
Tài liệu này là phần tiếp theo của Các tính năng nâng cao WebAssembly và WebGPU để AI trên web hoạt động nhanh hơn, phần 1. Bạn nên đọc bài đăng này hoặc xem buổi trò chuyện tại IO 24 trước khi tiếp tục.



WebGPU
WebGPU cấp cho các ứng dụng web quyền truy cập vào phần cứng GPU của máy khách để thực hiện các phép tính song song hiệu quả. Kể từ khi ra mắt WebGPU trong Chrome, chúng tôi đã thấy các bản minh hoạ đáng kinh ngạc về trí tuệ nhân tạo (AI) và học máy (ML) trên web.
Ví dụ: Web Stable Diffusion đã chứng minh rằng có thể sử dụng AI để tạo hình ảnh từ văn bản ngay trong trình duyệt. Đầu năm nay, nhóm Mediapipe của Google đã phát hành hỗ trợ thử nghiệm cho suy luận mô hình ngôn ngữ lớn.
Ảnh động sau đây cho thấy Gemma, mô hình ngôn ngữ lớn (LLM) nguồn mở của Google, chạy hoàn toàn trên thiết bị trong Chrome theo thời gian thực.
Bản minh hoạ của Huggin Face sau đây về Mô hình phân đoạn bất kỳ của Meta tạo ra mặt nạ đối tượng chất lượng cao hoàn toàn trên máy khách.
Đây chỉ là một vài dự án tuyệt vời thể hiện sức mạnh của WebGPU cho AI và ML. WebGPU cho phép các mô hình này và các mô hình khác chạy nhanh hơn đáng kể so với trên CPU.
Điểm chuẩn WebGPU của Hugging Face để nhúng văn bản cho thấy tốc độ tăng lên đáng kể so với việc triển khai CPU của cùng một mô hình. Trên máy tính xách tay Apple M1 Max, WebGPU nhanh hơn gấp hơn 30 lần. Một số người khác đã báo cáo rằng WebGPU tăng tốc điểm chuẩn hơn 120 lần.
Cải thiện các tính năng WebGPU cho AI và ML
WebGPU rất phù hợp với các mô hình AI và ML, có thể có hàng tỷ tham số nhờ khả năng hỗ trợ lập trình đổ bóng điện toán. Chương trình đổ bóng điện toán chạy trên GPU và giúp chạy các phép toán song song trên mảng với số lượng lớn dữ liệu.
Trong số nhiều điểm cải tiến đối với WebGPU trong năm qua, chúng tôi đã tiếp tục bổ sung thêm nhiều tính năng để cải thiện hiệu suất của công nghệ học máy và trí tuệ nhân tạo trên web. Gần đây, chúng tôi đã ra mắt hai tính năng mới: dấu phẩy động 16 bit và tích dấu chấm số nguyên đóng gói.
Dấu phẩy động 16 bit
Hãy nhớ rằng các khối lượng công việc về học máy không yêu cầu độ chính xác. shader-f16 là một tính năng cho phép sử dụng loại f16 trong ngôn ngữ đổ bóng WebGPU. Loại dấu phẩy động này chiếm 16 bit thay vì 32 bit thông thường. f16 có phạm vi nhỏ hơn và kém chính xác hơn, nhưng đối với nhiều mô hình học máy, điều này là đủ.
Tính năng này giúp tăng hiệu quả theo một số cách:
Giảm bộ nhớ: Tensor có các phần tử f16 chiếm một nửa không gian, giúp giảm một nửa mức sử dụng bộ nhớ. Các phép tính của GPU thường bị tắc nghẽn về băng thông bộ nhớ, vì vậy, việc giảm một nửa bộ nhớ thường có nghĩa là chương trình đổ bóng chạy nhanh gấp đôi. Về mặt kỹ thuật, bạn không cần f16 để tiết kiệm băng thông bộ nhớ. Bạn có thể lưu trữ dữ liệu ở định dạng có độ chính xác thấp, sau đó mở rộng dữ liệu đó thành f32 đầy đủ trong chương trình đổ bóng để tính toán. Tuy nhiên, GPU sẽ tiêu tốn thêm năng lượng tính toán để đóng gói và giải nén dữ liệu.
Giảm việc chuyển đổi dữ liệu: f16 sử dụng ít điện toán hơn bằng cách giảm thiểu việc chuyển đổi dữ liệu. Bạn có thể lưu trữ dữ liệu có độ chính xác thấp rồi sử dụng trực tiếp mà không cần chuyển đổi.
Tăng tính song song: GPU hiện đại có thể chứa nhiều giá trị hơn cùng lúc trong các đơn vị thực thi của GPU, cho phép GPU thực hiện nhiều phép tính song song hơn. Ví dụ: một GPU hỗ trợ tối đa 5 nghìn tỷ phép tính dấu phẩy động f32 mỗi giây có thể hỗ trợ 10 nghìn tỷ phép tính dấu phẩy động f16 mỗi giây.
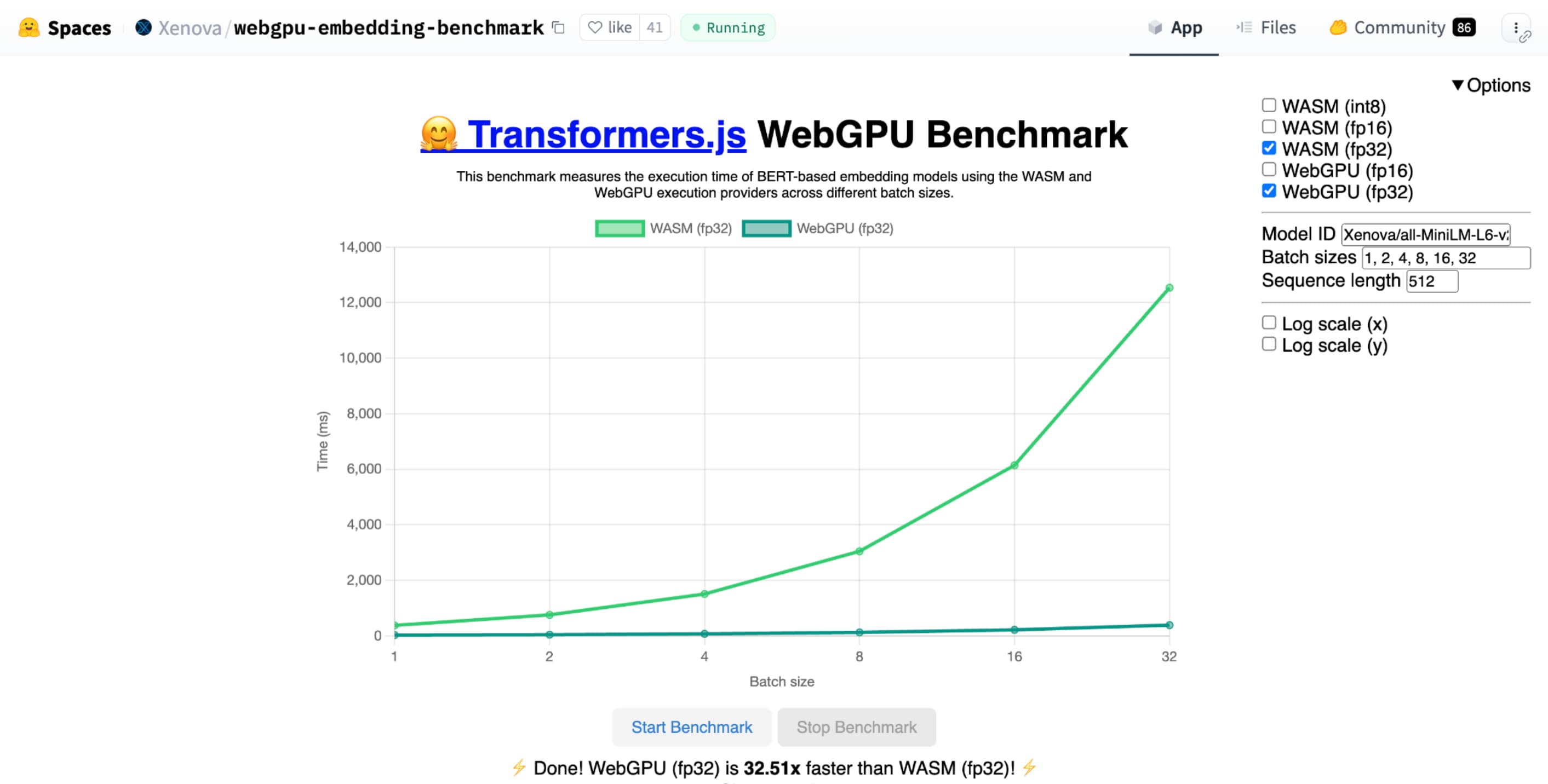
shader-f16, phép đo điểm chuẩn WebGPU để nhúng văn bản của Hugging Face chạy phép đo điểm chuẩn nhanh hơn 3 lần so với f32 trên máy tính xách tay Apple M1 Max.
WebLLM là một dự án có thể chạy nhiều mô hình ngôn ngữ lớn. Công cụ này sử dụng Apache TVM, một khung biên dịch học máy nguồn mở.
Tôi đã yêu cầu WebLLM lên kế hoạch cho một chuyến đi đến Paris, sử dụng mô hình Llama 3 có 8 tỷ tham số. Kết quả cho thấy trong giai đoạn điền sẵn của mô hình, f16 nhanh hơn f32 gấp 2,1 lần. Trong giai đoạn giải mã, tốc độ nhanh hơn 1,3 lần.
Trước tiên, các ứng dụng phải xác nhận rằng bộ chuyển đổi GPU hỗ trợ f16 và nếu có, hãy bật bộ chuyển đổi đó một cách rõ ràng khi yêu cầu thiết bị GPU. Nếu f16 không được hỗ trợ, bạn không thể yêu cầu f16 trong mảng requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Sau đó, trong chương trình đổ bóng WebGPU, bạn phải bật f16 ở trên cùng một cách rõ ràng. Sau đó, bạn có thể sử dụng biến này trong chương trình đổ bóng như bất kỳ kiểu dữ liệu float nào khác.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Tích vô hướng số nguyên đóng gói
Nhiều mô hình vẫn hoạt động tốt chỉ với độ chính xác 8 bit (nửa f16). Phương pháp này phổ biến trong các LLM và mô hình hình ảnh để phân đoạn và nhận dạng đối tượng. Tuy nhiên, chất lượng đầu ra của các mô hình sẽ giảm đi khi độ chính xác thấp hơn, vì vậy, việc lượng tử hoá 8 bit không phù hợp với mọi ứng dụng.
Có tương đối ít GPU hỗ trợ giá trị 8 bit ngay từ đầu. Đây là lúc các phép nhân dấu chấm số nguyên đóng gói phát huy tác dụng. Chúng tôi đã phát hành DP4a trong Chrome 123.
GPU hiện đại có các hướng dẫn đặc biệt để lấy hai số nguyên 32 bit, diễn giải từng số nguyên là 4 số nguyên 8 bit được đóng gói liên tiếp và tính toán tích vô hướng giữa các thành phần của chúng.
Điều này đặc biệt hữu ích cho AI và học máy vì hạt nhân nhân ma trận bao gồm rất nhiều tích vô hướng.
Ví dụ: hãy nhân một ma trận 4 x 8 với một vectơ 8 x 1. Để tính toán điều này, bạn cần thực hiện 4 phép tích vô hướng để tính toán từng giá trị trong vectơ đầu ra; A, B, C và D.
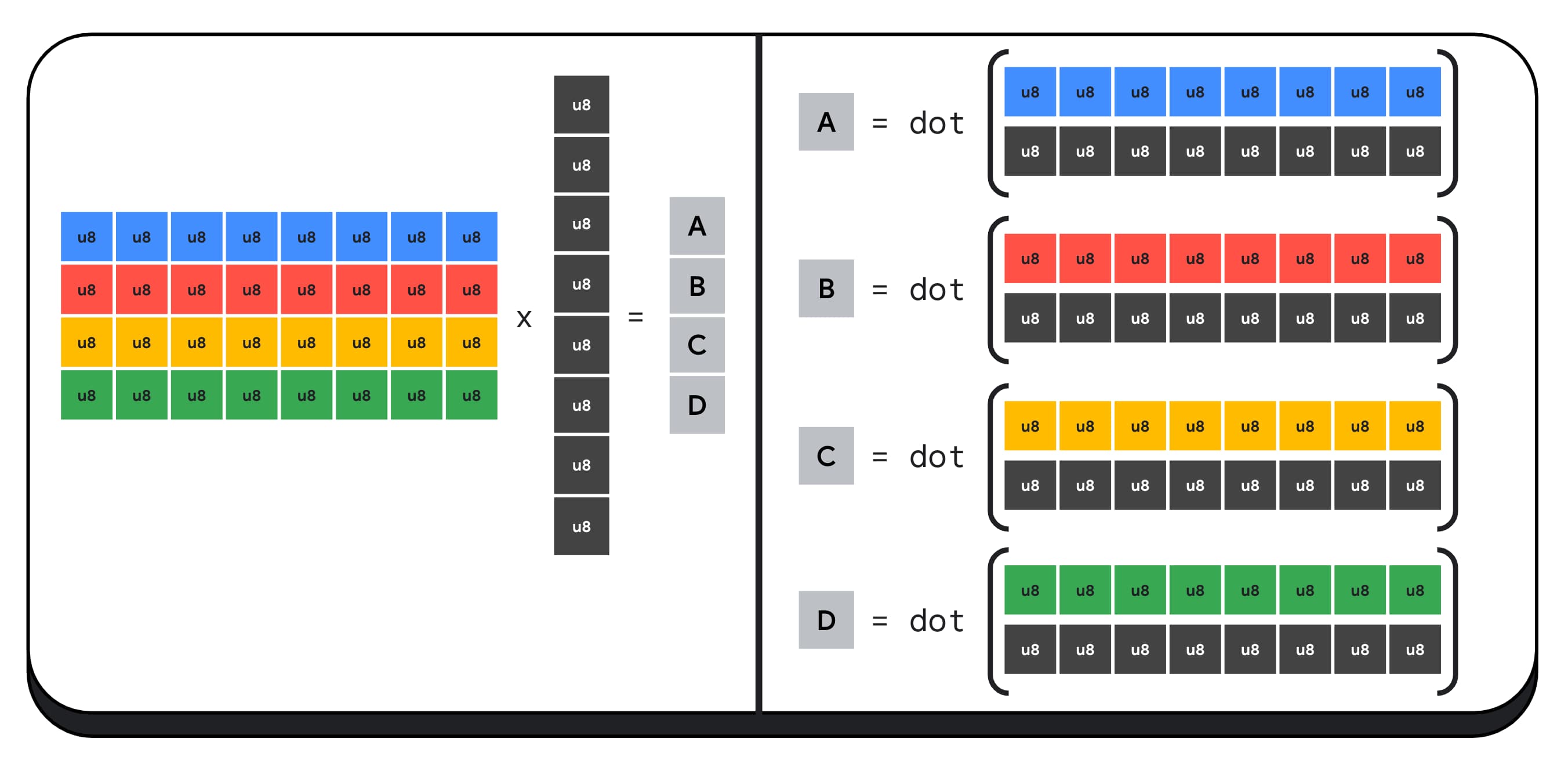
Quy trình tính toán từng kết quả đầu ra này đều giống nhau; chúng ta sẽ xem xét các bước liên quan đến việc tính toán một trong số đó. Trước khi thực hiện bất kỳ phép tính nào, trước tiên, chúng ta cần chuyển đổi dữ liệu số nguyên 8 bit thành một loại dữ liệu mà chúng ta có thể thực hiện phép tính số học, chẳng hạn như f16. Sau đó, chúng ta chạy phép nhân theo phần tử và cuối cùng, cộng tất cả các tích lại với nhau. Tổng cộng, đối với toàn bộ phép nhân ma trận-vectơ, chúng ta thực hiện 40 lượt chuyển đổi số nguyên sang số thực để giải nén dữ liệu, 32 phép nhân số thực và 28 phép cộng số thực.
Đối với các ma trận lớn hơn có nhiều phép toán hơn, tích vô hướng số nguyên đóng gói có thể giúp giảm khối lượng công việc.
Đối với mỗi đầu ra trong vectơ kết quả, chúng ta thực hiện hai phép tính tích vô hướng đóng gói bằng cách sử dụng Ngôn ngữ đổ bóng WebGPU tích hợp sẵn dot4U8Packed, sau đó cộng các kết quả lại với nhau. Tổng cộng, đối với toàn bộ phép nhân ma trận-vectơ, chúng ta không thực hiện bất kỳ lượt chuyển đổi dữ liệu nào. Chúng ta thực thi 8 phép nhân dấu chấm đóng gói và 4 phép cộng số nguyên.
Chúng tôi đã thử nghiệm các phép nhân dấu chấm số nguyên đóng gói với dữ liệu 8 bit trên nhiều GPU tiêu dùng. So với dấu phẩy động 16 bit, chúng ta có thể thấy rằng 8 bit nhanh hơn từ 1,6 đến 2,8 lần. Khi chúng ta sử dụng thêm các tích dấu chấm số nguyên đóng gói, hiệu suất sẽ còn tốt hơn nữa. Nhanh hơn từ 1,7 đến 2,9 lần.
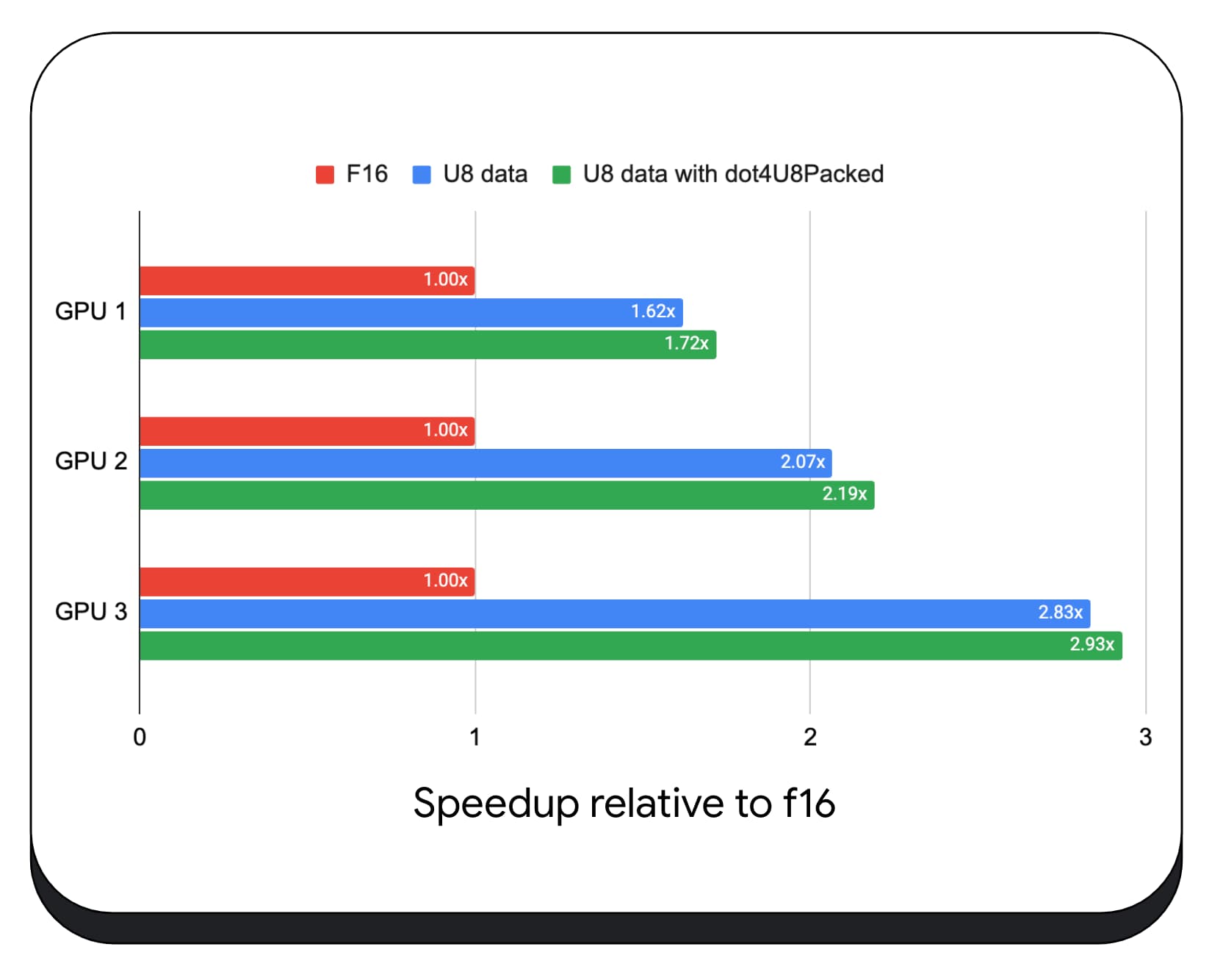
Kiểm tra khả năng hỗ trợ trình duyệt bằng thuộc tính wgslLanguageFeatures. Nếu GPU không hỗ trợ các sản phẩm dấu chấm đóng gói theo cách gốc, thì trình duyệt sẽ tự triển khai polyfill.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Đoạn mã sau đây cho thấy sự khác biệt (diff) nêu bật những thay đổi cần thiết để sử dụng các sản phẩm số nguyên đóng gói trong chương trình đổ bóng WebGPU.
Trước – Một chương trình đổ bóng WebGPU tích luỹ một phần tích vô hướng vào biến "sum". Ở cuối vòng lặp, "sum" giữ tích vô hướng đầy đủ giữa một vectơ và một hàng của ma trận đầu vào.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Sau – Một chương trình đổ bóng WebGPU được viết để sử dụng tích vô hướng số nguyên đóng gói. Điểm khác biệt chính là thay vì tải 4 giá trị float ra khỏi vectơ và ma trận, chương trình đổ bóng này sẽ tải một số nguyên 32 bit. Số nguyên 32 bit này chứa dữ liệu của 4 giá trị số nguyên 8 bit. Sau đó, chúng ta gọi dot4U8Packed để tính tích vô hướng của hai giá trị.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Cả dấu phẩy động 16 bit và tích dấu chấm số nguyên đóng gói đều là các tính năng được cung cấp trong Chrome để tăng tốc AI và ML. Điểm nổi 16 bit có sẵn khi phần cứng hỗ trợ và Chrome triển khai các phép nhân dấu chấm số nguyên đóng gói trên tất cả thiết bị.
Bạn có thể sử dụng các tính năng này trong Chrome phiên bản ổn định ngay hôm nay để đạt được hiệu suất tốt hơn.
Tính năng đề xuất
Trong tương lai, chúng tôi sẽ nghiên cứu thêm hai tính năng: nhóm con và phép nhân ma trận hợp tác.
Tính năng nhóm con cho phép tính song song cấp SIMD để giao tiếp hoặc thực hiện các phép toán tập thể, chẳng hạn như tổng của hơn 16 số. Điều này cho phép chia sẻ dữ liệu hiệu quả giữa các luồng. Các nhóm con được hỗ trợ trên các API GPU hiện đại, với nhiều tên và ở các dạng khác nhau.
Chúng tôi đã chắt lọc tập hợp thông tin chung thành một đề xuất mà chúng tôi đã đưa đến nhóm chuẩn hoá WebGPU. Ngoài ra, chúng tôi đã tạo nguyên mẫu cho các nhóm con trong Chrome bằng một cờ thử nghiệm và đưa kết quả ban đầu vào cuộc thảo luận. Vấn đề chính là làm cách nào để đảm bảo hành vi di động.
Nhân ma trận cộng tác là một tính năng mới bổ sung cho GPU. Bạn có thể chia một phép nhân ma trận lớn thành nhiều phép nhân ma trận nhỏ hơn. Phép nhân ma trận cộng tác thực hiện phép nhân trên các khối có kích thước cố định nhỏ hơn này trong một bước logic duy nhất. Trong bước đó, một nhóm luồng sẽ cộng tác hiệu quả để tính toán kết quả.
Chúng tôi đã khảo sát khả năng hỗ trợ trong các API GPU cơ bản và dự định trình bày một đề xuất cho nhóm chuẩn hoá WebGPU. Cũng như các nhóm con, chúng tôi dự kiến phần lớn nội dung thảo luận sẽ xoay quanh khả năng di chuyển.
Để đánh giá hiệu suất của các thao tác trong nhóm con, trong một ứng dụng thực tế, chúng tôi đã tích hợp tính năng hỗ trợ thử nghiệm cho các nhóm con vào MediaPipe và kiểm thử tính năng này bằng nguyên mẫu của Chrome cho các thao tác trong nhóm con.
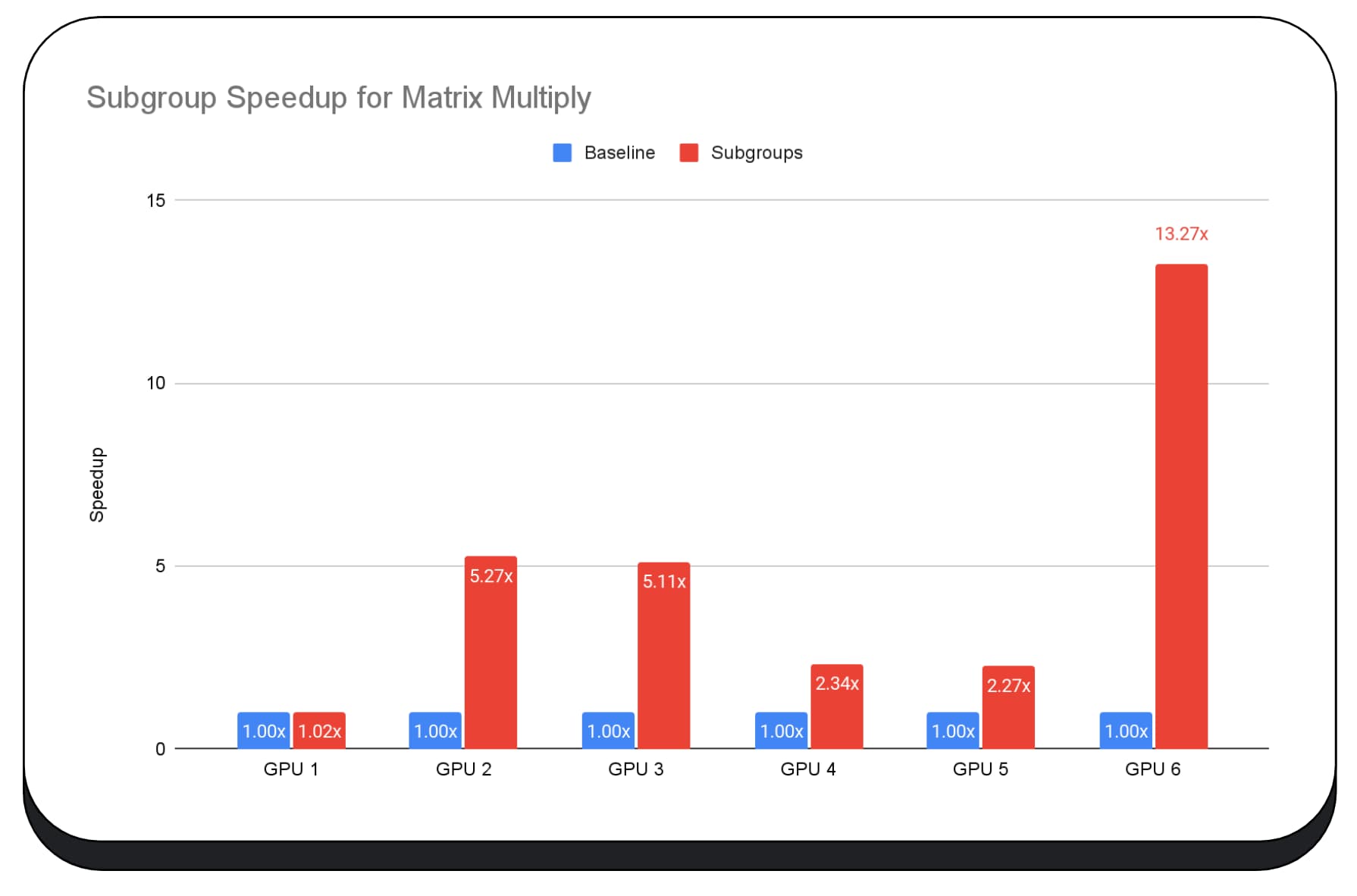
Chúng tôi đã sử dụng các nhóm con trong hạt nhân GPU của giai đoạn điền sẵn của mô hình ngôn ngữ lớn, vì vậy, tôi chỉ báo cáo tốc độ tăng cho giai đoạn điền sẵn. Trên GPU Intel, chúng ta thấy rằng các nhóm con hoạt động nhanh hơn gấp 2,5 lần so với đường cơ sở. Tuy nhiên, những điểm cải tiến này không nhất quán trên các GPU khác nhau.
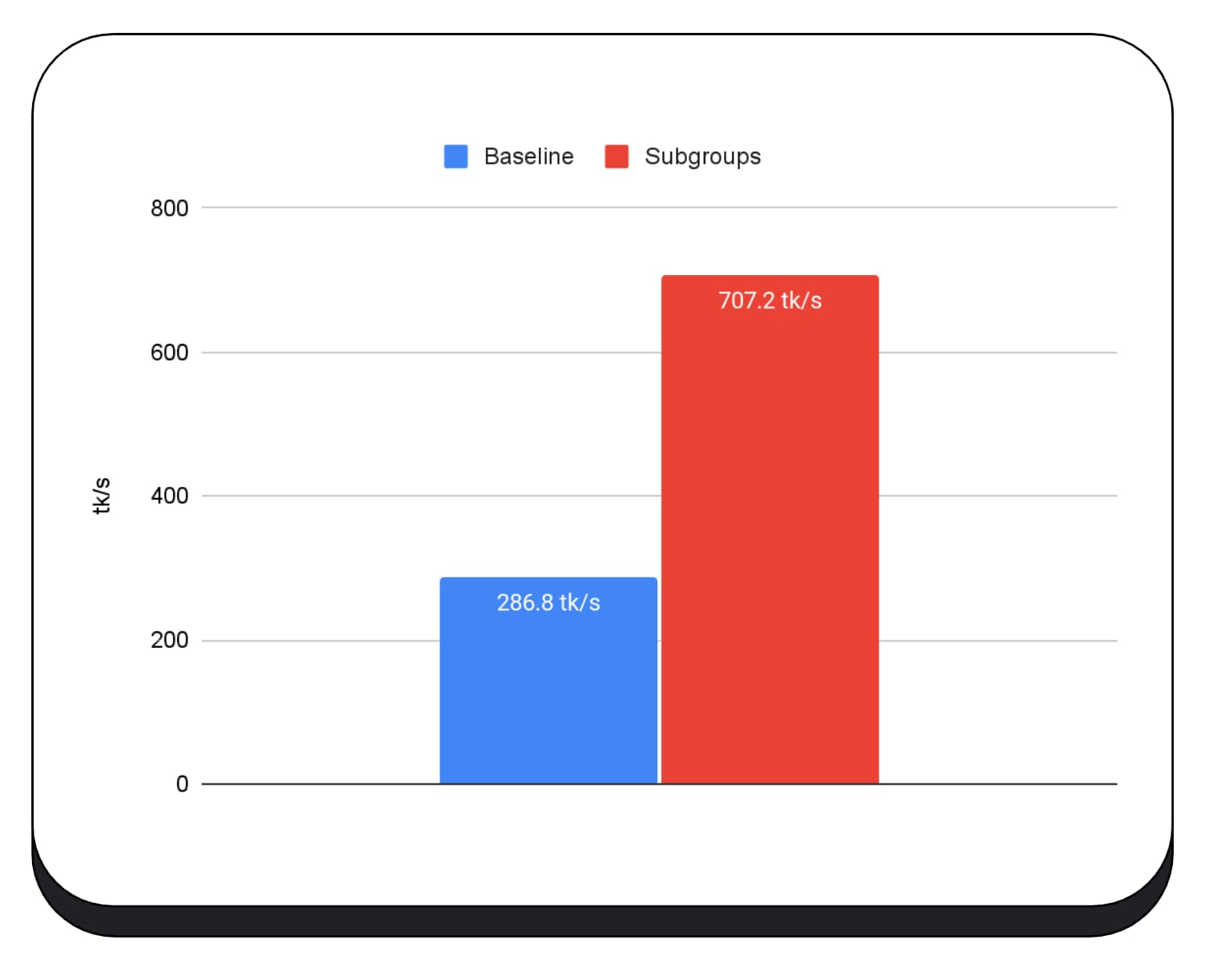
Biểu đồ tiếp theo cho thấy kết quả của việc áp dụng các nhóm con để tối ưu hoá phép nhân ma trận vi điểm chuẩn trên nhiều GPU tiêu dùng. Nhân ma trận là một trong những phép toán nặng hơn trong các mô hình ngôn ngữ lớn. Dữ liệu cho thấy rằng trên nhiều GPU, các nhóm con làm tăng tốc độ gấp 2, 5 và thậm chí là 13 lần so với đường cơ sở. Tuy nhiên, hãy lưu ý rằng trên GPU đầu tiên, các nhóm con không tốt hơn chút nào.
Khó tối ưu hoá GPU
Cuối cùng, cách tốt nhất để tối ưu hoá GPU phụ thuộc vào GPU mà ứng dụng cung cấp. Việc sử dụng các tính năng GPU mới và hấp dẫn không phải lúc nào cũng mang lại hiệu quả như mong đợi, vì có thể có nhiều yếu tố phức tạp liên quan. Chiến lược tối ưu hoá tốt nhất trên một GPU có thể không phải là chiến lược tốt nhất trên một GPU khác.
Bạn muốn giảm thiểu băng thông bộ nhớ, đồng thời sử dụng tối đa các luồng điện toán của GPU.
Mẫu truy cập bộ nhớ cũng có thể rất quan trọng. GPU thường hoạt động hiệu quả hơn nhiều khi các luồng điện toán truy cập vào bộ nhớ theo một mẫu tối ưu cho phần cứng. Quan trọng: Bạn nên mong đợi các đặc điểm hiệu suất khác nhau trên phần cứng GPU khác nhau. Bạn có thể cần chạy nhiều tính năng tối ưu hoá tuỳ thuộc vào GPU.
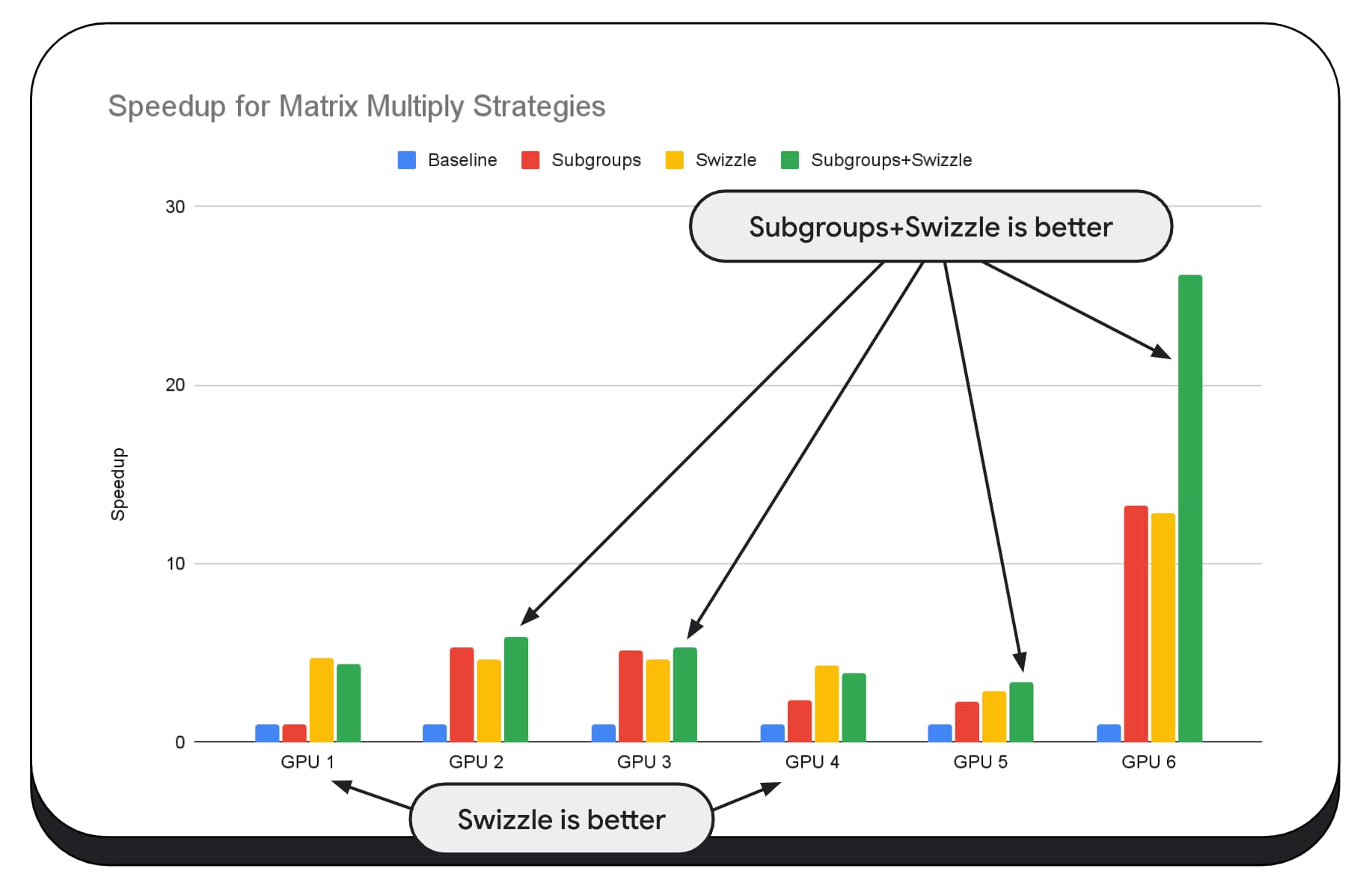
Trong biểu đồ sau, chúng tôi đã sử dụng cùng một thuật toán nhân ma trận, nhưng thêm một phương diện khác để minh hoạ rõ hơn tác động của nhiều chiến lược tối ưu hoá, cũng như độ phức tạp và độ biến thiên trên nhiều GPU. Chúng tôi đã giới thiệu một kỹ thuật mới tại đây, gọi là "Swizzle". Swizzle tối ưu hoá các mẫu truy cập bộ nhớ để phù hợp hơn với phần cứng.
Bạn có thể thấy rằng việc hoán đổi bộ nhớ có tác động đáng kể; đôi khi, nó còn tác động nhiều hơn cả các nhóm con. Trên GPU 6, swizzle giúp tăng tốc 12 lần, trong khi các nhóm con giúp tăng tốc 13 lần. Khi kết hợp, các tính năng này giúp tăng tốc đáng kinh ngạc lên 26 lần. Đối với các GPU khác, đôi khi việc kết hợp swizzle và nhóm con sẽ mang lại hiệu suất tốt hơn so với việc chỉ sử dụng một trong hai. Còn trên các GPU khác, việc chỉ sử dụng swizzle sẽ mang lại hiệu suất tốt nhất.
Việc điều chỉnh và tối ưu hoá các thuật toán GPU để hoạt động tốt trên mọi phần cứng có thể đòi hỏi nhiều kiến thức chuyên môn. Nhưng rất may là có rất nhiều công việc xuất sắc được đưa vào các khung thư viện cấp cao hơn, chẳng hạn như Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web, v.v.
Thư viện và khung được định vị phù hợp để xử lý sự phức tạp của việc quản lý nhiều cấu trúc GPU và tạo mã dành riêng cho nền tảng sẽ chạy tốt trên ứng dụng.
Cướp lại bóng
Nhóm Chrome tiếp tục giúp phát triển các tiêu chuẩn WebAssembly và WebGPU để cải thiện nền tảng web cho các khối lượng công việc học máy. Chúng tôi đang đầu tư vào các nguyên hàm điện toán nhanh hơn, khả năng tương tác tốt hơn trên các tiêu chuẩn web và đảm bảo rằng cả mô hình lớn và nhỏ đều có thể chạy hiệu quả trên các thiết bị.
Mục tiêu của chúng tôi là tối đa hoá các tính năng của nền tảng này trong khi vẫn giữ lại những ưu điểm tốt nhất của web: phạm vi tiếp cận, khả năng hữu dụng và khả năng di chuyển. Chúng tôi không đơn độc trong việc này. Chúng tôi đang hợp tác với các nhà cung cấp trình duyệt khác tại W3C và nhiều đối tác phát triển.
Khi làm việc với WebAssembly và WebGPU, bạn cần nhớ những điều sau:
- Tính năng suy luận AI hiện đã có trên web, trên nhiều thiết bị. Điều này mang lại lợi thế khi chạy trên thiết bị khách, chẳng hạn như giảm chi phí máy chủ, độ trễ thấp và tăng quyền riêng tư.
- Mặc dù nhiều tính năng được thảo luận chủ yếu liên quan đến tác giả khung, nhưng ứng dụng của bạn có thể hưởng lợi mà không tốn nhiều chi phí.
- Các tiêu chuẩn web luôn thay đổi và phát triển, vì vậy, chúng tôi luôn mong nhận được ý kiến phản hồi. Chia sẻ ý kiến của bạn về WebAssembly và WebGPU.
Lời cảm ơn
Chúng tôi xin cảm ơn nhóm đồ hoạ web của Intel, những người đã đóng vai trò quan trọng trong việc thúc đẩy WebGPU f16 và các tính năng tích hợp dấu chấm số nguyên. Chúng tôi muốn cảm ơn các thành viên khác của nhóm làm việc WebAssembly và WebGPU tại W3C, bao gồm cả các nhà cung cấp trình duyệt khác.
Cảm ơn các nhóm AI và ML tại Google cũng như trong cộng đồng nguồn mở vì đã trở thành những đối tác tuyệt vời. Và tất nhiên, tất cả các thành viên trong nhóm đã giúp chúng tôi làm được tất cả những điều này.