能在各种设备上高效运行。
我们的目标是最大限度地发挥该平台的功能,同时保留 Web 的优势:覆盖面、易用性和可移植性。我们并非单独完成这项工作。我们正在与 W3C 的其他浏览器供应商以及许多开发合作伙伴合作。
在使用 WebAssembly 和 WebGPU 时,希望您能记住以下几点:
- AI 推理功能现已在网站上推出,可跨设备使用。这带来了在客户端设备上运行的优势,例如降低服务器成本、延迟时间短以及增强隐私保护。
- 虽然所讨论的许多功能主要与框架作者相关,但您的应用也可以受益,而不会产生太多开销。
- 网络标准是动态的,并且会不断发展变化,我们随时欢迎您提供反馈。请分享您对 WebAssembly 和 WebGPU 的看法。
致谢
我们要感谢 Intel 网站图形团队,他们在推动 WebGPU f16 和打包整数点积产品功能方面发挥了重要作用。我们要感谢 W3C WebAssembly 和 WebGPU 工作组的其他成员,包括其他浏览器供应商。
感谢 Google 和开源社区的 AI 和机器学习团队,他们是出色的合作伙伴。当然,还有所有促成这一切的团队成员。