
本文件是「WebAssembly 和 WebGPU 強化功能,提升網路 AI 速度,第 1 部分」的續篇。建議您先閱讀這篇文章,或觀看第 24 屆 Google I/O 大會的演講內容,再繼續閱讀本文。



WebGPU
WebGPU 可讓網頁應用程式存取用戶端的 GPU 硬體,執行高效能且高度平行的運算作業。自從在 Chrome 中推出 WebGPU,我們就看到許多令人驚豔的人工智慧 (AI) 和機器學習 (ML) 示範。
舉例來說,Web Stable Diffusion 證明我們可以使用 AI,直接在瀏覽器中根據文字產生圖片。今年稍早,Google 的 Mediapipe 團隊發布了大型語言模型推論的實驗支援功能。
以下動畫顯示 Gemma,也就是 Google 的開放原始碼大型語言模型 (LLM),在 Chrome 中即時在裝置上執行。
以下是 Meta 的 Segment Anything 模型的 Hugging Face 示範,可在用戶端產生高品質的物件遮罩。
以上只是幾個展示 WebGPU 在 AI 和機器學習方面的強大功能的優異專案。透過 WebGPU,這些模型和其他模型的執行速度將比在 CPU 上執行時快上許多。
與相同模型的 CPU 實作方式相比,Hugging Face 的文字嵌入 WebGPU 基準測試顯示出極大的加速效果。在 Apple M1 Max 筆電上,WebGPU 的速度比原先快了 30 倍。其他人也回報,WebGPU 可將基準測試加速 120 倍。
改善 WebGPU 功能,以便支援 AI 和機器學習
WebGPU 支援運算著色器,因此非常適合 AI 和機器學習模型,這些模型可能含有數十億個參數。運算著色器會在 GPU 上執行,並協助針對大量資料執行平行陣列作業。
在過去一年中,我們持續改善 WebGPU 的多項功能,以改善網頁上的 ML 和 AI 效能。我們最近推出了兩項新功能:16 位元浮點和已封裝的整數點積。
16 位元浮點
請注意,機器學習工作負載不需要精確度。shader-f16 是一項功能,可在 WebGPU 著色語言中使用 f16 類型。這個浮點型別會占用 16 位元,而非一般 32 位元。f16 的範圍較小且精確度較低,但對許多 ML 模型來說,這就足夠了。
這項功能可透過以下幾種方式提高效率:
減少記憶體用量:含有 f16 元素的張量會占用一半的空間,因此可將記憶體用量減半。GPU 運算通常會因為記憶體頻寬而出現瓶頸,因此記憶體減半通常代表著著色器執行速度會快上兩倍。從技術層面來說,您不需要使用 f16 就能節省記憶體頻寬。您可以以低精確度格式儲存資料,然後在著色器中將其展開為完整的 f32 以進行運算。但 GPU 會耗用額外的運算能力來封裝及解封裝資料。
減少資料轉換:f16 會盡量減少資料轉換,以便減少運算量。低精確度資料可儲存後直接使用,無須轉換。
增加平行處理能力:新一代 GPU 可同時在 GPU 的執行單元中放入更多值,因此可執行更多平行運算。舉例來說,如果 GPU 支援每秒 5 兆次 f32 浮點運算,可能就支援每秒 10 兆次 f16 浮點運算。
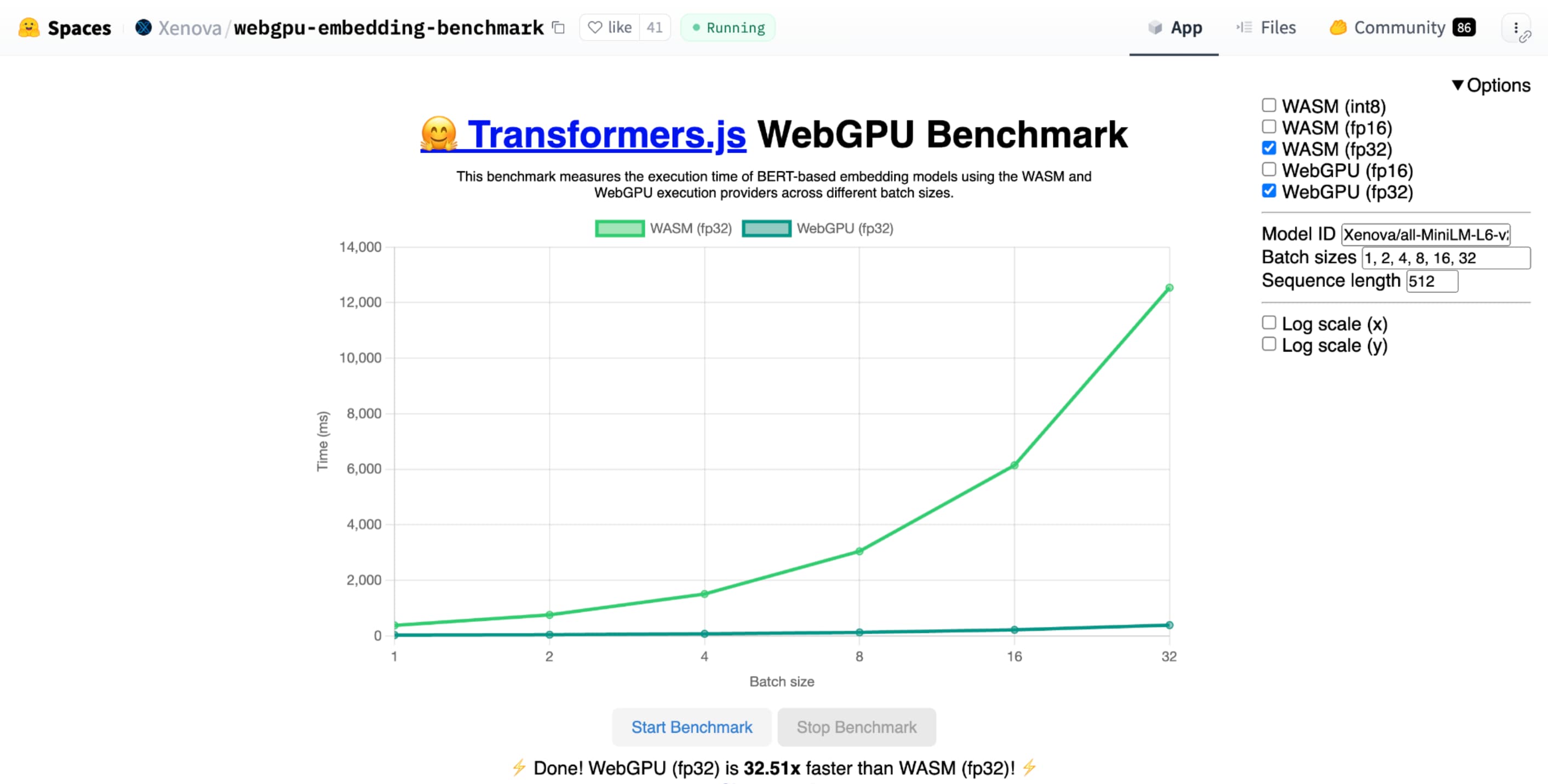
shader-f16 中,Hugging Face 的文字嵌入 WebGPU 基準測試基準測試比在 Apple M1 Max 筆電上執行 f32 快上 3 倍。
WebLLM 是可執行多個大型語言模型的專案。使用 Apache TVM,這是開放原始碼機器學習編譯器架構。
我要求 WebLLM 使用 Llama 3 八十億參數模型規劃前往巴黎的行程。結果顯示,在模型的預填階段,f16 的速度比 f32 快 2.1 倍。在解碼階段,速度快了 1.3 倍以上。
應用程式必須先確認 GPU 轉接器支援 f16,如果可用,請在要求 GPU 裝置時明確啟用。如果不支援 f16,您就無法在 requiredFeatures 陣列中要求。
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
接著,您必須在 WebGPU 著色器中明確啟用頂端的 f16。之後,您可以像使用任何其他浮點資料類型一樣,在著色器中自由使用它。
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
已壓縮的整數點積
許多模型只需 8 位元精確度 (f16 的一半) 即可正常運作。這項技術在 LLM 和圖像模型中很常見,用於區隔和物件辨識。不過,模型的輸出品質會隨著精確度的降低而降低,因此 8 位元量化並不適合所有應用程式。
只有少數 GPU 原生支援 8 位元值。這正是壓縮整數點積運算式發揮作用的時機。我們已在 Chrome 123 中發布 DP4a。
新型 GPU 有特殊指令,可將兩個 32 位元整數解讀為 4 個連續包裝的 8 位元整數,並計算其元件之間的內積。
這對於 AI 和機器學習特別實用,因為矩陣乘法核心是由許多點積組成。
舉例來說,我們來將 4 x 8 矩陣與 8 x 1 向量相乘。計算這個值時,需要使用 4 個內積來計算輸出向量中的每個值,也就是 A、B、C 和 D。
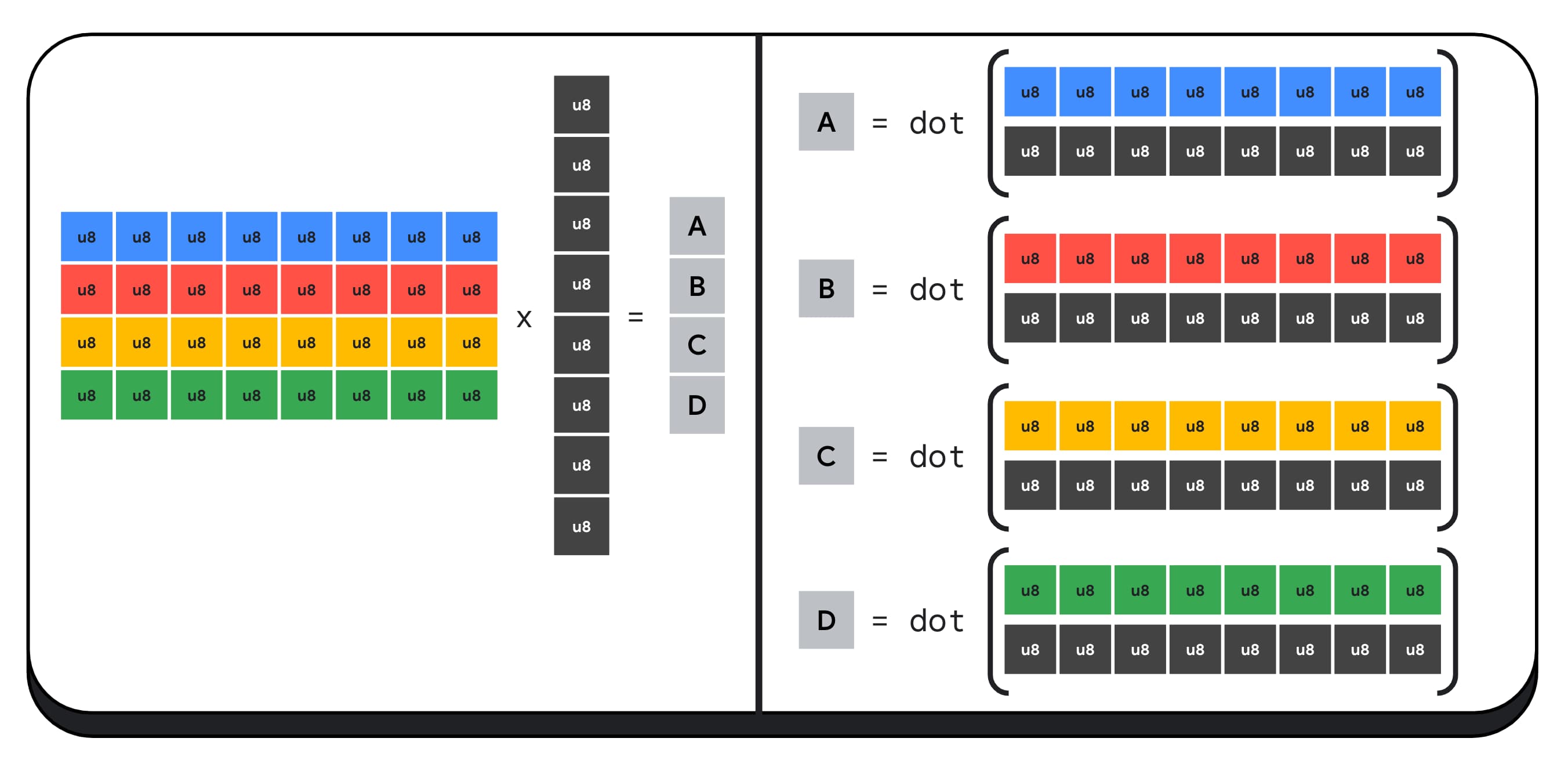
計算這些輸出的程序都相同,我們將說明計算其中一個輸出的步驟。在進行任何運算之前,我們必須先將 8 位元整數資料轉換為可執行算術運算的類型,例如 f16。接著,我們會執行元素相乘運算,最後將所有乘積加總。總而言之,在整個矩陣-向量相乘作業中,我們會執行 40 次整數至浮點轉換,以便解開資料、32 次浮點相乘,以及 28 次浮點加法。
對於包含更多運算的較大矩陣,壓縮整數點積運算可協助減少工作量。
針對結果向量中的每個輸出值,我們會使用 WebGPU 著色語言內建的 dot4U8Packed 執行兩個已壓縮的內積運算,然後將結果加總。總而言之,在整個矩陣-向量相乘運算中,我們不會執行任何資料轉換。我們執行 8 個已壓縮的點積乘積和 4 個整數加法。
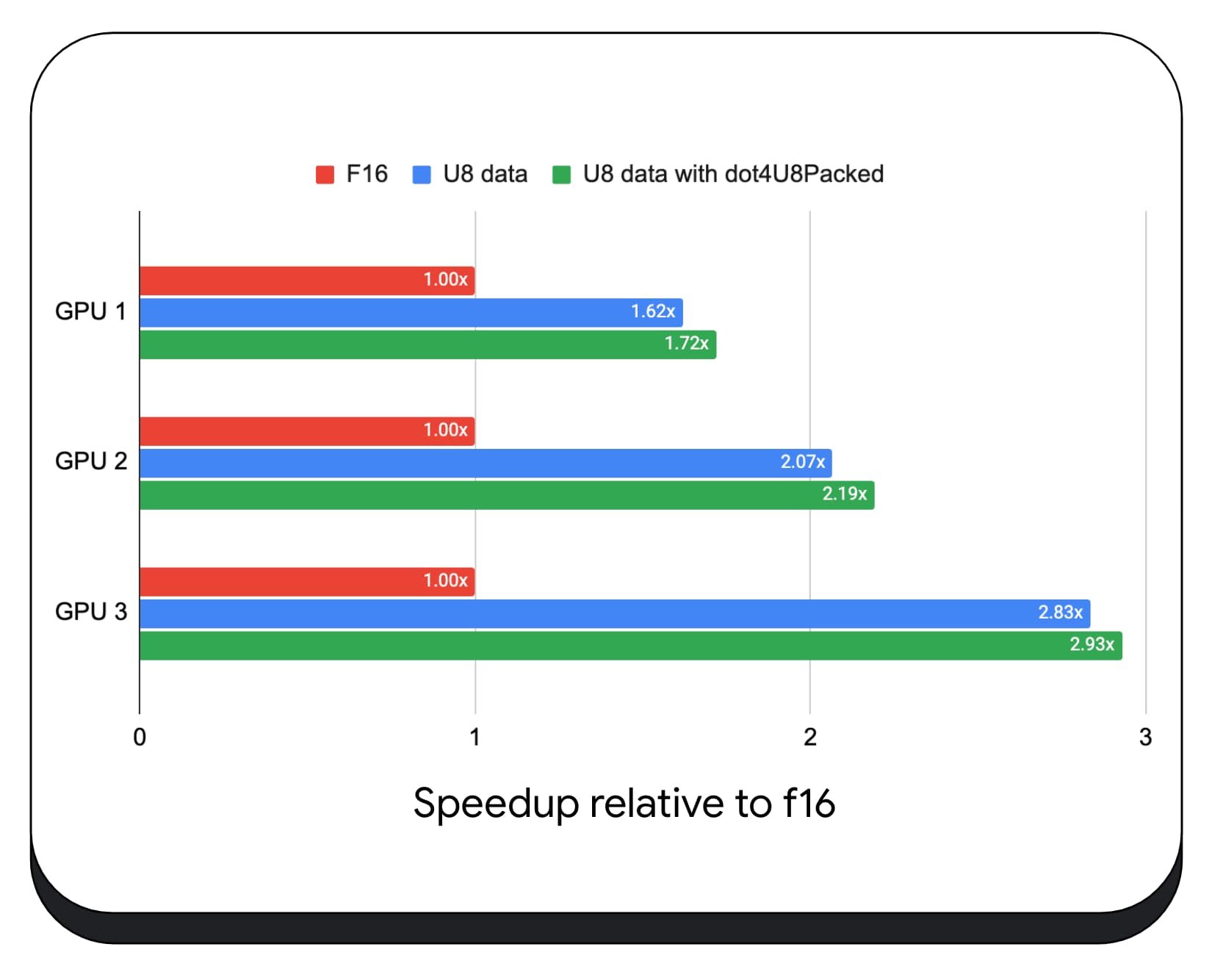
我們在各種消費性 GPU 上測試了使用 8 位元資料的內含整數點產品。與 16 位元浮點值相比,我們發現 8 位元浮點值的速度快了 1.6 到 2.8 倍。如果再加上使用已壓縮的整數點積運算式,效能會更佳。速度快了 1.7 到 2.9 倍。
使用 wgslLanguageFeatures 屬性檢查瀏覽器支援情形。如果 GPU 不支援已封裝的點產品,瀏覽器就會使用自身實作方式進行 polyfill。
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
下列程式碼片段差異 (差異) 會強調在 WebGPU 著色器中使用已封裝整數積數所需的變更。
前置:WebGPU 著色器會將部分內積累積至變數 `sum`。在迴圈結束時,`sum` 會保留向量與輸入矩陣一列之間的完整內積。
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
後:WebGPU 著色器是為了使用已封裝的整數點積運算結果而編寫。主要差異在於,這個著色器會載入單一 32 位元整數,而非從向量和矩陣載入 4 個浮點值。這個 32 位元整數會保留四個 8 位元整數值的資料。接著,我們呼叫 dot4U8Packed 來計算這兩個值的內積。
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
16 位元浮點運算和已壓縮的整數點產品,都是 Chrome 推出的功能,可加速 AI 和機器學習。硬體支援 16 位元浮點運算時,Chrome 會在所有裝置上實作已壓縮的整數點乘運算。
你現在就能在 Chrome 穩定版中使用這些功能,提升效能。
建議的功能
我們正在研究另外兩項功能:子群組和合作矩陣相乘。
子群組功能可讓 SIMD 級別的平行處理功能進行通訊或執行集體數學運算,例如加總超過 16 個數字。這可讓跨執行緒資料共用更有效率。子群組可在最新的 GPU API 上使用,但名稱和形式略有不同。
我們已將常見的集合提煉成提案,並提交給 WebGPU 標準化群組。我們也已在實驗旗標下 製作 Chrome 子群組的原型,並將初步結果納入討論。主要問題是如何確保可攜行為。
合作矩陣乘法是最近才加入 GPU 的功能。大型矩陣相乘運算可拆分為多個較小的矩陣相乘運算。合作矩陣乘法會在單一邏輯步驟中,對這些較小的固定大小區塊執行乘法。在該步驟中,一組執行緒會有效合作,以便計算結果。
我們調查了底層 GPU API 的支援功能,並打算向 WebGPU 標準化小組提出建議。與子群組一樣,我們預期大部分的討論內容都會聚焦於可攜性。
為了評估子群組作業的效能,我們在實際應用程式中整合了子群組實驗支援功能,並使用 Chrome 的子群組作業原型進行測試。
我們在大型語言模型的預填階段使用 GPU 核心子集,因此我只會回報預填階段的加速效果。在 Intel GPU 上,我們發現子群組的執行速度比基準快兩倍半。不過,這些改善措施在不同 GPU 上並未一致。
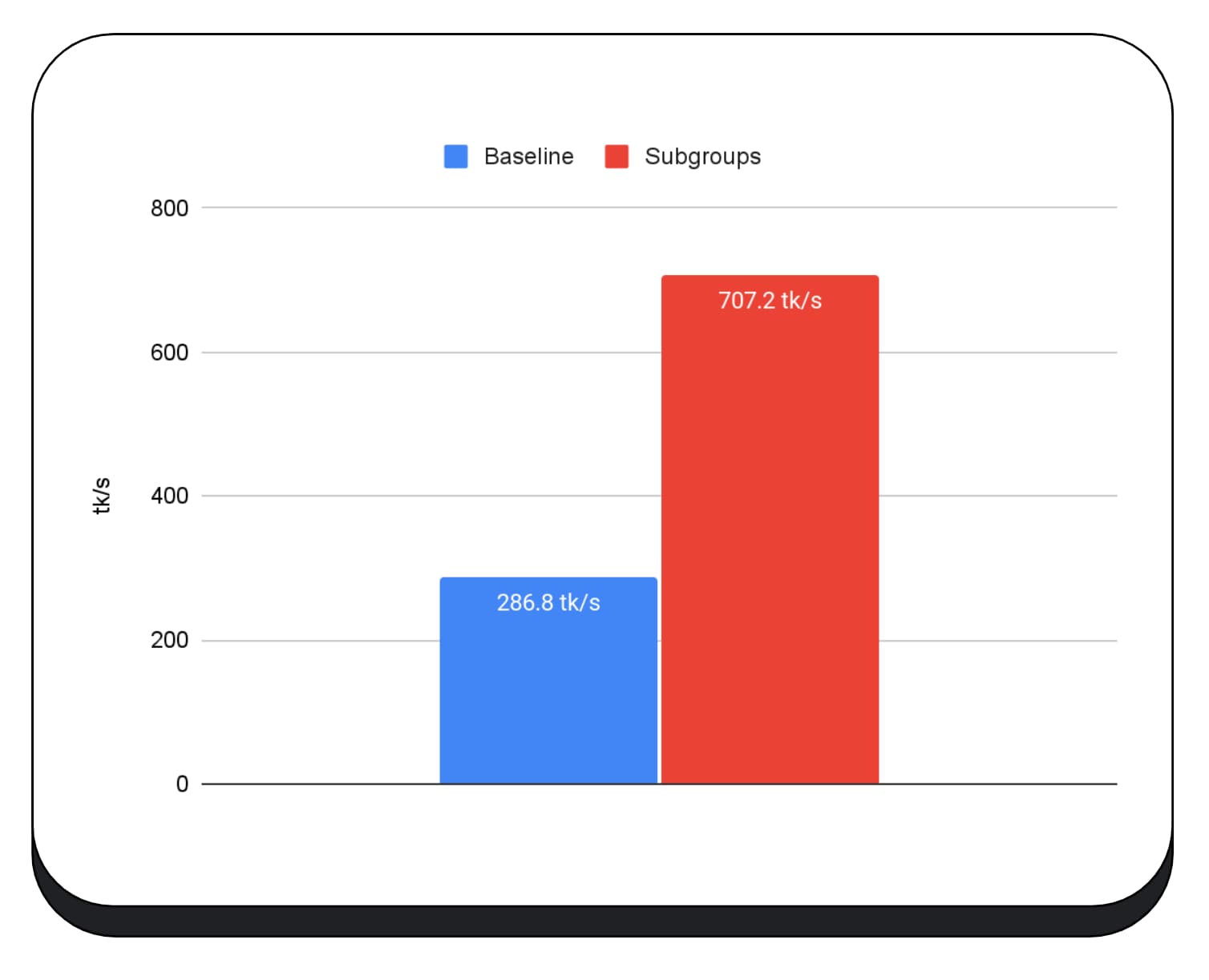
下圖顯示套用子群組以在多個消費性 GPU 上最佳化矩陣乘法微型基準測試的結果。矩陣相乘是大型語言模型中較為繁重的運算之一。資料顯示,在許多 GPU 上,子群組可將速度提高兩倍、五倍,甚至十三倍。不過,請注意,在第一個 GPU 上,子群組並沒有明顯改善。
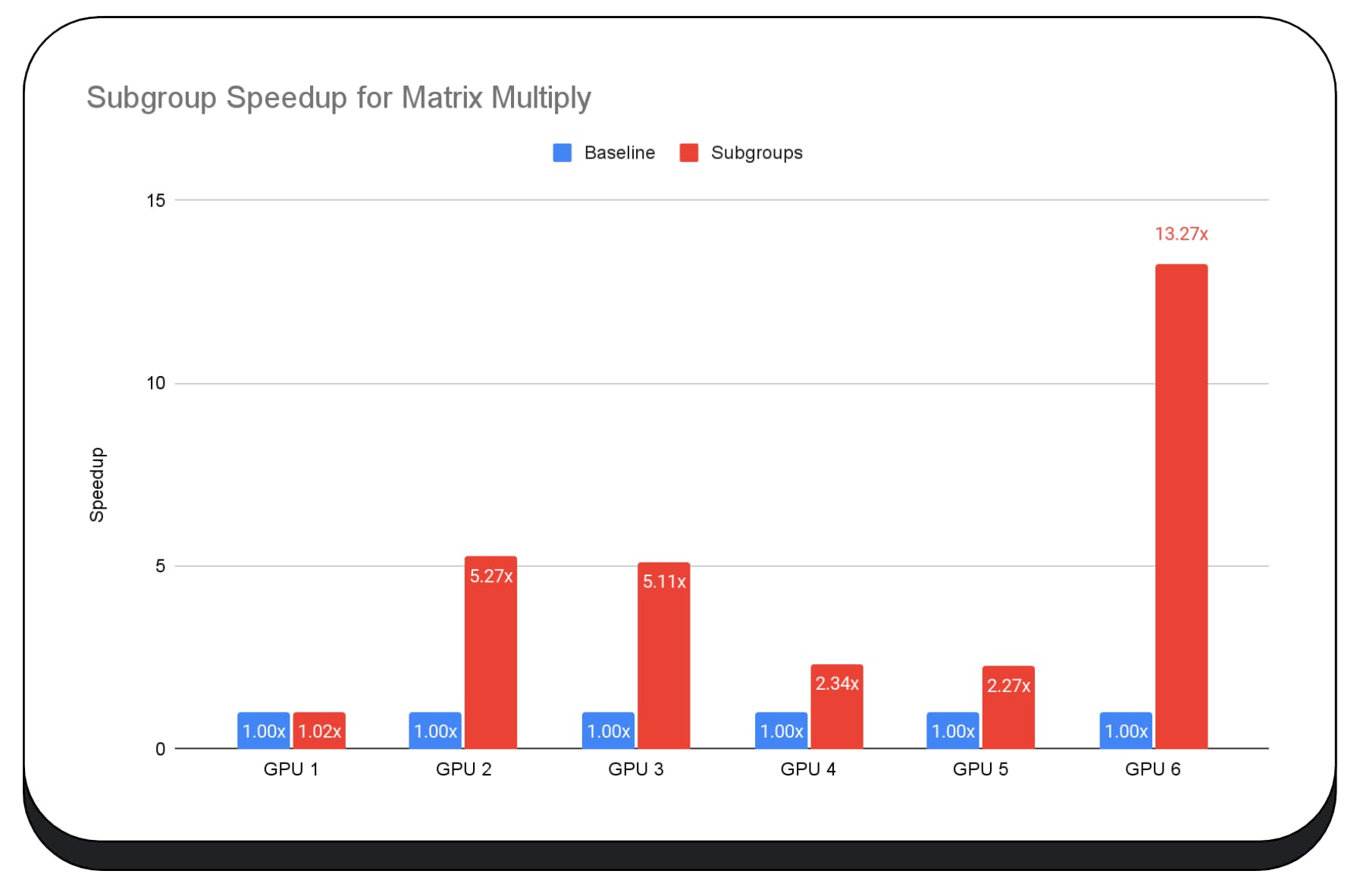
難以最佳化 GPU
最終,最佳的 GPU 最佳化方式取決於用戶端提供的 GPU。使用新穎的 GPU 功能不一定會帶來預期的效益,因為這可能牽涉到許多複雜的因素。適用於某個 GPU 的最佳最佳化策略,不一定適用於其他 GPU。
您希望盡可能減少記憶體頻寬,同時充分利用 GPU 的運算執行緒。
記憶體存取模式也非常重要。當運算執行緒以硬體最佳化模式存取記憶體時,GPU 的效能通常會大幅提升。重要事項:不同 GPU 硬體的效能特性可能會有所差異。視 GPU 而定,您可能需要執行不同的最佳化作業。
在下方圖表中,我們採用了相同的矩陣乘法演算法,但加入了另一個維度,進一步說明各種最佳化策略的影響,以及不同 GPU 的複雜度和差異。我們在這裡引入了一種新技術,稱為「Swizzle」。Swizzle 會最佳化記憶體存取模式,以便更有效地發揮硬體效能。
您可以看到記憶體交換有重大影響,有時甚至比子集更具影響力。在 GPU 6 上,swizzle 可提供 12 倍的加速效果,而子群組則可提供 13 倍的加速效果。兩者相加,速度提升了 26 倍。對於其他 GPU,有時將 Swizzle 和子群組結合起來,比單獨使用其中一個更有效率。在其他 GPU 上,專門使用 swizzle 的效能最佳。
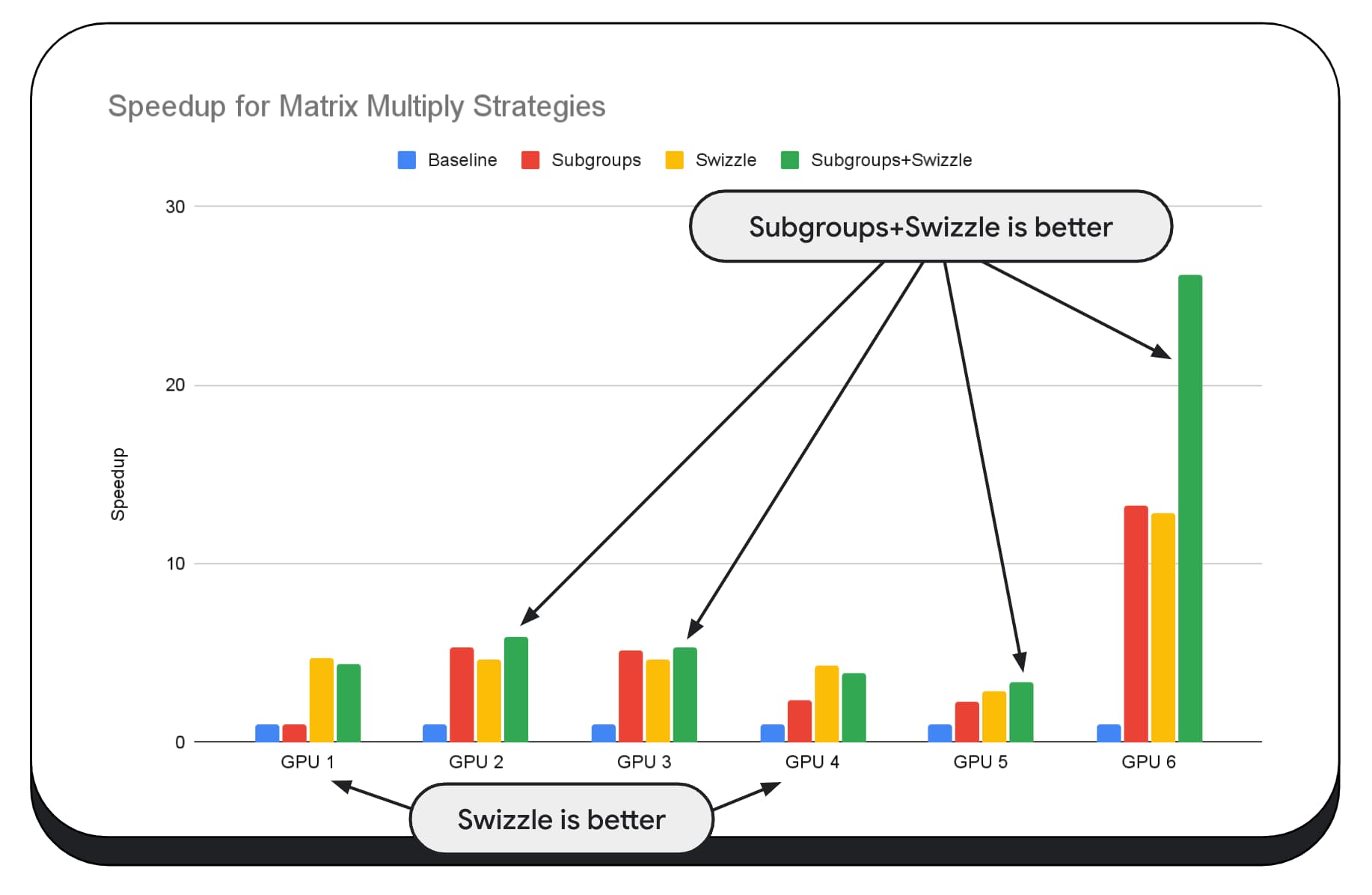
調整及最佳化 GPU 演算法,讓其在所有硬體上運作良好,可能需要大量專業知識。不過,幸好有許多優秀的程式設計師投入更高層級的程式庫架構,例如 Mediapipe、Transformers.js、Apache TVM、ONNX Runtime Web 等等。
程式庫和架構可妥善處理管理多種 GPU 架構的複雜性,並產生可在用戶端順利執行的平台專屬程式碼。
重點整理
Chrome 團隊持續協助改進 WebAssembly 和 WebGPU 標準,以改善機器學習工作負載的網路平台。我們致力於開發更快速的運算原語元,改善跨網頁標準的互通性,並確保大型和小型模型都能在各裝置上順利執行。
我們的目標是盡可能發揮平台的功能,同時保留網路的優點:觸及範圍、可用性和可移植性。我們並非獨自完成這項工作。我們正在與 W3C 的其他瀏覽器供應商和許多開發合作夥伴合作。
在使用 WebAssembly 和 WebGPU 時,請記住以下事項:
- 人工智慧推論功能現已在網頁上推出,可跨裝置使用。這可帶來在用戶端裝置上執行的優勢,例如降低伺服器成本、延遲時間短,以及提升隱私權。
- 雖然許多討論的功能主要與架構作者相關,但您的應用程式也可以從中受益,且不會增加太多負擔。
- 網路標準會隨著時間不斷演進,我們也一直在尋找意見回饋。請分享您對 WebAssembly 和 WebGPU 的想法。
特別銘謝
我們要感謝 Intel 網頁圖形團隊,他們在推動 WebGPU f16 和已封裝整數點產品功能方面發揮了重要作用。在此感謝 W3C 的 WebAssembly 和 WebGPU 工作小組其他成員,包括其他瀏覽器供應商。
感謝 Google 和開放原始碼社群的 AI 和 ML 團隊,成為我們出色的合作夥伴。當然,也要感謝所有團隊成員的努力。