
このドキュメントは、WebAssembly と WebGPU の機能強化によるウェブ AI の高速化(パート 1)の続きです。続行する前に、この投稿を読むか、IO 24 での講演を視聴することをおすすめします。



WebGPU
WebGPU を使用すると、ウェブ アプリケーションはクライアントの GPU ハードウェアにアクセスして、効率的で高度な並列計算を実行できます。Chrome で WebGPU をリリースしてから、ウェブでの人工知能(AI)と機械学習(ML)の素晴らしいデモが登場しています。
たとえば、Web Stable Diffusion では、AI を使用してブラウザ内で直接テキストから画像を生成できることを示しました。今年の初めに、Google 独自の Mediapipe チームが大規模言語モデル推論の試験運用版サポートを公開しました。
次のアニメーションは、Google のオープンソースの大規模言語モデル(LLM)である Gemma が、Chrome で完全にデバイス上でリアルタイムで実行されている様子を示しています。
Meta の Segment Anything モデルの次の Hugging Face のデモでは、高品質のオブジェクト マスクが完全にクライアント上で生成されます。
これらは、AI と ML 向けの WebGPU のパワーを示す素晴らしいプロジェクトのほんの一部です。WebGPU を使用すると、これらのモデルやその他のモデルを CPU よりも大幅に高速に実行できます。
Hugging Face の テキスト エンベディングの WebGPU ベンチマークでは、同じモデルの CPU 実装と比較して大幅な高速化が示されています。Apple M1 Max ノートパソコンでは、WebGPU は 30 倍以上高速でした。また、WebGPU によってベンチマークが 120 倍以上高速化されたという報告もあります。
AI と ML 向けの WebGPU 機能の改善
WebGPU は、コンピューティング シェーダーをサポートしているため、数十億のパラメータを持つ AI モデルや ML モデルに適しています。コンピューティング シェーダーは GPU で実行され、大量のデータに対して並列配列オペレーションを実行するのに役立ちます。
昨年、WebGPU には多くの改善が加えられましたが、ウェブでの ML と AI のパフォーマンスを向上させる機能も引き続き追加されています。最近、16 ビット浮動小数点数とパック整数のドット積の 2 つの新機能をリリースしました。
16 ビット浮動小数点数
ML ワークロードでは精度が要求されないことを忘れないでください。shader-f16 は、WebGPU シェーディング言語で f16 型を使用できるようにする機能です。この浮動小数点型は、通常の 32 ビットではなく 16 ビットを使用します。f16 は範囲が狭く精度が低くなりますが、多くの ML モデルでは十分です。
この機能により、次のような方法で効率性が向上します。
メモリの削減: f16 要素を持つテンソルは占有するスペースが半分になるため、メモリ使用量が半分に削減されます。GPU の計算はメモリ帯域幅でボトルネックになることが多いため、メモリを半分にするとシェーダーの実行速度が 2 倍になることがあります。技術的には、メモリ帯域幅を節約するために f16 は必要ありません。データを低精度形式で保存し、シェーダーで計算用にフル f32 に拡張できます。ただし、GPU はデータの圧縮と解凍に追加のコンピューティング能力を消費します。
データ変換の削減: f16 は、データ変換を最小限に抑えることでコンピューティングの使用量を削減します。低精度データは、変換せずに保存して直接使用できます。
並列処理の増加: 最新の GPU では、GPU の実行ユニットに同時により多くの値を収容できるため、より多くの並列計算を実行できます。たとえば、1 秒あたり最大 5000 兆回の f32 浮動小数点演算をサポートする GPU は、1 秒あたり 10000 兆回の f16 浮動小数点演算をサポートしている場合があります。
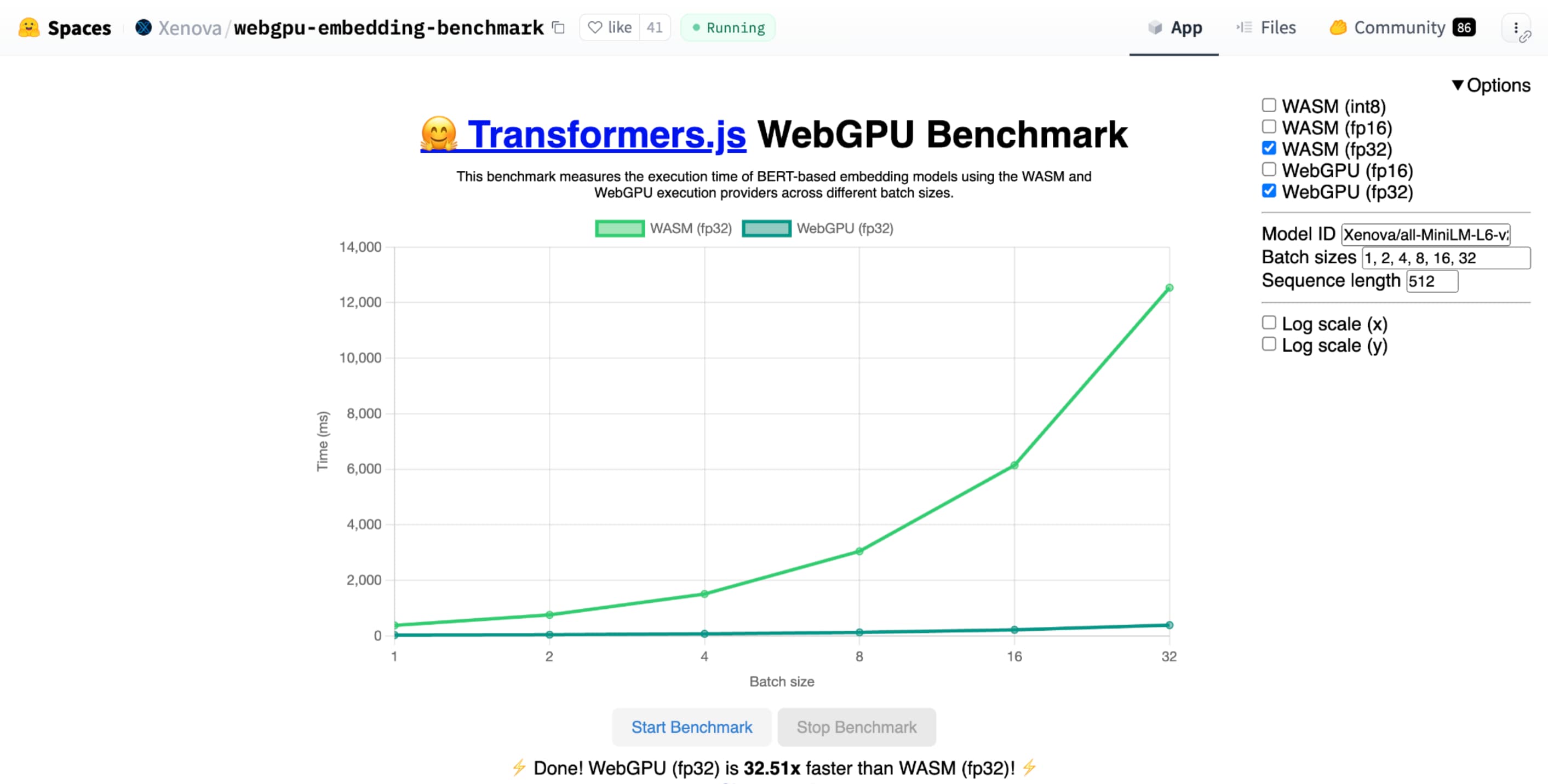
shader-f16 を使用すると、Hugging Face のテキスト エンベディング用の WebGPU ベンチマークのベンチマークは、Apple M1 Max ラップトップで f32 よりも 3 倍速く実行されます。
WebLLM は、複数の大規模言語モデルを実行できるプロジェクトです。オープンソースの ML コンパイラ フレームワークである Apache TVM を使用します。
Llama 3 の 80 億パラメータモデルを使用して、WebLLM にパリへの旅行を計画してもらいました。結果から、モデルのプリフィル フェーズで、f16 は f32 の 2.1 倍高速であることがわかります。デコード フェーズでは 1.3 倍以上高速です。
アプリはまず、GPU アダプターが f16 をサポートしていることを確認し、利用可能な場合は、GPU デバイスをリクエストするときに明示的に有効にする必要があります。f16 がサポートされていない場合、requiredFeatures 配列でリクエストすることはできません。
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
次に、WebGPU シェーダーで、上部にある f16 を明示的に有効にする必要があります。その後、他の浮動小数点データ型と同様にシェーダー内で自由に使用できます。
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
整数のドット積の圧縮
多くのモデルは、8 ビットの精度(f16 の半分)でも問題なく動作します。これは、セグメンテーションやオブジェクト認識用の LLM や画像モデルでよく使用されます。ただし、精度が低くなるとモデルの出力品質が低下するため、8 ビットの量子化はすべてのアプリケーションに適しているわけではありません。
8 ビット値をネイティブにサポートする GPU は比較的少ないため、ここで、整数のパッキングされた内積が役立ちます。Chrome 123 で DP4a をリリースしました。
最新の GPU には、2 つの 32 ビット整数を受け取り、それぞれを 4 つの連続した 8 ビット整数として解釈し、コンポーネント間のドット積を計算する特別な命令があります。
これは、行列乗算カーネルが多数のドット積で構成されているため、AI と ML に特に役立ちます。
たとえば、4 x 8 行列に 8 x 1 ベクトルを乗算します。この計算では、4 つの内積を計算して、出力ベクトル A、B、C、D の各値を計算します。
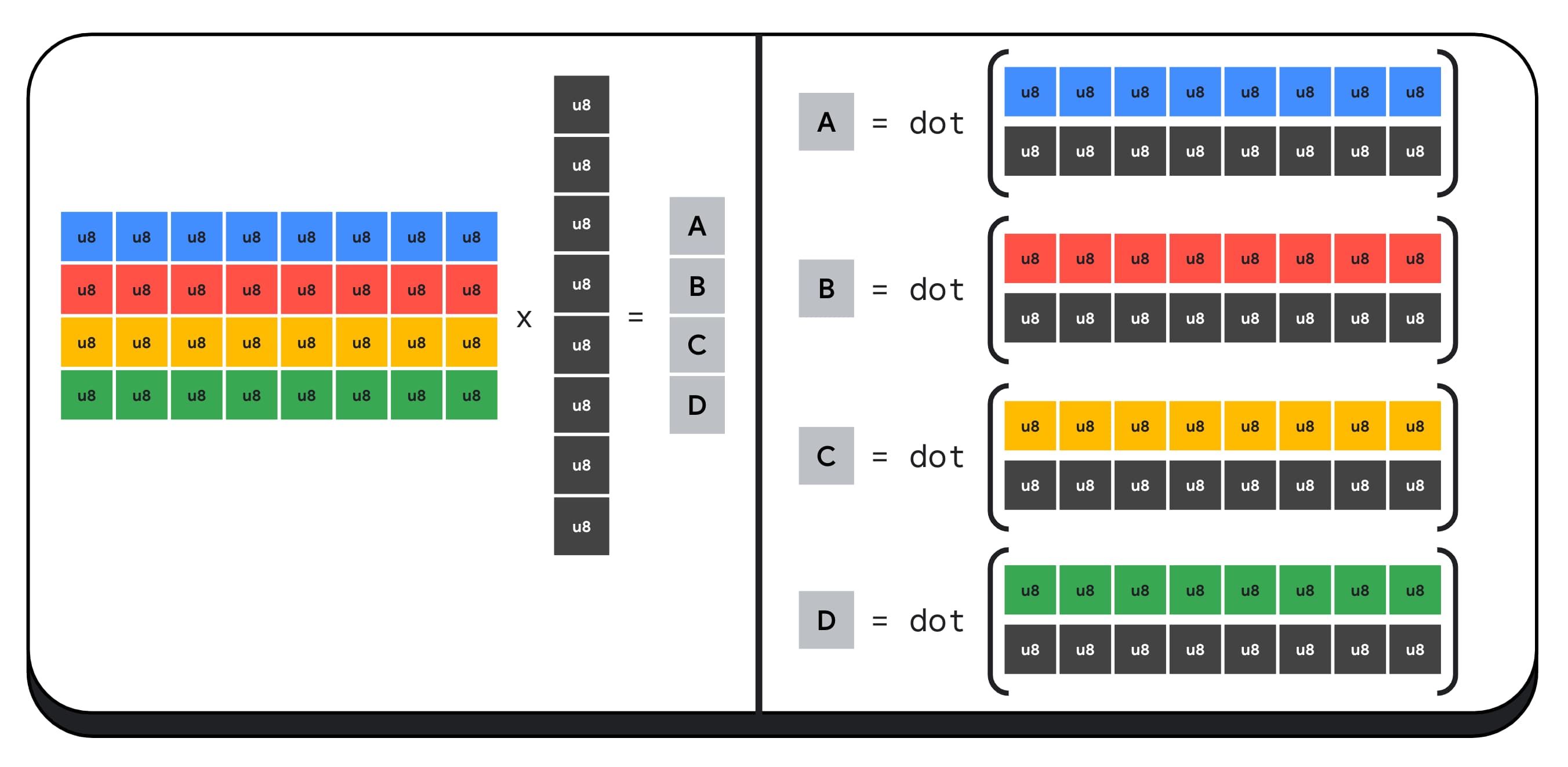
これらの出力の計算プロセスは同じです。ここでは、1 つの出力の計算手順について説明します。計算を行う前に、まず 8 ビットの整数データを、算術演算を実行できる型(f16 など)に変換する必要があります。次に、要素ごとの乗算を実行し、最後にすべての積を合計します。行列とベクトルの乗算全体で、40 回の整数から浮動小数点への変換(データの展開)、32 回の浮動小数点乗算、28 回の浮動小数点加算が行われます。
演算が多い大規模な行列の場合、パックされた整数の内積を使用すると、作業量を削減できます。
結果ベクトルの各出力について、WebGPU シェーディング言語の組み込み dot4U8Packed を使用して 2 つのパックド ドット積演算を行い、結果を合計します。合計すると、行列とベクトルの乗算全体でデータ変換は行われません。8 個のパッキングされた内積と 4 個の整数加算を実行します。
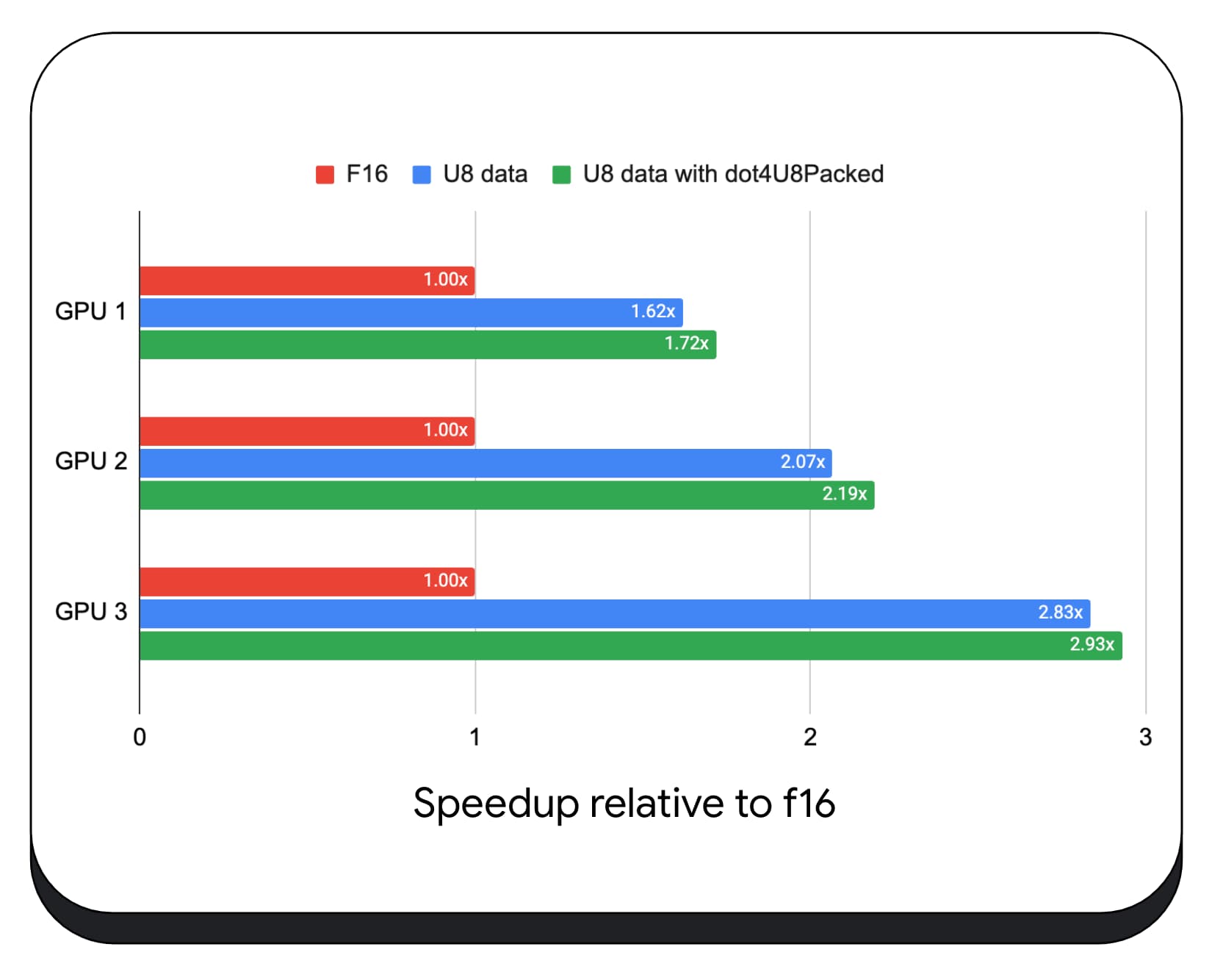
さまざまなコンシューマ GPU で、8 ビットデータの圧縮整数点積をテストしました。16 ビット浮動小数点数と比較すると、8 ビットの方が 1.6 ~ 2.8 倍高速です。パックされた整数の内積も使用すると、パフォーマンスはさらに向上します。1.7 ~ 2.9 倍高速になります。
wgslLanguageFeatures プロパティでブラウザのサポートを確認します。GPU がパックド ドット積をネイティブにサポートしていない場合、ブラウザは独自の実装をポリフィルします。
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
次のコード スニペットの差分(違い)は、WebGPU シェーダーでパック整数積を使用する際に必要な変更を示しています。
前 - 部分的なドット積を変数 sum に累積する WebGPU シェーダー。ループの終了時に、sum はベクトルと入力行列の 1 行の間の完全なドット積を保持します。
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
後 - パック整数のドット積を使用するように記述された WebGPU シェーダー。主な違いは、このシェーダーはベクトルと行列から 4 つの浮動小数点値を読み込むのではなく、単一の 32 ビット整数を読み込む点です。この 32 ビット整数には、4 つの 8 ビット整数値のデータが保持されます。次に、dot4U8Packed を呼び出して、2 つの値の内積を計算します。
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
16 ビットの浮動小数点とパック整数の内積は、AI と ML を高速化する Chrome の標準機能です。16 ビット浮動小数点数は、ハードウェアがサポートしている場合に使用できます。Chrome では、すべてのデバイスでパック整数の内積を実装しています。
これらの機能は Chrome 安定版で今すぐ使用でき、パフォーマンスの向上に役立ちます。
提案された機能
今後は、サブグループと協調型行列乗算の 2 つの機能を検討しています。
サブグループ機能を使用すると、SIMD レベルの並列処理を使用して、16 を超える数値の合計など、集約的な数学演算を通信または実行できます。これにより、スレッド間の効率的なデータ共有が可能になります。サブグループは、名前が異なり、形式が若干異なるものの、最新の GPU API でサポートされています。
共通セットを抽出して提案書にまとめ、WebGPU 標準化グループに提出しました。また、試験運用版フラグを使用して Chrome のサブグループのプロトタイプを作成して、最初の結果を議論に持ち込みました。主な問題は、ポータブルな動作を確保する方法です。
協調型行列乗算は、最近 GPU に追加されたものです。大きな行列乗算は、複数の小さな行列乗算に分割できます。協調型行列乗算では、これらの小さな固定サイズのブロックに対して 1 つの論理ステップで乗算を行います。このステップでは、スレッドのグループが効率的に連携して結果を計算します。
基盤となる GPU API のサポートを調査し、WebGPU 標準化グループに提案を提出する予定です。サブグループと同様に、議論の多くはポータビリティを中心に展開される見込みです。
サブグループ オペレーションのパフォーマンスを評価するため、実際のアプリケーションで、サブグループの試験運用版のサポートを MediaPipe に統合し、Chrome のサブグループ オペレーションのプロトタイプでテストしました。
大規模言語モデルのプリフィル フェーズで GPU カーネルのサブグループを使用したため、プリフィル フェーズの高速化のみを報告します。Intel GPU では、サブグループのパフォーマンスがベースラインの 2.5 倍になっています。ただし、これらの改善は GPU によって異なります。
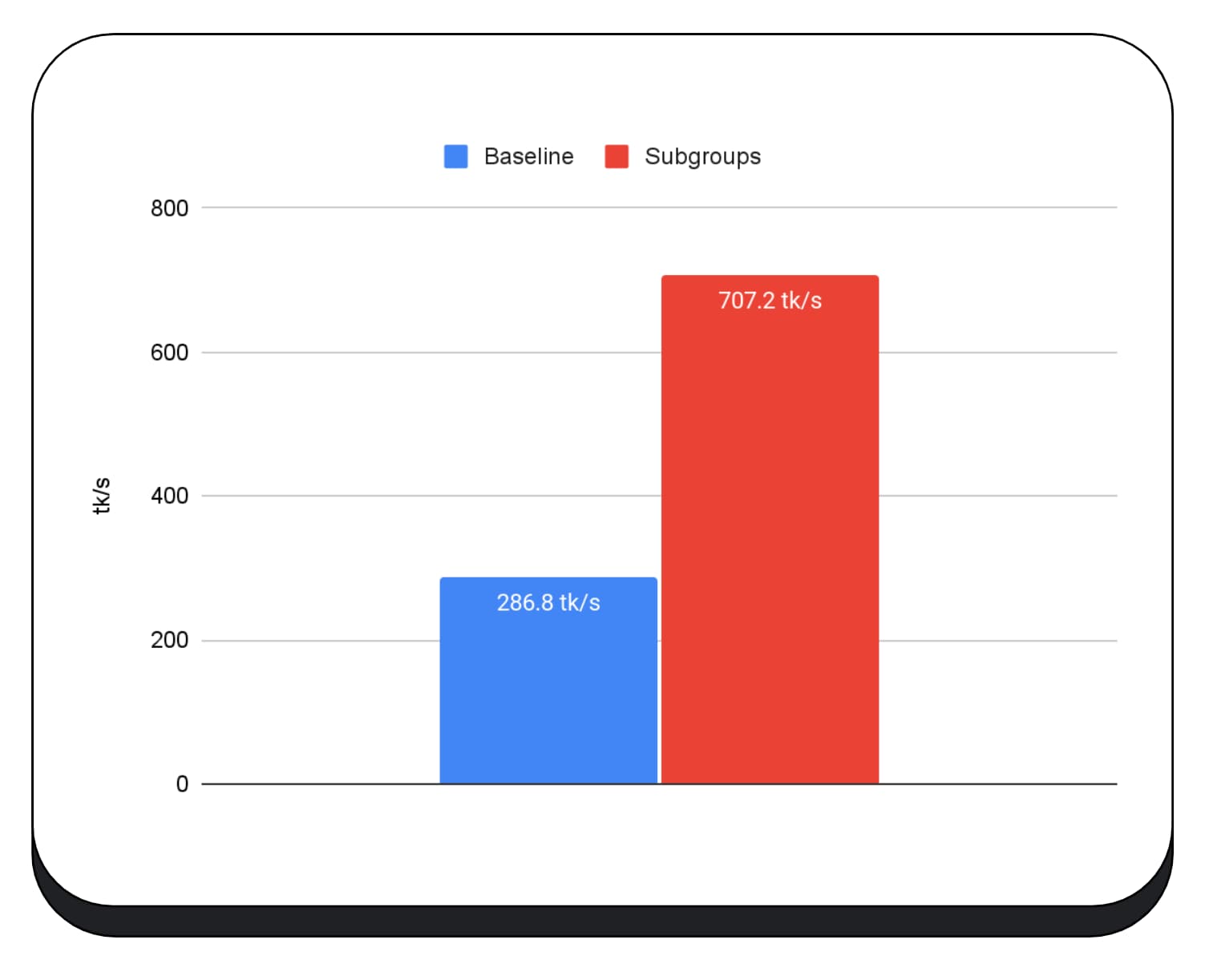
次のグラフは、サブグループを適用して複数のコンシューマ GPU で行列乗算マイクロベンチマークを最適化した結果を示しています。行列乗算は、大規模言語モデルで最も負荷の高いオペレーションの 1 つです。データによると、多くの GPU で、サブグループによってベースラインの 2 倍、5 倍、さらには 13 倍の速度向上が見られました。ただし、最初の GPU では、サブグループによる改善はほとんどありません。
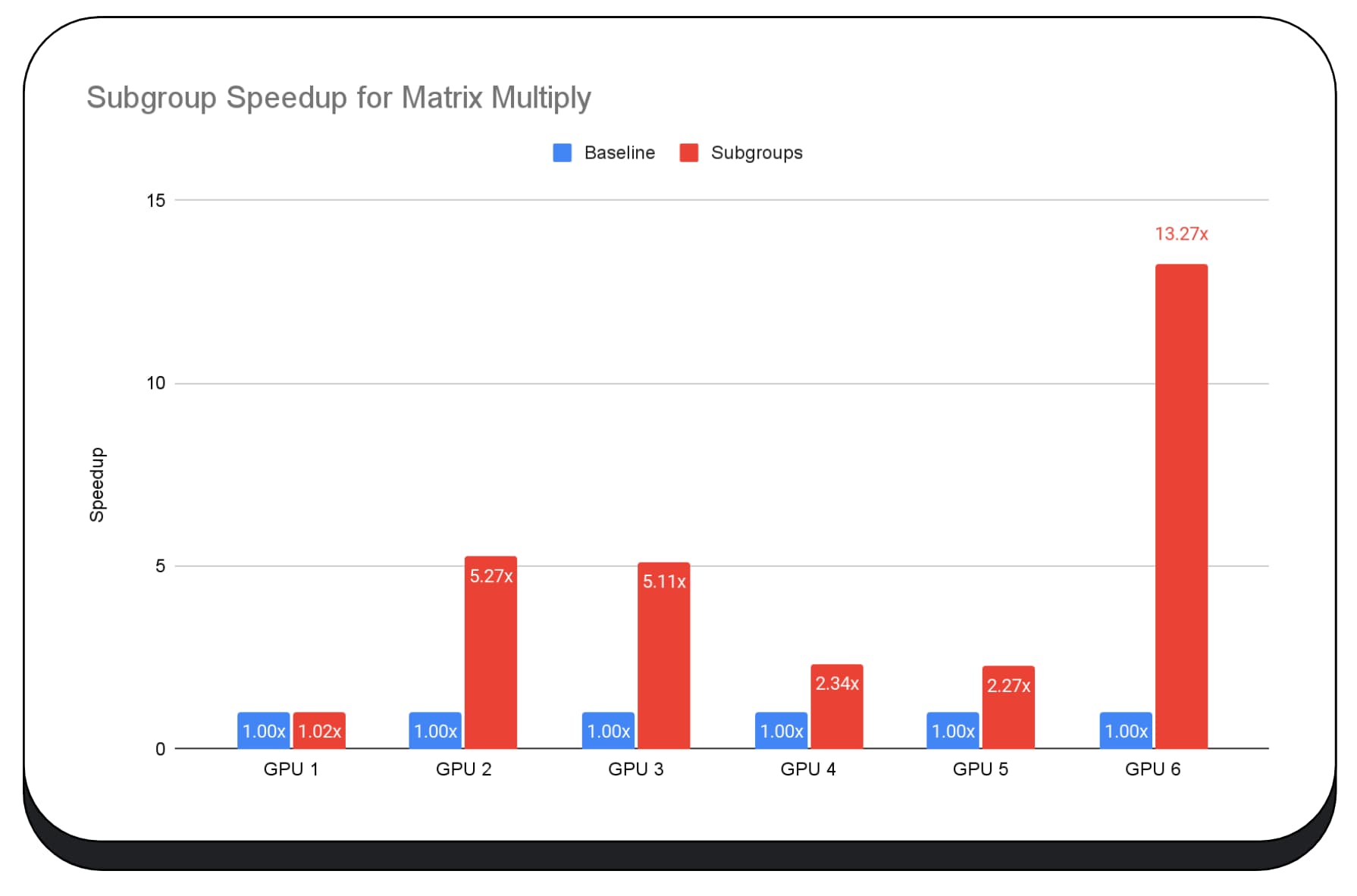
GPU の最適化が難しい
最終的に、GPU を最適化する最善の方法は、クライアントが提供する GPU によって異なります。新しい GPU 機能を使用すると、期待どおりに効果が得られない場合があります。これは、複雑な要因が関係しているためです。1 つの GPU で最適な最適化戦略が、別の GPU で最適な戦略とは限りません。
GPU のコンピューティング スレッドを最大限に活用しながら、メモリ帯域幅を最小限に抑える必要がある。
メモリアクセス パターンも非常に重要です。GPU は、コンピューティング スレッドがハードウェアに最適なパターンでメモリにアクセスすると、パフォーマンスが大幅に向上する傾向があります。重要: GPU ハードウェアによってパフォーマンス特性が異なることを想定してください。GPU によっては、異なる最適化を実行する必要があります。
次のグラフでは、同じ行列乗算アルゴリズムを使用していますが、別のディメンションを追加して、さまざまな最適化戦略の影響と、さまざまな GPU 間の複雑さとばらつきをさらに示しています。ここでは、新しい手法「Swizzle」を導入しました。スウィズルは、ハードウェアに最適なメモリアクセス パターンを最適化します。
メモリ スウィズルが大きな影響を与えていることがわかります。場合によっては、サブグループよりも影響が大きいこともあります。GPU 6 では、スウィズルは 12 倍の高速化を実現し、サブグループは 13 倍の高速化を実現します。これらを組み合わせることで、驚異的な 26 倍の高速化を実現できます。他の GPU では、スウィズルとサブグループを組み合わせた方が、どちらか一方を使用するよりもパフォーマンスが向上する場合があります。他の GPU では、スウィズルのみを適用した場合が最もパフォーマンスが優れています。
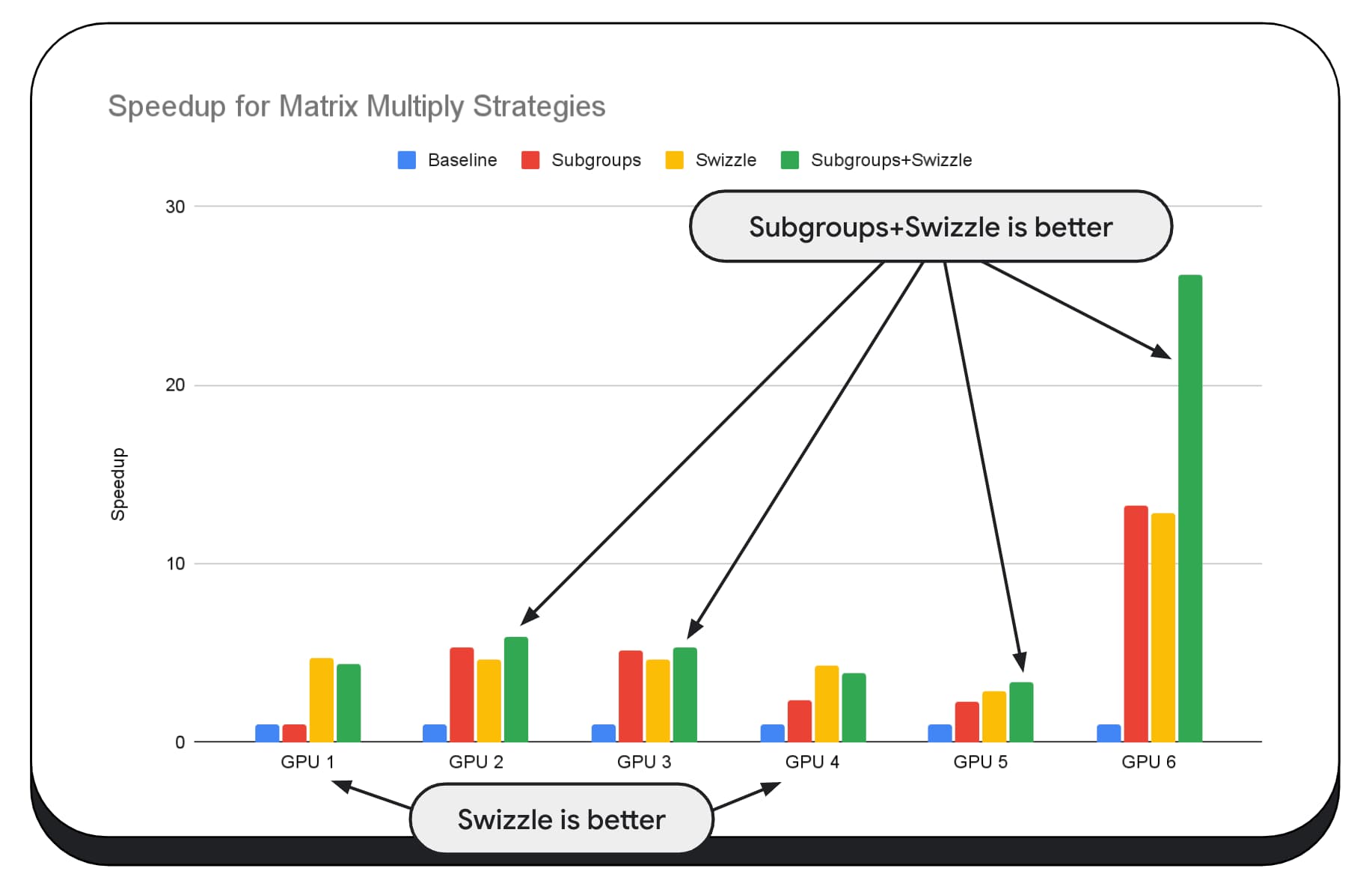
すべてのハードウェアで適切に動作するように GPU アルゴリズムをチューニングして最適化するには、高度な専門知識が必要になる場合があります。幸い、Mediapipe、Transformers.js、Apache TVM、ONNX Runtime Web などの高度なライブラリ フレームワークには、優れた成果がもたらされています。
ライブラリとフレームワークは、さまざまな GPU アーキテクチャの管理の複雑さを処理し、クライアントで適切に実行されるプラットフォーム固有のコードを生成するのに適しています。
要点
Chrome チームは、WebAssembly と WebGPU の標準の進化を支援し、ML ワークロード向けのウェブ プラットフォームを改善し続けています。Google は、コンピューティング プリミティブの高速化、ウェブ標準間の相互運用性の向上に投資し、大小さまざまなモデルをデバイス間で効率的に実行できるようにしています。
Google の目標は、ウェブの利点(リーチ、ユーザビリティ、ポータビリティ)を維持しながら、プラットフォームの機能を最大限に引き出すことです。この取り組みは Google だけでは実現できません。Google は、W3C の他のブラウザ ベンダーや多くの開発パートナーと連携して取り組んでいます。
WebAssembly と WebGPU を使用する際は、次の点にご注意ください。
- AI 推論は、ウェブ上のさまざまなデバイスで利用できるようになりました。これにより、サーバー費用の削減、低レイテンシ、プライバシーの強化など、クライアント デバイスで実行するメリットがもたらされます。
- 説明する機能の多くは主にフレームワークの作成者に関連するものですが、オーバーヘッドをほとんど増やさずにアプリケーションにメリットをもたらすことができます。
- ウェブ標準は流動的で進化しており、Google は常にフィードバックを募集しています。WebAssembly と WebGPU のフィードバックをお寄せください。
謝辞
WebGPU f16 とパック整数のドット積の機能の実現に貢献した Intel ウェブ グラフィック チームに感謝いたします。他のブラウザ ベンダーを含む、W3C の WebAssembly ワーキング グループと WebGPU ワーキング グループの他のメンバーに感謝いたします。
Google とオープンソース コミュニティの AI および ML チームの皆様、素晴らしいパートナーとしてご協力いただきありがとうございます。そして、このすべてを可能にしてくれたすべてのチームメイトにも感謝しています。