
Dit document is een voortzetting van WebAssembly- en WebGPU-verbeteringen voor snellere Web AI, deel 1 . We raden u aan dit bericht te lezen of de lezing op IO 24 te bekijken voordat u verdergaat .



WebGPU
WebGPU geeft webapplicaties toegang tot de GPU-hardware van de klant om efficiënte, zeer parallelle berekeningen uit te voeren. Sinds de lancering van WebGPU in Chrome hebben we ongelooflijke demo's van kunstmatige intelligentie (AI) en machine learning (ML) op internet gezien.
Web Stable Diffusion heeft bijvoorbeeld aangetoond dat het mogelijk is om AI te gebruiken om afbeeldingen uit tekst te genereren, rechtstreeks in de browser. Eerder dit jaar publiceerde Google's eigen Mediapipe-team experimentele ondersteuning voor gevolgtrekking in grote taalmodellen .
De volgende animatie toont Gemma , het open source grote taalmodel (LLM) van Google, dat volledig op het apparaat in Chrome draait, in realtime.
De volgende demo van Hugging Face van Meta's Segment Anything Model produceert objectmaskers van hoge kwaliteit, volledig op de klant.
Dit zijn slechts een paar van de geweldige projecten die de kracht van WebGPU voor AI en ML laten zien. Met WebGPU kunnen deze en andere modellen aanzienlijk sneller werken dan op de CPU.
De WebGPU-benchmark van Hugging Face voor het insluiten van tekst laat enorme snelheden zien in vergelijking met een CPU-implementatie van hetzelfde model. Op een Apple M1 Max-laptop was WebGPU ruim 30 keer sneller. Anderen hebben gemeld dat WebGPU de benchmark ruim 120 keer versnelt.
Verbetering van WebGPU-functies voor AI en ML
WebGPU is geweldig voor AI- en ML-modellen, die miljarden parameters kunnen hebben, dankzij ondersteuning voor compute shaders . Compute shaders draaien op de GPU en helpen bij het uitvoeren van parallelle array-bewerkingen op grote hoeveelheden gegevens.
Naast de vele verbeteringen aan WebGPU in het afgelopen jaar, zijn we doorgegaan met het toevoegen van meer mogelijkheden om de ML- en AI-prestaties op internet te verbeteren. Onlangs hebben we twee nieuwe functies gelanceerd: 16-bits drijvende-komma- en verpakte integer-dot-producten.
16-bits drijvende komma
Houd er rekening mee dat ML-workloads geen precisie vereisen . shader-f16 is een functie die het gebruik van het f16-type in WebGPU-shading-taal mogelijk maakt. Dit drijvende-kommatype neemt 16 bits in beslag, in plaats van de gebruikelijke 32 bits. f16 heeft een kleiner bereik en is minder nauwkeurig, maar voor veel ML-modellen is dit voldoende.
Deze functie verhoogt de efficiëntie op een aantal manieren:
Verminderd geheugen : Tensors met f16-elementen nemen de helft van de ruimte in beslag, waardoor het geheugengebruik wordt gehalveerd. GPU-berekeningen hebben vaak een knelpunt in de geheugenbandbreedte, dus de helft van het geheugen kan er vaak voor zorgen dat shaders twee keer zo snel werken. Technisch gezien heb je geen f16 nodig om geheugenbandbreedte te besparen. Het is mogelijk om de gegevens op te slaan in een indeling met lage precisie en deze vervolgens uit te breiden tot volledige f32 in de arcering voor berekeningen. Maar de GPU besteedt extra rekenkracht om de gegevens in en uit te pakken.
Verminderde dataconversie : f16 gebruikt minder rekenkracht door de dataconversie te minimaliseren. Gegevens met een lage nauwkeurigheid kunnen worden opgeslagen en vervolgens zonder conversie direct worden gebruikt.
Verhoogd parallellisme : moderne GPU's kunnen meer waarden tegelijkertijd in de uitvoeringseenheden van de GPU passen, waardoor deze een groter aantal parallelle berekeningen kan uitvoeren. Een GPU die tot 5 biljoen f32 drijvende-kommabewerkingen per seconde ondersteunt, kan bijvoorbeeld 10 biljoen f16 drijvende-kommabewerkingen per seconde ondersteunen.
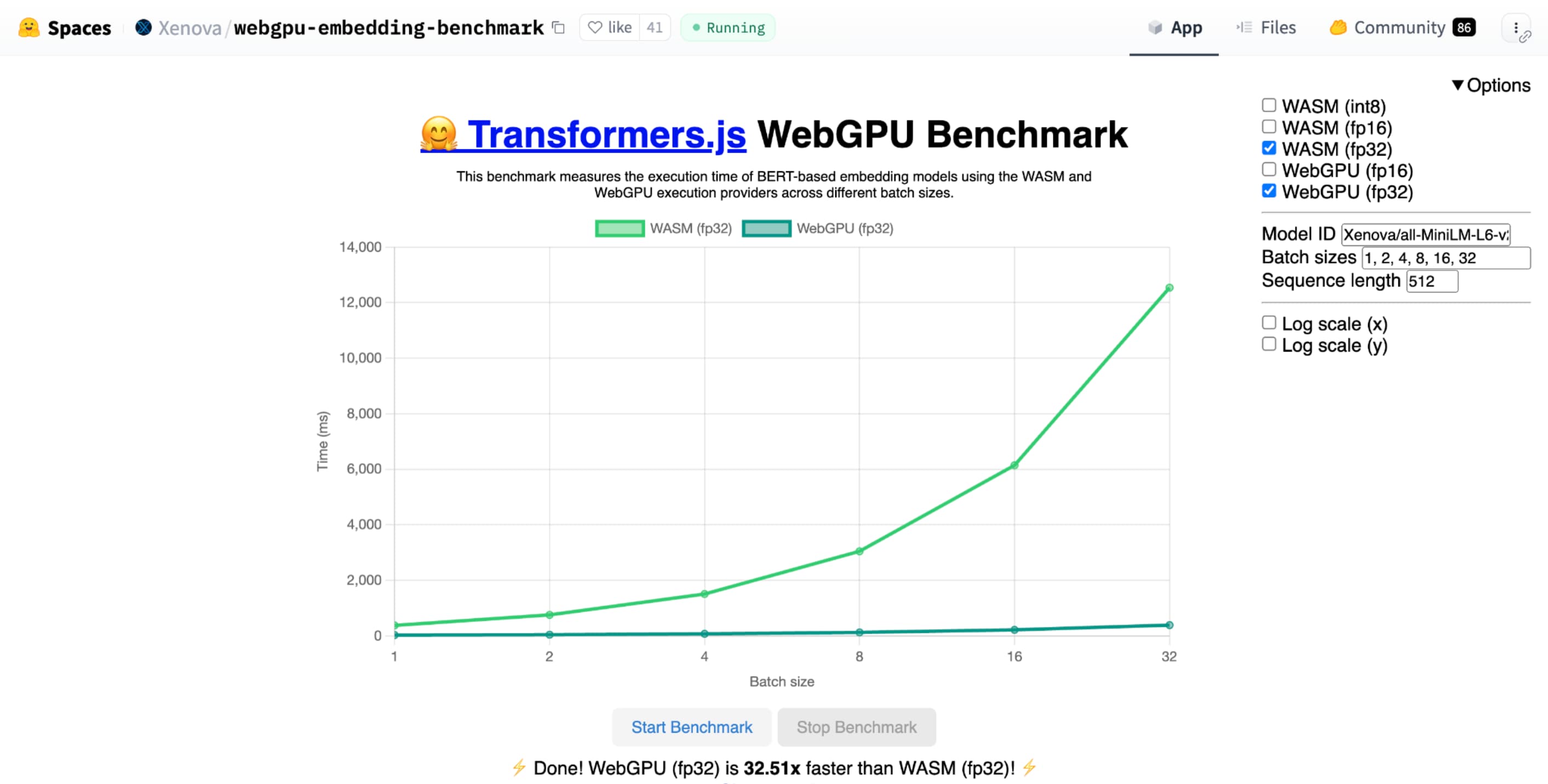
shader-f16 draait de WebGPU-benchmark van Hugging Face voor het insluiten van tekst de benchmark 3 keer sneller dan f32 op een Apple M1 Max-laptop.WebLLM is een project dat meerdere grote taalmodellen kan uitvoeren. Het maakt gebruik van Apache TVM , een open source machine learning compilerframework.
Ik vroeg WebLLM om een reis naar Parijs te plannen, met behulp van het Llama 3-model van acht miljard parameters. De resultaten laten zien dat f16 tijdens de prefill-fase van het model 2,1 keer sneller is dan f32. Tijdens de decodeerfase is het ruim 1,3 keer sneller.
Toepassingen moeten eerst bevestigen dat de GPU-adapter f16 ondersteunt en, indien beschikbaar, deze expliciet inschakelen bij het aanvragen van een GPU-apparaat. Als f16 niet wordt ondersteund, kunt u dit niet aanvragen in de array requiredFeatures .
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Vervolgens moet u in uw WebGPU-shaders bovenaan expliciet f16 inschakelen. Daarna bent u vrij om het binnen de shader te gebruiken, net als elk ander float-gegevenstype.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Verpakte integer dot-producten
Veel modellen werken nog steeds goed met slechts 8 bits precisie (de helft van f16). Dit is populair onder LLM's en beeldmodellen voor segmentatie en objectherkenning. Dat gezegd hebbende, neemt de uitvoerkwaliteit voor modellen af met minder precisie, dus 8-bit kwantisering is niet geschikt voor elke toepassing.
Relatief weinig GPU's ondersteunen native 8-bit-waarden. Dit is waar verpakte integer dot-producten van pas komen. We hebben DP4a geleverd in Chrome 123 .
Moderne GPU's hebben speciale instructies om twee gehele getallen van 32 bits te nemen, deze elk te interpreteren als vier opeenvolgend verpakte gehele getallen van 8 bits, en het puntproduct tussen hun componenten te berekenen.
Dit is vooral handig voor AI en machinaal leren, omdat matrixvermenigvuldigingskernels uit heel veel puntproducten bestaan.
Laten we bijvoorbeeld een matrix van 4 x 8 vermenigvuldigen met een vector van 8 x 1. Om dit te berekenen, moeten we 4 puntproducten nemen om elk van de waarden in de uitvoervector te berekenen; A, B, C en D.
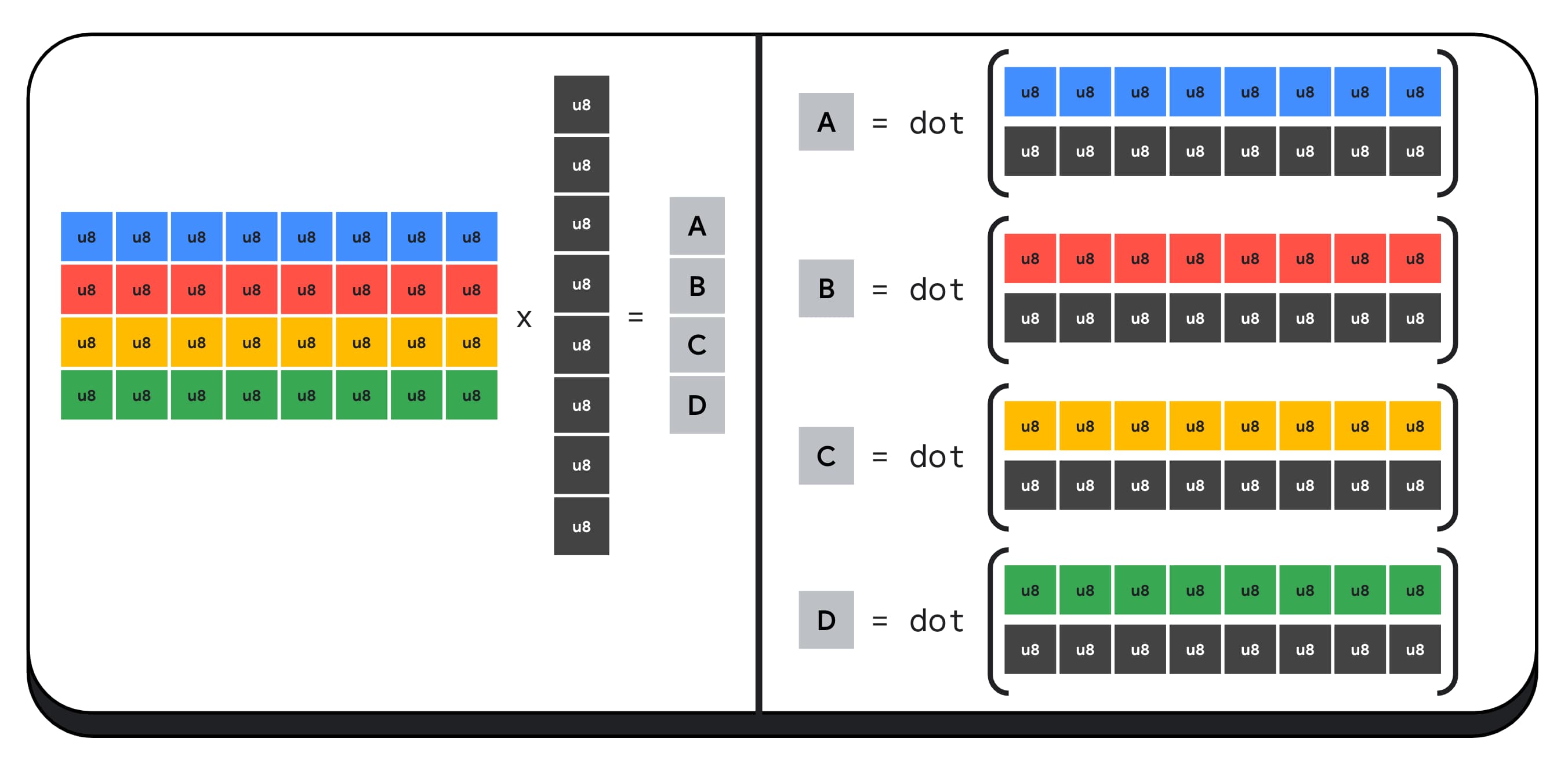
Het proces om elk van deze outputs te berekenen is hetzelfde; we zullen kijken naar de stappen die betrokken zijn bij het berekenen van een van deze stappen. Voordat we met enige berekening beginnen, moeten we eerst de 8-bits integer-gegevens converteren naar een type waarmee we kunnen rekenen, zoals f16. Vervolgens voeren we een elementgewijze vermenigvuldiging uit en tenslotte tellen we alle producten bij elkaar op. In totaal voeren we voor de gehele matrix-vectorvermenigvuldiging 40 integer-to-float-conversies uit om de gegevens uit te pakken, 32 float-vermenigvuldigingen en 28 float-optellingen.
Voor grotere matrices met meer bewerkingen kunnen verpakte integer-dot-producten de hoeveelheid werk helpen verminderen.
Voor elk van de uitvoer in de resultaatvector voeren we twee 'packed dot'-productbewerkingen uit met behulp van de ingebouwde WebGPU Shading Language dot4U8Packed en tellen we vervolgens de resultaten bij elkaar op. In totaal voeren we voor de gehele matrix-vectorvermenigvuldiging geen gegevensconversie uit. We voeren 8 'packed dot'-producten en 4 gehele optellingen uit.
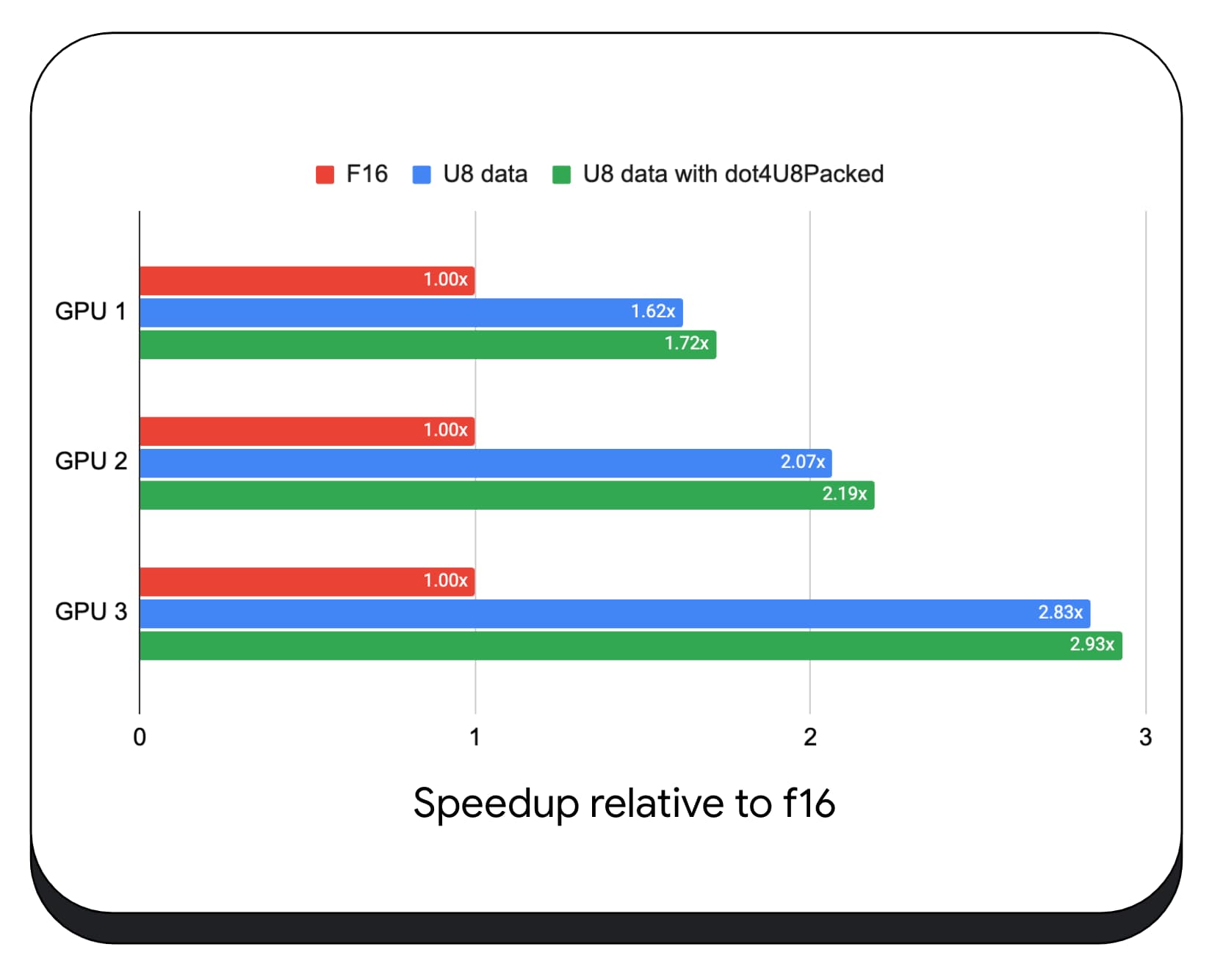
We hebben verpakte integer dot-producten met 8-bits gegevens getest op verschillende consumenten-GPU's. Vergeleken met 16-bits drijvende komma kunnen we zien dat 8-bits 1,6 tot 2,8 keer sneller is. Wanneer we bovendien verpakte integer dot-producten gebruiken, zijn de prestaties nog beter. Het is 1,7 tot 2,9 keer sneller.
Controleer of er browserondersteuning is met de eigenschap wgslLanguageFeatures . Als de GPU standaard geen 'packed dot'-producten ondersteunt, vult de browser zijn eigen implementatie.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Het volgende codefragment diff (verschil) benadrukt de wijzigingen die nodig zijn om verpakte gehele producten in een WebGPU-shader te gebruiken.
Before — Een WebGPU-shader die gedeeltelijke puntproducten accumuleert in de variabele `sum`. Aan het einde van de lus bevat 'som' het volledige puntproduct tussen een vector en één rij van de invoermatrix.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
After - Een WebGPU-shader geschreven om verpakte integer-dot-producten te gebruiken. Het belangrijkste verschil is dat in plaats van vier float-waarden uit de vector en matrix te laden, deze shader één enkel 32-bits geheel getal laadt. Dit 32-bits gehele getal bevat de gegevens van vier 8-bits gehele getallen. Vervolgens roepen we dot4U8Packed aan om het puntproduct van de twee waarden te berekenen.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Zowel 16-bit floating point-producten als verpakte integer dot-producten zijn de meegeleverde functies in Chrome die AI en ML versnellen. 16-bits drijvende komma is beschikbaar als de hardware dit ondersteunt, en Chrome implementeert verpakte integer dot-producten op alle apparaten.
U kunt deze functies vandaag nog in Chrome Stable gebruiken om betere prestaties te bereiken.
Voorgestelde functies
Vooruitkijkend onderzoeken we nog twee kenmerken: subgroepen en coöperatieve matrixvermenigvuldiging.
Dankzij de subgroepenfunctie kan parallellisme op SIMD-niveau communiceren of collectieve wiskundige bewerkingen uitvoeren, zoals een som voor meer dan 16 getallen. Dit maakt een efficiënte cross-thread gegevensuitwisseling mogelijk. Subgroepen worden ondersteund op moderne GPU's API's, met verschillende namen en in enigszins verschillende vormen.
We hebben de gemeenschappelijke set gedestilleerd in een voorstel dat we hebben voorgelegd aan de WebGPU-standaardisatiegroep. En we hebben prototypes gemaakt van subgroepen in Chrome achter een experimentele vlag, en onze eerste resultaten in de discussie gebracht. Het belangrijkste probleem is hoe draagbaar gedrag kan worden gegarandeerd.
Coöperatieve matrixvermenigvuldiging is een recentere toevoeging aan GPU's. Een grote matrixvermenigvuldiging kan worden opgesplitst in meerdere kleinere matrixvermenigvuldigingen. Coöperatieve matrixvermenigvuldiging voert vermenigvuldigingen uit op deze kleinere blokken met een vaste grootte in een enkele logische stap. Binnen die stap werkt een groep threads efficiënt samen om het resultaat te berekenen.
We hebben de ondersteuning in onderliggende GPU-API's onderzocht en zijn van plan een voorstel te presenteren aan de WebGPU-standaardisatiegroep. Net als bij subgroepen verwachten we dat een groot deel van de discussie zich zal concentreren op overdraagbaarheid.
Om de prestaties van subgroepbewerkingen te evalueren, hebben we in een echte toepassing experimentele ondersteuning voor subgroepen in MediaPipe geïntegreerd en deze getest met het prototype van Chrome voor subgroepbewerkingen.
We gebruikten subgroepen in GPU-kernels van de prefill-fase van het grote taalmodel, dus ik rapporteer alleen de versnelling voor de prefill-fase. Op een Intel GPU zien we dat subgroepen tweeënhalf keer sneller presteren dan de basislijn. Deze verbeteringen zijn echter niet consistent voor verschillende GPU's.
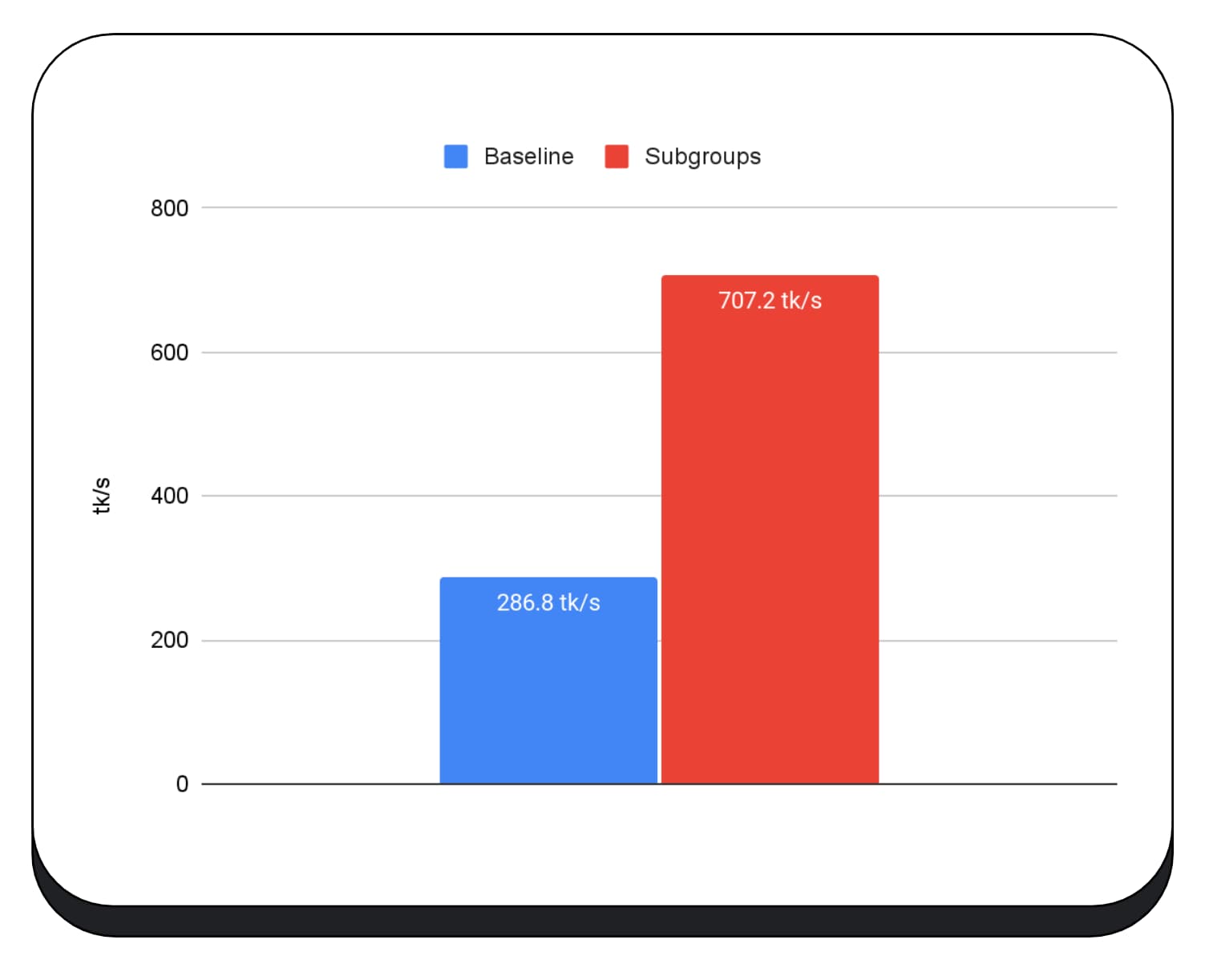
Het volgende diagram toont de resultaten van het toepassen van subgroepen om een matrix-multiply-microbenchmark voor meerdere consumenten-GPU's te optimaliseren. Matrixvermenigvuldiging is een van de zwaardere bewerkingen in grote taalmodellen. Uit de gegevens blijkt dat op veel GPU's subgroepen de snelheid twee, vijf en zelfs dertien keer verhogen ten opzichte van de basislijn. Merk echter op dat subgroepen op de eerste GPU helemaal niet veel beter zijn.
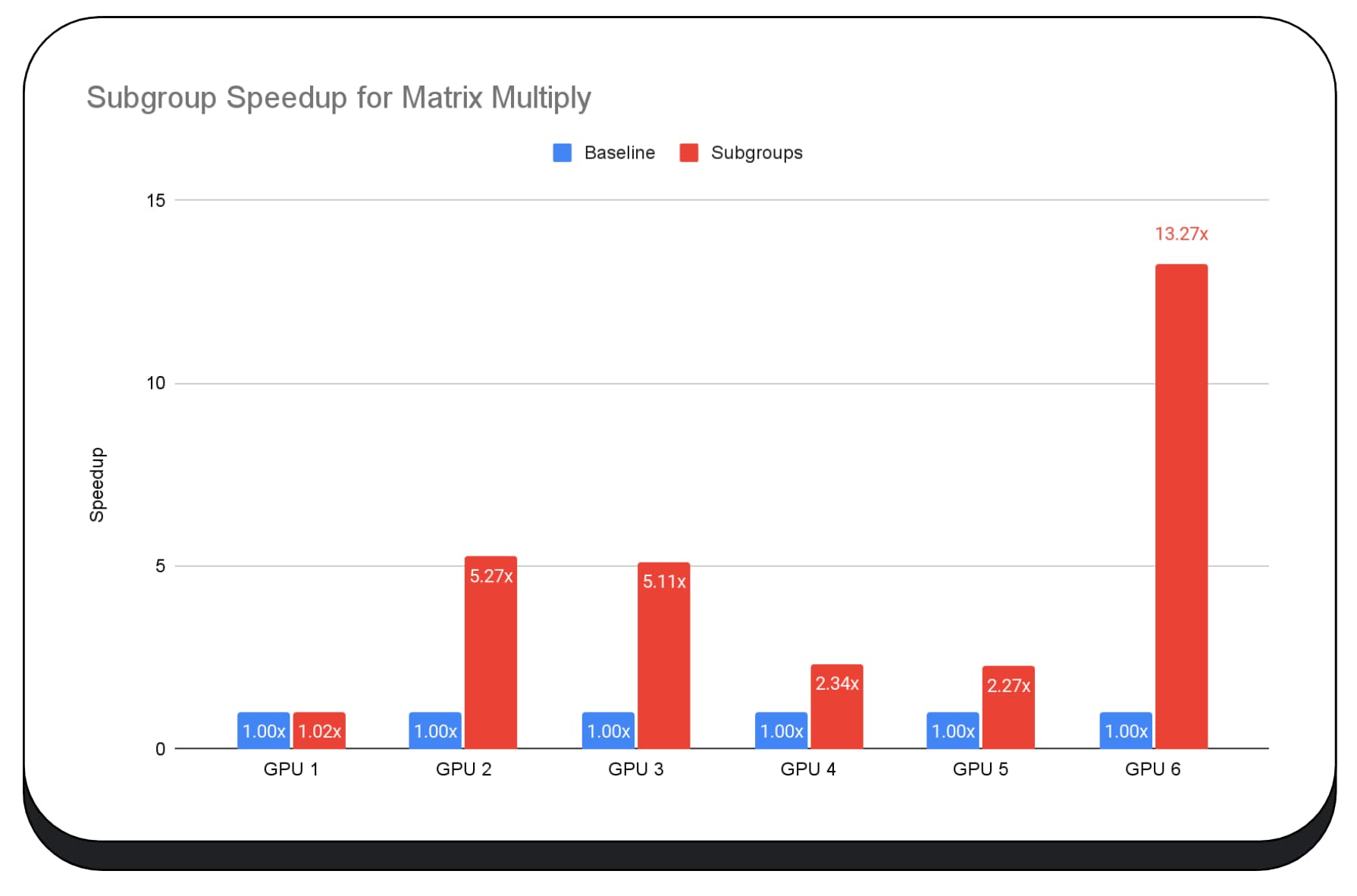
GPU-optimalisatie is moeilijk
Uiteindelijk is de beste manier om uw GPU te optimaliseren afhankelijk van welke GPU de klant biedt. Het gebruik van fraaie nieuwe GPU-functies levert niet altijd de gewenste resultaten op, omdat er veel complexe factoren bij betrokken kunnen zijn. De beste optimalisatiestrategie op de ene GPU is mogelijk niet de beste strategie op een andere GPU.
U wilt de geheugenbandbreedte minimaliseren, terwijl u de computerthreads van de GPU volledig gebruikt.
Geheugentoegangspatronen kunnen ook erg belangrijk zijn. GPU's presteren doorgaans veel beter wanneer de rekenthreads toegang krijgen tot het geheugen in een patroon dat optimaal is voor de hardware. Belangrijk: u kunt op verschillende GPU-hardware verschillende prestatiekenmerken verwachten. Mogelijk moet u verschillende optimalisaties uitvoeren, afhankelijk van de GPU.
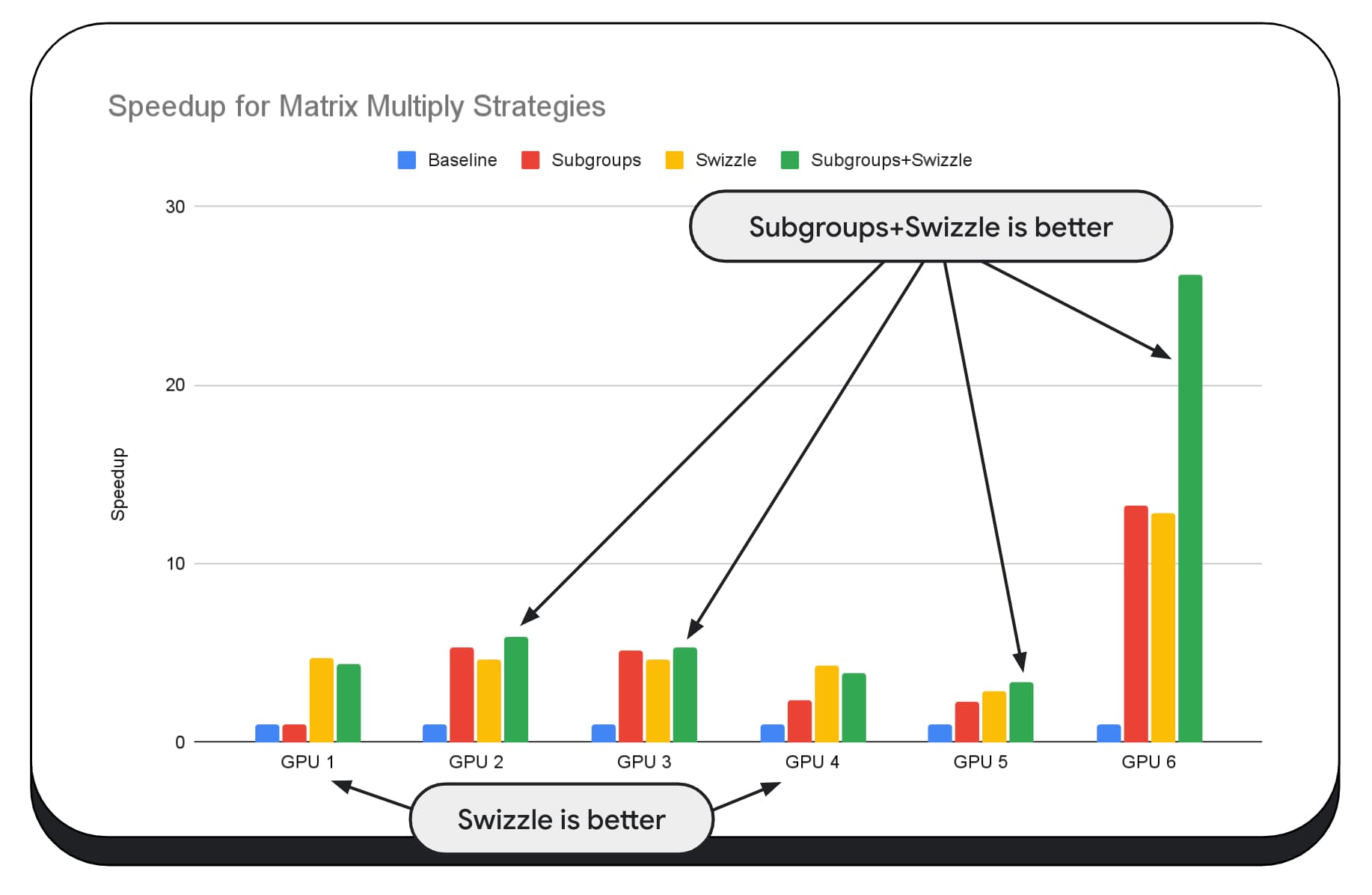
In het volgende diagram hebben we hetzelfde matrixvermenigvuldigingsalgoritme gebruikt, maar een andere dimensie toegevoegd om de impact van verschillende optimalisatiestrategieën en de complexiteit en variantie tussen verschillende GPU's verder aan te tonen. We hebben hier een nieuwe techniek geïntroduceerd, die we 'Swizzle' zullen noemen. Swizzle optimaliseert de geheugentoegangspatronen om optimaal te zijn voor de hardware.
Je kunt zien dat de geheugenswizzle een aanzienlijke impact heeft; het heeft soms zelfs meer impact dan subgroepen. Op GPU 6 biedt swizzle een versnelling van 12x, terwijl subgroepen een versnelling van 13x bieden. Gecombineerd hebben ze een ongelooflijke snelheidswinst van 26x. Voor andere GPU's presteren swizzle en subgroepen soms beter dan elk afzonderlijk. En op andere GPU's presteert uitsluitend gebruik van swizzle het beste.
Het afstemmen en optimaliseren van GPU-algoritmen zodat ze goed werken op elk stuk hardware, kan veel expertise vergen. Maar gelukkig gaat er enorm veel getalenteerd werk naar bibliothekenframeworks van een hoger niveau, zoals Mediapipe , Transformers.js , Apache TVM , ONNX Runtime Web en meer.
Bibliotheken en raamwerken zijn goed gepositioneerd om de complexiteit aan te kunnen van het beheer van diverse GPU-architecturen en het genereren van platformspecifieke code die goed op de client werkt.
Afhaalrestaurants
Het Chrome-team blijft helpen bij het ontwikkelen van de WebAssembly- en WebGPU-standaarden om het webplatform voor machine learning-workloads te verbeteren. We investeren in snellere rekenprimitieven, betere interoperabiliteit tussen webstandaarden en zorgen ervoor dat zowel grote als kleine modellen efficiënt op verschillende apparaten kunnen worden uitgevoerd.
Ons doel is om de mogelijkheden van het platform te maximaliseren en tegelijkertijd het beste van internet te behouden: bereik, bruikbaarheid en draagbaarheid. En we doen dit niet alleen. We werken samen met de andere browserleveranciers bij W3C en met veel ontwikkelingspartners.
We hopen dat u het volgende onthoudt terwijl u met WebAssembly en WebGPU werkt:
- AI-inferentie is nu beschikbaar op internet, op verschillende apparaten. Dit biedt het voordeel van het draaien op clientapparaten, zoals lagere serverkosten, lage latentie en verhoogde privacy.
- Hoewel veel besproken functies vooral relevant zijn voor de auteurs van het raamwerk, kunnen uw toepassingen hiervan profiteren zonder veel overhead.
- Webstandaarden zijn veranderlijk en evolueren, en we zijn altijd op zoek naar feedback. Deel de jouwe voor WebAssembly en WebGPU .
Dankbetuigingen
We willen graag het Intel web graphics-team bedanken, dat een belangrijke rol heeft gespeeld bij het aansturen van de WebGPU f16 en de ingebouwde integer dot-productfuncties. We willen graag de andere leden van de WebAssembly- en WebGPU-werkgroepen bij W3C bedanken, inclusief de andere browserleveranciers.
Bedankt aan de AI- en ML-teams, zowel bij Google als in de open source-gemeenschap, omdat jullie geweldige partners zijn. En natuurlijk al onze teamgenoten die dit allemaal mogelijk maken.
,Dit document is een voortzetting van WebAssembly- en WebGPU-verbeteringen voor snellere Web AI, deel 1 . We raden u aan dit bericht te lezen of de lezing op IO 24 te bekijken voordat u verdergaat .
WebGPU
WebGPU geeft webapplicaties toegang tot de GPU-hardware van de klant om efficiënte, zeer parallelle berekeningen uit te voeren. Sinds de lancering van WebGPU in Chrome hebben we ongelooflijke demo's van kunstmatige intelligentie (AI) en machine learning (ML) op internet gezien.
Web Stable Diffusion heeft bijvoorbeeld aangetoond dat het mogelijk is om AI te gebruiken om afbeeldingen uit tekst te genereren, rechtstreeks in de browser. Eerder dit jaar publiceerde Google's eigen Mediapipe-team experimentele ondersteuning voor gevolgtrekking in grote taalmodellen .
De volgende animatie toont Gemma , het open source grote taalmodel (LLM) van Google, dat volledig op het apparaat in Chrome draait, in realtime.
De volgende demo van Hugging Face van Meta's Segment Anything Model produceert objectmaskers van hoge kwaliteit, volledig op de klant.
Dit zijn slechts een paar van de fantastische projecten die de kracht van WebGPU voor AI en ML laten zien. Met WebGPU kunnen deze en andere modellen aanzienlijk sneller werken dan op de CPU.
De WebGPU-benchmark van Hugging Face voor het insluiten van tekst laat enorme snelheden zien in vergelijking met een CPU-implementatie van hetzelfde model. Op een Apple M1 Max-laptop was WebGPU ruim 30 keer sneller. Anderen hebben gemeld dat WebGPU de benchmark ruim 120 keer versnelt.
Verbetering van WebGPU-functies voor AI en ML
WebGPU is geweldig voor AI- en ML-modellen, die miljarden parameters kunnen hebben, dankzij ondersteuning voor compute shaders . Compute shaders draaien op de GPU en helpen bij het uitvoeren van parallelle array-bewerkingen op grote hoeveelheden gegevens.
Naast de vele verbeteringen aan WebGPU in het afgelopen jaar, zijn we doorgegaan met het toevoegen van meer mogelijkheden om de ML- en AI-prestaties op internet te verbeteren. Onlangs hebben we twee nieuwe functies gelanceerd: 16-bits drijvende-komma- en verpakte integer-dot-producten.
16-bits drijvende komma
Houd er rekening mee dat ML-workloads geen precisie vereisen . shader-f16 is een functie die het gebruik van het f16-type in WebGPU-shading-taal mogelijk maakt. Dit drijvende-kommatype neemt 16 bits in beslag, in plaats van de gebruikelijke 32 bits. f16 heeft een kleiner bereik en is minder nauwkeurig, maar voor veel ML-modellen is dit voldoende.
Deze functie verhoogt de efficiëntie op een aantal manieren:
Verminderd geheugen : Tensors met f16-elementen nemen de helft van de ruimte in beslag, waardoor het geheugengebruik wordt gehalveerd. GPU-berekeningen hebben vaak een knelpunt in de geheugenbandbreedte, dus de helft van het geheugen kan er vaak voor zorgen dat shaders twee keer zo snel werken. Technisch gezien heb je geen f16 nodig om geheugenbandbreedte te besparen. Het is mogelijk om de gegevens op te slaan in een indeling met lage precisie en deze vervolgens uit te breiden tot volledige f32 in de arcering voor berekeningen. Maar de GPU besteedt extra rekenkracht om de gegevens in en uit te pakken.
Verminderde dataconversie : f16 gebruikt minder rekenkracht door de dataconversie te minimaliseren. Gegevens met een lage nauwkeurigheid kunnen worden opgeslagen en vervolgens zonder conversie direct worden gebruikt.
Verhoogd parallellisme : moderne GPU's kunnen meer waarden tegelijkertijd in de uitvoeringseenheden van de GPU passen, waardoor deze een groter aantal parallelle berekeningen kan uitvoeren. Een GPU die tot 5 biljoen f32 drijvende-kommabewerkingen per seconde ondersteunt, kan bijvoorbeeld 10 biljoen f16 drijvende-kommabewerkingen per seconde ondersteunen.
shader-f16 draait de WebGPU-benchmark van Hugging Face voor het insluiten van tekst de benchmark 3 keer sneller dan f32 op een Apple M1 Max-laptop.WebLLM is een project dat meerdere grote taalmodellen kan uitvoeren. Het maakt gebruik van Apache TVM , een open source machine learning compilerframework.
Ik vroeg WebLLM om een reis naar Parijs te plannen, met behulp van het Llama 3-model van acht miljard parameters. De resultaten laten zien dat f16 tijdens de prefill-fase van het model 2,1 keer sneller is dan f32. Tijdens de decodeerfase is het ruim 1,3 keer sneller.
Toepassingen moeten eerst bevestigen dat de GPU-adapter f16 ondersteunt en, indien beschikbaar, deze expliciet inschakelen bij het aanvragen van een GPU-apparaat. Als f16 niet wordt ondersteund, kunt u dit niet aanvragen in de array requiredFeatures .
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Vervolgens moet u in uw WebGPU-shaders bovenaan expliciet f16 inschakelen. Daarna bent u vrij om het binnen de shader te gebruiken, net als elk ander float-gegevenstype.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Verpakte integer dot-producten
Veel modellen werken nog steeds goed met slechts 8 bits precisie (de helft van f16). Dit is populair onder LLM's en beeldmodellen voor segmentatie en objectherkenning. Dat gezegd hebbende, neemt de uitvoerkwaliteit voor modellen af met minder precisie, dus 8-bit kwantisering is niet geschikt voor elke toepassing.
Relatief weinig GPU's ondersteunen native 8-bit-waarden. Dit is waar verpakte integer dot-producten van pas komen. We hebben DP4a geleverd in Chrome 123 .
Moderne GPU's hebben speciale instructies om twee 32-bit gehele getallen te nemen, deze elk te interpreteren als vier opeenvolgend verpakte 8-bit gehele getallen, en het puntproduct tussen hun componenten te berekenen.
Dit is vooral handig voor AI en machinaal leren, omdat matrixvermenigvuldigingskernels uit heel veel puntproducten bestaan.
Laten we bijvoorbeeld een matrix van 4 x 8 vermenigvuldigen met een vector van 8 x 1. Om dit te berekenen, moeten we 4 puntproducten nemen om elk van de waarden in de uitvoervector te berekenen; A, B, C en D.
Het proces om elk van deze outputs te berekenen is hetzelfde; we zullen kijken naar de stappen die betrokken zijn bij het berekenen van een van deze stappen. Voordat we met enige berekening beginnen, moeten we eerst de 8-bits integer-gegevens converteren naar een type waarmee we kunnen rekenen, zoals f16. Vervolgens voeren we een elementgewijze vermenigvuldiging uit en tenslotte tellen we alle producten bij elkaar op. In totaal voeren we voor de gehele matrix-vectorvermenigvuldiging 40 integer-naar-float-conversies uit om de gegevens uit te pakken, 32 float-vermenigvuldigingen en 28 float-optellingen.
Voor grotere matrices met meer bewerkingen kunnen verpakte integer-dot-producten de hoeveelheid werk helpen verminderen.
Voor elk van de uitvoer in de resultaatvector voeren we twee 'packed dot'-productbewerkingen uit met behulp van de ingebouwde WebGPU Shading Language dot4U8Packed en tellen we vervolgens de resultaten bij elkaar op. In totaal voeren we voor de gehele matrix-vectorvermenigvuldiging geen dataconversie uit. We voeren 8 'packed dot'-producten en 4 gehele optellingen uit.
We hebben verpakte integer dot-producten met 8-bits gegevens getest op verschillende consumenten-GPU's. Vergeleken met 16-bits drijvende komma kunnen we zien dat 8-bits 1,6 tot 2,8 keer sneller is. Wanneer we bovendien verpakte integer dot-producten gebruiken, zijn de prestaties nog beter. Het is 1,7 tot 2,9 keer sneller.
Controleer of er browserondersteuning is met de eigenschap wgslLanguageFeatures . Als de GPU standaard geen 'packed dot'-producten ondersteunt, vult de browser zijn eigen implementatie.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Het volgende codefragment diff (verschil) benadrukt de wijzigingen die nodig zijn om verpakte gehele producten in een WebGPU-shader te gebruiken.
Before — Een WebGPU-shader die gedeeltelijke puntproducten accumuleert in de variabele `sum`. Aan het einde van de lus bevat 'som' het volledige puntproduct tussen een vector en één rij van de invoermatrix.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
After - Een WebGPU-shader geschreven om verpakte integer-dot-producten te gebruiken. Het belangrijkste verschil is dat in plaats van vier float-waarden uit de vector en matrix te laden, deze shader één enkel 32-bits geheel getal laadt. Dit 32-bits gehele getal bevat de gegevens van vier 8-bits gehele getallen. Vervolgens roepen we dot4U8Packed aan om het puntproduct van de twee waarden te berekenen.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Zowel 16-bit floating point-producten als verpakte integer dot-producten zijn de meegeleverde functies in Chrome die AI en ML versnellen. 16-bits drijvende komma is beschikbaar als de hardware dit ondersteunt, en Chrome implementeert verpakte integer dot-producten op alle apparaten.
U kunt deze functies vandaag nog in Chrome Stable gebruiken om betere prestaties te bereiken.
Voorgestelde functies
Vooruitkijkend onderzoeken we nog twee kenmerken: subgroepen en coöperatieve matrixvermenigvuldiging.
Dankzij de subgroepenfunctie kan parallellisme op SIMD-niveau communiceren of collectieve wiskundige bewerkingen uitvoeren, zoals een som voor meer dan 16 getallen. Dit maakt een efficiënte cross-thread gegevensuitwisseling mogelijk. Subgroepen worden ondersteund op moderne GPU's API's, met verschillende namen en in enigszins verschillende vormen.
We hebben de gemeenschappelijke set gedestilleerd in een voorstel dat we hebben voorgelegd aan de WebGPU-standaardisatiegroep. En we hebben prototypes gemaakt van subgroepen in Chrome achter een experimentele vlag, en onze eerste resultaten in de discussie gebracht. Het belangrijkste probleem is hoe draagbaar gedrag kan worden gegarandeerd.
Coöperatieve matrixvermenigvuldiging is een recentere toevoeging aan GPU's. Een grote matrixvermenigvuldiging kan worden opgesplitst in meerdere kleinere matrixvermenigvuldigingen. Coöperatieve matrixvermenigvuldiging voert vermenigvuldigingen uit op deze kleinere blokken met een vaste grootte in een enkele logische stap. Binnen die stap werkt een groep threads efficiënt samen om het resultaat te berekenen.
We hebben de ondersteuning in onderliggende GPU-API's onderzocht en zijn van plan een voorstel te presenteren aan de WebGPU-standaardisatiegroep. Net als bij subgroepen verwachten we dat een groot deel van de discussie zich zal concentreren op overdraagbaarheid.
Om de prestaties van subgroepbewerkingen te evalueren, hebben we in een echte toepassing experimentele ondersteuning voor subgroepen in MediaPipe geïntegreerd en deze getest met het prototype van Chrome voor subgroepbewerkingen.
We gebruikten subgroepen in GPU-kernels van de prefill-fase van het grote taalmodel, dus ik rapporteer alleen de versnelling voor de prefill-fase. Op een Intel GPU zien we dat subgroepen tweeënhalf keer sneller presteren dan de basislijn. Deze verbeteringen zijn echter niet consistent voor verschillende GPU's.
Het volgende diagram toont de resultaten van het toepassen van subgroepen om een matrix-multiply-microbenchmark voor meerdere consumenten-GPU's te optimaliseren. Matrixvermenigvuldiging is een van de zwaardere bewerkingen in grote taalmodellen. Uit de gegevens blijkt dat op veel GPU's subgroepen de snelheid twee, vijf en zelfs dertien keer verhogen ten opzichte van de basislijn. Merk echter op dat subgroepen op de eerste GPU helemaal niet veel beter zijn.
GPU-optimalisatie is moeilijk
Uiteindelijk is de beste manier om uw GPU te optimaliseren afhankelijk van welke GPU de klant biedt. Het gebruik van fraaie nieuwe GPU-functies levert niet altijd de gewenste resultaten op, omdat er veel complexe factoren bij betrokken kunnen zijn. De beste optimalisatiestrategie op de ene GPU is mogelijk niet de beste strategie op een andere GPU.
U wilt de geheugenbandbreedte minimaliseren, terwijl u de computerthreads van de GPU volledig gebruikt.
Geheugentoegangspatronen kunnen ook erg belangrijk zijn. GPU's presteren doorgaans veel beter wanneer de rekenthreads toegang krijgen tot het geheugen in een patroon dat optimaal is voor de hardware. Belangrijk: u kunt op verschillende GPU-hardware verschillende prestatiekenmerken verwachten. Mogelijk moet u verschillende optimalisaties uitvoeren, afhankelijk van de GPU.
In het volgende diagram hebben we hetzelfde matrixvermenigvuldigingsalgoritme gebruikt, maar een andere dimensie toegevoegd om de impact van verschillende optimalisatiestrategieën en de complexiteit en variantie tussen verschillende GPU's verder aan te tonen. We hebben hier een nieuwe techniek geïntroduceerd, die we 'Swizzle' zullen noemen. Swizzle optimaliseert de geheugentoegangspatronen om optimaal te zijn voor de hardware.
Je kunt zien dat de geheugenswizzle een aanzienlijke impact heeft; het heeft soms zelfs meer impact dan subgroepen. Op GPU 6 biedt swizzle een versnelling van 12x, terwijl subgroepen een versnelling van 13x bieden. Gecombineerd hebben ze een ongelooflijke snelheidswinst van 26x. Voor andere GPU's presteren swizzle en subgroepen soms beter dan elk afzonderlijk. En op andere GPU's presteert uitsluitend gebruik van swizzle het beste.
Het afstemmen en optimaliseren van GPU-algoritmen zodat ze goed werken op elk stuk hardware, kan veel expertise vergen. Maar gelukkig gaat er enorm veel getalenteerd werk naar bibliothekenframeworks op een hoger niveau, zoals Mediapipe , Transformers.js , Apache TVM , ONNX Runtime Web en meer.
Bibliotheken en raamwerken zijn goed gepositioneerd om de complexiteit aan te kunnen van het beheer van diverse GPU-architecturen en het genereren van platformspecifieke code die goed op de client werkt.
Afhaalrestaurants
Het Chrome-team blijft helpen bij het ontwikkelen van de WebAssembly- en WebGPU-standaarden om het webplatform voor machine learning-workloads te verbeteren. We investeren in snellere rekenprimitieven, betere interoperabiliteit tussen webstandaarden en zorgen ervoor dat zowel grote als kleine modellen efficiënt op verschillende apparaten kunnen worden uitgevoerd.
Ons doel is om de mogelijkheden van het platform te maximaliseren en tegelijkertijd het beste van internet te behouden: bereik, bruikbaarheid en draagbaarheid. En we doen dit niet alleen. We werken samen met de andere browserleveranciers bij W3C en met veel ontwikkelingspartners.
We hopen dat u het volgende onthoudt terwijl u met WebAssembly en WebGPU werkt:
- AI-inferentie is nu beschikbaar op internet, op verschillende apparaten. Dit biedt het voordeel van het draaien op clientapparaten, zoals lagere serverkosten, lage latentie en verhoogde privacy.
- Hoewel veel besproken functies vooral relevant zijn voor de auteurs van het raamwerk, kunnen uw toepassingen hiervan profiteren zonder veel overhead.
- Webstandaarden zijn veranderlijk en evolueren, en we zijn altijd op zoek naar feedback. Deel de jouwe voor WebAssembly en WebGPU .
Dankbetuigingen
We willen graag het Intel web graphics-team bedanken, dat een belangrijke rol heeft gespeeld bij het aansturen van de WebGPU f16 en de ingebouwde integer dot-productfuncties. We willen graag de andere leden van de WebAssembly- en WebGPU-werkgroepen bij W3C bedanken, inclusief de andere browserleveranciers.
Bedankt aan de AI- en ML-teams, zowel bij Google als in de open source-gemeenschap, omdat jullie geweldige partners zijn. En natuurlijk al onze teamgenoten die dit allemaal mogelijk maken.
,Dit document is een voortzetting van WebAssembly- en WebGPU-verbeteringen voor snellere Web AI, deel 1 . We raden u aan dit bericht te lezen of de lezing op IO 24 te bekijken voordat u verdergaat .
WebGPU
WebGPU geeft webapplicaties toegang tot de GPU-hardware van de klant om efficiënte, zeer parallelle berekeningen uit te voeren. Sinds de lancering van WebGPU in Chrome hebben we ongelooflijke demo's van kunstmatige intelligentie (AI) en machine learning (ML) op internet gezien.
Web Stable Diffusion heeft bijvoorbeeld aangetoond dat het mogelijk is om AI te gebruiken om afbeeldingen uit tekst te genereren, rechtstreeks in de browser. Eerder dit jaar publiceerde Google's eigen Mediapipe-team experimentele ondersteuning voor gevolgtrekking in grote taalmodellen .
De volgende animatie toont Gemma , het open source grote taalmodel (LLM) van Google, dat volledig op het apparaat in Chrome draait, in realtime.
De volgende demo van Hugging Face van Meta's Segment Anything Model produceert objectmaskers van hoge kwaliteit, volledig op de klant.
Dit zijn slechts een paar van de fantastische projecten die de kracht van WebGPU voor AI en ML laten zien. Met WebGPU kunnen deze en andere modellen aanzienlijk sneller werken dan op de CPU.
De WebGPU-benchmark van Hugging Face voor het insluiten van tekst laat enorme snelheden zien in vergelijking met een CPU-implementatie van hetzelfde model. Op een Apple M1 Max-laptop was WebGPU ruim 30 keer sneller. Anderen hebben gemeld dat WebGPU de benchmark ruim 120 keer versnelt.
Verbetering van WebGPU-functies voor AI en ML
WebGPU is geweldig voor AI- en ML-modellen, die miljarden parameters kunnen hebben, dankzij ondersteuning voor compute shaders . Compute shaders draaien op de GPU en helpen bij het uitvoeren van parallelle array-bewerkingen op grote hoeveelheden gegevens.
Naast de vele verbeteringen aan WebGPU in het afgelopen jaar, zijn we doorgegaan met het toevoegen van meer mogelijkheden om de ML- en AI-prestaties op internet te verbeteren. Onlangs hebben we twee nieuwe functies gelanceerd: 16-bits drijvende-komma- en verpakte integer-dot-producten.
16-bits drijvende komma
Houd er rekening mee dat ML-workloads geen precisie vereisen . shader-f16 is een functie die het gebruik van het f16-type in WebGPU-shading-taal mogelijk maakt. Dit drijvende-kommatype neemt 16 bits in beslag, in plaats van de gebruikelijke 32 bits. f16 heeft een kleiner bereik en is minder nauwkeurig, maar voor veel ML-modellen is dit voldoende.
Deze functie verhoogt de efficiëntie op een aantal manieren:
Verminderd geheugen : Tensors met f16-elementen nemen de helft van de ruimte in beslag, waardoor het geheugengebruik wordt gehalveerd. GPU-berekeningen hebben vaak een knelpunt in de geheugenbandbreedte, dus de helft van het geheugen kan er vaak voor zorgen dat shaders twee keer zo snel werken. Technisch gezien heb je geen f16 nodig om geheugenbandbreedte te besparen. Het is mogelijk om de gegevens op te slaan in een indeling met lage precisie en deze vervolgens uit te breiden tot volledige f32 in de arcering voor berekeningen. Maar de GPU besteedt extra rekenkracht om de gegevens in en uit te pakken.
Verminderde dataconversie : f16 gebruikt minder rekenkracht door de dataconversie te minimaliseren. Gegevens met een lage nauwkeurigheid kunnen worden opgeslagen en vervolgens zonder conversie direct worden gebruikt.
Verhoogd parallellisme : moderne GPU's kunnen meer waarden tegelijkertijd in de uitvoeringseenheden van de GPU passen, waardoor deze een groter aantal parallelle berekeningen kan uitvoeren. Een GPU die tot 5 biljoen f32 drijvende-kommabewerkingen per seconde ondersteunt, kan bijvoorbeeld 10 biljoen f16 drijvende-kommabewerkingen per seconde ondersteunen.
shader-f16 wordt de WebGPU-benchmark van Hugging Face voor de inbedding van de tekst 3 keer sneller de benchmark uitgevoerd dan F32 op Apple M1 Max-laptop.Webllm is een project dat meerdere grote taalmodellen kan uitvoeren. Het maakt gebruik van Apache TVM , een open source machine learning compiler framework.
Ik vroeg Webllm om een reis naar Parijs te plannen met behulp van het LLAMA 3 Acht miljard parametermodel. De resultaten laten zien dat tijdens de voorkeursfase van het model F16 2,1 keer sneller is dan F32. Tijdens de decodefase is deze meer dan 1,3 keer sneller.
Toepassingen moeten eerst bevestigen dat de GPU -adapter F16 ondersteunt, en als deze beschikbaar is, schakelt u deze expliciet in bij het aanvragen van een GPU -apparaat. Als F16 niet wordt ondersteund, kunt u dit niet aanvragen in de requiredFeatures array.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Vervolgens moet u in uw WebGPU -shaders F16 expliciet bovenaan inschakelen. Daarna ben je vrij om het in de shader te gebruiken, net als elk ander vlotterdattype.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Packed Integer Dot -producten
Veel modellen werken nog steeds goed met slechts 8 bits precisie (de helft van de F16). Dit is populair bij LLMS en beeldmodellen voor segmentatie en objectherkenning. Dat gezegd hebbende, de uitvoerkwaliteit voor modellen degradeert met minder precisie, dus 8-bit kwantisatie is niet geschikt voor elke toepassing.
Relatief weinig GPU's ondersteunen native 8-bit waarden. Dit is waar gepakte gehele DOT -producten binnenkomen. We verzonden DP4A in Chrome 123 .
Moderne GPU's hebben speciale instructies om twee 32-bits gehele getallen te nemen, ze elk te interpreteren als 4 opeenvolgende 8-bits gehele getallen en het puntproduct tussen hun componenten te berekenen.
Dit is met name handig voor AI en machine learning omdat matrixvermenigingskorrels zijn samengesteld uit vele, vele DOT -producten.
Laten we bijvoorbeeld een 4 x 8 matrix vermenigvuldigen met een 8 x 1 vector. Computeren hiermee omvat het nemen van 4 puntproducten om elk van de waarden in de uitgangsvector te berekenen; A, B, C en D.
Het proces om elk van deze uitgangen te berekenen is hetzelfde; We zullen kijken naar de stappen die betrokken zijn bij het berekenen van een van hen. Vóór een berekening moeten we eerst de 8-bit integer-gegevens converteren naar een type waarmee we rekenkunde kunnen uitvoeren, zoals F16. Vervolgens voeren we een elementgewijze vermenigvuldiging uit en voegen ten slotte alle producten toe. In totaal voeren we voor de gehele matrix-vector vermenigvuldiging 40 geheel getal uit om conversies te drijven om de gegevens uit te pakken, 32 float-vermenigvuldigingen en 28 float-toevoegingen.
Voor grotere matrices met meer bewerkingen kunnen gepakte gehele dot -producten helpen de hoeveelheid werk te verminderen.
Voor elk van de uitgangen in de resultaatvector voeren we twee verpakte DOT-productbewerkingen uit met behulp van de WebGPU-schaduwtaal ingebouwde dot4U8Packed en voegen we de resultaten bij elkaar toe. In totaal voeren we voor de gehele matrix-vector vermenigvuldiging geen gegevensconversie uit. We voeren 8 ingepakte puntproducten en 4 gehele toevoegingen uit.
We hebben verpakte gehele getal DOT-producten getest met 8-bit gegevens over verschillende GPU's van de consument. In vergelijking met 16-bits drijvende punt kunnen we zien dat 8-bit 1,6 tot 2,8 keer sneller is. Wanneer we bovendien ingepakte gehele DOT -producten gebruiken, zijn de prestaties nog beter. Het is 1,7 tot 2,9 keer sneller.
Controleer op browserondersteuning met de eigenschap wgslLanguageFeatures . Als de GPU geen native ingepakte DOT -producten ondersteunt, dan wordt de browser zijn eigen implementatie polyfills.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Het volgende codefragment diff (verschil) dat de wijzigingen benadrukt die nodig zijn om gepakte gehele producten te gebruiken in een WebGPU -shader.
Voordat - een WebGPU -schader die gedeeltelijke puntproducten verzamelt in de variabele 'sum'. Aan het einde van de lus bevat `sum` het volledige puntproduct tussen een vector en een rij van de invoermatrix.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Na - een WebGPU -shader geschreven om ingepakte gehele DOT -producten te gebruiken. Het belangrijkste verschil is dat in plaats van 4 floatwaarden uit de vector en matrix te laden, deze schader een enkel gehele 32-bits geheel getal laadt. Dit 32-bit gehele getal bevat de gegevens van vier 8-bit gehele waarde. Vervolgens roepen we dot4U8Packed aan om het puntproduct van de twee waarden te berekenen.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Zowel 16-bit drijvende punt als verpakte gehele DOT-producten zijn de verzonden functies in chroom die AI en ML versnellen. 16-bit drijvende punt is beschikbaar wanneer de hardware het ondersteunt en Chrome in alle apparaten ingepakte gehele TEGER DOT-producten implementeert.
U kunt deze functies vandaag in Chrome Stable gebruiken om betere prestaties te bereiken.
Voorgestelde kenmerken
Uitkijken vooruit, we onderzoeken nog twee functies: subgroepen en coöperatieve matrix vermenigvuldiging.
Met de functie Subgroepen kan SIMD-niveau parallellisme communiceren of collectieve wiskundige bewerkingen uitvoeren, zoals een som voor meer dan 16 nummers. Dit zorgt voor efficiënte cross-thread gegevensuitwisseling. Subgroepen worden ondersteund op moderne GPUS API's, met verschillende namen en in enigszins verschillende vormen.
We hebben de gemeenschappelijke set gedistilleerd in een voorstel dat we naar de WebGPU -standaardisatiegroep hebben gebracht. En we hebben geprototypeerde subgroepen in chroom achter een experimentele vlag en hebben onze eerste resultaten in de discussie gebracht. Het belangrijkste probleem is hoe draagbaar gedrag te garanderen.
Cooperative Matrix Multipy is een recentere toevoeging aan GPU's. Een grote matrixvermenigvuldiging kan worden onderverdeeld in meerdere kleinere matrixvermenigvuldigingen. Cooperative Matrix Multipy voert vermenigvuldigingen uit op deze kleinere blokken met een vaste grootte in een enkele logische stap. Binnen die stap werkt een groep threads efficiënt samen om het resultaat te berekenen.
We hebben ondersteuning onderzocht in onderliggende GPU API's en zijn van plan een voorstel te presenteren aan de WebGPU -standaardisatiegroep. Net als bij subgroepen verwachten we dat veel van de discussie zich zal concentreren op de draagbaarheid.
Om de prestaties van subgroepoperaties te evalueren, in een echte toepassing, hebben we experimentele ondersteuning voor subgroepen in MediaPipe geïntegreerd en getest met het prototype van Chrome voor subgroepbewerkingen.
We hebben subgroepen gebruikt in GPU -kernels van de voorvulfase van het grote taalmodel, dus ik rapporteer alleen de versnelling voor de voorvillfase. Op een Intel GPU zien we dat subgroepen twee en een half keer sneller presteren dan de basislijn. Deze verbeteringen zijn echter niet consistent in verschillende GPU's.
De volgende grafiek toont de resultaten van het toepassen van subgroepen om een Matrix Multiple Microbenchmark te optimaliseren over meerdere GPU's van meerdere consumenten. Matrix vermenigvuldiging is een van de zwaardere bewerkingen in grote taalmodellen. Uit de gegevens blijkt dat op veel van de GPU's subgroepen de snelheid twee, vijf en zelfs dertien keer de basislijn verhogen. Merk echter op dat op de eerste GPU subgroepen helemaal niet veel beter zijn.
GPU -optimalisatie is moeilijk
Uiteindelijk is de beste manier om uw GPU te optimaliseren, afhankelijk van welke GPU de klant biedt. Het gebruik van fancy nieuwe GPU -functies loont niet altijd op hun manier die u zou verwachten, omdat er veel complexe factoren kunnen zijn. De beste optimalisatiestrategie voor de ene GPU is misschien niet de beste strategie voor een andere GPU.
U wilt de geheugenbandbreedte minimaliseren, terwijl u de computerthreads van de GPU volledig gebruikt.
Geheugentoegangspatronen kunnen ook erg belangrijk zijn. GPU's hebben de neiging om veel beter te presteren wanneer het Compute -threads toegang krijgen tot geheugen in een patroon dat optimaal is voor de hardware. Belangrijk: u moet verschillende prestatiekenmerken verwachten op verschillende GPU -hardware. Mogelijk moet u verschillende optimalisaties uitvoeren, afhankelijk van de GPU.
In de volgende grafiek hebben we hetzelfde Matrix Multipy -algoritme genomen, maar een andere dimensie toegevoegd om de impact van verschillende optimalisatiestrategieën en de complexiteit en variantie over verschillende GPU's verder aan te tonen. We hebben hier een nieuwe techniek geïntroduceerd, die we "Swizzle" zullen noemen. Swizzle optimaliseert de geheugentoegangspatronen om optimaaler te zijn voor de hardware.
Je kunt zien dat de geheugen swizzle een aanzienlijke impact heeft; Het is soms zelfs zelfs impactvoller dan subgroepen. Op GPU 6 biedt Swizzle een 12x versnelling, terwijl subgroepen een 13x versnelling bieden. Gecombineerd hebben ze een ongelooflijke 26x -versnelling. Voor andere GPU's presteren soms swizzle en subgroepen gecombineerd beter dan een van beide alleen. En op andere GPU's presteert exclusief gebruiken Swizzle het beste.
Het afstemmen en optimaliseren van GPU -algoritmen om goed te werken op elk stuk hardware, kan veel expertise vereisen. Maar gelukkig is er een enorme hoeveelheid getalenteerd werk naar bibliotheken op een hoger niveau, zoals MediaPipe , Transformers.js , Apache TVM , OnNX Runtime Web en meer.
Bibliotheken en frameworks zijn goed gepositioneerd om de complexiteit van het beheren van diverse GPU-architecturen en het genereren van platformspecifieke code die goed op de client zal werken, om te gaan.
Afhaalrestaurants
Het Chrome -team blijft helpen bij het evolueren van de WebAssembly- en WebGPU -normen om het webplatform voor werklast van machine learning te verbeteren. We investeren in snellere rekenprimitieven, een betere interop tussen webstandaarden en zorgen ervoor dat modellen zowel groot als klein in staat zijn om efficiënt te lopen op apparaten.
Ons doel is om de mogelijkheden van het platform te maximaliseren met behoud van het beste van het web: het is bereik, bruikbaarheid en draagbaarheid. En we doen dit niet alleen. We werken in samenwerking met de andere browserverkopers bij W3C en veel ontwikkelingspartners.
We hopen dat u zich het volgende herinnert, terwijl u werkt met WebAssembly en WebGPU:
- AI -inferentie is nu beschikbaar op internet, over apparaten. Dit biedt het voordeel van het uitvoeren van clientapparaten, zoals lagere serverkosten, lage latentie en verhoogde privacy.
- Hoewel veel besproken functies voornamelijk relevant zijn voor de auteurs van de kader, kunnen uw applicaties profiteren zonder veel overhead.
- Webstandaarden zijn vloeiend en evolueren, en we zijn altijd op zoek naar feedback. Deel de uwe voor WebAssembly en WebGPU .
Dankbetuigingen
We willen graag het Intel Web Graphics Team bedanken, die een belangrijke rol speelden bij het besturen van de WebGPU F16 en Packed Integer DOT -productfuncties. We willen graag de andere leden van de WebAssembly- en WebGPU -werkgroepen bedanken bij W3C, inclusief de andere browserverkopers.
Bedankt aan de AI- en ML -teams, zowel bij Google als in de open source -community voor ongelooflijke partners. En natuurlijk, al onze teamgenoten die dit allemaal mogelijk maken.
,Dit document is een voortzetting van webassembly- en WebGPU -verbeteringen voor snellere web AI, deel 1 . We raden u aan dit bericht te lezen of het gesprek te bekijken op IO 24 voordat u verder gaat .
WebGPU
WebGPU geeft webtoepassingen toegang tot de GPU-hardware van de client om efficiënte, zeer parallelle berekening uit te voeren. Sinds de lancering WebGPU in Chrome , hebben we ongelooflijke demo's van kunstmatige intelligentie (AI) en machine learning (ML) op internet gezien.
Webstabiele diffusie heeft bijvoorbeeld aangetoond dat het mogelijk was om AI te gebruiken om afbeeldingen uit tekst te genereren, direct in de browser. Eerder dit jaar publiceerde Google's eigen MediaPipe -team experimentele ondersteuning voor grote taalmodelinferentie .
De volgende animatie toont Gemma , Google's Open Source Large Language Model (LLM), die volledig op de apparaten in Chrome wordt uitgevoerd, in realtime.
De volgende knuffelface's demo van het segment van Meta Alles Model produceert objectmaskers van hoge kwaliteit volledig op de klant.
Dit zijn slechts een paar van de geweldige projecten die de kracht van WebGPU voor AI en ML laten zien. Met WebGPU kunnen deze modellen en anderen aanzienlijk sneller werken dan op de CPU.
Webgpu -benchmark van Hugging Face voor tekstinbedding toont enorme versnellings in vergelijking met een CPU -implementatie van hetzelfde model. Op een Max -laptop van Apple M1 was WebGPU meer dan 30 keer sneller. Anderen hebben gemeld dat WebGPU de benchmark versnelt met meer dan 120 keer .
WebGPU -functies verbeteren voor AI en ML
WebGPU is geweldig voor AI- en ML -modellen, die miljarden parameters kunnen hebben, dankzij ondersteuning voor Compute Shaders . Bereken shaders die worden uitgevoerd op de GPU en help parallelle array -bewerkingen uit te voeren op grote hoeveelheden gegevens.
Onder de vele verbeteringen in WebGPU in het afgelopen jaar zijn we meer mogelijkheden blijven toevoegen om ML- en AI -prestaties op internet te verbeteren. Onlangs hebben we twee nieuwe functies gelanceerd: 16-bits drijvende punt en ingepakte gehele DOT-producten.
16-bits drijvende punt
Vergeet niet dat ML -workloads geen precisie vereisen . shader-f16 is een functie die het gebruik van het F16-type in WebGPU-schaduwtaal mogelijk maakt. Dit drijvende punttype neemt 16 bits in in plaats van de gebruikelijke 32 bits. F16 heeft een kleiner bereik en is minder nauwkeurig, maar voor veel ML -modellen is dit voldoende.
Deze functie verhoogt de efficiëntie op een paar manieren:
Verminderd geheugen : Tensoren met F16 -elementen nemen de helft van de ruimte in beslag, wat geheugengebruik in de helft snijdt. GPU -berekeningen zijn vaak knelpunten op geheugenbandbreedte, dus de helft van het geheugen kan vaak betekenen dat shaders twee keer zo snel werken. Technisch gezien heb je geen F16 nodig om op te slaan op geheugenbandbreedte. Het is mogelijk om de gegevens op te slaan in een formaat met weinig nauwkeurigheid en vervolgens uit te breiden naar volledige F32 in de shader voor berekening. Maar de GPU besteedt extra rekenkracht om de gegevens in te pakken en uit te pakken.
Verminderde gegevensconversie : F16 maakt gebruik van minder reken door gegevensconversie te minimaliseren. Lage precisiegegevens kunnen worden opgeslagen en vervolgens direct zonder conversie worden gebruikt.
Verhoogd parallellisme : moderne GPU's kunnen meer waarden tegelijkertijd passen in de uitvoeringseenheden van de GPU, waardoor het een groter aantal parallelle berekeningen kan uitvoeren. Een GPU die bijvoorbeeld tot 5 biljoen F32 Floating-Point-bewerkingen per seconde ondersteunt, kan bijvoorbeeld 10 biljoen F16 Floating-Point-bewerkingen per seconde ondersteunen.
shader-f16 wordt de WebGPU-benchmark van Hugging Face voor de inbedding van de tekst 3 keer sneller de benchmark uitgevoerd dan F32 op Apple M1 Max-laptop.Webllm is een project dat meerdere grote taalmodellen kan uitvoeren. Het maakt gebruik van Apache TVM , een open source machine learning compiler framework.
Ik vroeg Webllm om een reis naar Parijs te plannen met behulp van het LLAMA 3 Acht miljard parametermodel. De resultaten laten zien dat tijdens de voorkeursfase van het model F16 2,1 keer sneller is dan F32. Tijdens de decodefase is deze meer dan 1,3 keer sneller.
Toepassingen moeten eerst bevestigen dat de GPU -adapter F16 ondersteunt, en als deze beschikbaar is, schakelt u deze expliciet in bij het aanvragen van een GPU -apparaat. Als F16 niet wordt ondersteund, kunt u dit niet aanvragen in de requiredFeatures array.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Vervolgens moet u in uw WebGPU -shaders F16 expliciet bovenaan inschakelen. Daarna ben je vrij om het in de shader te gebruiken, net als elk ander vlotterdattype.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Packed Integer Dot -producten
Veel modellen werken nog steeds goed met slechts 8 bits precisie (de helft van de F16). Dit is populair bij LLMS en beeldmodellen voor segmentatie en objectherkenning. Dat gezegd hebbende, de uitvoerkwaliteit voor modellen degradeert met minder precisie, dus 8-bit kwantisatie is niet geschikt voor elke toepassing.
Relatief weinig GPU's ondersteunen native 8-bit waarden. Dit is waar gepakte gehele DOT -producten binnenkomen. We verzonden DP4A in Chrome 123 .
Moderne GPU's hebben speciale instructies om twee 32-bits gehele getallen te nemen, ze elk te interpreteren als 4 opeenvolgende 8-bits gehele getallen en het puntproduct tussen hun componenten te berekenen.
Dit is met name handig voor AI en machine learning omdat matrixvermenigingskorrels zijn samengesteld uit vele, vele DOT -producten.
Laten we bijvoorbeeld een 4 x 8 matrix vermenigvuldigen met een 8 x 1 vector. Computeren hiermee omvat het nemen van 4 puntproducten om elk van de waarden in de uitgangsvector te berekenen; A, B, C en D.
Het proces om elk van deze uitgangen te berekenen is hetzelfde; We zullen kijken naar de stappen die betrokken zijn bij het berekenen van een van hen. Vóór een berekening moeten we eerst de 8-bit integer-gegevens converteren naar een type waarmee we rekenkunde kunnen uitvoeren, zoals F16. Vervolgens voeren we een elementgewijze vermenigvuldiging uit en voegen ten slotte alle producten toe. In totaal voeren we voor de gehele matrix-vector vermenigvuldiging 40 geheel getal uit om conversies te drijven om de gegevens uit te pakken, 32 float-vermenigvuldigingen en 28 float-toevoegingen.
Voor grotere matrices met meer bewerkingen kunnen gepakte gehele dot -producten helpen de hoeveelheid werk te verminderen.
Voor elk van de uitgangen in de resultaatvector voeren we twee verpakte DOT-productbewerkingen uit met behulp van de WebGPU-schaduwtaal ingebouwde dot4U8Packed en voegen we de resultaten bij elkaar toe. In totaal voeren we voor de gehele matrix-vector vermenigvuldiging geen gegevensconversie uit. We voeren 8 ingepakte puntproducten en 4 gehele toevoegingen uit.
We hebben verpakte gehele getal DOT-producten getest met 8-bit gegevens over verschillende GPU's van de consument. In vergelijking met 16-bits drijvende punt kunnen we zien dat 8-bit 1,6 tot 2,8 keer sneller is. Wanneer we bovendien ingepakte gehele DOT -producten gebruiken, zijn de prestaties nog beter. Het is 1,7 tot 2,9 keer sneller.
Controleer op browserondersteuning met de eigenschap wgslLanguageFeatures . Als de GPU geen native ingepakte DOT -producten ondersteunt, dan wordt de browser zijn eigen implementatie polyfills.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Het volgende codefragment diff (verschil) dat de wijzigingen benadrukt die nodig zijn om gepakte gehele producten te gebruiken in een WebGPU -shader.
Voordat - een WebGPU -schader die gedeeltelijke puntproducten verzamelt in de variabele 'sum'. Aan het einde van de lus bevat `sum` het volledige puntproduct tussen een vector en een rij van de invoermatrix.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Na - een WebGPU -shader geschreven om ingepakte gehele DOT -producten te gebruiken. Het belangrijkste verschil is dat in plaats van 4 floatwaarden uit de vector en matrix te laden, deze schader een enkel gehele 32-bits geheel getal laadt. Dit 32-bit gehele getal bevat de gegevens van vier 8-bit gehele waarde. Vervolgens roepen we dot4U8Packed aan om het puntproduct van de twee waarden te berekenen.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Zowel 16-bit drijvende punt als verpakte gehele DOT-producten zijn de verzonden functies in chroom die AI en ML versnellen. 16-bit drijvende punt is beschikbaar wanneer de hardware het ondersteunt en Chrome in alle apparaten ingepakte gehele TEGER DOT-producten implementeert.
U kunt deze functies vandaag in Chrome Stable gebruiken om betere prestaties te bereiken.
Voorgestelde kenmerken
Uitkijken vooruit, we onderzoeken nog twee functies: subgroepen en coöperatieve matrix vermenigvuldiging.
Met de functie Subgroepen kan SIMD-niveau parallellisme communiceren of collectieve wiskundige bewerkingen uitvoeren, zoals een som voor meer dan 16 nummers. Dit zorgt voor efficiënte cross-thread gegevensuitwisseling. Subgroepen worden ondersteund op moderne GPUS API's, met verschillende namen en in enigszins verschillende vormen.
We hebben de gemeenschappelijke set gedistilleerd in een voorstel dat we naar de WebGPU -standaardisatiegroep hebben gebracht. En we hebben geprototypeerde subgroepen in chroom achter een experimentele vlag en hebben onze eerste resultaten in de discussie gebracht. Het belangrijkste probleem is hoe draagbaar gedrag te garanderen.
Cooperative Matrix Multipy is een recentere toevoeging aan GPU's. Een grote matrixvermenigvuldiging kan worden onderverdeeld in meerdere kleinere matrixvermenigvuldigingen. Cooperative Matrix Multipy voert vermenigvuldigingen uit op deze kleinere blokken met een vaste grootte in een enkele logische stap. Binnen die stap werkt een groep threads efficiënt samen om het resultaat te berekenen.
We hebben ondersteuning onderzocht in onderliggende GPU API's en zijn van plan een voorstel te presenteren aan de WebGPU -standaardisatiegroep. Net als bij subgroepen verwachten we dat veel van de discussie zich zal concentreren op de draagbaarheid.
Om de prestaties van subgroepoperaties te evalueren, in een echte toepassing, hebben we experimentele ondersteuning voor subgroepen in MediaPipe geïntegreerd en getest met het prototype van Chrome voor subgroepbewerkingen.
We hebben subgroepen gebruikt in GPU -kernels van de voorvulfase van het grote taalmodel, dus ik rapporteer alleen de versnelling voor de voorvillfase. Op een Intel GPU zien we dat subgroepen twee en een half keer sneller presteren dan de basislijn. Deze verbeteringen zijn echter niet consistent in verschillende GPU's.
De volgende grafiek toont de resultaten van het toepassen van subgroepen om een Matrix Multiple Microbenchmark te optimaliseren over meerdere GPU's van meerdere consumenten. Matrix vermenigvuldiging is een van de zwaardere bewerkingen in grote taalmodellen. Uit de gegevens blijkt dat op veel van de GPU's subgroepen de snelheid twee, vijf en zelfs dertien keer de basislijn verhogen. Merk echter op dat op de eerste GPU subgroepen helemaal niet veel beter zijn.
GPU -optimalisatie is moeilijk
Uiteindelijk is de beste manier om uw GPU te optimaliseren, afhankelijk van welke GPU de klant biedt. Het gebruik van fancy nieuwe GPU -functies loont niet altijd op hun manier die u zou verwachten, omdat er veel complexe factoren kunnen zijn. De beste optimalisatiestrategie voor de ene GPU is misschien niet de beste strategie voor een andere GPU.
U wilt de geheugenbandbreedte minimaliseren, terwijl u de computerthreads van de GPU volledig gebruikt.
Geheugentoegangspatronen kunnen ook erg belangrijk zijn. GPU's hebben de neiging om veel beter te presteren wanneer het Compute -threads toegang krijgen tot geheugen in een patroon dat optimaal is voor de hardware. Belangrijk: u moet verschillende prestatiekenmerken verwachten op verschillende GPU -hardware. Mogelijk moet u verschillende optimalisaties uitvoeren, afhankelijk van de GPU.
In de volgende grafiek hebben we hetzelfde Matrix Multipy -algoritme genomen, maar een andere dimensie toegevoegd om de impact van verschillende optimalisatiestrategieën en de complexiteit en variantie over verschillende GPU's verder aan te tonen. We hebben hier een nieuwe techniek geïntroduceerd, die we "Swizzle" zullen noemen. Swizzle optimaliseert de geheugentoegangspatronen om optimaaler te zijn voor de hardware.
Je kunt zien dat de geheugen swizzle een aanzienlijke impact heeft; Het is soms zelfs zelfs impactvoller dan subgroepen. Op GPU 6 biedt Swizzle een 12x versnelling, terwijl subgroepen een 13x versnelling bieden. Gecombineerd hebben ze een ongelooflijke 26x -versnelling. Voor andere GPU's presteren soms swizzle en subgroepen gecombineerd beter dan een van beide alleen. En op andere GPU's presteert exclusief gebruiken Swizzle het beste.
Het afstemmen en optimaliseren van GPU -algoritmen om goed te werken op elk stuk hardware, kan veel expertise vereisen. Maar gelukkig is er een enorme hoeveelheid getalenteerd werk naar bibliotheken op een hoger niveau, zoals MediaPipe , Transformers.js , Apache TVM , OnNX Runtime Web en meer.
Bibliotheken en frameworks zijn goed gepositioneerd om de complexiteit van het beheren van diverse GPU-architecturen en het genereren van platformspecifieke code die goed op de client zal werken, om te gaan.
Afhaalrestaurants
Het Chrome -team blijft helpen bij het evolueren van de WebAssembly- en WebGPU -normen om het webplatform voor werklast van machine learning te verbeteren. We investeren in snellere rekenprimitieven, een betere interop tussen webstandaarden en zorgen ervoor dat modellen zowel groot als klein in staat zijn om efficiënt te lopen op apparaten.
Ons doel is om de mogelijkheden van het platform te maximaliseren met behoud van het beste van het web: het is bereik, bruikbaarheid en draagbaarheid. En we doen dit niet alleen. We werken in samenwerking met de andere browserverkopers bij W3C en veel ontwikkelingspartners.
We hopen dat u zich het volgende herinnert, terwijl u werkt met WebAssembly en WebGPU:
- AI -inferentie is nu beschikbaar op internet, over apparaten. Dit biedt het voordeel van het uitvoeren van clientapparaten, zoals lagere serverkosten, lage latentie en verhoogde privacy.
- Hoewel veel besproken functies voornamelijk relevant zijn voor de auteurs van de kader, kunnen uw applicaties profiteren zonder veel overhead.
- Webstandaarden zijn vloeiend en evolueren, en we zijn altijd op zoek naar feedback. Deel de uwe voor WebAssembly en WebGPU .
Dankbetuigingen
We willen graag het Intel Web Graphics Team bedanken, die een belangrijke rol speelden bij het besturen van de WebGPU F16 en Packed Integer DOT -productfuncties. We willen graag de andere leden van de WebAssembly- en WebGPU -werkgroepen bedanken bij W3C, inclusief de andere browserverkopers.
Bedankt aan de AI- en ML -teams, zowel bij Google als in de open source -community voor ongelooflijke partners. En natuurlijk, al onze teamgenoten die dit allemaal mogelijk maken.