
המסמך הזה הוא המשך של שיפורים ב-WebAssembly וב-WebGPU לשיפור מהירות ה-AI באינטרנט, חלק 1. מומלץ לקרוא את הפוסט הזה או לצפות בהרצאה ב-IO 24 לפני שממשיכים.



WebGPU
WebGPU מעניק לאפליקציות אינטרנט גישה לחומרת ה-GPU של הלקוח כדי לבצע חישוב יעיל במקבילות גבוהה. מאז השקת WebGPU ב-Chrome, ראינו הדגמות מדהימות של בינה מלאכותית (AI) ולמידת מכונה (ML) באינטרנט.
לדוגמה, Web Stable Diffusion הראה שאפשר להשתמש ב-AI כדי ליצור תמונות מטקסט, ישירות בדפדפן. מוקדם יותר השנה, צוות Mediapipe של Google פרסם תמיכה ניסיונית בהסקה ממודל שפה גדול.
באנימציה הבאה מוצגת Gemma, מודל שפה גדול (LLM) של Google בקוד פתוח, שפועל במלואו במכשיר ב-Chrome, בזמן אמת.
הדגמה של Hugging Face לדגם Segment Anything של Meta יוצרת מסכות אובייקט באיכות גבוהה לגמרי בצד הלקוח.
אלה רק כמה מהפרויקטים המדהימים שממחישים את העוצמה של WebGPU ל-AI וללמידת מכונה. WebGPU מאפשר להריץ את המודלים האלה ומודלים אחרים מהר יותר באופן משמעותי מאשר ב-CPU.
בדיקת הביצועים של WebGPU להטמעת טקסט של Hugging Face מראה שיפור משמעותי במהירות בהשוואה להטמעה של אותו מודל ב-CPU. במחשב נייד עם Apple M1 Max, WebGPU היה מהיר פי 30 יותר. אחרים דיווחו על כך ש-WebGPU מאיץ את בדיקת הביצועים ביותר מ-120 פעמים.
שיפור התכונות של WebGPU ל-AI ול-ML
WebGPU מתאים מאוד למודלים של AI ולמודלים של למידת מכונה, שיכולים לכלול מיליארדי פרמטרים, בזכות התמיכה במעבדי שגיאות (shaders) לחישוב. Compute shaders פועלים ב-GPU ומאפשרים להריץ פעולות מערך מקבילות בנפח גדול של נתונים.
בין השיפורים הרבים שערכנו ב-WebGPU בשנה האחרונה, המשכנו להוסיף יכולות נוספות לשיפור הביצועים של למידת מכונה ו-AI באינטרנט. לאחרונה השקנו שתי תכונות חדשות: נקודה צפה של 16 ביט ומכפילים של ערכים שלמים ארוזים.
נקודה צפה (floating-point) של 16 ביט
חשוב לזכור שעומסי עבודה של למידת מכונה לא דורשים דיוק. shader-f16 היא תכונה שמאפשרת להשתמש בסוג f16 בשפת ההצללה של WebGPU. סוג הנקודה הצפה הזה תופס 16 ביט, במקום 32 הביט הרגילים. ל-f16 יש טווח קטן יותר והוא פחות מדויק, אבל הוא מספיק למודלים רבים של למידת מכונה.
התכונה הזו משפרת את היעילות בכמה דרכים:
זיכרון מופחת: מודולים של טינסורים עם רכיבי f16 תופסים חצי מהמקום, כך שצריכת הזיכרון מופחתת בחצי. לעיתים קרובות, חישובים של GPU נתקלים בצווארון בקבוק ברוחב הפס של הזיכרון, כך שלרוב, חצי מהזיכרון יכול להוביל להפעלה מהירה פי שניים של שיבושים. מבחינה טכנית, אין צורך ב-f16 כדי לחסוך ברוחב הפס של הזיכרון. אפשר לאחסן את הנתונים בפורמט עם דיוק נמוך, ואז להרחיב אותם ל-f32 מלא בשניידר לצורך חישוב. עם זאת, ה-GPU משתמש בכוח מחשוב נוסף כדי לארוז ולפרוק את הנתונים.
הפחתת המרה של נתונים: f16 משתמש בפחות משאבי מחשוב על ידי צמצום ההמרה של נתונים. אפשר לאחסן נתונים ברמת דיוק נמוכה ולהשתמש בהם ישירות, בלי המרה.
הגדלת המודל המקביל: מעבדי GPU מודרניים יכולים להכיל יותר ערכים בו-זמנית ביחידות הביצוע של ה-GPU, וכך לבצע מספר גדול יותר של חישובים מקבילים. לדוגמה, מעבד GPU שתומך ב-5 טריליון פעולות של נקודה צפה מסוג f32 בשנייה עשוי לתמוך ב-10 טריליון פעולות של נקודה צפה מסוג f16 בשנייה.
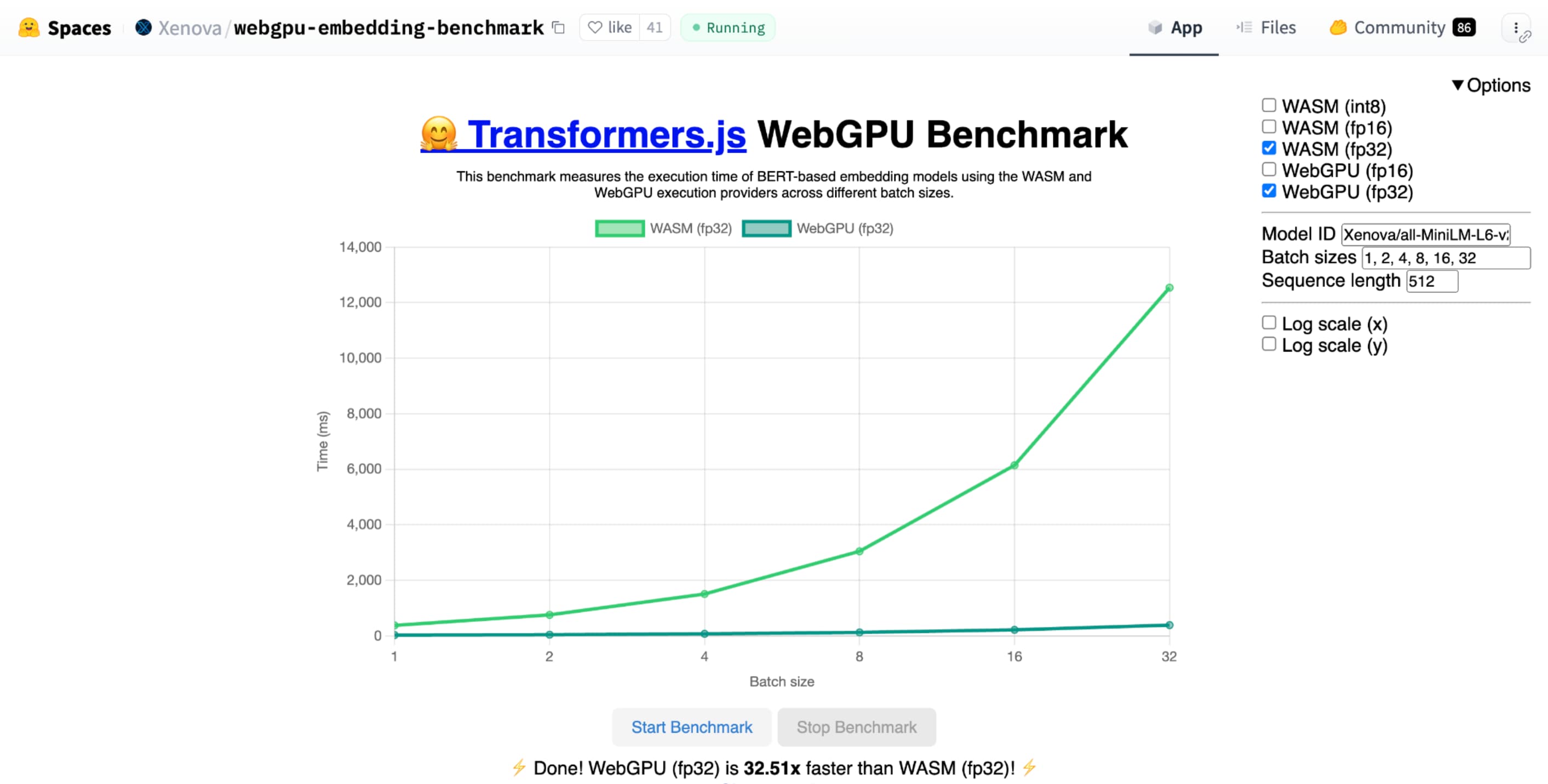
shader-f16, ה-benchmark של WebGPU להטמעת טקסט של Hugging Face מפעיל את ה-benchmark פי 3 מהר יותר מ-f32 במחשב הנייד Apple M1 Max.
WebLLM הוא פרויקט שאפשר להריץ בו כמה מודלים גדולים של שפה. הוא מבוסס על Apache TVM, מסגרת של קומפילטור בקוד פתוח ללמידת מכונה.
ביקשתי מ-WebLLM לתכנן טיול לפריז, באמצעות מודל Llama 3 עם שמונה מיליארד פרמטרים. התוצאות מראות שבמהלך שלב המילוי מראש של המודל, f16 מהיר פי 2.1 מ-f32. בשלב הפענוח, המהירות גבוהה פי 1.3.
האפליקציות צריכות קודם לוודא שהמתאם של ה-GPU תומך ב-f16, ואם הוא זמין, להפעיל אותו באופן מפורש כשמבקשים מכשיר GPU. אם ה-f16 לא נתמך, אי אפשר לבקש אותו במערך requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
לאחר מכן, ב-shaders של WebGPU, צריך להפעיל את f16 בחלק העליון באופן מפורש. לאחר מכן, תוכלו להשתמש בו בתוך ה-shader כמו בכל סוג נתונים אחר מסוג float.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
מוצר מכפלה של מספרים שלמים ארוזים
מודלים רבים עדיין פועלים היטב עם דיוק של 8 ביט בלבד (מחצית מ-f16). האפשרות הזו פופולרית במודלים של LLM ובמודלים של תמונות לצורכי פילוח וזיהוי אובייקטים. עם זאת, איכות הפלט של המודלים פוחתת ככל שהדיוק נמוך יותר, ולכן קידוד 8 ביט לא מתאים לכל אפליקציה.
מעט מאוד מעבדי GPU תומכים באופן מקורי בערכים של 8 ביט. כאן נכנסים לתמונה מוצרים של מכפלות של מספרים שלמים ארוזים. השקנו את DP4a ב-Chrome 123.
ל-GPUs מודרניים יש הוראות מיוחדות לקבלת שני מספרים שלמים של 32 ביט, לפרש כל אחד מהם כ-4 מספרים שלמים של 8 ביט ברצף ולחשב את המכפלה הפנימית בין הרכיבים שלהם.
הפתרון הזה שימושי במיוחד ל-AI וללמידת מכונה, כי ליבות של כפל מטריצות מורכבות ממוצרי מכפלה רבים מאוד.
לדוגמה, נכפיל מטריצה בגודל 4 x 8 בוקטור בגודל 8 x 1. כדי לחשב את זה, צריך לבצע 4 מכפלות סקלריות כדי לחשב כל אחד מהערכים בוקטור הפלט: A, B, C ו-D.
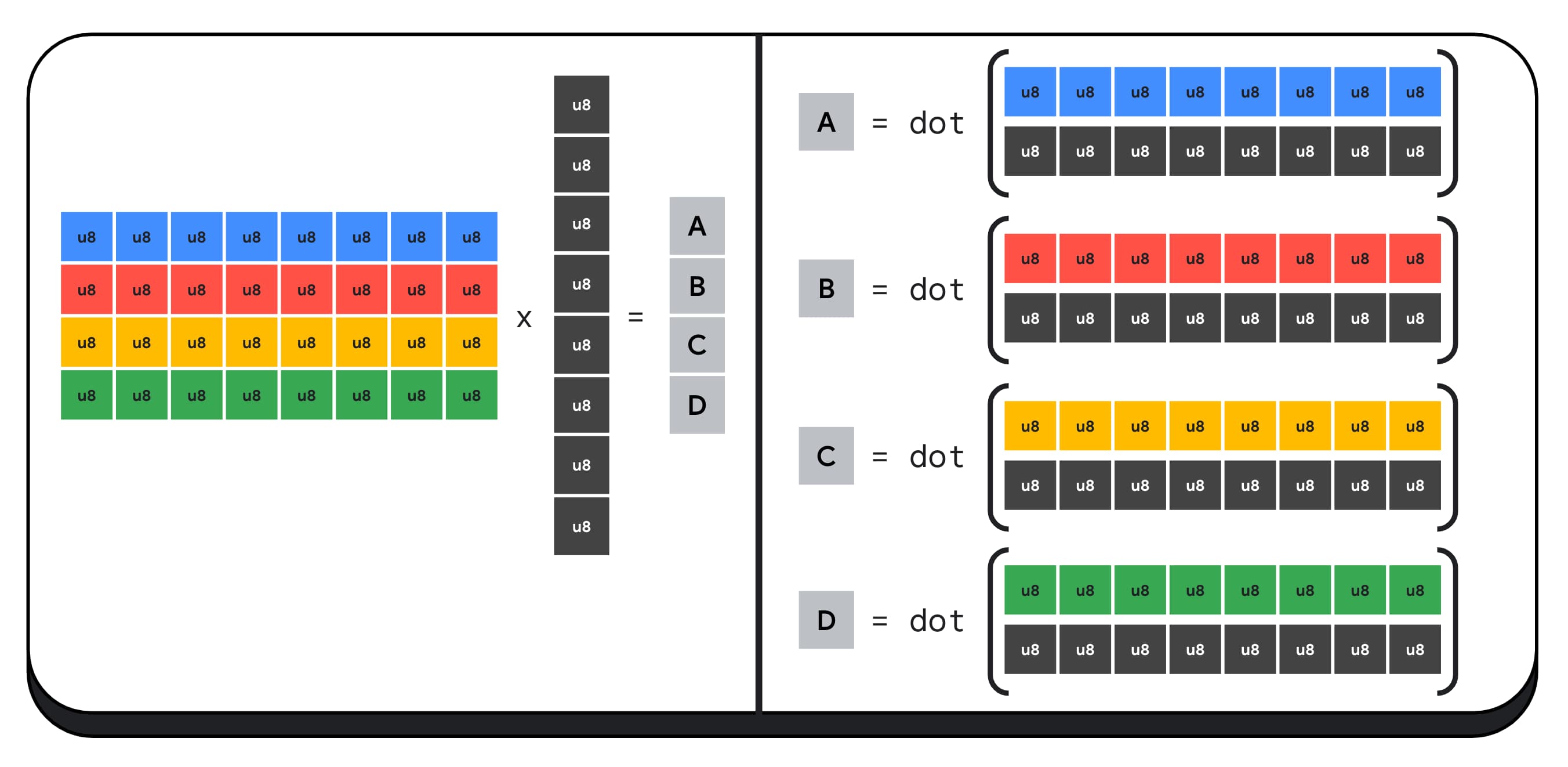
התהליך לחישוב כל אחד מהפלטים האלה זהה. נבחן את השלבים שקשורים לחישוב של אחד מהם. לפני כל חישוב, קודם צריך להמיר את נתוני המספרים השלמים באורך 8 ביט לסוג שאפשר לבצע איתו פעולות אריתמטיות, כמו f16. לאחר מכן, מריצים כפל לפי רכיבים ולבסוף מוסיפים את כל המוצרים. בסך הכול, לכל המכפלה של המטריצה-וקטור, אנחנו מבצעים 40 המרות של מספר שלם למספר צף כדי לפרוס את הנתונים, 32 מכפילות של מספר צף ו-28 הוספות של מספר צף.
במטריצות גדולות יותר עם יותר פעולות, מוצרים של נקודות שלמים ארוזים יכולים לעזור לצמצם את כמות העבודה.
לכל אחד מהפלטים בוקטור התוצאה, אנחנו מבצעים שתי פעולות של מכפלת נקודות ארוזה באמצעות הפונקציה המובנית dot4U8Packed של שפת ההצללה של WebGPU, ואז מוסיפים את התוצאות. בסך הכול, לא מבצעים המרת נתונים לכל המכפלה של המטריצה-וקטור. אנחנו מבצעים 8 מכפילים של נקודות ארוכות ו-4 הוספות של מספרים שלמים.
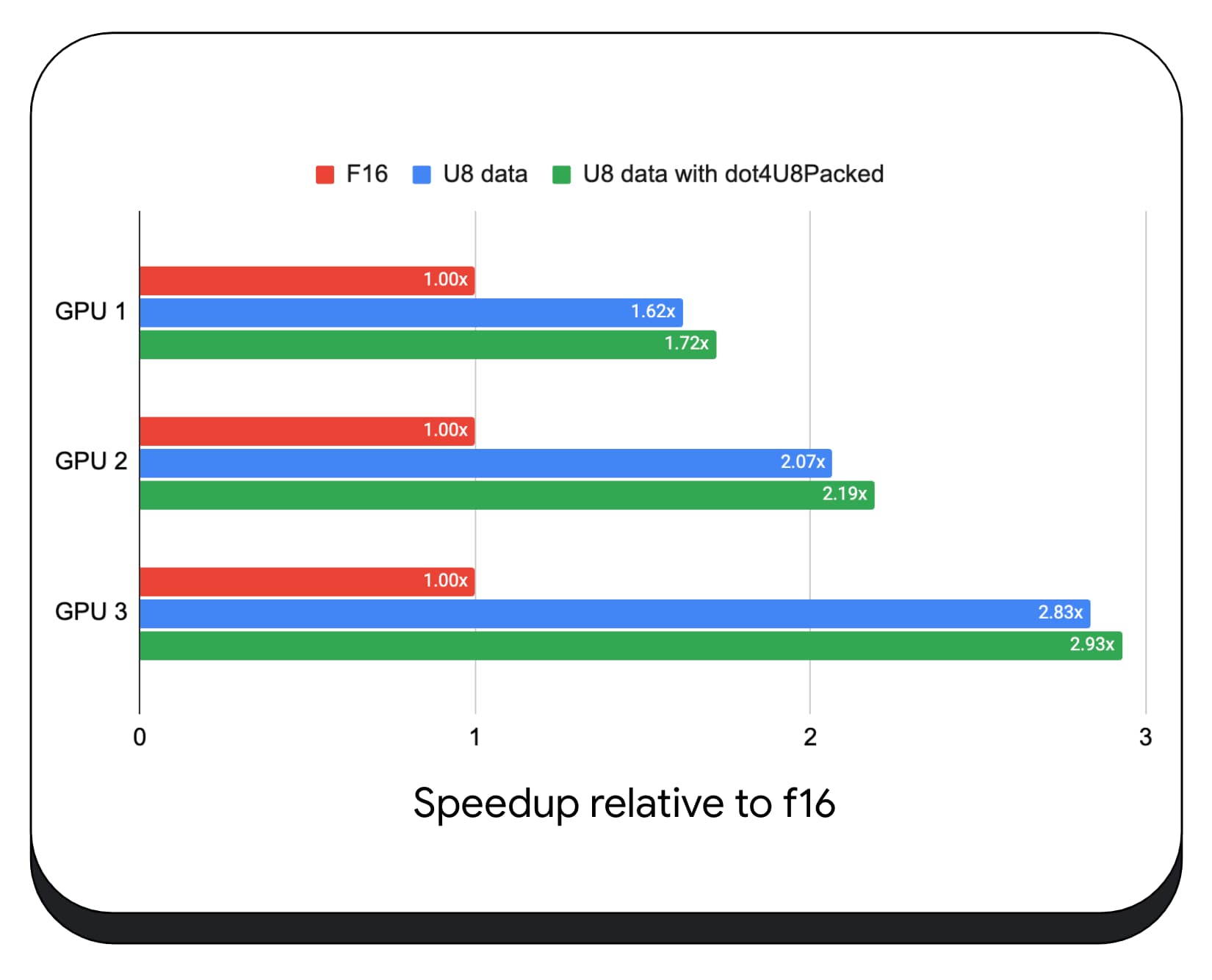
בדקנו מכפילים של מוצרים שלמים ארוזים עם נתונים של 8 ביט במגוון של מעבדי GPU לצרכן. בהשוואה לנקודת צפה של 16 ביט, אפשר לראות ש-8 ביט מהיר פי 1.6 עד 2.8. כשמשתמשים בנוסף במכפילים של מוצרים שלמים ארוזים, הביצועים משתפרים עוד יותר. המהירות גבוהה פי 1.7 עד פי 2.9.
בודקים את תמיכת הדפדפן באמצעות המאפיין wgslLanguageFeatures. אם ה-GPU לא תומך באופן מקורי במכפילים של נקודות ארוכות, הדפדפן יבצע פוליפילינג להטמעה משלו.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
ב-diff (ההבדל) של קטע הקוד הבא מודגשים השינויים הנדרשים כדי להשתמש במוצרי שלמים ארוזים ב-shader של WebGPU.
לפני – שדרן WebGPU שמצטבר בו סכום של מכפילים חלקיים של נקודה במשתנה sum. בסוף הלולאה, המשתנה sum מכיל את המכפיל המלא של נקודה בין וקטור לשורה אחת של מטריצת הקלט.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
אחרי – שדר של WebGPU שנכתב כך שישתמש במכפלות סקלריות של מספרים שלמים ארוזים. ההבדל העיקרי הוא שבמקום לטעון 4 ערכים מסוג float מהוקטור והמטריצה, ה-shader הזה טוען מספר שלם יחיד באורך 32 ביט. המספר השלם של 32 הביט הזה מכיל את הנתונים של ארבעה ערכים של מספרים שלמים של 8 ביט. לאחר מכן, אנחנו קוראים ל-dot4U8Packed כדי לחשב את המכפלה הפנימית של שני הערכים.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
הן מוצרים של נקודה צפה באורך 16 ביט והן מוצרים של מכפלת נקודה של מספר שלם ארוז הן תכונות ששולחים ב-Chrome כדי להאיץ את ה-AI וה-ML. נקודה צפה של 16 ביט זמינה כשהחומרה תומכת בה, ו-Chrome מטמיע מוצרים של נקודות צומת שלמים ארוזים בכל המכשירים.
כבר עכשיו אפשר להשתמש בתכונות האלה בגרסת Chrome היציבה כדי לשפר את הביצועים.
הצעות לתכונות
בעתיד, אנחנו בודקים שתי תכונות נוספות: קבוצות משנה ומודל 'מכפלת מטריצות שיתופית'.
התכונה 'קבוצות משנה' מאפשרת לבצע פעולות מתמטיות קולקטיביות, כמו סיכום של יותר מ-16 מספרים, או לתקשר ברמת SIMD (סינכרון מקבילי של הוראות). כך אפשר לשתף נתונים ביעילות בין שרשורים שונים. יש תמיכה בקבוצות משנה בממשקי API מודרניים של GPUs, בשמות שונים ובצורות מעט שונות.
צמצמנו את הקבוצה המשותפת להצעה ששלחנו לקבוצת התקינה של WebGPU. בנוסף, יצרנו אב טיפוס של קבוצות משנה ב-Chrome באמצעות דגל ניסיוני, והצגנו את התוצאות הראשוניות שלנו בדיון. הבעיה העיקרית היא איך להבטיח התנהגות ניידת.
כפל מטריצות שיתופי הוא תוספת חדשה יותר למעבדי GPU. אפשר לפרק כפל מטריצות גדול למספר כפלים של מטריצות קטנות יותר. ב-Cooperative matrix multiply מתבצעות פעולות כפל בבלוקים קטנים יותר בגודל קבוע, בשלב לוגי אחד. בשלב הזה, קבוצה של חוטים עובדת בשיתוף פעולה כדי לחשב את התוצאה.
ערכנו סקירה של התמיכה בממשקי ה-API הבסיסיים של GPU, ואנחנו מתכננים להציג הצעה לקבוצת התקינה של WebGPU. בדומה לקבוצות משנה, אנחנו צופים שרוב הדיון יתרכז בנושא ניידות.
כדי להעריך את הביצועים של פעולות בקבוצות משנה, באפליקציה אמיתית, שילבנו תמיכה ניסיונית בקבוצות משנה ב-MediaPipe ובדקנו אותה באמצעות אב הטיפוס של Chrome לפעולות בקבוצות משנה.
השתמשנו בקבוצות משנה בליבות GPU בשלב המילוי מראש של מודל השפה הגדול, ולכן אני מדווח רק על העלייה במהירות בשלב המילוי מראש. ב-GPU של Intel, אנחנו רואים שהביצועים של קבוצות משנה מהירים פי שניים וחצי מהביצועים של קבוצת הבקרה. עם זאת, השיפורים האלה לא עקביים במעבדי GPU שונים.
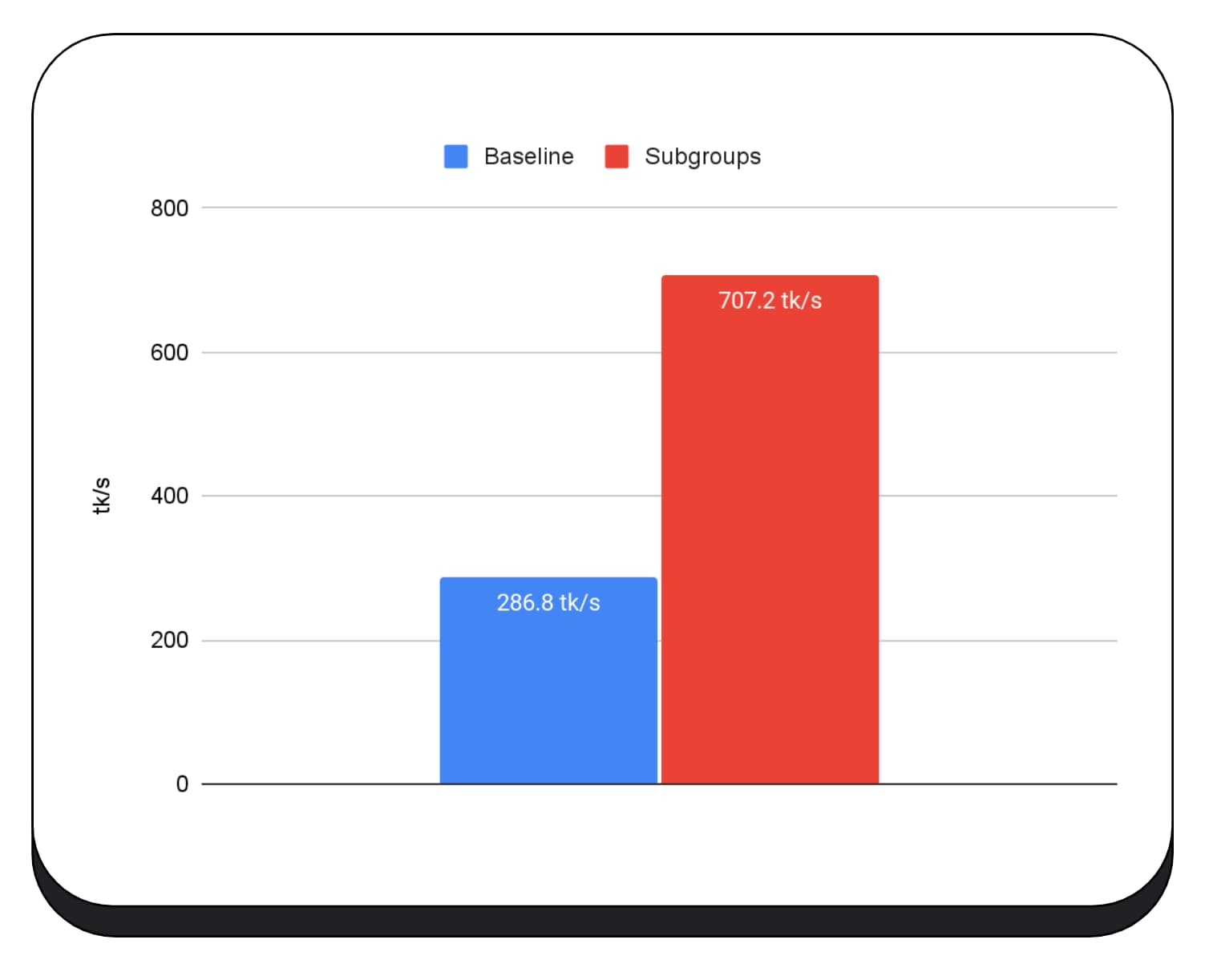
בתרשים הבא מוצגות התוצאות של החלת קבוצות משנה כדי לבצע אופטימיזציה של מיקרו-בדיקת ביצועים של כפל מטריצות במספר מעבדי GPU של צרכנים. כפל מטריצות הוא אחת מהפעולות הכבדות ביותר במודלים גדולים של שפה. הנתונים מראים שבכרטיסי GPU רבים, קבוצות משנה מגדילות את המהירות פי שניים, פי חמישה ואפילו פי 13 מהבסיס. עם זאת, שימו לב שב-GPU הראשון, קבוצות המשנה לא נותנות שיפור משמעותי.
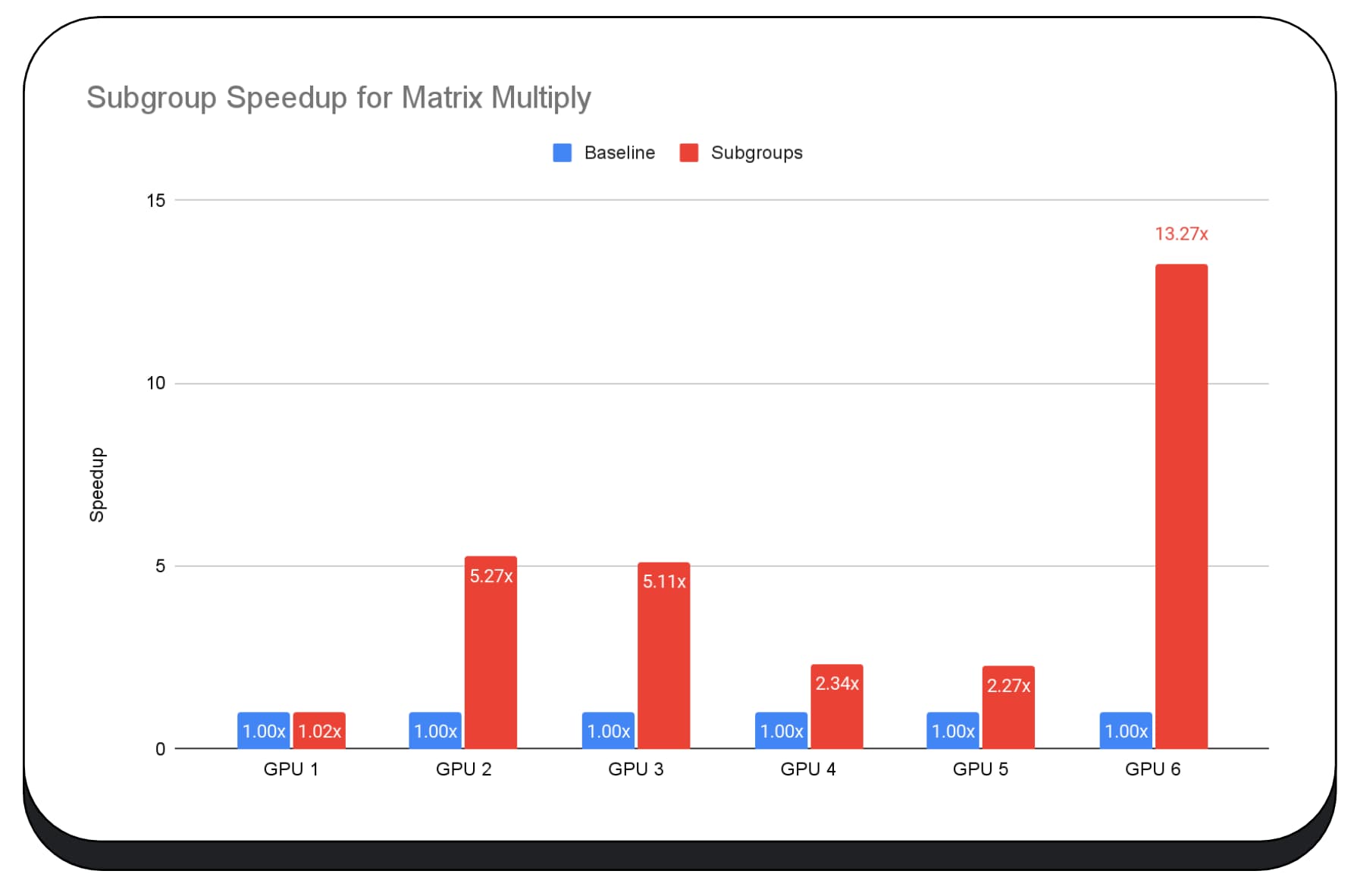
קשה לבצע אופטימיזציה של GPU
בסופו של דבר, הדרך הטובה ביותר לבצע אופטימיזציה של ה-GPU תלויה ב-GPU שהלקוח מציע. השימוש בתכונות חדשות ומגניבות של GPU לא תמיד משתלם כפי שציפיתם, כי יכולים להיות מעורבים הרבה גורמים מורכבים. יכול להיות ששיטת האופטימיזציה הטובה ביותר ב-GPU אחד לא תהיה הטובה ביותר ב-GPU אחר.
רוצים לצמצם את רוחב הפס של הזיכרון, תוך שימוש מלא בשרשראות המחשוב של ה-GPU.
גם דפוסי הגישה לזיכרון יכולים להיות חשובים מאוד. בדרך כלל, ביצועי המעבדים הגרפיים (GPU) טובים בהרבה כשלשרשראות המחשוב יש גישה לזיכרון בתבנית שמתאימה לחומרה. חשוב: מאפייני הביצועים עשויים להיות שונים בחומרה שונה של GPU. יכול להיות שתצטרכו להריץ אופטימיזציות שונות בהתאם ל-GPU.
בתרשים הבא, השתמשנו באותו אלגוריתם של כפל מטריצות, אבל הוספנו עוד מאפיין כדי להמחיש את ההשפעה של אסטרטגיות אופטימיזציה שונות, ואת המורכבות והשונות בין מעבדי GPU שונים. הוספנו כאן טכניקה חדשה שנקראת 'Swizzle'. Swizzle מבצע אופטימיזציה של דפוסי הגישה לזיכרון כך שיתאימו יותר לחומרה.
אפשר לראות שלשינוי המיקום של הנתונים בזיכרון יש השפעה משמעותית, ולפעמים היא משמעותית יותר מההשפעה של קבוצות משנה. ב-GPU 6, השימוש ב-swizzle מאפשר להאיץ את התהליך פי 12, ואילו השימוש בקבוצות משנה מאפשר להאיץ אותו פי 13. בשילוב, יש להם שיפור מהירות מדהים של פי 26. במעבדים גרפיים אחרים, לפעמים השילוב של swizzle ושל קבוצות משנה מניב ביצועים טובים יותר מאשר כל אחת מהאפשרויות בנפרד. וב-GPU אחרים, השימוש הבלעדי ב-swizzle מניב את הביצועים הטובים ביותר.
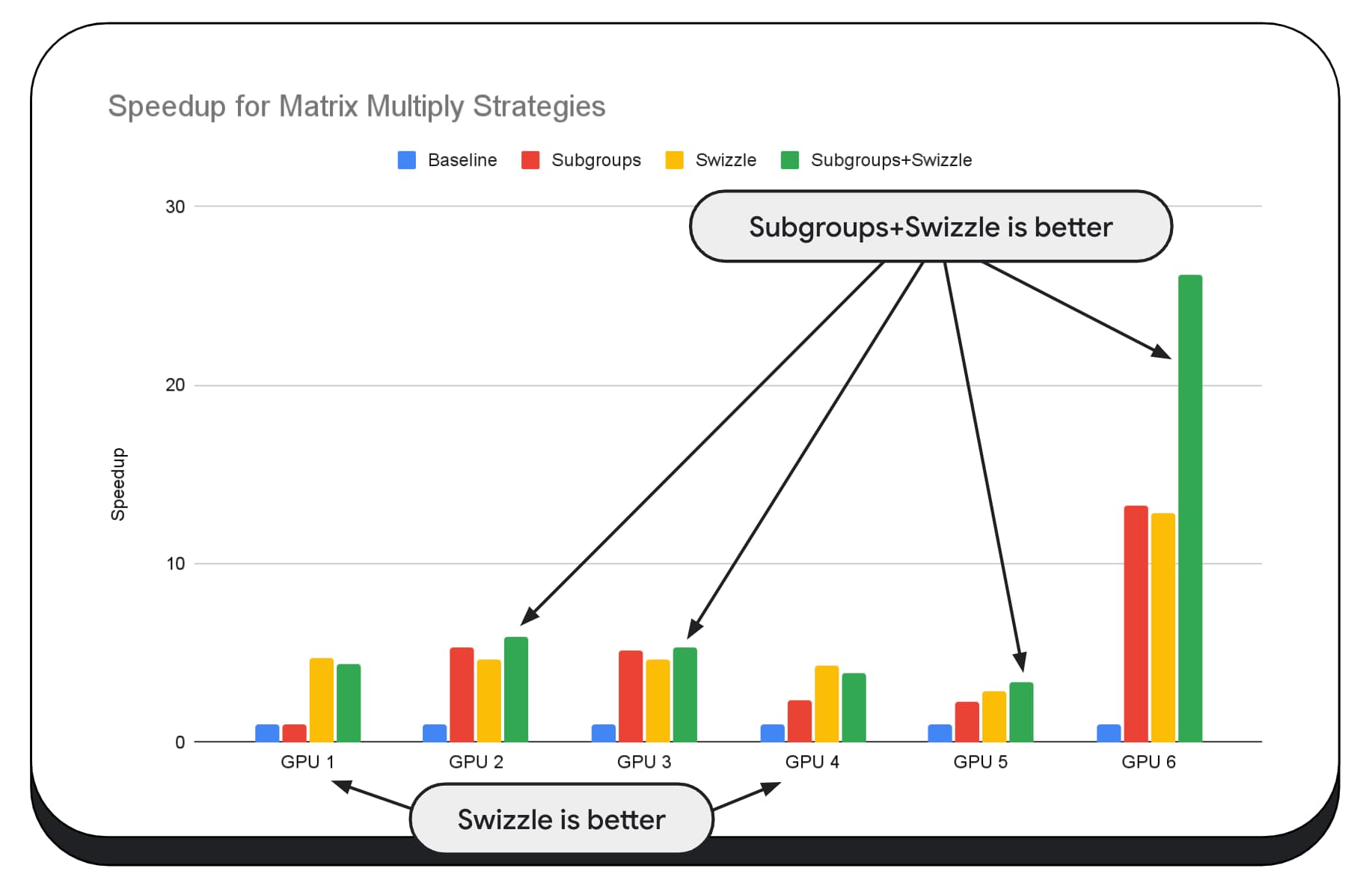
כדי לכוונן ולבצע אופטימיזציה של אלגוריתמים של GPU כך שיפעלו היטב בכל חומרה, נדרש הרבה מומחיות. למרבה המזל, יש כמות עצומה של עבודה מוכשרת שמתבצעת במסגרות של ספריות ברמה גבוהה יותר, כמו Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web ועוד.
ספריות ותבניות מתאימות במיוחד לטיפול במורכבות של ניהול ארכיטקטורות GPU מגוונות, ויצירת קוד ספציפי לפלטפורמה שפועל היטב בצד הלקוח.
חטיפות דסקית
צוות Chrome ממשיך לפתח את התקנים WebAssembly ו-WebGPU כדי לשפר את פלטפורמת האינטרנט לעומסי עבודה של למידת מכונה. אנחנו משקיעים ברכיבי מחשוב בסיסיים מהירים יותר, באינטראקציה טובה יותר בין תקני אינטרנט שונים ומוודאים שמודלים גדולים וקטנים כאחד יכולים לפעול ביעילות במכשירים שונים.
המטרה שלנו היא למקסם את היכולות של הפלטפורמה תוך שמירה על היתרונות העיקריים של האינטרנט: פוטנציאל החשיפה, נוחות השימוש והניידות. ואנחנו לא עושים את זה לבד. אנחנו עובדים בשיתוף עם יצרני הדפדפנים האחרים ב-W3C ועם הרבה שותפי פיתוח.
אנחנו מקווים שתזכרו את הדברים הבאים כשתפעלו עם WebAssembly ו-WebGPU:
- הסקת מסקנות מ-AI זמינה עכשיו באינטרנט, במכשירים שונים. כך אפשר ליהנות מהיתרונות של הפעלה במכשירי לקוח, כמו עלות שרתי מופחתת, זמן אחזור קצר ופרטיות משופרת.
- אמנם תכונות רבות שנדון בהן רלוונטיות בעיקר למחברים של המסגרת, אבל גם היישומים שלכם יכולים ליהנות מהן בלי הרבה התקורה.
- סטנדרטים של אינטרנט הם דינמיים ומשתנים, ואנחנו תמיד שמחים לקבל משוב. אתם יכולים לשתף את העדכונים שלכם לגבי WebAssembly ו-WebGPU.
תודות
אנחנו רוצים להודות לצוות הגרפיקה באינטרנט של Intel, שסייע לנו להטמיע את התכונות של WebGPU f16 ושל מכפלת ערך שלם ארוז. אנחנו רוצים להודות לשאר החברים בקבוצות העבודה של WebAssembly ו-WebGPU ב-W3C, כולל ספקי הדפדפנים האחרים.
תודה לצוותים של ה-AI וה-ML ב-Google ובקהילת הקוד הפתוח על השותפות המדהימה. וכמובן, כל חברי הצוות שלנו שאפשרו את כל זה.