
Ce document fait suite à Améliorations de WebAssembly et WebGPU pour une IA Web plus rapide, partie 1. Nous vous recommandons de lire cet article ou de regarder la conférence de IO 24 avant de continuer.



WebGPU
WebGPU permet aux applications Web d'accéder au matériel GPU du client pour effectuer des calculs efficaces et hautement parallèles. Depuis le lancement de WebGPU dans Chrome, nous avons vu des démonstrations incroyables de l'intelligence artificielle (IA) et du machine learning (ML) sur le Web.
Par exemple, Web Stable Diffusion a démontré qu'il était possible d'utiliser l'IA pour générer des images à partir de texte, directement dans le navigateur. Plus tôt cette année, l'équipe Mediapipe de Google a publié une version expérimentale de l'inférence de grands modèles de langage.
L'animation suivante montre Gemma, le grand modèle de langage (LLM) Open Source de Google, qui s'exécute entièrement sur l'appareil dans Chrome, en temps réel.
La démo de Hugging Face du modèle Segment Anything de Meta produit des masques d'objets de haute qualité entièrement sur le client.
Ce ne sont là que quelques-uns des projets incroyables qui démontrent la puissance de WebGPU pour l'IA et le ML. WebGPU permet à ces modèles et à d'autres de s'exécuter beaucoup plus rapidement que sur le processeur.
L'analyse comparative WebGPU pour l'embedding de texte de Hugging Face démontre des accélérations considérables par rapport à une implémentation du même modèle sur CPU. Sur un ordinateur portable Apple M1 Max, WebGPU était plus de 30 fois plus rapide. D'autres ont indiqué que WebGPU accélère le benchmark de plus de 120 fois.
Amélioration des fonctionnalités WebGPU pour l'IA et le ML
WebGPU est idéal pour les modèles d'IA et de ML, qui peuvent comporter des milliards de paramètres, grâce à la prise en charge des shaders de calcul. Les nuanceurs de calcul s'exécutent sur le GPU et permettent d'exécuter des opérations de tableau parallèles sur de grands volumes de données.
Parmi les nombreuses améliorations apportées à WebGPU au cours de l'année écoulée, nous avons continué à ajouter des fonctionnalités pour améliorer les performances du ML et de l'IA sur le Web. Nous avons récemment lancé deux nouvelles fonctionnalités: les produits scalaires à virgule flottante 16 bits et les produits scalaires entiers empaquetés.
Valeur à virgule flottante 16 bits
N'oubliez pas que les charges de travail de ML ne nécessitent pas de précision. shader-f16 est une fonctionnalité qui permet d'utiliser le type f16 dans le langage de nuanceur WebGPU. Ce type de nombres à virgule flottante occupe 16 bits au lieu des 32 bits habituels. f16 a une plage plus petite et est moins précis, mais pour de nombreux modèles de ML, cela suffit.
Cette fonctionnalité améliore l'efficacité de plusieurs manières:
Mémoire réduite: les tenseurs avec des éléments f16 occupent la moitié de l'espace, ce qui réduit de moitié l'utilisation de la mémoire. Les calculs du GPU sont souvent limités par la bande passante de la mémoire. Par conséquent, réduire la mémoire de moitié peut souvent permettre aux nuanceurs de s'exécuter deux fois plus rapidement. Techniquement, vous n'avez pas besoin de f16 pour économiser de la bande passante de mémoire. Vous pouvez stocker les données dans un format à faible précision, puis les développer en f32 complet dans le nuanceur pour le calcul. Toutefois, le GPU dépense une puissance de calcul supplémentaire pour emballer et décompresser les données.
Réduction de la conversion des données: f16 consomme moins de calcul en minimisant la conversion des données. Les données à faible précision peuvent être stockées, puis utilisées directement sans conversion.
Parallélisme accru: les GPU modernes peuvent accueillir plus de valeurs simultanément dans les unités d'exécution du GPU, ce qui leur permet d'effectuer un plus grand nombre de calculs parallèles. Par exemple, un GPU compatible avec jusqu'à 5 milliards d'opérations à virgule flottante f32 par seconde peut prendre en charge 10 milliards d'opérations à virgule flottante f16 par seconde.
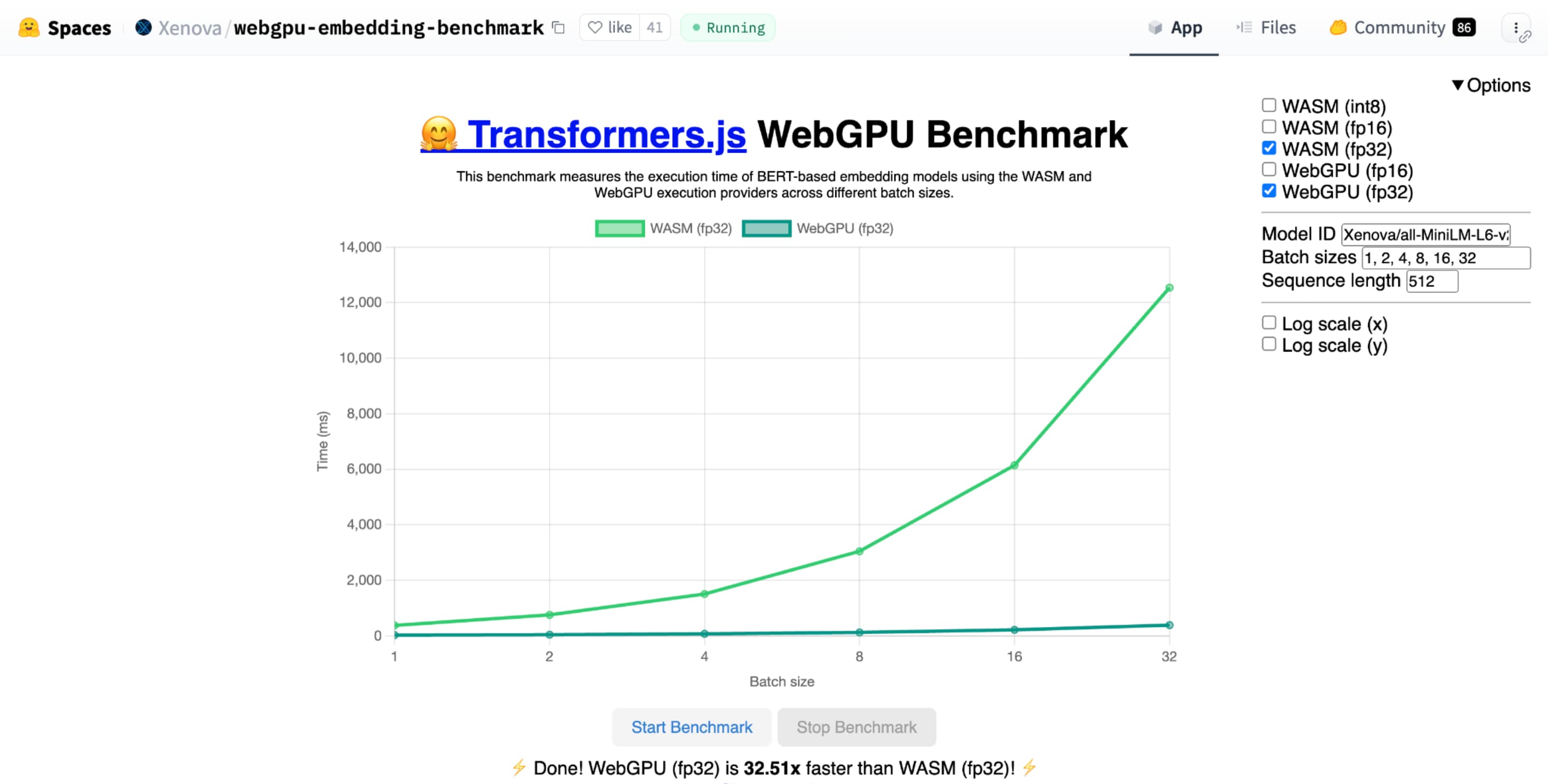
shader-f16, le benchmark WebGPU pour l'intégration de texte de Hugging Face s'exécute trois fois plus rapidement que f32 sur l'ordinateur portable Apple M1 Max.
WebLLM est un projet qui peut exécuter plusieurs grands modèles de langage. Il utilise Apache TVM, un framework de compilation de machine learning Open Source.
J'ai demandé à WebLLM de planifier un voyage à Paris, à l'aide du modèle Llama 3 à huit milliards de paramètres. Les résultats montrent que pendant la phase de préremplissage du modèle, f16 est 2,1 fois plus rapide que f32. Pendant la phase de décodage, il est plus de 1,3 fois plus rapide.
Les applications doivent d'abord confirmer que l'adaptateur GPU est compatible avec f16 et, si c'est le cas, l'activer explicitement lorsqu'elles demandent un appareil GPU. Si f16 n'est pas pris en charge, vous ne pouvez pas le demander dans le tableau requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Ensuite, dans vos nuanceurs WebGPU, vous devez activer explicitement f16 en haut. Vous pouvez ensuite l'utiliser dans le nuanceur comme n'importe quel autre type de données float.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Produits de point entier compressés
De nombreux modèles fonctionnent toujours correctement avec seulement 8 bits de précision (la moitié de f16). Cette approche est populaire parmi les LLM et les modèles d'image pour la segmentation et la reconnaissance d'objets. Toutefois, la qualité de sortie des modèles se dégrade avec une précision moindre. Par conséquent, la quantification sur 8 bits n'est pas adaptée à toutes les applications.
Un nombre relativement faible de GPU sont compatibles en mode natif avec les valeurs 8 bits. C'est là qu'interviennent les produits de point entier empaquetés. Nous avons publié DP4a dans Chrome 123.
Les GPU modernes disposent d'instructions spéciales pour prendre deux entiers 32 bits, les interpréter chacun comme quatre entiers 8 bits empaquetés consécutivement et calculer le produit scalaire entre leurs composants.
Cela est particulièrement utile pour l'IA et le machine learning, car les noyaux de multiplication matricielle sont composés de très nombreux produits scalaires.
Par exemple, multiplions une matrice 4 x 8 par un vecteur 8 x 1. Pour ce faire, vous devez effectuer quatre produits scalaires pour calculer chacune des valeurs du vecteur de sortie : A, B, C et D.
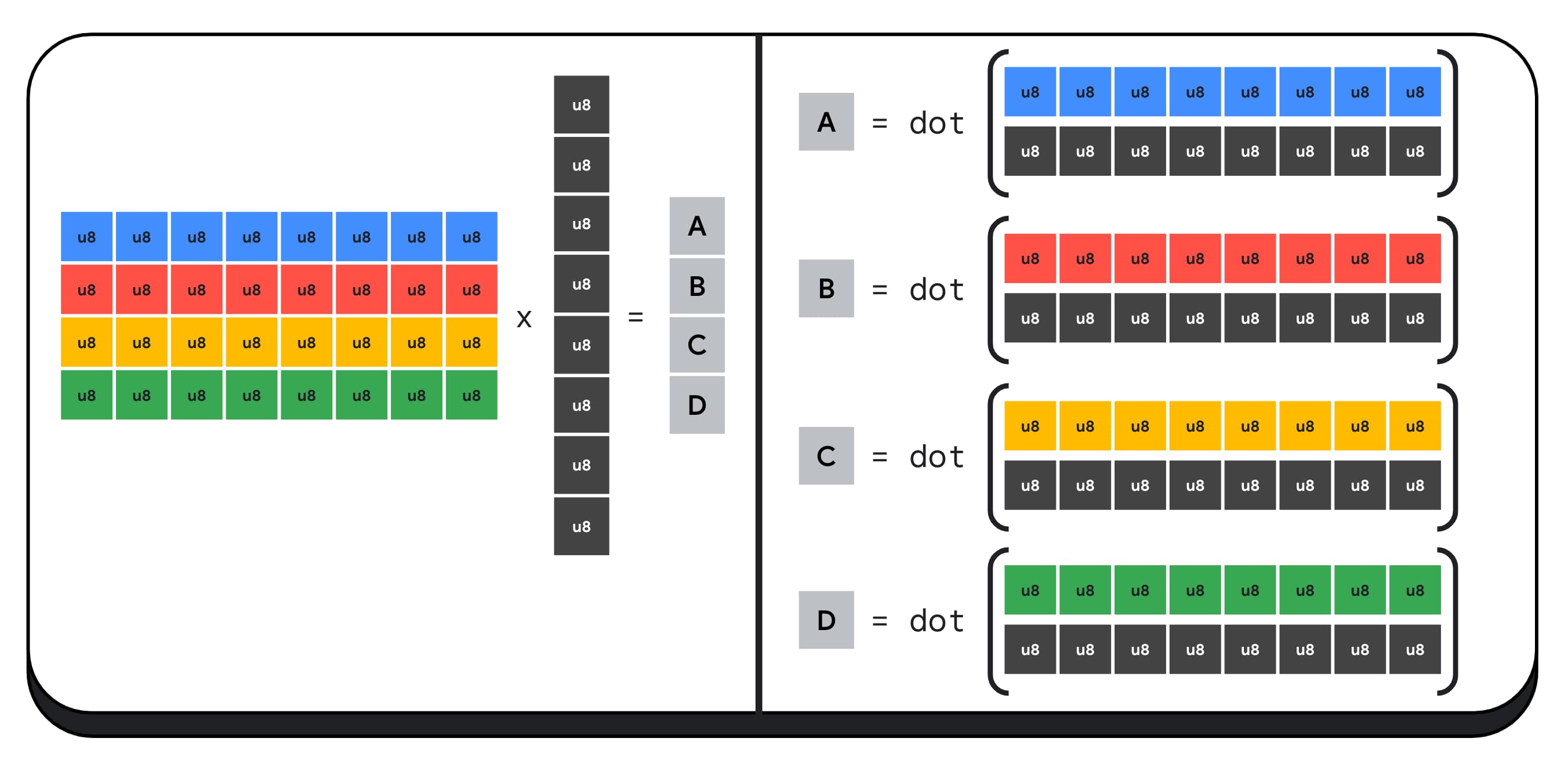
Le processus de calcul de chacune de ces sorties est le même. Nous allons examiner les étapes impliquées dans le calcul de l'une d'entre elles. Avant tout calcul, nous devons d'abord convertir les données entières de 8 bits en un type avec lequel nous pouvons effectuer des opérations arithmétiques, comme f16. Nous effectuons ensuite une multiplication par élément, puis nous additionnons tous les produits. Au total, pour l'ensemble de la multiplication matricielle-vectorielle, nous effectuons 40 conversions d'entiers en nombres à virgule flottante pour décompresser les données, 32 multiplications à virgule flottante et 28 additions à virgule flottante.
Pour les matrices plus grandes avec plus d'opérations, les produits scalaires entiers empaquetés peuvent aider à réduire la quantité de travail.
Pour chacune des sorties du vecteur de résultats, nous effectuons deux opérations de produit scalaire empaquetées à l'aide de la fonction dot4U8Packed intégrée au langage de nuanceur WebGPU, puis nous additionnons les résultats. Au total, pour l'ensemble de la multiplication matricielle-vectorielle, nous n'effectuons aucune conversion de données. Nous exécutons huit produits scalaires empaquetés et quatre additions d'entiers.
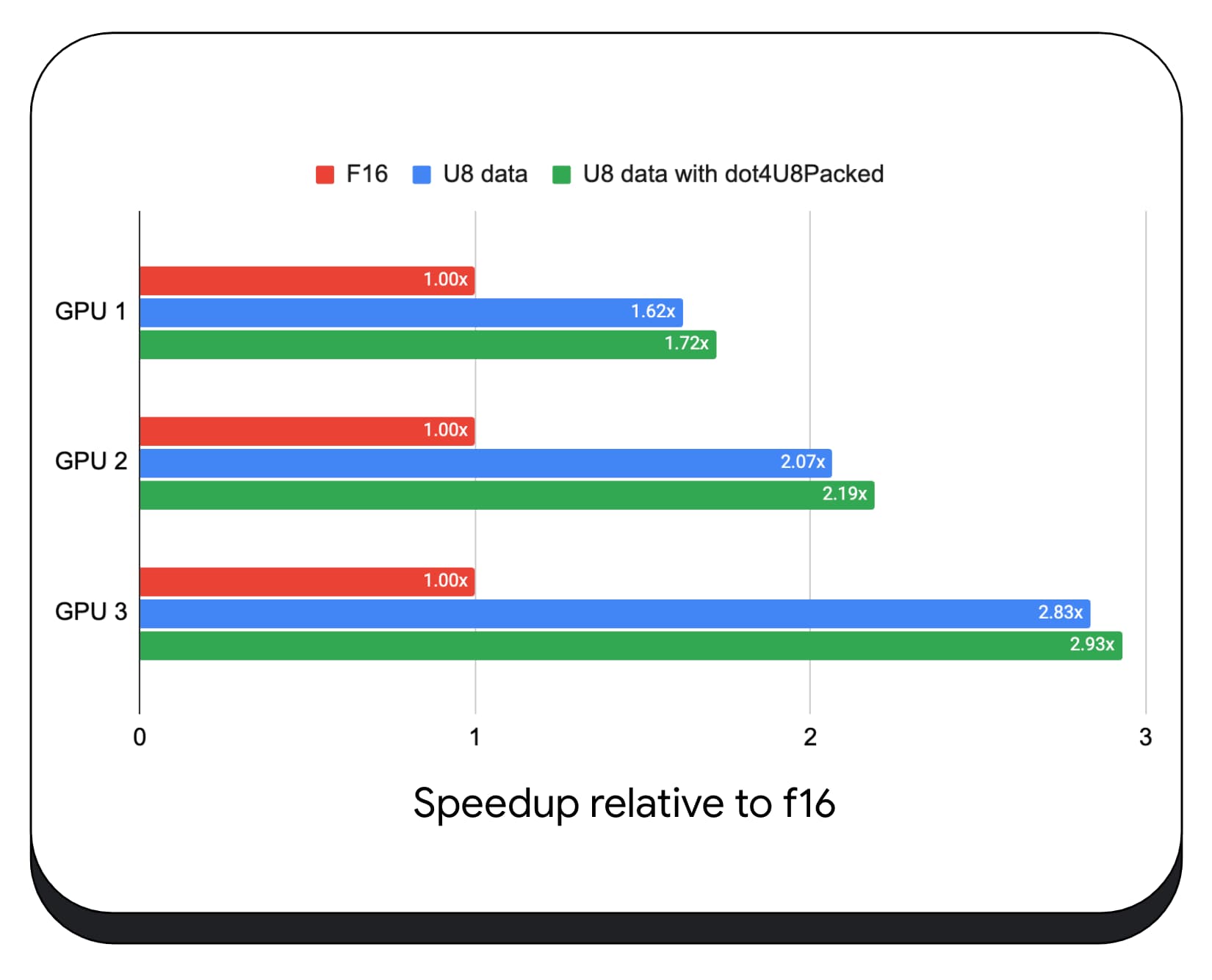
Nous avons testé les produits de pointage entiers empaquetés avec des données 8 bits sur différents GPU grand public. Par rapport à la virgule flottante 16 bits, nous constatons que la virgule flottante 8 bits est 1,6 à 2,8 fois plus rapide. Lorsque nous utilisons également des produits scalaires entiers empaquetés, les performances sont encore meilleures. Il est 1,7 à 2,9 fois plus rapide.
Vérifiez la compatibilité du navigateur avec la propriété wgslLanguageFeatures. Si le GPU n'est pas compatible de manière native avec les produits de points empaquetés, le navigateur polyfille sa propre implémentation.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
La différence de l'extrait de code suivant met en évidence les modifications nécessaires pour utiliser des produits entiers empaquetés dans un nuanceur WebGPU.
Avant : nuanceur WebGPU qui accumule des produits scalaires partiels dans la variable "sum". À la fin de la boucle, "sum" contient le produit scalaire complet entre un vecteur et une ligne de la matrice d'entrée.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Après : nuanceur WebGPU écrit pour utiliser des produits scalaires entiers empaquetés. La principale différence est qu'au lieu de charger quatre valeurs de flottant à partir du vecteur et de la matrice, ce nuanceur charge un seul entier de 32 bits. Cet entier 32 bits contient les données de quatre valeurs entières 8 bits. Nous appelons ensuite dot4U8Packed pour calculer le produit scalaire des deux valeurs.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Les produits à virgule flottante 16 bits et les produits à virgule flottante empaquetés sont des fonctionnalités intégrées à Chrome qui accélèrent l'IA et le ML. Les nombres à virgule flottante 16 bits sont disponibles lorsque le matériel est compatible, et Chrome implémente les produits à virgule flottante entiers empaquetés sur tous les appareils.
Vous pouvez déjà utiliser ces fonctionnalités dans Chrome stable pour améliorer vos performances.
Fonctionnalités proposées
À l'avenir, nous allons étudier deux autres fonctionnalités: les sous-groupes et la multiplication de matrices coopérative.
La fonctionnalité de sous-groupes permet au parallélisme au niveau SIMD de communiquer ou d'effectuer des opérations mathématiques collectives, telles qu'une somme pour plus de 16 nombres. Cela permet un partage de données interthread efficace. Les sous-groupes sont compatibles avec les API de GPU modernes, avec des noms différents et des formes légèrement différentes.
Nous avons condensé l'ensemble commun dans une proposition que nous avons transmise au groupe de normalisation WebGPU. Nous avons également créé des prototypes de sous-groupes dans Chrome à l'aide d'un indicateur expérimental et avons présenté nos résultats initiaux lors de la discussion. Le principal problème est de savoir comment assurer un comportement portable.
La multiplication matricielle coopérative est une fonctionnalité plus récente des GPU. Une multiplication de matrices volumineuse peut être décomposée en plusieurs multiplications de matrices plus petites. La multiplication matricielle coopérative effectue des multiplications sur ces blocs plus petits de taille fixe en une seule étape logique. Au cours de cette étape, un groupe de threads coopère efficacement pour calculer le résultat.
Nous avons examiné la compatibilité dans les API GPU sous-jacentes et prévoyons de présenter une proposition au groupe de normalisation WebGPU. Comme pour les sous-groupes, nous nous attendons à ce que la majeure partie de la discussion porte sur la portabilité.
Pour évaluer les performances des opérations de sous-groupes dans une application réelle, nous avons intégré une prise en charge expérimentale des sous-groupes dans MediaPipe et l'avons testée avec le prototype de Chrome pour les opérations de sous-groupes.
Nous avons utilisé des sous-groupes dans les noyaux GPU de la phase de préremplissage du grand modèle de langage. Je ne communique donc que l'accélération pour la phase de préremplissage. Sur un GPU Intel, nous constatons que les sous-groupes sont deux fois et demie plus rapides que la référence. Cependant, ces améliorations ne sont pas cohérentes entre les différents GPU.
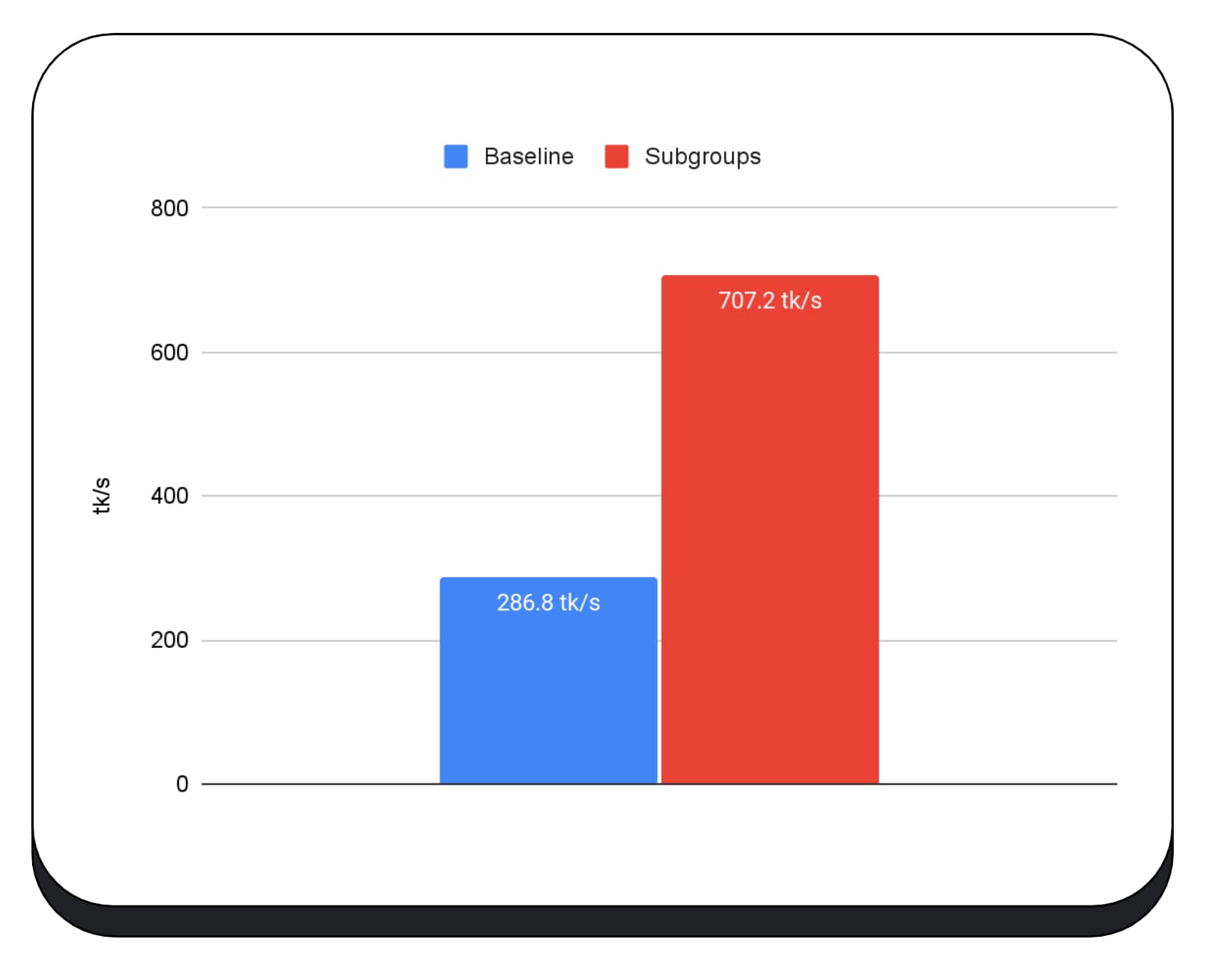
Le graphique suivant présente les résultats de l'application de sous-groupes pour optimiser un micro-benchmark de multiplication de matrices sur plusieurs GPU grand public. La multiplication de matrices est l'une des opérations les plus lourdes dans les grands modèles de langage. Les données montrent que sur de nombreux GPU, les sous-groupes augmentent la vitesse de deux, cinq et même treize fois par rapport à la référence. Toutefois, notez que sur le premier GPU, les sous-groupes ne sont pas beaucoup mieux.
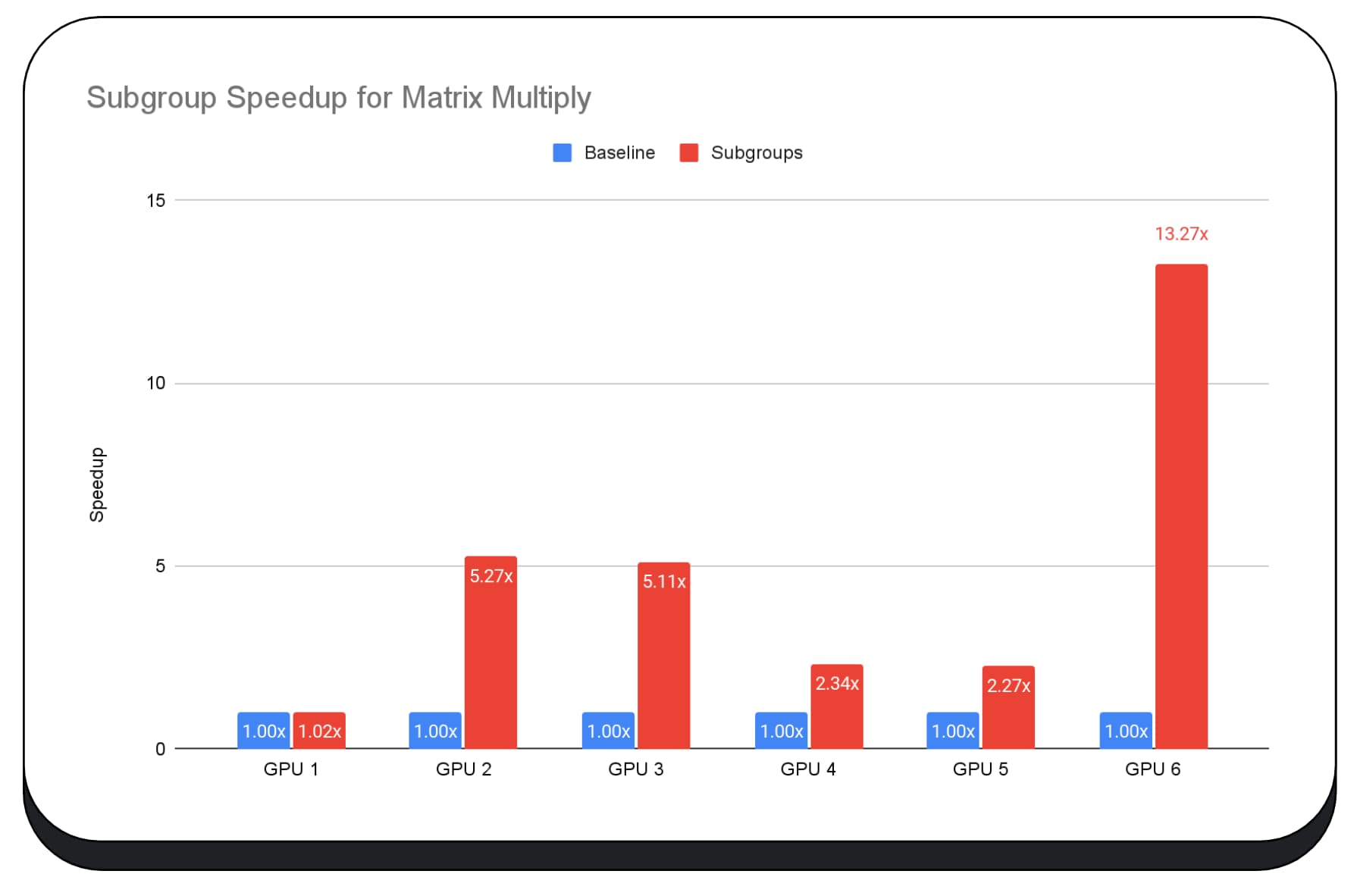
L'optimisation du GPU est difficile
En fin de compte, la meilleure façon d'optimiser votre GPU dépend du GPU proposé par le client. L'utilisation de nouvelles fonctionnalités de GPU sophistiquées ne s'avère pas toujours payante comme vous pourriez l'imaginer, car de nombreux facteurs complexes peuvent être impliqués. La meilleure stratégie d'optimisation sur un GPU n'est pas forcément la meilleure sur un autre.
Vous souhaitez réduire la bande passante de la mémoire tout en utilisant pleinement les threads de calcul du GPU.
Les modèles d'accès à la mémoire peuvent également être très importants. Les GPU ont tendance à offrir de bien meilleures performances lorsque les threads de calcul accèdent à la mémoire selon un schéma optimal pour le matériel. Important: Les caractéristiques de performances sont différentes d'un GPU à l'autre. Vous devrez peut-être exécuter différentes optimisations en fonction du GPU.
Dans le graphique suivant, nous avons utilisé le même algorithme de multiplication matricielle, mais nous avons ajouté une autre dimension pour mieux démontrer l'impact des différentes stratégies d'optimisation, ainsi que la complexité et la variance entre les différents GPU. Nous avons introduit une nouvelle technique, que nous appellerons "Swizzle". La permutation optimise les modèles d'accès à la mémoire pour les adapter au matériel.
Vous pouvez constater que le swizzle de mémoire a un impact significatif, parfois même plus important que les sous-groupes. Sur le GPU 6, le swizzle offre un gain de vitesse de 12 fois, tandis que les sous-groupes offrent un gain de vitesse de 13 fois. Combinées, elles offrent une accélération incroyable de 26 fois. Pour d'autres GPU, le swizzle et les sous-groupes combinés sont parfois plus performants que chacun d'eux seul. Sur d'autres GPU, l'utilisation exclusive de la swizzle est la plus efficace.
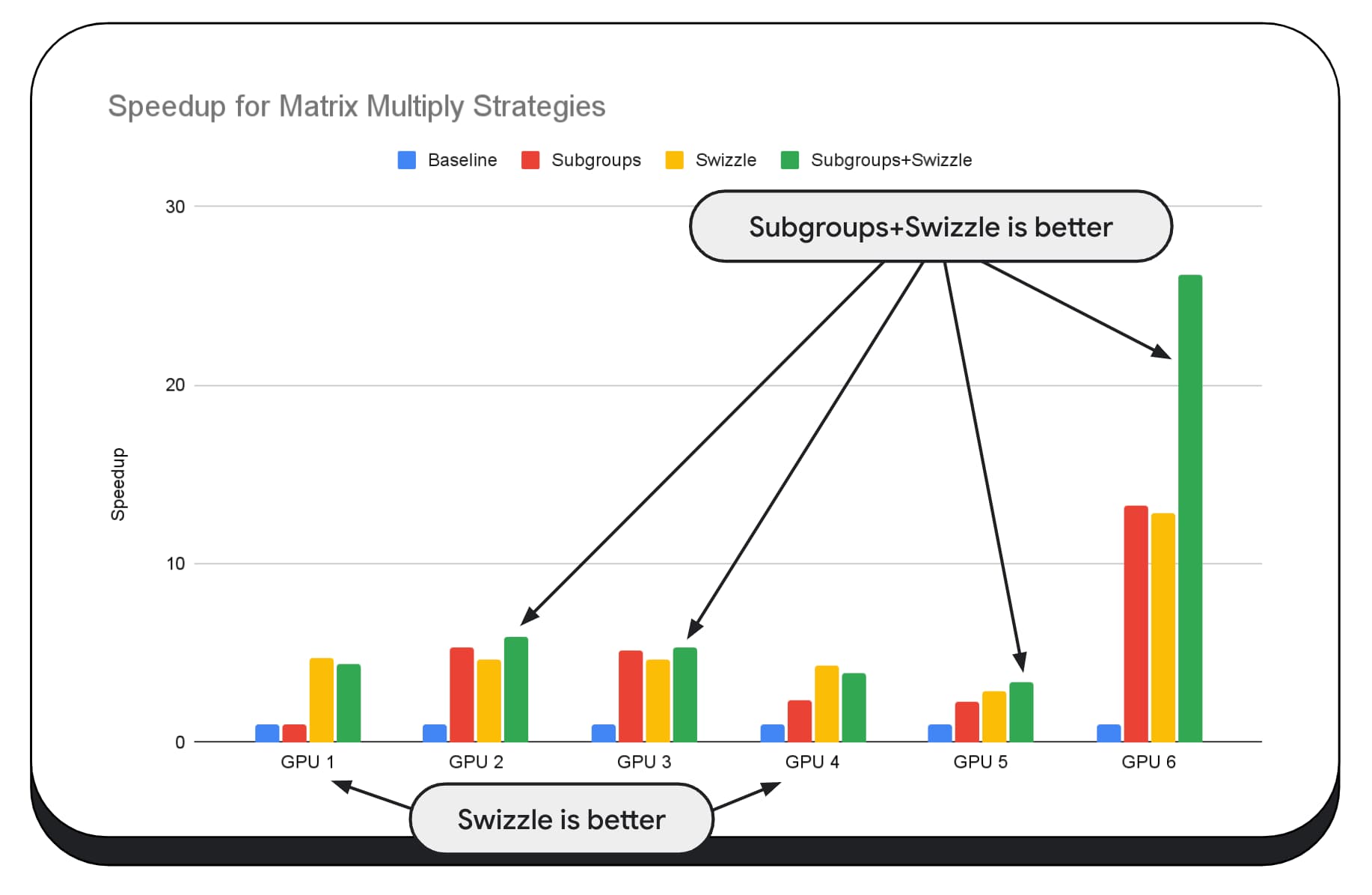
Affiner et optimiser les algorithmes de GPU pour qu'ils fonctionnent correctement sur chaque matériel peut nécessiter une grande expertise. Heureusement, de nombreux développeurs talentueux travaillent sur des frameworks de bibliothèques de niveau supérieur, comme Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web, etc.
Les bibliothèques et les frameworks sont bien adaptés pour gérer la complexité de la gestion de diverses architectures de GPU et générer du code spécifique à la plate-forme qui s'exécutera correctement sur le client.
Points à retenir
L'équipe Chrome continue de contribuer à l'évolution des normes WebAssembly et WebGPU afin d'améliorer la plate-forme Web pour les charges de travail de machine learning. Nous investissons dans des primitives de calcul plus rapides, une meilleure interopérabilité entre les normes Web et nous nous assurons que les modèles, qu'ils soient petits ou grands, peuvent s'exécuter efficacement sur tous les appareils.
Notre objectif est de maximiser les fonctionnalités de la plate-forme tout en conservant le meilleur du Web: sa couverture, son usabilité et sa portabilité. Et nous ne faisons pas cela seuls. Nous collaborons avec les autres fournisseurs de navigateurs du W3C et de nombreux partenaires de développement.
Nous espérons que vous garderez à l'esprit les points suivants lorsque vous utiliserez WebAssembly et WebGPU:
- Les inférences d'IA sont désormais disponibles sur le Web, sur tous les appareils. Cela présente l'avantage d'être exécuté sur les appareils clients, ce qui permet de réduire les coûts de serveur, de réduire la latence et d'améliorer la confidentialité.
- Bien que de nombreuses fonctionnalités abordées soient principalement pertinentes pour les auteurs du framework, vos applications peuvent en bénéficier sans trop de frais généraux.
- Les normes Web sont fluides et évoluent. Nous sommes toujours à l'écoute de vos commentaires. Partagez les vôtres pour WebAssembly et WebGPU.
Remerciements
Nous tenons à remercier l'équipe de graphisme Web d'Intel, qui a joué un rôle essentiel dans le développement des fonctionnalités f16 et du produit scalaire entier empaqueté de WebGPU. Nous tenons à remercier les autres membres des groupes de travail WebAssembly et WebGPU du W3C, y compris les autres fournisseurs de navigateurs.
Merci aux équipes Google et de la communauté Open Source d'avoir été d'incroyables partenaires. Et bien sûr, à tous nos coéquipiers qui rendent tout cela possible.